目录
0.前言
0.1 为什么要写这个教程
其实最重要的目的是为了总结自己学习和整理的资料,同时锻炼下自己的写作水平。毕业已经十多年了,平常也一直爱学习一些自己感兴趣的东西。自己对软件硬件都非常感兴趣,有些知识学过之后,一段时间就忘了,需要用的时候再看一遍,以前我经常自己用笔记本记下来,但发现有很多的弊端:(1)一些涉及代码的手写笔记并不是很友好,(2)手写记录的东西不直观且没有一个总的概览,(3)由于搬家以及时间太久等原因,一些笔记本都丢了,自己当时总结的一些知识点也没了。
CSDN上看文章博客也好多年了,感觉在这里写文档还是蛮好的,可以把自己学到的东西记录下来,方便自己日后需要的时候再翻看。因为这个资料一个主要目的是自己看的,所以写的东西肯定都是自己认真看过的,肯定有理解不深的地方,所以我会一直不断更新改正,也会根据自己理解的深入一步步完善。俗话说“好记性不如烂笔头”,把自己从其他地方学到的东西,再一个字一个字的敲出来,图再重新画一遍,代码再敲一次,对个人提升还是非常有帮助的。
当前行业太卷了,平常工作很忙,下班也很晚了,更新会非常不及时,只能抽空更新整理。
0.2 学习STM32需要具备的知识
(1)C语言:这个是最重要的,如果C语言不会,那建议先学习下C语言再来。我大学学习单片机的时候,编程都是用的汇编语言写的,但现在已经不推荐了,当前主流还是基于C语言来开发。以前大学的时候学完C语言感觉这玩意没啥用,还不如VB能编写一些桌面应用,看得见摸得着的。毕业后进了汽车行业,才知道C语言是多么重要,可以说整个嵌入式领域,C语言就是当之无愧的NO.1,没有之一。STM32的开发都是基于C语言,需要我们有较为扎实的C语言功底。
(2)数电、模电、电路原理: 能懂一些肯定是很有帮助的,以我自己的经历来说,也可以在学习的过程中再对涉及到的知识点进行了解学习。因为大学的时候我学过数电、模电电路原理等课程,还是有一定基础的,但学习过程中很多知识点也忘了,也是又重新补习了一些。
(3)是否要先学习51单片机:个人感觉非常有必要。我们的主要目的还是学习,往往越简单的一些设备的使用越接近最底层的知识。就像我们现在汽车软件的开发,由于工具链过于完备,你可以一年不用敲一个代码就把软件做出来。画画图,开发软件里咣咣一通配置也不需要你写什么代码,软件就做出来了。这样开发效率虽然高,但对个人掌握知识来说并不算一个好事,很多人的认知也就停留在表面,一些东西就不懂所以然。
我们51单片机的开发主要还是通过配置寄存器的方式,STM32再通过这种模式就有点太过复杂了,但本质的原理是一样的。STM32的开发就直接从库函数开始。
(4)学习资料推荐: 野火,正点原子,哔站江协科技的STM32教程都可以。
(5) 学习建议:多练习多动手。
第1章.STM32单片机入门知识介绍
1.1 嵌入式系统简介
1.1.1 什么是嵌入式系统
嵌入式系统的标准定义如下:
嵌入式系统是以应用为中心、以计算机技术为基础、软硬件可裁剪、对功能、可靠性、成本、体积和功耗有严格要求的专用计算机系统。
如上定义,嵌入型系统属于专用的计算机系统,其对应的就是通用计算机系统,也就是我们的个人电脑等,也就是我们的电脑等通用计算机系统具有“通用而复杂”的功能,而嵌入式系统只为实现一些特定的专用功能。
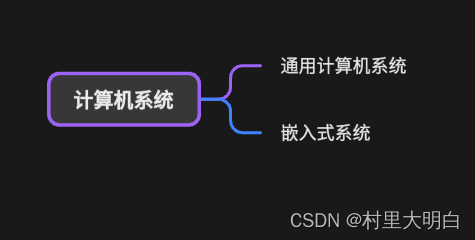
图1.1-1计算机系统组成
嵌入式系统和通用计算机系统都属于计算机系统。如图1.1-1。从系统组成上它们都是软件和硬件组成,工作原理也相同。从硬件上看,两者都是由CPU、存储器、I/O接口和中断系统等部件组成;从软件上看,两者都可以换分为系统软件和应用软件。
嵌入式系统和通用计算机系统也是有很多不同点,如下图1.1-2所示。
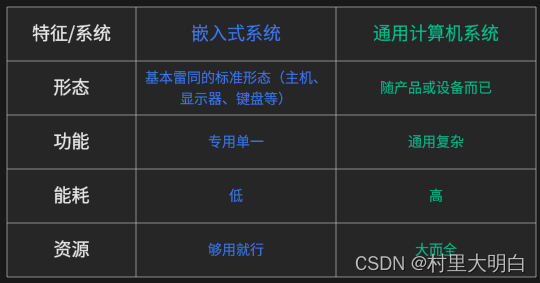
图1.1-2嵌入式系统与通用计算系统的不同点
1.1.2 嵌入式系统的特点
和通用计算机系统比较,嵌入式系统有一下特点:
(1)专用性强:嵌入式系统按照具体应用需求进行设计,完成指定的任务,通常没有通用性,只能完成特定的应用。比如冰箱的控制系统只能完成冰箱的控制,而不能在空调的控制中使用。
(2)可裁剪性:基于体积、成本等因素,嵌入式系统的软硬件可根据需求进行裁剪,在满足要求的前提下做到最精简的配置。
(3)实时性好:大多数实时性系统都是嵌入式系统,嵌入式系统也基本都具有实时性的要求和性能。
(4)可靠性高:很多嵌入式系统必须全天候持续工作,甚至在极端环境下正常运行,大多数嵌入式系统都具有可靠性机制。
(5) 生命周期长:通用计算机的更新迭代较快,嵌入式系统的生命周期与其嵌入的产品同步,生命周期较长。
1.1.3 嵌入式系统的应用领域
如图1.1-3所示,嵌入式系统的应用非常广泛,在工业控制,交通管理,信息家电,环境工程等广泛应用。
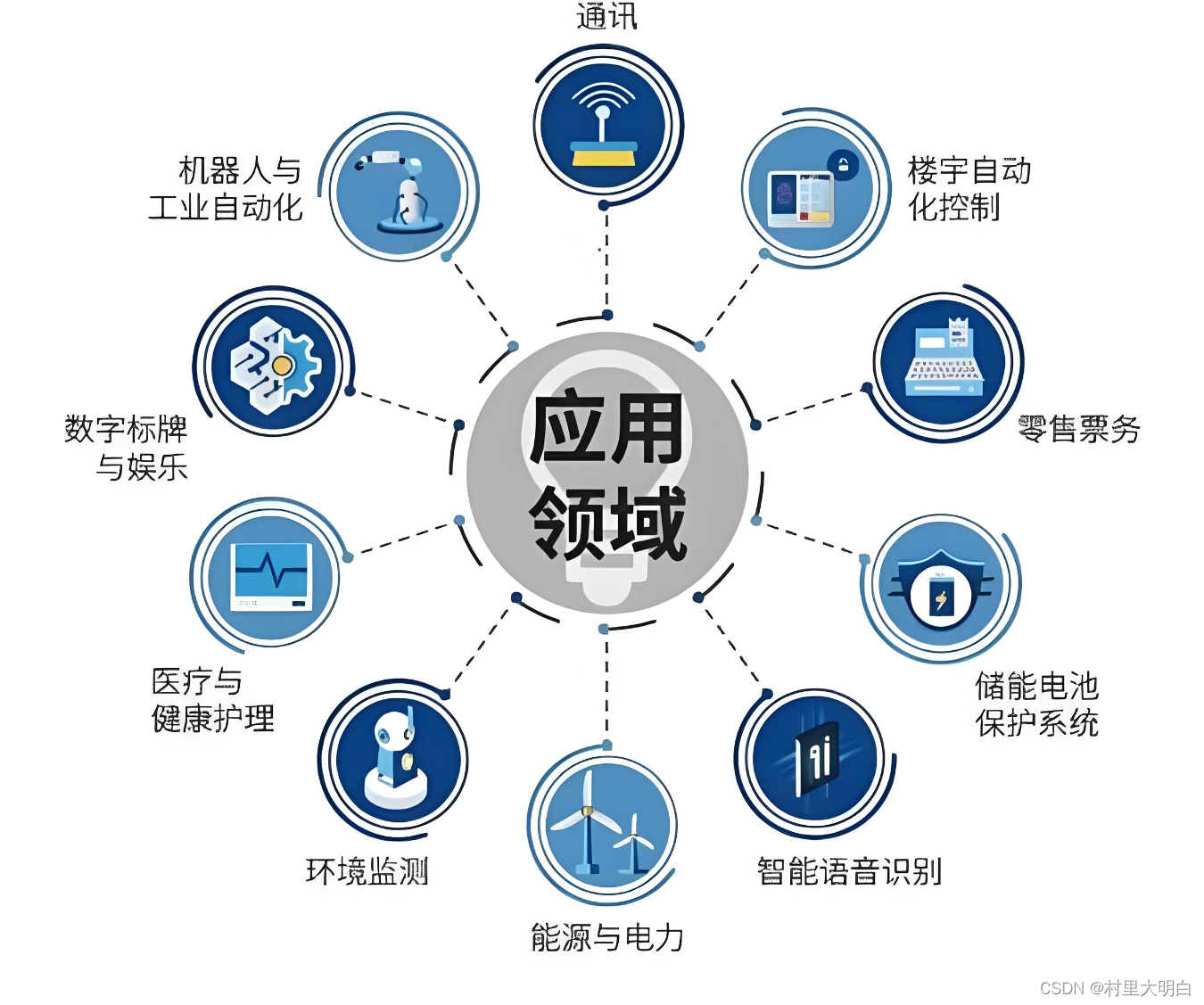
图1.1-3 嵌入式系统的应用领域
1.2 单片机基本概念
单片机,全称单片微型计算机(Single-Chip Microcomputer),是指集成在一个芯片上的微型计算机。这种计算机系统的体积较小,内部包含中央处理器CPU、随机存储器RAM、只读存储器ROM、定时/计数器和多种I/O接口电路,并在一块集成电路芯片上集成了微型计算机的各种功能部件,具有高性能、低价格的优点。国内经常使用“单片机”这个称呼,国外通常称为“微控制器”,英文缩写MCU(Microcontroller Unit)。
单片机是嵌入式系统中的一个重要子类,单片机在嵌入式系统中扮演了关键的角色,是实现嵌入式系统功能的重要组件之一。
1.3 ARM简介
1.3.1 ARM公司简介
ARM,全称为Advanced RISC Machines,既指ARM公司,也指ARM处理器内核。ARM公司是全球领先的半导体知识产权(IP)提供商,是一家在微处理器设计领域具有重要影响力和广泛应用的公司,ARM的总部位于英国的剑桥。
ARM设计了大量高性能、廉价、低功耗的RISC(Reduced Instruction Set Computer,精简指令集计算机)处理器及芯片。ARM作为知识产权供应商,本身不直接从事芯片的生产,其将知识产权授权给世界各大半导体厂商后,各大生产商再根据不同的应用领域,加入适当的外围电路,形成自己的ARM微处理器芯片。ARM架构其高效、节能的特性,使得它非常适合在移动设备和嵌入式系统中使用,它的技术广泛应用于各种嵌入式系统设计,从无线通讯、网络和消费娱乐产品到成像、汽车、安全和存储解决方案等领域。ARM架构已经成为当今使用最广泛的32位嵌入式RISC指令集架构,ARM公司已经成为全球RISC标准的缔造者。目前全球超过95%的智能手机和平板电脑都采用了ARM架构。
1.3.2 ARM处理器简介
ARM公司开发了很多系列的处理器内核,以前都是以ARMx(x是数字)进行命名,比如经典的ARM7,ARM9,ARM11等。在早期,还在数字后面加字母后缀,用来进一步明确该处理器支持的特性。比如,ARM7TDMI,T代表Thumb指令集,D代表支持JTAG调试(Debugging),M代表快速乘法器,I代表一个嵌入式ICE模块。
到了ARMv7架构时代,ARM改革了一度使用的冗长命名方法,转为另一种看起来比较整齐的命名法:按照应用等级分成3个类别,并以Cortex作为前缀,而且每一个大的系列又换分若干小的系列。ARM体系结构与ARM内核的对应关系如图1.3-1。
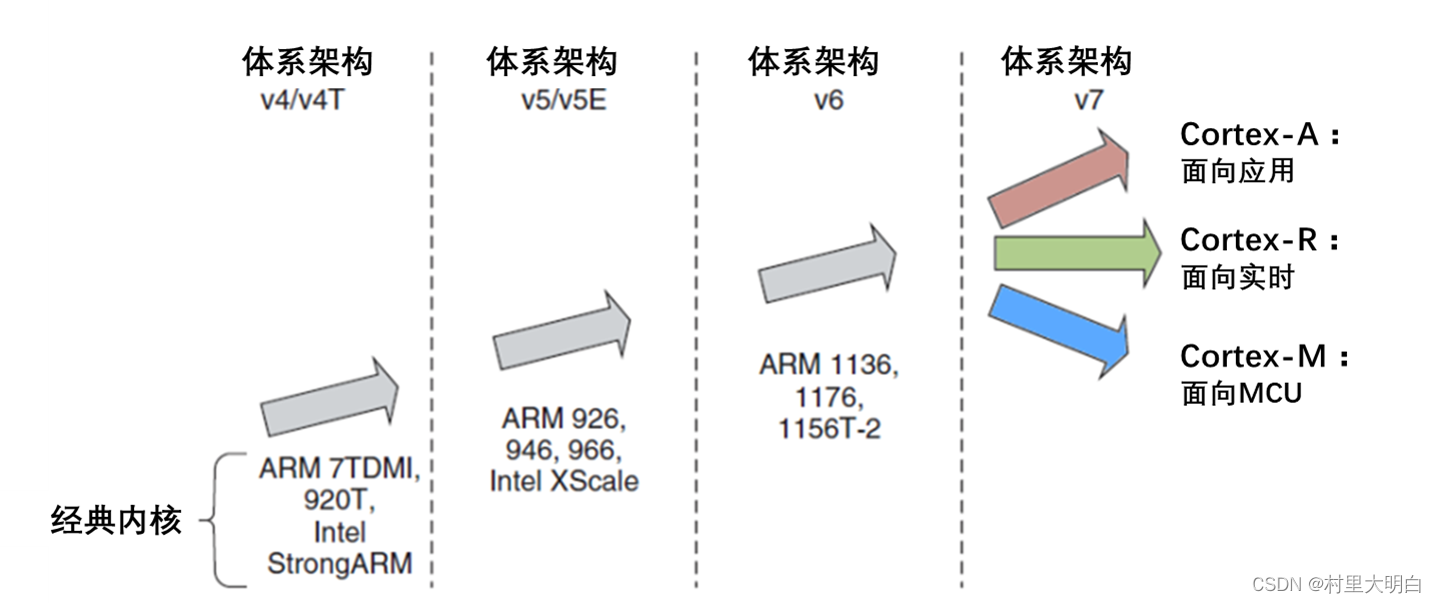
图1.3-1 ARM处理器架构进化史
ARM的Cortex系列处理器分为三种:Cortex-A、Cortex-R和Cortex-M,每种系列都有其特定的使用场景。
Cortex-A系列处理器:主要用于高性能计算设备,如智能手机、平板电脑、个人电脑和服务器等。它们通常具有较高的时钟频率和更大的存储容量,面向尖端的基于虚拟内存的操作系统和用户应用,因此也被称为应用程序处理器。
Cortex-R系列处理器:专为实时应用程序设计,如实时嵌入式系统中的自动驾驶、工控系统和医疗设备等。这些处理器针对实时系统,面向深层的嵌入式实时应用,能够处理需要快速响应和高可靠性的任务。
Cortex-M系列处理器:专为嵌入式系统设计,用于低功耗、实时控制和物联网设备。它们被广泛应用于各种应用,包括智能家居、汽车电子、医疗设备、工业自动化等领域。Cortex-M系列处理器具有低功耗、高性能、实时性、易于开发等特点,能够满足微控制器领域对于快速且具有高确定性的中断管理,以及低功耗和低成本的需求。
目前市场上比较流行的几大系列微处理,按性能、功能和处理能力划分如图1.3-2.
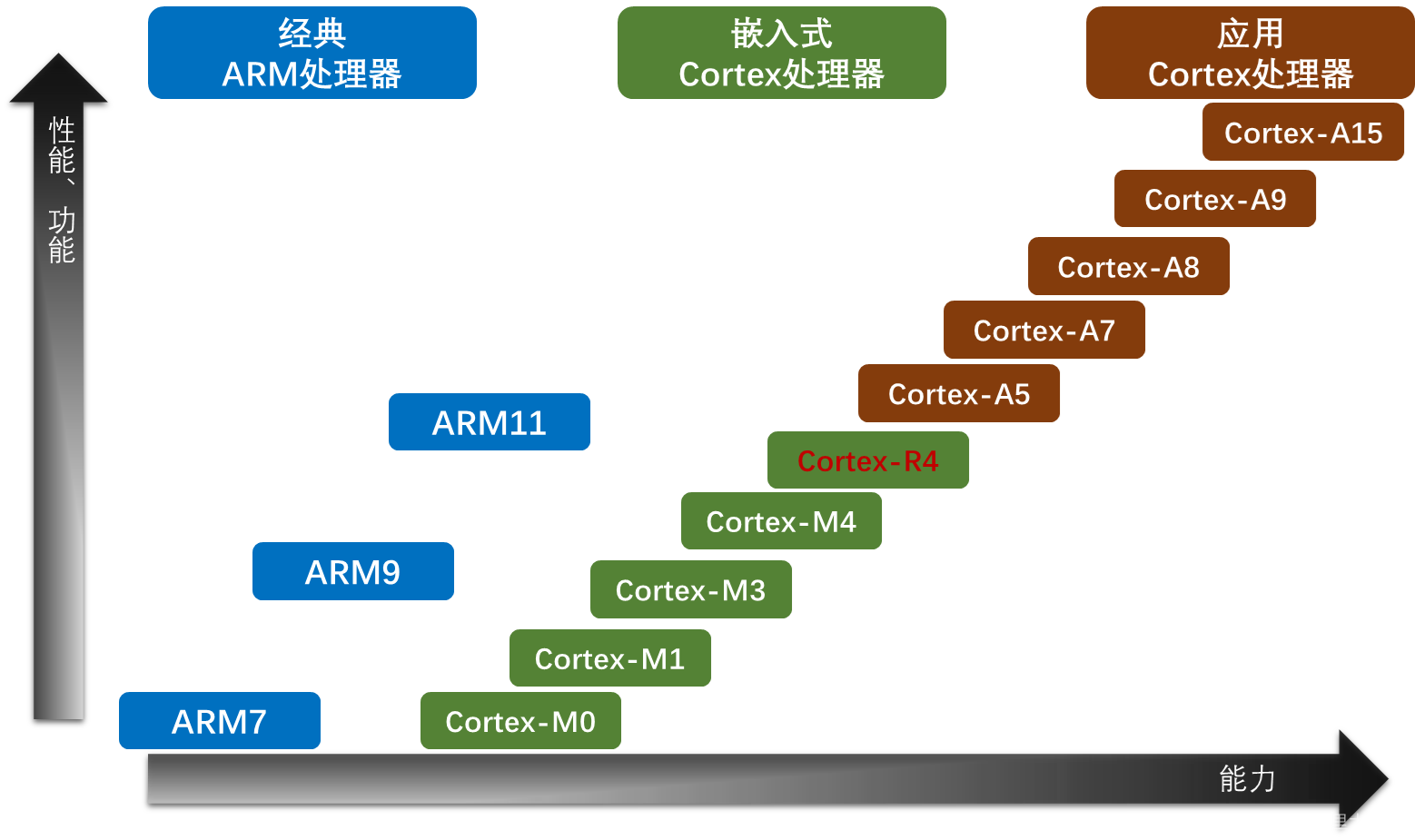
图1.3-2 ARM处理器性能示意图
我们教程主要讲述的是目前被控制领域广泛使用的基于Cortex-M3内核的STM32F103微控制器。
1.4 STM32简介
1.4.1 基于Cortex内核的MCU
前面介绍了ARM公司推出的Cortex处理器,但却无法从ARM公司直接购买到这样一款ARM处理器芯片。按照ARM公司的经营策略,它只负责设计处理器IP核,而不生产和销售具体的处理器芯片。
ARM-Cortex处理器内核是微控制器的中央处理单元(CPU)。完整的基于Cortex的MCU(MicroController Unit)还需要很多其他组件。在芯片制造商得到Cortex处理器内核的使用授权后,它们就可以把Cortex内核用在自己的硅片设计中,添加存储器、外设、I/O及其他功能块,即为基于Cortex的微控制器。不同厂家设计出的MCU会有不同的配置,包括存储器容量、类型、外设等都各具特色。以STM32的Cortex-M3内核为例,Cortex-M3内核和基于Cortex-M3的MCU关系如图1.4-1所示。
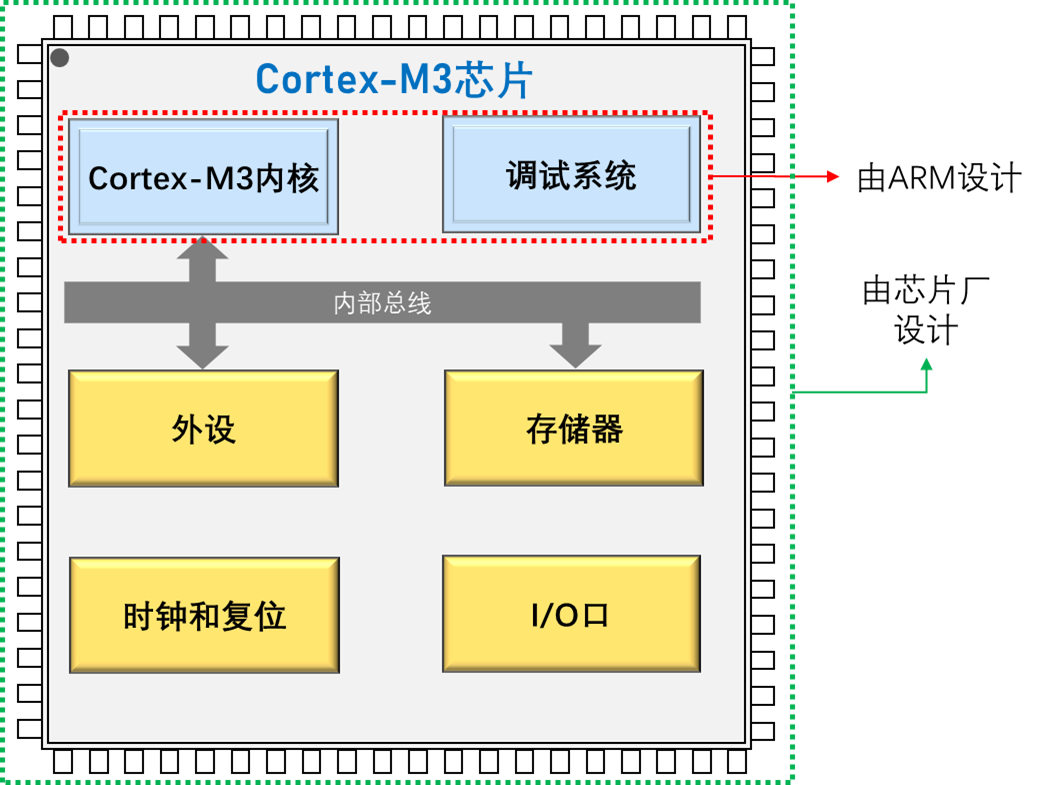
图1.4-1 Cortex-M3内核与基于Cortex-M3内核MCU关系图
1.4.2 什么是STM32
STM32是意法半导体(STMicroelectronics)公司推出的32位ARM Cortex-M内核微控制器系列。从字面上来理解,ST代表意法半导体,M是Microelectronics的缩写,而32则表示32位。这一系列微控制器具有高性能、低功耗、可靠性强等特点,广泛应用于工业控制、智能家居、汽车电子、医疗设备等领域。
STM32系列微控制器采用了多种ARM Cortex-M内核,如Cortex-M0、Cortex-M3、Cortex-M4等,具有不同的性能和功能特点,可根据应用场景的需求进行选择。STM32系列单片机采用了先进的低功耗技术,可以在不降低性能的情况下降低功耗,适合需要长时间运行或在电池供电的设备中使用。STM32作为一款功能强大的微控制器,以其高性能、低功耗和广泛的应用领域,赢得了工程师和市场的青睐。

.图1.4-2意法半导体公司Logo
1.4.3 STM32产品线简介
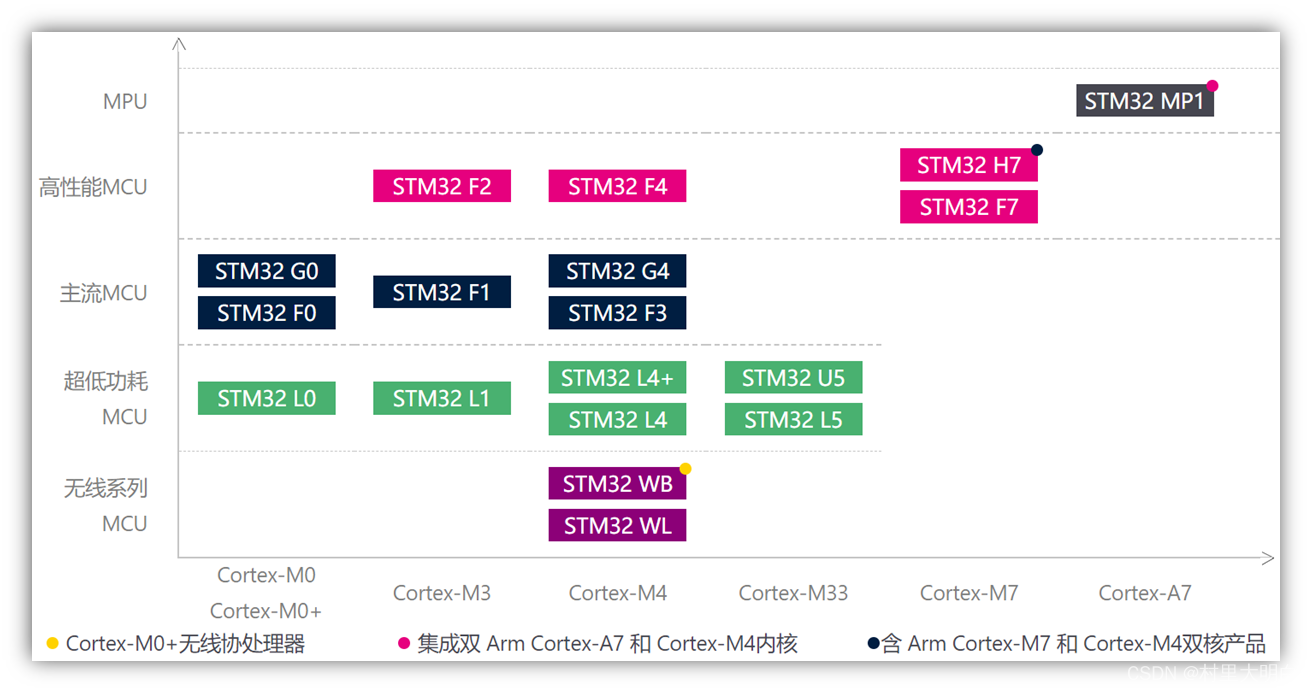
图1.4-3 STM32产品线
STM32 从 2007 年推出至今,已经有 18 个系列,超过 1000 个型号。STM32系列微控制器适合多种应用场景,其强大的功能和性能使得它能够胜任许多复杂的任务,以下是一些STM32的典型应用场景:
- 工业自动化:STM32在工业自动化领域发挥着重要作用,包括工厂自动化、机器人控制、传感器接口和数据采集等方面。它可以与各种传感器和执行器集成,实现远程控制和自动化功能,从而帮助实现高效的工业自动化系统。
- 消费电子:STM32广泛应用于智能手机、平板电脑、家庭娱乐系统、数字相机和音频设备等消费电子产品中。它提供了强大的处理能力和丰富的功能集成,为这些产品提供了卓越的性能和用户体验。
- 汽车电子:在汽车电子领域,STM32的应用也非常广泛。它可以用于发动机控制、车身电子系统、车载娱乐系统和驾驶员辅助系统等。其高性能和可靠性确保了车辆的安全性和功能的高度集成。
- 物联网:STM32非常适用于开发物联网设备,如智能传感器、网关、路由器等。它可以实现设备之间的互联互通,为物联网应用提供可靠的数据传输和控制功能。
- 智能家居:STM32可以与各种智能家居设备相连,实现智能化控制。例如,它可以控制智能插座、智能灯泡、智能门锁等设备,提供便捷和舒适的家居环境。
- 医疗设备:STM32在医疗设备中也扮演着重要角色,如心电图仪、血压计、血糖仪和医疗图像处理等。其高性能和可靠性确保了医疗设备的准确性和安全性。
此外,STM32还可以用于无人机和机器人的控制系统开发,提供高性能的实时控制和传感器处理能力。同时,它也可以用于开发各种嵌入式设备,如测试仪器、智能卡等。
而下面的场景是绝大多数STM32控制器(不是全部)不太适合处理的,或者下面这些场景下并不推荐使用STM32,列举如下:
- 程序代码较大的应用:STM32微控制器的存储空间相对有限,其FLASH大小通常在几百KB到几MB之间。对于程序代码超过1MB的大型应用,STM32可能无法满足存储需求。在这种情况下,可能需要考虑使用具有更大存储空间的处理器或微控制器。
- 基于Linux或Android的应用:STM32微控制器更适合运行轻量级的操作系统或实时操作系统(RTOS),而不是像Linux或Android这样的复杂操作系统。这些操作系统通常需要更高的处理器性能、更大的内存和存储空间,以及更丰富的外设接口。因此,基于Linux或Android的应用更适合使用性能更强大的处理器或嵌入式系统。
- 需要极高计算能力的场景:STM32虽然是一款性能出色的微控制器,但在需要极高计算能力的场景中,如高性能计算、大型数据处理或复杂图像识别等,其计算能力可能无法满足需求。在这种情况下,可能需要选择更强大的处理器或计算单元。
如图1.4-3所示STM32的产品线,STM32 目前总共有 5 大类,18 个系列,简单总结如下表:
表1.4-1 STM32分类说明
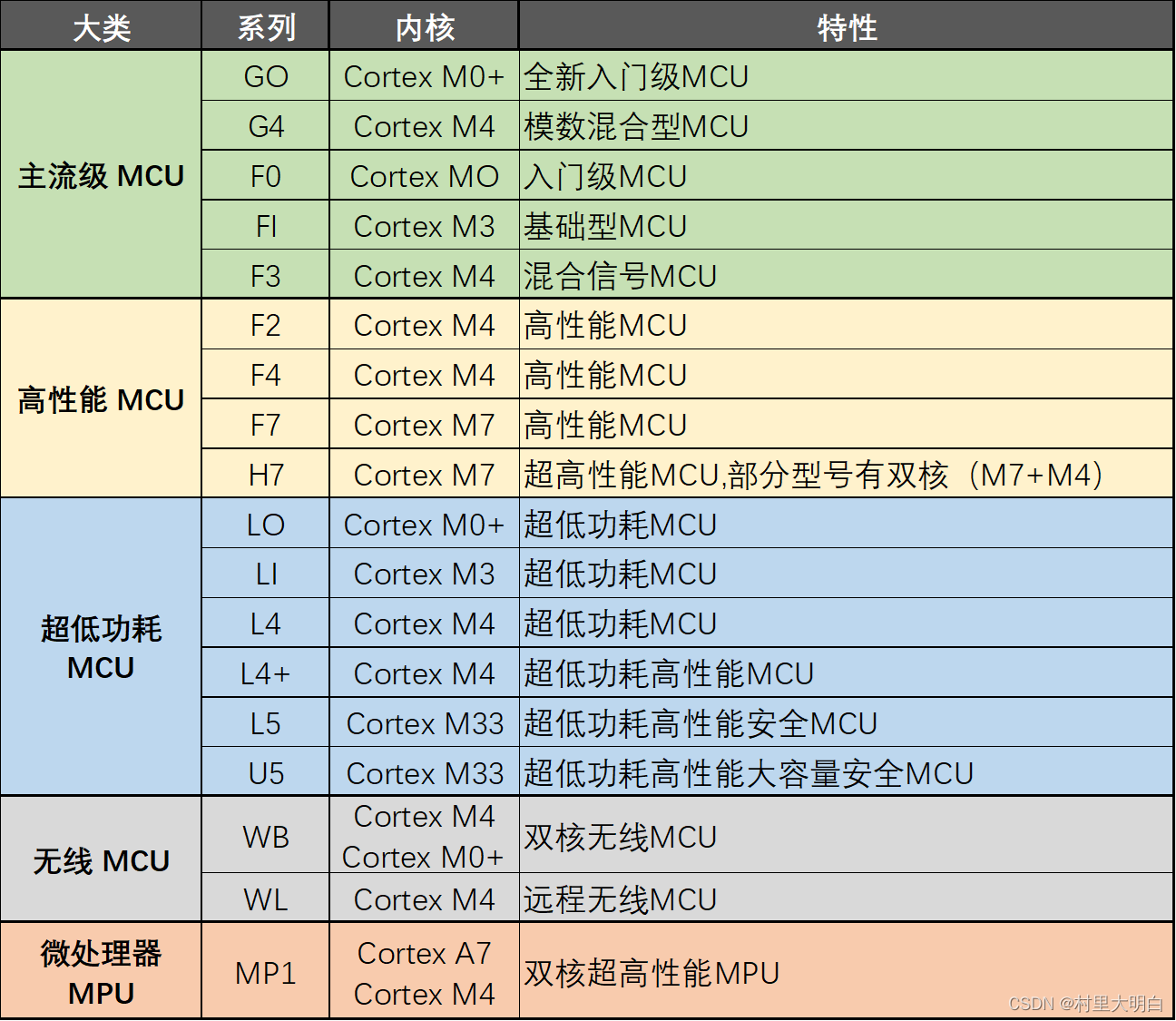
根据上表,可见STM32 主要分两大类,MCU 和 MPU,MCU 就是我们常见的STM32微控器,不能跑 Linux,而 MPU 则是 ST 在 19 年才推出的微处理器,可以跑 Linux。STM32的MCU 提供了包括:基础入门、混合信号、高性能、超低功耗和无线等 5 方面应用的产品型号,我们可以根据自己的实际需要选择合适的 STM32 来设计。比如,我们的产品对性能要求比较高,则可以选择 ST 的高性能 MCU,包括:F2、F4、F7、H7 等 4 个系列的产品;又比如想做超低功耗,则可以选择 ST 的超低功耗 MCU,L 系列的产品。
由于 STM32 系列有很好的兼容性,我们只要能够熟练掌握其中一任何一款 MCU,就可以
很方便的学会并使用其他系列的 MCU。比如学好了 STM32F103,再去学 F4/F7/H7 就比较容易
学会,由于 STM32F103 系列最早推向市场,资料和教程都是最多的,在市场上的使用也是最为
广泛,所以对于没有接触过 STM32 的初学者来说,建议先学习 STM32F103,再去学习其他的 STM32 系列。本专栏介绍的STM32F103C8T6属于主流 MCU 分类里面的基础型 F1 系列。下面我们对STM32常见的几类控制器再进行进一步的介绍。
[1].STM32F1系列(主流类型)
STM32F1系列微控制器包含以下5个产品线,它们的引脚、外设和软件均兼容。
(1)STM32F100,超值型,24MHzCPU,具有电机控制和CEC功能。
(2)STM32F101,基本型,36MHzCPU,具有高达1MB的Flash。
(3)STM32F102,USB基本型,48MHz CPU,具备USBFS。
(4)STM32F103,增强型,72MHzCPU,具有高达1MB的Flash、电机控制、USB和CAN。
(5)STM32F105/107,互联型,72MHz CPU, 具有以太网MAC、CAN和USB2.0 OTG。
[2]. STM32F4系列(高性能类型)
STM32F4系列微控制器基于Cortex-M4内核,采用意法半导体有限公司的90nmNVM工艺和ART加速器,在高达180MHz工作频率下通过闪存执行时,处理性能达225DMIPS/608CoreMark。由于采用了动态功耗调整功能,通过闪存执行时的电流消耗范围为STM32F401的128μA/MHz到STM32F439的260μA/MHz。
STM32F4系列包括8条互相兼容的数字信号控制器(Digital SignalController,DSC)产品线,是MCU实时控制功能与DSP信号处理功能的完美结合体。
(1)STM32F401,84MHz CPU/105DMIPS,尺寸最小、成本最低的解决方案,具有卓越的功耗效率(动态效率系列)。
(2)STM32F410,100MHz CPU/125DMIPS,采用新型智能DMA,优化了数据批处理的功耗(采用批采集模式的动态效率系列),配备的随机数发生器、低功耗定时器和DAC,为卓越的功率效率性能设立了新的里程碑(停机模式下89μA/MHz)。
(3)STM32F411,100MHz CPU/125DMIPS,具有卓越的功率效率、更大的SRAM和新型智能DMA,优化了数据批处理的功耗(采用批采集模式的动态效率系列)。
(4)STM32F405/415,168MHz CPU/210DMIPS,高达1MB的Flash闪存,具有先进连接功能和加密功能。
(5)STM32F407/417,168MHz CPU/210DMIPS,高达1MB的Flash闪存,增加了以太网MAC和照相机接口。
(6)STM32F446,180MHz CPU/225DMIPS,高达512KB的Flash闪存,具有DualQuad SPI和SDRAM接口。
(7)STM32F429/439, 180MHz CPU/225DMIPS, 高达2MB的双区闪存,带SDRAM接口、Chrom-ART加速器和LCD-TFT控制器。
(8)STM32F427/437,180MHz CPU/225DMIPS,高达2MB的双区闪存,具有SDRAM接口、Chrom-ART加速器、串行音频接口,性能更高,静态功耗更低。
(9)SM32F469/479,180MHz CPU/225DMIPS,高达2MB的双区闪存,带SDRAM和QSPI接口、Chrom-ART加速器、LCD-TFT控制器和MPI-DSI接口。
[3]. STM32F7系列(高性能类型)
STM32F7是世界上第一款基于Cortex-M7内核的微控制器。它采用6级超标量流水线和浮点单元,并利用ST的ART加速器和L1缓存,实现了Cortex-M7的最大理论性能。无论是从嵌入式闪存还是外部存储器来执行代码,都能在216MHz处理器频率下使性能达到462DMIPS/1082CoreMark。由此可见,相对于意法半导体以前推出的高性能器控制器,如F2、F4系列,STM32F7的优势就在于其强大的运算性能,能够适用于那些对高性能计算有巨大需求的应用。STM32F7系列与STM32F4系列引脚兼容,包含以下STM32F7x5子系列,STM32F7x6子系列、STM32F7x7子系列和STM32F7x9子系列,四个产品线。
[4]. STM32L1系列(超低功耗类型)
STM32L1系列微控制器基于Corter-M3内核,采用意法半导体专有的超低泄漏制程,具有创新型自主动态电压调节功能和5种低功耗模式,为各种应用提供了完美的平台灵活性。STM32L1扩展了超低功耗的理念,并且不会牺牲性能。与STM32L0一样,STM32L1提供了动态电压调节、超低功耗时钟振荡器、LCD接口、比较器、DAC及硬件加密等部件。
STM32L1系列微控制器可以实现在1.65~3.6V范围内以32MHz的频率全速运行其功耗参考值如下:
(1)动态运行模式,低至177μA/MHz。
2)低功耗运行模式:低至9μA。
(3)超低功耗模式+备份寄存器+RTC:900nA(3个唤醒引脚)。
(4)超低功耗模式+备份寄存器:280nA(3个唤醒引脚)。
除了超低功耗MCU以外,STM32L1还提供了多种特性、存储容量和封装引脚数选项。如 32~512KB Flash 存储器、高达 80KB的SDRAM、16KB真正的嵌入式EEPROM、48~144个引脚。为了简化移植步骤和为工程师提供所需的灵活性,STM32L1与不同的STM32F系列均引脚兼容。STM32L1系列微控制器包含4款不同的子系列:STM32L100超值型、STM32L151、STM32L152(LCD)和STM32L162(LCD和AES-128)。
[5]. STM32-MP1(可跑Linux)
STM32-MP1是意法半导体(STMicroelectronics)推出的一款功能丰富的微控制器,它采用了灵活的异构计算架构,集成了高性能的ARM Cortex-A7应用处理器内核和高效的Cortex-M4微控制器内核。
在STM32-MP1中,Cortex-A7内核的时钟频率可以达到650MHz,配备了32-Kbyte的L1指令高速缓存、32-Kbyte的一级数据高速缓存和256-Kbyte的二级高速缓存。这使得它在执行复杂的数据处理和操作系统任务时具有出色的性能。而Cortex-M4内核则专注于实时处理和低功耗任务,其运行频率为209MHz,并配备了单精度浮点单元(FPU)、全套数字信号处理器(DSP)指令和内存保护单元(MPU),从而增强了应用程序的安全性和效率。
此外,STM32-MP1还具备一个可选的兼容OpenGL的3D GPU,可用于执行高级HMI开发任务。它提供了时钟频率为533MHz的DDR和LPDDR接口,支持经济实惠的DDRSDRAM存储器,如DDR3、DDR3L、LPDDR2和533MHz的32/16位LPDDR3。这样的设计有助于Cortex-M4内核在实时处理和低功耗模式下实现更高效的操作。
STM32-MP1系列微控制器在生态系统方面具有诸多优势,每个产品线都配备了安全选项,如加密和安全启动功能。这使得它在各种应用中都能达到卓越的性能和低功耗效果。此外,STM32-MP1特别适用于长寿命工业应用,公司提供了滚动的10年使用寿命承诺,为设计人员、产品经理和采购团队提供了组件在其设计的整个生命周期中始终可用的保证。
综上所述,STM32-MP1具有强大的性能和丰富的功能,完全能够胜任运行Linux系统的任务,为嵌入式系统和物联网设备的开发提供了强大的支持。
1.4.4 STM32的命名规则
STM32 的产品名字里面包含了:家族、类别、特定功能、引脚数、闪存容量、封装、温度范围等重要信息,这些信息可以帮助我们识别和区分 STM32 不同芯片。STM32的命名规则可参考下图 1.4-4.后面遇到STM32 型号的产品,都可以按图1.4-4 所示命名规则进行区分解读。

图1.4-4 STM32命名规则
第2章.STM32开发C语言常用知识点
2.1. STM32嵌入式开发C语言编程的不同
STM32开发中的C语言编程与通用计算机编程之间存在一些显著的区别,这些区别主要源于两者不同的应用场景和硬件环境。如下图2.1-1,区别主要体现在以下五个方面:
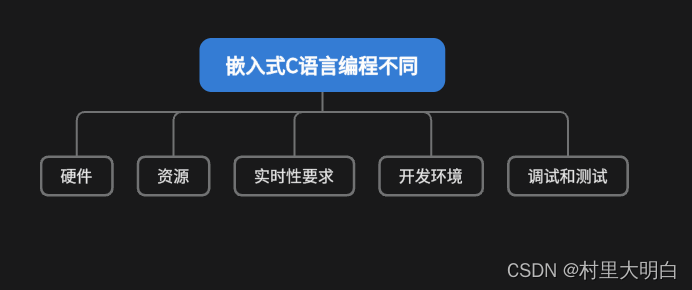
图2.1-1 STM32嵌入式开发C语言编程和通用编程的区别点
- 硬件相关性:
- STM32开发中的C语言编程直接关联到特定的硬件,如微控制器、IO端口、中断、DMA等。开发者需要直接操作这些硬件资源,因此必须了解相关的硬件手册和寄存器配置。
- 通用计算机编程则更多关注于软件设计和算法实现,与硬件的关联度较低。开发者通常不需要直接操作硬件寄存器,而是通过操作系统提供的API进行编程。
- 资源限制:
- STM32等嵌入式系统通常具有有限的内存、存储空间和计算能力。因此,在STM32开发中,C语言编程需要特别注意内存管理、代码优化和性能调优。
- 通用计算机则具有较大的内存和存储空间,以及强大的计算能力。开发者在编写通用计算机程序时,通常不需要过分关注这些资源限制。
- 实时性要求:
- STM32等嵌入式系统通常需要满足严格的实时性要求,即系统需要在规定的时间内响应外部事件。因此,在STM32开发中,C语言编程需要特别注意时间管理和代码执行效率。
- 通用计算机编程则通常不需要满足如此严格的实时性要求。
- 开发工具和环境:
- STM32开发通常使用专门的嵌入式开发环境和工具链,如Keil MDK、IAR Embedded Workbench、STM32CubeIDE等。这些工具提供了针对STM32硬件的特定支持和优化。
- 通用计算机编程则可以使用各种通用的集成开发环境(IDE),如Visual Studio、Eclipse、Dev-C++等。
- 调试和测试:
- STM32开发中的调试和测试通常需要借助专门的调试器、仿真器和测试工具,以模拟硬件环境和验证程序功能。
- 通用计算机编程则可以使用各种调试器和测试框架,以方便地进行程序调试和测试。
总之,STM32开发中的C语言编程与通用计算机编程在硬件相关性、资源限制、实时性要求、开发工具和环境以及编程语言特性等方面存在显著的区别。这些区别要求开发者在编写STM32程序时,需要更加注重底层编程和硬件操作,并充分考虑到嵌入式系统的特殊性和限制。
2.2. C语言常用知识点
我们这里就列举部分 STM32 学习中会遇见的 C 语言基础知识点。
2.2.1 位操作
C 语言位操作就是对基本类型变量可以在位级别进行操作。C 语言支持如下表6种位操作:
表2.2-1-C语言支持的位操作
| 运算符 | 含义 |
| & | 按位与 |
| | | 按位或 |
| ^ | 按位异或 |
| ~ | 按位取反 |
| << | 左移 |
| >> | 右移 |
这些按位与或,取反,异或,右移,左移这些我们就不多做详细讲解,毕竟这里不是给大家普及C语言的基本知识,不清楚的大家可以再复习一下。下面我们着重讲解位操作在嵌入式开发中的一些实用技巧。
1.在不改变其他位的值的状况下对某几个位进行设值
这个场景在单片机开发中经常使用,方法就是先对需要设置的位用"&"操作符进行清零操作,然后用"|"操作符设值。比如我要改变 GPIOA 的状态,可以先对寄存器的值进行&清零操作:
GPIOA->CRL &= 0XFFFFFF0F; /* 将第 4~7位清 0 */
/*然后再与需要设置的值进行|或运算:*/
GPIOA->CRL |= 0X00000040; /* 设置相应位的值(4),不改变其他位的值 */ 2.移位操作提高代码的可读性
移位操作在单片机开发中非常重要,下面是 delay_init 函数的一行代码:
SysTick->CTRL |= 1 << 1;这个操作就是将 CTRL 寄存器的第 1 位(从 0 开始算起)设置为 1,为什么要通过左移而不是直接设置一个固定的值呢?其实这是为了提高代码的可读性以及可重用性。这行代码可以很直观明了的知道,是将第 1 位设置为 1。如果写成:
SysTick->CTRL |= 0X0002;这个虽然也能实现同样的效果,但是可读性稍差,而且修改也比较麻烦。
3.~按位取反操作使用技巧
按位取反在设置寄存器的时候经常被使用,常用于清除某一个/某几个位。下面是 delay_us函数的一行代码:
SysTick->CTRL &= ~(1 << 0) ; /* 关闭 SYSTICK */ 该代码可以解读为 仅设置 CTRL 寄存器的第 0 位(最低位)为 0,其他位的值保持不变。同样我们也不使用按位取反,将代码写成:
SysTick->CTRL &= 0XFFFFFFFE; /* 关闭 SYSTICK */ 可见前者的可读性,及可维护性都要比后者好很多。
4.^按位异或操作使用技巧
该功能非常适合用于控制某个位翻转,常见的应用场景就是控制 LED 闪烁,如:
GPIOB->ODR ^= 1 << 5;执行一次该代码,就会使 PB5 的输出状态翻转一次,如果我们的 LED 接在 PB5 上,就可以看到 LED 闪烁了。
2.2.2 define 宏定义
define 是 C 语言中的预处理命令,它用于宏定义(定义的是常量),可以提高源代码的可读性,为编程提供方便。常见的格式:
#define 标识符 字符串"标识符"为所定义的宏名;"字符串"可以是常数、表达式、格式串等。例如:
#define PIE 3.14159fPIE在后续出现的地方都代表3.14159。后续如果想修改π的值,可以直接在宏定义的地方修改,不用再在程序出现的每一个地方再去修改,而且非常直观,代码可读性强。
2.2.3 条件编译
2.2.3.1 #ifdef
嵌入式程序开发过程中,经常会遇到一种情况,当满足某条件时对一组语句进行编译,而当条件不满足时则编译另一组语句。条件编译命令最常见的形式为:
#ifdef 标识符
程序段 1
#else
程序段 2
#endif 它的作用是:当标识符已经被定义过(一般是用#define 命令定义),则对程序段 1 进行编译,否则编译程序段 2。 其中#else 部分也可以没有,即:
#ifdef
程序段 1
#endif 2.2.3.2 #ifndef
#ifndef SOME_MACRO
// 如果 SOME_MACRO 没有被定义,则编译以下代码
#endif2.2.3.3 #if !defined
#if !defined(SOME_MACRO)
// 如果 SOME_MACRO 没有被定义,则编译以下代码
#endif这也是检查是否没有定义某个宏的方法,但它使用了!defined操作符.
在这个例子中!defined(SOME_MACRO) 是一个条件表达式,当 SOME_MACRO 没有被定义时,该表达式的值为真(非零),从而编译 #if 和对应 #endif 之间的代码。下面是STM32里的一段代码:
#if !defined (HSE_VALUE)
#define HSE_VALUE 24000000U
#endif 如果没有定义HSE_VALUE这个宏,则定义HSE_VALUE宏,并且HSE_VALUE的值为24000000U。24000000U中的U表示无符号整型,常见的,UL表示无符号长整型,F表示浮点型。这里加了U以后,系统编译时就不进行类型检查,直接以U的形式把值赋给某个对应的内存,如果超出定义变量的范围,则截取。
2.2.4 extern 变量声明
C 语言中 extern 可以置于变量或者函数前,以表示变量或者函数的定义在别的文件中,提示编译器遇到此变量和函数时在其他模块中寻找其定义。这里面要注意,对于extern声明变量可以多次,但定义只有一次。在我们的代码中你会看到看到这样的语句:
extern uint16_t speed_x; 这个语句是申明 speed_x变量在其他文件中已经定义了,在这里要使用到。所以,你肯定可以找到在某个地方有变量定义的语句:
uint16_t speed_x;2.2.5 typedef 类型别名
typedef 用于为现有类型创建一个新的名字,或称为类型别名,用来简化变量的定义。
例如C99标准中引入的头文件<stdint.h>,定义了一组具有固定宽度的整数类型,包括有符号和无符号的8位、16位、32位和64位整数。这些类型分别命名为int8_t、int16_t、int32_t、int64_t(以及对应的无符号类型uint8_t、uint16_t、uint32_t、uint64_t)。在STM32F10x的标准库函数stm32f10x.h中又对这些数据类型进行了重新定义,代码如下:
typedef int32_t s32;
typedef int16_t s16;
typedef int8_t s8;
typedef uint32_t u32;
typedef uint16_t u16;
typedef uint8_t u8;typedef在 MDK 用得最多的就是定义结构体的类型别名和枚举类型了。
struct _GPIO
{
__IO uint32_t CRL;
__IO uint32_t CRH;
…
}; 定义了一个结构体 GPIO,这样我们定义结构体变量的方式为:
struct _GPIO gpiox; /* 定义结构体变量 gpiox */ 但是这样很繁琐,MDK中有很多这样的结构体变量需要定义。这里我们可以为结体定义一
个别名GPIO_TypeDef,这样我们就可以在其他地方通过别名GPIO_TypeDef来定义结构体变量了,方法如下:
typedef struct
{
__IO uint32_t CRL;
__IO uint32_t CRH;
…
} GPIO_TypeDef; Typedef为结构体定义一个别名GPIO_TypeDef,这样我们可以通过GPIO_TypeDef来定义结构体变量:
GPIO_TypeDef gpiox;这里的 GPIO_TypeDef 就跟 struct _GPIO 是等同的作用了,但是 GPIO_TypeDef 使用起来方便很多。
2.2.6 结构体
在C语言中,结构体(struct)是一种用户自定义的数据类型,它允许你将不同类型的数据项组合成一个单独的数据结构。结构体可以用来表示一个具有复杂属性的实体,比如一个人(具有姓名、年龄、性别等属性)或者一本书(具有书名、作者、出版日期等属性)。
2.2.6.1 结构体的声明和定义
/*声明结构体类型: */
struct 结构体名
{
成员列表;
}变量名列表; 你可以在声明结构体的时候直接创建结构体变量,也可以先定义结构体类型,然后再创建变量,如下面几种方式都是可以的:
// 直接定义并创建结构体变量
struct {
int age;
char name[50];
} person1;
// 直接定义并创建结构体变量
struct Person{
int age;
char name[50];
} person2;
// 先定义结构体类型,再创建变量
struct Person {
int age;
char name[50];
};
struct Person person3;2.2.6.2 引用结构体成员变量
要访问结构体变量的成员,你需要使用.运算符(对于结构体变量)或->运算符(对于指向结构体的指针)。
/*接前面章节2.6.1的示例代码*/
// 访问结构体变量的成员
person1.age = 25;
// 如果有一个指向结构体的指针
struct Person *ptr = &person2;
ptr->age = 30; 2.2.6.3 结构体的作用
下面我们将简单的通过一个实例描述一下结构体的作用。
在我们单片机程序开发过程中,经常会遇到要初始化一个外设比如串口,它的初始化状态是由几个属性来决定的,比如串口号,波特率,极性,以及模式。对于这种情况,在我们没有学习结构体的时候,我们一般的方法是:
void usart_init(uint8_t usartx, uiut32_t BaudRate, uint32_t Parity,
uint32_t Mode); 这种方式是有效的同时在一定场合是可取的。但是试想,如果有一天,我们希望往这个函数里面再传入一个/几个参数,那么势必我们需要修改这个函数的定义,重新加入新的入口参数,随着开发不断的增多,那么是不是我们就要不断的修改函数的定义呢?这是不是给我们开发带来很多的麻烦?那又怎样解决这种情况呢?
我们使用结构体参数,就可以在不改变入口参数的情况下,只需要改变结构体的成员变量就可以达到改变入口参数的目的。
结构体就是将多个变量组合为一个有机的整体,上面的函数usartx,BaudRate,Parity,Mode等这些参数,他们对于串口而言,是一个有机整体,都是来设置串口参数的,所以我们可以将他们通过定义一个结构体来组合在一个。MDK中是这样定义的:
typedef struct
{
uint32_t BaudRate;
uint32_t WordLength;
uint32_t StopBits;
uint32_t Parity;
uint32_t Mode;
uint32_t HwFlowCtl;
uint32_t OverSampling;
} UART_InitTypeDef; 这样,我们在初始化串口的时候入口参数就可以是 USART_InitTypeDef 类型的变量或者指针变量了,于是我们可以改为:
void usart_init(UART_InitTypeDef *huart); 这样,任何时候,我们只需要修改结构体成员变量,往结构体中间加入新的成员变量,而不需要修改函数定义就可以达到修改入口参数同样的目的了。这样的好处是不用修改任何函数定义就可以达到增加变量的目的。
在以后的开发过程中,如果你的变量定义过多,如果某几个变量是用来描述某一个对象,你可以考虑将这些变量定义在结构体中,这样也许可以提高你的代码的可读性。使用结构体组合参数,可以提高代码的可读性,不会觉得变量定义混乱。
2.2.6.4 结构体成员的内存分布与对齐
首先一些基本知识点:
(1)声明一个结构体类型的时候是没有为它分配任何存储空间的,只有在定义结构体变量的时候,才会为变量分配存储空间。
(2)结构体中可以有不同的数据类型成员,成员在定义时依次存储在内存连续的空间中,结构体变量的首地址就是第一个成员的地址,内存偏移量就是各个成员相对于第一个成员地址的差(即,把低位内存分配给最先定义的变量)。
(3)理论上,结构体所占用的存储空间是各个成员变量所占的存储空间之和,但是为了提高CPU的访问效率,采用了内存对齐方式:
①结构体的每一个成员起始地址必须是自身类型大小的整数倍,若不足,则不足部分用数据填充至所占内存的整数倍。
②结构体大小必须是结构体占用最大字节数成员的整数倍,这样在处理数组时可以保证每一项都边界对齐根据上面的说明,我们举例子分析如下:
struct test
{
char a;
int b;
float c;
double d;
}mytest; 这个结构体所占用的内存怎么算呢?理论结果为17,实际上并不是17,而是24。为什么会这样呢?这个就是前面我们说的内存对齐。
char型变量占1个字节,所以它的起始地址是0。int类型占用4个字节,它的起始地址要求是4的整数倍数,那么内存地址1、2、3就需要被填充(被填充的内存不适于变量),b从4开始。float类型也是占用4个字节,起始地址要求是4的倍数,所以c的起始地址就是8。double类型变量占用8个字节,起始地址为16,12~15被填充。这里,第一个成员a的地址首地止,第二个成员b的偏移量为4,第三个成员c的偏移量是8,以此类推,是如下图2.6-1所示:

图2.6-1 结构地地址内存分配
2.2.7 关键字
在STM32的一些库函数头文件中,经常会看到如下代码, 表示将 volatile 或者 volatile const 来代替某一个符号。
#define __I volatile
#define __O volatile
#define __IO volatile
#define __IM volatile const
#define __OM volatile
#define __IOM volatile 2.2.7.1 volatile
volatile 表示强制编译器减少优化,告诉编译器必须每次去内存中取变量值。
程序运行时数据是存储在主内存(物理内存)中的,每个线程先从主内存拷贝变量到对应的寄存器中。对没有加volatile的变量进行读写时,为了提高读取速度,编译器进行优化时,会先把主内存中的变量读取到一个寄存器中,以后,再读取此变量的值时,就直接从该寄存器中读取,而不是直接从内存中读取了,这样的读写速度比较快。如果其它程序改变了内存中变量的值,上面已经保存到寄存器中的值不会跟着改变,从而造成应用程序读取的值和实际的变量值不一致。加了修饰关键字volatile以后的变量,表示不想被编译器优化掉,每次都要从内存中读取该变量的数据,不会用寄存器里的值,这样确保了数据的准确性,但影响了效率。
2.2.7.2 const
const称为常量限定符,用来限定特定变量为只读属性,如果修改此变量,则编译器会报错。const修饰的变量存储在只读数据段,在程序结束时释放,而const局部变量存储在栈中,代码块结束时释放。用const定义变量时就要初始化该变量:
const int a = 1; 2.2.7.3 static
static关键字修饰的变量称为静态变量,如果该变量在声明时未赋初始值,则编译器自动初始化为0,静态变量存储在全局区(静态区)。
在函数内被static声明的变量,仅能在本函数中使用,也叫静态局部变量。
在文件内(函数体外)被static声明的变量,仅能被本文件内的函数访问,不能被其他文件中的函数访问,也叫静态全局变量。
静态全局变量和普通的全局变量不同,静态全局变量仅限于本文件中使用,在其它文件中可以定义一个与静态全局变量名字相同的变量。普通的全局变量可以通过extern外部声明后被其他文件使用,也就是整个工程可见,而且其他文件不能再定义一个与普通全局变量名字相同的变量了。
用static修饰的函数和用static修饰的变量类似。 下面是用法举例说明:
1.局部静态变量:
当在函数内部声明一个变量为static时,该变量的存储期将变为整个程序的执行期,而不是只在函数调用被时存在。这意味着局部变量只会被初始化一次,并且会保留其值,直到程序结束。这在需要跨函数调用保留某些信息时非常有用。
void func() {
static int count = 0; // 只在程序开始时初始化一次
count++;
printf("%d\n", count);
}每次调用func()时,count的值都会递增。
2.全局静态变量:
在文件级别(即不在任何函数内部)声明的static变量只能在该文件内部可见。这意味着它们只能被定义它们的文件内的函数访问,而不能被其他文件访问。这提供了一种封装机制,允许你在一个文件中定义和使用变量,而不用担心与其他文件冲突。
// file1.c
static int file_scope_var = 42; // 只能在file1.c中访问
// file2.c
extern int file_scope_var; // 错误:无法在其他文件中访问file_scope_var3.静态函数:
当在文件级别使用static关键字声明一个函数时,该函数将具有内部链接,即它只能在其定义的文件内被调用。这提供了另一种封装机制,允许你隐藏函数的实现细节,只暴露需要被其他文件使用的函数。
// file1.c
static void internal_function() {
// ...
}
// file2.c
extern void internal_function(); // 错误:无法在其他文件中调用internal_function4.静态初始化:
尽管这不是static的直接用途,但它在静态初始化中扮演了重要角色。当全局变量或静态变量被声明并赋予初值时,编译器会确保在程序开始执行之前进行初始化。这通常是在main()函数之前发生的。
2.2.8 指针
在STM32开发中,指针的作用十分重要。首先,指针是C语言的一个重要组成部分,它允许我们通过内存地址直接访问和操作数据。在STM32这样的嵌入式系统开发中,指针的使用与底层硬件的联系尤为密切。
具体来说,STM32库开发中,我们对寄存器进行了封装,将寄存器放入到结构体(如GPIOX)当中。通过指针,我们可以指向这些结构体的地址,从而访问和操作寄存器,完成对寄存器的配置。这种方式可以减少开发时的代码量,提高开发效率。
同时,指针移位操作在STM32开发中也是常见的。通过指针移位,我们可以方便地访问连续的内存区域,比如数组或结构体中的连续元素。在C语言中,我们可以通过指针算术运算(如加法、减法)来实现指针的移位。需要注意的是,在进行指针移位操作时,应确保指针类型和指向的数据类型一致,并遵循C语言指针算术运算的规则。
此外,指针还可以用于访问和操作内存映射的硬件寄存器。在STM32中,许多硬件资源都是通过内存映射的方式暴露给软件的。通过指针,我们可以直接访问这些硬件寄存器的地址,从而实现对硬件的控制和配置。
总的来说,指针在STM32开发中具有重要的作用,它允许我们通过内存地址直接访问和操作数据,实现对硬件的底层控制和优化。然而,由于指针直接操作内存地址,因此在使用时也需要格外小心,以避免出现内存泄漏、野指针等问题。
指针的具体使用方法,这里就不再赘述。
第3章.STM32F1x系统架构及资源介绍
3.1.STM32F1x系统架构
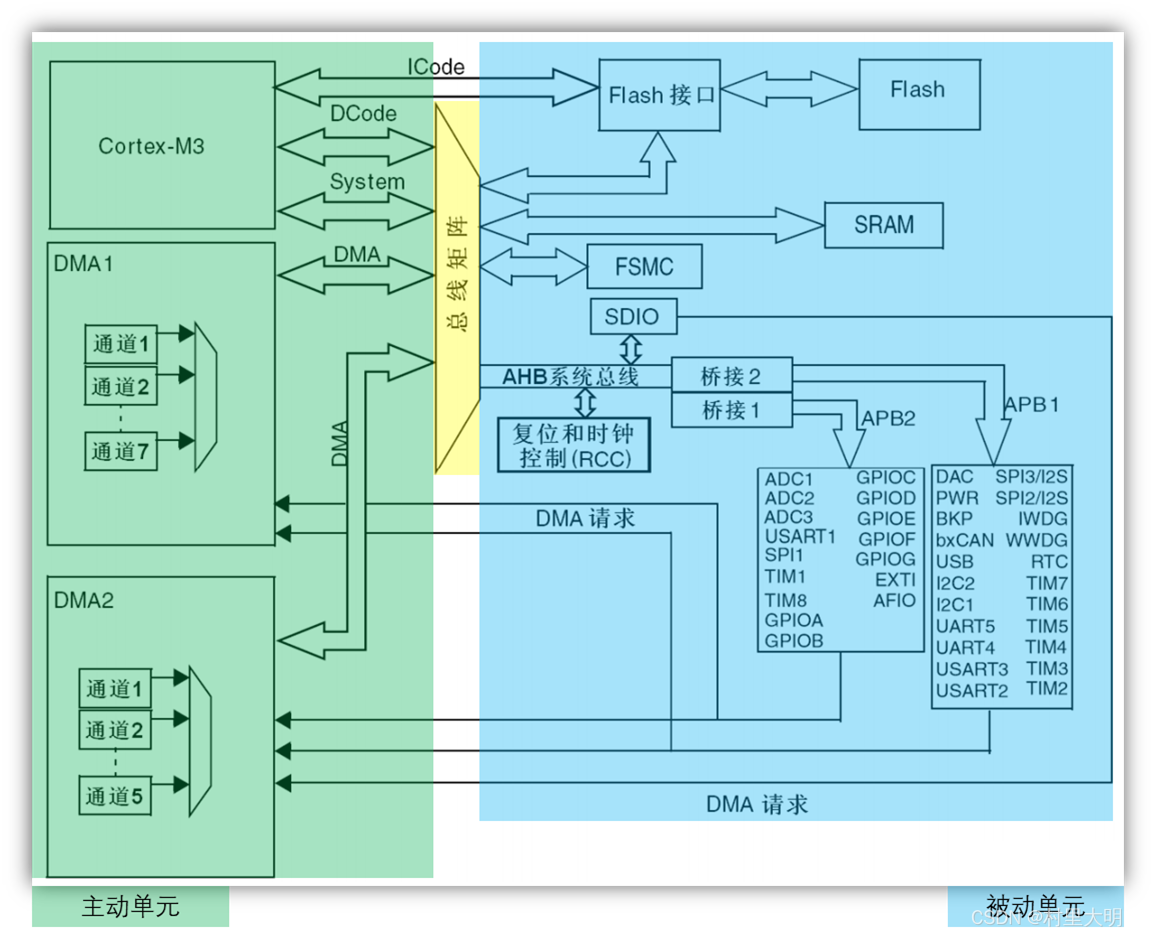
图3.1-1STM32F1x系统架构图
如图3.1-1所示为STM32F1系列的系统架构图。蓝色为被动单元,绿色为主动单元。主动和被动单元之间通过总线矩阵连接。STM32F1x各总线和设备总结如下图3.1-2.
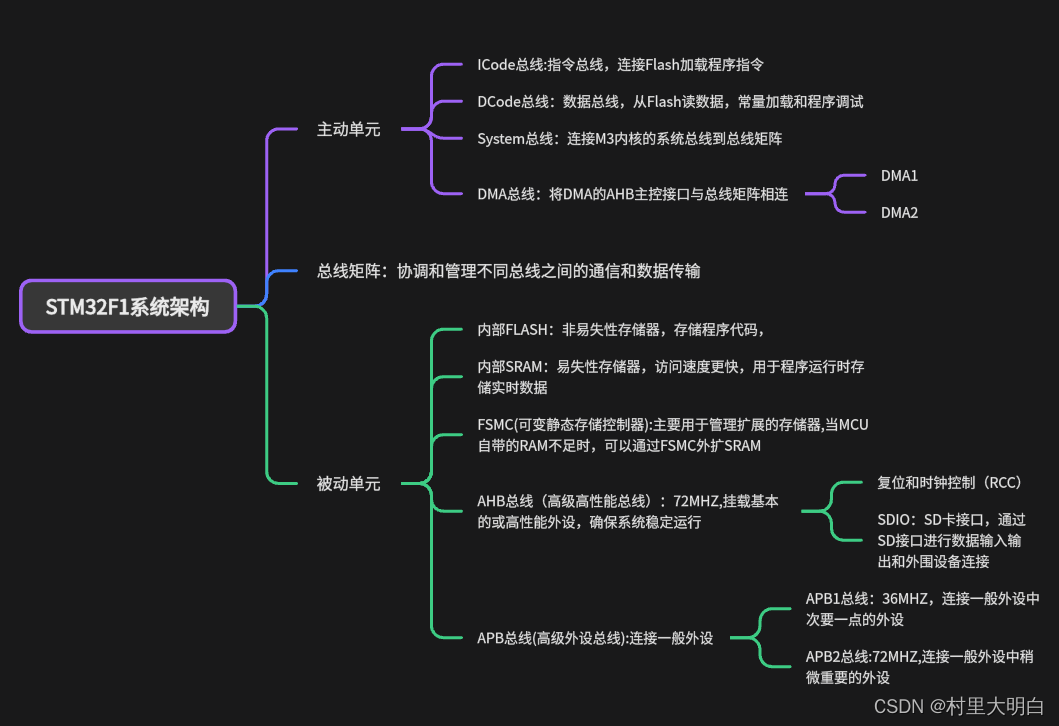
图3.1-2 STM32F1x总线简介
3.1.1-ICode总线
ICode总线是指令总线,它的主要作用是连接Cortex-M3内核与FLASH存储器的指令接口。具体来说,ICode总线用于加载FLASH闪存中的程序指令。当我们编写的程序被编译后,它会转换为一条条机器指令,并存储在FLASH闪存中。Cortex-M3内核通过ICode总线可以获取这些指令,并按顺序执行代码。因此,ICode总线在STM32F1系列单片机中起到了关键的作用,确保内核能够正确地读取并执行程序指令。ICode总线直接连接Flash接口,不需要经过总线矩阵。
3.1.2-DCode总线
DCode总线是数据总线。它主要负责从Flash存储器或其他非易失性存储器中取指(Fetch),即将指令读取到指令流水线中。具体来说,DCode总线是Cortex-M3内核与存储器系统之间指令传输的通道,确保CPU能够按照程序顺序执行存储在存储器中的指令。此外,DCode总线还用于加载数据,如常量和调试数据等。Cortex-M3内核可以通过DCode总线访问Flash闪存和SRAM中的数据。在实际应用中,变量通常会储存在内部的SRAM中,而Flash闪存中则会储存程序所用到的常量。
那么ICode总线和DCode总线有什么区别呢?
ICode总线主要承担的是指令的预取任务。它将M3内核指令总线和闪存指令接口相连接,确保CPU能够正确且高效地获取存储在Flash闪存中的指令。这一过程对于单片机的正常运行至关重要,因为只有获取到正确的指令,CPU才能按照程序设定的逻辑进行工作。
而DCode总线则主要负责数据的传输和访问。它将M3内核的DCode总线与闪存存储器的数据接口相连接,使得CPU能够读取Flash中存储的全局变量的数值以及其他数据(例如常量)。此外,DCode总线还负责常量加载和调试访问,这些都是在数据传输和访问过程中必须完成的任务。
3.1.3-System总线
系统总线连接Cortex-M3内核系统总线到总线矩阵,从而连接Cortex-M3内核与外设寄存器,确保CPU能够高效、准确地访问和操作这些外设。通过system系统总线,CPU可以读取外设的状态信息,了解外设的当前工作状况;同时,CPU还可以向外设发送控制指令,实现对外设的精确控制。此外,system系统总线还负责在CPU和外设之间进行数据传输,无论是读取传感器数据还是向执行器发送指令,都需要通过这条总线来完成。
system系统总线的存在,使得STM32F1系列单片机能够灵活地控制和管理各种外设,实现复杂的系统功能。它是单片机与外设之间通信和数据传输的关键通道,确保了单片机系统的正常运行和高效性能。
3.1.4-总线矩阵
总线矩阵主要用于连接Cortex-M内核、DMA控制器、外设和存储器,实现这些组件之间的互连和数据传输。
具体来说,总线矩阵通过协调内核系统总线和DMA主控总线之间的访问仲裁,确保多个总线之间的通信和数据传输能够高效、有序地进行。这种协调功能基于轮换算法实现,确保了即使在多个高速外设同时运行的情况下,系统也能实现并发访问和高效运行。此外,总线矩阵还负责管理控制总线之间的访问优先级。这有助于优化系统性能,确保关键数据和指令能够优先传输和处理。
3.1.5-DMA总线
DMA(Direct Memory Access,直接内存访问)总线允许外设设备直接与内存进行数据传输,而无需CPU的干预。这使得数据可以在外设与存储器之间或存储器与存储器之间直接传输,大大提高了数据传输的效率和性能。
DMA传输数据移动过程无需CPU直接操作,从而节省了CPU资源,使其可供其它操作使用。这种数据传输方式不仅提高了CPU的效率,还降低了系统的功耗。
在STM32F1系列单片机中,DMA控制器被集成在内部总线矩阵中。通过DMA控制器的配置和操作,可以实现外设和内存之间的数据传输。STM32F1系列的DMA控制器可能包含多个通道,每个通道专门用来管理来自于一个或多个外设对存储器访问的请求。这些通道可以理解为传输数据的一种管道,通过软件来配置。
3.1.6-AHB/APB总线
AHB总线通过两个桥接与2个APB总线连接。
AHB(Advanced High-performance Bus,高级高性能总线) 主要用于挂载基本或者高性能的外设,确保系统的稳定运行,AHB的最大频率是72MHZ。
APB(Advanced Peripheral Bus,高级外设总线)主要负责连接低速外设,如UART、I2C、I/O接口等。AHB总线注重高性能模块之间的数据交换,而APB总线则更侧重于简单、高效的外设连接。
其中APB又分为高速的APB2和低速的APB1,APB2连接外设中比较重要的外设,APB1连接次重要的外设,如下图3.1-3所示。很多外设的1号通道都配置在了APB2中。APB2的最大频率和AHB一样是72MHZ,APB1的最大频率只有36MHZ。

图3.1-3 STM32F1系列APB2和APB1总线挂载外设图
3.2.STM32F1x片上资源

图3.2-1 STM32F1系列的外设资源
如图3.2-1, 是STM32系列的外设资源,需要注意,有些型号可能并不一定有,具体每个芯片有哪些资源,需要查看对应手册。后面我们的教程就是围绕这些外设展开的。
3.3.STM32F103C8T6引脚定义

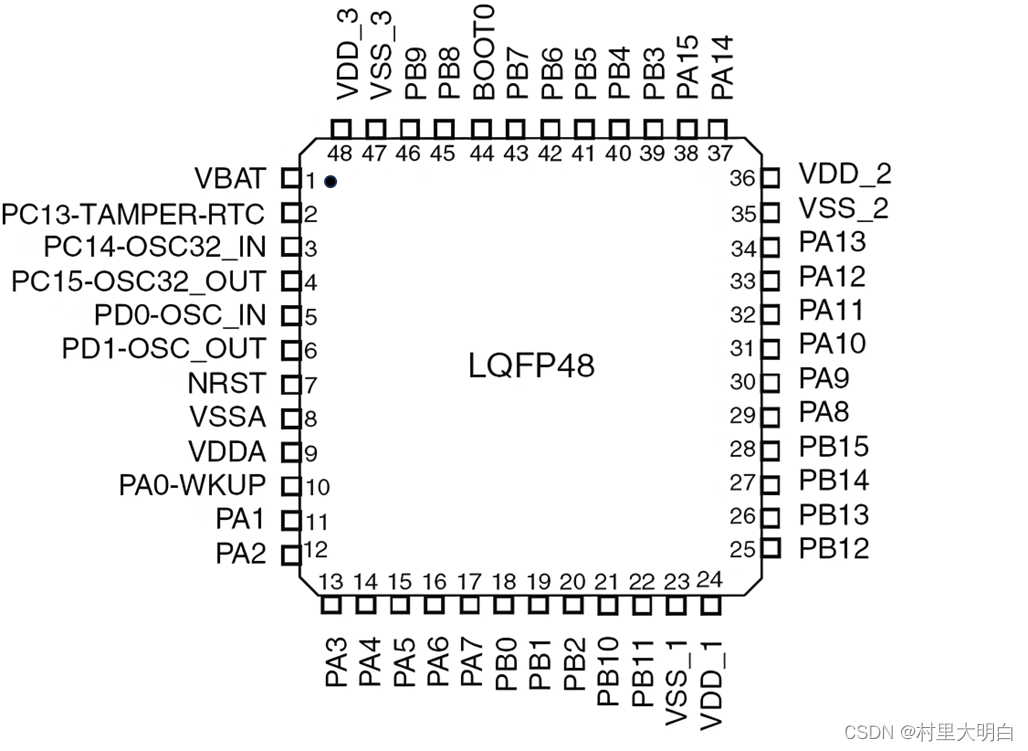
图3.3-1 STM32F103C8T6主要参数及引脚
如上图,STM32F103C8T6的引脚排布,左上角一般都会有个标记黑圈等,这个标记左侧的引脚定义为1号引脚,然后按逆时针依次排序。其他型号的芯片一般也都是按这个规则进行引脚定义排布。STM32F103C8T6有48个引脚,各引脚的功能及含义总结如下图:
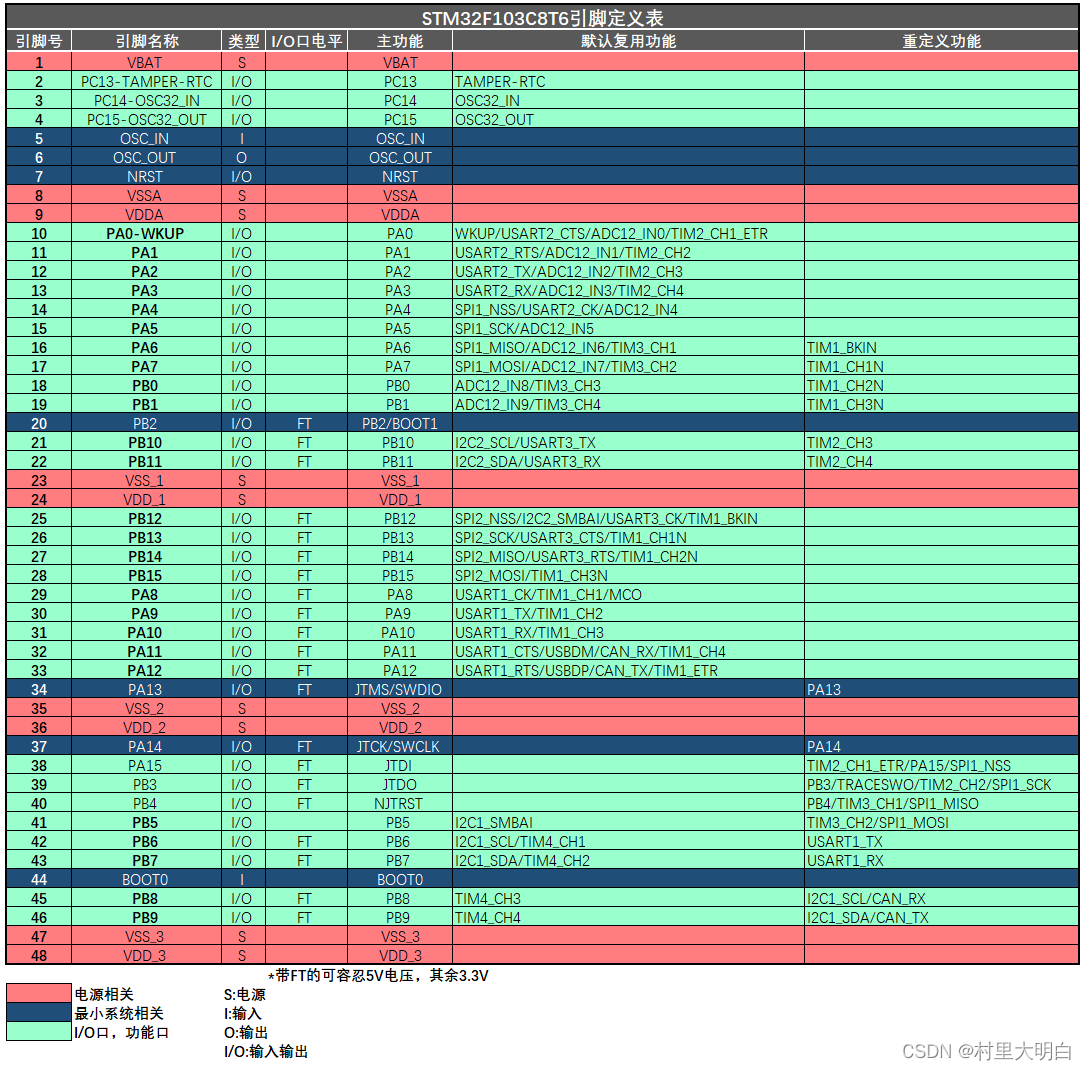
图3.3-2 STM32F103C8T6各引脚定义
如图3-2.红色标注的是和电源相关的引脚,蓝色是和最小系统有关的引脚,绿色是正常的I/O口,功能口。 引脚的类型以及电平,下图的最下方已经进行了标注,这里不再赘述,下面将一下引脚的这3个功能的含义:
3.3.1 主功能
STM32引脚的主功能是其上电后的默认功能。通常,主功能与引脚名称相同,但也可能存在实际功能与引脚名称不符的情况。在这种情况下,引脚的实际功能应被视为其主功能,而不是引脚名称所指示的功能。主功能涵盖了通信、控制、数据传输等单片机常用的操作。
3.3.2 默认复用功能
在STM32中,GPIO(通用输入输出)引脚具有复用功能,即这些引脚可以被配置为执行除其主要功能之外的其他功能。这种复用功能使得单片机能够在有限的引脚数量上实现更多的外设功能。例如,某些GPIO引脚可以被复用为I2C通信、SPI通信或其他外设的接口。这种复用性是通过软件配置来实现的,使得引脚的功能更加灵活多变。即复用功能就是I/O口上同时连接的外设功能引脚,这个我们可以在配置I/O口的时候选择主功能还是默认复用功能。
3.3.3 重定义功能
在某些情况下,一个外设的引脚除了具有默认的端口外,还可以重新映射,将外设的功能映射到其他的引脚上。这就是引脚的重定义功能,也被称为重映射。这种功能在引脚被其他外设占用,但仍需要其原始外设功能时非常有用。如果有2个功能同时复用在了一个I/O口上,而我们却又确实需要用到这2个功能,我们就可以把其中一个复用功能映射到其他端口,当然前提是这个重定义功能的表里有对应的端口。
3.4.STM32数据手册及资料资源
学习单片机一定要学会查看参考手册。同时提供ST中文社区网站:
ST中文社区网:https://www.stmcu.org.cn

第4章.STM32单片机的最小系统电路
4.1. STM32单片机最小系统电路的组成
单独一个微处理器自己是无法工作的,还必须有供电,时钟,晶振等电路才能正常工作,即最小系统电路。那么STM32的最小系统电路有哪些部分组成呢,如下图4.1-1所示。
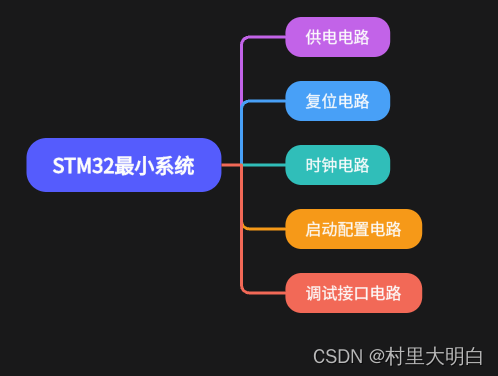
图4.1-1.STM32最小系统电路组成
STM32单片机的最小系统主要由以下几个部分组成:
[1].电源电路:这是为STM32芯片提供工作电压的电路部分。通常,STM32的工作电压为3.3V,因此电源电路可能需要使用LDO(低压差线性稳压器)将5V电压转换为3.3V,以满足STM32的工作需求。同时,为了稳定输入电压,电路中还会加入去耦电容进行滤波。一个设计电路图如下图4.1-2.
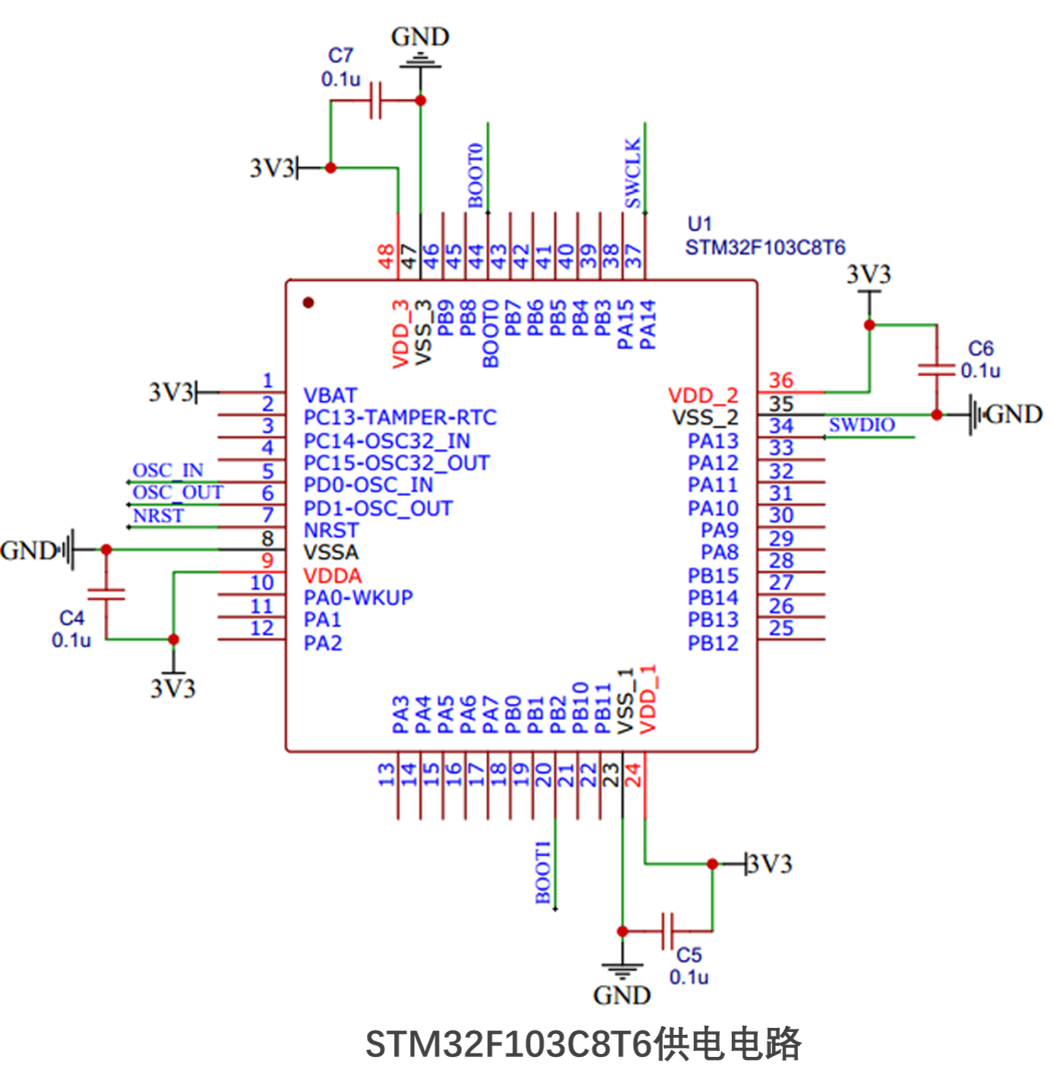
图4.1.2 STM32供电电路设计
[2].复位电路:复位电路在STM32单片机中起着至关重要的作用。它能在复位时,使单片机的程序计数器回到初始地址(如0000H),从而使程序从起始处重新执行。此外,复位操作还会将寄存器和存储单元的值重置为初始设定值,使单片机能够重新开始执行。STM32中有三种复位方式,分别是上电复位、手动复位和程序自动复位。复位电路如图4.1-3.
[3].时钟电路:时钟电路为STM32单片机提供时钟信号,这是单片机正常工作的基础。时钟电路通常由晶振和相关的电路组成,为单片机提供稳定的时钟频率。STM32主晶振为8MHZ,经过倍频后为72MHZ。
[4].调试接口电路:这是用于下载程序和调试单片机的接口电路,常见的调试接口有JTAG和SWD。
[5].启动配置电路:启动配置通常是通过STM32的BOOT引脚来实现的,这些引脚(如BOOT0和BOOT1)能够支持从内部FLASH启动、系统存储器启动以及内部SRAM启动等多种启动方式。这些启动配置决定了单片机在上电或复位后从哪个存储器区域开始执行程序。
因此,在设计和搭建STM32单片机的最小系统时,启动配置是不可或缺的一部分。它确保了单片机在启动时能够按照预期的方式加载和执行程序,从而实现所需的功能和控制逻辑。
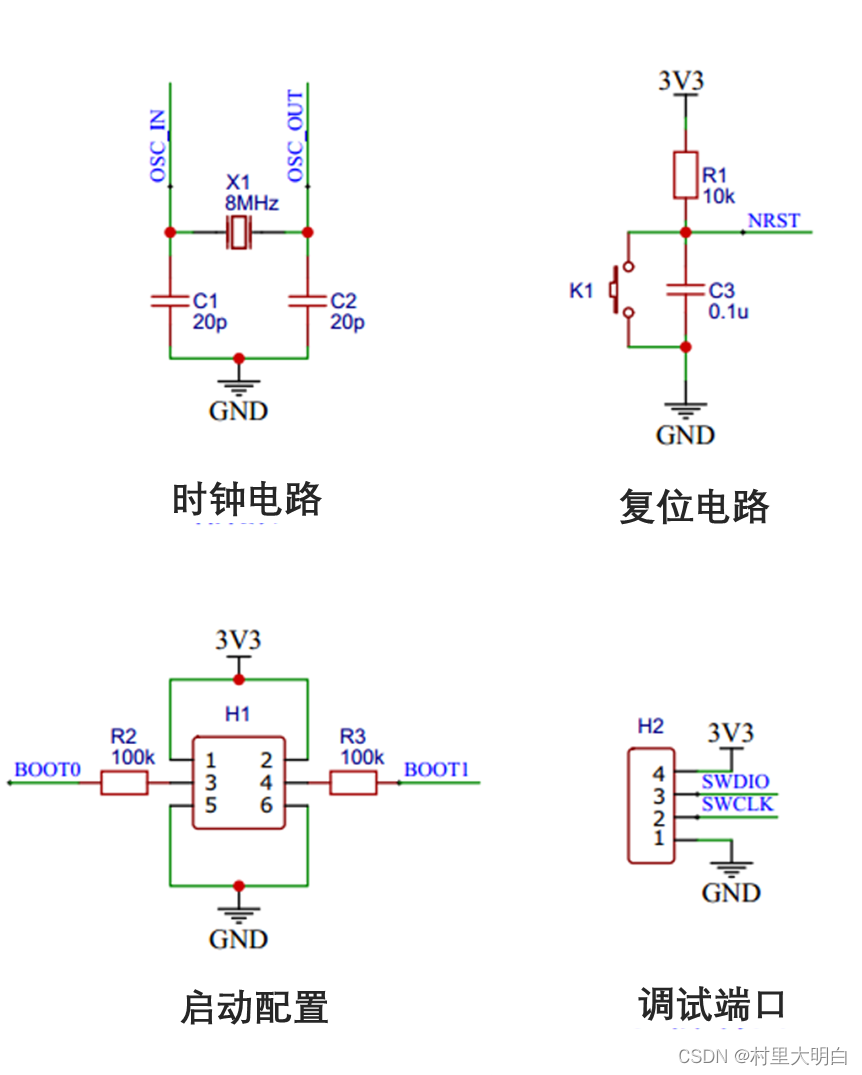
图4.1-3 STM32时钟,复位,调试电路
4.2. STM32单片机的调试接口
调试接口不是系统运行的必需的接口电路,但是为了系统开发、调试、升级等方便,我们在设计最小系统时,可以加上这一部分电路。STM32 系列微处理器内置了一个JTAG和一个SWD接口,通过这两个接口可以控制芯片的运行,并可以获取内部寄存器的信息。这两个接口都要使用GPIO(普通I/O口)来供调试仿真器使用。选用其中一个接口即可将在PC上编译好的程序下载到单片机中运行调试。
4.2.1 JTAG 调试接口
JTAG 是一种国际标准测试协议,主要用于芯片内部测试。标准的JTAG调试接口有4根线,分别为模式选择(TMS)、时钟(TCK)、数据输入(TDI)和数据输出(TDO)线。JTAG 调试接口电路如图4.2-1所示。
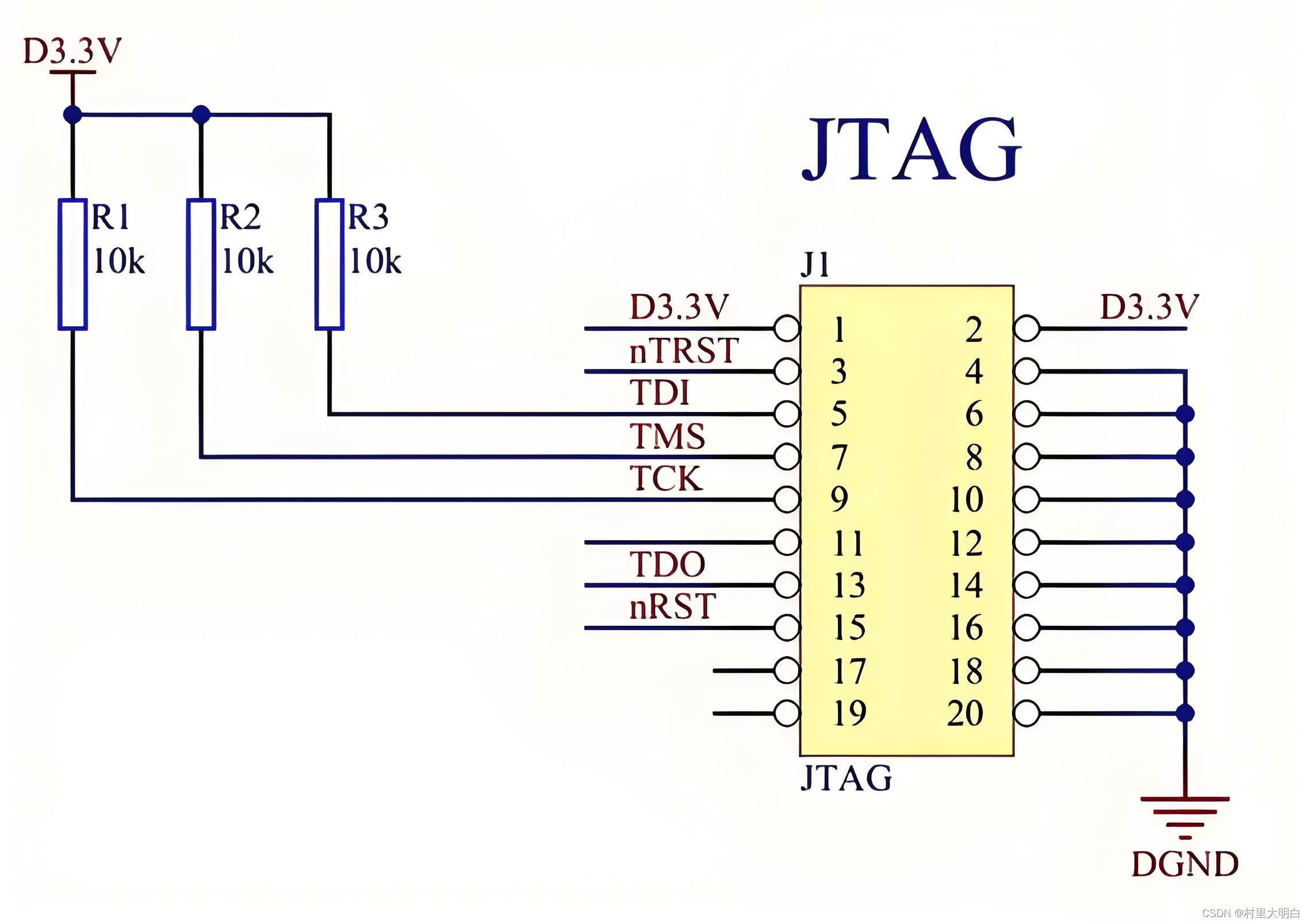
图4.2-1 JTAG调试接口电路
4.2.2 SWD接口
图4.2-2所示为SWD接口。在高速模式和数据量大的情况下,通过JTAG下载程序会失败,但是通过SWD下载出现失败的概率会小很多,更加可靠。SWD模式支持更少的引脚接线,所以需要的PCB空间更小,在芯片体积有限的时候推荐使用SWD模式。SWD模式的连接需要2根线,其中SWDIO为双向数据口,用于主机到目标的数据传送;SWDCLK为时钟口,用于主机驱动。
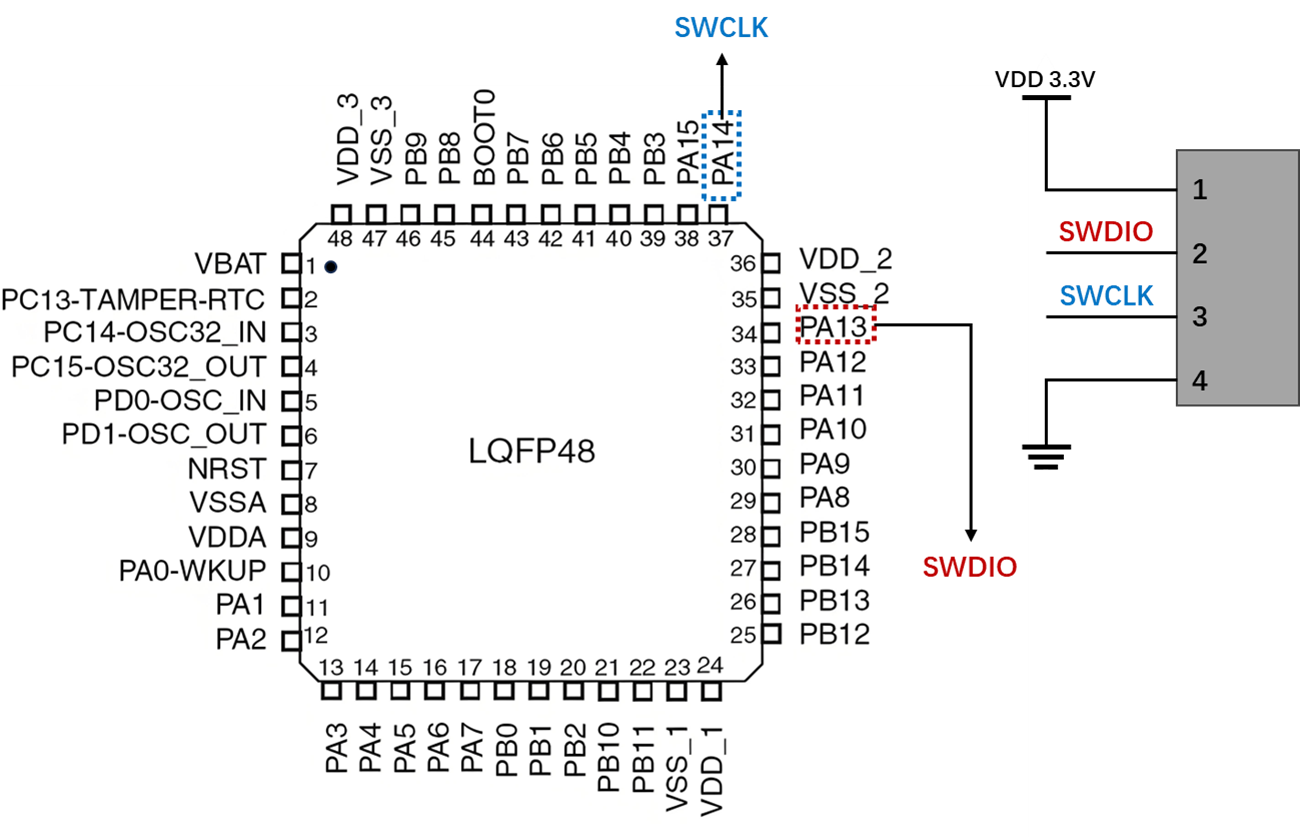
图4.2-2 SWD接口
STM32系列处理器支持两种调试方式,但是采用JTAG占用了大量的PCB的面积,而采用SWD模式则占用得少得多。而且在调试速度等方面,SWD并不比JTAG模式差,所以建议在实际应用中尽量采用SWD进行设计。SWD不是采用标准端口,可以根据自己的需要排列引脚。
4.3. 启动模式
该处很多知识引用自正点原子的开发板资料,这块知识正点原子的资料讲的很透彻。
STM32单片机的程序计数器寄存器的默认值决定了处理器从哪个具体地址去获得第1条需要执行的指令。但是对于处理器来说,无论它挂接的是闪存、内存,还是硬盘,它在启动时是“一无所知”的,我们需要通过硬件设计来告诉它存储第一条指令的外设。STM32系列处理器的第一条执行指令地址是通过硬件设计来实现的。
表4.3-1 启动模式选择

如图表4.3-1,在STM32F10x里,可以通过配置BOOT[1:0]引脚选择3种不同的启动模式。系统复位后,在系统时钟的第4个上升沿到来时,BOOT引脚的值将被锁存,然后被CPU读取。这意味着一旦BOOT引脚的值被确定并锁存,后续改变这些引脚的状态将不会影响已经选择的启动模式。用户可以通过设置BOOT1和BOOTO引脚的状态,来选择在复位后的启动模式。
复位方式有三种:上电复位,硬件复位和软件复位。当产生复位并且离开复位状态后,Cortex-M3 内核做的第一件事就是读取下列两个 32 位整数的值:
(1)从地址 0x0000 0000 处取出堆栈指针 MSP 的初始值,该值就是栈顶地址。
(2)从地址 0x0000 0004 处取出程序计数器指针 PC 的初始值,该值指向复位后执行的
第一条指令。下面用示意图表示,如图4.3-1 所示。
注: 概念解释:MSP
在嵌入式系统或低级编程中,MSP 通常指的是“Main Stack Pointer”,即主堆栈指针。堆栈是一个后进先出(LIFO)的数据结构,用于存储局部变量、返回地址和其他临时数据。MSP 指向堆栈的顶部,是堆栈操作(如入栈和出栈)的关键。
在许多微控制器和处理器中,可能会有多个堆栈,例如主堆栈和进程堆栈,用于不同的任务或线程。MSP 通常与主任务或主线程相关。
与 MSP 相对的是 PSP(Process Stack Pointer),它是进程堆栈指针,用于特定的线程或任务。了解 MSP 和其他相关概念对于理解和编写低级代码,如中断处理程序或操作系统内核代码,是非常重要的。这些概念也与实时操作系统(RTOS)和并发编程密切相关。
简而言之,MSP 是指向主堆栈顶部的指针,用于追踪和管理主线程或任务的堆栈操作
概念解释:程序计数器-PC
PC代表程序计数器(Program Counter)。它是一个16位专用寄存器,用于存放下一条将要执行的指令地址。当执行一条指令时,首先需要根据PC中存放的指令地址,将指令取出送到指令寄存器中,此过程称为“取指令”。与此同时,PC中的地址会自动加1,以便指向下一条将要执行的指令。这样,CPU就可以依次执行每一条指令,保证程序的顺序执行。因此,程序计数器PC是保证程序顺序执行的重要特殊功能寄存器。

图.4.3-1 复位序列
上述过程中,内核是从 0x0000 0000 和 0x0000 0004 两个的地址获取堆栈指针 SP 和程序计
数器指针 PC。事实上,0x0000 0000 和 0x0000 0004 两个的地址可以被重映射到其他的地址空
间。例如:我们将 0x0800 0000 映射到 0x0000 0000,即从内部 FLASH 启动,那么内核会从地
址 0x0800 0000 处取出堆栈指针 MSP 的初始值,从地址 0x0800 0004 处取出程序计数器指针
PC 的初始值。CPU 会从 PC 寄存器指向的地址空间取出的第 1 条指令开始执行程序,就是开始
执行复位中断服务程序 Reset_Handler。将 0x0000 0000 和 0x0000 0004 两个地址重映射到其他的地址空间,就是启动模式选择。
对于 STM32F1 的启动模式,表3-1转为对应地址模式,如图4.3-2.
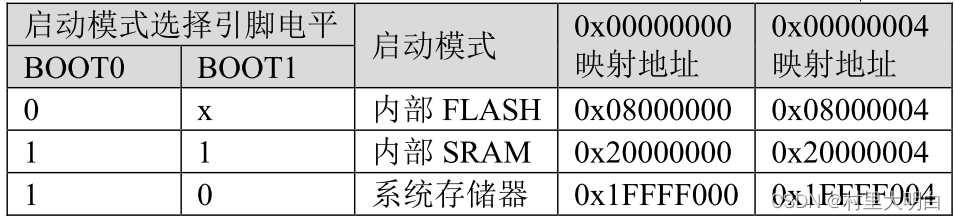
图4.3-2 STM32启动模式表对应地址
由图4.3-2 可以看到,STM32F1 根据 BOOT 引脚的电平选择启动模式,这两个 BOOT 引脚
根据外部施加的电平来决定芯片的启动地址。
从主闪存FALSH启动:
- 这是STM32F1系列的正常工作模式。
- 当BOOT0=0,BOOT1=x时(其中x可以是0或1,通常推荐BOOT1也设置为0以确保一致性),单片机将从用户闪存(即内部的Flash存储器)启动。
- 用户闪存中通常存储了程序代码和数据,单片机在启动时将从这里读取并执行程序。
从系统存储器启动:
- 这种启动模式主要用于从STM32内部固化的Bootloader程序启动。
- 当BOOT0=1,BOOT1=0时,单片机将从系统存储器启动。
- 系统存储器中包含了一个内置的Bootloader程序,可以用于从串口接收新的程序代码并烧写到用户闪存中,实现程序的远程升级
从内置SRAM启动:
- 这种启动模式通常用于调试目的或特殊应用。
- 当BOOT0=1,BOOT1=1时,单片机将从内部的SRAM(静态随机存取存储器)启动。
- SRAM通常用作程序的临时运行空间,其内容在掉电后会丢失。从SRAM启动通常用于测试或特殊的应用程序,其中程序可能需要在不写入Flash的情况下运行。
第5章.STM32F1x的寄存器和存储器
5.1. 寄存器的概念
寄存器(Register)是单片机内部一种特殊的内存,它可以实现对单片机各个功能的控制,简单的来说可以把寄存器当成一些控制开关,控制包括内核及外设的各种状态。无论是 51单片机还是 STM32单片机,都需要用寄存器来实现各种控制,以完成不同的功能。寄存器是连接软件和硬件的桥梁。
寄存器资源非常宝贵,一般都是一个位或者几个位控制一个功能,对于 STM32 来说,其寄存器是 32 位的,一个 32 位的寄存器,可能会有 32 个控制功能,相当于 32 个开关,由于STM32的复杂性,它内部有几百个寄存器,所以整体来说 STM32 的寄存器还是比较复杂的。 STM32 是由于内部有很多外设,所以导致寄存器很多,实际上我们把它分好类,每个外设也就那么几个或者几十个寄存器。
寄存器可以分为两类,内核寄存器和外设寄存器。如图5.1-1.
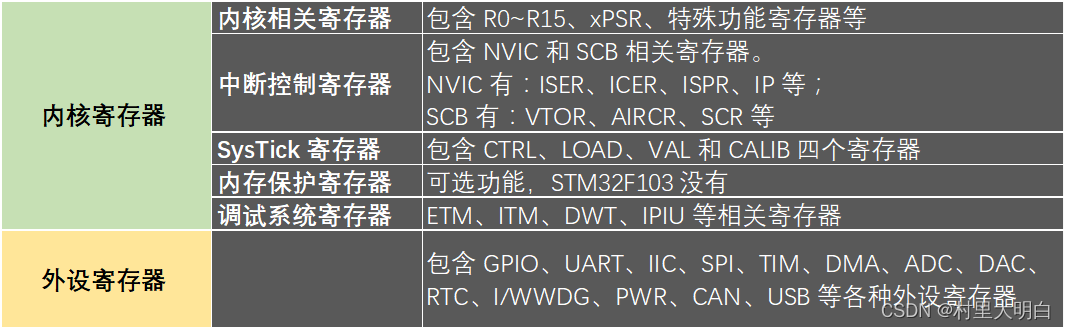
图5.1-1 STM32寄存器分类
其中,内核寄存器,我们一般只需要关心中断控制寄存器和 SysTick 寄存器即可,其他三大类,我们一般很少直接接触。而外设寄存器,则是学到哪个外设,就了解哪个外设相关寄存器即可,所以整体来说,我们需要关心的寄存器并不是很多,而且很多都是有共性的,我们只需要学习了其中一个的相关寄存器,其他个基本都是一样。
给大家举个简单的例子,我们知道寄存器的本质是一个特殊的内存,对于STM32 来说,以 GPIOB 的 ODR 寄存器为例,其寄存器地址为:0X40010C0C,所以我们对其赋值可以写成:
(*(unsigned int *))(0X40010C0C) = 0XFFFF;这样我们就完成了对 GPIOB->ODR 寄存器的赋值,0XFFFF表示GPIOB所有I/O口(16个I/O口)都输出高电平,0X40010C0C 就是一个寄存器的特殊地址。
5.2. 存储器映射
STM32是一个32位单片机,他可以访问(2^32 = 4GB)4GB以内的存储空间。在前面章节介绍过STM32F10xx 系统框图,如下图5.2-1.被控单元有FLASH,RAM,FSMC 和AHB 到APB 的桥(即片上外设),这些功能部件共同排列在一个4GB 的地址空间内。我们可以通过C语言来访问这些地址空间,从而操作相关外设(读/写)。数据字节以小端格式(小端模式)存放在存储器中,数据的高字节保存在内存的高地址中,而数据的低字节保存在内存的低地址中。
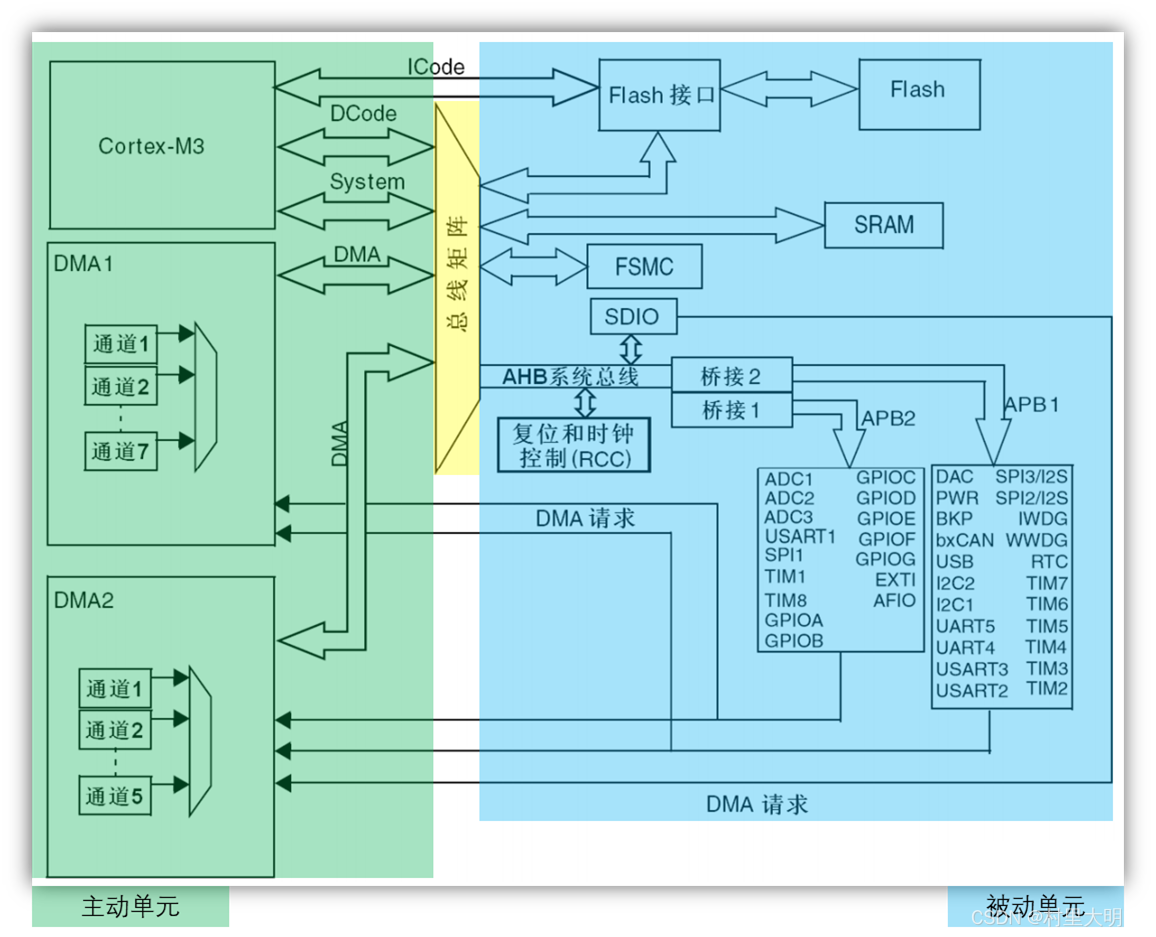
图5.2-1-STM32F1系列系统结构图
存储器本身是没有地址信息的,我们对存储器分配地址的过程就叫存储器映射。这个分配一般由芯片厂商做好了,ST将所有的存储器及外设资源都映射在一个4GB的地址空间上(8个块),从而可以通过访问对应的地址,访问具体的外设。其映射关系如图5.2-2所示:
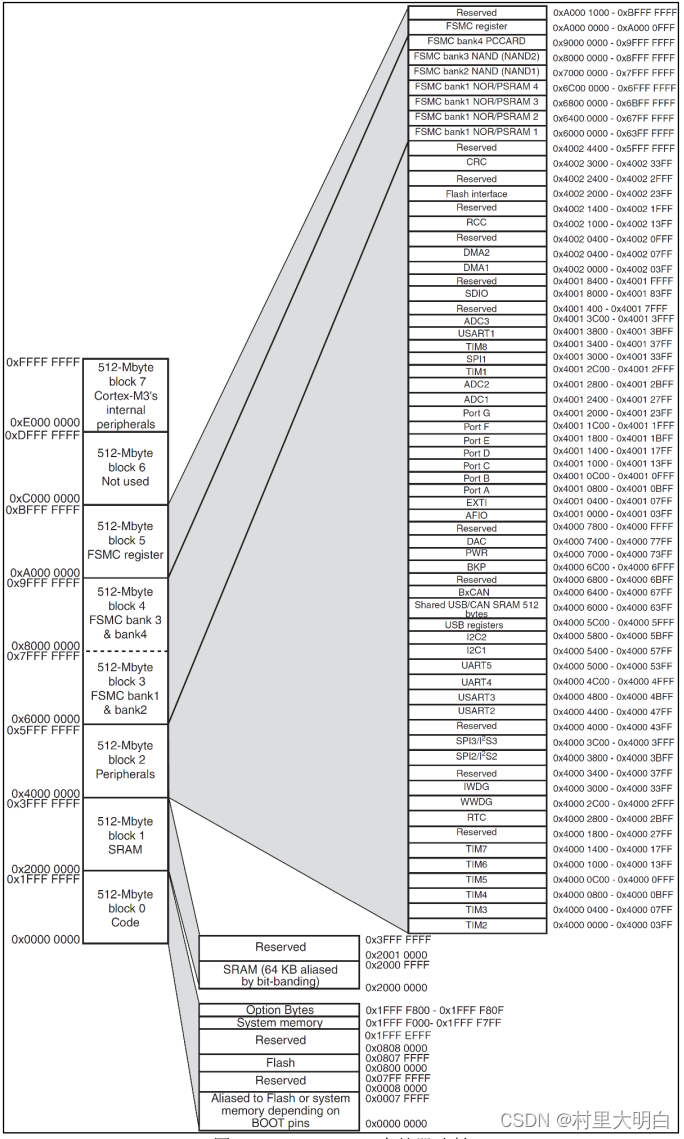
图5.2-2 STM32存储器映射图
如果给存储器再分配一个地址就叫存储器重映射。
存储器重映射是将已经映射过的存储器再次映射的过程。它可以使同一物理存储单元映射多个不同的逻辑地址。在这个过程中,存储单元会被再分配一个地址,这样存储单元就有了两个地址,用户可以通过这两个地址来访问该存储单元。存储器重映射的目的是为了快速响应中断或者快速完成某个任务,可以将同一地址段映射到不同速度的两个存储块,然后将低速存储块中的代码段复制到高速存储块中,对低速存储块的访问将被重映射为对高速存储块的访问。这种技术通过改变中断向量映射关系,使得系统能够更高效地处理数据和任务。
存储器本身不具有地址信息,其地址是由芯片厂商或用户分配的,给存储器分配地址的过程就称为存储器映射。对于具体的某款嵌入式芯片,它包含的各种存储器的大小、地址分布都是确定的。存储器映射是对各种存储器的大小和地址分布的规划,而存储器重映射则是在此基础上进行的进一步操作。
存储器重映射是一种优化系统性能的技术手段,通过对存储器的重新映射,可以提高系统的响应速度和任务处理效率。
5.2.1 存储器区域功能划分
ST将4GB空间分成8个块,每个块512MB,如下图5.2-3所示,从图中我们可以看出有很多保留区域(Reserved),这是因为一般的芯片制造厂家是不可能把4GB空间用完的,同时,为了方便后续型号升级,会将一些空间预留(Reserved)。
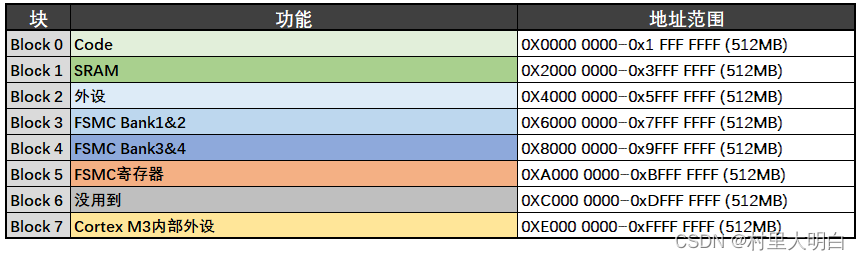
图5.2-3 STM32 存储块功能及地址范围
在这8 个Block 里面,有3 个块非常重要,也是我们最关心的三个块。Block0 用来设计成内部FLASH,Block1 用来设计成内部RAM,Block2 用来设计成片上的外设,下面我们简单的介绍下这三个Block 里面的具体区域的功能划分。
5.2.2 存储器Block0 内部区域功能划分

图5.2-4 存储块0的功能划分
Block 0,用于存储代码,即FLASH空间,其功能划分如上图5.2-4所示。图示用户FLASH大小是512KB,这是属于大容量的STM32F103x,如STM32F103ZET6,其他型号,如32F103C8T6则远没有这么多。理论上ST也可以推出更大容量的STM32F103单片机,因为这里保留了一大块地址空间。STM32的出厂固化BootLoader非常精简,整个BootLoder只占了2KB FLASH空间。
BootLoader:嵌入式系统的BootLoader,也称为引导加载程序,是嵌入式系统在加电后执行的第一段代码。它负责在系统启动时初始化硬件设备,并将操作系统映像或固化的嵌入式应用程序装载到内存中,然后跳转到操作系统所在的空间,启动操作系统运行。BootLoader的主要功能包括初始化处理器和周边电路、建立内存空间映射图、加载操作系统映像或用户应用程序等,为最终调用操作系统内核或执行用户应用程序准备好正确的环境。
在嵌入式系统中,BootLoader的代码通常是由开发人员编写,并针对特定的硬件平台进行优化。它通常存储在系统的非易失性存储器中,如闪存或EEPROM,以确保在系统上电后能够被访问和执行。
总之,嵌入式系统的BootLoader是确保系统能够正常启动和运行的关键组件,它负责初始化硬件、加载操作系统或应用程序,并为系统的正常运行提供必要的环境。
5.2.3 储存器Block1 内部区域功能划分

图5.2-5 STM32 存储块1的功能划分
Block 1,用于存储数据,即SRAM空间,其功能划分如图5.2-5所示 ,图示为大容量产品,也仅用了64KB( 如STM32F103ZET6,STM32F103C8T6则只有20KB),用于SRAM访问,同时也有大量保留地址用于扩展。
5.2.4 储存器Block2 内部区域功能划分
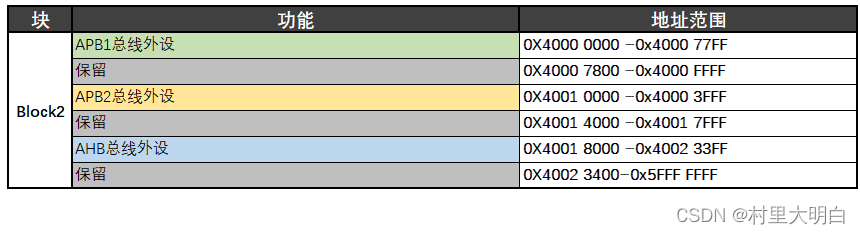
图5.2-6 STM32 存储块2的功能划分
Block 2,用于外设访问,STM32内部大部分的外设都是放在这个块里面的,该存储块里面包括了AHB、APB1和APB2三个总线相关的外设,其中AHB和APB2是高速总线(72MHZ),APB1是低速总线(36MHZ)。其功能划分如图5.2-6所示. 同样可以看到,各个总线之间,都有预留地址空间,方便后续扩展。关于STM32各个外设具体挂在哪个总线上面,大家可以参考前面的 STM32F103系统结构图和STM32F103存储器映射图进行查找对应。
5.3.寄存器映射
给存储器分配地址的过程叫存储器映射,寄存器是一类特殊的存储器,它的每个位都有特定的功能,可以实现对外设/功能的控制,给寄存器的地址命名的过程就叫寄存器映射。
举例说明,我们的纸质笔记本就好比通用存储器,用来记录数据是完全没问题的,但是不会有具体的动作,只能做记录使用。而我们家中的电闸开关,就好比寄存器了,如下图家中电闸箱有8个熔断器控制着8处用电设备(相当于一个8位寄存器),这些熔断器开关也可以记录状态,同时还能让对应用电器开/关,是会产生具体动作的。同时我们也可以通过读取这些熔断器的状态了解一些用电器是否存在问题,比如某些熔断器一直处于断开的状态,可能是对应的用电器存在短路等问题。为了方便区分和使用,我们会给每个开关命名,如厨房开关、大厅开关、卧室开关等,给开关命名的过程,就是寄存器映射。

图5.3-1 寄存器作用举例(家中电闸开关)
STM32内部的寄存器有非常多,远远不止8个开关这么简单,但是原理是差不多的,每个寄存器的每一个位,一般都有特定的作用,涉及到寄存器描述,可以参考《STM32F10x参考手册》对应章节的寄存器描述部分,有详细的描述。
在存储器Block2 这块区域,设计的是片上外设,它们以四个字节为一个单元,共32bit,每一个单元对应不同的功能,当我们控制这些单元时就可以驱动外设工作。我们可以找到每个单元的起
始地址,然后通过C 语言指针的操作方式来访问这些单元,如果每次都是通过这种地址的方式来访问,不仅不好记忆还容易出错,这时我们可以根据每个单元功能的不同,以功能为名给这个内存单元取一个别名,这个别名就是我们经常说的寄存器,这个给已经分配好地址的有特定功能的内存单元取别名的过程就叫寄存器映射。
比如,我们找到GPIOB端口的输出数据寄存器ODR 的地址是0x40010C0C(这个地址如何找到的后面我们会讲),ODR 寄存器是32bit,低16bit 有效,对应着16 个外部IO,写0/1 对应的IO 则输出低/高电平。现在我们通过C 语言指针的操作方式,让GPIOB的16 个IO 都输出高电平:
// GPIOB 端口全部输出 高电平
*(unsigned int*)(0x40010C0C) = 0xFFFF;0x40010C0C 在我们看来是GPIOB 端口ODR 的地址,但是在编译器看来,这只是一个普通的变量,是一个立即数,要想让编译器也认为是指针,我们得进行强制类型转换,把它转换成指针,即(unsigned int *)0x4001 0C0C,然后再对这个指针进行* 操作。
通过绝对地址访问内存单元不好记忆且容易出错,我们可以通过寄存器别名的方式来操作,见代码如下代码: (其中GPIOB_BASE 指的是GPIOB 端口的基地址,稍后会讲)。
// GPIOB 端口全部输出 高电平
#define GPIOB_ODR (unsigned int *)(GPIOB_BASE+0x0C)
* GPIOB_ODR = 0xFF;为了方便操作,我们直接把指针操作“*”也定义到寄存器别名里面,具体见如下代码:
//GPIOB 端口全部输出 高电平
#define GPIOB_ODR *(unsigned int *)(GPIOB_BASE+0x0C)
GPIOB_ODR = 0xFF;5.3.1 STM32 的外设地址映射
5.3.1.1 寄存器地址计算
具体某个寄存器地址,由三个参数决定:
1、总线基地址(BUS_BASE_ADDR);
2,外设基于总线基地址的偏移量(PERIPH_OFFSET);
3,寄存器相对外设基地址的偏移量(REG_OFFSET)。
可以表示为:
寄存器地址 = BUS_BASE_ADDR + PERIPH_OFFSET + REG_OFFSET
5.3.1.2 总线基地址
片上外设区分为三条总线,根据外设速度的不同,不同总线挂载着不同的外设,APB1 挂载低速外设,APB2 和AHB 挂载高速外设。
相应总线的最低地址我们称为该总线的基地址(BUS_BASE_ADDR),总线基地址也是挂载在该总线上的首个外设的地址。其中APB1 总线的地址最低,片上外设从这里开始,也叫外设基地址。 如前面图5.2-6所示,提取见下图。
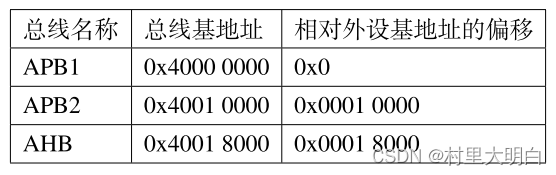
图5.3-2 外设总线基地址
“相对外设基地址偏移”即该总线地址与“片上外设”基地址0x4000 0000 的差值。
5.3.1.3 外设基地址
总线上挂载着各种外设,这些外设也有自己的地址范围,特定外设的首个地址称为“XX 外设基地址”,也叫XX 外设的边界地址。具体有关STM32F10xx 外设的边界地址请参考《STM32F10xx
参考手册》的存储器映射图。
这里面我们以GPIO 这个外设来讲解外设的基地址,GPIO 属于高速的外设,挂载到APB2 总线上,具体见图5.3-3。最后一列就是外设基于总线基地址的偏移量(PERIPH_OFFSET)。

图5.3-3 GPIO外设基地址
5.3.1.4 外设寄存器
在XX 外设的地址范围内,分布着的就是该外设的寄存器。以GPIO 外设为例,GPIO 是通用输入输出端口的简称,简单来说就是STM32 可控制的引脚,基本功能是控制引脚输出高电平或者低电平。最简单的应用就是把GPIO 的引脚连接到LED 灯的阴极,LED 灯的阳极接电源,然后通
过STM32 控制该引脚的电平,从而实现控制LED 灯的亮灭。
GPIO 有很多个寄存器,每一个都有特定的功能。每个寄存器为32bit,占四个字节,在该外设的基地址上按照顺序排列,寄存器的位置都以相对该外设基地址的偏移地址来描述。这里我们以
GPIOB 端口为例,来说明GPIO 都有哪些寄存器,具体见图5.3-4。图中的偏移量,就是寄存器基于外设基地址的偏移量(REG_OFFSET)。
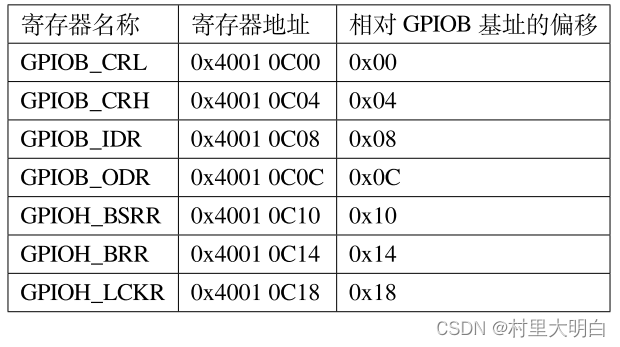
图5.3-4 GPIOB 端口的寄存器地址列表
5.3.2 寄存器描述解读
这里以“GPIO 端口置位/复位寄存器”为例,教大家如何理解寄存器的说明,具体见图5.3-5.
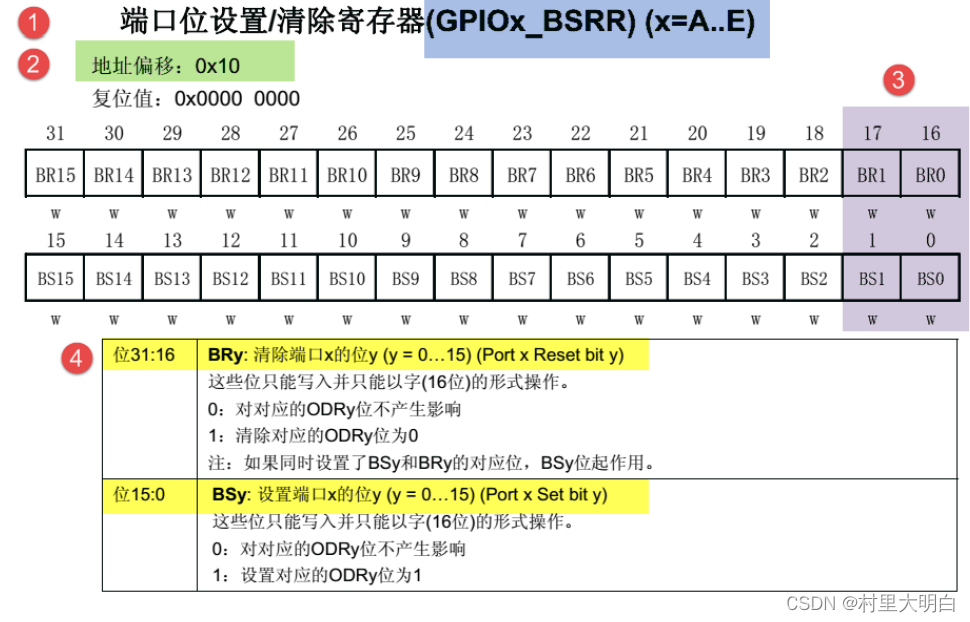
图5.3-5 GPIO 端口置位/复位寄存器说明
① 寄存器名称
寄存器说明中首先列出了该寄存器中的名称,“(GPIOx_BSRR)(x=A⋯E)”这段的意思是该寄存器名为“GPIOx_BSRR”其中的“x”可以为A-E,也就是说这个寄存器说明适用于GPIOA、GPIOB至GPIOE,这些GPIO 端口都有这样的一个寄存器,一些低端的芯片可能没有这么多端口,一些高端的芯片也可能比这些端口要多,但意思都是一样的。
② 偏移地址
偏移地址是指本寄存器相对于这个外设的基地址的偏移。本寄存器的偏移地址是0x10,从参
考手册中我们可以查到GPIOA 外设的基地址为0x4001 0800 ,我们就可以算出GPIOA 的这个GPIOA_BSRR 寄存器的地址为:0x4001 0800+0x10 ;同理,由于GPIOB 的外设基地址为x4001
0C00,可算出GPIOB_BSRR 寄存器的地址为:0x4001 0C00+0x10 。其他GPIO 端口以此类推即
可。
③ 寄存器位表
紧接着的是本寄存器的位表,表中列出它的0-31 位的名称及权限。表上方的数字为位编号,中间为位名称,最下方为读写权限,其中w 表示只写,r 表示只读,rw 表示可读写。本寄存器中的
位权限都是w,所以只能写,如果读本寄存器,是无法保证读取到它真正内容的。而有的寄存器位只读,一般是用于表示STM32 外设的某种工作状态的,由STM32 硬件自动更改,程序通过读取那些寄存器位来判断外设的工作状态。
④ 位功能说明
位功能是寄存器说明中最重要的部分,它详细介绍了寄存器每一个位的功能。例如本寄存器中有两种寄存器位,分别为BRy 及BSy,其中的y 数值可以是0-15,这里的0-15 表示端口的引脚号,如BR0、BS0 用于控制GPIOx 的第0 个引脚,若x 表示GPIOA,那就是控制GPIOA 的第0 引脚,而BR1、BS1 就是控制GPIOA 第1 个引脚。
其中BRy 引脚的说明是“0:不会对相应的ODRy 位执行任何操作;1:对相应ODRy 位进行复
位”。这里的“复位”是将该位设置为0 的意思,而“置位”表示将该位设置为1;说明中的ODRy是另一个寄存器的寄存器位,我们只需要知道ODRy 位为1 的时候,对应的引脚y 输出高电平,为0 的时候对应的引脚输出低电平即可。所以,如果对BR0 写入“1”的话,那么GPIOx 的第0 个引脚就会输出“低电平”,但是对BR0 写入“0”的话,却不会影响ODR0 位,所以引脚电平不会改变。要想该引脚输出“高电平”,就需要对“BS0”位写入“1”,寄存器位BSy 与BRy 是相反的操作。
5.3.3 STM32库函数的寄存器映射实现
STM32F103所有寄存器映射都在stm32f103xe.h里面完成,包括各种基地址定义、结构体定义、外设寄存器映射、寄存器位定义等,整个文件有1W多行,非常庞大。我们没有必要对该文件进行全面分析,因为很多内容都是相似的,我们只需要知道寄存器是如何被映射的,就可以了。以上所有的关于存储器映射的内容,最终都是为大家更好地理解STM32库函数如何用C 语言控制读写外设寄存器做准备。下面是实现过程:
5.3.3.1 封装总线和外设基地址
在编程上为了方便理解和记忆,我们把总线基地址和外设基地址都以相应的宏定义起来,总线或者外设都以他们的名字作为宏名,具体见如下代码:
/* 外设基地址 */
#define PERIPH_BASE ((unsigned int)0x40000000)
/* 总线基地址 */
#define APB1PERIPH_BASE PERIPH_BASE
#define APB2PERIPH_BASE (PERIPH_BASE + 0x00010000)
#define AHBPERIPH_BASE (PERIPH_BASE + 0x00020000)
/* GPIO 外设基地址 */
#define GPIOA_BASE (APB2PERIPH_BASE + 0x0800)
#define GPIOB_BASE (APB2PERIPH_BASE + 0x0C00)
#define GPIOC_BASE (APB2PERIPH_BASE + 0x1000)
#define GPIOD_BASE (APB2PERIPH_BASE + 0x1400)
#define GPIOE_BASE (APB2PERIPH_BASE + 0x1800)
#define GPIOF_BASE (APB2PERIPH_BASE + 0x1C00)
#define GPIOG_BASE (APB2PERIPH_BASE + 0x2000)
/* 寄存器基地址,以 GPIOB 为例 */
#define GPIOB_CRL (GPIOB_BASE+0x00)
#define GPIOB_CRH (GPIOB_BASE+0x04)
#define GPIOB_IDR (GPIOB_BASE+0x08)
#define GPIOB_ODR (GPIOB_BASE+0x0C)
#define GPIOB_BSRR (GPIOB_BASE+0x10)
#define GPIOB_BRR (GPIOB_BASE+0x14)
#define GPIOB_LCKR (GPIOB_BASE+0x18)上述代码首先定义了“片上外设”基地址PERIPH_BASE,接着在PERIPH_BASE 上加入各个总线的地址偏移,得到APB1、APB2 总线的地址APB1PERIPH_BASE、APB2PERIPH_BASE,在其之上加入外设地址的偏移,得到GPIOA-G 的外设地址,最后在外设地址上加入各寄存器的地址偏移,得到特定寄存器的地址。一旦有了具体地址,就可以用指针读写,具体见代码:
/* 控制 GPIOB 引脚 0 输出低电平 (BSRR 寄存器的 BR0 置 1) */
*(unsigned int *)GPIOB_BSRR = 0x01<<16;
/* 控制 GPIOB 引脚 0 输出高电平 (BSRR 寄存器的 BS0 置 1) */
*(unsigned int *)GPIOB_BSRR = 0x01<<0;
unsigned int temp;
/* 读取 GPIOB 端口所有引脚的电平 (读 IDR 寄存器) */
temp = *(unsigned int *)GPIOB_IDR; 该代码使用(unsigned int *) 把GPIOB_BSRR 宏的数值强制转换成了地址,然后再用“*”号做取
指针操作,对该地址的赋值,从而实现了写寄存器的功能。同样,读寄存器也是用取指针操作,把寄存器中的数据取到变量里,从而获取STM32 外设的状态。
5.3.3.2 封装寄存器列表
用上面的方法去定义地址,还是稍显繁琐,例如GPIOA-GPIOE 都各有一组功能相同的寄存器,如GPIOA_ODR/GPIOB_ODR/GPIOC_ODR 等等,它们只是地址不一样,但却要为每个寄存器都定义它的地址。为了更方便地访问寄存器,我们引入C 语言中的结构体语法对寄存器进行封装,如下代码所示:
typedef unsigned int uint32_t; /* 无符号 32 位变量 */
typedef unsigned short int uint16_t; /* 无符号 16 位变量 */
/* GPIO 寄存器列表 */
typedef struct {
uint32_t CRL; /*GPIO 端口配置低寄存器 地址偏移: 0x00 */
uint32_t CRH; /*GPIO 端口配置高寄存器 地址偏移: 0x04 */
uint32_t IDR; /*GPIO 数据输入寄存器 地址偏移: 0x08 */
uint32_t ODR; /*GPIO 数据输出寄存器 地址偏移: 0x0C */
uint32_t BSRR; /*GPIO 位设置/清除寄存器 地址偏移: 0x10 */
uint32_t BRR; /*GPIO 端口位清除寄存器 地址偏移: 0x14 */
uint16_t LCKR; /*GPIO 端口配置锁定寄存器 地址偏移: 0x18 */
} GPIO_TypeDef;这段代码用typedef 关键字声明了名为GPIO_TypeDef 的结构体类型,结构体内有7个成员变量,变量名正好对应寄存器的名字。C 语言的语法规定,结构体内变量的存储空间是连续的,其中32位的变量占用4 个字节,16 位的变量占用2 个字节,具体见图5.3-6.GPIO_TypeDef 结构体成员的地址偏移。
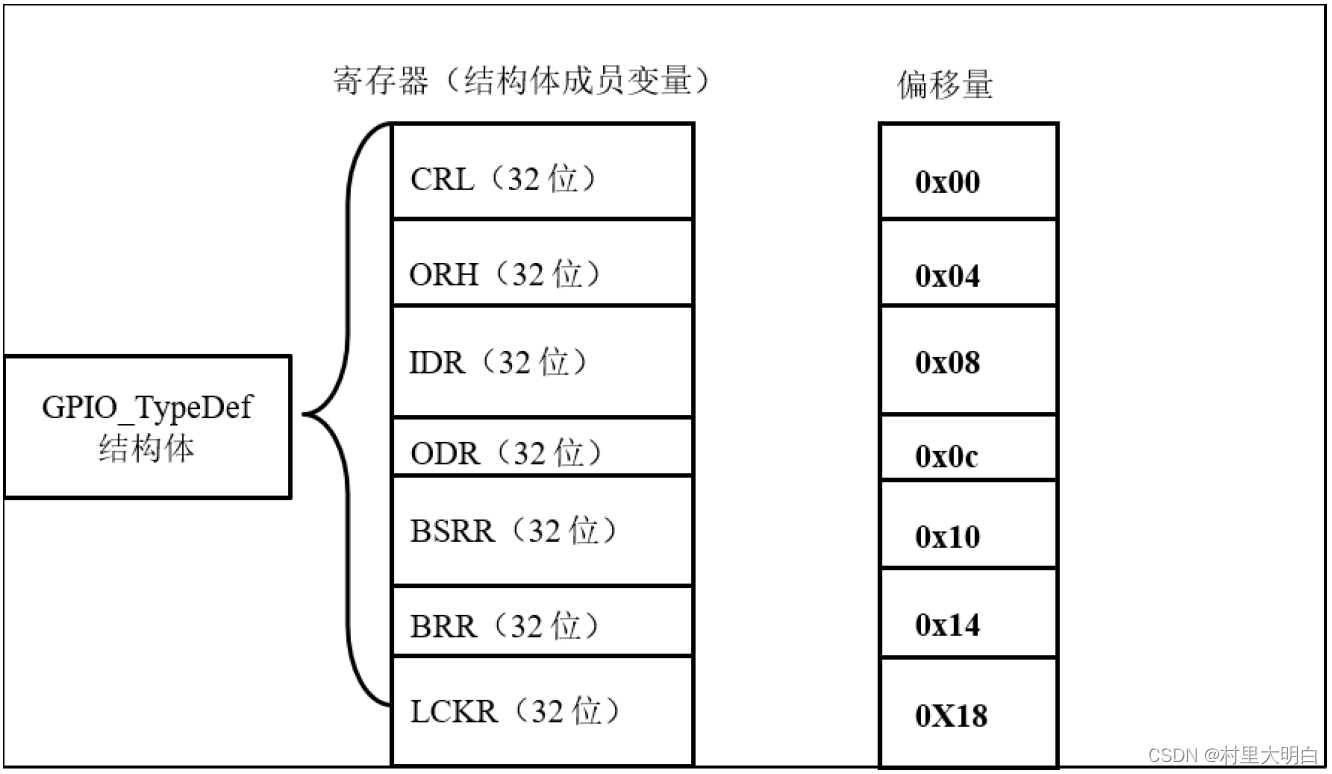
5.3-6.GPIO_TypeDef 结构体成员的地址偏移
也就是说,我们定义的这个GPIO_TypeDef ,假如这个结构体的首地址为0x4001 0C00(这也是第一个成员变量CRL 的地址),那么结构体中第二个成员变量CRH 的地址即为0x4001 0C00 +0x04,加上的这个0x04,正是代表CRL 所占用的4 个字节地址的偏移量,其它成员变量相对于结构体首地址的偏移,在上述代码右侧注释已注明。
这样的地址偏移与STM32 GPIO 外设定义的寄存器地址偏移一一对应,只要给结构体设置好首地址,就能把结构体内成员的地址确定下来,然后就能以结构体的形式访问寄存器,具体见代码如下:
GPIO_TypeDef * GPIOx; //定义一个 GPIO_TypeDef 型结构体指针 GPIOx
GPIOx = GPIOB_BASE; //把指针地址设置为宏 GPIOB_BASE 地址
GPIOx->IDR = 0xFFFF;
GPIOx->ODR = 0xFFFF;
uint32_t temp;
temp = GPIOx->IDR; //读取 GPIOB_IDR 寄存器的值到变量 temp 中 这段代码先用 GPIO_TypeDef 类型定义一个结构体指针 GPIOx,并让指针指向地址GPIOB_BASE(0x4001 0C00),地址确定下来,然后根据C 语言访问结构体的语法,用GPIOx->ODR 及GPIOx->IDR 等方式读写寄存器。
最后,我们更进一步,直接使用宏定义好GPIO_TypeDef 类型的指针,而且指针指向各个GPIO端口的首地址,使用时我们直接用该宏访问寄存器即可,具体代码:
/* 使用 GPIO_TypeDef 把地址强制转换成指针 */
#define GPIOA ((GPIO_TypeDef *) GPIOA_BASE)
#define GPIOB ((GPIO_TypeDef *) GPIOB_BASE)
#define GPIOC ((GPIO_TypeDef *) GPIOC_BASE)
#define GPIOD ((GPIO_TypeDef *) GPIOD_BASE)
#define GPIOE ((GPIO_TypeDef *) GPIOE_BASE)
#define GPIOF ((GPIO_TypeDef *) GPIOF_BASE)
#define GPIOG ((GPIO_TypeDef *) GPIOG_BASE)
#define GPIOH ((GPIO_TypeDef *) GPIOH_BASE)
/* 使用定义好的宏直接访问 */
/* 访问 GPIOB 端口的寄存器 */
GPIOB->BSRR = 0xFFFF; //通过指针访问并修改 GPIOB_BSRR 寄存器
GPIOB->CRL = 0xFFFF; //修改 GPIOB_CRL 寄存器
GPIOB->ODR =0xFFFF; //修改 GPIOB_ODR 寄存器
uint32_t temp;
temp = GPIOB->IDR; //读取 GPIOB_IDR 寄存器的值到变量 temp 中
/* 访问 GPIOA 端口的寄存器 */
GPIOA->BSRR = 0xFFFF;
GPIOA->CRL = 0xFFFF;
GPIOA->ODR =0xFFFF;
uint32_t temp;
temp = GPIOA->IDR; //读取 GPIOA_IDR 寄存器的值到变量 temp 中 这里我们仅是以GPIO 这个外设为例,给大家讲解了C 语言对寄存器的封装。以此类推,其他外设也同样可以用这种方法来封装。好消息是,这部分工作都由固件库帮我们完成了,这里我们只
是分析了下这个封装的过程,让大家知其然,也知道其所以然。
第6章.STM32开发环境介绍
6.1.STM32的常用开发环境
STM32开发常见的开发环境如图6.1-1所示,按照普及率进行了排名,用的最多的就是Keil公司的MDK,下面分别进行介绍。
图6.1-1 STM32的常用开发环境
6.1.1 MDK
图6.1-2 MDK软件
STM32的开发环境MDK(也称为MDK-ARM Version 5或MDK-ARM)是由德国Keil公司(现已并入ARM公司)开发的一款针对ARM Cortex-M系列微控制器的完整软件开发环境。界面美观,简单易用,是 STM32 最常用的集成开发环境。它为嵌入式软件开发者提供了从项目创建、代码编写、编译链接、仿真调试到最终程序烧录的一整套解决方案。在ST(意法半导体)开发环境中,MDK常被用于各种基于ARM Cortex-M内核的MCU(微控制器)的程序开发。
MDK与Keil的关系在于,MDK是Keil公司的一个集成开发环境(IDE),专门针对ARM公司的微控制器进行软件开发。Keil公司开发的基于μVision IDE,支持绝大部分8051内核的微控制器开发工具。而MDK-ARM则是ARM公司目前最新推出的针对各种嵌入式处理器的软件开发工具,它集成了业内最领先的技术,包括μVision集成开发环境与RealView编译器。
在开发过程中,使用MDK可以方便地进行项目创建、代码编写、编译链接和仿真调试等操作。MDK的设备数据库中有很多厂商的芯片,是专为微控制器开发的工具,支持ARM7、ARM9、Cortex-M4/M3/M1、Cortex-R0/R3/R4等ARM微控制器内核。这使得STM32的开发者能够轻松地进行嵌入式软件的开发和调试。
6.1.2 STM32CubeIDE

图6.1-3 STM32CubeIDE
STM32CubeIDE是ST于2019年新推出的一款多功能的集成开发工具,它集成了TrueSTUDIO和STM32CubeMX插件,并基于GDB进行调试,它允许集成数百个现有插件,这些插件完成Eclipse的功能。
TrueSTUDIO插件是一款建立在EclipseCDT、GCC和GDB的C/C++集成开发工具,其具有项目创建和管理、代码编辑、代码编译以及代码在线调试等功能。
STM32CubeMX插件具有图形化配置功能,可以直观地选择MCU/MPU型号、动态配置引脚和设置时钟树、动态设置外围设备和中间器件的模式,可以自动处理引脚冲突和生成初始化代码。
TrueSTUDIO和STM32CubeMX的强强联手,使STM32CubeIDE得以和MDK进行媲美。STM32CubeIDE完全开源免费,并且跨平台,目前支持Windows、Linux和macOS多个操作系统。但是STM32CubeIDE只是ST公司芯片的开发环境,MDK所支持的芯片就要广的多了。
6.1.3 EWARM

图6.1-4 IAR EWARM
EWARM,全称为IAR Embedded Workbench for ARM(IAR EWARM),是由IAR Systems公司开发的一款集成开发环境(IDE),专为ARM架构的微控制器设计。它提供了一个综合性的开发环境,用于编译、调试和优化基于ARM架构的嵌入式应用程序,适用于STM32等ARM Cortex-M系列微控制器的开发。
IAR EWARM的主要特点包括:
- 强大的编译器:EWARM配备了一款高效而稳定的C/C++编译器,能够生成高度优化的机器语言代码。这种编译器具有出色的代码大小和执行速度优化能力,保证了嵌入式应用程序的高效运行。
- 综合性的开发环境:EWARM提供了一个集成的开发环境,包括源代码编辑器、项目管理工具、构建系统和调试器等。开发人员可以在一个界面中完成代码编写、构建、调试等开发任务,简化了开发流程,提高了开发效率。
- 广泛的芯片支持:EWARM支持多个芯片系列,包括Arm Cortex-M、Arm Cortex-R和Arm Cortex-A等。这使得开发人员可以根据项目需求选择适合的芯片,并使用EWARM进行开发。
- 入门容易、使用方便:EWARM具有友好的用户界面和直观的操作方式,使得初学者可以快速上手。同时,它还提供了丰富的文档和示例代码,帮助开发人员更好地理解和使用EWARM。
- 代码紧凑:EWARM生成的代码紧凑,占用的内存空间较小,这对于资源有限的嵌入式系统来说非常重要。
此外,IAR EWARM还包含一个全软件的模拟程序(simulator),用户不需要任何硬件支持就可以模拟各种ARM内核、外部设备甚至中断的软件运行环境。从中可以了解和评估IAR EWARM的功能和使用方法。对比 MDK,IAR的使用人数少一些。
6.1.4 几种开发环境的比较
在众多IDE里,以前MDK和IAR的用户是比较多的,现在感觉使用STM32CubeIDE的已经超过IAR。很多人一开始学习单片机的时候使用的是MDK或者IAR来开发,这两个IED使用起来简单、好用并且普及很广。例如MDK,其开发界面美观,不需要做很麻烦的配置就可以进行开发,编译速度快,并且具有一键下载功能,可以说是比较方便的,对初学者来说比较友好。不过,MDK是一款付费集成开发环境,如果要商用,需要联系Keil公司购买,而免费版或评估版要么有器件型号限制,要么有程序容量限制。
使用MDK进行开发,易于上手,操作简单,如果之前有接触MDK的人,可以更快上手STM32MCU开发。但MDK没有没有图形化配置界面,也没有自动生成初始化代码的功能,需要自己手动去实现,不过这有助于加深学习者对底层操作过程的理解。
使用STM32CubeIDE进行开发,可以借助STM32CubeMX插件的图形化配置功能进行配置,操作直观,可以自动生成初始化代码。STM32CubeMX插件把很多东西封装的比较好,就是因为封装的比较好,所以我们可以直接跳过对部分底层的操作,不过这不利于对底层的理解。当然,我们也可以不使用STM32CubeMX插件的图形化配置功能和初始化代码生成功能,可以直接使用TrueSTUDIO插件的功能,这个时候可以在STM32CubeIDE上导入已有的TrueSTUDIO工程来进行开发也是可以的,使用上就和TrueSTUDIO、MDK差不多。STM32CubeMX插件的图形界面操作加上TrueSTUDIO插件的ECLIPSE/CDT框架,使得STM32CubeIDE的配置过程比MDK要麻烦,而且没有一键下载功能,使用上会让人觉得有一种―慢的感觉,比起MDK,STM32CubeIDE有点慢、卡顿。
6.2. MDK安装
MDK的安装可参考如下视频:
MDK5 的安装分为两步:1,安装 MDK5;2,安装器件支持包。
6.2.1 安装MDK5
MDK5 的安装比较简单,需要提醒一下在选择安装路径的时候,建议大家将 Pack 的路径和 Core 的路径放在一个盘中。安装目录及路径不要有任何中文汉字在里面,最好电脑系统名和用户名,都不要有任何中文。
6.2.2 安装器件支持包
器件支持包可以选择离线和在线安装方式,具体请参考前面视频链接。
需要注意的是MDK 是一款付费集成开发环境,默认软件是试用版的,只能编译不超过32K的代码,我们作为学习者仅做学习使用,可以使用注册工具注册,参考上述视频。如果大家要商用,要从Keil 公司购买!
6.3.安装STLINK驱动
STM32 可以通过 DAP、STLINK、JLINK 等仿真调试器进行程序下载和仿真,我们使用的是STLINK,STLINK的驱动可以直接在我们Keil软件的安装目录里就可以找到,如下图。
图6.3-1 STLINK驱动安装
6.4.安装USB转串口驱动
安装 CH340USB 虚拟串口驱动,以便我们使用电脑通过 USB 和 STM32 进行串口通信。这个网上下载资源很多,这里就不赘述了。
第7章.嵌入式开发常见概念简介
本文介绍一些在嵌入式开发中常见的概念,比如API,硬件抽象,库函数等,会不断进行补充。
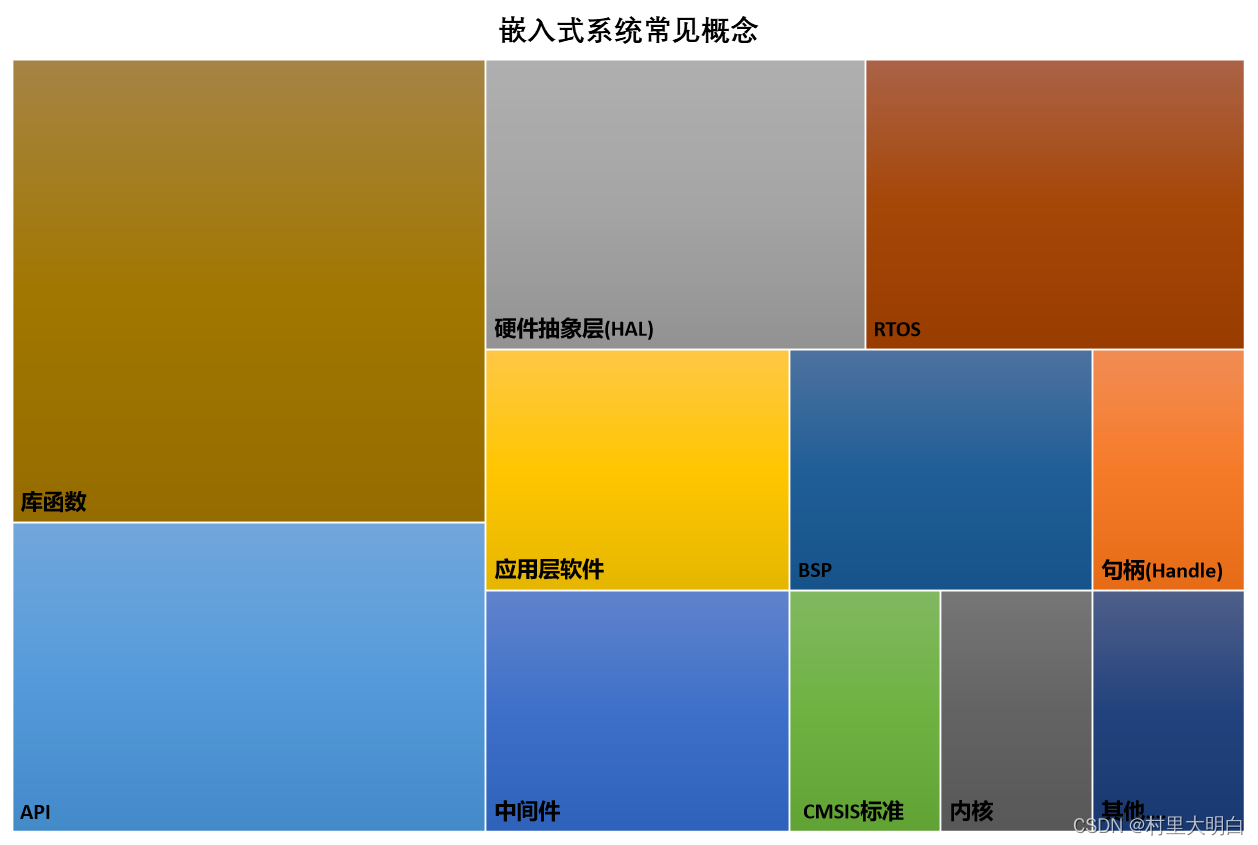
7.1.API,Handle(句柄)
7.1.1 API:
在嵌入式开发中,API(Application Programming Interface,应用程序编程接口)是一组定义、协议和工具的集合,它允许不同的软件组件相互交互。API为开发人员提供了一种标准化的方式,来访问特定功能或数据,而无需了解底层实现的细节。
可以理解为是一些已经封装好了的可以被调用的功能函数或者方法,我们把这些函数放到我们的工程中,当我们要实现某个功能时,就可以在工程中找到对应的函数,然后进行调用。
7.1.2 Handle(句柄):

Handle按英文的翻译就是“把手”,“抓手”,就像上图中的门把手,我们一旦抓到这个Handle“门把手”,那么我们就可以对这个房间进行一些操作,比如进入房间,知道里面放了什么,或者可以进去取一些东西之类的。在软件开发里,Handle的意思和前面的比喻是一样的,你只要获取了某个“东西”的句柄Handle(把手),那么你就可以对这个“东西”进行一些操作。
说的正式一些就是:在软件开发中,Handle(句柄)是一种特殊类型的标识符,它用来唯一地标识和引用系统内某个资源或对象。Handle在软件开发中起到了一个桥梁的作用,使得开发人员能够间接地访问和控制底层资源,从而提高了代码的灵活性和可维护性。
在STM32 的手册上经常看到这个词,可以理解为它是一个指针,或者是一些表的索引,或者是用于描述和标记某些资源的的标识,这些资源可以是函数、可以是一段内存、可以是一组数字、可以是一个外设等等,总之很广泛,通过句柄我们可以访问到打开的资源。我们在调用 API 函数的时候,可以利用句柄来说明要操作哪些资源。
7.2.CMSIS标准,HAL(硬件抽象层)
7.2.1 CMSIS标准
CMSIS(Cortex Microcontroller SoftwareInterface Standard)标准的建立主要是为了解决不同芯片厂商生产的Cortex微控制器软件兼容性问题。基于Cortex系列芯片采用的内核都是相同的,区别主要为核外的片上外设的差异,这些差异却导致软件在同内核,不同外设的芯片上移植困难。为了解决这个问题,ARM与芯片厂商建立了CMSIS标准。CMSIS标准的建立为基于Cortex核的嵌入式系统开发带来了诸多便利和优势,使得开发人员可以更加高效、快速地开发出高质量的产品。
CMSIS 标准,实际是新建了一个软件抽象层。见图7-1.CMSIS 架构。
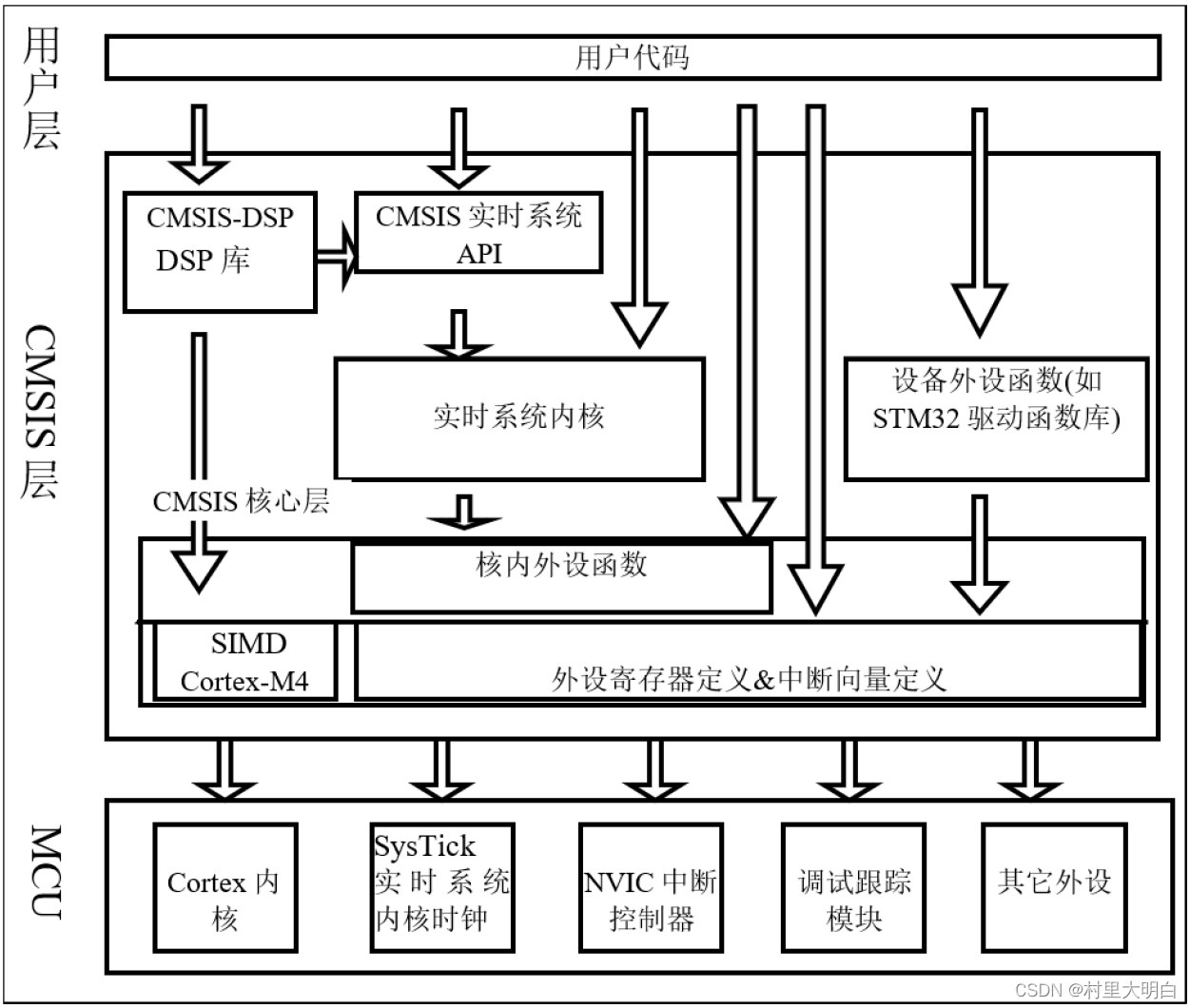
图7-1.CMSIS架构
CMSIS标准中最主要的为CMSIS核心层,它包括了:
•内核函数层:其中包含用于访问内核寄存器的名称、地址定义,主要由ARM公司提供。
•设备外设访问层:提供了片上的核外外设的地址和中断定义,主要由芯片生产商提供。
可见CMSIS层位于硬件层与操作系统或用户层之间,提供了与芯片生产商无关的硬件抽象层,可以为接口外设、实时操作系统提供简单的处理器软件接口,屏蔽了硬件差异,这对软件的移植是有极大的好处的。
CMSIS标准的优势主要体现在以下几个方面:
- 降低学习曲线和开发成本:CMSIS提供了统一的软件接口和标准,使得开发人员可以更容易地学习和使用不同芯片厂商的Cortex微控制器。这降低了学习成本,提高了开发效率。
- 提高软件的可移植性和可重用性:通过遵循CMSIS标准,开发人员可以编写出在不同芯片上都能运行的代码,提高了软件的可移植性。同时,CMSIS提供的标准接口也使得软件模块的重用成为可能,进一步降低了开发成本。
- 缩短上市时间:CMSIS标准的采用可以加速新微控制器的部署和上市过程。由于CMSIS提供了与芯片生产商无关的硬件抽象层,开发人员可以更快地开发出符合市场需求的产品。
- 支持多种编译器:CMSIS独立于编译器,因此它支持主流编译器。这使得开发人员可以根据自己的喜好和需要选择适合的编译器进行开发。
- 增强程序调试:CMSIS提供了用于调试连接、调试外设视图、软件交付和设备支持的接口,以及通过调试器的外围信息和用于printf样式输出的ITM通道来增强程序调试。这使得开发人员可以更方便地进行程序调试和错误排查。
- 实现快速软件交付和简化更新:CMSIS以CMSIS-Pack格式交付,可以实现快速软件交付、简化更新,并与开发工具实现一致集成。这使得开发人员可以更方便地管理和更新他们的软件项目。
- 简化系统资源和分区:CMSIS-Zone将简化系统资源和分区,因为它管理多个处理器、内存区域和外围设备的配置。这使得开发人员可以更有效地管理系统资源,提高系统的整体性能。
7.2.2 HAL(硬件抽象层):
在嵌入式开发中,“硬件抽象层”(Hardware Abstraction Layer,简称HAL)是一个关键的概念,它主要用于隐藏底层硬件的细节,为上层软件提供统一的接口。硬件抽象层是嵌入式系统开发中的重要组成部分,它为上层软件提供了统一的、标准化的接口,并隐藏了底层硬件的细节。通过合理地设计和实现硬件抽象层,可以极大地提高嵌入式系统的开发效率和产品质量。
以下是关于硬件抽象层(HAL)的详细介绍:
- 定义与功能:
- 硬件抽象层是一种软件层,其主要目的是将硬件差别与操作系统的其他层相隔离。它通过将不同硬件平台的功能和特性抽象出来,为上层软件提供一个统一的、标准化的接口。
- 通过硬件抽象层,相同的代码可以在不同的硬件平台上运行,而无需进行大量的修改。这极大地提高了代码的可复用性和可移植性。
- 当需要对系统进行修改或添加新的功能时,可以通过修改或添加硬件抽象层来实现,而无需对整个系统进行大规模的修改。这降低了开发难度和成本。
- 优势:
- 硬件抽象层在嵌入式系统开发中扮演着至关重要的角色。它简化了软件开发的复杂性,降低了开发难度和成本,并提高了代码的可复用性和可移植性。
- 通过硬件抽象层,开发者可以更加专注于实现应用层逻辑,而无需深入了解底层硬件的细节。这有助于加速开发进程并提高产品质量。
- 随着硬件技术的不断发展,新的硬件功能不断涌现。通过设计可扩展的硬件抽象层,可以方便地添加新的硬件支持和功能,从而满足不断变化的市场需求。
7.3.BSP和库函数
7.3.1 BSP(板级支持包):
BSP(Board Support Package,板级支持包)是指针对特定硬件平台的软件支持包。它位于主板硬件和操作系统(或裸机系统)之间,提供了一组软件接口和驱动程序,用于实现对底层硬件设备的抽象和管理,使上层应用程序能够更加方便、高效地访问和控制硬件资源。
它是针对特定硬件平台(例如某款开发板或特定的嵌入式系统)的软件支持包。BSP的作用是提供一系列软件组件,帮助开发者在特定硬件平台上进行软件开发。这些组件包括了对硬件的初始化、配置以及访问硬件的接口,以确保软件能够正确地运行在目标硬件上。
BSP通常包括以下内容:
-
引脚配置:包括各功能引脚的初始化设置,比如串口、I2C、SPI等接口的引脚配置。
-
中断配置:处理器中断控制器的初始化设置,确保中断能够正常工作。
-
时钟配置:处理器和外设的时钟配置,确保系统时钟和外设时钟能够正常运行。
-
外设驱动:对于特定的开发板,可能包含对应外设的驱动程序,比如液晶显示屏驱动、触摸屏驱动等。
-
其他硬件初始化:例如初始化LED、按键、传感器等外部硬件设备。
7.3.2 库函数
库函数在嵌入式领域中也经常被称为固件库(Firmware Library)。固件库的作用是为特定的微控制器MCU或处理器MPU提供高级别的函数接口,以简化对硬件的访问和控制,并且为开发者提供更加便捷的软件开发和调试环境。在不同的硬件和开发工具厂商中,固件库也可能被称为不同的名字,比如标准外设库、处理器支持库等等。
STM32的库函数是为ST公司生产的STM32系列微控制器而设计的一组函数库。这些库函数旨在简化对STM32微控制器的编程和开发,提供了对处理器内部功能和外设的高级抽象,使得开发者可以更容易地与STM32系列微控制器进行交互和控制。
STM32的库函数主要包括标准外设库(Standard Peripheral Library,SPL)和STM32Cube库(HAL库和LL库)两种形式。标准外设库提供了对处理器内部外设(比如定时器、串口、I2C、SPI等)的底层驱动函数,而STM32Cube库则提供了一套更加高级、现代化的API,包含了对各种传感器、通信接口和外设的驱动函数,并提供了更加丰富和易用的功能。
通过使用STM32的库函数,开发者可以更便捷地进行嵌入式软件开发,加快产品上市速度,并且为不同型号的STM32微控制器的开发提供了一定的通用性。
7.3.3 BSP和库函数的区别
以STM32开发为例,BSP和库函数这2个概念经常容易混淆,下面是我个人对这2个概念的理解。
BSP是针对特定的开发板或硬件平台的(比如我们STM32的MCU做了个控制板),它包含了特定硬件的初始化和配置信息,因此具有一定的特殊性。而库函数则是针对某款MCU(微控制器单元)的,提供了对处理器内部功能的封装,具有普遍性,可以适用于多种硬件平台,比如STM32F103C8T6这个MCU的库函数,不管是谁设计控制板都可以使用且是一样的。在实际开发过程中,BSP和库函数通常配合使用,BSP用于配置和初始化特定硬件平台,而库函数则用于提供通用的MCU或MPU处理器功能和外设控制。
7.4 应用层软件,中间层软件,底层软件
以我自己的认识来看,这3个概念似乎只有应用层软件是比较固定的,而中间层和底层的定义在不同的环境中可能具有不同的含义,很难给出统一的解释,在不同人和不同场景下,中间层和底层的一些内容可能会有重叠,但一般而言下面这张关系图都是成立的。
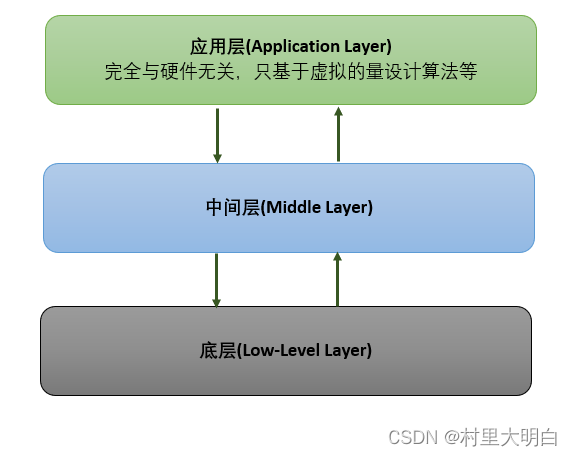
以STM32开发为例,应用层软件、中间层软件和底层软件具体含义和内容:
- 应用层软件:
- 含义:应用层软件是STM32微控制器上运行的最终功能程序,它直接满足用户需求或完成特定的功能任务。
- 内容:应用层软件包括用户界面、通信协议、数据处理算法等。例如,如果你正在开发一个基于STM32的温度控制系统,应用层软件可能包括温度数据的读取、处理、显示以及与上位机的通信功能。
- 中间层软件(硬件抽象层HAL或板级支持包BSP):
- 含义:中间层软件是连接应用层软件和底层硬件的桥梁,它隐藏了底层硬件的复杂性,为应用层软件提供了一组统一的接口。
- 内容:在STM32开发中,中间层软件通常包括STM32的HAL库(硬件抽象层库)或特定的BSP(板级支持包)。HAL库提供了一组高级API,用于访问STM32微控制器的硬件资源,如GPIO、UART、SPI等。BSP则针对特定的STM32开发板提供了初始化代码、驱动程序等。这些库和包使得开发者能够以一种统一、标准化的方式访问底层硬件,而不必深入了解底层寄存器和位操作。
- 底层软件:
- 含义:底层软件直接与STM32微控制器的硬件交互,负责完成硬件的初始化、驱动程序的加载以及硬件资源的直接控制。
- 内容:底层软件通常包括与STM32微控制器直接相关的代码,如启动文件(Startup Files)、链接脚本(Linker Scripts)、中断服务程序(Interrupt Service Routines, ISRs)以及硬件的初始化代码。这些代码负责设置微控制器的时钟、内存、外设等,为中间层和应用层软件提供一个稳定、可靠的硬件环境。
第8章.STM32开发方式(库函数)介绍
8.1 单片机的开发方式
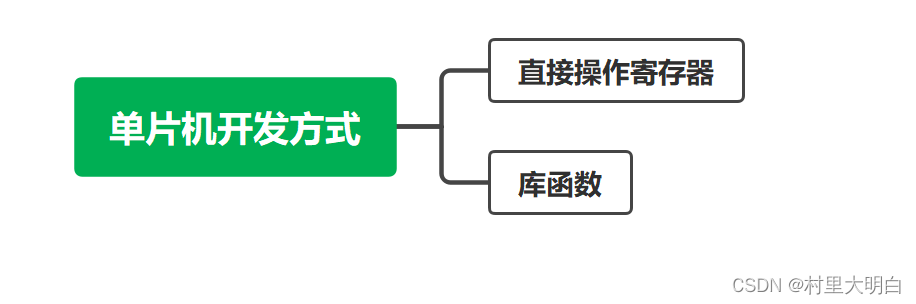
图8.1-1 单片机开发方式
如图8.1-1,单片机开发常见的开发方式有两种:直接操作寄存器和使用库函数。我们在51单片机开发的时候就直接配置寄存器,但是到了32位单片机开发,如果开发大型项目,需要的功能外设很多,再使用这种方式就已经力不从心了。因为 STM32 的外设资源丰富,寄存器数量是51单片机寄存器的数十倍,那么多的寄存器根本无法记忆,而且开发中需要不停查找芯片手册,开发过程就显得机械和费力,完成的程序代码可读性差,可移植性不高,程序的维护成本变高了。当然了,采用直接配置寄存器方式开发会显得更直观,程序运行占用资源少。 下面将这两种方式的优缺点总结一下:
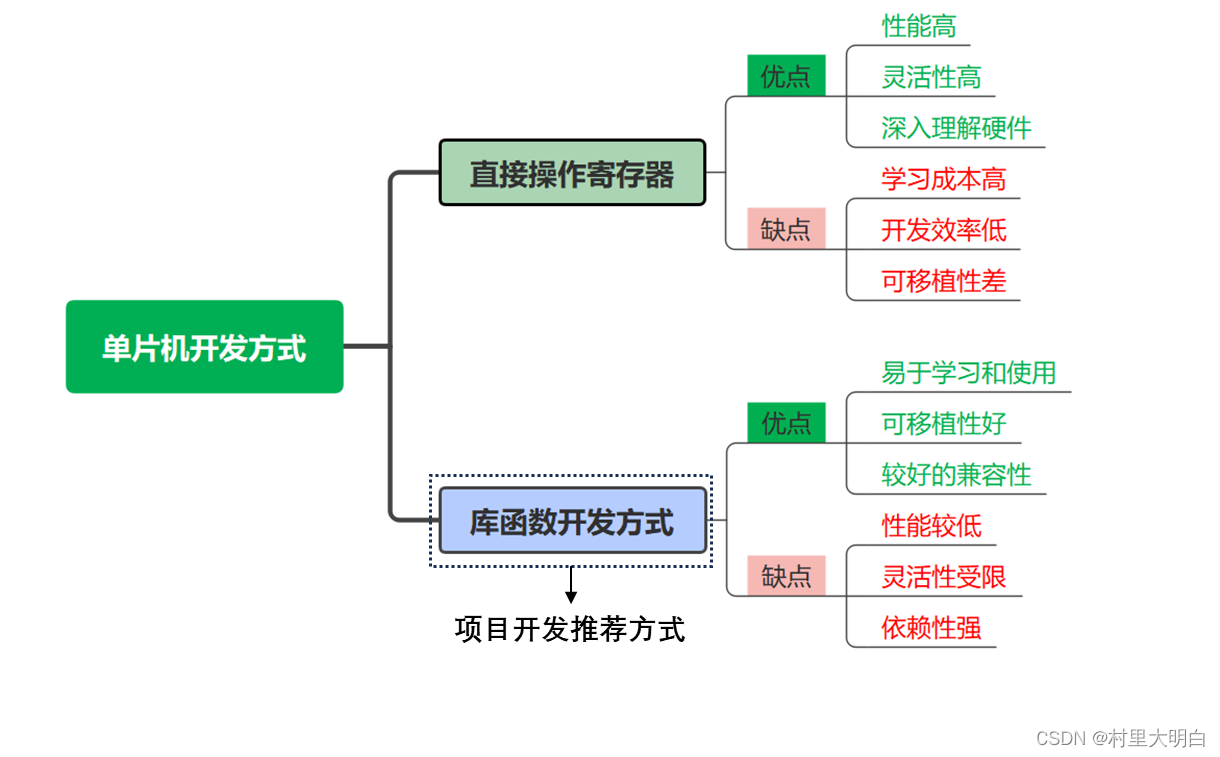
图8.1-2 两种开发方式的优缺点
8.1.1 直接操作寄存器
优点:
- 性能高:直接操作寄存器可以绕过库函数的调用和转换,直接对硬件进行操作,因此执行效率更高。
- 灵活性高:直接操作寄存器可以实现对硬件的底层控制,能够灵活地根据具体需求进行配置和操作。
- 深入理解硬件:通过直接操作寄存器,可以更深入地理解硬件的工作原理和内部机制,有助于提升个人的开发能力和经验。
缺点:
- 学习成本高:直接操作寄存器需要对硬件的底层结构和工作原理有较深的理解,对于初学者来说学习成本较高。
- 开发效率低:直接操作寄存器需要编写大量的底层代码,包括寄存器的配置、读写等,这会增加开发的工作量,降低开发效率。
- 可移植性差:直接操作寄存器是针对特定硬件的,当更换硬件或平台时,需要重写大量的底层代码,可移植性较差。
8.1.2 使用库函数
优点:
- 易于学习和使用:库函数提供了对硬件操作的封装,使得开发者无需深入了解硬件的底层细节,即可进行开发。这降低了学习成本,提高了开发效率。
- 可移植性好:库函数通常是跨平台的,可以在不同的硬件和操作系统上运行。因此,使用库函数开发的程序具有较好的可移植性。
- 较好的兼容性:库函数经过了严格的测试和验证,通常具有较好的兼容性和稳定性。
缺点:
- 性能较低:由于库函数需要进行封装和调用,相对于直接操作寄存器来说,执行效率可能会稍低一些。但在大多数情况下,这种性能差异是可以接受的。
- 灵活性受限:使用库函数进行开发时,可能会受到库函数功能的限制。如果库函数没有提供所需的功能,或者功能不满足具体需求,那么就需要进行底层开发或寻找其他解决方案。
- 依赖性强:使用库函数开发的程序通常依赖于特定的库文件或环境。如果更换库文件或环境,可能会导致程序无法正常运行或需要重新编译。因此,在使用库函数进行开发时,需要注意库文件的版本和兼容性等问题。
目前现在大型项目开发里,肯定是推荐库函数方式。现在项目开发最重要的是“方便人”,方便产品的合作开发,而不再是“方便计算机”,封装越好越利于项目的开发,虽然封装越好运行速度越慢,但目前这个缺点可以忽略。我们平常开发时,有同事经常会说,计算机你就把它当成“一头驴”,不要管它累不累,我们自己不累才是现代项目该有的特征。
虽然直接操作寄存器这种方式可以使我们更深入地理解硬件的工作原理和内部机制,有助于提升个人的开发能力,但STM32的学习过程却完全没必要按直接操作寄存器的方式去学习或者开发,我们只需要明白原理即可,了解了一种寄存器,其余寄存器操作方式也都是一样的。我们没必要在这上面耗费青春。
8.2 STM32的库函数
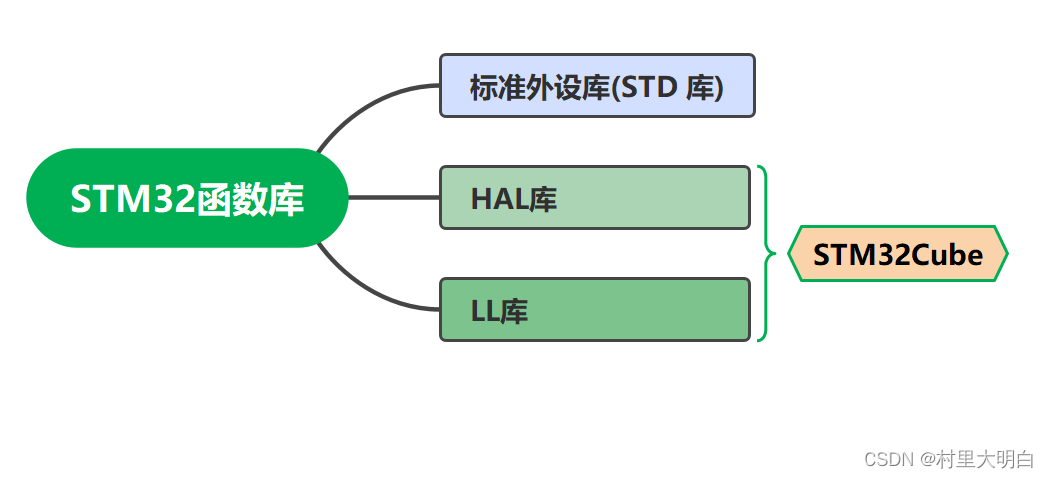
图8.2-1 STM32的库函数
为了简化开发人员的工作,减少开发工作时间和成本,针对STM32系列芯片,ST公司推出了标准外设库(STD库)、HAL库和LL库。在这些库中,有很多用结构体封装好的寄存器参数,有常用的表示参数的宏,还有封装好的对寄存器操作的API,开发者可以调用这些资源实现配置相应的寄存器,效率大大提高了。使用库的框架来开发,程序控制语句结构化,程序单元模块化,贴近人的思维,易于阅读,易于移植和维护。下面介绍一下3种库函数的区别。

图8.2-2 STM32各产品的库函数支持情况
8.2.1 标准外设库(STD库)
STD(StandardPeripheralLibraries)标准外设库,它把实现功能中需要配置的寄存器以结构体的形式封装起来,使用者只需要配置结构体变量成员就可以修改外设的配置寄存器,比直接操作寄存器方便了不少。但标准外设库仍然接近于寄存器操作,它的方便也是针对某一系列芯片而言,在不同系列芯片上使用标准外设库开发的程序可移植性比较差,例如,在F4上开发的程序移植到F3上,使用标准库是不通用的。目前STM32系列产品中仅F0-F4以及L1系列支持标准外设库。目前,对于较新的STM32系列,如STM32F7、STM32L4等,ST公司已经停止提供STD库的支持。这些新系列的MCU产品主要使用HAL库和LL库进行开发。
8.2.2 HAL库
为了解决标准库存在的问题,ST公司在标准库的基础上又推出了 HAL 库。这几年ST公司大力推广HAL 库,而且在ST新出的STM32 芯片中, ST直接只提供 HAL 库。HAL库取代之前的标准库已经是确定的趋势,HAL库也更符合现代项目的开发方式。
HAL库在设计的时候更注重软硬件分离,HAL库的目的就是尽量抽离物理层,HAL库的API集中关注各个外设的公共函数功能,以便定义通用性更好的API函数接口,具有更好的可移植性。HAL库写的代码在不同的STM32产品上移植,非常方便,效率得到提升。目前HAL库支持STM32全系列微控制器,具有良好的跨平台支持。
8.2.3 LL库
- LL库(Low-Level Library)是STMicroelectronics在HAL库的基础上提供的更低级别的库。
- 它提供了对底层寄存器和外设的更直接的访问,允许开发者编写更底层的代码,实现对微控制器和外设的精细控制。
- LL库保留了更多的硬件细节,为开发人员提供了更高级别的灵活性和控制。
- 相对于HAL库,LL库的执行效率可能更高,但使用难度也相应增加。
- LL库适用于对性能和资源要求极高,以及对底层硬件控制有特殊需求的应用。
LL库是ST在HAL库的基础上提供的更低级别的库,是继HAL库之后新增的库,与HAL库捆绑发布。LL库也更接近硬件层,它和STD库类似,都是直接操作的寄存器,只不过LL库可以在STM32Cube中实现。LL库提供一组轻量级、优化、面向专家的API,具有最佳的性能和运行时效率。LL库可以完全独立使用,也可以结合HAL库一起使用。当HAL库需要优化运行时,可以调用LL库来处理,例如对于一些复杂的外设(如USB驱动),两者混合使用才能正常驱动这个复杂的外设。
我们本教程的目的是学习,为了对硬件和原理有更深入的理解,很明显采用STD库是更好的一种学习方式。我们的学习也基于标准库开展。
第9章.Keil5-MDK软件简介
9.1 主界面
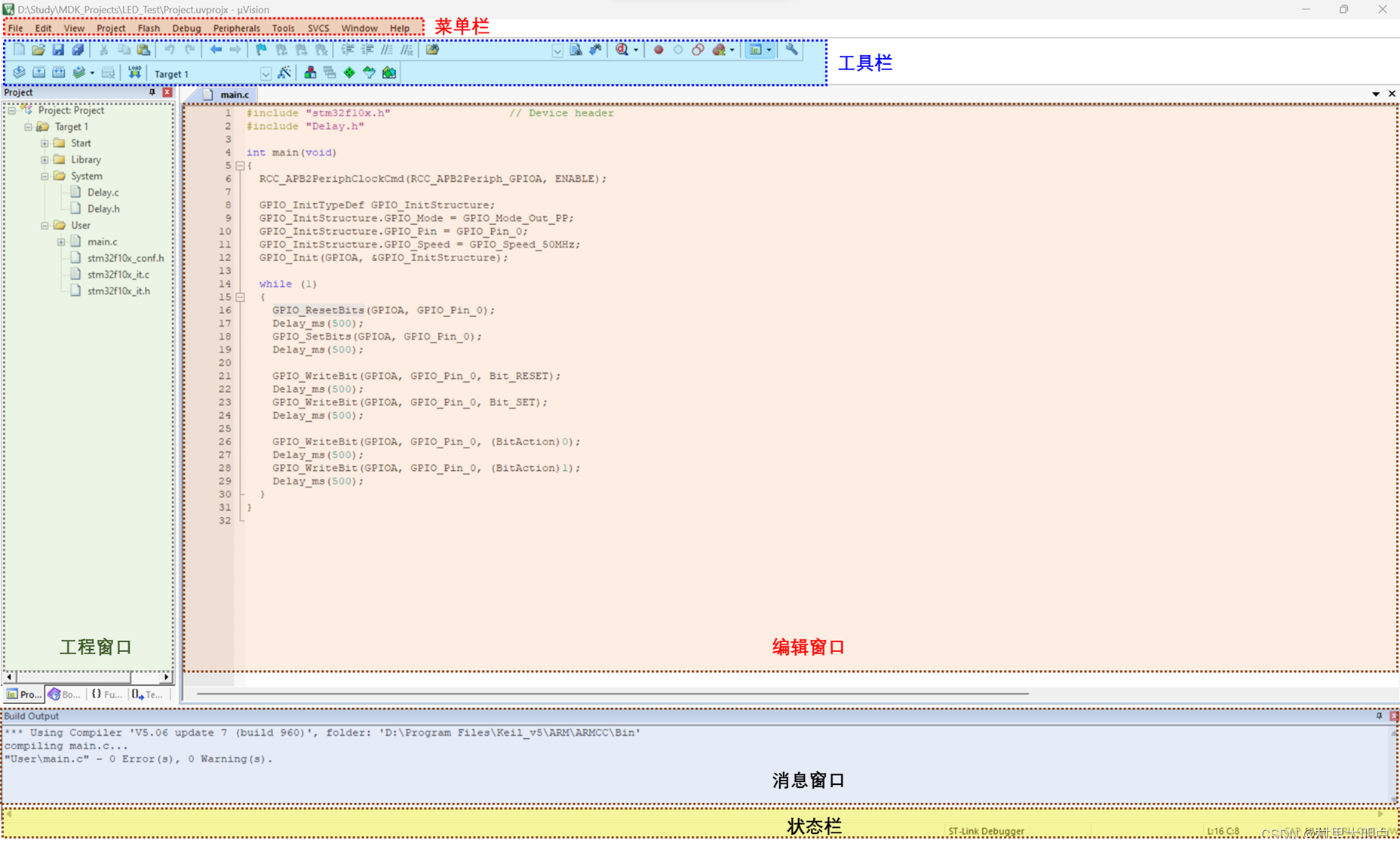
图9.1-1 Keil5主界面
本节我们简单介绍一下Keil5软件的界面及一些常用操作。后面创建例程的时候,我们还会详细讲解操作步骤。图9.1-1为KEIL5 的主窗口界面.分为了一下几个部分:
菜单栏:包含File文件、Edit编辑、View视图、Project工程、Help帮助等
工具栏:常见工具的快捷按钮,下面会重点介绍一些常用的工具
工程窗口:主要显示项目内容,文件组、源文件和头文件等
编辑窗口:编写代码的地方
消息窗口:反馈编译信息、烧录信息等
状态栏:光标的行列位置、字符编码、键盘NUM锁定等一些状态信息
工具栏里有几类常用的按钮是我们经常要用到的,如图9.1-2.

图9.1-2 工具栏常用按钮
① 编译类快捷按钮:对代码进行编译下载
| 按钮英文名称 | 中文含义 | 快捷键 |
| Translate | 编译当前文件 | Ctrl + F7 |
| Build | 编译工程目标 | F7 |
| Rebuild | 重新编译所有目标文件 | – |
| Batch Build | 分批编译(多工程) | – |
| Stop Build | 停止编译(正在编译时有效) – | – |
| Download | 下载程序 | F8 |
② 工程目标选项又称魔术棒:即对工程目标的配置,如芯片设备选择、C/C++ 选项、仿真配
置等等
③ 调试类按钮:
| 英文名称 | 中文描述 | 快捷键 |
| Start/Stop Debug Session | 打开/关闭调试 | Ctrl + F5 |
| Insert/Remove Breakpoint | 插入/移除断点 | F9 |
| Enable/Disable Breakpoint | 使能/失能断点 | Ctrl + F9 |
| Disable All Breakpoints | 失能所有断点 | – |
| Kill All Breakpoints | 取消所有断点 | Ctrl + Shift + F9 |
9.2 文本格式编辑
文本格式编辑,主要是设置一些关键字、注释、数字等的颜色和字体。如果刚装Keil5,没
进行字体颜色配置,我们的界面效果如图9.2-1所示,看上去不是特别舒服。
图9.2-1 Keil5默认文本效果
我们可以在软件中对字体颜色大小等进行自定义。我们可以在工具条上点击“扳手”按钮,如下图位置。

弹出的编辑对话框,如图9.2-2所示:
Editor选项卡中:
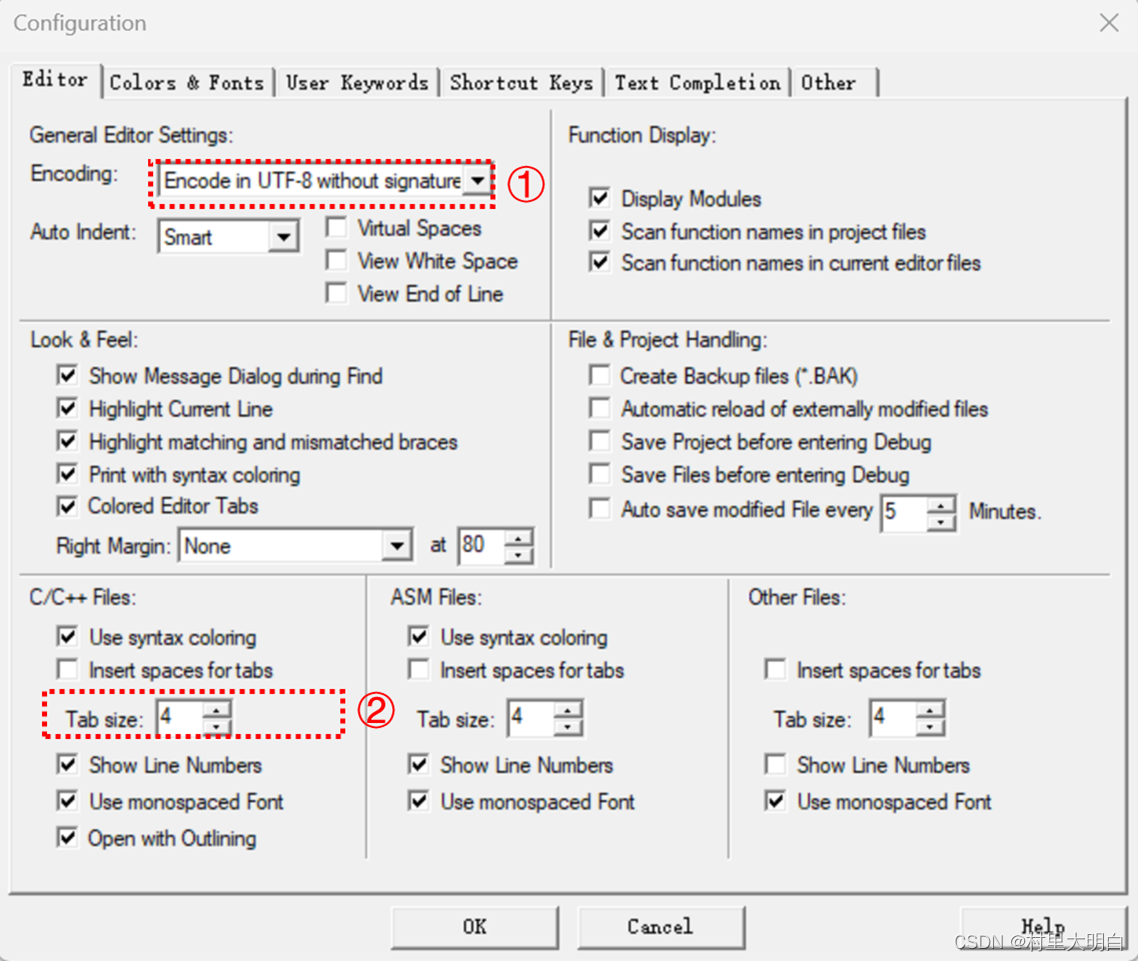
图9.2-2 配置对话框中Editor选项卡
①设置代码的编码格式:可以选择Chinese GB2312(Simplified)或UTF-8,如果打开别人的例程出现中文乱码,可以尝试修改这个Encoding格式。
②设置 C/C++文件,TAB 键的大小为 4 个字符 。
Colors & Fonts 选项卡:
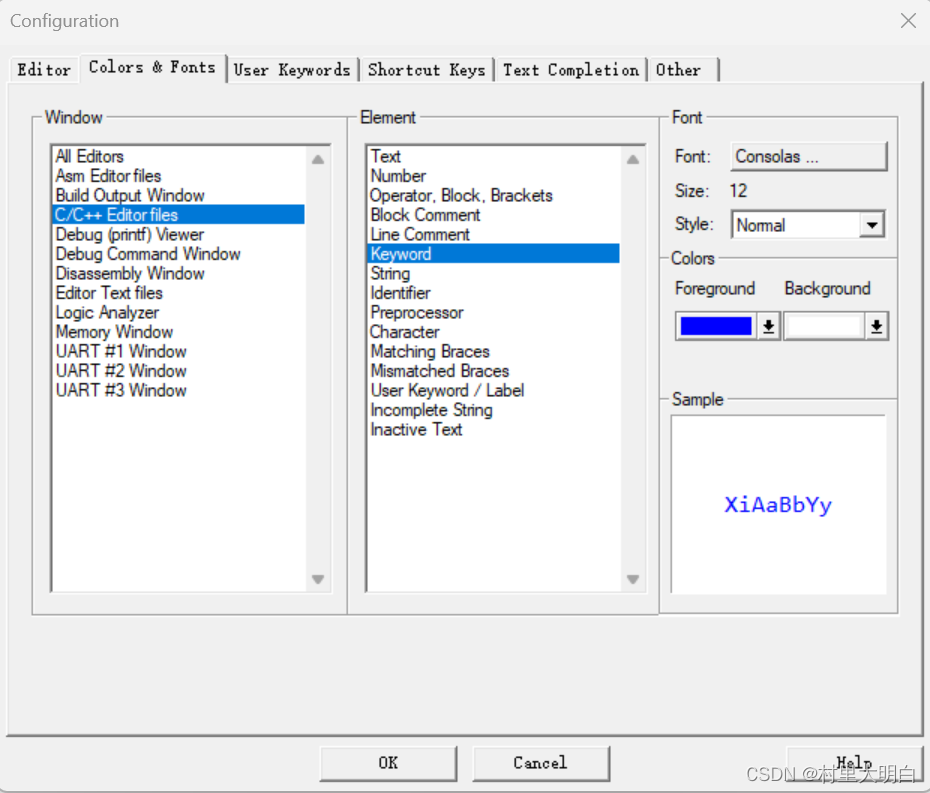
图9.2-3 配置对话框中Colors&Fonts 选项卡
Colors&Fonts选项卡,在该选项卡内,我们就可以设置自己的代码的字体和颜色了。由于我们使用的是C语言,故在Window下面选择:C/C++EditorFiles在右边就可以看到相应的元素了,如图9.2-3。点击各个元素(Element)修改为你喜欢的颜色,也可以在Font栏设置你字体的类型(这个软件支持的字体类型实在是少的可怜,这里面没有一个我喜欢的字体),以及字体的大小等。字体大小,也可以直接按住ctrl+鼠标滚轮,进行放大或者缩小.
User Keywords选项卡
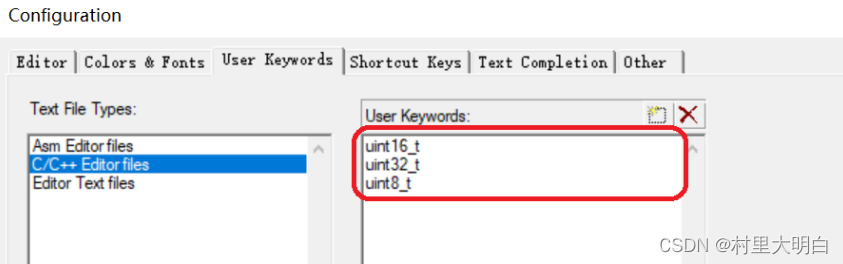
图9.2-4 配置对话框中User Keywords选项卡
点击 User Keywords 选项卡,设置用户定义关键字,以便用户自定义关键字也显示对应的颜色(对应图 9.2-3中的 User Keyword/Lable )。在 User Keywords 选项卡对话框输入你自己定义的关键字,如图 9.2-4示。如我们设置了 uint8_t、uint16_t 和 uint32_t 等三个用户自定义关键字,相当于 unsigned char、unsigned short 和 unsigned int。如果你还有其他自定义关键字,在这里添加即可。设置成之后点击OK,就可以在主界面看到你所修改后的结果。
9.3 代码提示&语法检测&代码模版
Text Completion选项卡:
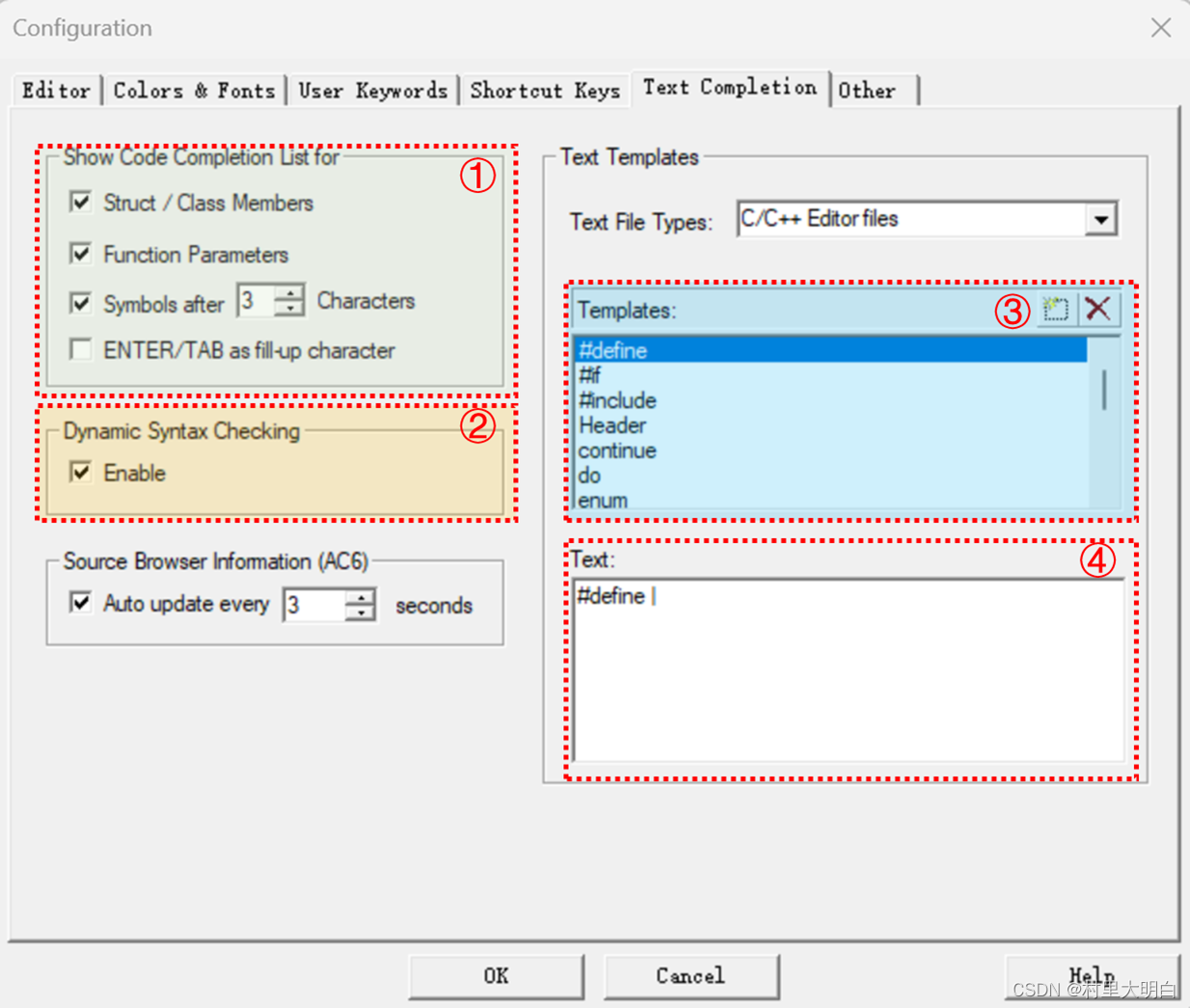
图9.3-1 配置对话框中Text Completion选项卡
配置对话框,选择 Text Completion选项卡,如图9.3-1,有3个地方是对我们比较有帮助的。
①代码提示:
上图中的“ShowCodeCompletionListFor”标签中有4个选项:
Strut/ClassMembers:用于开启结构体/类成员提示功能。
FunctionParameters:用于开启函数参数提示功能。
Symbolsafterxxcharacters:用于开启代码提示功能,即在输入多少个字符以后,提示匹配的内容(比如函数名字、结构体名字、变量名字等),这里默认设置3个字符以后,就开始提示。如图9.3-2.
ENTER/TAB as fill-up character:使用回车和 TAB 键填充字符。

②动态语法检测:
“Dynamic Syntax Checking”则用于开启动态语法检测,比如编写的代码存在语法错误的时,会在对应行前面出现X图标,如出现警告,则会出现图标,将鼠标光标放图标上面,则会提示产生的错误/警告的原因,如图 9.3-3 所示:
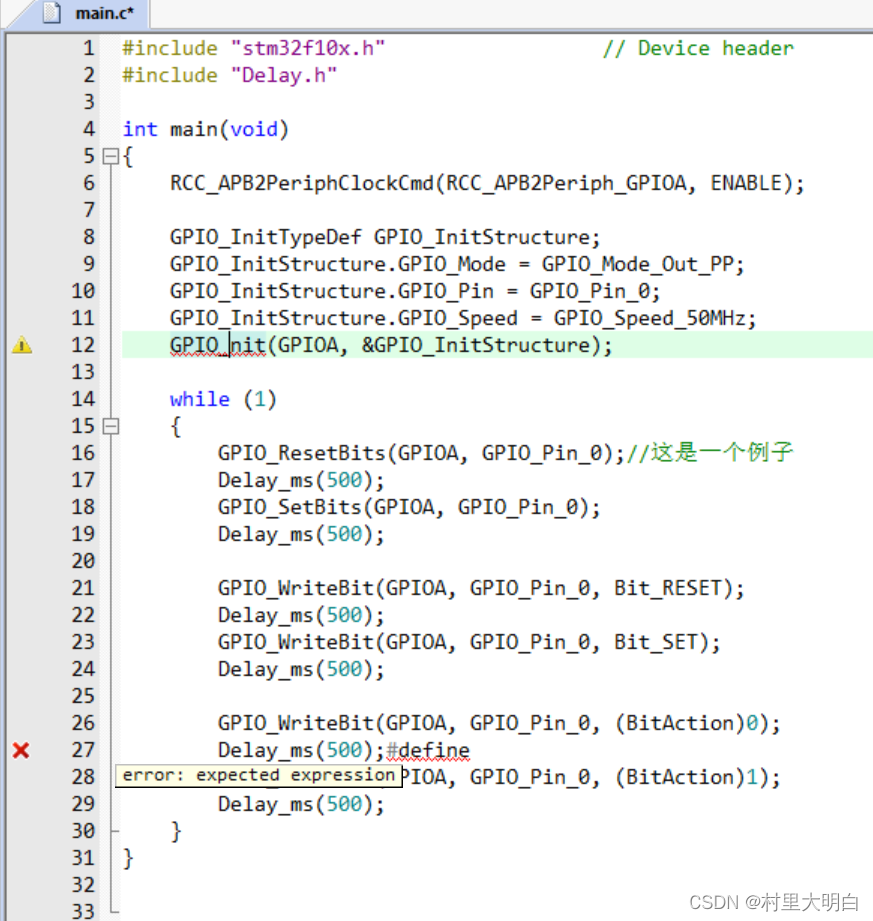
图9.3-3 动态语法检测
③代码模版:
图9.3-1中的③和④为代码模版,其中③是一段代码的名字,④是这个名字对应的具体代码,然后在主界面的工程窗口中,选择“Template”选项卡,双击“代码名”,便可以将③中代码名字对应的一段代码插入当前代码编辑区光标所在位置中,还是非常方便的,如图9.3-4.
9.3-4 代码模版
9.4 其他小技巧
9.4.1 TAB 键的使用
首先要介绍的就是TAB键的使用,除了按下Tab键可以让光标及后面的代码右移指定的空格(就是我们前面设定的Tab键代表的空格位数),MDK的TAB键还支持块操作。也就是可以让选中一片代码整体右移固定的几个位,也可以通过SHIFT+TAB键整体左移固定的几个位。
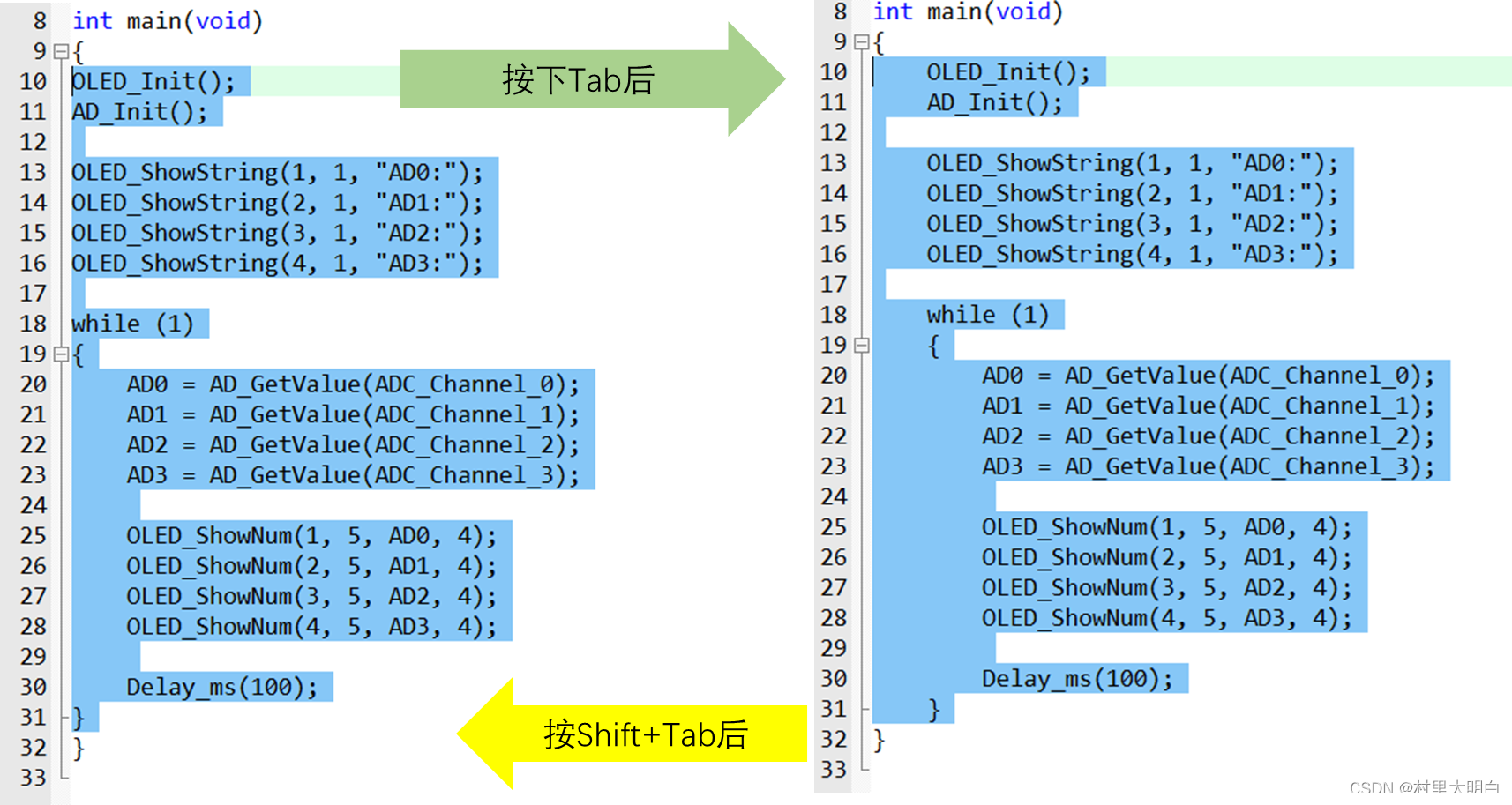
图9.4-1 Tab键的使用
9.4.2 快速定位函数/变量被定义的地方
在调试代码或编写代码的时候,我们肯定有时需要看看某个函数是在那里定义的,具体里面的内容是怎么样的,也可能想看看某个变量或数组是在哪个地方定义的等。尤其在调试代码或者看别人代码的时候,如果编译器没有快速定位的功能的时候,那我们只能慢慢的自己找,代码量少的时候还好说,如果代码量非常大,那就极为痛苦了。MDK提供了这样的快速定位的功能。只要你把光标放到我们想要查找的函数或变量的上面,然后右键,弹出如图9.4-2所示的菜单栏:
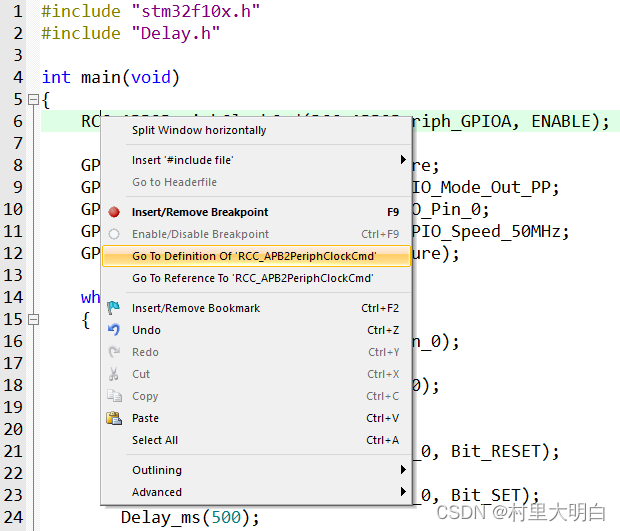
图9.4-2 快速定位
上图中我们找到Goto Definition Of ‘RCC_APB2PeriphClockCmd’这个地方,然后单击左键就可以快速跳到RCC_APB2PeriphClockCmd函数的定义处,如图9.4-3所示。
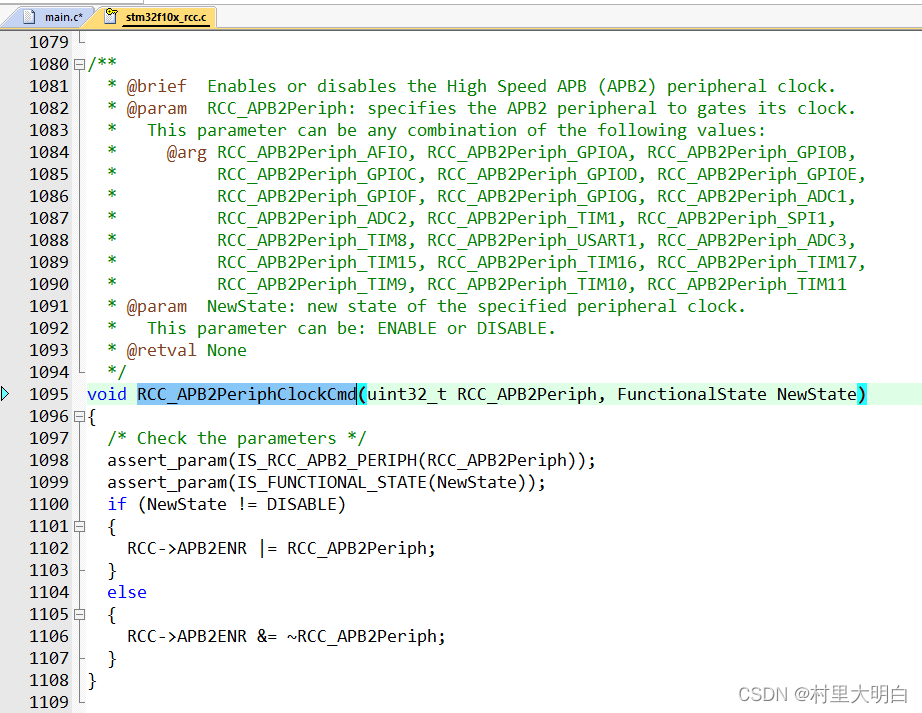
图9.4-3 定位结果
但这里需要注意,要实现快速定位必须满足以下两个条件,缺一不可。
条件1:在魔术棒中的Output 选项卡里面勾选 Browse Information 选项,如图9.4-4所示。
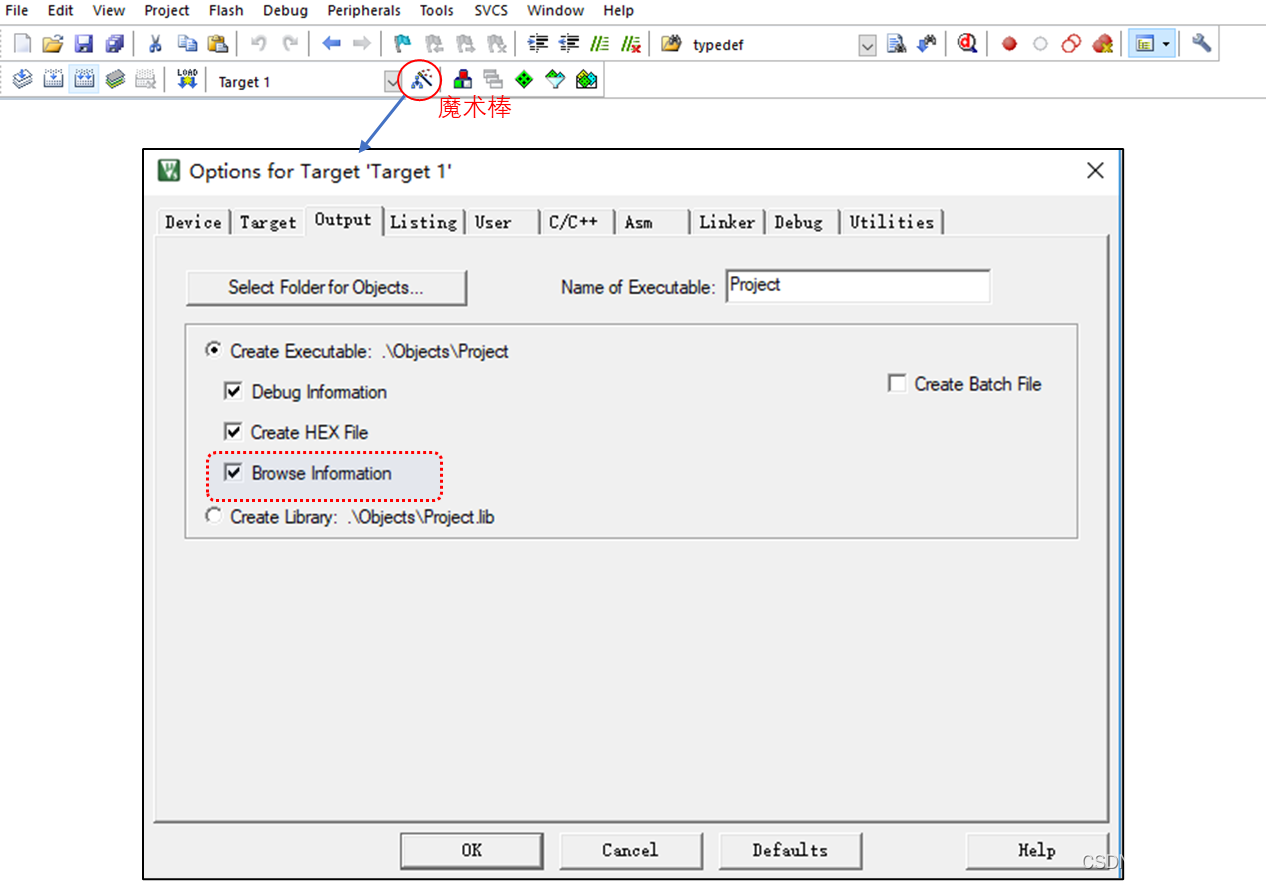
图9.4-4 魔术棒中配置快速定位
条件2:该工程必须被编译过才能定位!
对于变量我们也可以按这样的操作快速来定位这个变量被定义的地方,大大缩短了我们查找代码的时间。
我们利用Go to Definition看完函数/变量的定义后,如果想返回之前的代码,此时我们可以通过工具栏上的按钮(Back to previous position)快速的返回之前的位置,也可以通过
按钮再切换回去。这两个箭头就是各代码编辑位置进行切换的,如图9.4-5所示。

图9.4-5 代码编辑位置切换
9.4.3 快速注释与快速消注释
在调试代码的时候,在MDK中可以通过右键对一段代码进行快速注释/取消注释。这个操作比较简单,就是先选中要注释的代码区,然后右键,选择Advanced→Comment Selection就可以了。取消注释与注释类似,先选中被注释掉的地方,然后通过右键→Advanced,选择Uncomment Selection即可。
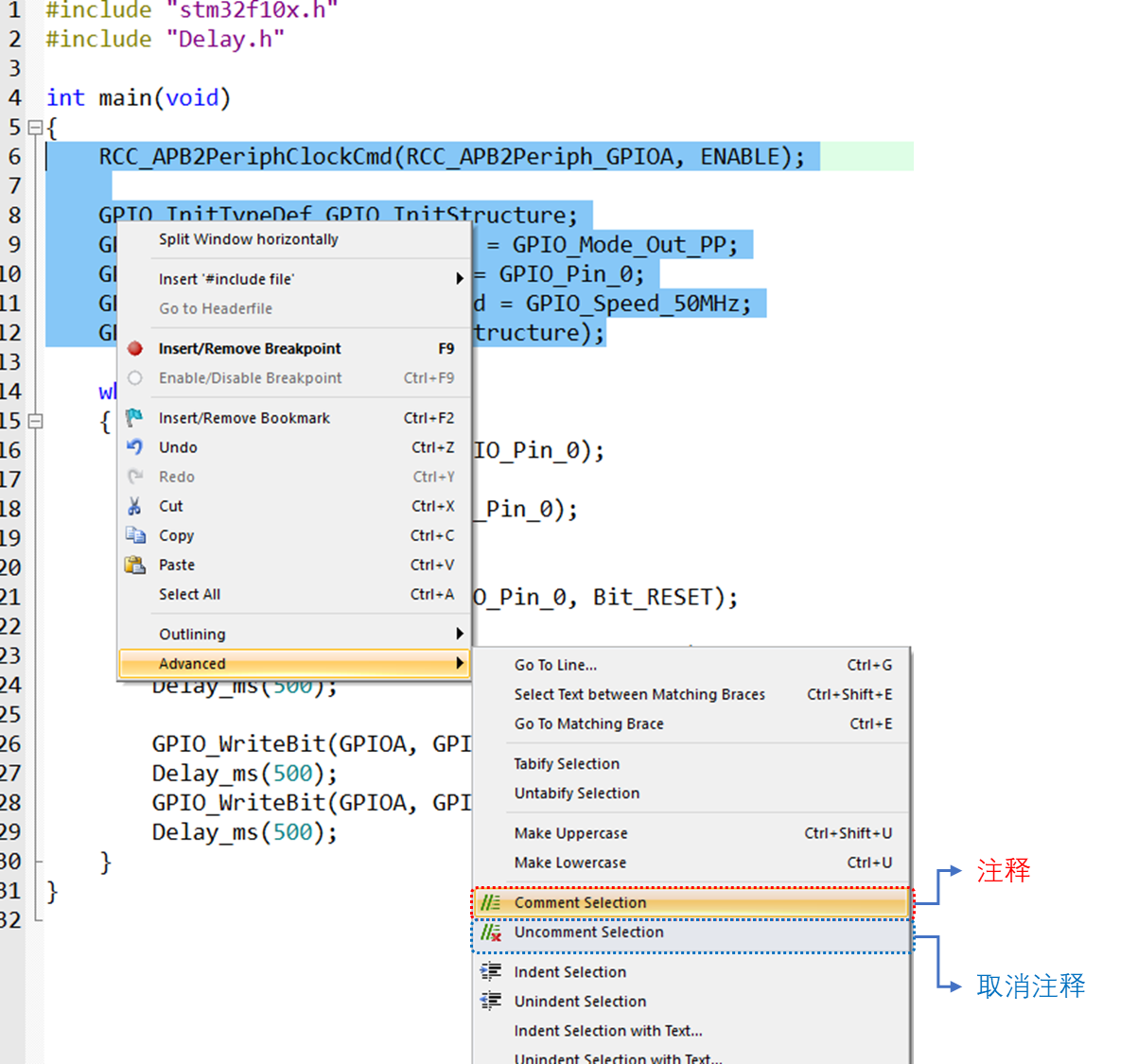
图9.4-6 注释与取消注释
9.4.4 快速插入&打开头文件
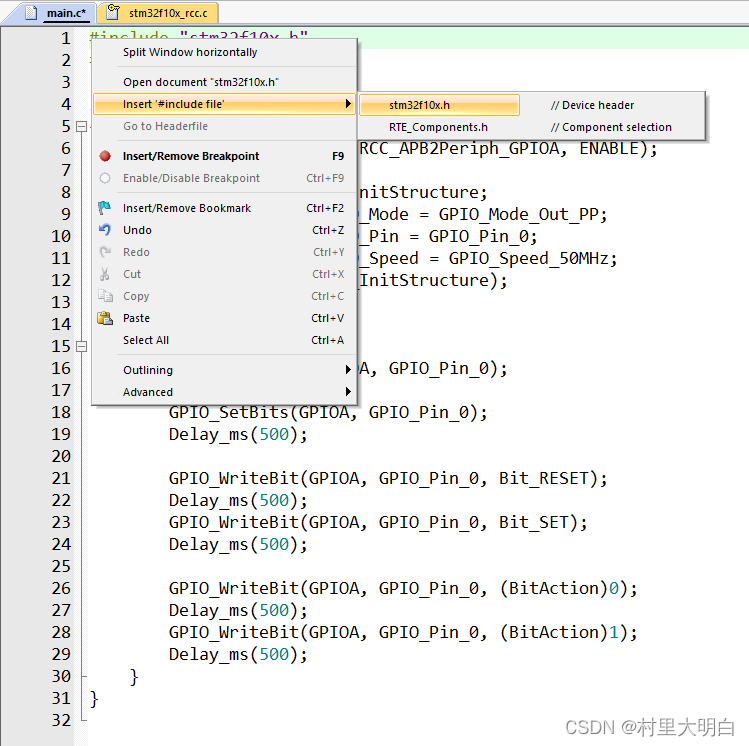
图9.4-7 快速插入头文件
如图9.4-7,我们可以在需要插入头文件定义的地方,鼠标右键,选择Insert '#Include file' ,MDK会根据我们选择的MCU类型自动提供我们需要插入的头文件,当然不嫌麻烦,手动输入也是可以的。
右键选择 Open Doc-ument“XXX”,就可以快速打开我们要看的头文件了(XXX 是我们要打开的头文件名字),如上图9.4-7,我们选择的Insert选项的上一个选项便是。
9.4.5 查找替换功能
这个和Word等编辑器是一样:
Ctrl+F:查找
Ctrl+H:替换
不管是查找还是替换,都会调出如下图9.4-8的查找替换对话框:
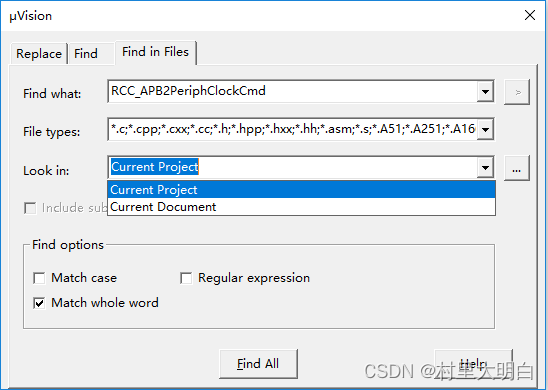
图9.4-8 查找和替换
这个用法和Word等一样,就不赘述了。简单再说一下,上面最后一个选项卡“Find in Files”就是可以选择在整个工程中进行查找我们需要的函数或变量等,并在消息栏里给出搜索的结果。如图9.4-9.

图9.4-9 Find in Files 查找结果
另外提一下,查找和替换,如图9.4-8这个对话框,也可以在工具栏中点击 图标,如下图9.4-10.

图9.4-10 工具栏里的查找图标
第10章.创建MDK工程-寄存器版
本章介绍如何创建寄存器版本的MDK工程。
10.1 新建本地工程文件夹
图10.1-1 新建文件夹
我们首先建立一个文件夹(取名:Led_RegVersion)用于后续建立MDK工程。正常项目我们这个时候是需要再建立一些文件夹,用来分别存放启动文件,外设以及内核等支持文件的,这章我们就省掉这一步,后续正式建工程的时候再正规讲解,也是为了有一个对比,效果会更好。
10.2 新建工程
打开MDK,新建一个工程,工程名根据个人喜好,最好取一个一眼就能知道含义的名字,我这里取LED_RegVersionTest,直接保存在上一步骤建立的Led_RegVersion文件中。
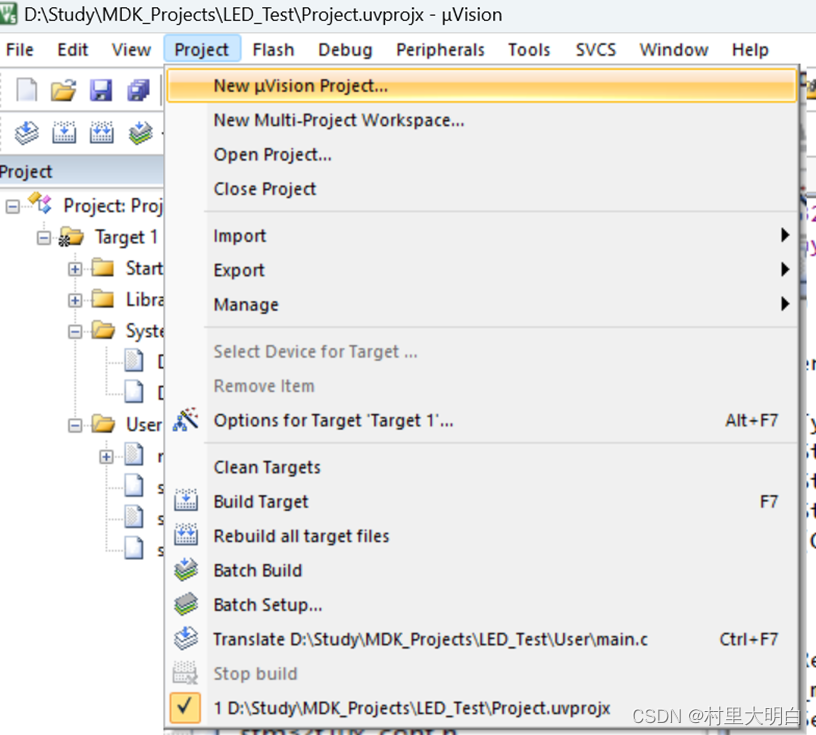
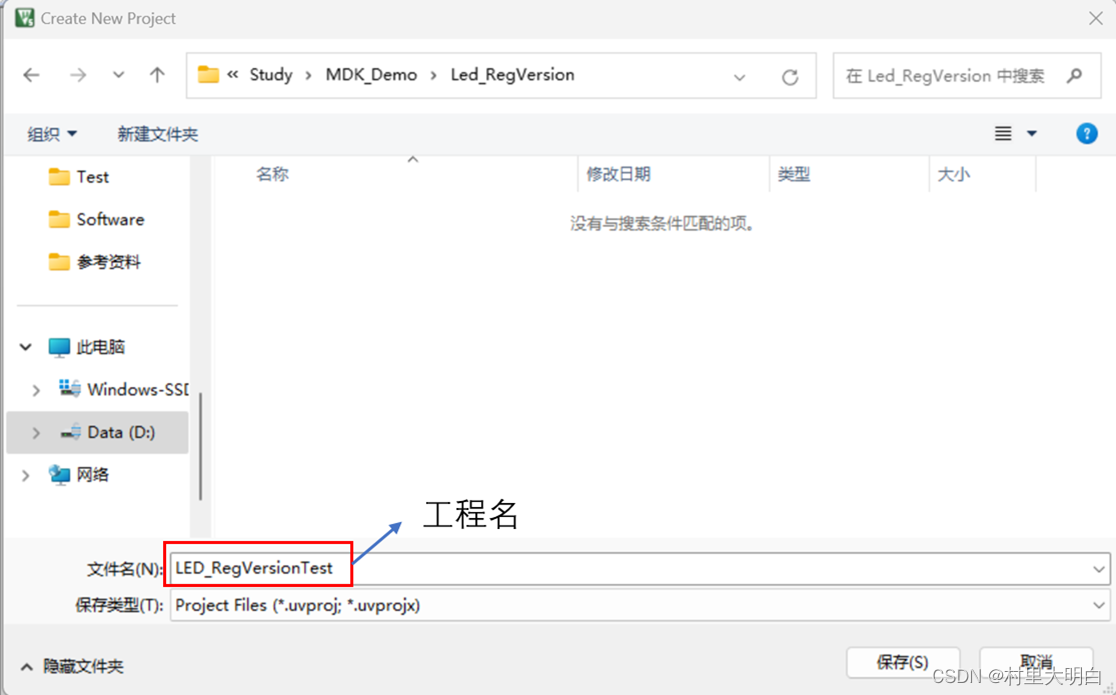
图10.2-1 新建工程
10.2.1 选择MCU 型号
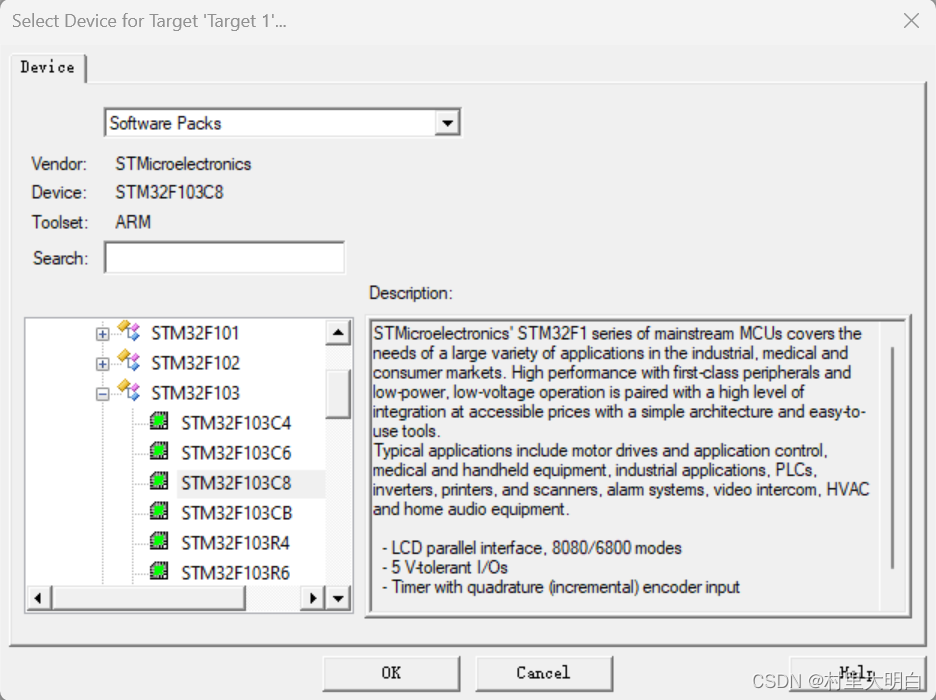
新建工程后会弹出MCU型号选择对话框,这个根据我们自己所用的型号选择即可,我们用的F103C8T6,所以我们选择STM32F103C8。注意如果这里没有你找到的型号,说明前面安装的时候没有安装对应的器件支持包,安装一下即可。
10.2.2 在线添加库文件
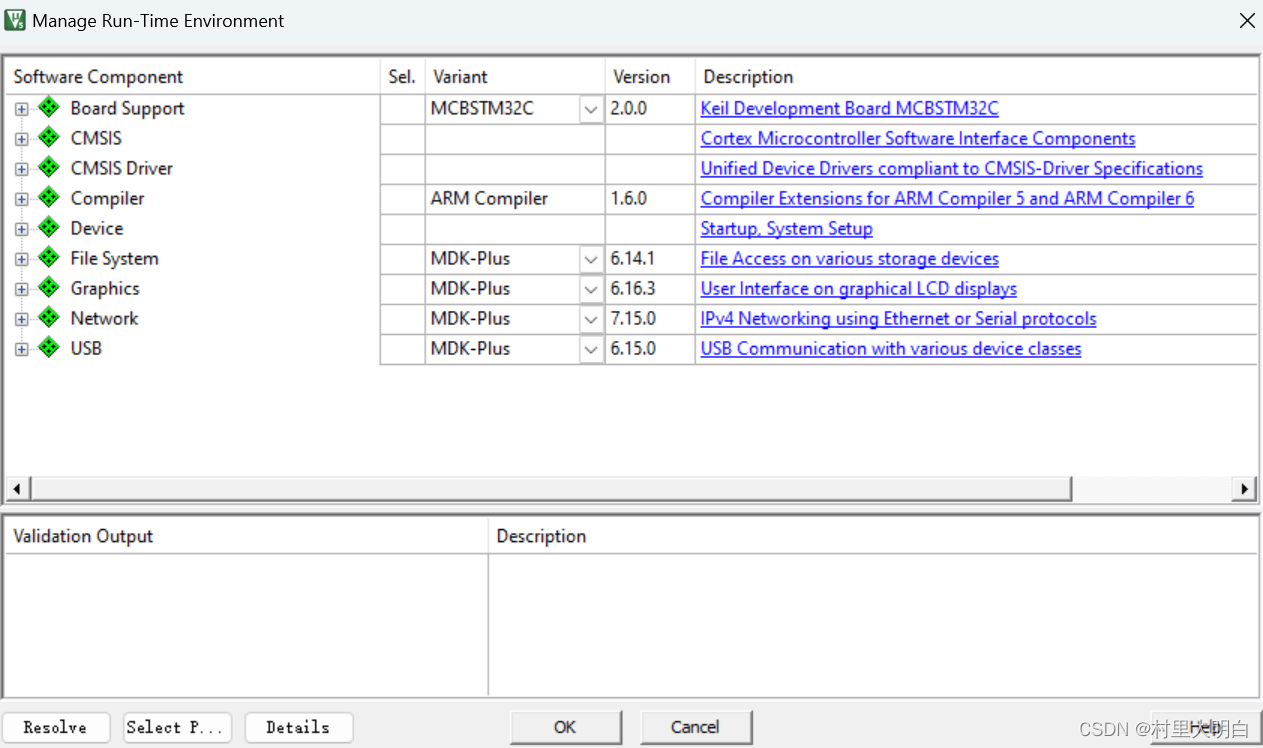
点击 OK后MDK 会弹出 Manage Run-Time Environment 对话框,如图 10.2-3 所示.在这个界面,我们可以添加自己需要的组件,从而方便构建开发环境,这里我们暂时用不到就直接跳过,我们直接点击 Cancel,即可。
10.2.3 生成工程文件结构介绍
此时我们打开我们创建的文件夹,会看到 MDK 在该文件夹下自动创建了 3 个文件夹:
DebugConfig,Listings 和 Objects),如图 10.2-4所示. 这三个文件夹是随着.uvprojx文件创建时自动生成的。
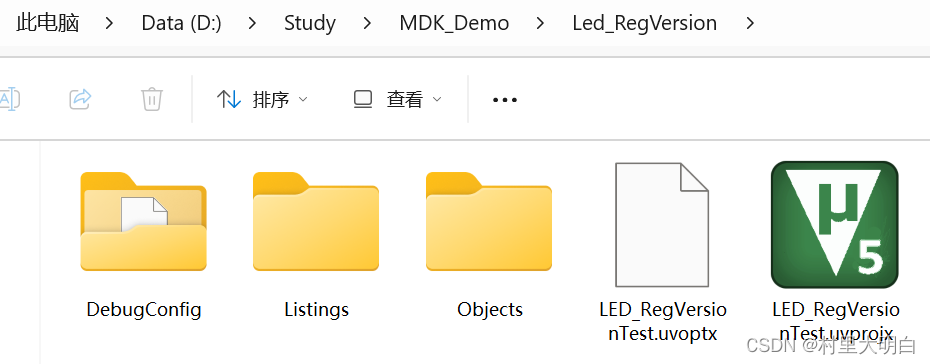
图10.2-4 MDK新建工程时自动创建的文件夹
这三个文件夹的作用如下图10.2-5所示:
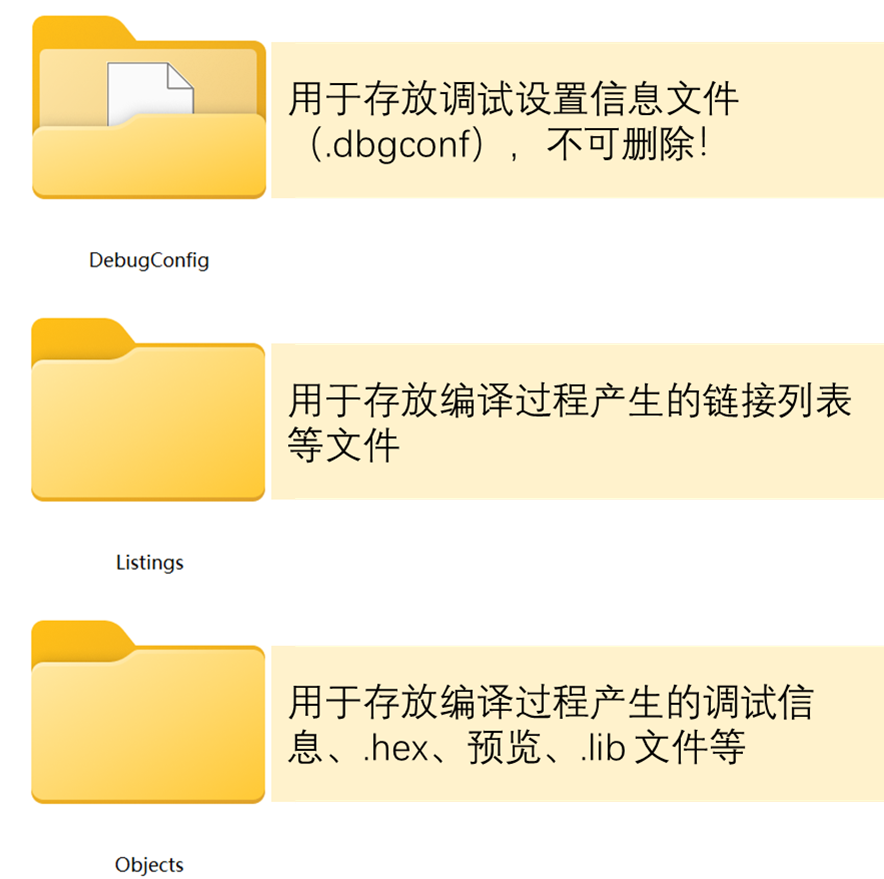
图10.2-5 MDK自动生成的文件夹的作用
10.2.4 添加分组及文件
在Project→Target 上右键,选择 Manage Project Items…或在菜单栏点击品字形红绿白图标进入工程管理界面,如图10.2-6所示:
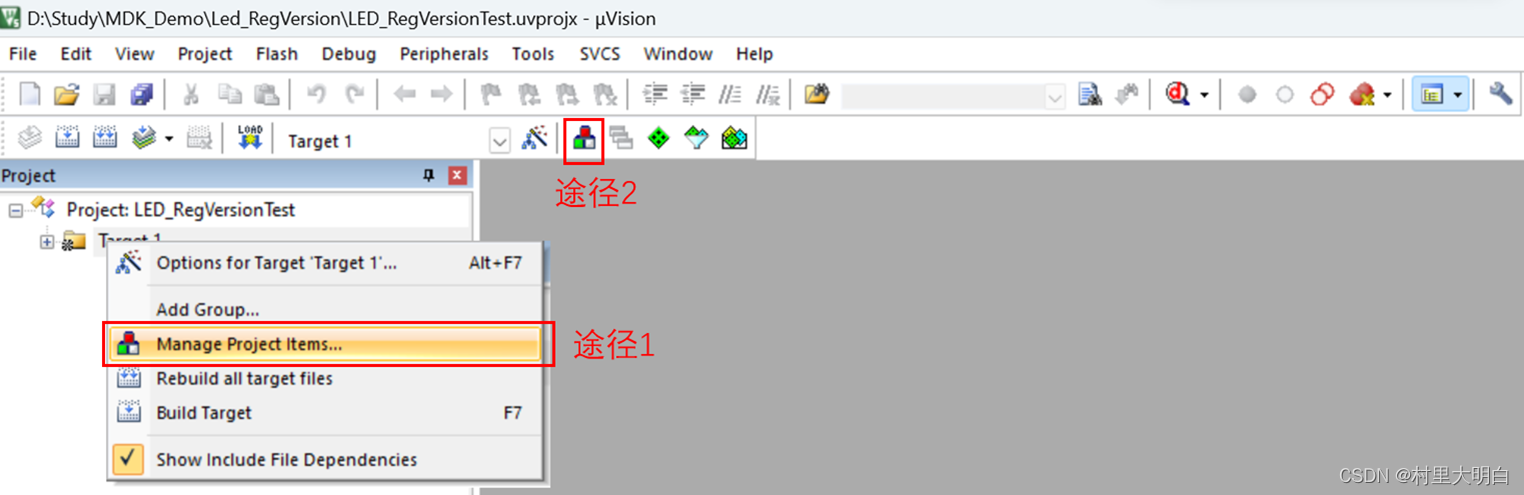
图10.2-6 进入工程管理界面
在工程管理界面,我们可以执行设置工程名字(Project Targets)、分组名字(Groups)以
及添加每个分组的文件(Files)等操作。我们设置工程名字为:Target 1,并设置2个分组:
Startup(存放启动文件)、User(存放 main.c 等用户代码)如图 10.2-7所示:
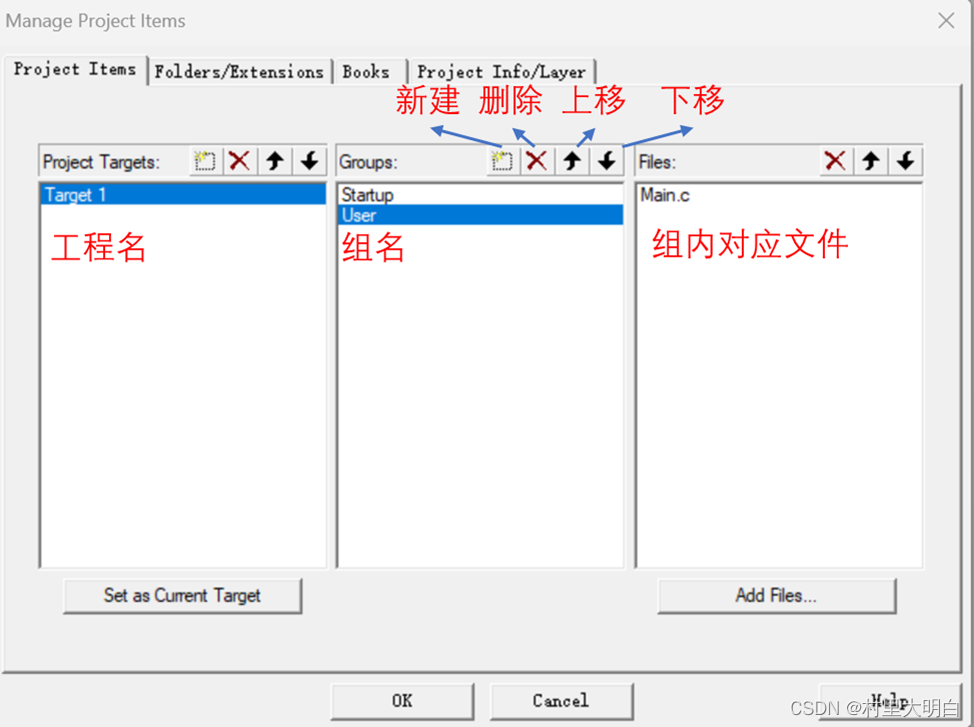
图10.2-7 工程管理配置
在实际使用过程中,我们也经常会在新建的组里右键添加文件,如图10.2-8。
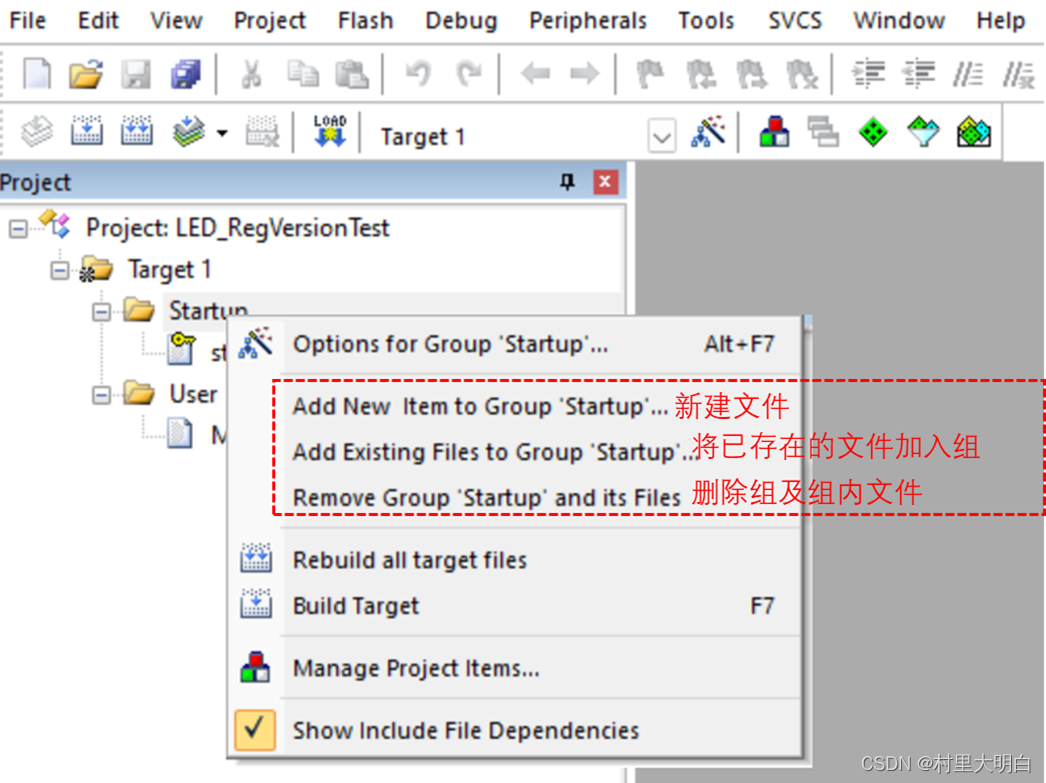
图10.2-8 组新建文件
添加启动文件
启动文件就是,系统上电后第一个运行的程序,由汇编编写。这个文件从标准固件库里面复制过来即可,由官方提供。这个文件我们添加到前面建立的Startup组里去。文件在下面目录,如图10.2-6。 STM32F10x_StdPeriph_Lib_V3.5.0\Libraries\CMSIS\CM3\DeviceSupport\ST\STM32F10x\startup\arm
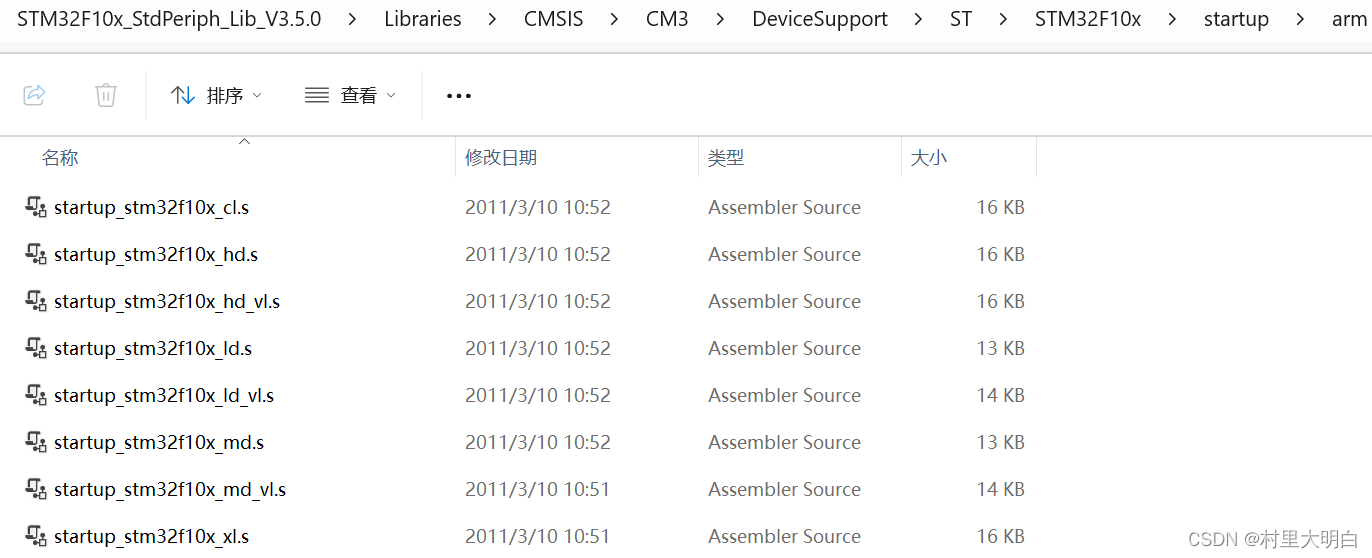
图10.2-6 启动文件
从上图我们可以看到,启动文件有很多,哪个是我们需要的呢?我们可以根据下表10.2-1查找。我们所用的STM32F103C8T6是64K的ROM因此,对应的启动文件是后缀为MD的,即启动文件为:startup_stm32f10x_md.s。我们把这个文件copy到我们新建的文件夹Led_RegVersion之下。
表10.2-1 不同型号STM32缩写
| 缩写 | 含义 | Flash | 型号 |
| LD_VL | 小容量产品超值系列 | 16~32K | STM32F100 |
| MD_VL | 中容量产品超值系列 | 64~128K | STM32F100 |
| HD_VL | 大容量产品超值系列 | 256~512K | STM32F100 |
| LD | 小容量产品 | 16~32K | STM32F101/102/103 |
| MD | 中容量产品 | 64~128K | STM32F101/102/103 |
| HD | 大容量产品 | 256~512K | STM32F101/102/103 |
| XL | 加大容量产品 | 大于512K | STM32F101/102/103 |
| CL | 互联型产品 | - | STM32F105/107 |
添加Main.c文件
用户手动新建,用于存放main 函数,暂时为空。建成后文件夹如图10.2-7所示。这个我们添加到User组里。
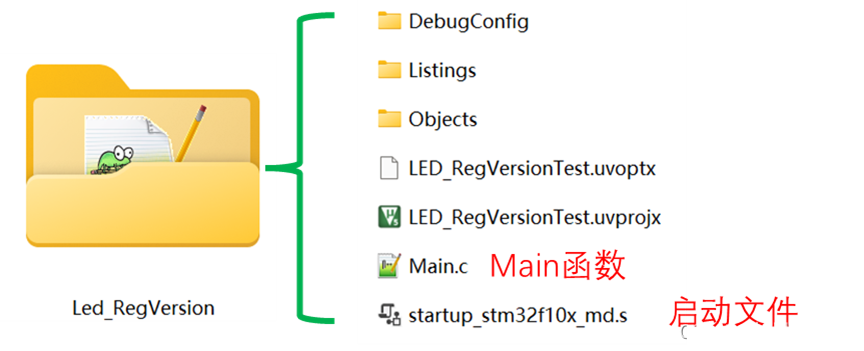
图10.2-7 添加文件后的文件夹
10.3 硬件连接
如图10.3-1,我们把LED 灯的阳极连接到3.3V 电源,阴极各经过1 个限流电阻接到我们使用的STM32最小系统板的PB0口,我们只要控制这PB0引脚输出高/低电平,即可控制所连接LED 灯的亮灭。我们的目标是把GPIO-PB0口的引脚设置成推挽输出模式并且默认下拉,输出低电平,这样就能让LED灯亮起来了。(关于GPIO的模式等问题后面再讲,这里不用管)
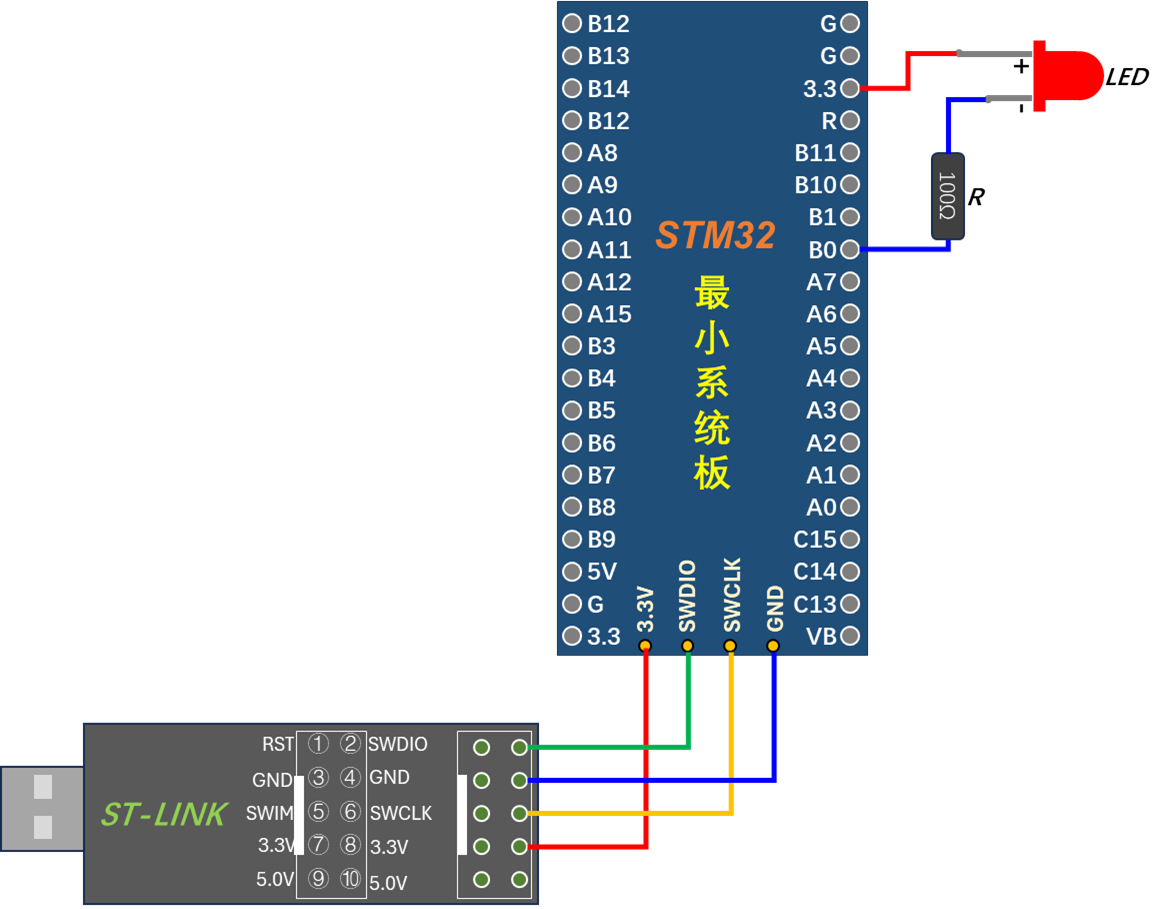
图10.3-1 硬件连接图
10.4 代码编写
10.4.1 启动文件解释
前面名为“startup_stm32f10x_md.s”的文件,它里边使用汇编语言写好了基本程序,当STM32芯片上电启动的时候,首先会执行这里的汇编程序,从而建立起C语言的运行环境,所以我们把这个文件称为启动文件。该文件使用的汇编指令是Cortex-M3内核支持的指令。startup_stm32f10x_md.s文件由官方提供,一般不需要修改。启动文件这部分的主要功能如下:
•初始化堆栈指针SP;
•初始化程序计数器指针PC;
•设置堆、栈的大小;
•初始化中断向量表;
•调用SystemIni()函数配置STM32的系统时钟。
•设置C库的分支入口“__main”(最终用来调用main函数);
这里面对我们来说最重要的是,在启动文件中有一段复位后立即执行的程序,搜索Reset_Handler 即可找到,代码如下:
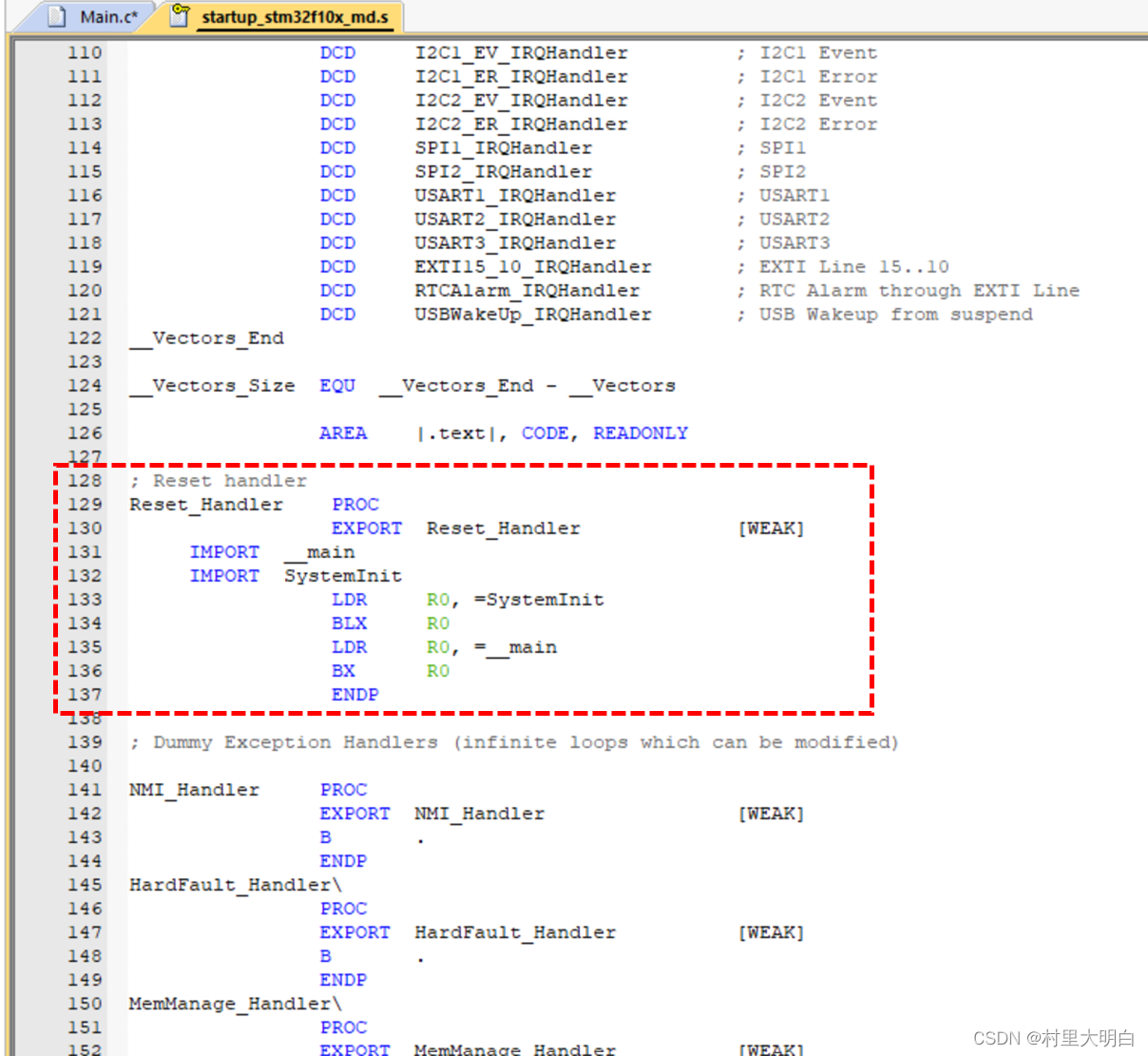
图10.4-1 启动文件中Reset_Handler代码
下面对这段代码进行解析:
; Reset handler
代码含义:程序注释,在汇编里面注释用的是“;”,相当于C 语言的“//”注释符。Reset_Handler PROC
代码含义:
定义了一个子程序:Reset_Handler。PROC 是子程序定义伪指令。这里就相当于C 语言
里定义了一个函数,函数名为Reset_Handler。EXPORT Reset_Handler [WEAK]
代码含义:
EXPORT 表示Reset_Handler 这个子程序可供其他模块调用。相当于C 语言的函数声明。
关键字[WEAK] 表示弱定义,如果编译器发现在别处定义了同名的函数,则在链接时用别处的地
址进行链接,如果其它地方没有定义,编译器也不报错,以此处地址进行链接。IMPORT __main
IMPORT SystemInit
代码含义:
IMPORT 说明SystemInit 和__main 这两个标号在其他文件,在链接的时候需要到
其他文件去寻找。相当于C 语言中,从其它文件引入函数声明。以便下面对外部函数进行调
用。__main其实不是我们定义的(不要与C语言中的main函数混淆),这是一个C库函数,当编译器编译时,只要遇到这个标号就会定义这个函数,该函数的主要功能是:负责初始化栈、堆,配置系统环境,并在函数的最后调用用户编写的main函数,从此来到C的世界。SystemInit是用来配置系统时钟的,这个是官方写好的。
LDR R0, =SystemInit
代码含义:
把SystemInit 的地址加载到寄存器R0。
BLX R0
代码含义:
程序跳转到R0 中的地址执行程序,即执行SystemInit 函数的内容。
LDR R0, =__main
代码含义:
把__main 的地址加载到寄存器R0。
BX R0
代码含义:
程序跳转到R0 中的地址执行程序,即执行__main 函数,执行完毕之后就去到我们熟知的
C 世界,进入main 函数。
ENDP
代码含义:
表示子程序的结束因为我们目前体验的是寄存器版本的MDK工程,我们是假定没有官方支持的,所以我们的函数里是没有SystemInit这个函数的,为了程序不报错,我们有2种处理方法:
1.修改一下启动代码,把SystemInit相关的注释掉。修改后如下:
; Reset handler
Reset_Handler PROC
EXPORT Reset_Handler [WEAK]
IMPORT __main
;IMPORT SystemInit
;LDR R0, =SystemInit
;BLX R0
LDR R0, =__main
BX R0
ENDP2.在我们的C文件函数里编写一个 SystemInit的空函数。
因为启动文件是只读的,改起来麻烦,我们就直接采用写个SystemInit的空函数的方式。
10.4.2 main.c编写
现在我们开始编写我们的程序。除了前面提到的SystemInit的空函数, 我们主要是要配置GPIO-PB0端口,使其输出低电平。这里主要需要配置3个寄存器,分别是:
①开启APB2时钟控制寄存器
②CRL输入输出方式寄存器
③ODR端口输出数据寄存器
这里不太懂没关系,后面我们还会针对GPIO开专题讲解。下面是配置方式:
①开启外设时钟:
由于STM32 的外设很多,为了降低功耗,每个外设都对应着一个时钟,在芯片刚上电的时候这些时钟都是被关闭的,如果想要外设工作,必须把相应的时钟打开。STM32 的所有外设的时钟由一个专门的外设来管理,叫RCC(Reset and ClockControl),RCC 在《STM32 中文参考手册》的第六章。
通过前面章节,我们知道所有的GPIO 都挂载到APB2 总线上,具体的时钟由APB2外设时钟使能寄存器(RCC_ APB2ENR)来控制。
首先我们需要配置RCC_ APB2ENR的地址。关于地址的配置,可以参考本专栏的第5章。
在《STM32 中文参考手册》中RCC寄存器的地址范围,如图10.4-2:

10.4-2 参考手册中RCC寄存器地址范围
由此我们看到,RCC时钟控制寄存器的基地址是0x4002 1000。APB2外设时钟使能寄存器(RCC_ APB2ENR)的描述如下图,我们只用把该寄存器的bit3置1即可开启GPIO-B的时钟。
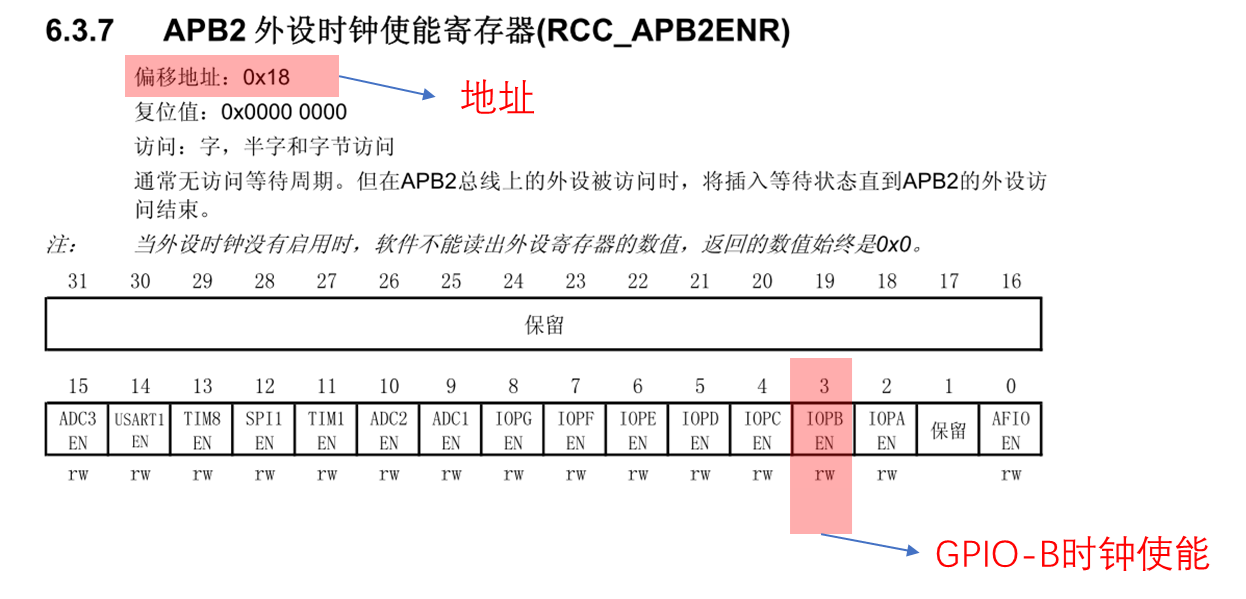
图10.4-3 APB2外设时钟使能寄存器
根据以上信息,相关代码如下,代码中“|=”的目的是不改变其他bit的设置。
/*RCC基地址*/
#define RCC_BASE ((unsigned int) 0x40021000)
/*GPIO_B地址*/
#define RCC_APB2ENR *(unsigned int*)(RCC_BASE+0x18)
RCC_APB2ENR |= 0x00000008;// 开启 GPIOB 端口 时钟②配置输入输出方式:
首先我们把连接到LED灯的GPIO引脚PB0配置成输出模式,即配置GPIO的端口配置低寄存器CRL,见图GPIO端口控制低寄存器CRL。CRL中包含0-7号引脚,每个引脚占用4个寄存器位。MODE位用来配置输出的速度,CNF位用来配置各种输入输出模式。在这里我们把PB0配置为通用推挽输出,输出的速度为10M。
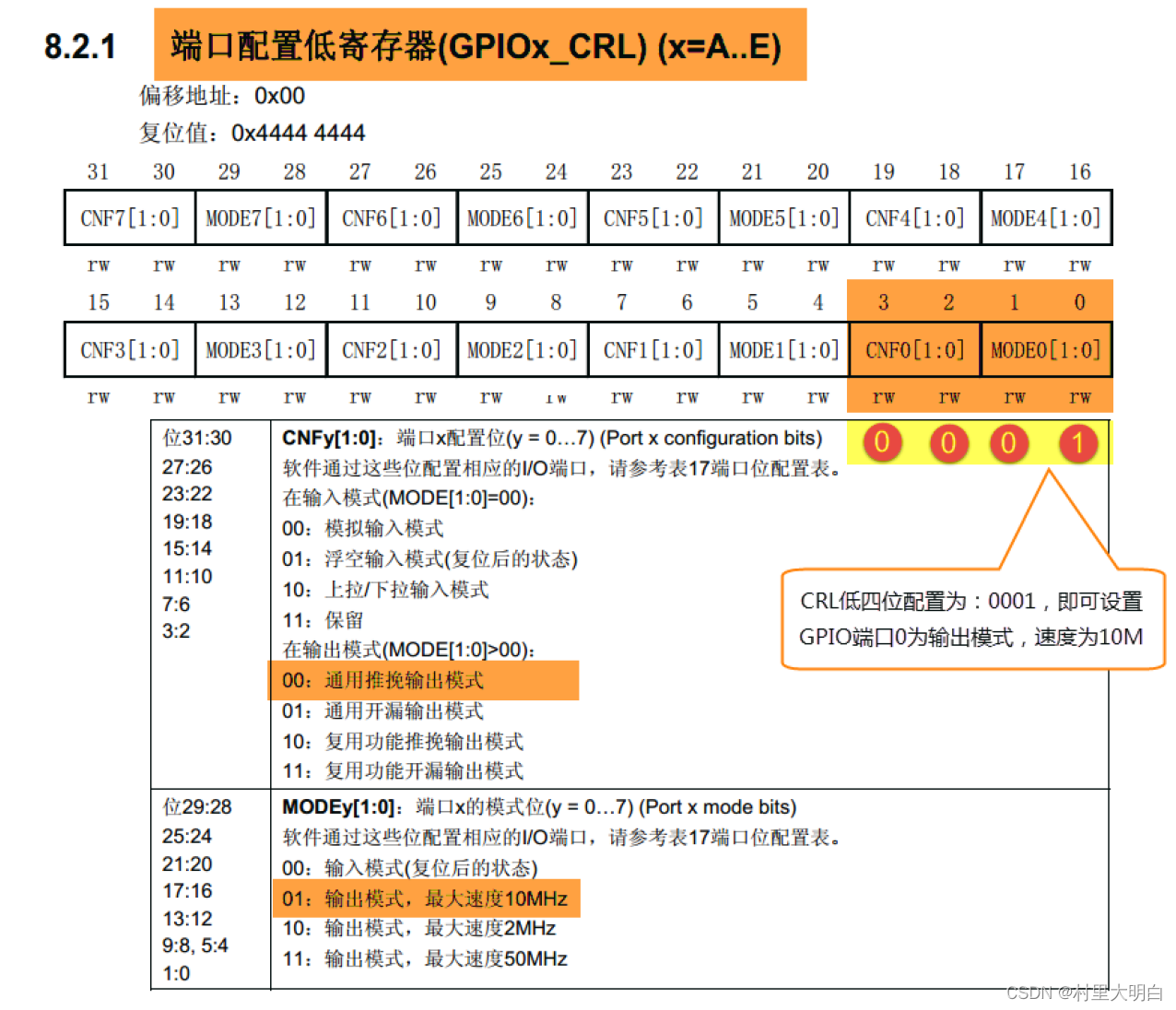
图10.4-4 CRL寄存器配置图
对应代码如下:
/*GPIO-B基地址*/
#define GPIOB_BASE ((unsigned int) 0X40010C00)//可查看参考手册
/*GPIO_B-CRL地址*/
#define GPIOB_CRL *(unsigned int*)(GPIOB_BASE+0x00)
GPIOB_CRL &= ~((unsigned int)0x0000000F);// 清空控制 PB0 的端口位
GPIOB_CRL |= (unsigned int)0x00000001;// 配置 PB0 为通用推挽输出,速度为 10M
③配置端口输出寄存器:
我们在这里直接操作ODR 寄存器来控制GPIO的电平,如图10.4-5.ODR寄存器的配置图。
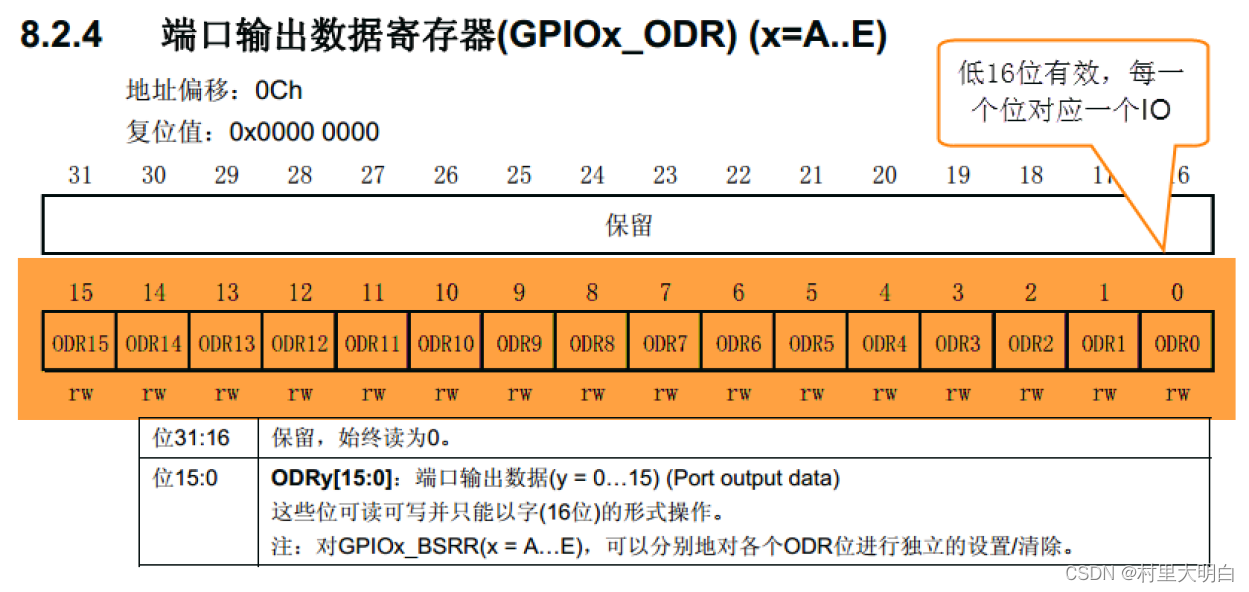
图10.4-6 ODR寄存器配置图
对应代码如下:
/*GPIO_B-CRL地址*/
#define GPIOB_ODR *(unsigned int*)(GPIOB_BASE+0x0C)
GPIOB_ODR &= ~((unsigned int)0x00000001);// PB0 输出低电平至此代码全部写完,完整的代码如下:
/*RCC基地址*/
#define RCC_BASE ((unsigned int) 0x40021000)
/*GPIO_B地址*/
#define RCC_APB2ENR *(unsigned int*)(RCC_BASE+0x18)
/*GPIO-B基地址*/
#define GPIOB_BASE ((unsigned int) 0X40010C00)//可查看参考手册
/*GPIO_B-CRL地址*/
#define GPIOB_CRL *(unsigned int*)(GPIOB_BASE+0x00)
/*GPIO_B-CRL地址*/
#define GPIOB_ODR *(unsigned int*)(GPIOB_BASE+0x0C)
void SystemInit(void);
int main()
{
RCC_APB2ENR |= 0x00000008;// 开启 GPIOB 端口 时钟
GPIOB_CRL &= ~((unsigned int)0x0000000F);// 清空控制 PB0 的端口位
GPIOB_CRL |= (unsigned int)0x00000001;// 配置 PB0 为通用推挽输出,速度为 10M
GPIOB_ODR &= ~((unsigned int)0x00000001);// PB0 输出低电平
while(1)
{
}
}
void SystemInit(void)// 函数为空,目的是为了骗过编译器不报错
{
}
10.5 魔术棒配置
10.5.1 Output 选项卡
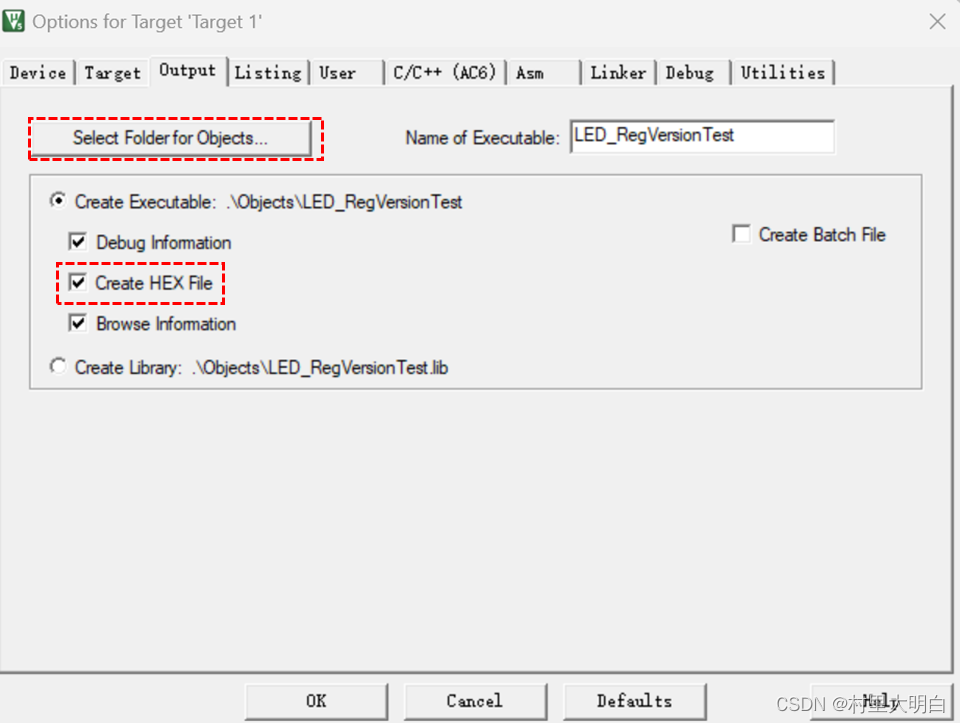
图10.5-1 Output选项卡配置
Output 选项卡主要是选择把输出文件放到哪个文件夹,如果不选择就是系统默认的前面建立工程时自动生成的“Objects”文件夹,也可以自己选择指定文件夹存放。如果想在编译的过程中生成hex 文件,那么那Create HEX File 选项勾上。
10.5.2 Listing选项卡配置
在Listing 选项卡和前面Output类似,如果不选择就是系统默认的前面建立工程时自动生成的“Listings”文件夹,也可以选择自己习惯的文件夹。
10.5.2 下载器配置
在debug选项卡中,我们选择我们使用的下载器STLINK。右边蓝色框点开Debug Settings 选项配置,弹出对话框的“Flash Download”选项卡,把“Reset and Run 也勾选上,这样程序下载完之后就会自动运行,否则需要手动复位”。
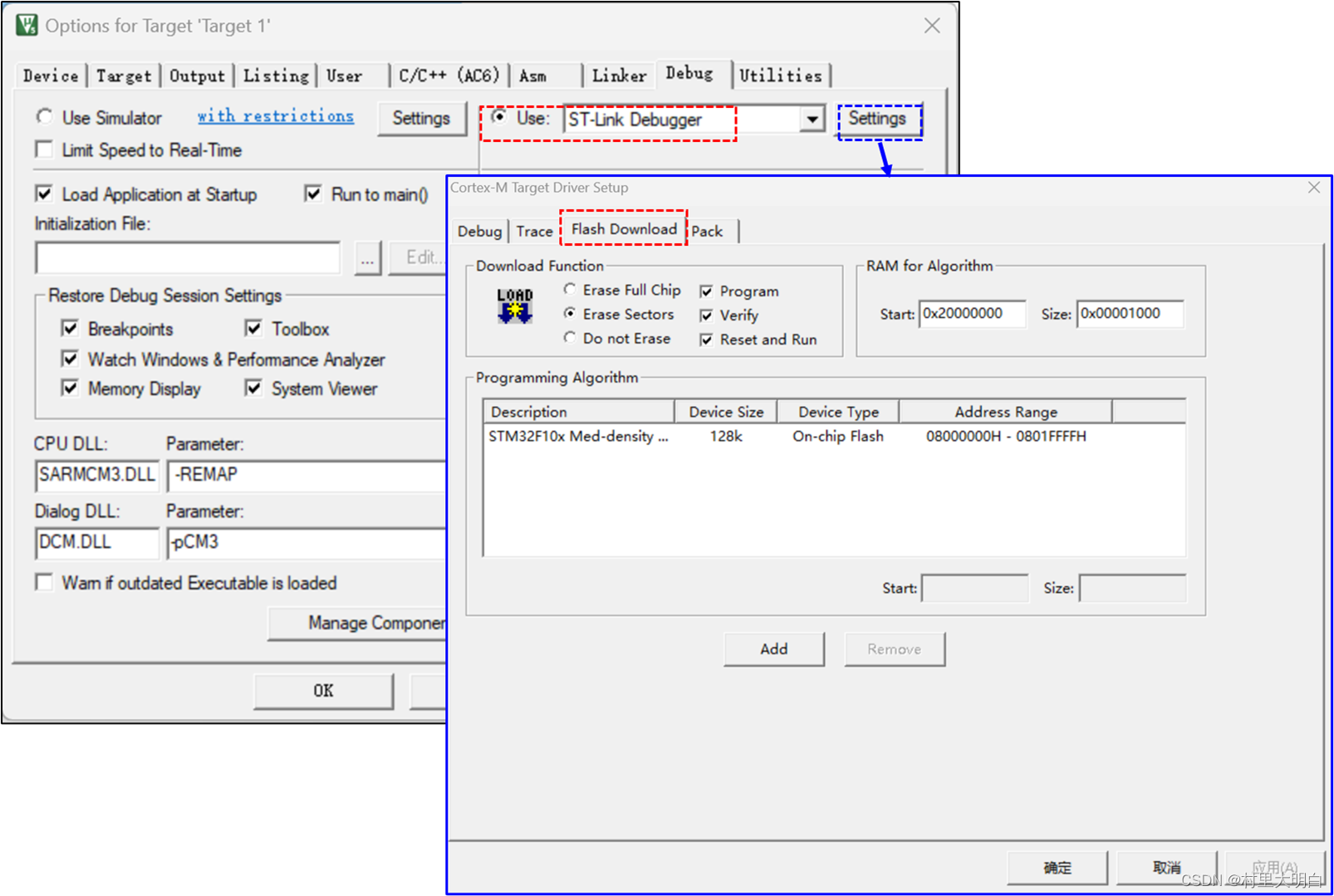
图10.5-2 下载配置
10.6 下载程序
前面步骤都成功后,接下来就是编译,连接最小系统板到电脑,然后下载程序到最小系统板上运行。下载程序不需要其他额外的软件,直接点击KEIL中的LOAD 按钮即可,如图10.6-1。消息栏,出现“Application running…”,则表示代码下载成功,且开始运行 就可以观察实验现象了。

图10.6-1 编译下载
如图10.6-2我们终于点亮了我们第一个LED灯。。。

图10.6-2 实验现象
第11章.创建MDK工程-基于自建库函数
本章在上一节的基础上,介绍如何创建库函数,实现点亮LED灯的MDK工程。 我们上一章用寄存器点亮了LED,代码好像没有几行,看着也很简单,但是我们需要明白,我们点亮LED这个案例功能非常简单,只用了STM32功能的九牛一毛。在用寄存器点亮LED的时候,每次配置写代码的时候都要对照着《STM32F10X-中文参考手册》中寄存器的说明,然后根据说明对每个控制的寄存器位写入特定参数,因此在配置的时候非常容易出错,而且代码可读性不强不好理解,难于维护。所以学习STM32最好的方法是用固件库,然后在固件库的基础上了解底层,学习寄存器。懂得原理后,我们开发自然是用已有的固件库去开发效率最高,也便于维护。
11.1 基于库函数的开发方式
这个问题我们前面第8章已经进行过了介绍,这里再简单提一下。固件库是指“STM32标准函数库”,它是由ST公司针对STM32提供的函数接口,即API(Application Program Interface),开发者可调用这些函数接口来配置STM32的寄存器,使开发人员得以脱离最底层的寄存器操作,有开发快速,易于阅读,维护成本低等优点。当我们调用库API的时候不需要挖空心思去了解库底层的寄存器操作,就像当年我们编程的时候调用某个函数,我们会用就行,并不需要去研究它的源码实现。
简单来讲库就是架设在寄存器与用户驱动层之间的代码,向下处理与寄存器直接相关的配置,向上为用户提供配置寄存器的接口。库开发方式与直接配置寄存器方式的区别见图11.1-1。
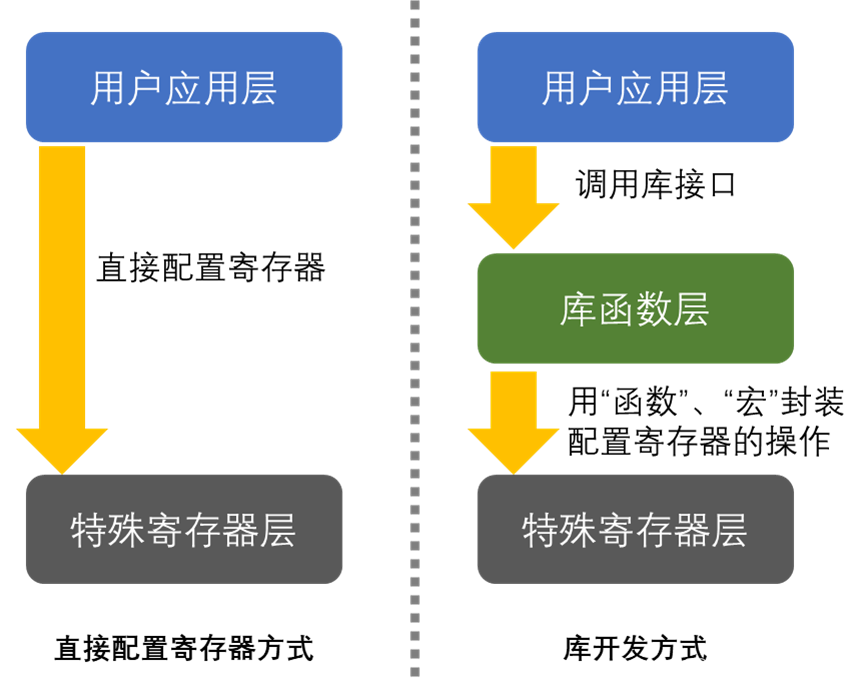
图11.1-1 固件库开发与寄存器开发对比
相对于库开发的方式,直接配置寄存器方式生成的代码量的确会少一点,但因为STM32 有充足的资源,权衡库的优势与不足,绝大部分时候,我们愿意牺牲一点CPU 资源,选择库开发。一般只有在对代码运行时间要求极苛刻的地方,才用直接配置寄存器的方式代替,对于库开发与直接配置寄存器的方式,就好比编程是用汇编好还是用C 好一样。
那么对于STM32的学习哪种方式好呢?有人认为用寄存器好。事实上,库函数的底层实现正是直接配置寄存器的最好例子,它代替我们完成了寄存器配置的工作,而想深入了解芯片是如何工作的,我们只要直接查看库函数的最底层实现就能理解。等我们读懂了库函数的实现方式,一定会为它的严谨和优美的实现方式而倾倒,也是我们学习C语言的极好教材,ST的库实现方式堪称教科书级别的上好资料。所以基于ST库的学习,我们既能学会用寄存器控制STM32,还能学到库函数的封装技巧。
11.2 构建自己的库函数
构建自己的库函数,其实就是把我们上一节中,寄存器地址计算和一些位操作封装起来到一个.c文件或者头文件中。然后用的时候直接调用即可。
如图11.2-1,我们和上节一样的方式创建一个MDK工程,命名为LED_LibVersionTest.在文件夹中新建一个stm32f10x.h的空文件,并添加到Startup组里(或者从startup里右键创建也可以),这个文件用于我们后面编写库函数。如图11.2-2.
图11.2-1 新建库函数的MDK工程
11.2-2 新建自建库函数版MDK工程文件夹
后面我们在上节寄存器点亮LED 的代码上继续完善,把代码一层层封装,实现库的最初的雏形,经过这一步的学习后,我们对库的理解和运用会更加深入。本节主要是实现GPIO的函数库,其他外设大同小异,我们直接参考ST标准库即可,不必自己写,懂得原理就够了。
下面的代码都是标准库里的,我们只是摘出来,了解库的建立过程。举一反三,道理都是一样的。
11.2.1 头文件的常见操作
在开始后面内容之前我们先讲一个C编程的常见知识点。假如我们编写了一个.c文件,文件中的变量或者函数,是可能被其他文件调用的,我们一般会相应创建一个同名的.h文件,用以对这个.c文件的声明。例如我们创建了一个head.c文件,对应的我们要新建一个head.h文件。而在head.h文件里,开头的语句一般都是固定的防重复包含的预处理指令#ifndef,#define,#endif语句。如下代码所示:
#ifndef __HEAD_H
#define __HEAD_H
// ... 这里是头文件的内容,比如函数声明、结构体定义等 ...
#endif // __HEAD_H在C语言(以及C++)中,使用#ifndef、#define和#endif预处理指令来防止头文件被多次包含(也称为“包含守卫”或“头文件保护”)是一种常见的做法。这样做的目的是避免在编译时因多次包含同一个头文件而导致的重复定义错误。
具体来说,#ifndef __HEAD_H检查是否已定义了名为__HEAD_H的宏。如果没有定义(即这是第一次包含该头文件),则编译器会执行#define __HEAD_H,定义这个宏,并继续处理头文件中的其余内容。如果__HEAD_H已经被定义(即这不是第一次包含该头文件),则编译器会跳过头文件中的其余内容,从而避免了重复定义。
注意:宏名(如__HEAD_H)通常是大写的,并且包含双下划线前缀和后缀,以避免与程序中的其他标识符冲突。
11.2.2 外设寄存器结构体定义
上一章我们在操作寄存器的时候,是查到寄存器的绝对地址后,挨个进行配置,如果每个外设寄存器都这样操作,那就太麻烦了。从前面第5章,我们知道外设寄存器的地址都是基于外设基地址加偏移地址,都是在外设基地址上逐个连续递增的,每个寄存器占32 个字节,这种方式跟结构体里面的成员类似。因此我们可以定义一种外设结构体,结构体的地址等于外设的基地址,结构体的成员等于寄存器,成员的排列顺序跟寄存器的顺序一样。这样我们操作寄存器的时候就不用每次都找到绝对地址,只要知道外设的基地址就可以操作外设的全部寄存器,即操作结构体的成员即可。
在工程中的“stm32f10x.h”文件中,我们使用结构体封装GPIO 及RCC 外设的的寄存器,代码如下。结构体成员的顺序按照寄存器的偏移地址从低到高排列,成员类型跟寄存器类型一样。
//volatile 表示易变的变量,防止编译器优化,
#define __IO volatile
typedef unsigned int uint32_t;
typedef unsigned short uint16_t;
// GPIO 寄存器结构体定义
typedef struct
{
__IO uint32_t CRL; // 端口配置低寄存器, 地址偏移 0X00
__IO uint32_t CRH; // 端口配置高寄存器, 地址偏移 0X04
__IO uint32_t IDR; // 端口数据输入寄存器, 地址偏移 0X08
__IO uint32_t ODR; // 端口数据输出寄存器, 地址偏移 0X0C
__IO uint32_t BSRR; // 端口位设置/清除寄存器,地址偏移 0X10
__IO uint32_t BRR; // 端口位清除寄存器, 地址偏移 0X14
__IO uint32_t LCKR; // 端口配置锁定寄存器, 地址偏移 0X18
} GPIO_TypeDef;图11.2-3 寄存器结构体定义
代码中结构体成员前增加了前缀“__IO”,代码的第一行#define__IO volatile,指定了C语言中的关键字“volatile”,含义是要求编译器不要优化,这个在前面《第2章.STM32开发C语言常用知识点》已有介绍。
11.2.3 外设存储器映射
外设寄存器结构体定义之后,下一步就是把寄存器地址跟结构体的地址对应起来。映射的方法在上一节以及《第5章.STM32F1x的寄存器和存储器》里已经有提及。这块代码如下:
/*片上外设基地址 */
#define PERIPH_BASE ((unsigned int)0x40000000)
/*APB2 总线基地址 */
#define APB2PERIPH_BASE (PERIPH_BASE + 0x10000)
/* AHB 总线基地址 */
#define AHBPERIPH_BASE (PERIPH_BASE + 0x20000)
/*GPIO 外设基地址*/
#define GPIOA_BASE (APB2PERIPH_BASE + 0x0800)
#define GPIOB_BASE (APB2PERIPH_BASE + 0x0C00)
#define GPIOC_BASE (APB2PERIPH_BASE + 0x1000)
#define GPIOD_BASE (APB2PERIPH_BASE + 0x1400)
#define GPIOE_BASE (APB2PERIPH_BASE + 0x1800)
#define GPIOF_BASE (APB2PERIPH_BASE + 0x1C00)
#define GPIOG_BASE (APB2PERIPH_BASE + 0x2000)
/*RCC 外设基地址*/
#define RCC_BASE (AHBPERIPH_BASE + 0x1000) 11.2.4 外设声明
实现完外设存储器映射后,我们再把外设的基地址进行强制类型转换,转换为我们前面定义的外设寄存器结构体指针类型,然后再把该指针声明成外设名,外设名(即寄存器结构体指针)就跟外设的地址对应起来了,通过该外设名可以直接操作该外设的全部寄存器,代码如下:
/* GPIO 外设声明 */
#define GPIOA ((GPIO_TypeDef *) GPIOA_BASE)
#define GPIOB ((GPIO_TypeDef *) GPIOB_BASE)
#define GPIOC ((GPIO_TypeDef *) GPIOC_BASE)
#define GPIOD ((GPIO_TypeDef *) GPIOD_BASE)
#define GPIOE ((GPIO_TypeDef *) GPIOE_BASE)
#define GPIOF ((GPIO_TypeDef *) GPIOF_BASE)
#define GPIOG ((GPIO_TypeDef *) GPIOG_BASE)
/*RCC 外设声明 */
#define RCC ((RCC_TypeDef *) RCC_BASE)
/*RCC 的 AHB1 时钟使能寄存器地址,强制转换成指针*/
#define RCC_APB2ENR *(unsigned int*)(RCC_BASE+0x18) 下面开始,我们就对上节main.c函数中出现的操作函数,一一进行函数定义,再写main.c的时候,就可以直接调用。
11.2.5 GPIO的位操作函数
现在我们在组“Startup”里再新建2个文件,分别是stm32f10x_gpio.c和stm32f10x_gpio.h。操作方法如下图11.2-4.
图 11.2-4 新建.c和.h文件
把上节Main函数中对GPIO外设操作的函数及其宏定义分别存放在stm32f10x_gpio.c和stm32f10x_gpio.h文件中。可以理解为.c文件是用来描述函数的具体的实现方式,.h文件是对这些.c里定义的函数或变量的全局声明。也就是这2个文件都是和GPIO相关的。
在上一节我们把PB0设置为0的时候,是通过把GPIO的ODR寄存器对应端口直接写入值实现,我们也可以通过BSRR和BRR寄存器对相应位进行置位或清除操作。
11.2.5.1 位设置函数

图11.2-5 STM32F10X-中文参考手册中位设置/清除寄存器BSRR说明
如上图是BSRR端口设置/清除寄存器的说明, 我们如果要设置PB0为1,只需要设置BSRR寄存器的0位为1即可,即:
GPIOB->BSRR |= 0x0001;如果是设置第二位为1就是, GPIOB->BSRR |= 0x0002;第三位就是GPIOB->BSRR |= 0x0004;我们这里会发现一个问题,就是0x0002等不够形象,我们如果用宏定义,用对应的Pin名称来代替就会好很多,于是我们可以这么操作,在stm32f10x_gpio.h对各pin做如下宏定义:
#define GPIO_Pin_0 ((uint16_t)0x0001) //Pin0 即(00000000 00000001)b
#define GPIO_Pin_1 ((uint16_t)0x0002) //Pin1 即(00000000 00000010)b
#define GPIO_Pin_2 ((uint16_t)0x0004) //Pin2 即(00000000 00000100)b
#define GPIO_Pin_3 ((uint16_t)0x0008) //Pin3 即(00000000 00001000)b
#define GPIO_Pin_4 ((uint16_t)0x0010) //Pin4 即(00000000 00010000)b
#define GPIO_Pin_5 ((uint16_t)0x0020) //Pin5 即(00000000 00100000)b
#define GPIO_Pin_6 ((uint16_t)0x0040) //Pin6 即(00000000 01000000)b
#define GPIO_Pin_7 ((uint16_t)0x0080) //Pin7 即(00000000 10000000)b
#define GPIO_Pin_8 ((uint16_t)0x0100) //Pin8 即(00000001 00000000)b
#define GPIO_Pin_9 ((uint16_t)0x0200) //Pin9 即(00000010 00000000)b
#define GPIO_Pin_10 ((uint16_t)0x0400) //Pin10 即(00000100 00000000)b
#define GPIO_Pin_11 ((uint16_t)0x0800) //Pin11 即(00001000 00000000)b
#define GPIO_Pin_12 ((uint16_t)0x1000) //Pin12 即(00010000 00000000)b
#define GPIO_Pin_13 ((uint16_t)0x2000) //Pin13 即 (00100000 00000000)b
#define GPIO_Pin_14 ((uint16_t)0x4000) //Pin14 即(01000000 00000000)b
#define GPIO_Pin_15 ((uint16_t)0x8000) //Pin15 即(10000000 00000000)b 在stm32f10x_gpio. c中定义位设置函数GPIO_SetBits如下:
void GPIO_SetBits(GPIO_TypeDef *GPIOx,uint16_t GPIO_Pin)
{
/*
$函数功能:设置GPIOx对应引脚为高电平
$参数说明:
@GPIOx: 该参数为 GPIO_TypeDef 类型的指针,指向GPIO 端口的地址
@GPIO_Pin: 选择要设置的 GPIO 端口引脚,可输入GPIO_Pin_0-15,表示 GPIOx 端口 0-15 号引脚
*/
GPIOx->BSRR |= GPIO_Pin;
}11.2.5.2 位清除函数
位清除函数和位设置函数的操作方式一样,只是需要操作BRR寄存器,如图11.2-6. 这里不再赘述。

图11.2-6 STM32F10X-中文参考手册中位清除寄存器BRR说明
在stm32f10x_gpio. c中定义位设置函数GPIO_ResetBits如下:
void GPIO_ResetBits( GPIO_TypeDef *GPIOx,uint16_t GPIO_Pin )
{
/*
$函数功能:设置GPIOx对应引脚为低电平
$参数说明:
@GPIOx: 该参数为 GPIO_TypeDef 类型的指针,指向GPIO 端口的地址
@GPIO_Pin: 选择要设置的 GPIO 端口引脚,可输入GPIO_Pin_0-15,表示 GPIOx 端口 0-15 号引脚
*/
GPIOx->BRR |= GPIO_Pin;
}
11.2.6 定义GPIO初始化函数
上一节我们知道,除了位操作,还有GPIO工作模式以及速度等的设置。下面我们开始这一部分的功能设计。设计的核心思想其实就是用“名称”去替代那些难以记忆的数字,把一切操作尽量都做到“名称化”,只要看到名称就知道是什么意思,提高代码的可读性和可操作性,不用再每写一个功能就去不停地翻看参考手册。
那么根据前面一节main.c中这部分的代码,需要“名称化”的内容主要有:GPIO引脚,GPIO速度,GPIO工作模式,以及GPIO的初始化函数。GPIO引脚前面已经实现了,这里就不讲了。
11.2.6.1 GPIO初始化结构体
为方便后续的GPIO初始化,我们有必要声明一个名为GPIO_InitTypeDef的结构体类型。 我们在头文件stm32f10x_gpio.h中进行如下定义:
typedef struct
{
uint16_t GPIO_Pin; // 选择要配置的 GPIO 引脚
uint16_t GPIO_Speed; // 选择 GPIO 引脚的速率
uint16_t GPIO_Mode; // 选择 GPIO 引脚的工作模式
}GPIO_InitTypeDef;定义这个结构体之后,我们以后在初始化某个GPIO前,就可以先定义一个这样的结构体变量,根据需要配置的GPIO模式,对这个结构体的成员进行赋值,最后再把这个变量作为“GPIO初始化函数”的输入参数,该函数能根据这个输入参数值中的内容去配置相应寄存器,从而实现了GPIO的初始化操作。
但是我们上述定义的结构体类型,速率和模式仍使用“uint16_t”类型,那么成员值还得输入数字,赋值时还需要查询参考手册的寄存器说明。而实际上像速度和模式只能输入几个固定的数值。我们如何解决这个问题呢,让代码看上去既形象又不易出错?答案就是使用枚举类型。枚举类型可以对结构体成员起到限定输入的作用,只能输入相应已定义的枚举值,而且比较形象,见名知意。
下面我们就对GPIO的速率和工作模式进行枚举类型定义。
11.2.6.2 定义引脚模式的枚举类型
在上一节中,我们知道GPIO的PB0的工作模式和速率是在CRL寄存器配置的,CRL控制GPIOB的低8位,CRH控制高8位,因为我们用的是0位,这里方便起见,我们就只配置CRL。

图.11.2-7 CRL寄存器配置图
GPIO_Speed枚举类型:
由上图11.2-7可见,GPIO_Speed主要有10MHZ,2MHZ,50MHZ三个值,分别对应二进制数0b01,0b10,0b11,对应十进制的1,2,3.那么定义枚举类型就非常简单了,我们在 stm32f10x_gpio.h中做如下定义:
typedef enum
{
GPIO_Speed_10MHz = 1, // 10MHZ:(01)b
GPIO_Speed_2MHz, // 2MHZ :(10)b
GPIO_Speed_50MHz // 50MHZ : (11)b
}GPIOSpeed_TypeDef;如上代码中,枚举类型的定义中,第一个给出数字后,后面的如果是比前面得都大1,那么后面的枚举定义可以不用再写“=多少” ,当然写上也是无所谓的。如果不是这种后面比前面大1的关系,就必须每个都进行赋值。
GPIO_Mode枚举类型:
工作模式的枚举类型定义就比较难理解一些,我们先看代码,代码我们也是直接参考标准库。
typedef enum
{ GPIO_Mode_AIN = 0x0, // 模拟输入 (0000 0000)b
GPIO_Mode_IN_FLOATING = 0x04, // 浮空输入 (0000 0100)b
GPIO_Mode_IPD = 0x28, // 下拉输入 (0010 1000)b
GPIO_Mode_IPU = 0x48, // 上拉输入 (0100 1000)b
GPIO_Mode_Out_OD = 0x14, // 开漏输出 (0001 0100)b
GPIO_Mode_Out_PP = 0x10, // 推挽输出 (0001 0000)b
GPIO_Mode_AF_OD = 0x1C, // 复用开漏输出 (0001 1100)b
GPIO_Mode_AF_PP = 0x18 // 复用推挽输出 (0001 1000)b
}GPIOMode_TypeDef;单纯从定义的这些数值,我们很难发现什么规律,可以说之所以这么定义,完全是人为的,在便于理解的前提下通过后续我们编写的函数实现引脚的初始化配置。也就是根据我们人为指定的这个枚举类型,进行工作模式的配置。在引脚的初始化中引脚工作模式和速率是都要指定和配置的,这2个要结合起来看。为了便于理解,整理如下图11.2-8,转化成二进制之后,就比较容易发现规律。
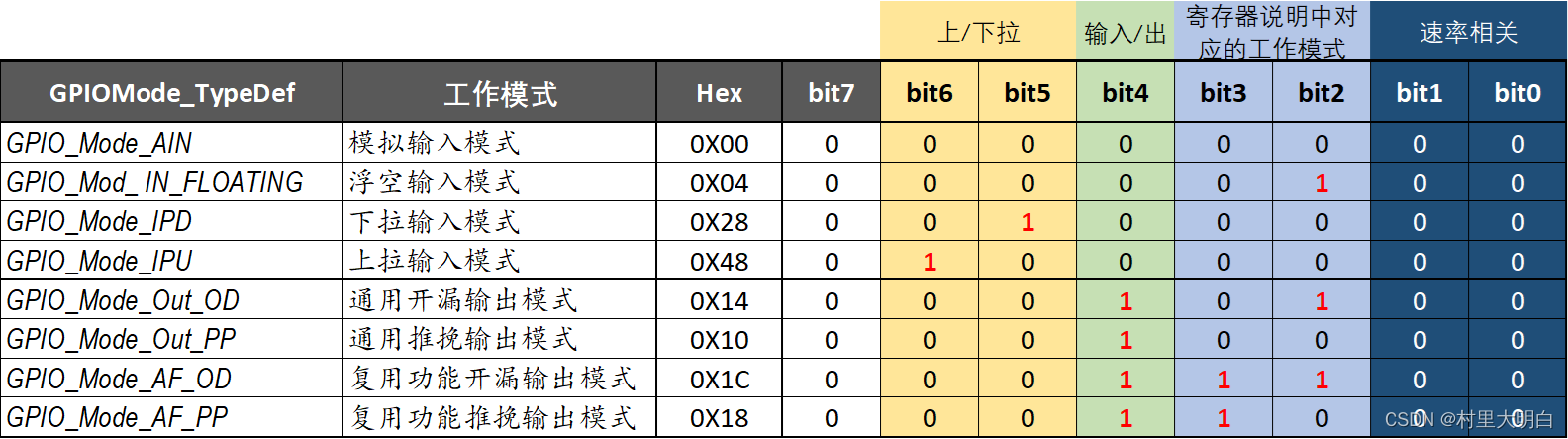
图11.2-8 GPIO 引脚工作模式真值表
这个表里的高4位是人为定义的,可以根据个人习惯随意配置,仅仅是为了后续的GPIO初始化函数方便区分,真正要写进寄存器的是bit2和bit3,对应寄存器的CNFY[1:0]位,是我们真正要写入到CRL这个端口控制寄存器中的值。而bit1和bit0之所以都配置为0,主要是后续GPIO的初始化函数里,这2位是由前面的GPIO_Speed定义的。 bit4用来区分端口是输入还是输出,0表示输入,1表示输出。其中在下拉输入和上拉输入中我们设置 bit5 和 bit6 的值为 01 和 10 来以示区别。
至此,我们就可以对上节的GPIO初始化结构体,再进行改进。 我们的 GPIO_InitTypeDef 结构体就可以使用枚举类型来限定输入参数,也更形象。代码修改如下,unit16_t就可以替换为枚举类型了:
typedef struct
{
uint16_t GPIO_Pin;
GPIOSpeed_TypeDef GPIO_Speed;
GPIOMode_TypeDef GPIO_Mode;
}GPIO_InitTypeDef;11.2.6.3 定义GPIO 初始化函数
在开始写函数之前,需要首先讲一个知识点,否则代码就会看的云里雾里。如前面“图11.2-7 CRL寄存器配置图”,这里面上拉和下拉输入对应的CNF位都是10,并没有说明是怎么配置实现区分的。实际上是而是通过写BSRR 或者 BRR寄存器来实现的。
*下拉输入模式,引脚默认置0,对BRR寄存器写1对引脚置0;
*上拉输入模式,引脚默认值为1,对BSRR寄存器写1对引脚置1;
代码如下:
void GPIO_Init(GPIO_TypeDef* GPIOx, GPIO_InitTypeDef* GPIO_InitStruct)
{
/*
* 函数功能:初始化引脚模式
* 参数说明:GPIOx,该参数为 GPIO_TypeDef 类型的指针,指向 GPIO 端口的地址
* GPIO_InitTypeDef:GPIO_InitTypeDef 结构体指针,指向初始化变量
*/
uint32_t currentmode = 0x00, currentpin = 0x00, pinpos = 0x00, pos = 0x00;
uint32_t tmpreg = 0x00, pinmask = 0x00;
/*---------------------- GPIO 模式配置 --------------------------*/
// 把输入参数GPIO_Mode的低四位暂存在currentmode
currentmode = ((uint32_t)GPIO_InitStruct->GPIO_Mode) & ((uint32_t)0x0F);
// 判断bit4是1还是0,即首选判断是输入还是输出模式,bit4是1表示输出,bit4是0则是输入
if ((((uint32_t)GPIO_InitStruct->GPIO_Mode) & ((uint32_t)0x10)) != 0x00)
{
// 输出模式则要设置输出速度
currentmode |= (uint32_t)GPIO_InitStruct->GPIO_Speed;
}
/*-------------GPIO CRL 寄存器配置 CRL寄存器控制着低8位IO- -------*/
// 配置端口低8位,即Pin0~Pin7
if (((uint32_t)GPIO_InitStruct->GPIO_Pin & ((uint32_t)0x00FF)) != 0x00)
{
// 先备份CRL寄存器的值
tmpreg = GPIOx->CRL;
// 循环,从Pin0开始配对,找出具体的Pin
for (pinpos = 0x00; pinpos < 0x08; pinpos++)
{
// 令pos与输入参数GPIO_PIN作位与运算,为下面的判断作准备
currentpin = (GPIO_InitStruct->GPIO_Pin) & ( ((uint32_t)0x01) << pinpos);
//找到使用的引脚
if (currentpin !=0)
{
pos = pinpos << 2;// pinpos的值左移两位,相等于乘以4,因为寄存器中4个寄存器位配置一个引脚
//把控制这个引脚的4个寄存器位清零,其它寄存器位不变
pinmask = ((uint32_t)0x0F) << pos;
tmpreg &= ~pinmask;
// 向寄存器写入将要配置的引脚的模式
tmpreg |= (currentmode << pos);
// 判断是否为下拉输入模式
if (GPIO_InitStruct->GPIO_Mode == GPIO_Mode_IPD)
{
// 下拉输入模式,引脚默认置0,对BRR寄存器写1可对引脚置0,因为配置为0无影响,可以直接用=覆盖其他位,也可以用|=
GPIOx->BRR = (((uint32_t)0x01) << pinpos);
}
else
{
// 判断是否为上拉输入模式
if (GPIO_InitStruct->GPIO_Mode == GPIO_Mode_IPU)
{
// 上拉输入模式,引脚默认值为1,对BSRR寄存器写1可对引脚置1,因为配置为0无影响,可以直接用=覆盖其他位,也可以用|=
GPIOx->BSRR = (((uint32_t)0x01) << pinpos);
}
}
}
}
// 把前面处理后的暂存值写入到CRL寄存器之中
GPIOx->CRL = tmpreg;
}
/*-------------GPIO CRH 寄存器配置 CRH寄存器控制着高8位IO- -----------*/
// 配置端口高8位,即Pin8~Pin15
if (GPIO_InitStruct->GPIO_Pin > 0x00FF)
{
// 先备份CRH寄存器的值
tmpreg = GPIOx->CRH;
// 循环,从Pin8开始配对,找出具体的Pin
for (pinpos = 0x00; pinpos < 0x08; pinpos++)
{
// pos与输入参数GPIO_PIN作位与运算
currentpin = (GPIO_InitStruct->GPIO_Pin) & ((((uint32_t)0x01) << (pinpos + 0x08)));
//找到使用的引脚
if (currentpin !=0)
{
//pinpos的值左移两位(乘以4),因为寄存器中4个寄存器位配置一个引脚
pos = pinpos << 2;
//把控制这个引脚的4个寄存器位清零,其它寄存器位不变
pinmask = ((uint32_t)0x0F) << pos;
tmpreg &= ~pinmask;
// 向寄存器写入将要配置的引脚的模式
tmpreg |= (currentmode << pos);
// 判断是否为下拉输入模式
if (GPIO_InitStruct->GPIO_Mode == GPIO_Mode_IPD)
{
// 下拉输入模式,引脚默认置0,对BRR寄存器写1可对引脚置0
GPIOx->BRR = (((uint32_t)0x01) << (pinpos + 0x08));
}
// 判断是否为上拉输入模式
if (GPIO_InitStruct->GPIO_Mode == GPIO_Mode_IPU)
{
// 上拉输入模式,引脚默认值为1,对BSRR寄存器写1可对引脚置1
GPIOx->BSRR = (((uint32_t)0x01) << (pinpos + 0x08));
}
}
}
// 把前面处理后的暂存值写入到CRH寄存器之中
GPIOx->CRH = tmpreg;
}
}下图是对程序中循环体的解释说明:

图11.2-9 程序循环体说明
11.3 基于自己构建库函数的主程序
完成以上工作后,我们就可以基于自己写的库函数,点亮LED。为和上次寄存器版本的做区分,这次我们点亮PB1端口。
int main()
{
RCC_APB2ENR |= 0x00000008;// 开启 GPIOB 端口 时钟
// 定义一个 GPIO_InitTypeDef 类型的结构体
GPIO_InitTypeDef GPIO_InitStructure;
GPIO_InitStructure.GPIO_Pin = GPIO_Pin_1; // 选择要控制的 GPIO 引脚
GPIO_InitStructure.GPIO_Mode = GPIO_Mode_Out_PP; // 设置引脚模式为通用推挽输出
GPIO_InitStructure.GPIO_Speed = GPIO_Speed_50MHz; // 设置引脚速率为 50MHz
// 调用库函数,初始化 GPIO 引脚
GPIO_Init(GPIOB, &GPIO_InitStructure);
// 使引脚输出低电平,点亮 LED1
GPIO_ResetBits(GPIOB,GPIO_Pin_1);
while(1)
{
}
}因为只是为了讲解原理,为使篇幅不至太长,上述代码中,RCC部分我们还没有构建函数,但道理是一样的,有兴趣的朋友可以自己尝试一下。
11.4 程序现象
编译下载后,LED成功点亮,如图11.4-1.

图11.4-1 程序现象
相关程序文件已上传资源:
参考资料:
【1】哔站江协科技STM32入门教程
【2】《STM32单片机原理与项目实战》刘龙、高照玲、田华著
【3】《ARM Cortex-M3嵌入式原理及应用》黄可亚著
【4】《STM32嵌入式微控制器快速上手》陈志旺著
【5】《STM32单片机应用与全案例实践》沈红卫等著
【6】《野火STM32开发指南》
【7】《正点原子STM32开发指南》