前言
关于LightGBM,网上已经介绍的很多了,笔者也零零散散的看了一些,有些写的真的很好,但是最终总觉的还是不够清晰,一些细节还是懵懵懂懂,大多数只是将原论文翻译了一下,可是某些技术具体是怎么做的呢?即落实到代码是怎么做的呢?网上资料基本没有,所以总有一种似懂非懂的感觉,貌似懂了LightGBM,但是又很陌生,很不踏实,所以本篇的最大区别或者优势是:源码分析,看看其到底怎么实现的,同时会将源码中的参数和官网给的API结合,这样对一些超参数理解会更透彻(对于一些诸如学习率的参数都是以前GBDT同用的,很熟悉了这里就没源码介绍,感兴趣的自行看源码),下面理解仅代表个人观点,若有错还请大家指教,一起学习交流,同时这里最大的贡献就是对源码的大体框架进行了一个摸索,对其中很多细节也欢迎大家交流学习!!!!最后希望本篇能够给大家在认识LightGBM方面带来那么一点点帮助!!!共勉!!!
建议:大家在学习LightGBM的时候(学习其他算法一样),不要仅仅是在网上随便百度一下,支零破碎的了解,最好一开始还是通读一遍原论文,其是最权威的,也是网上所有解析LightGBM文章的出处,包括最终LightGBM实际实现都是来源此论文,有部分博客包括本篇博客有可能因为个人理解有偏差,导致解析有误,如果不看论文容易被误导,所以还是建议看论文,加上自己的理解和博客介绍可能会更好!!!!!
本篇是按照相关技术来划分模块介绍的,以“ -------------”分隔开来,每个技术都以紫色斜体单独标了出来!!!!
参考:
原论文:https://papers.nips.cc/paper/6907-lightgbm-a-highly-efficient-gradient-boosting-decision-tree.pdf
官方API:Parameters — LightGBM 3.2.1.99 documentation
关于其实践,笔者这里用了一个kaggle上面正在比赛的赛题,有兴趣的同学可以看下:
lightgbm实践:Kaggle桑坦德银行客户交易预测比赛baseline_爱吃火锅的博客-CSDN博客
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
概述:
GBDT一经提出,就得到了广泛的关注,其演变的算法多多,包括Scikit-learn,gbm in R和pGBRT等等,尤其Xgboost更是被认为泛化能力最好的算法,其在各种问题中都表现出了优异的性能,但是在使用的过程中可以感受得出来Xgboost模型训练需要较长的时间,也就是说效率不是很高,能不能在Xgboost的基础上进一步改进,使得其训练速度提高呢?有需求就有了努力的方向,正是在这一背景下LightGBM出现了。
从名字也可以看出是Light+GBM,对于GBM很熟悉了其全称应该是gradient boosting machine即梯度提升树算法,其在该方面继续延续了Xgboost那一套集成学习方法,这里不再重述,Light是轻量级的意思,其关注的是模型训练速度,其也是LightGBM提出的初衷。所以本文就着眼盯住Light,看看其究竟是怎么做到Light的。
再次强调,LightGBM的着重点就是两个字 “要快!!!!!!!!!”,所以我们在看其算法的时候不论其提出采用了什么新的技术记住其就是一个出发点快!!!本着这个原则我们来学习LightGBM。(所介绍的技术都是和快有关的)
LightGBM在实际代码实现的时候采用了多种“快”的技术集合,但就原论文的而言主要提出了两大技术:
(1)GOSS(Gradient-based One-Side Sampling):减少样本数
(2)EFB (Exclusive Feature Bundling ):减少特征数
可以看到其想法的出发点很简单也很容易想到,关键怎么落实,后面大家会看到。
除此之外其在真真实现的时候还采用了直方图,支持分布式等等,通过下面的源码分析会看到一下细节:
直方图差加速
自动处理缺省值,包括是否将0视为缺省值。
处理类别特征
EFB、GOSS、Leaf-wise等细节
LightGBM正是由于本着快的思想,最终导致的一个优点就是能够处理大数据!!!!!!!
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
直方图 FeatureHistogram
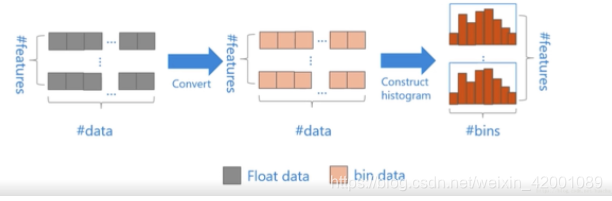
在训练树的时候,需要找到最佳划分节点,为此其中需要遍历特征下的每一个value,这里通常有两种做法:pre-sorted algorithm(预排序算法)和histogram-based algorithm(直方图算法)。
预排序算法就是传统的要遍历当前特征下的每一个value,其通常是在开始对该特征下的每个value进行排序,后面就是遍历选取最佳划分点,直方图算法其实就是将value离散化了,生成一个个bin,常称为分桶,离散化后的bin数其实是小于原始的value数的,于是复杂度从(#feature*#data)降为了(#feature*#bin)。
需要注意:直方图算法并不是LightGBM所特有的或是闪亮点(其闪亮点还是论文所说的两大技术GOSS和EFB),GBDT的相关演变算法有很多,有部分计算法就用了直方图,类如Scikit-learn和gbm in R演变算法使用了pre-sorted algorithm算法,pGBRT算法是使用了histogram-based algorithm,而XGBoost两者都支持,这里多说一句,Xgboost的近似算法其实就用了histogram-based algorithm如下:
(上面所说的几种演变算法,在论文的参考文献都可以找到,有兴趣的可以拜读一下)

对于特征k这里找到先找到一组候选分割点就是上图中的Sk1,Sk2,Sk2,这里和LightGBM中所提到的bin其实思想是一样的
不同于pre-sorted algorithm的穷举方法,这里有两种算法一种是全局算法:即在初始化tree的时候划分好候选分割点,并且在树的每一层都使用这些候选分割点;另一种是局部算法,即每一次划分的时候都重新计算候选分割点。这两者各有利弊,全局算法不需要多次计算候选节点,但需要一次获取较多的候选节点供后续树生长使用,而局部算法一次获取的候选节点较少,可以在分支过程中不断改善,即适用于生长更深的树,两者在effect和accuracy做trade off。
关于怎么找这些候选集合,其使用了Weighted Quantile Sketch算法,有兴趣的同学可以看一下:Xgboost近似分位数算法_anshuai_aw1的博客-CSDN博客
总之这里想表达一句话就是:因为在以前GBDT的众多演变算法中,Xgbosst性能应该是最好的一个啦(Xgboost简单介绍https://blog.csdn.net/weixin_42001089/article/details/84965333),而LightGBM也算是演变家族中的一员,所以为了凸显其优越性,都是直接和Xgboost对比的,论文第五部分给出了对比结果大家可以直接去看,但是须知单从和Xgboost对比角度来看并不是直方图带来的这种差异可观的效果或者说很大方面不是,其是下面介绍的多种其他方面技术结合的结果,尤其是其论文提到的两大技术,当然了单单看直方图算法,这不是也是一种优化,所以LightGBM本着快的原则也采用了histogram-based algorithm
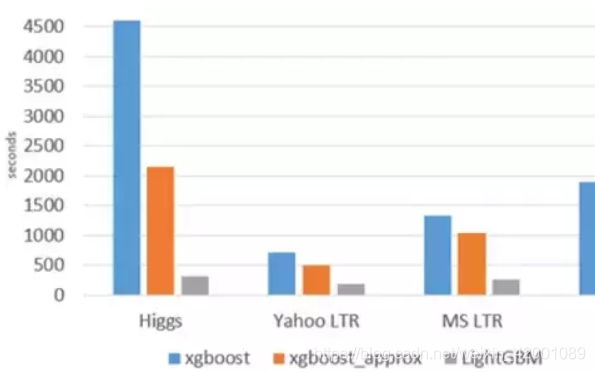
看到Xgboost,其近似算法和LightGBM算法的速度对比
好了说了这么多理论下面看一下其源码吧:
位于LightGBM/src/treelearner/feature_histogram.hpp
其下一共有三个类:
FeatureMetainfo
FeatureHistogram
HistogramPool
其中 FeatureMetainfo类是直方图分裂算法的一些基本配置,其只有属性没有方法。
FeatureHistogram可以说是直方图分裂算法的核心部分,我们主要来看看该类和分裂相关的几个主要方法,其属性很简单就是data_即直方图中的储存数据,包括一阶导数总和以及二阶导数总和等等。
HistogramPool类的作用就是构建data_的过程。
明白了大致的作用,接下来我们就深入其中一探究竟:
FeatureMetainfo属性:
类的属性如下:
public:
int num_bin;
MissingType missing_type;
int8_t bias = 0;
uint32_t default_bin;
int8_t monotone_type;
double penalty;
/*! \brief pointer of tree config */
const Config* config;
BinType bin_type;
};其中config中包含了很多与树有关的属性,在下面会看到,这里还有一个比较重要的属性是missing_type,其是lightGBM的一个超参数,用于指明缺省值类型后面会看到解释
接下来就是FeatureHistogram这个重点啦,
其属性较为简单:
FeatureHistogram() {
data_ = nullptr;
}接下来我们重点看看该类定义的方法
(1)ThresholdL1:L1门限
static double ThresholdL1(double s, double l1) {
const double reg_s = std::max(0.0, std::fabs(s) - l1);
return Common::Sign(s) * reg_s;
}其中s就是一阶导数和,不难看出其返回的值是:、
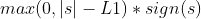
(2)CalculateSplittedLeafOutput:计算分裂节点的输出
static double CalculateSplittedLeafOutput(double sum_gradients, double sum_hessians, double l1, double l2, double max_delta_step) {
double ret = -ThresholdL1(sum_gradients, l1) / (sum_hessians + l2);
if (max_delta_step <= 0.0f || std::fabs(ret) <= max_delta_step) {
return ret;
} else {
return Common::Sign(ret) * max_delta_step;
}
}不难看出其返回的值核心是:

注意其还有一个重载函数其实就是将结果进一步规范在了一个范围内(min_constraint,max_contraint)
static double CalculateSplittedLeafOutput(double sum_gradients, double sum_hessians, double l1, double l2, double max_delta_step,
double min_constraint, double max_constraint) {
double ret = CalculateSplittedLeafOutput(sum_gradients, sum_hessians, l1, l2, max_delta_step);
if (ret < min_constraint) {
ret = min_constraint;
} else if (ret > max_constraint) {
ret = max_constraint;
}
return ret;
}(3)GetLeafSplitGainGivenOutput:计算当前节点的熵
static double GetLeafSplitGainGivenOutput(double sum_gradients, double sum_hessians, double l1, double l2, double output) {
const double sg_l1 = ThresholdL1(sum_gradients, l1);
return -(2.0 * sg_l1 * output + (sum_hessians + l2) * output * output);
}这里的output就是经过(2)函数的结果,从这里就可以清晰的看到在lightGBM真实实践中计算当前节点熵的具体表达式,还记得在Xgboost推导的结算当前节点对应的熵的结果吗?其大概形式是:(sum_gradients)*(sum_gradients)/(sum_hessians+L)即一阶导数的平方除以二阶导数加正则项的和,其和(2)的结果即这里的output比较像,只不过(2)的结果还给sum_gradients加了正则项L1(分母的正则项是+,分子的正则项是-,即带来的效果保持了一致性),而且一阶导数不是完全的平方,而是其中一个用到了激活函数(深度学习中通常这样称呼)sign,然后lgb最后的得到熵公式可以从上面看到。
对应的官方超参数有:
lambda_l1 : default = 0.0, type = double, aliases: reg_alpha, constraints: lambda_l1 >= 0.0
- L1 regularization
lambda_l2 : default = 0.0, type = double, aliases: reg_lambda, lambda, constraints: lambda_l2 >= 0.0
- L2 regularization
(4)GetSplitGains:计算分裂后左右子树的熵的和:
概括一下就是:其值=GetLeafSplitGainGivenOutput(left)+GetLeafSplitGainGivenOutput(right)
(5)GetLeafSplitGain:计算分裂前的熵
概括一下就是:其值等于:GetLeafSplitGainGivenOutput(left+right)
同时从这里可以看到:GetSplitGains-GetLeafSplitGain就是分裂后的增益
以上就是定义的基本操作函数,下面介绍的函数就是功能函数(直方图寻找最佳切分点):
首先其可以看成是两大类:
一:特征下的值是非连续的即所谓的类别特征。
二:特征下的值是连续的
下面先来看处理类别特征的相关函数,再来看处理连续特征的相关函数
(6)FindBestThresholdCategorical:处理处理类别特征。
其分为两种情况:one-hot形式和非one-hot形式,one-hot形式其实是一种one VS many的情况,而非one-hot是一种many VS many形式
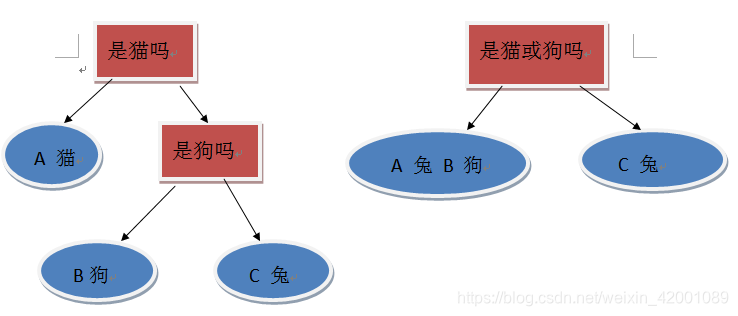
那么不言而喻第二种在大数据的情况下,好处多多,起码考虑的情况更多,而且不至于树深度太大,还有一个直观的好处就是单一的分裂其实带来的增益通常较少,因为每次仅仅从一大推信息中区分出那么一丁点信息,带来的信息增益自然不会高,第二种则是不一样。
加下来我们具体看看源码:
当bin的数目小于meta_->config->max_cat_to_onehot时即类别数目较少时例如开关状态只有两种这时候就采用one-hot形式,否则不采用one-hot形式。
当采用one-hot形式时:遍历每一个bin(类别),丢弃那些样本少的类别以及总二阶导数和少的样本:
if (use_onehot) {
for (int t = 0; t < used_bin; ++t) {
// if data not enough, or sum hessian too small
if (data_[t].cnt < meta_->config->min_data_in_leaf
|| data_[t].sum_hessians < meta_->config->min_sum_hessian_in_leaf) continue;
data_size_t other_count = num_data - data_[t].cnt;
// if data not enough
if (other_count < meta_->config->min_data_in_leaf) continue;
double sum_other_hessian = sum_hessian - data_[t].sum_hessians - kEpsilon;
// if sum hessian too small
if (sum_other_hessian < meta_->config->min_sum_hessian_in_leaf) continue;
注意看:这里是综合考虑左右子树的即只要按当前的bin划分出来的左右子树有一个满足抛弃条件即抛弃。同时这里也很好的体现了所谓的直方图差加速概念,说白了就是我们只要得到比如左子树,那么右子树就直接可以使用总的减去左子树得到,是不是很快!是不是很巧妙!这就是差加速的概念。
从这里可以看到ont-hot的one VS many形式:因为 不论是other_count还是sum_other_hessian等等都是除了当前这一类别之外其他所有类别的和。
最少样本数和最少二阶导数和树均是配置参数:meta_->config->min_data_in_leaf,config->min_sum_hessian_in_leaf
然后在剩下的bin中使用GetSplitGains计算得到分裂后的左右子树的熵的和current_gain,其先和min_gain_shift比较,
if (current_gain <= min_gain_shift) continue;min_gain_shift是最小熵其定义如下:
min_gain_shift = gain_shift + meta_->config->min_gain_to_split其中gain_shift是通过GetLeafSplitGain计算得到的未分裂前的熵,min_gain_to_split是一个配置参数,其含义就是当前分裂最小需要的增益。话句话说比如没有分裂前熵是5,我们要求分裂后熵最少的增加2,所以当current_gain小于等于7时,说明利用该Bin分裂得到的增益不大,就不选用该bin作为分裂节点了,直接跳过。更直接点说就是分裂了还没有没分裂前熵大,那还分什么,对吧。
要是满足了current_gain 大于 min_gain_shift,那么我们就判断并更新:
if (current_gain > best_gain) {
best_threshold = t;
best_sum_left_gradient = data_[t].sum_gradients;
best_sum_left_hessian = data_[t].sum_hessians + kEpsilon;
best_left_count = data_[t].cnt;
best_gain = current_gain;
}这里的best_gain初始化值为kMinScore即最小得分,后续就是不断随着更新一直保持当前最大啦
当不采用one-hot形式时:
其首先遍历bin,得到样本多的bin,这一结果保存在sorted_idx中:
for (int i = 0; i < used_bin; ++i) {
if (data_[i].cnt >= meta_->config->cat_smooth) {
sorted_idx.push_back(i);
}
}当然了,这个多的衡量同样是一个配置参数控制的即meta_->config->cat_smooth
然后对sorted_idx根据(一阶导数/(二阶导数+meta_->config->cat_smooth))的大小进行排序:
auto ctr_fun = [this](double sum_grad, double sum_hess) {
return (sum_grad) / (sum_hess + meta_->config->cat_smooth);
};接下来是两个for循环,外面for循环代表的是方向即从左到右和从右到左两种遍历方式,为了便于理解这里举一个简单的例子,假设当前这一特征有4种类别:A,B,C,D,数学化后为0,1,2,3
那么我们先按照从左到右的顺序遍历,从0开始那么左树类别就是0,右树就是1,2,3,4计算增益比较更新,接着到1,那么左树就是0和1,右树就是2,3,4计算增益比较更新,接着到2,那么左树就是0,1,2右树就是3
其次我们按照从右到左的顺序遍历,从3开始,那么左树就是3,右树就是0,1,2计算增益比较更新,依次类推,,,,
代码中find_direction是方向其是一个数组里面有(1,-1),start_position代表起始点其值是(0,used_bin - 1)
左到右即:从0开始每次加1;右到左即:从used_bin - 1开始每次加-1;
for (size_t out_i = 0; out_i < find_direction.size(); ++out_i) {
auto dir = find_direction[out_i];
auto start_pos = start_position[out_i];
data_size_t min_data_per_group = meta_->config->min_data_per_group;
data_size_t cnt_cur_group = 0;
double sum_left_gradient = 0.0f;
double sum_left_hessian = kEpsilon;
data_size_t left_count = 0;
for (int i = 0; i < used_bin && i < max_num_cat; ++i) {
auto t = sorted_idx[start_pos];
start_pos += dir;
sum_left_gradient += data_[t].sum_gradients;
sum_left_hessian += data_[t].sum_hessians;
left_count += data_[t].cnt;
cnt_cur_group += data_[t].cnt;从外层for可以看到,其是先从左到右的, sum_left_gradient等累加的过程其实就是含义就是说将当前Bin的左面所有bin都归为左子树,毫无疑问当前Bin的右面所有bin就都归为左子树,就是此处出现了many VS many的身影!!!!!!!
当然了在遍历的过程中,在源代码中也可以看到同样会考虑分裂后左右子树的最少样本数和最少二阶导数和树即用到meta_->config->min_data_in_leaf,config->min_sum_hessian_in_leaf。
同时在代码中还有一点需要注意的就是:
if (cnt_cur_group < min_data_per_group) continue;
这里的cnt_cur_group就是当前单个bin中的样本数,min_data_per_group是一个配置选项,意思就是说当单个bin的data小于min_data_per_group就忽略掉,注意和min_data_in_leaf区分,min_data_in_leaf指的是当前被划分到一边(左或右)的所有bin的data数目。那么cat_smooth和min_data_per_group又是什么区别呢?看一下源码的逻辑是这样的:首先使用cat_smooth淘汰掉那些data小的bin,然后在剩下的bin中按照上述所说的排序,然后左右遍历,遍历的过程中又会根据min_data_per_group淘汰掉一部分小的data。
这里需要两点说明:
<1>可以看到非one-hot 是一种many VS many的形式即有左子树是0和1,右子树是2,3这种情况,而在one-hot中是不会出现这种情况的,其只可能是左子树是0,右子树是1,2,3或左子树是1,右子树是0,2,3这种one VS many的形式。
<2>左右两次遍历的意义何在?其意义就在于缺省值到底是在哪里?其实这类问题叫做Sparsity-aware Split Finding稀疏感知算法,
当从左到右,对于缺省值就规划到了右面,当方向相反时,缺省值都规划到了左面,大家可以这样想这个问题:
当从左到右时,我们记录不论是当前一阶导数和也好二阶导数也罢,都是针对有值的(缺省值就没有一阶导数和二阶导数),那么我们用差加速得到右子树,既然左子树没有包括缺省值,那么总的减去左子树自然就将缺省值归到右子树了,假如没有缺省值,其实这里进行两次方向的遍历并没有什么意义,为什么呢?假如最好的划分是样本1和样本3在一边,样本2和样本4在一边,那么两次方向遍历无非就是对应下图两种情况:

有区别吗?其实并没有,因为下一次根据Leaf-wise原则无非就是选取左面和右面一个进行下去即可所以说1,3到底在左面还是右面并没有关系,可是当有缺省值时就完全不一样了,比如这里有一个缺省值5.于是上图就变为:
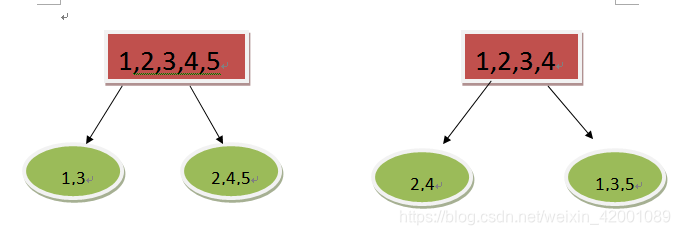
看出不同了吧,其实两次方向的遍历说白了就是将缺省值分别放到左右看看到底哪边好!!!!!!
<3>最后不论是one-hot还是非one-hot最后都会得到最佳分裂的Bin索引,记录在了best_threshold中,当然了对应非one-hot还得记录一个参数那就是方向 best_dir(1或者-1)
通过上面我们看到了一些参数(就是上文说的配置),下面我们结合官方给出的API,将其来还原到源码中就会更加清楚其作用:
min_data_per_group :default = 100, type = int, constraints: min_data_per_group > 0
- minimal number of data per categorical group
cat_smooth :default = 10.0, type = double, constraints: cat_smooth >= 0.0
- used for the categorical features
- this can reduce the effect of noises in categorical features, especially for categories with few data
min_data_in_leaf :default = 20, type = int, aliases: min_data_per_leaf, min_data, min_child_samples, constraints: min_data_in_leaf >= 0
- minimal number of data in one leaf. Can be used to deal with over-fitting
min_sum_hessian_in_leaf :default = 1e-3, type = double, aliases: min_sum_hessian_per_leaf, min_sum_hessian, min_hessian, min_child_weight, constraints: min_sum_hessian_in_leaf >= 0.0
- minimal sum hessian in one leaf. Like
min_data_in_leaf, it can be used to deal with over-fitting
max_cat_to_onehot :default = 4, type = int, constraints: max_cat_to_onehot > 0
- when number of categories of one feature smaller than or equal to
max_cat_to_onehot, one-vs-other split algorithm will be used
注意这里所说的one-vs-other就是我们上述的one-vs-many,含义一样。
min_gain_to_split :default = 0.0, type = double, aliases: min_split_gain, constraints: min_gain_to_split >= 0.0
- the minimal gain to perform split
看!是不是感觉一下明朗起来了,其实这些超参数大部分都是为了防止过拟合。
以上由于是第一次介绍相关的参数所以篇幅较长,尽量将所有的细节都介绍了,下面对相同的内容就不再重述啦!比如下面同样使用了min_data_in_leaf 以及左右遍历等伎俩,大家明白其目的就好了。
(7)FindBestThresholdNumerical:处理连续特征
该函数只是一个表象,其真真分裂算法核心在于(8),那么这里主要是做了一个判断,即是否将0看为缺省值,为此进行了不同的处理:
if (meta_->missing_type == MissingType::Zero) {
FindBestThresholdSequence(sum_gradient, sum_hessian, num_data, min_constraint, max_constraint, min_gain_shift, output, -1, true, false);
FindBestThresholdSequence(sum_gradient, sum_hessian, num_data, min_constraint, max_constraint, min_gain_shift, output, 1, true, false);
} else {
FindBestThresholdSequence(sum_gradient, sum_hessian, num_data, min_constraint, max_constraint, min_gain_shift, output, -1, false, true);
FindBestThresholdSequence(sum_gradient, sum_hessian, num_data, min_constraint, max_constraint, min_gain_shift, output, 1, false, true);
}通过对比大家可以看到两者的不同之处在于调用(8)函数时,最后两个参数不同,这两个参数是Bool类型含义如下:
bool skip_default_bin, bool use_na_as_missing第一个代表是否跳过默认bin,第二个含义是是否使用NaN作为缺省值。同时可以看道不论那种情况,都是调用了两遍(8)函数,两次的不同在于1或-1,该字段的意思是方向,1代表从左到右,-1代表是从右到左。所以我们还是将重点放在(8)函数吧!
(8)FindBestThresholdSequence:处理连续特征的分裂算法核心
这里核心的东西:
double current_gain = GetSplitGains(sum_left_gradient, sum_left_hessian, sum_right_gradient, sum_right_hessian,
meta_->config->lambda_l1, meta_->config->lambda_l2, meta_->config->max_delta_step,
min_constraint, max_constraint, meta_->monotone_type);
// gain with split is worse than without split
if (current_gain <= min_gain_shift) continue;
// mark to is splittable
is_splittable_ = true;
// better split point
if (current_gain > best_gain) {
best_left_count = left_count;
best_sum_left_gradient = sum_left_gradient;
best_sum_left_hessian = sum_left_hessian;
// left is <= threshold, right is > threshold. so this is t-1
best_threshold = static_cast<uint32_t>(t - 1 + bias);
best_gain = current_gain;
}可以看到和处理类别特征非one-hot形式一样,方向的话这里就简单判断了一下:是-1时从右遍历,1是从左:
-1时:
const int t_end = 1 - bias;
// from right to left, and we don't need data in bin0
for (; t >= t_end; --t) {
............1时:
t = -1;
for (; t <= t_end; ++t) {
.............有两点需要注意:
<1>当遇见默认的Bin时需要跳过:
if (skip_default_bin && (t + bias) == static_cast<int>(meta_->default_bin)) { continue; }当将0也视为缺省值时是需要跳过默认的bin 的,而将只将NaN视为缺省值时是不需要跳过默认的bin 的
<2>在没将0也视为缺省值时需要进行的特殊处理是:
注意这一过程只在从左到右这一方向做:
if (use_na_as_missing && bias == 1) {
sum_left_gradient = sum_gradient;
sum_left_hessian = sum_hessian - kEpsilon;
left_count = num_data;
for (int i = 0; i < meta_->num_bin - bias; ++i) {
sum_left_gradient -= data_[i].sum_gradients;
sum_left_hessian -= data_[i].sum_hessians;
left_count -= data_[i].cnt;
}
t = -1;
}
结合上面缺省值的分析,假设特征值下是0,那么是不是也相当于没计数,所以代码中并没有进行什么处理就是左右遍历两次,相当于将0放到左右看看哪个好?但是当不将其视为缺省值,即这里的use_na_as_missing为真时,我们就要将bin最右边偏离bias为止的所有bin默认为了左子树。注意在从右到左的这一过程和use_na_as_missing并没有什么关系,也就是说将0划分到了左面,但在从左到右的时候按以前的话应该将其划分到右面了,但这里采用了默认还是左子树的做法(看似道理正确,但是还是有一点小纠结,还望大佬指正,笔者也再想想,好了接着往下写吧)
对应官方超参数的API:
use_missing :default = true, type = bool
- set this to
falseto disable the special handle of missing value
zero_as_missing : default = false, type = bool
- set this to
trueto treat all zero as missing values (including the unshown values in libsvm/sparse matrices) - set this to
falseto usenafor representing missing values
接着说一下HistogramPool这个类:
说白了该类主要就是构建data_的信息,其中包括bin等等,深入到代码中你会发现其主要是使用了Dataset这个数据集,例如下面的train_data:
void DynamicChangeSize(const Dataset* train_data, const Config* config, int cache_size, int total_size) {
if (feature_metas_.empty()) {
int num_feature = train_data->num_features();
feature_metas_.resize(num_feature);而这个Dataset类是在通过头文件中导入的:
#include <LightGBM/dataset.h>于是可以找到对应的源代码,仔细看其细节:
该类具体在LightGBM/include/LightGBM/dataset.h,大约在282行就可以看到其定义,这是头文件,其只是定义了一些接口,其主要实现细节即.cpp是在LightGBM/src/io/dataset.cpp位置。
该类有很多属性和方法,其中比较重要的方法就是:ConstructHistograms方法即构造直方图方法
从该方法中可以看到很多细节,例如使不使用二阶导数,不使用时会将其视为一个常数:
if (!is_constant_hessian) {
#pragma omp parallel for schedule(static)
for (data_size_t i = 0; i < num_data; ++i) {
ordered_gradients[i] = gradients[data_indices[i]];
ordered_hessians[i] = hessians[data_indices[i]];
}
} else {
#pragma omp parallel for schedule(static)
for (data_size_t i = 0; i < num_data; ++i) {
ordered_gradients[i] = gradients[data_indices[i]];
}
}这里的data_indices[i]就是具体到每一个样本,可以看到,当不使用二阶导数时即else部分就没有记录具体每个样本的二阶导数。但一阶导数都是始终记录的。
说到这里我们有必要另外起一个分界线了:因为下面涉及到LightGBM论文中提到的两大技术之一:EFB
----------------------------------------------------------------------------------------------------------------------------------------------------------------
EFB
上述我们已经简单介绍过了,在原论文中给出特征捆绑算法:

首先说一下其原理:(本人理解有误或大家有疑惑的可以去看原论文4.1部分)
大部分高纬度的数据集都是稀疏的,这就为我们捆绑特征带来了可能性,特征的稀疏就说明很多特征是相互排斥的,例如它们不总是同时取非0值,所以我们可以很放心的将多个特征捆绑为一个特征,所以复杂度就从(#data*#feature)降为(#data*#bundle),其中bundle就是经过捆绑后的特征数,通常bundle远小于feature。
需要点(论文2.2第三段):这和以往减少特征有着很大的区别,以往采用的都是例如PCA这种,但是这种算法有一个大前提那就是
特征有冗余性比如:动物类别,是否是狗(是笔者自己举的例子),很明显两个特征其实有冗余性,但是这种情况并不是出现,当特征没有这种冗余性的时候,这种算法就逊色很多了,于是LightGBM在特征降维这个问题上,提出了EFB来解决这一棘手问题。
到此就面临到两个待解决的问题:(1)到底那些特征需要合并到一起(2)怎么合并到一起
其中(1)是采用图涂色算法,同时注意到有些特征并不是100%的互相排斥,但是呢?其也很少同时取非0值,如果我们允许一部分冲突,那么这部分特征就可以进一步进行合并,使得bundle进一步减少。
说了这么多可能大家还是一头雾水,相互排斥到底是个什么东西?下面就一种理想情况画一张图直观的看一下其原理:
假设现在有13个样本,每个样本有四个特征A,B,C,D,可以看到这很稀疏了吧(左图),那么怎么合并呢?很简单将ABCD捆绑为一个特征M就是右图
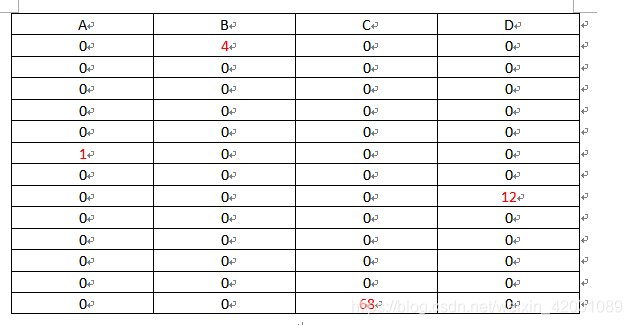

是不是感觉很眼熟,是的其逆过程即从右图到左图就是有种ont-hot的味道。
知道了何谓排斥那么第一个问题就解决了,再来看第二个问题,具体怎么合并,上面是一种比较极端的情况,一般的情况是这样:
假如A特征的范围是[0,10),B特征的范围是[0,20),那么就给B特征加一个偏值,比如10,那么B的范围就变为[10,30),所以捆绑为一个特征后范围就是[0,30]。算法对应右图
所以结合两个问题来看其完成的任务不但是简简单单的捆绑,而且要达到捆绑后还能从取值上区分出特征之间的关系。
上了上面的理论再看左边的算法就很简单了,大概就是先计算当前特征和当前bundle冲突,冲突小就将当前特征捆绑到当前bundle中,否则就再重新建一个bundle。需要注意的是该过程只需要在最开始做一次就好了,后面就都用捆绑好的bundle,其算法复杂度显而易见是#feature*#feature,但是当特征纬度过高,这显然也是不好的,于是乎对算法进行了改进,其不再建立图了,而是统计非零的个数,非零个数越多就说明冲突越大,互相排斥越小,越不能捆绑到一起。
有了上面理论,我们就看看你源码中的部分吧:
(1) GetConfilctCount:这里就是计算冲突树的地方
大体可以其就是在统计非零个数。
int GetConfilctCount(const std::vector<bool>& mark, const int* indices, int num_indices, int max_cnt) {
int ret = 0;
for (int i = 0; i < num_indices; ++i) {
if (mark[indices[i]]) {
++ret;
if (ret > max_cnt) {
return -1;
}
}
}
return ret;
}(2)FindGroups:解决上述问题一即哪些特征需要合并
这里就看一下最关键的部分大约在105行
for (auto gid : search_groups) {
const int rest_max_cnt = max_error_cnt - group_conflict_cnt[gid];
int cnt = GetConfilctCount(conflict_marks[gid], sample_indices[fidx], num_per_col[fidx], rest_max_cnt);
if (cnt >= 0 && cnt <= rest_max_cnt) {
data_size_t rest_non_zero_data = static_cast<data_size_t>(
static_cast<double>(cur_non_zero_cnt - cnt) * num_data / total_sample_cnt);
if (rest_non_zero_data < filter_cnt) { continue; }
need_new_group = false;
features_in_group[gid].push_back(fidx);
group_conflict_cnt[gid] += cnt;
group_non_zero_cnt[gid] += cur_non_zero_cnt - cnt;
MarkUsed(conflict_marks[gid], sample_indices[fidx], num_per_col[fidx]);
if (is_use_gpu) {
group_num_bin[gid] += bin_mappers[fidx]->num_bin() + (bin_mappers[fidx]->GetDefaultBin() == 0 ? -1 : 0);
}
break;
}
}
if (need_new_group) {
features_in_group.emplace_back();
features_in_group.back().push_back(fidx);
group_conflict_cnt.push_back(0);
conflict_marks.emplace_back(total_sample_cnt, false);
MarkUsed(conflict_marks.back(), sample_indices[fidx], num_per_col[fidx]);
group_non_zero_cnt.emplace_back(cur_non_zero_cnt);
if (is_use_gpu) {
group_num_bin.push_back(1 + bin_mappers[fidx]->num_bin() + (bin_mappers[fidx]->GetDefaultBin() == 0 ? -1 : 0));
}
}其首先通过 GetConfilctCount计算冲突数,如果符合要求就将其捆绑当前的bundle即源码中features_in_group,并且将need_new_group设置为false意思是不用新建bundle啦,否则就新建,并且将当前feature的id捆绑当其中即代码中的:
features_in_group.emplace_back();
features_in_group.back().push_back(fidx);最后改函数返回的就是features_in_group即分好的bundle。
return features_in_group;(3)FastFeatureBundling:进一步捆绑
捆绑过程还没有结束,该函数对捆绑做了进一步处理:
该函数遍历经过(2)的初步捆绑的bundle,保留了哪些只有一个特征和5个以上的bundle,对于其他的bundle做了如下处理:
对哪些稀疏度低的bundle,将其进行了拆分,又一次还原到了初始的正式特征,换句话说就是解散了稀疏度低,排斥性小,冲突大的bundle。
这里的稀疏度计算方法很简单就是:1-非零值数目/总数目
double sparse_rate = 1.0f - static_cast<double>(cnt_non_zero) / (num_data);然后和一个门限值 sparse_threshold比较,低就拆分:
if (sparse_rate >= sparse_threshold && is_enable_sparse) {
for (size_t j = 0; j < features_in_group[i].size(); ++j) {
const int fidx = features_in_group[i][j];
ret.emplace_back();
ret.back().push_back(fidx);
}
} else {
ret.push_back(features_in_group[i]);
}该函数结尾还将这些分好的bundle进行了打乱:
int num_group = static_cast<int>(ret.size());
Random tmp_rand(12);
for (int i = 0; i < num_group - 1; ++i) {
int j = tmp_rand.NextShort(i + 1, num_group);
std::swap(ret[i], ret[j]);
}最后结果就保存在了ret中,该函数最后就返回了ret
------------------------------------------------------------------------------------------------------------------------------------------------------------------
GOSS:
GOSS是论文提出两大技术的另一个,其算法如下:

对于稀疏数据集来说:
首先GBDT如果采用pre-sorted方式进行分裂可以通过忽略掉大部分值为0特征来减少复杂度(具体怎么做有兴趣的可以看一下原论文参考文献13),但是我们说了使用histogram-based的好处多多,但是GBDT如果使用了histogram-based形式,则没有了相关的稀疏优化方法,因为histogram-based需要遍历所有的数据的bin值,而不会管其值是不是0,同时呢?我们知道传统的Adaboost其实数据集都是有一个权值的,用来衡量其重要程度,没有被好好训练的样本其权值就大,以便下一个基学习器对其多加训练,于是就可以依据该权值对其采用,这样就做到采用利用部分数据集,但是呢?我们知道在GBDT中是没有权值这一说的,其每次利用的都是整个数据集,其这些数据集的权重是一样的,所以怎么办呢?
于是乎lightGBM提出了GOSS,其是这样想的:
抽样肯定还是要抽的,毕竟减少了样本减少了复杂度嘛!没有权值我们根据什么抽呢?其发现可以将一阶导数看做权重,一阶导数大的说明离最优解还远,这部分样本带来的增益大,或者说这部分样本还没有被好好训练,下一步我们应该重点训练他们。
对应的是右图的算法,a代表对大梯度样本的采样率,b代表对小梯度样本的采样率,首先对梯度排序得到sorted,前后取前topN作为大梯度样本集合topSet(topN的个数是通过a确定的),然后在剩下的里面随机抽取(RandomPick为随机抽取算法)randN个作为小梯度样本集合randSet,最后将两者合并作为采用后的样本usedSet,我们就拿这个样本取训练,同时呢为了尽可能不改变数据集的概率分布(因为这样抽的结果就是小梯度的样本被不断的减少再减少),所以还有给小样本一个补偿,那就是乘以一个常数即(1-a)/b,可以看到当a=0时就变成了随机采用啦,这样抽的结果还是能保持准确率的,这里有详细的数学证明,请看论文的3.2部分。
下面来看一下源码:
其.h文件位于LightGBM/src/boosting/goss.hpp
该类下主要有如下方法:
Init
ResetTrainingData
ResetGoss
Bagging
BaggingHelper
(1)Init、ResetTrainingData、ResetGoss
前三个方法都可以简单将其看为GOSS的一些初始化。都很简单,看一下源码就大概明白了,这里顺便简单说一下ResetGoss中的几个注意点:
首先看如下代码:
CHECK(config_->top_rate + config_->other_rate <= 1.0f);
CHECK(config_->top_rate > 0.0f && config_->other_rate > 0.0f);
if (config_->bagging_freq > 0 && config_->bagging_fraction != 1.0f) {
Log::Fatal("Cannot use bagging in GOSS");
}
Log::Info("Using GOSS");这里的的top_rate和other_rate就是我们上面理论部分说的a,b,正如代码看到的两则都必须大于0且和小于1,否则就不能用GOSS,同时还会发现,当bagging_freq大于0且bagging_fraction不等于1时也是不能用GOSS的,对应到官方API如下
top_rate :default = 0.2, type = double, constraints: 0.0 <= top_rate <= 1.0
- used only in
goss - the retain ratio of large gradient data
other_rate :default = 0.1, type = double, constraints: 0.0 <= other_rate <= 1.0
- used only in
goss - the retain ratio of small gradient data
bagging_fraction :default = 1.0, type = double, aliases: sub_row, subsample, bagging, constraints: 0.0 < bagging_fraction <= 1.0
- like
feature_fraction, but this will randomly select part of data without resampling - can be used to speed up training
- can be used to deal with over-fitting
- Note: to enable bagging,
bagging_freqshould be set to a non zero value as well
bagging_freq :default = 0, type = int, aliases: subsample_freq
- frequency for bagging
0means disable bagging;kmeans perform bagging at everykiteration- Note: to enable bagging,
bagging_fractionshould be set to value smaller than1.0as well
其次:
if (config_->top_rate + config_->other_rate <= 0.5) {
auto bag_data_cnt = static_cast<data_size_t>((config_->top_rate + config_->other_rate) * num_data_);
bag_data_cnt = std::max(1, bag_data_cnt);
tmp_subset_.reset(new Dataset(bag_data_cnt));
tmp_subset_->CopyFeatureMapperFrom(train_data_);
is_use_subset_ = true;
}
// flag to not bagging first
bag_data_cnt_ = num_data_;可以看到当a+b小于等于0.5,就可以用GOSS,其中bag_data_cnt就是抽样后的样本数,num_data_是总样本数,当大于0.5时,就暂时先不进行GOSS了。
(2)Bagging
这部分就是表象,主要就是处理了一些线程的东西,而真正的GOSS算法是在(3)BaggingHelper,所以下面会重点说一下(3)的函数。本函数也注意几点:
Random cur_rand(config_->bagging_seed + iter * num_threads_ + i);
data_size_t cur_left_count = BaggingHelper(cur_rand, cur_start, cur_cnt,
tmp_indices_.data() + cur_start, tmp_indice_right_.data() + cur_start);这里的cur_rand就是上面所说的随机抽取小梯度时用的seed数,可以看到其是下面(3)函数的一个参数,其对应的官方API:
bagging_seed :default = 3, type = int, aliases: bagging_fraction_seed
- random seed for bagging
tree_learner_->ResetTrainingData(tmp_subset_.get());最后看到将抽样后的数据设置为了训练树的训练数据集,那么我们具体看一下tmp_subset_是怎么来的:
tmp_subset_->ReSize(bag_data_cnt_);
tmp_subset_->CopySubset(train_data_, bag_data_indices_.data(), bag_data_cnt_, false);这里是先设置了bag_data_cnt(上面我们已经说过了)大小的空间,然后将bag_data_indices_ 复制了过来,那么再看一下bag_data_indices_
std::memcpy(bag_data_indices_.data() + left_write_pos_buf_[i],
tmp_indices_.data() + offsets_buf_[i], left_cnts_buf_[i] * sizeof(data_size_t));它又是通过tmp_indices_复制来的,再看一下tmp_indices_:
data_size_t cur_left_count = BaggingHelper(cur_rand, cur_start, cur_cnt,
tmp_indices_.data() + cur_start, tmp_indice_right_.data() + cur_start);会发现最终还是定位到了(3)函数,所以我们就来看看(3)函数吧!!!!!!!!!!
(3)BaggingHelper
data_size_t top_k = static_cast<data_size_t>(cnt * config_->top_rate);
data_size_t other_k = static_cast<data_size_t>(cnt * config_->other_rate);top_k和 other_k 就是我们要抽取的大梯度数据集和小梯度数据集的样本数
ArrayArgs<score_t>::ArgMaxAtK(&tmp_gradients, 0, static_cast<int>(tmp_gradients.size()), top_k - 1);
score_t threshold = tmp_gradients[top_k - 1];这里的threshold就是门限,梯度大于该门限的我们都抽取,因为这里先对tmp_gradients进行了排序,然后选取了索引为top_k - 1作为门限值,可想而知,大于该门限值的一共就是top_k,那么是根据什么对tmp_gradients排序的呢?
mp_gradients[i] += std::fabs(gradients_[idx] * hessians_[idx]);会发现其和理论部分还有有点不一样,理论部分只是高度概括使用导数(一阶导数),实际上这里是是使用了一阶导数和二阶导数的成绩进行排序的。
score_t multiply = static_cast<score_t>(cnt - top_k) / other_k;multiply就是理论部分所说的对小梯度集合的补偿常数(1-a)/b,注意这里直接使用了样本数,结果是一样的:
样本总数*(1-a)/b=(样本总数-大梯度样本数)/小梯度样本数=(cnt - top_k) / other_k
下面部分算是最核心的部分了吧。
首先结果是保存在了buffer中的,也就是对应(2)函数的tmp_indices_
if (grad >= threshold) {
buffer[cur_left_cnt++] = start + i;
++big_weight_cnt;
} 可以看到对大于threshold的样本那就是大梯度样本直接保存到buffer中,如果是小梯度,除了保存之外,还需要补偿工作:
double prob = (rest_need) / static_cast<double>(rest_all);
if (cur_rand.NextFloat() < prob) {可以看到这里的prob=还需要抽取小梯度数/总共需要抽取小梯度数,如果小于其值进行补偿:
gradients_[idx] *= multiply;
hessians_[idx] *= multiply;当然了别忘了还要将该样本保存到buffer中作为小梯度中抽取的样本:
buffer[cur_left_cnt++] = start + i;如果大于该值,就直接进行:
buffer[cur_left_cnt++] = start + i;无需补偿。
-------------------------------------------------------------------------------------------------------------------------------------------------------------------
Leaf-wise
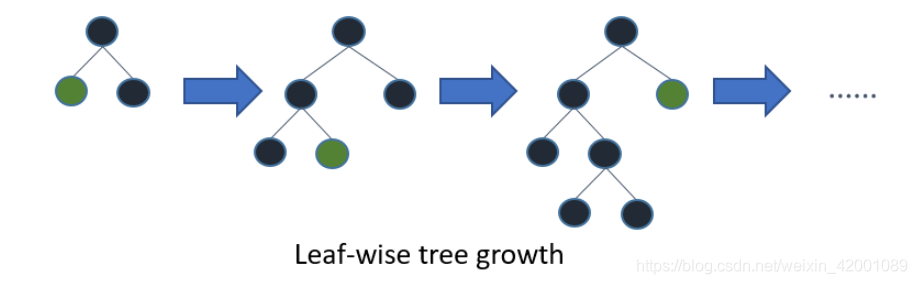
Level-wise是将同一层所有的叶子节点进行分裂,这也是以前GBDT各种演变算法所采用的策略,而LightGBM采用的Leaf-wise是每次选取最大增益的那个叶子节点进行分类,可以看到生长相同的leaf时,leaf-wise 算法可以比 level-wise 算法减少更多的损失即得到更大的增益,但是其缺点就是可能会长出比较深的决策树,产生过拟合。因此LightGBM在Leaf-wise之上增加了一个最大深度限制,在保证高效率的同时防止过拟合。
下面来看一下源码:
(1)首先看SerialTreeLearner::BeforeFindBestSplit这个方法:
该方法就是在寻找最佳划分点之前需要做哪些工作,最终返回的是一个bool类型,false代表不要再往下分裂了,true代表接着分。
其中一点就包括我们上面所说的检查当前树的深度,如果已经超过了配置选项就不在分裂了:
if (tree->leaf_depth(left_leaf) >= config_->max_depth) {
best_split_per_leaf_[left_leaf].gain = kMinScore;
if (right_leaf >= 0) {
best_split_per_leaf_[right_leaf].gain = kMinScore;
}
return false;需注意这里仅仅检查了左树的深度就够了,因为leaf-wise这种方法从上面图中也可以看出,左右深度是一样的,检查一边就好了。这里的max_depath对应的官方API:
max_depth :default = -1, type = int
- limit the max depth for tree model. This is used to deal with over-fitting when
#datais small. Tree still grows leaf-wise < 0means no limit
当然了,该方法中还有其他检查选项类如,当数据不够多时也是不会往下分裂的:
if (num_data_in_right_child < static_cast<data_size_t>(config_->min_data_in_leaf * 2)
&& num_data_in_left_child < static_cast<data_size_t>(config_->min_data_in_leaf * 2)) {
best_split_per_leaf_[left_leaf].gain = kMinScore;
if (right_leaf >= 0) {
best_split_per_leaf_[right_leaf].gain = kMinScore;
}
return false;
}这里的num_data_in_right_child和num_data_in_left_child分别代表左右子树的数据量,可以看到多两边的数据量同时小于门限值的2倍时就不分裂了,其中门限值min_data_in_leaf是配置选项,对应官网API:
min_data_in_leaf :default = 20, type = int, aliases: min_data_per_leaf, min_data, min_child_samples, constraints: min_data_in_leaf >= 0
- minimal number of data in one leaf. Can be used to deal with over-fitting
其他这里不讲了,因为我们重点要看Leaf-wise相关内容,总之该方法的作用可以简单看做是为了防止过拟合采取的一系列手段。
(2)SerialTreeLearner::Train
for (int split = init_splits; split < config_->num_leaves - 1; ++split) {可以看到其先遍历当前层的所有的叶子结点(上述理论部分是2个,实际上不仅仅是2个),其中num_leaves是叶子总数,配置选项,官网API:
num_leaves :default = 31, type = int, aliases: num_leaf, max_leaves, max_leaf, constraints: num_leaves > 1
- max number of leaves in one tree
int best_leaf = static_cast<int>(ArrayArgs<SplitInfo>::ArgMax(best_split_per_leaf_));Split(tree.get(), best_leaf, &left_leaf, &right_leaf);得到best_leaf,然后进行划分Split。
其他部分都是树的训练了,和以前GBDT本质上没有什么不同,例如这里的Spilt具体的划分函数等等,这小节我们只看和Leaf-wise技术有关的代码,其他部分感兴趣可以深入研究。
------------------------------------------------------------------------------------------------------------------------------------------------------------------
其他部分:
比较重点的还有GBDT部分,即集成学习boosting部分,这里和以前的提升算法没有什么大的不同,即LightGBM重点提到的技术就是我们上面所说的,如果对其感兴趣可以进一步研究,这部分代码位置位于LightGBM/src/boosting/
---------------------------------------------------------------------------------------------------------------------------------------------------------------------
结束:
每天进步一点点!!!!!
看到很多小伙伴私信和关注,为了不迷路,欢迎大家关注笔者的微信公众号,会定期发一些关于NLP的干活总结和实践心得,当然别的方向也会发,一起学习:
