前提必备知识:学会使用pandas 和numpy 产生时间序列数据--在pandas数据分析中有讲解
1,数据重采样:
1.1 降采样:
假设我收集了一年的数据,时间数据的频率是1天,一共365天的数据,那么我想按照月这个频率记,那么时间频率就变成了12个月了,频率变低了,叫做降采样。
1.2 升采样:
与降采样相反,时间频率变高了。
1.2 代码演示:
降采样
import pandas as pd
import numpy as np
# 创建一个时间序列:以天为周期90天的数据
rng = pd.date_range('1/1/2011', periods=90, freq='D')
ts = pd.Series(np.random.randn(len(rng)), index=rng)
# 降低频率
ts.resample('M').sum() # 将其以按照月为单位,
ts.resample('3D').sum()# 每隔3天合并
day3Ts = ts.resample('3D').mean() #可以以均值合并,也可以自己写一个apply函数自己定义算法
# 升采样
print(day3Ts.resample('D').asfreq()) # 原来3天一个间隔,现在将其分隔开,但是有问题,有缺失值。解决方法看下一段代码升采样插值方法:
'''
2011-01-01 -1.007135
2011-01-02 NaN
2011-01-03 NaN
2011-01-04 0.776943
2011-01-05 NaN
2011-01-06 NaN
...
'''升采样插值方法:
- ffill 空值取前面的值
- bfill 空值取后面的值
- interpolate 线性取值
day3Ts.resample('D').ffill(1) #缺失值的地方 取前一个不是缺失值的数据。ffill里面的1 效果如下
'''
2011-01-01 0.015214
2011-01-02 NaN
2011-01-03 -0.751735
2011-01-04 -0.751735
2011-01-05 NaN
2011-01-06 0.190381
ffill(2):
2011-01-01 0.015214
2011-01-02 -0.240435
2011-01-03 -0.496085
2011-01-04 -0.751735
2011-01-05 -0.437697
2011-01-06 -0.123658
'''
day3Ts.resample('D').bfill(1)
day3Ts.resample('D').interpolate('linear') # 这个是线性的感觉比较好,就是中间找出来两个点,使间距相等。滑动窗口
这个比较容易理解
%matplotlib inline
import matplotlib.pylab
import numpy as np
import pandas as pd
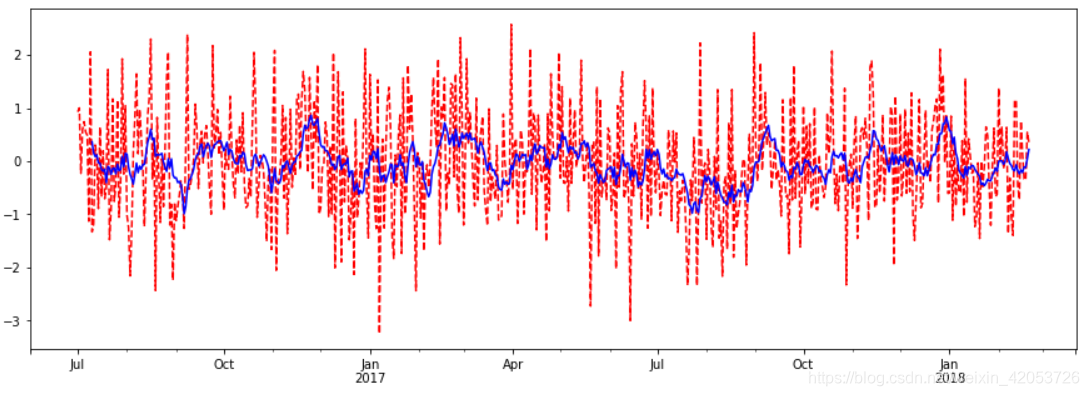
df = pd.Series(np.random.randn(600), index = pd.date_range('7/1/2016', freq = 'D', periods = 600))
''' 定义滑动窗口'''
r = df.rolling(window = 10) # 窗口长度为10,可以计算这十个数的信息,比如最大值,均值等等
#r.max, r.median, r.std, r.skew, r.sum, r.var
print(r.mean()) #计算均值
'''
df.rolling(window=10).mean() 效果如下
2016-07-01 NaN
2016-07-02 NaN
2016-07-03 NaN
2016-07-04 NaN
2016-07-05 NaN
2016-07-06 NaN
2016-07-07 NaN
2016-07-08 NaN
2016-07-09 NaN
2016-07-10 0.365879
2016-07-11 0.154923
2016-07-12 0.085345
2016-07-13 0.117916
...
'''
# 画图,pandas的画图也不错啊!
import matplotlib.pyplot as plt
%matplotlib inline
plt.figure(figsize=(15, 5))
df.plot(style='r--')
df.rolling(window=10).mean().plot(style='b')