前言
这节来介绍一下开集识别的定义以及其与闭集识别的区别。希望大家学有所获~
一、开集识别是什么?
开集识别,英文Open Set Recognition,简写为OSR。
背景:在封闭世界中训练的机器学习模型通常将属于未知类别的测试样本错误地分类为具有高置信度的已知类别。一些文献将模型这种过度自信的行为称为“模型的傲慢”。因此,OSR 于 2013 年被提出,旨在解决这个问题。
定义:“开集识别”要求多分类器同时达到如下两个要求:
- 对测试集中属于 “已知类别“的图片进行准确分类;“已知类别” 代表训练集中存在的类别。
- 检测出”未知”类别, “未知类别”不属于训练集中任何类别。
总结来看就是,将属于已知类的数据识别为具体的类别,将不属于已知类的数据识别为未知的类别,即异常类。
二、闭集识别 VS 开集识别
在论文《Open Set Classification for Signal Diagnosis of Machinery Sensor in Industrial Environment》中给出了开集识别与闭集识别的区别:
其中左边是闭集识别,右边是开集识别。
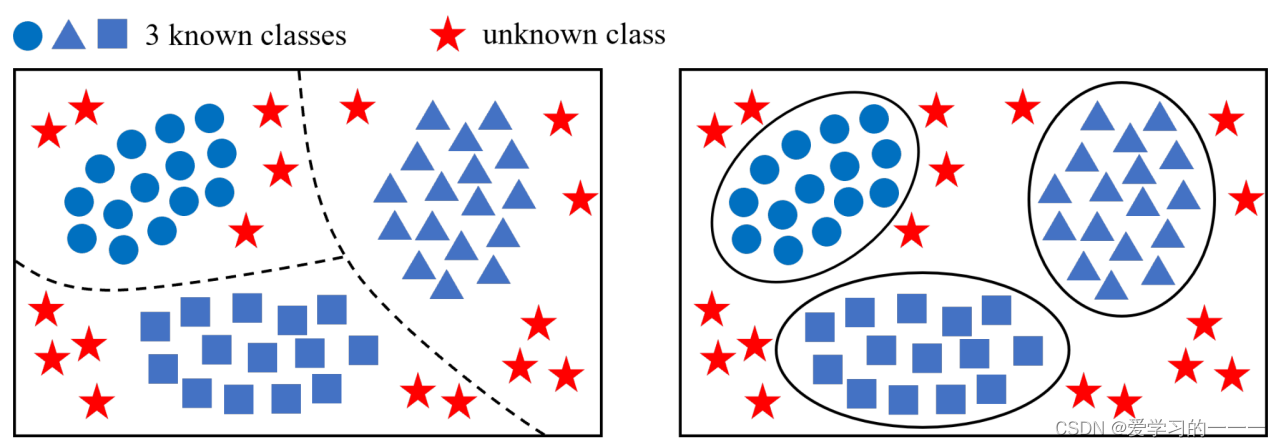
在闭集假设下,该算法根据训练集中已有的样本,为每个类划分相应的空间。如图3(a)所示,虚线表示每个类的无界决策边界。在测试阶段,样本将被分配到其中一个空间,但来自未知类别的数据可能被错误地分类到一个已知类别(如图中的红星符号所示)。
在开放集场景中,基于训练集中某些类是未知的假设,算法为每个类确定一个与之相关联的有限区域。如图所示,用实线表示的决策边界是有界的。如果一个样本位于已知类的一个区域内,那么它将被标识为该类。另一方面,如果它位于一个与任何已知类没有关联的空间中,那么它将被拒绝作为一个未知类。在这种情况下,算法可以看作是n+1分类器,其中n表示训练阶段已知类的数量,1表示未知类。
总结来看,闭集识别是根据已知分类进行判断,不会产生别的结果,而开集识别可以产生新的一类,并检测出异常。
总结
以上就是要介绍的开集识别的定义,希望大家有所收获~
参考网站如下:
离群?异常?新类?开集?分布外检测?一文搞懂其间异同!