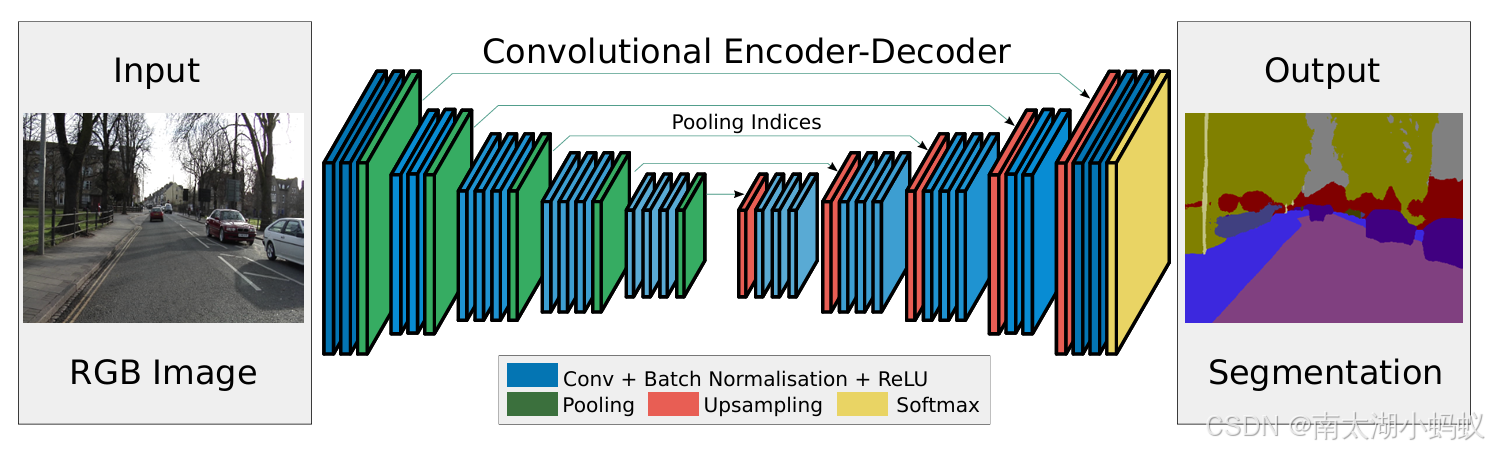
SegNet是由剑桥大学团队开发的一个图像分割的开源项目,该项目可以对图像中的物体所在区域进行分割,例如车、马路、行人等,并且精确到像素级别。SegNet提出了一种编码器,解码器的结构,其实有点类似于FCN,但又有所不同。他的主要流程如下:
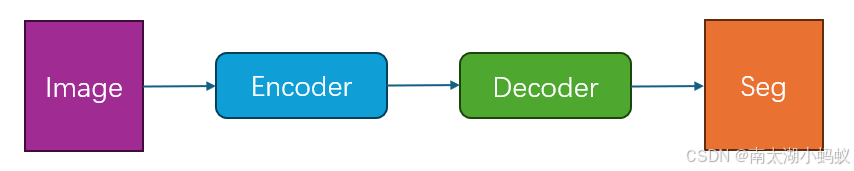
输入一幅待分割的图像,先进入编码器,再进入解码器,最后通过一个softmax得到每个像素的分类结果,也就是语义分割的结果。在我看来,SegNet和FCN最大的不同,也就是SegNet最大的特点就是它存储了编码过程中最大池化的索引。在SegNet网络结构中,进行2×2最大池化时,会存储相应的最大池化索引(位置)。在解码器处,执行上采样和卷积时,会调用相应编码器层处的最大池化索引以进行上采样。这种方式可以一定程度上解决物体边界划分不清的问题,因为上采样的信息是直接从原始输入图像中获取的,能够更准确地反映物体的边界。而FCN在上采样过程中,并没有考虑到编码时最大池化的索引位置,如下图所示:
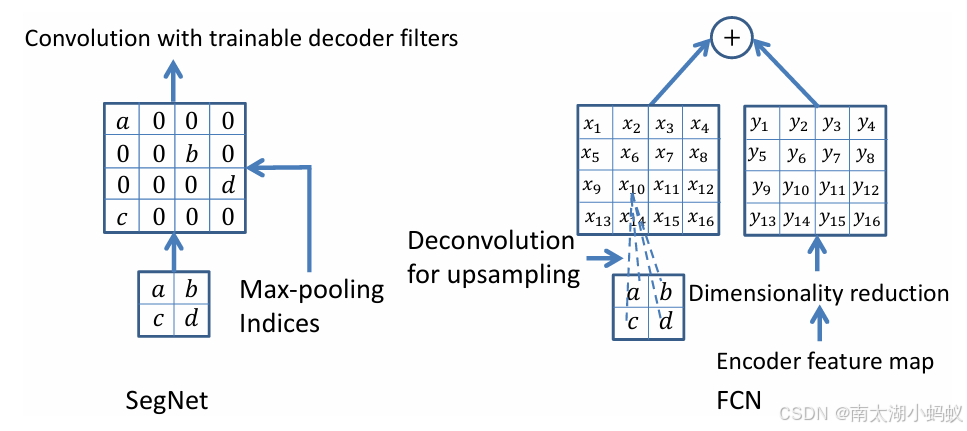
整个SegNet的结构如下:
可以看到,编码器和解码器都有五个模块构成。
编码器1:两个卷积模块和一个最大池化模块(每个卷积模块包含一次卷积一次批归一化和一次非线性变换),大小缩小一半
编码器2:两个卷积模块和一个最大池化模块,大小缩小一半
编码器3:三个卷积模块和一个最大池化模块,大小缩小一半
编码器4:三个卷积模块和一个最大池化模块,大小缩小一半
编码器5:三个卷积模块和一个最大池化模块,大小缩小一半
解码器1:一个上采样模块和三个卷积模块,大小扩大一倍(在上采样过程中,使用保存的编码器最大池化时的索引)
解码器2:一个上采样模块和三个卷积模块,大小扩大一倍
解码器3:一个上采样模块和三个卷积模块,大小扩大一倍
解码器4:一个上采样模块和两个卷积模块,大小扩大一倍
解码器5:一个上采样模块和两个卷积模块,再拼接上一个softmax操作进行分类,大小扩大一倍,恢复成原始图像大小。
下面我们来看一下根据这个设计编写的代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.models as models
class SegNet(nn.Module):
def __init__(self, num_classes=21):
super(SegNet, self).__init__()
self.encoder1 = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
)
self.encoder2 = nn.Sequential(
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
)
self.encoder3 = nn.Sequential(
nn.Conv2d(128, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
)
self.encoder4 = nn.Sequential(
nn.Conv2d(256, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
self.encoder5 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
)
# Decoder
self.decoder1 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True)
)
self.decoder2 = nn.Sequential(
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 512, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(512),
nn.ReLU(inplace=True),
nn.Conv2d(512, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True)
)
self.decoder3 = nn.Sequential(
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
)
self.decoder4 = nn.Sequential(
nn.Conv2d(128, 128, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(128),
nn.ReLU(inplace=True),
nn.Conv2d(128, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True)
)
self.decoder5 = nn.Sequential(
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, 64, kernel_size=3, stride=1, padding=1),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.Conv2d(64, num_classes, kernel_size=1)
)
def forward(self, x):
# 用来保存各层的池化索引
pool_indices = []
x = self.encoder1(x)
x, pool_indices1 = nn.MaxPool2d(2, stride=2, return_indices=True)(x)
pool_indices.append(pool_indices1)
print("x.shape: ",x.shape)
x = self.encoder2(x)
x, pool_indices2 = nn.MaxPool2d(2, stride=2, return_indices=True)(x)
pool_indices.append(pool_indices2)
print("x.shape: ",x.shape)
x = self.encoder3(x)
x, pool_indices3 = nn.MaxPool2d(2, stride=2, return_indices=True)(x)
pool_indices.append(pool_indices3)
print("x.shape: ",x.shape)
x = self.encoder4(x)
x, pool_indices4 = nn.MaxPool2d(2, stride=2, return_indices=True)(x)
pool_indices.append(pool_indices4)
print("x.shape: ",x.shape)
x = self.encoder5(x)
x, pool_indices5 = nn.MaxPool2d(2, stride=2, return_indices=True)(x)
pool_indices.append(pool_indices5)
print("x.shape: ",x.shape)
#---------------------
print("-------decoder--------")
x = nn.MaxUnpool2d(kernel_size=2, stride=2, padding=0)(x, pool_indices[4])
x = self.decoder1(x)
print("x.shape: ",x.shape)
x = nn.MaxUnpool2d(kernel_size=2, stride=2, padding=0)(x, pool_indices[3])
x = self.decoder2(x)
print("x.shape: ",x.shape)
x = nn.MaxUnpool2d(kernel_size=2, stride=2, padding=0)(x, pool_indices[2])
x = self.decoder3(x)
print("x.shape: ",x.shape)
x = nn.MaxUnpool2d(kernel_size=2, stride=2, padding=0)(x, pool_indices[1])
x = self.decoder4(x)
print("x.shape: ",x.shape)
x = nn.MaxUnpool2d(kernel_size=2, stride=2, padding=0)(x, pool_indices[0])
x = self.decoder5(x)
print("x.shape: ",x.shape)
return x
def _initialize_weights(self, *stages):
for modules in stages:
for module in modules.modules():
if isinstance(module, nn.Conv2d):
nn.init.kaiming_normal_(module.weight)
if module.bias is not None:
module.bias.data.zero_()
elif isinstance(module, nn.BatchNorm2d):
module.weight.data.fill_(1)
module.bias.data.zero_()
# Example usage
if __name__ == "__main__":
model = SegNet(num_classes=21) # For example, Cityscapes dataset has 21 classes
input_tensor = torch.randn(1, 3, 320, 480)
output = model(input_tensor)
print(output.shape)
# 输出
x.shape: torch.Size([1, 64, 160, 240])
x.shape: torch.Size([1, 128, 80, 120])
x.shape: torch.Size([1, 256, 40, 60])
x.shape: torch.Size([1, 512, 20, 30])
x.shape: torch.Size([1, 512, 10, 15])
-------decoder--------
x.shape: torch.Size([1, 512, 20, 30])
x.shape: torch.Size([1, 256, 40, 60])
x.shape: torch.Size([1, 128, 80, 120])
x.shape: torch.Size([1, 64, 160, 240])
x.shape: torch.Size([1, 21, 320, 480])
torch.Size([1, 21, 320, 480])可以看到整个数据在编码器和解码器中的数据流转过程,最终输出为分为21类的结果。实际应用中,由于从头开始训练需要花不少时间,我们可以加载VGG模型的预训练权重,因为SegNet的编码器结构和VGG基本类似,可以稍作改动把五个编码层的权重(除最大池化层)替换为VGG的预训练权重。核心代码如下:
if self.preTrained:
vgg = models.vgg16(pretrained=True)
else:
vgg = models.vgg16(pretrained=False)
self.encoder1 = nn.Sequential(vgg.features[0:3])
self.encoder2 = nn.Sequential(vgg.features[5:8])
self.encoder3 = nn.Sequential(vgg.features[10:15])
self.encoder4 = nn.Sequential(vgg.features[17:22])
self.encoder5 = nn.Sequential(vgg.features[24:29])下面我们看看SegNet的训练结果。

在VOC2012数据集上,SegNet和FCN都训练150个epoch,SegNet的效果是不如FCN的,可能是SegNet需要更多的资源,更长的训练轮数。
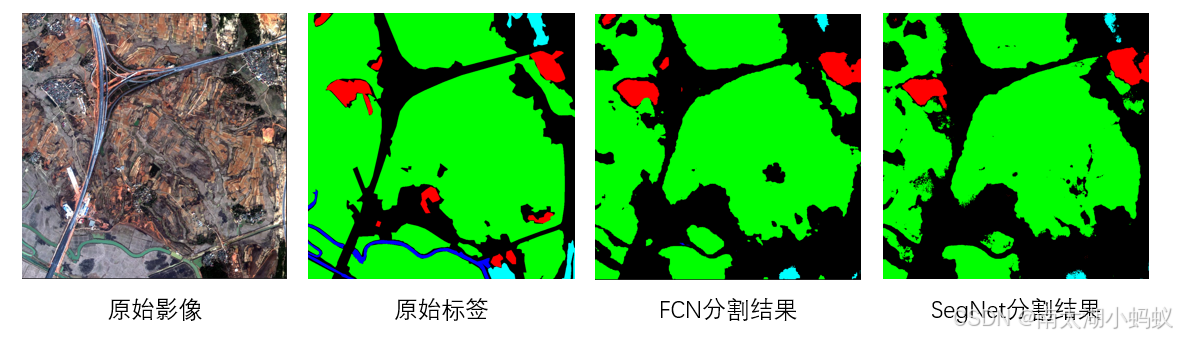
可以看到,在GID遥感数据集上,SegNet的分割效果就好了不少,同样的训练轮数和FCN效果类似,并且SegNet的边缘更平滑些。