说明:这是一个机器学习实战项目(附带数据+代码+文档+视频讲解),如需数据+代码+文档+视频讲解可以直接到文章最后关注获取。

1.项目背景
近年来,深度学习技术在计算机视觉、语音识别、自然语言处理等领域取得了显著的成功。卷积神经网络(CNN)作为深度学习的一个重要分支,因其在图像处理任务上的出色表现而备受关注。然而,CNN模型的训练是一个极其复杂的优化问题,尤其是当网络层数增加或数据集规模扩大时,训练过程会变得异常漫长且容易陷入局部最优解。
传统的方法如梯度下降法及其变种(如Adam、RMSprop等)尽管在许多情况下表现良好,但对于某些具有挑战性的任务,它们可能无法有效地探索整个解空间,尤其是在存在大量局部极小值的情况下。此外,对于大规模数据集而言,单机训练的时间成本非常高,这促使研究人员寻求更高效的优化算法以及能够利用分布式计算环境的方法。
随机分布式延迟粒子群优化(Randomly Delayed Distributed Particle Swarm Optimization, RODDPSO)是一种结合了粒子群优化(PSO)与分布式计算的新型优化算法。该算法通过引入随机延迟机制来改善粒子之间的信息交换,从而增强全局搜索能力,并通过分布式处理来加速计算过程。RODDPSO算法的设计目的是为了克服传统PSO算法容易陷入局部最优的问题,并通过分布式计算来提高优化速度。
本项目致力于将RODDPSO算法应用于CNN回归模型的优化,目标是改善模型的训练效率和预测准确性。具体来说,我们将利用RODDPSO算法来优化CNN模型中的超参数,通过随机延迟策略来增强粒子之间的信息交换,同时利用分布式计算环境来加速训练过程。
本项目通过Python实现随机分布式延迟PSO优化算法(RODDPSO)优化CNN回归模型项目实战。
2.数据获取
本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
| 编号 | 变量名称 | 描述 |
| 1 | x1 | |
| 2 | x2 | |
| 3 | x3 | |
| 4 | x4 | |
| 5 | x5 | |
| 6 | x6 | |
| 7 | x7 | |
| 8 | x8 | |
| 9 | x9 | |
| 10 | x10 | |
| 11 | y | 标签 |
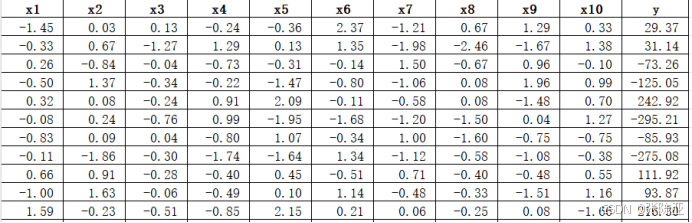
数据详情如下(部分展示):
3.数据预处理
3.1 用Pandas工具查看数据
使用Pandas工具的head()方法查看前五行数据:

关键代码:

3.2数据缺失查看
使用Pandas工具的info()方法查看数据信息:
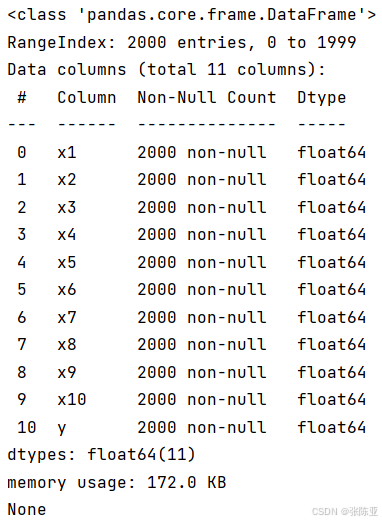
从上图可以看到,总共有11个变量,数据中无缺失值,共2000条数据。
关键代码:

3.3数据描述性统计
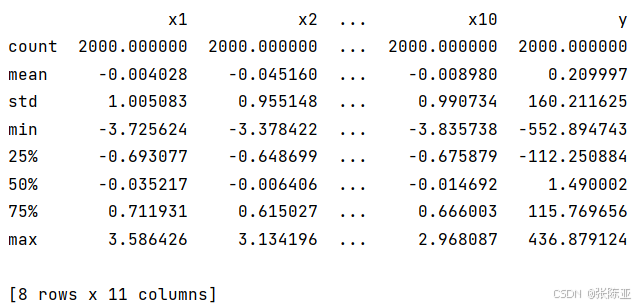
通过Pandas工具的describe()方法来查看数据的平均值、标准差、最小值、分位数、最大值。
关键代码如下:

4.探索性数据分析
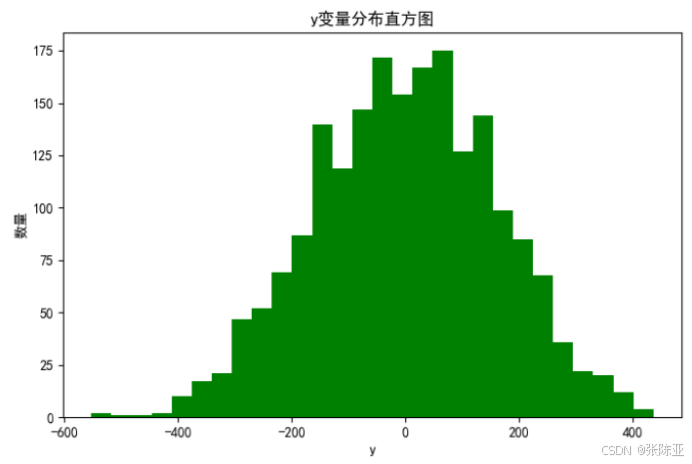
4.1 y变量分布直方图
用Matplotlib工具的hist()方法绘制直方图:
4.2 相关性分析
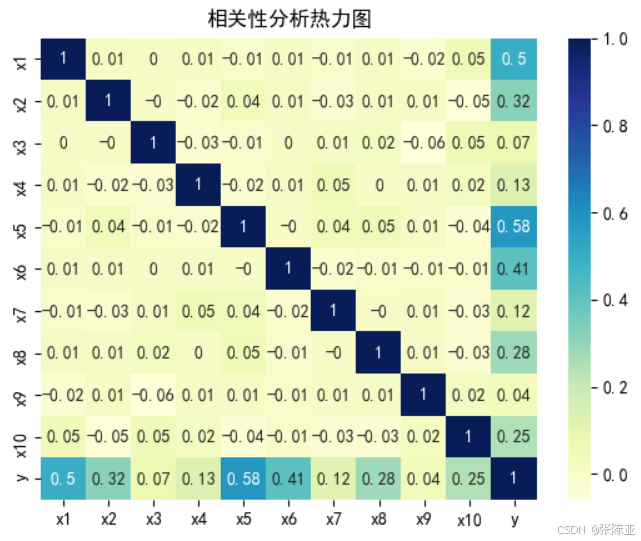
从上图中可以看到,数值越大相关性越强,正值是正相关、负值是负相关。
5.特征工程
5.1 建立特征数据和标签数据
关键代码如下:

5.2 数据集拆分
通过train_test_split()方法按照80%训练集、20%测试集进行划分,关键代码如下:
5.3 特征样本增维
特征增维后的形状如下:

6.构建随机分布式延迟PSO优化算法(RODDPSO)优化CNN回归模型
主要使用通过PSO优化算法(RODDPSO)优化CNN回归模型,用于目标回归。
6.1 随机分布式延迟PSO算法寻找最优参数值
适应度曲线:
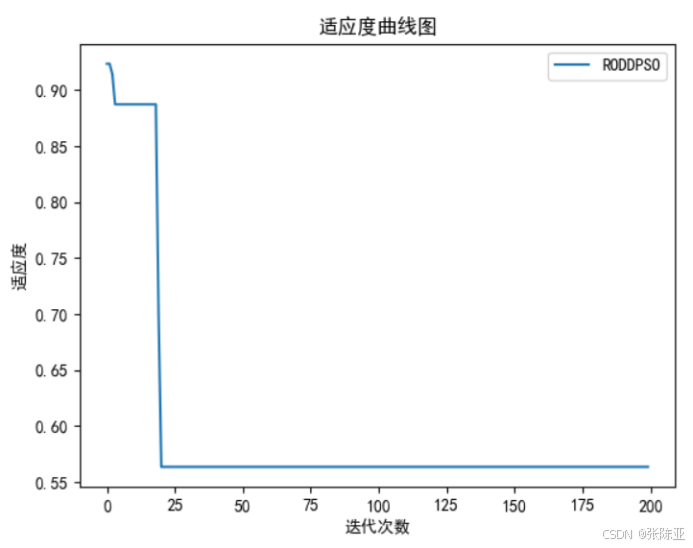
最优参数值:

6.2 最优参数构建模型
| 编号 | 模型名称 | 参数 |
| 1 | CNN回归模型 | units=best_units |
| 2 | epochs=best_epochs |
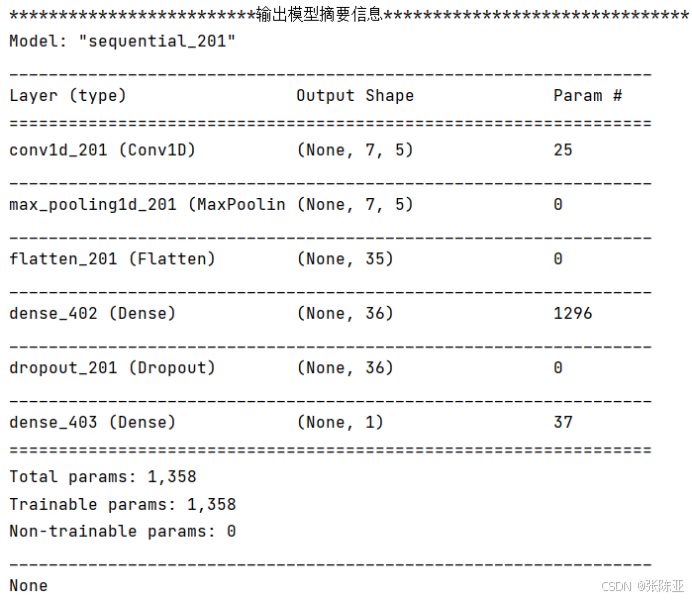
6.3 模型摘要信息
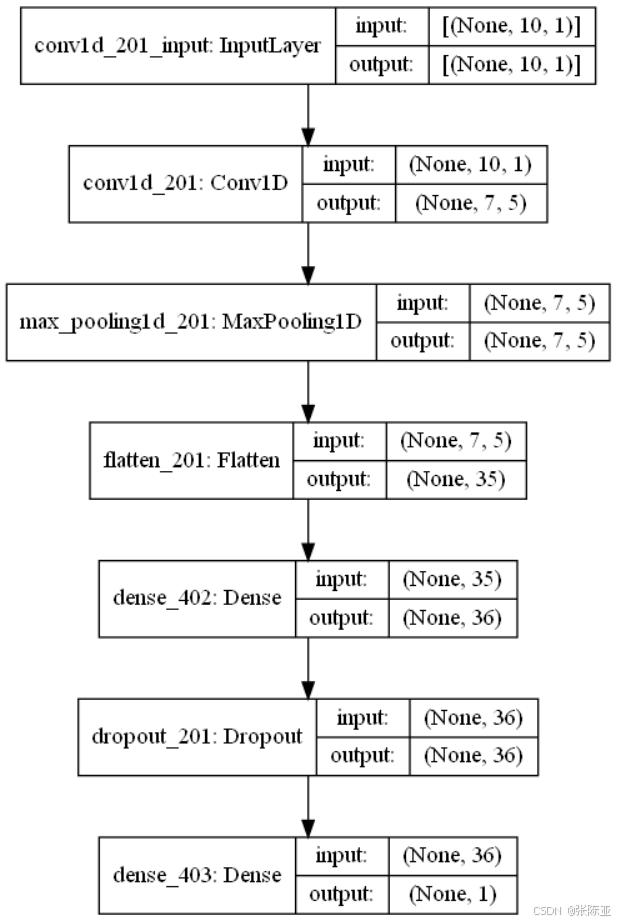
6.4 模型网络结构
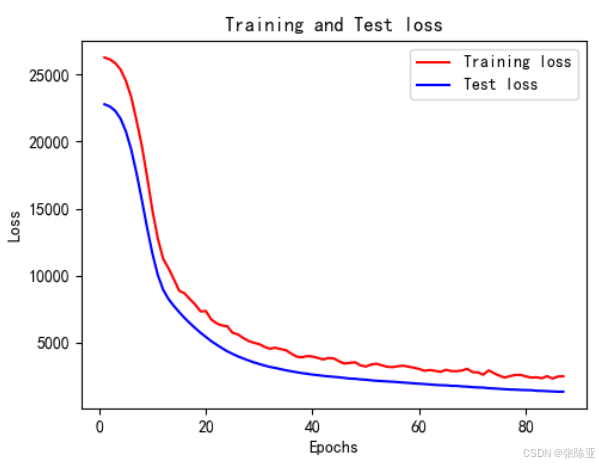
6.5 模型训练集测试集损失曲线图
7.模型评估
7.1评估指标及结果
评估指标主要包括R方、均方误差、解释性方差、绝对误差等等。
| 模型名称 | 指标名称 | 指标值 |
| 测试集 | ||
| CNN回归模型 | R方 | 0.9415 |
| 均方误差 | 1338.4005 | |
| 解释方差分 | 0.9417 | |
| 绝对误差 | 28.4934 | |
从上表可以看出,R方分值为0.9415,说明模型效果比较好。
关键代码如下:

7.2 真实值与预测值对比图

从上图可以看出真实值和预测值波动基本一致,模型效果良好。
8.结论与展望
综上所述,本文采用了PSO粒子群优化算法优化CNN回归算法来构建回归模型,最终证明了我们提出的模型效果良好。此模型可用于日常产品的预测。