文章目录
一、任务内容
利用Srapy框架爬取广州图书馆的活动信息,网址为:http://www.gzlib.org.cn/hdActForecast/index.jhtml,该页面是一个活动信息列表,分页显示,每页15条,由JS代码动态生成,点击下一页后页面地址不会发生变化。每一条活动信息都是一个超链接,对应一个唯一的URL,点击后打开一个新的网址,显示该活动信息的详细信息。因此,利用splash作为JS引擎,从而获得渲染后的页面,并模拟点击下一页的动作,获得所有的活动信息。爬取的活动信息保存在Mysql数据库中。
广图会不定期更新活动信息,每隔一天运行一次爬虫程序,但Scrapy会对所有信息重新爬取一遍,包括前一次已经爬取的信息,因此,利用redis内存数据库保存已经爬取的活动信息URL,每次爬取时跳过已经爬取的URL,只对新增的活动信息进行爬取。
二、Scrapy安装、配置、调试
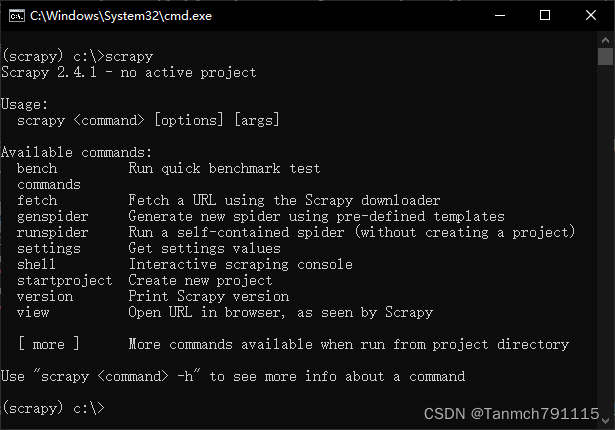
安装Anaconda,在cmd窗口输入:conda install scrapy ,输入y回车表示允许安装依赖库,安装完成后输入scrapy,如果显示如下,则表示安装成功。
在pycharm的工程目录下创建文件夹scrapy,在终端输入指令:
cd scrapy
scrapy startproject gzlib
cd gzlib
scrapy genspider hdACT www.gzlib.org.cn
scrapy startproject gzlib是创建gzlib项目的命令,scrapy genspider hdACT www.gzlib.org.cn是创建hdACT 爬虫的命令。完成后目录结构如下图所示:
这里需要关注的是hdACT.py文件(爬虫文件),items.py文件(定义需要Pipeline处理的元素),middlewares.py文件(定义spider中间件和downloader中间件),settings.py文件(配置文件)。

三、splash安装、配置、调试
由于爬取的目标网页内容是由JS动态渲染,必须配合JS引擎对网页上的js脚本进行渲染,获得渲染后的页面,这里选择splash作为JS引擎。
安装splash主要的问题是安装Docker,由于我使用的是win10 home版,已经安装了WSL2,并安装了Ubuntu虚拟机(安装方法请自行百度),只需要打开hyper-v虚拟化功能,主要参考了这篇文章
开启hyper-v
把以下的命令保存在一个txt文件中,然后重命名为.cmd文件,最后以管理员身份运行该文件。
pushd '%~dp0'
dir /b %SystemRoot%\servicing\Packages\*Hyper-V*.mum >hyper-v.txt
for /f %%i in ('findstr /i . hyper-v.txt 2^>nul') do dism /online /norestart /add-package:'%SystemRoot%\servicing\Packages\%%i'
del hyper-v.txt
Dism /online /enable-feature /featurename:Microsoft-Hyper-V-All /LimitAccess /ALL
运行过程中会出现百分比,如果运行成功不关闭的话可能会一遍遍运行,当你看到运行成功即可关闭该文件,然后重启电脑就可以拥有完整的Hyper-V选项了。

安装Docker Desktop
从https://www.docker.com/get-docker下载Docker desktop 安装包,直接安装即可。
拉取和开启Splash
在命令行界面输入:
docker pull scrapinghub/splash
拉取splash,完成后,输入:
docker run -p 8050:8050 scrapinghub/splash
完成后,双击桌面上Docker的小鲸鱼图标,启动Docker界面:
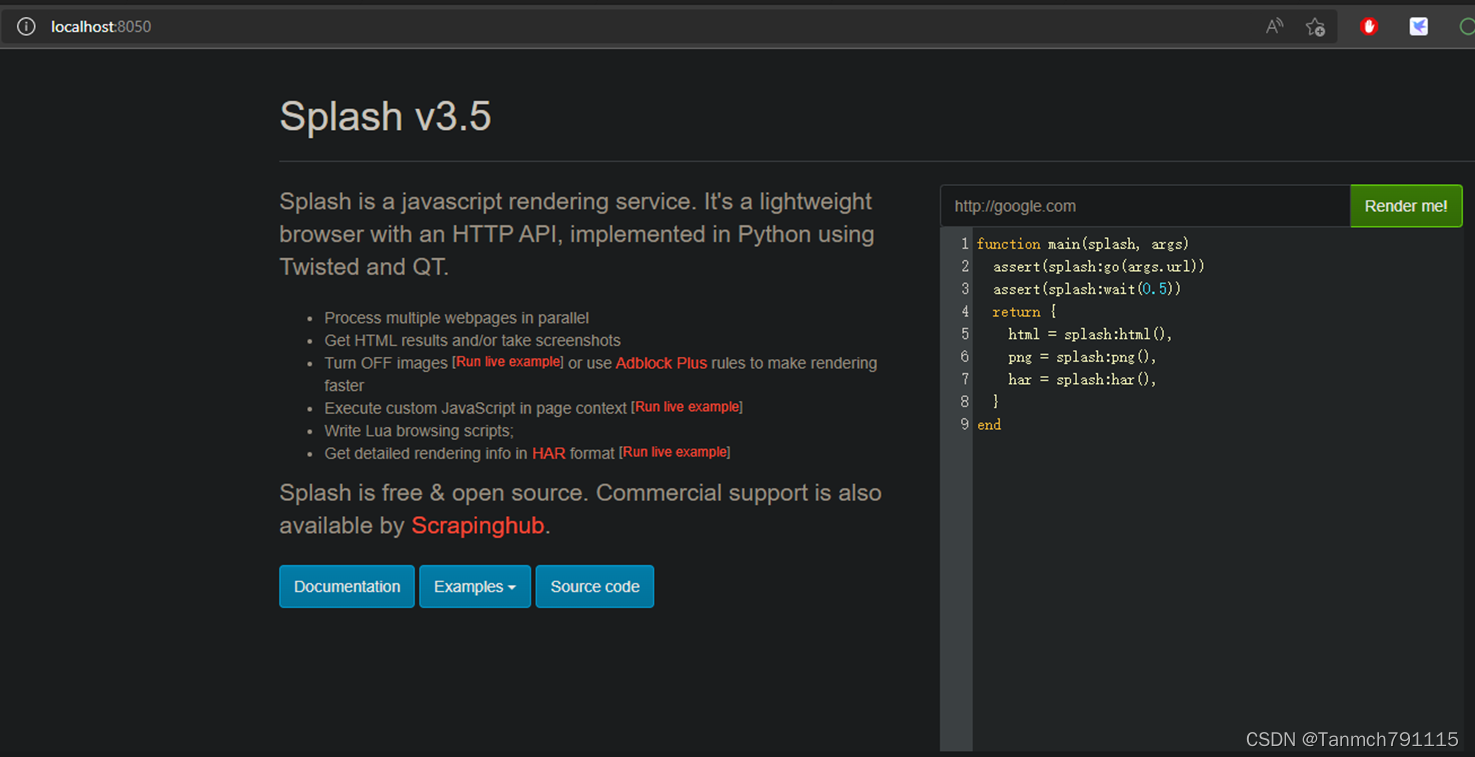
点击Open in browser按钮,可在浏览器中看到如下界面,说明安装成功。
安装scrapy-splash包
要在Scrapy中使用splash需要安装scrapy-splash包,在命令行中执行如下命令。
pip install scrapy-splash
配置scrapy-splash环境
在项目配置文件settings.py中,需要配置scrapy-splash,配置内容如下:
#设置Splash服务器地址和端口
SPLASH_URL = 'http://localhost:8050'
# 设置去重过滤器
DUPEFILTER_CLASS = 'scrapy_splash.SplashAwareDupeFilter'
# 设置缓存
HTTPCACHE_STORAGE = 'scrapy_splash.SplashAwareFSCacheStorage'
# 开启Splash的两个下载器中间件并调整HttpCompressionMiddleware的次序
DOWNLOAD_MIDDLEWARES = {
#将splash middleware 添加到DOWNLOAD_MIDDLEWARE中
'scrapy_splash.SplashCookieMiddleware': 723,
'scrapy_splash.SplashMiddleware': 725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware': 810,
}
四、Mysql和redis安装、配置、调试
从https://dev.mysql.com/downloads/mysql/下载最新版mysql安装程序mysql-installer-community-8.0.28.0.msi,进行安装。
从https://github.com/tporadowski/redis/releases下载最新版的redis安装程序Redis-x64-3.0.504.msi,进行安装。
创建数据库
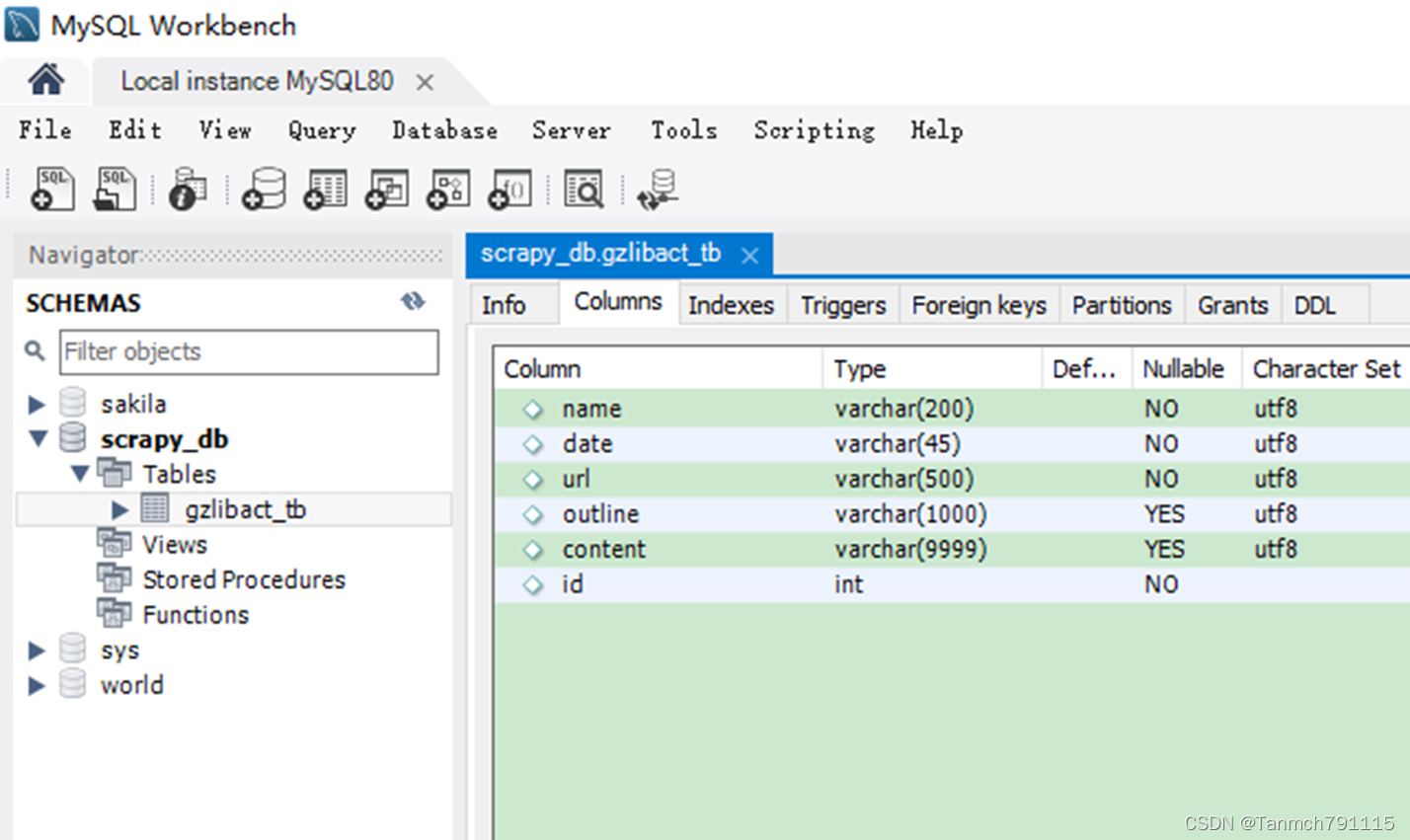
mysql安装好以后,打开MySql Workbench创建数据库,如下图所示:
redis安装好后,可以自行下载RedisDesktopManager工具,对redis进行管理。如下图:

安装pymysql和redis包
要在python中使用mysql和redis需要相应的包支持,由于我已经安装了anaconda,通过一下命令安装这两个包:
conda install pymysql
conda install redis
四、源代码
setting.py
import scrapy.pipelines.images
BOT_NAME = 'gzlib'
SPIDER_MODULES = ['gzlib.spiders']
NEWSPIDER_MODULE = 'gzlib.spiders'
USER_AGENT = 'Mozilla/5.0(Windows NT6.1;Win64;x64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/78.0.3904.87 Safari/537.36'
ROBOTSTXT_OBEY = False
DOWNLOAD_DELAY = 0.5
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
'User-Agent':'Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML,like Gecko) Chrome/94.0.4606.71 Safari/537.36'
}
ITEM_PIPELINES = {
'gzlib.pipelines.GzlibPipeline': 300,
'gzlib.pipelines.GzlibImgPipeline': 1,
}
#图片存储目录
IMAGES_STORE = 'images'
#渲染服务的URL
SPLASH_URL='http://localhost:8050'
#下载器中间件
DOWNLOADER_MIDDLEWARES={
'scrapy_splash.SplashCookiesMiddleware':723,
'scrapy_splash.SplashMiddleware':725,
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware':810,
}
#去重过滤器
DUPEFILTER_CLASS='scrapy_splash.SplashAwareDupeFilter'
#使用Splash的Http缓存
HTTPCACHE_STORAGE='scrapy_splash.SplashAwareFSCacheStorage'
items.py
import scrapy
class GzlibItem(scrapy.Item):
name= scrapy.Field()
time=scrapy.Field()
imgsrc=scrapy.Field()
detail_url=scrapy.Field()
detail_outline=scrapy.Field()
detail_content=scrapy.Field()
pass
hdACT.py
import scrapy
from ..items import GzlibItem
import urllib
# 使用scrapy_splash包提供的request对象
from scrapy_splash import SplashRequest
import pymysql
import pandas as pd # 用来读MySQL
import redis
class HdactSpider(scrapy.Spider):
name = 'hdACT'
allowed_domains = ['www.gzlib.org.cn', 'action.gzlib.org.cn']#列表页和详情页的域名不一样,要把两个域名都加入
start_urls = ['http://www.gzlib.org.cn/hdActForecast/index.jhtml']
next = False # 设定是否需要翻页,不翻页的话只爬取列表页的第一个页面
redis_db = redis.Redis(host='127.0.0.1', port=6379, db=4) # 连接redis,相当于MySQL的conn
redis_data_dict = "f_url" # 设置redis字典名称
connect = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='wjcumt790625',
database='scrapy_db', charset='utf8') # 连接mysql数据库
cursor = connect.cursor() # 建立游标
# splash执行”下一页“JS代码的lua脚本
next_lua = """
function main(splash, args)
assert(splash:go(args.url))
splash:wait(10)
nxtPage=splash:runjs(args.script)
splash:wait(10)
return splash:html()
end
"""
def __init__(self):
if self.redis_db.hlen(self.redis_data_dict) != 0:#如果redis中有数据
self.redis_db.flushdb() ## 删除redis里面的所有数据
sql = "SELECT url FROM gzlibact_tb;"
df = pd.read_sql(sql, self.connect) # 读MySQL中的保存的已经爬取的详情页url数据
for url in df['url'].values: # 把每一条url写入key的字段里
self.redis_db.hset(self.redis_data_dict, url, 0)
self.connect.close()
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(url,
callback=self.parse_splash_actList,
args={'wait': 10}, # 最大超时时间
endpoint='render.html' # 使用splash服务的固定参数
)
def parse_splash_actList(self, response):
act_names = response.xpath("//div[@class='yg-detail']/div[@class='yg2-info']/a/h3/text()").extract()
act_times = response.xpath("//div[@class='yg-detail']/div[@class='yg2-info']/p/text()").extract()
act_detail_urls = response.xpath("//*[@id='actForecast']/li/div/div/a/@href").extract()
act_imgsrc=response.xpath("//*[@id='actForecast']/li/div/a/img/@src").extract()
for name, time, detail_url,imgsrc in zip(act_names, act_times, act_detail_urls,act_imgsrc):
item = GzlibItem()
item['name'] = '' if name == None else name.strip()
item['time'] = '' if time == None else time.strip()
item['detail_url'] = '' if detail_url == None else detail_url.strip()
item['imgsrc'] = ['' if imgsrc==None else urllib.parse.urljoin(response.url,imgsrc.strip())]#url拼接
if self.redis_db.hexists(self.redis_data_dict,
detail_url): # 取列表中每一条对应的详情页url和key里的字段对比,看是否存在,存在就直接跳过
print(detail_url + 'url已经被爬取过。')
pass
else:
print(detail_url + 'url未被爬取过。')
self.redis_db.hset(self.redis_data_dict, detail_url, 0)#将新的详情页url作为key保存进redis字典
#调用splash获取渲染后的页面
yield SplashRequest(detail_url,
callback=self.parse_splash_actDetail,
meta={'item': item},#将item传递给parse_splash_actDetail
args={'wait': 10}, # 最大超时时间
endpoint='render.html' # 使用splash服务的固定参数
)
nextJS = response.xpath("//a[contains(text(), '下一页')]/@onclick").extract_first()#‘下一页’对应的JS代码
if nextJS and self.next:
print('next page script is :' + str(nextJS) + '!!')
#调用splash执行下一页对应的JS代码,获取下一页列表
yield SplashRequest(response.url,
callback=self.parse_splash_actList,
args={'wait': 10, 'lua_source': self.next_lua, 'url': response.url, 'script': nextJS},
# wait:最大超时时间,lua_source:要执行的lua脚本
endpoint='execute' # 使用splash服务执行JS代码的固定参数
)
pass
def parse_splash_actDetail(self, response):
item = response.meta['item']#获取parse_splash_actList传来的item
outline = response.xpath(
"// *[ @ id = 'view-text'] / div[@class='action']/ div[@class='title'] /a/text()").extract_first().strip() + '\n'
outline += response.xpath(
"// *[ @ id = 'view-text'] / div[@class='action']/ div[@class='title'] /p")[0].xpath(
'string()').extract_first().strip() + '\n'
for node in response.xpath(
"// *[ @ id = 'view-text'] / div[@class='p'] "):
outline += node.xpath('string(.)').extract_first().strip() + '\n'
pass
item['detail_outline'] = outline
content = ''
for node in response.xpath("// div[ @ class = 'view-content'][1] / p "):
content += node.xpath('string(.)').extract_first().strip() + '\n'
pass
item['detail_content'] = content.strip().replace('\n\n','\n')
yield item
pass
pipelines.py
import hashlib
from scrapy.utils.python import to_bytes
import openpyxl
from scrapy.http import Request
from scrapy.pipelines.images import ImagesPipeline
import pymysql
from itemadapter import ItemAdapter
class GzlibPipeline:
connect = pymysql.connect(host='127.0.0.1', port=3306, user='root', password='wjcumt790625',
database='scrapy_db', charset='utf8') # 连接mysql数据库
cursor = connect.cursor() # 建立游标
def __init__(self):
self.wb = openpyxl.Workbook()
self.ws = self.wb.active
self.ws.append(['活动名称', '时间','详情页地址','概要','内容'])
def process_item(self, item, spider):
line = [item['name'], item['time'],item['detail_url'],item['detail_outline'],item['detail_content']]
self.ws.append(line)
query = 'insert into gzlibact_tb(name,date,url,outline,content) values(%s, %s, %s, %s, %s)'
values=(item['name'], item['time'],item['detail_url'],item['detail_outline'],item['detail_content'])
try:
self.cursor.execute(query, values)
except:
self.connect.rollback()
return item
def close_spider(self, spider):
self.connect.commit()
self.wb.save('hdACT1.xlsx')
self.wb.close()
class GzlibImgPipeline(ImagesPipeline):
def get_media_requests(self, item, info):
urls=item['imgsrc']
return [Request(u,meta={'item': item}) for u in urls]
def file_path(self, request, response=None, info=None, *, item=None):
item=request.meta['item']
image_name=item['imgsrc'][0].split('/')[-1]
return f'full/{image_name}.jpg'
五、运行爬虫
在命令行中输入以下命令:
scrapy crawl hdACT