第一:了解什么是YOLOv5算法
这里说很详细,你自己看就可以了。写论文你绝对用得上,但既然称之为Yolov5,也有很多非常不错的地方值得我们学习。不过因为Yolov5的网络结构和Yolov3、Yolov4相比,不好可视化。
1.Yolov5四种网络结构
Yolov5官方代码中,给出的目标检测网络中一共有4个版本,分别是Yolov5s、Yolov5m、Yolov5l、Yolov5x四个模型。学习一个新的算法,最好在脑海中对算法网络的整体架构有一个清晰的理解。但比较尴尬的是,Yolov5代码中给出的网络文件是yaml格式,和原本Yolov3、Yolov4中的cfg不同。因此无法用netron工具直接可视化的查看网络结构,造成有的同学不知道如何去学习这样的网络。
比如下载了Yolov5的四个pt格式的权重模型:

- Yolov5网络结构图
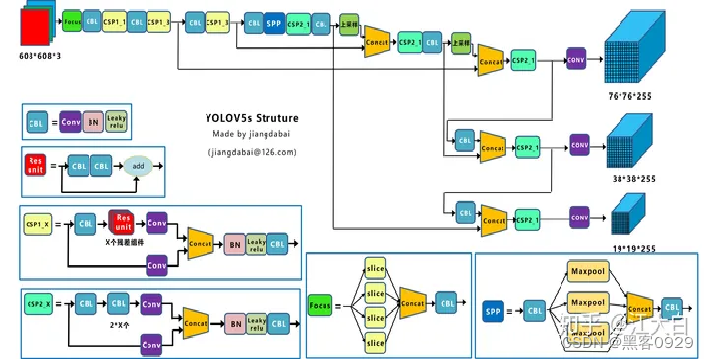
2.Yolov5核心基础内容
Yolov5的结构和Yolov4很相似,但也有一些不同,大白还是按照从整体到细节的方式,对每个板块进行讲解。
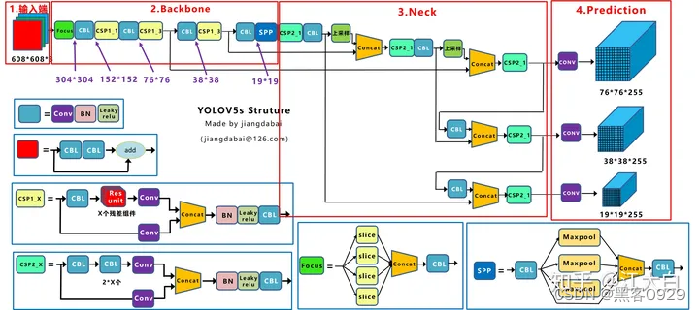
上图即Yolov5的网络结构图,可以看出,还是分为输入端、Backbone、Neck、Prediction四个部分。
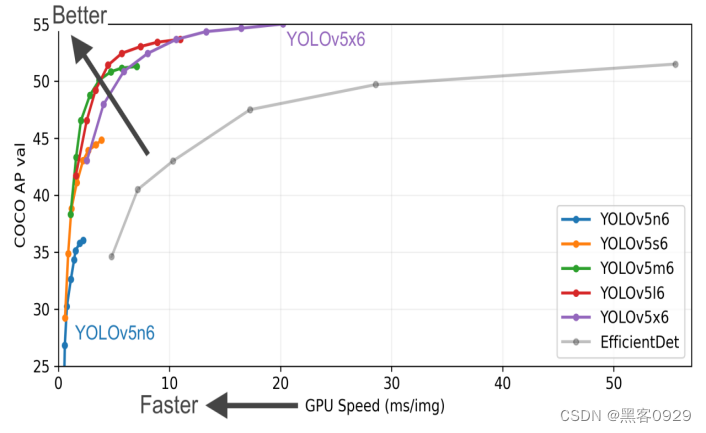
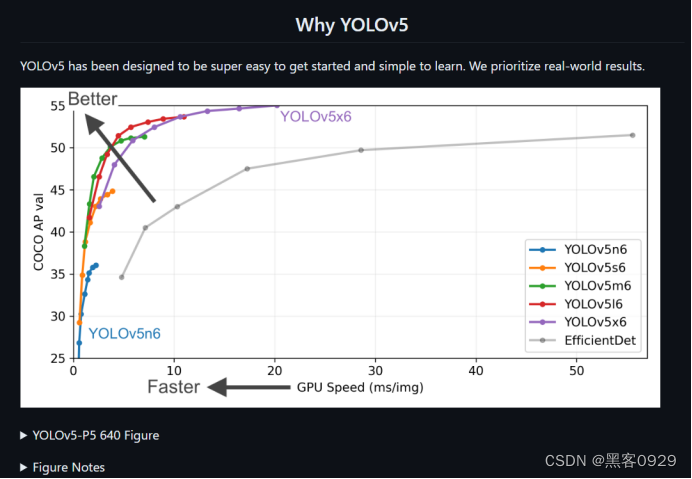
上面是Yolov5作者的算法性能测试图:
1、Yolov5的项目结构
看这篇博客:你会学会很多,写论问也用得上。(博主连接如下)
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析-CSDN博客


2、YOLO总体架构图
-
3、训练自己的自定义数据集YOLOv5。
# coding:utf-8
# ----------------------------------------------------------------------------
# Pytorch multi-GPU YOLOV5 based UMT
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import logging
import math
import os
import random
import sys
import time
import warnings
import yaml
import numpy as np
from copy import deepcopy
from pathlib import Path
from threading import Thread
from tqdm import tqdm
import torch.distributed as dist
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch.optim.lr_scheduler as lr_scheduler
import torch.utils.data
from torch.cuda import amp
from torch.nn.parallel import DistributedDataParallel as DDP
from torch.utils.tensorboard import SummaryWriter
FILE = Path(__file__).absolute()
sys.path.append(FILE.parents[0].as_posix()) # add yolov5/ to path
import ssda_yolov5_test as test # for end-of-epoch mAP
from models.experimental import attempt_load
from models.yolo import Model
from utils.autoanchor import check_anchors
from utils.datasets import create_dataloader
from utils.datasets_single import create_dataloader_single
from utils.google_utils import attempt_download
from utils.loss import ComputeLoss
from utils.torch_utils import ModelEMA, WeightEMA, select_device, intersect_dicts, torch_distributed_zero_first, de_parallel
from utils.wandb_logging.wandb_utils import WandbLogger, check_wandb_resume
from utils.plots import plot_images, plot_labels, plot_results, plot_evolution
from utils.metrics import fitness
from utils.general import labels_to_class_weights, increment_path, labels_to_image_weights, init_seeds, \
strip_optimizer, get_latest_run, check_dataset, check_file, check_git_status, check_img_size, \
check_requirements, print_mutation, set_logging, one_cycle, colorstr, \
non_max_suppression, check_dataset_umt, xyxy2xywhn
logger = logging.getLogger(__name__)
LOCAL_RANK = int(os.getenv('LOCAL_RANK', -1)) # https://pytorch.org/docs/stable/elastic/run.html
RANK = int(os.getenv('RANK', -1))
WORLD_SIZE = int(os.getenv('WORLD_SIZE', 1))
# hyp means path/to/hyp.yaml or hyp dictionary
def train(hyp, opt, device):
save_dir, epochs, batch_size, weights, single_cls, evolve, data, cfg, resume, notest, nosave, workers, = \
opt.save_dir, opt.epochs, opt.batch_size, opt.weights, opt.single_cls, opt.evolve, opt.data, opt.cfg, \
opt.resume, opt.notest, opt.nosave, opt.workers
teacher_alpha, conf_thres, iou_thres, max_gt_boxes, lambda_weight, student_weight, teacher_weight = \
opt.teacher_alpha, opt.conf_thres, opt.iou_thres, opt.max_gt_boxes, opt.lambda_weight, \
opt.student_weight, opt.teacher_weight
all_shift = opt.consistency_loss
# Directories
save_dir = Path(save_dir)
wdir = save_dir / 'weights'
wdir.mkdir(parents=True, exist_ok=True) # make dir
last_student, last_teacher = wdir / 'last_student.pt', wdir / 'last_teacher.pt'
best_student, best_teacher = wdir / 'best_student.pt', wdir / 'best_teacher.pt'
results_file = save_dir / 'results.txt'
# Hyperparameters
if isinstance(hyp, str):
with open(hyp) as f: # default path data/hyps/hyp.scratch.yaml
hyp = yaml.safe_load(f) # load hyps dict
logger.info(colorstr('hyperparameters: ') + ', '.join(f'{k}={v}' for k, v in hyp.items()))
# Save run settings
with open(save_dir / 'hyp.yaml', 'w') as f:
yaml.safe_dump(hyp, f, sort_keys=False)
with open(save_dir / 'opt.yaml', 'w') as f:
yaml.safe_dump(vars(opt), f, sort_keys=False)
# Configure
plots = not evolve # create plots
cuda = device.type != 'cpu'
init_seeds(1 + RANK)
with open(data) as f:
data_dict = yaml.safe_load(f) # data dict
# Loggers
loggers = {'wandb': None, 'tb': None} # loggers dict
if RANK in [-1, 0]:
# TensorBoard
if not evolve:
prefix = colorstr('tensorboard: ')
logger.info(f"{prefix}Start with 'tensorboard --logdir {opt.project}', view at http://localhost:6006/")
loggers['tb'] = SummaryWriter(str(save_dir))
# W&B
opt.hyp = hyp # add hyperparameters
run_id = torch.load(weights).get('wandb_id') if weights.endswith('.pt') and os.path.isfile(weights) else None
run_id = run_id if opt.resume else None # start fresh run if transfer learning
wandb_logger = WandbLogger(opt, save_dir.stem, run_id, data_dict)
loggers['wandb'] = wandb_logger.wandb
if loggers['wandb']:
data_dict = wandb_logger.data_dict
weights, epochs, hyp = opt.weights, opt.epochs, opt.hyp # may update weights, epochs if resuming
nc = 1 if single_cls else int(data_dict['nc']) # number of classes
names = ['item'] if single_cls and len(data_dict['names']) != 1 else data_dict['names'] # class names
assert len(names) == nc, '%g names found for nc=%g dataset in %s' % (len(names), nc, data) # check
is_coco = data.endswith('coco.yaml') and nc == 80 # COCO dataset
# Model
pretrained = weights.endswith('.pt')
# torch.cuda.empty_cache()
# strip_optimizer(weights) # strip optimizers, this will apparently reduce the model size
if pretrained:
with torch_distributed_zero_first(RANK):
weights = attempt_download(weights) # download if not found locally
ckpt = torch.load(weights, map_location=device) # load checkpoint
# model_student
model_student = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# model_teacher
model_teacher = Model(cfg or ckpt['model'].yaml, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
exclude = ['anchor'] if (cfg or hyp.get('anchors')) and not resume else [] # exclude keys
state_dict = ckpt['model'].float().state_dict() # to FP32
state_dict = intersect_dicts(state_dict, model_student.state_dict(), exclude=exclude) # intersect
model_student.load_state_dict(state_dict, strict=False) # load
# model_teacher.load_state_dict(state_dict, strict=False) # load
model_teacher.load_state_dict(state_dict.copy(), strict=False) # load
logger.info('Transferred %g/%g items from %s' % (len(state_dict), len(model_student.state_dict()), weights)) # report
else:
model_student = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
model_teacher = Model(cfg, ch=3, nc=nc, anchors=hyp.get('anchors')).to(device) # create
# Update models weights [only by this way, we can resume the old training normally...][ref models.experimental.attempt_load()]
if student_weight != "None" and teacher_weight != "None": # update model_student and model_teacher
torch.cuda.empty_cache()
ckpt_student = torch.load(student_weight, map_location=device) # load checkpoint
state_dict_student = ckpt_student['ema' if ckpt_student.get('ema') else 'model'].float().half().state_dict() # to FP32
model_student.load_state_dict(state_dict_student, strict=False) # load
del ckpt_student, state_dict_student
ckpt_teacher = torch.load(teacher_weight, map_location=device) # load checkpoint
state_dict_teacher = ckpt_teacher['ema' if ckpt_teacher.get('ema') else 'model'].float().half().state_dict() # to FP32
model_teacher.load_state_dict(state_dict_teacher, strict=False) # load
del ckpt_teacher, state_dict_teacher
# Dataset
with torch_distributed_zero_first(RANK):
# check_dataset(data_dict) # check, need to be re-write or command out
check_dataset_umt(data_dict) # check, need to be re-write or command out
train_path_source_real = data_dict['train_source_real'] # training source dataset w labels
train_path_source_fake = data_dict['train_source_fake'] # training target-like dataset w labels
train_path_target_real = data_dict['train_target_real'] # training target dataset w/o labels
train_path_target_fake = data_dict['train_target_fake'] # training source-like dataset w/o labels
test_path_target_real = data_dict['test_target_real'] # test on target dataset w labels, should not use testset to train
# test_path_target_real = data_dict['train_target_real'] # test on target dataset w labels, remember val in 'test_target_real'
# Freeze
freeze_student = [] # parameter names to freeze (full or partial)
for k, v in model_student.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze_student):
print('freezing %s' % k)
v.requires_grad = False
freeze_teacher = [] # parameter names to freeze (full or partial)
for k, v in model_teacher.named_parameters():
v.requires_grad = True # train all layers
if any(x in k for x in freeze_teacher):
print('freezing %s' % k)
v.requires_grad = False
# Optimizer
nbs = 64 # nominal batch size
accumulate = max(round(nbs / batch_size), 1) # accumulate loss before optimizing
hyp['weight_decay'] *= batch_size * accumulate / nbs # scale weight_decay
logger.info(f"Scaled weight_decay = {hyp['weight_decay']}")
pg0, pg1, pg2 = [], [], [] # optimizer parameter groups
for k, v in model_student.named_modules():
if hasattr(v, 'bias') and isinstance(v.bias, nn.Parameter):
pg2.append(v.bias) # biases
if isinstance(v, nn.BatchNorm2d):
pg0.append(v.weight) # no decay
elif hasattr(v, 'weight') and isinstance(v.weight, nn.Parameter):
pg1.append(v.weight) # apply decay
if opt.adam:
student_optimizer = optim.Adam(pg0, lr=hyp['lr0'], betas=(hyp['momentum'], 0.999)) # adjust beta1 to momentum
else:
student_optimizer = optim.SGD(pg0, lr=hyp['lr0'], momentum=hyp['momentum'], nesterov=True)
student_optimizer.add_param_group({'params': pg1, 'weight_decay': hyp['weight_decay']}) # add pg1 with weight_decay
student_optimizer.add_param_group({'params': pg2}) # add pg2 (biases)
logger.info('Optimizer groups: %g .bias, %g conv.weight, %g other' % (len(pg2), len(pg1), len(pg0)))
del pg0, pg1, pg2
# UMT algorithm
student_detection_params = []
for key, value in model_student.named_parameters():
if value.requires_grad:
student_detection_params += [value]
teacher_detection_params = []
for key, value in model_teacher.named_parameters():
if value.requires_grad:
teacher_detection_params += [value]
value.requires_grad = False
teacher_optimizer = WeightEMA(teacher_detection_params, student_detection_params, alpha=teacher_alpha)
# For debugging
# for k, v in model_student.named_parameters():
# print(k, v.requires_grad)
# for k, v in model_teacher.named_parameters():
# print(k, v.requires_grad)
# Scheduler https://arxiv.org/pdf/1812.01187.pdf
# https://pytorch.org/docs/stable/_modules/torch/optim/lr_scheduler.html#OneCycleLR
if opt.linear_lr:
lf = lambda x: (1 - x / (epochs - 1)) * (1.0 - hyp['lrf']) + hyp['lrf'] # linear
else:
lf = one_cycle(1, hyp['lrf'], epochs) # cosine 1->hyp['lrf']
scheduler = lr_scheduler.LambdaLR(student_optimizer, lr_lambda=lf)
# plot_lr_scheduler(optimizer, scheduler, epochs)
# EMA (exponential moving average)
ema = ModelEMA(model_student) if RANK in [-1, 0] else None
# Resume
start_epoch, best_fitness = 0, 0.0
if pretrained:
# Optimizer
if ckpt['optimizer'] is not None:
student_optimizer.load_state_dict(ckpt['optimizer'])
best_fitness = ckpt['best_fitness']
# EMA
if ema and ckpt.get('ema'):
ema.ema.load_state_dict(ckpt['ema'].float().state_dict())
ema.updates = ckpt['updates']
# Results
if ckpt.get('training_results') is not None:
results_file.write_text(ckpt['training_results']) # write results.txt
# Epochs
start_epoch = ckpt['epoch'] + 1
if resume:
assert start_epoch > 0, '%s training to %g epochs is finished, nothing to resume.' % (weights, epochs)
if epochs < start_epoch:
logger.info('%s has been trained for %g epochs. Fine-tuning for %g additional epochs.' %
(weights, ckpt['epoch'], epochs))
epochs += ckpt['epoch'] # finetune additional epoches
del ckpt, state_dict
# Image sizes
gs = max(int(model_student.stride.max()), 32) # grid size (max stride)
nl = model_student.model[-1].nl # number of detection layers (used for scaling hyp['obj'])
imgsz, imgsz_test = [check_img_size(x, gs) for x in opt.img_size] # verify imgsz are gs-multiples
# DP mode
if cuda and RANK == -1 and torch.cuda.device_count() > 1:
logging.warning('DP not recommended, instead use torch.distributed.run for best DDP Multi-GPU results.\n'
'See Multi-GPU Tutorial at https://github.com/ultralytics/yolov5/issues/475 to get started.')
model_student = torch.nn.DataParallel(model_student)
model_teacher = torch.nn.DataParallel(model_teacher)
# SyncBatchNorm
if opt.sync_bn and cuda and RANK != -1:
model_student = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model_student).to(device)
model_teacher = torch.nn.SyncBatchNorm.convert_sync_batchnorm(model_teacher).to(device)
logger.info('Using SyncBatchNorm()')
# Trainloader
dataloader_sr, dataset_sr = create_dataloader(train_path_source_real, train_path_source_fake, imgsz, batch_size // WORLD_SIZE,
gs, single_cls, hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=RANK, workers=workers,
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train_source_real_fake: '))
dataloader_tr, dataset_tr = create_dataloader(train_path_target_real, train_path_target_fake, imgsz, batch_size // WORLD_SIZE,
gs, single_cls, hyp=hyp, augment=True, cache=opt.cache_images, rect=opt.rect, rank=RANK, workers=workers,
image_weights=opt.image_weights, quad=opt.quad, prefix=colorstr('train_target_real_fake: '))
mlc = np.concatenate(dataset_sr.labels, 0)[:, 0].max() # max label class
# nb = len(dataloader_sr) # number of batches. (For knowledge distillation, shall we calculate iters_per_epoch like this?)
# nb = max(len(dataloader_sr), len(dataloader_tr)) # number of batches. [This way will lead to larger dataset dominanting train]
nb = (len(dataloader_sr)+len(dataloader_tr)) // 2 # number of batches. [This way will keep a balance between double datasets]
assert mlc < nc, 'Label class %g exceeds nc=%g in %s. Possible class labels are 0-%g' % (mlc, nc, data, nc - 1)
# Process 0
if RANK in [-1, 0]:
testloader = create_dataloader_single(test_path_target_real, imgsz_test, batch_size // WORLD_SIZE * 2,
gs, single_cls, hyp=hyp, cache=opt.cache_images and not notest, rect=True, rank=-1,
workers=workers, pad=0.5, prefix=colorstr('val_source_real: '))[0]
if not resume:
labels = np.concatenate(dataset_sr.labels, 0)
c = torch.tensor(labels[:, 0]) # classes
# cf = torch.bincount(c.long(), minlength=nc) + 1. # frequency
# model._initialize_biases(cf.to(device))
if plots:
plot_labels(labels, names, save_dir, loggers) # ./labels.jpg, ./labels_correlogram.jpg
if loggers['tb']:
loggers['tb'].add_histogram('classes', c, 0) # TensorBoard
# Anchors
if not opt.noautoanchor:
check_anchors(dataset_sr, model=model_student, thr=hyp['anchor_t'], imgsz=imgsz)
check_anchors(dataset_tr, model=model_teacher, thr=hyp['anchor_t'], imgsz=imgsz)
model_student.half().float() # pre-reduce anchor precision
model_teacher.half().float() # pre-reduce anchor precision
# DDP mode
if cuda and RANK != -1:
# model_student = DDP(model_student, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
'''
# https://www.wangt.cc/2021/06/one-of-the-variables-needed-for-gradient-computation-has-been-modified-by-an-inplace-operation/
# https://discuss.pytorch.org/t/ddp-sync-batch-norm-gradient-computation-modified/82847/5
# for fixing bug: RuntimeError: one of the variables needed for gradient computation has been modified by an inplace operation [2021-12-14]
'''
model_student = DDP(model_student, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK, broadcast_buffers=False)
# model_teacher = DDP(model_teacher, device_ids=[LOCAL_RANK], output_device=LOCAL_RANK)
# Model parameters
hyp['box'] *= 3. / nl # scale to layers
hyp['cls'] *= nc / 80. * 3. / nl # scale to classes and layers
hyp['obj'] *= (imgsz / 640) ** 2 * 3. / nl # scale to image size and layers
hyp['label_smoothing'] = opt.label_smoothing
model_student.nc = nc # attach number of classes to model
model_student.hyp = hyp # attach hyperparameters to model
model_student.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)
model_student.class_weights = labels_to_class_weights(dataset_sr.labels, nc).to(device) * nc # attach class weights
model_student.names = names
model_teacher.nc = nc # attach number of classes to model
model_teacher.hyp = hyp # attach hyperparameters to model
model_teacher.gr = 1.0 # iou loss ratio (obj_loss = 1.0 or iou)
model_teacher.class_weights = labels_to_class_weights(dataset_tr.labels, nc).to(device) * nc # attach class weights
model_teacher.names = names
# Start training
t0 = time.time()
nw = max(round(hyp['warmup_epochs'] * nb), 1000) # number of warmup iterations, max(3 epochs, 1k iterations)
# nw = min(nw, (epochs - start_epoch) / 2 * nb) # limit warmup to < 1/2 of training
last_opt_step = -1
maps = np.zeros(nc) # mAP per class
# results = (0, 0, 0, 0, 0, 0, 0) # P, R, [email protected], [email protected], val_loss(box, obj, cls)
results = (0, 0, 0, 0, 0, 0, 0, 0) # P, R, [email protected], [email protected], [email protected], val_loss(box, obj, cls) # Added in 2021-10-01
scheduler.last_epoch = start_epoch - 1 # do not move
scaler = amp.GradScaler(enabled=cuda)
compute_loss = ComputeLoss(model_student) # init loss class. [Not used in knowledge distillation based UMT]
logger.info(f'Image sizes {imgsz} train, {imgsz_test} test\n'
f'Using {dataloader_sr.num_workers} dataloader_sr workers\n'
f'Logging results to {save_dir}\n'
f'Starting training for {epochs} epochs...')
for epoch in range(start_epoch, epochs): # start epoch ------------------------------------------------------------
model_student.train()
model_teacher.train()
# Update image weights (optional)
if opt.image_weights:
# Generate indices
if RANK in [-1, 0]:
cw = model_student.class_weights.cpu().numpy() * (1 - maps) ** 2 / nc # class weights
iw = labels_to_image_weights(dataset_sr.labels, nc=nc, class_weights=cw) # image weights
dataset_sr.indices = random.choices(range(dataset_sr.n), weights=iw, k=dataset_sr.n) # rand weighted idx
# Broadcast if DDP
if RANK != -1:
indices = (torch.tensor(dataset_sr.indices) if RANK == 0 else torch.zeros(dataset_sr.n)).int()
dist.broadcast(indices, 0)
if RANK != 0:
dataset_sr.indices = indices.cpu().numpy()
# Update mosaic border
# b = int(random.uniform(0.25 * imgsz, 0.75 * imgsz + gs) // gs * gs)
# dataset_sr.mosaic_border = [b - imgsz, -b] # height, width borders
# mloss = torch.zeros(4, device=device) # mean losses
if all_shift:
mloss = torch.zeros((4 + all_shift), device=device) # mean losses
else:
mloss = torch.zeros(4, device=device) # mean losses
# if RANK != -1 and False: # load dats sequentially in UMT
if RANK != -1: # load dats sequentially in UMT
dataloader_sr.sampler.set_epoch(epoch) # For DistributedSampler, this will shuffle dataset
dataloader_tr.sampler.set_epoch(epoch)
# dataloader_sr.sampler.set_epoch(epoch+random.random()) # For DistributedSampler, this will shuffle dataset
# dataloader_tr.sampler.set_epoch(epoch+random.random())
# pbar = enumerate(dataloader)
pbar = enumerate([ind for ind in range(nb)])
# source and target dataset have different images number
data_iter_sr = iter(dataloader_sr)
data_iter_tr = iter(dataloader_tr)
# logger.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size'))
if all_shift:
log_list = ['Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size']
if opt.consistency_loss: log_list = log_list[:6] + ['cons'] + log_list[6:]
shift = opt.consistency_loss
# if opt.sem_gcn: log_list = log_list[:6+shift] + ['sem'] + log_list[6+shift:]
# shift += opt.sem_gcn
logger.info(('\n' + '%10s' * (8 + shift)) % tuple(log_list))
else:
logger.info(('\n' + '%10s' * 8) % ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size'))
if RANK in [-1, 0]:
pbar = tqdm(pbar, total=nb) # progress bar
student_optimizer.zero_grad()
# for i, (imgs, targets, paths, _) in pbar:
for i, ind in pbar:
# start batch -------------------------------------------------------
ni = i + nb * epoch # number integrated batches (since train start)
# imgs = imgs.to(device, non_blocking=True).float() / 255.0 # uint8 to float32, 0-255 to 0.0-1.0
# for model_student, source real and fake images, with using labels
try:
imgs_sr, imgs_sf, targets_sr, paths_sr, paths_sf, _ = next(data_iter_sr)
except:
data_iter_sr = iter(dataloader_sr)
imgs_sr, imgs_sf, targets_sr, paths_sr, paths_sf, _ = next(data_iter_sr)
imgs_sr = imgs_sr.to(device, non_blocking=True).float() / 255.0
imgs_sf = imgs_sf.to(device, non_blocking=True).float() / 255.0
# for model_student and model_teacher, target real and fake images, without using labels
try:
imgs_tr, imgs_tf, targets_tr, paths_tr, paths_tf, _ = next(data_iter_tr)
except:
data_iter_tr = iter(dataloader_tr)
imgs_tr, imgs_tf, targets_tr, paths_tr, paths_tf, _ = next(data_iter_tr)
imgs_tr = imgs_tr.to(device, non_blocking=True).float() / 255.0
imgs_tf = imgs_tf.to(device, non_blocking=True).float() / 255.0
# Warmup
if ni <= nw:
xi = [0, nw] # x interp
# model.gr = np.interp(ni, xi, [0.0, 1.0]) # iou loss ratio (obj_loss = 1.0 or iou)
accumulate = max(1, np.interp(ni, xi, [1, nbs / batch_size]).round())
for j, x in enumerate(student_optimizer.param_groups):
# bias lr falls from 0.1 to lr0, all other lrs rise from 0.0 to lr0
x['lr'] = np.interp(ni, xi, [hyp['warmup_bias_lr'] if j == 2 else 0.0, x['initial_lr'] * lf(epoch)])
if 'momentum' in x:
x['momentum'] = np.interp(ni, xi, [hyp['warmup_momentum'], hyp['momentum']])
# Multi-scale
if opt.multi_scale:
temp_imgs_list = [imgs_sr, imgs_sf, imgs_tr, imgs_tf]
for i, imgs in enumerate(temp_imgs_list):
sz = random.randrange(imgsz * 0.5, imgsz * 1.5 + gs) // gs * gs # size
sf = sz / max(imgs.shape[2:]) # scale factor
if sf != 1:
ns = [math.ceil(x * sf / gs) * gs for x in imgs.shape[2:]] # new shape (stretched to gs-multiple)
imgs = F.interpolate(imgs, size=ns, mode='bilinear', align_corners=False)
temp_imgs_list[i] = imgs
[imgs_sr, imgs_sf, imgs_tr, imgs_tf] = temp_imgs_list
# Forward
with amp.autocast(enabled=cuda):
# [branch 1] for model_student, with using labels
model_student.zero_grad()
pred_sr = model_student(imgs_sr) # forward
loss_sr, loss_items_sr = compute_loss(pred_sr, targets_sr.to(device)) # loss scaled by batch_size
# [branch 2] for model_student, with using labels
pred_sf = model_student(imgs_sf) # forward
loss_sf, loss_items_sf = compute_loss(pred_sf, targets_sr.to(device)) # loss scaled by batch_size
# [branch 3] for model_teacher, without using labels
model_teacher.eval()
pred_tf, train_out = model_teacher(imgs_tf) # forward. when eval(), the output is (x1, x2) in yolo.py
pred_tf_nms = non_max_suppression(pred_tf, conf_thres=conf_thres, iou_thres=iou_thres,
max_det=max_gt_boxes, multi_label=True, agnostic=single_cls) # pred_tf_nms type is list with batch_size length
# [branch 4] for model_student, without using labels
pred_tr = model_student(imgs_tr)
# print(ni, len(pred_tr), pred_tr[0].shape, len(pred_tf_nms), pred_tf_nms[0].shape, pred_tf_nms[0], "\n",
# imgs_tr.shape, targets_tr.shape, "\n", targets_tr, "\n", paths_tr)
per_batch_size, channels, height, width = imgs_tf.shape
# print(type(targets_tr), targets_tr.shape, type(targets_tr[0]),
# targets_tr[0].shape, targets_tr[0].cpu().numpy(), targets_tr[-1].cpu().numpy())
# output: <class 'torch.Tensor'> torch.Size([49, 6]) <class 'torch.Tensor'>
# torch.Size([6]) [0,6,0.91104,0.40758,0.13493,0.2201] [3,4,0.55561,0.9577,0.080059,0.084592]
pred_labels_out_batch = []
for img_id in range(per_batch_size):
labels_num = pred_tf_nms[img_id].shape[0] # pred_tf_nms prediction shape is (bs,n,6), per image [xyxy, conf, cls]
if labels_num:
labels_list = torch.cat((pred_tf_nms[img_id][:, 5].unsqueeze(-1),
pred_tf_nms[img_id][:, 0:4]), dim=1) # remove predicted conf, new format [cls x y x y]
labels_list[:, 1:5] = xyxy2xywhn(labels_list[:, 1:5], w=width, h=height) # xyxy to xywh normalized
pred_labels_out = torch.cat(((torch.ones(labels_num)*img_id).unsqueeze(-1).to(device),
labels_list), dim=1) # pred_labels_out shape is (labels_num, 6), per label format [img_id cls x y x y]
# else:
# pred_labels_out = pred_tf_nms[img_id] # in this condition, pred_tf_nms[img_id] tensor size is [0,6]
'''[BUG] When training, nan can appear in batchnorm when all the values are the same, and thus std = 0'''
# pred_labels_out = torch.from_numpy(np.array([[img_id,0,0,0,0,0]])).to(device)
'''If no bboxes have been detected, we set a [0,0,w,h](xyxy) or [0.5,0.5,1,1](xywh) bounding-box for the image'''
# pred_labels_out = torch.from_numpy(np.array([[img_id,0,0.5,0.5,1,1]])).to(device)
pred_labels_out_batch.append(pred_labels_out)
if len(pred_labels_out_batch) != 0:
pred_labels = torch.cat(pred_labels_out_batch, dim=0)
else:
# pred_labels = torch.from_numpy(np.array([[0,0, 0.5, 0.5, 1, 1]])).to(device)
pred_labels = torch.from_numpy(np.array([[0,0, 0.5, 0.5, random.uniform(0.2,0.8), random.uniform(0.2,0.8)]])).to(device)
loss_distillation, loss_items_distillation = compute_loss(pred_tr, pred_labels.to(device)) # loss scaled by batch_size
# consistency loss (source_real and source_fake should have similarly outputs)
if opt.consistency_loss:
# loss_cons = torch.abs(loss_sr - loss_sf) * opt.alpha_weight # L1 loss
loss_cons = torch.abs(loss_sr - loss_sf)**2 * opt.alpha_weight # L2 loss
# combine all losses
loss = loss_sr + loss_sf + loss_distillation * lambda_weight
loss_items = loss_items_sr + loss_items_sf + loss_items_distillation * lambda_weight
if opt.consistency_loss:
loss += loss_cons
# print(loss_items.shape, loss_cons.shape) # torch.Size([4]) torch.Size([1])
loss_items[3] += loss_cons.detach()[0] # (lbox, lobj, lcls, total_loss)
loss_items = torch.cat((loss_items, loss_cons.detach()), 0)
if RANK != -1:
loss *= WORLD_SIZE # gradient averaged between devices in DDP mode
if opt.quad:
loss *= 4.
try:
# Backward
scaler.scale(loss).backward()
# Optimizer
if ni - last_opt_step >= accumulate:
scaler.step(student_optimizer) # optimizer.step
scaler.update()
student_optimizer.zero_grad()
if ema:
ema.update(model_student)
last_opt_step = ni
model_teacher.zero_grad()
teacher_optimizer.step()
except:
# for possible bug when running scaler.scale(loss).backward()
print("RuntimeError: Function 'CudnnConvolutionBackward0' returned nan values in its 1th output")
print(targets_sr, "\n", paths_sr, "\n", targets_tr, "\n", paths_tr)
print(pred_tf_nms, "\n", pred_labels, "\n", loss, "\n", loss_items)
print("Currently, we have not been able to find the bug. Please resume training from the last running...")
# continue
# Print
if RANK in [-1, 0]:
mloss = (mloss * i + loss_items) / (i + 1) # update mean losses
mem = '%.3gG' % (torch.cuda.memory_reserved() / 1E9 if torch.cuda.is_available() else 0) # (GB)
s = ('%10s' * 2 + '%10.4g' * (6 + all_shift)) % (
f'{epoch}/{epochs - 1}', mem, *mloss, targets_sr.shape[0], imgs_sr.shape[-1])
pbar.set_description(s)
# Plot
if plots and ni < 3:
f = save_dir / f'train_sr_batch{ni}.jpg' # filename
Thread(target=plot_images, args=(imgs_sr, targets_sr, paths_sr, f), daemon=True).start() # ./train_sr_batch[0,1,2].jpg
f = save_dir / f'train_sf_batch{ni}.jpg' # filename
Thread(target=plot_images, args=(imgs_sf, targets_sr, paths_sf, f), daemon=True).start() # ./train_sf_batch[0,1,2].jpg
f = save_dir / f'train_tr_batch{ni}.jpg' # filename
Thread(target=plot_images, args=(imgs_tr, targets_tr, paths_tr, f), daemon=True).start() # ./train_tr_batch[0,1,2].jpg
f = save_dir / f'train_tf_batch{ni}.jpg' # filename
Thread(target=plot_images, args=(imgs_tf, targets_tr, paths_tf, f), daemon=True).start() # ./train_tf_batch[0,1,2].jpg
if loggers['tb'] and ni == 0: # TensorBoard
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress jit trace warning
loggers['tb'].add_graph(torch.jit.trace(de_parallel(model_student), imgs_sr[0:1], strict=False), [])
elif plots and ni == 10 and loggers['wandb']:
wandb_logger.log({'Mosaics': [loggers['wandb'].Image(str(x), caption=x.name) for x in
save_dir.glob('train*.jpg') if x.exists()]})
# end batch ------------------------------------------------------------------------------------------------
# Scheduler
lr = [x['lr'] for x in student_optimizer.param_groups] # for loggers
scheduler.step()
# DDP process 0 or single-GPU
if RANK in [-1, 0]:
# mAP
ema.update_attr(model_student, include=['yaml', 'nc', 'hyp', 'gr', 'names', 'stride', 'class_weights'])
final_epoch = epoch + 1 == epochs
if not notest or final_epoch: # Calculate mAP
wandb_logger.current_epoch = epoch + 1
results, maps, _ = test.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz_test,
model=ema.ema,
single_cls=single_cls,
dataloader=testloader,
save_dir=save_dir,
save_json=is_coco and final_epoch,
verbose=nc < 50 and final_epoch,
plots=plots and final_epoch, # ./test_batch[0,1,2]_labels.jpg ./test_batch[0,1,2]_pred.jpg ...
wandb_logger=wandb_logger,
compute_loss=compute_loss)
# Write
with open(results_file, 'a') as f:
# f.write(s + '%10.4g' * 7 % results + '\n') # append metrics, val_loss
f.write(s + '%10.4g' * 8 % results + '\n') # append metrics, val_loss # Added in 2021-10-01
# former 8 values ('Epoch', 'gpu_mem', 'box', 'obj', 'cls', 'total', 'labels', 'img_size')
# latter 8 values (P, R, [email protected], [email protected], [email protected], val_loss(box, obj, cls))
# Log
# tags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', # train loss
tags = ['train/box_loss', 'train/obj_loss', 'train/cls_loss', 'train/total_loss', # Added in 2022-04-04
# 'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.5:0.95',
'metrics/precision', 'metrics/recall', 'metrics/mAP_0.5', 'metrics/mAP_0.75',
'metrics/mAP_0.5:0.95', # Added in 2021-10-01
'val/box_loss', 'val/obj_loss', 'val/cls_loss', # val loss
'x/lr0', 'x/lr1', 'x/lr2'] # params
if opt.consistency_loss: tags = tags[:4] + ['train/cons_loss'] + tags[4:] # Added in 2022-04-04
# for x, tag in zip(list(mloss[:-1]) + list(results) + lr, tags):
for x, tag in zip(list(mloss) + list(results) + lr, tags): # Changed in 2022-04-04
if loggers['tb']:
loggers['tb'].add_scalar(tag, x, epoch) # TensorBoard
if loggers['wandb']:
wandb_logger.log({tag: x}) # W&B
# Update best mAP
# fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, [email protected], [email protected]]
fi = fitness(np.array(results).reshape(1, -1)) # weighted combination of [P, R, [email protected], [email protected], [email protected]] # Added in 2021-10-01
if fi > best_fitness:
best_fitness = fi
wandb_logger.end_epoch(best_result=best_fitness == fi)
# Save model
if (not nosave) or (final_epoch and not evolve): # if save
ckpt_student = {
'epoch': epoch,
'best_fitness': best_fitness,
'training_results': results_file.read_text(),
'model': deepcopy(de_parallel(model_student)).half(),
'ema': deepcopy(ema.ema).half(),
'updates': ema.updates,
'optimizer': student_optimizer.state_dict(),
'wandb_id': wandb_logger.wandb_run.id if loggers['wandb'] else None}
ckpt_teacher = {
'epoch': epoch,
'best_fitness': best_fitness,
'model': deepcopy(de_parallel(model_teacher)).half(),
'wandb_id': wandb_logger.wandb_run.id if loggers['wandb'] else None}
# Save last, best and delete for model_student and model_teacher
torch.save(ckpt_student, last_student)
torch.save(ckpt_teacher, last_teacher)
if best_fitness == fi:
torch.save(ckpt_student, best_student)
torch.save(ckpt_teacher, best_teacher)
if loggers['wandb']:
if ((epoch + 1) % opt.save_period == 0 and not final_epoch) and opt.save_period != -1:
wandb_logger.log_model(last.parent, opt, epoch, fi, best_model=best_fitness == fi)
del ckpt_student, ckpt_teacher
# end epoch ----------------------------------------------------------------------------------------------------
# end training -----------------------------------------------------------------------------------------------------
if RANK in [-1, 0]:
logger.info(f'{epoch - start_epoch + 1} epochs completed in {(time.time() - t0) / 3600:.3f} hours.\n')
if plots:
plot_results(save_dir=save_dir) # save as results.png, confusion_matrix.png
if loggers['wandb']:
files = ['results.png', 'confusion_matrix.png', *[f'{x}_curve.png' for x in ('F1', 'PR', 'P', 'R')]]
wandb_logger.log({"Results": [loggers['wandb'].Image(str(save_dir / f), caption=f) for f in files
if (save_dir / f).exists()]})
if not evolve:
if is_coco: # COCO dataset
for m in [last_student, best_student] if best_student.exists() else [last_student]: # speed, mAP tests
results, _, _ = test.run(data_dict,
batch_size=batch_size // WORLD_SIZE * 2,
imgsz=imgsz_test,
conf_thres=0.001,
iou_thres=0.7,
model=attempt_load(m, device).half(),
single_cls=single_cls,
dataloader=testloader,
save_dir=save_dir,
save_json=True,
plots=False)
# Strip optimizers
for f in last_student, best_student:
if f.exists():
strip_optimizer(f) # strip optimizers, this will apparently reduce the model size
if loggers['wandb']: # Log the stripped model
loggers['wandb'].log_artifact(str(best_student if best_student.exists() else last_student), type='model',
name='run_' + wandb_logger.wandb_run.id + '_model',
aliases=['latest', 'best', 'stripped'])
wandb_logger.finish_run()
torch.cuda.empty_cache()
return results
def parse_opt(known=False):
parser = argparse.ArgumentParser()
parser.add_argument('--weights', type=str, default='yolov5s.pt', help='initial weights path')
parser.add_argument('--cfg', type=str, default='', help='model.yaml path')
parser.add_argument('--data', type=str, default='data/coco128.yaml', help='dataset.yaml path')
parser.add_argument('--hyp', type=str, default='data/hyps/hyp.scratch.yaml', help='hyperparameters path')
parser.add_argument('--epochs', type=int, default=300)
parser.add_argument('--batch-size', type=int, default=16, help='total batch size for all GPUs')
parser.add_argument('--img-size', nargs='+', type=int, default=[640, 640], help='[train, test] image sizes')
parser.add_argument('--rect', action='store_true', help='rectangular training')
parser.add_argument('--resume', nargs='?', const=True, default=False, help='resume most recent training')
parser.add_argument('--nosave', action='store_true', help='only save final checkpoint')
parser.add_argument('--notest', action='store_true', help='only test final epoch')
parser.add_argument('--noautoanchor', action='store_true', help='disable autoanchor check')
parser.add_argument('--evolve', action='store_true', help='evolve hyperparameters [removed]')
parser.add_argument('--bucket', type=str, default='', help='gsutil bucket [removed]')
parser.add_argument('--cache-images', action='store_true', help='cache images for faster training')
parser.add_argument('--image-weights', action='store_true', help='use weighted image selection for training')
parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')
parser.add_argument('--multi-scale', action='store_true', help='vary img-size +/- 50%%')
parser.add_argument('--single-cls', action='store_true', help='train multi-class data as single-class')
parser.add_argument('--adam', action='store_true', help='use torch.optim.Adam() optimizer')
parser.add_argument('--sync-bn', action='store_true', help='use SyncBatchNorm, only available in DDP mode')
parser.add_argument('--workers', type=int, default=8, help='maximum number of dataloader workers')
parser.add_argument('--project', default='runs/train', help='save to project/name')
parser.add_argument('--entity', default=None, help='W&B entity')
parser.add_argument('--name', default='exp', help='save to project/name')
parser.add_argument('--exist-ok', action='store_true', help='existing project/name ok, do not increment')
parser.add_argument('--quad', action='store_true', help='quad dataloader')
parser.add_argument('--linear-lr', action='store_true', help='linear LR')
parser.add_argument('--label-smoothing', type=float, default=0.0, help='Label smoothing epsilon')
parser.add_argument('--upload_dataset', action='store_true', help='Upload dataset as W&B artifact table')
parser.add_argument('--bbox_interval', type=int, default=-1, help='Set bounding-box image logging interval for W&B')
parser.add_argument('--save_period', type=int, default=-1, help='Log model after every "save_period" epoch')
parser.add_argument('--artifact_alias', type=str, default="latest", help='version of dataset artifact to be used')
parser.add_argument('--local_rank', type=int, default=-1, help='DDP parameter, do not modify')
parser.add_argument('--teacher_alpha', type=float, default=0.99, help='Teacher EMA alpha (decay) in UMT')
parser.add_argument('--conf_thres', type=float, default=0.5, help='Confidence threshold for pseudo label in UMT')
parser.add_argument('--iou_thres', type=float, default=0.3, help='Overlap threshold used for non-maximum suppression in UMT')
parser.add_argument('--max_gt_boxes', type=int, default=20, help='Maximal number of gt rois in an image during training in UMT')
parser.add_argument('--lambda_weight', type=float, default=0.005, help='The weight for distillation loss in UMT')
parser.add_argument('--consistency_loss', action='store_true', help='Whether use the consistency loss (newly added)')
parser.add_argument('--alpha_weight', type=float, default=2.0, help='The weight for the consistency loss (newly added)')
parser.add_argument('--student_weight', type=str, default='None', help='Resuming weights path of student model in UMT')
parser.add_argument('--teacher_weight', type=str, default='None', help='Resuming weights path of teacher model in UMT')
parser.add_argument('--save_dir', type=str, default='None', help='Resuming project path in UMT')
opt = parser.parse_known_args()[0] if known else parser.parse_args()
return opt
def main(opt):
set_logging(RANK)
if RANK in [-1, 0]:
print(colorstr('train: ') + ', '.join(f'{k}={v}' for k, v in vars(opt).items()))
check_git_status()
check_requirements(exclude=['thop'])
# Resume
wandb_run = check_wandb_resume(opt)
if opt.resume and not wandb_run: # resume an interrupted run
ckpt = opt.resume if isinstance(opt.resume, str) else get_latest_run() # specified or most recent path
assert os.path.isfile(ckpt), 'ERROR: --resume checkpoint does not exist'
with open(Path(ckpt).parent.parent / 'opt.yaml') as f:
opt = argparse.Namespace(**yaml.safe_load(f)) # replace
opt.cfg, opt.weights, opt.resume = '', ckpt, True # reinstate
logger.info('Resuming training from %s' % ckpt)
else:
# opt.hyp = opt.hyp or ('hyp.finetune.yaml' if opt.weights else 'hyp.scratch.yaml')
opt.data, opt.cfg, opt.hyp = check_file(opt.data), check_file(opt.cfg), check_file(opt.hyp) # check files
assert len(opt.cfg) or len(opt.weights), 'either --cfg or --weights must be specified'
opt.img_size.extend([opt.img_size[-1]] * (2 - len(opt.img_size))) # extend to 2 sizes (train, test)
opt.name = 'evolve' if opt.evolve else opt.name
if opt.save_dir == "None":
opt.save_dir = str(increment_path(Path(opt.project) / opt.name, exist_ok=opt.exist_ok | opt.evolve))
# DDP mode
device = select_device(opt.device, batch_size=opt.batch_size)
if LOCAL_RANK != -1:
from datetime import timedelta
assert torch.cuda.device_count() > LOCAL_RANK, 'insufficient CUDA devices for DDP command'
torch.cuda.set_device(LOCAL_RANK)
device = torch.device('cuda', LOCAL_RANK)
# dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo", timeout=timedelta(seconds=60))
dist.init_process_group(backend="nccl" if dist.is_nccl_available() else "gloo", timeout=timedelta(seconds=600)) # fixed bug in 2021-07-13
assert opt.batch_size % WORLD_SIZE == 0, '--batch-size must be multiple of CUDA device count'
assert not opt.image_weights, '--image-weights argument is not compatible with DDP training'
# Train
if not opt.evolve:
train(opt.hyp, opt, device)
if WORLD_SIZE > 1 and RANK == 0:
_ = [print('Destroying process group... ', end=''), dist.destroy_process_group(), print('Done.')]
if __name__ == "__main__":
opt = parse_opt()
main(opt)
- Yolov5相关论文及代码
https://github.com/ultralytics/yolov5
第二:基于yolov5的路面障碍物检测算法
0.前言
1、研究的主要内容
本文旨在研究一种基于YOLOV5算法的路面障碍物检测方法。主要内容包括:
- 对YOLOV5算法的原理和结构进行深入分析,阐述其在障碍物检测中的适用性和优势。
- 针对路面障碍物检测的特点,对YOLOV5算法进行改进和优化,以提高检测准确性和实时性。
- 搭建实验平台,采集并标注路面障碍物数据集,用于训练和验证所提出算法的有效性。
- 通过实验对比,评估所提出算法的性能表现,并分析其在实际应用中的潜在问题和挑战。
2、技术原理
基于YOLOV5的路面障碍物检测算法是一种实时目标检测算法。其技术原理主要包括:
- 采用深度学习技术,构建卷积神经网络(CNN)来提取图像特征。
- 引入边界框回归和类别分类,实现对路面障碍物的精确检测。
- 利用多尺度特征融合策略,提高算法对不同大小障碍物的适应性。
- 通过优化模型结构和训练策略,降低计算复杂度,提高检测速度。
3、开发平台(主要设备和仪器)
开发平台主要包括:
- 计算机硬件:高性能GPU(如NVIDIA Titan X或更高级别),用于加速深度学习模型的训练和推理。
- 数据采集设备:高清摄像头、激光雷达或毫米波雷达等,用于获取路面障碍物图像和数据。
- 数据标注工具:用于对采集的图像数据进行标注,供训练使用。
- 编程环境:PyCharm平台、Python、TensorFlow或PyTorch等深度学习框架,以及相关的开发工具和库。
4、选题依据和意义
随着智能交通系统的快速发展,路面障碍物检测技术在提高交通安全、推动自动驾驶技术方面具有重要意义。基于YOLOV5的路面障碍物检测算法研究具有重要的理论价值和实际应用前景:
- 理论价值:该研究有助于推动目标检测算法的发展,完善深度学习在计算机视觉领域的应用理论体系。通过对YOLOV5算法的改进和优化,可以为其他类似问题提供新的思路和方法。
实际应用价值:该算法能够实时、准确地检测路面障碍物,为自动驾驶系统的实现提供关键技术支持。通过提高交通系统的智能化水平,有助于减少交通事故、提高交通效率,为人类出行提供更加安全、便捷的服务。
1.开发语言和平台
我们任务书里面介绍的开发工具和平台依旧不变。编程环境:PyCharm平台、Python、TensorFlow或PyTorch等深度学习框架,以及相关的开发工具和库。
2.算法设计背景
随着社会经济的快速发展,汽车持有量不断增加,城市交通系统日益庞大,交通事故问题和交通拥堵问题日益加剧。目前人工智能技术正在高速发展,无人驾驶将是未来汽车行业的主要发展方向,发展智能交通可以一定程度上缓解交通压力,是解决以上交通难题的途径之一。基于视觉的YOLOV5路面障碍物检测是无人驾驶系统环境感知层的两个重要模块,所以实现无人车对行驶道路上的目标和路面障碍物进行检测与识别具有重要的实用价值,以提升无人驾驶系统的安全性,具有重要的理论指导意义。本文主要基于YOLOV5系列实现道路场景障碍物行人、交通设施、坑槽洼地等区域的检测。
1、 路面障碍分类
其实对于无人驾驶领域来说,路面障碍物分类很多!
除了自身,其余路上的一切对象都可以视作障碍物。
如:路上的车辆、行人、交通设施、围栏、石墩、路面上的坑坑洼洼等都可以是障碍物。那么,包罗万象的事物,我梦只能选取部分来做算法分析识别和及案例数据集使用。
根据物体的运动状态可以将位于路面上的障碍物分为两大类别:动态的和非动态的障碍物。
选取多个物体作为本文障碍数据集的组成类别。其中,person 表示行人和路人,他们可以主动进行避让,属于动态障碍。路上周围的立杆,包括电线杆、通信杆等,红绿灯,静态永久障碍。ashcan 表示垃圾箱、垃圾桶等,ashcan 可能位于路面上,也可能被放置在道路的周围,包括永久固定在某个位置的垃圾箱和临时的垃圾桶。motorbike、bicycle 和 tricycle 表示停放在道路周边的摩托车、电力摩托车、自行车和三轮车等,属于被动避让障碍。dog是行人携带的宠物狗或者一些其他视障人士出行携带的导盲犬等,属于动态主动避让障碍。
1、样本采集
确定好障碍类别后开始收集障碍物的图像用于数据集建立,关于图像的收集,总共确定了几个来源。首先根据确定的类别与 COCO 数据集和 VOC 数据集中已有的类别进行对比,从中选取了一些共同的物体类别并对其图像和标注信息进行提取,包括 person、bicycle、car、bus、motorbike、dog、truck、stop sign 和 fire hydrant。然而这些类别仅仅只是障碍数据集其中的一部分,剩余的几个类别通过利用移动设备进行拍摄和网络查找搜索等方式进行收集。其次还从 TT100K 数据集中提取了部分图片,TT100K 数据集中的图像拥有着较大的分辨率,能够增强数据集的泛化性能。但是由于 TT100K 的数据集标注方式与 VOC 不同,因此仅仅只需要提取图像即可,然后再逐一标注。
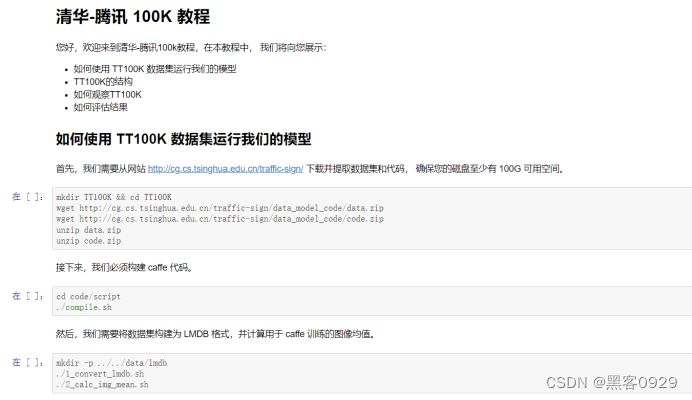
2、数据集下载地址
https://link.zhihu.com/?target=http%3A//cg.cs.tsinghua.edu.cn/traffic-sign/data_model_code/data.zip
创建了一个大型 来自100000张腾讯街景全景图的交通标志基准,正在进行 超越以前的基准。 我们称之为基准 清华-腾讯 100K。 它提供 1000 0 0 张图像,其中包含 30000 个流量标志实例。这些图像涵盖了以下方面的巨大变化 照度和天气条件。 每个交通标志 Benchmark 使用类标签、边界框和像素掩码进行注释。 其次,我们演示了鲁棒的端到端卷积神经网络 (CNN)可以同时检测和分类交通标志。 以前的大多数 CNN 图像处理解决方案都针对占据 图像的很大比例,而这样的网络不起作用 对于仅占据图像一小部分的目标对象,例如 这里的交通标志。实验结果表明 我们网络的稳健性及其相对于替代品的优越性。 本文中介绍的基准测试、源代码和 CNN 模型是 公开的。

这里关于清华-腾讯数据集的操作,有一个开源的项目你可以参考一下。
https://github.com/asyncbridge/tsinghua-tencent-100k
详情请参考清华-腾讯100K教程:
Tsinghua-Tencent 100K Tutorial
YOLOV5算法识别路面障碍物,并检测,那么障碍物也就是物体,这个本质上是一样的概念。总的来说,就是机器视觉里面的图像、视频识别与检测。由于YOLOV5算法很成熟了,需要我们做一些优化和改进!这里给你一个实验的代码和列子。
# Copyright 2023 LL.
# 导入PyTorch的nn模块,这个模块包含了各种神经网络相关的类和函数
import torch.nn as nn
# 定义一个名为activations的字典,它的键是激活函数的名称,值是对应的激活函数类
activations = {
"ReLU": nn.ReLU, # ReLU激活函数
"LeakyReLU": nn.LeakyReLU, # LeakyReLU激活函数
"ReLU6": nn.ReLU6, # ReLU6激活函数
"SELU": nn.SELU, # SELU激活函数
"ELU": nn.ELU, # ELU激活函数
"GELU": nn.GELU, # GELU激活函数
"PReLU": nn.PReLU, # PReLU激活函数
"SiLU": nn.SiLU, # SiLU激活函数
"HardSwish": nn.Hardswish, # HardSwish激活函数
# 注意这里有一个重复的键"Hardswish",这是一个错误,应该被修复
None: nn.Identity, # 如果激活函数名称为None,则返回恒等映射(不做任何激活)
}
# 定义一个名为act_layers的函数,它接受一个字符串参数name,表示激活函数的名称
def act_layers(name):
# 断言:确保输入的name在activations字典的键中
assert name in activations.keys()
# 根据name的值返回相应的激活层
if name == "LeakyReLU":
# 如果name是"LeakyReLU",返回带有指定negative_slope和inplace参数的LeakyReLU层
return nn.LeakyReLU(negative_slope=0.1, inplace=True)
elif name == "GELU":
# 如果name是"GELU",返回默认的GELU层
return nn.GELU()
elif name == "PReLU":
# 如果name是"PReLU",返回默认的PReLU层
return nn.PReLU()
else:
# 对于其他情况,直接返回activations字典中对应的激活函数类,并设置inplace参数为True
return activations[name](inplace=True)首先看论文:
Improved YOLOv5 network for real-time multi-scale traffic sign detection | Papers With Code

本文提出了一种改进的特征金字塔模型AF-FPN,该模型利用自适应注意力模块(AAM)和特征增强模块(FEM)来减少特征图生成过程中的信息损失,增强特征金字塔的表示能力。我们用AF-FPN替换了YOLOv5中原有的特征金字塔网络,在保证实时检测的前提下,提升了YOLOv5网络对多尺度目标的检测性能。此外,提出了一种新的自动学习数据增强方法,以丰富数据集并提高模型的鲁棒性,使其更适合实际场景。在清华-腾讯100K(TT100K)数据集上的大量实验结果表明,与几种最先进的方法相比,所提方法的有效性和优越性。
其中代码:工程文件夹:AF_FPN-main
import random
import torch
import torch.nn as nn
import torch.nn.functional as F
from conv import ConvModule
from init_weights import xavier_init
# from ..module.conv import ConvModule
# from ..module.init_weights import xavier_init
class AAM(nn.Module):
def __init__(self, feature_map_shape, pool_nums=3, in_channels=704, out_channels=128):
super(AAM, self).__init__()
self.pool_nums = pool_nums
self.out_channels = out_channels
self.adaptive_average_pool = nn.ModuleList()
self.cv1 = nn.ModuleList()
self.M5_feature_map_shape = feature_map_shape
for i in range(self.pool_nums):
self.adaptive_average_pool.append(nn.AdaptiveAvgPool2d(int(random.uniform(0.1, 0.5) * self.M5_feature_map_shape)))
self.cv1.append((nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1)))
self.layer = nn.Sequential(
nn.Conv2d(in_channels=out_channels * 3, out_channels=out_channels, kernel_size=1),
nn.BatchNorm2d(num_features=out_channels),
nn.ReLU(),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels, kernel_size=3, padding=1),
nn.ReLU(),
nn.Conv2d(in_channels=out_channels, out_channels=out_channels * 3, kernel_size=1),
nn.Sigmoid()
)
self.cv2 = nn.Conv2d(in_channels=in_channels, out_channels=out_channels, kernel_size=1)
def forward(self, x):
upsample_out = []
# 对于每个池化层
for i in range(self.pool_nums):
# 进行自适应平均池化
pool = self.adaptive_average_pool[i](x)
# 通过1x1的卷积层,保持通道数为256
cv1 = self.cv1[i](pool)
# 进行上采样,使特征图大小与原始输入一致
upsample = F.interpolate(cv1, size=[x.size(2), x.size(3)], mode="nearest")
# 将上采样后的特征图添加到列表中
upsample_out.append(upsample)
# 将三个上采样后的特征图在通道维度上拼接
cat_out = torch.cat((upsample_out[0], upsample_out[1], upsample_out[2]), dim=1)
# 通过一系列层(1x1卷积、ReLU激活、3x3卷积、sigmoid激活)得到空间权重映射
weight_map = self.layer(cat_out)
# 使用空间权重映射对拼接后的特征图进行加权
out = cat_out * weight_map
# 将加权后的特征图在通道维度上分割成多个部分
out = torch.split(out, dim=1, split_size_or_sections=self.out_channels)
# 将分割后的特征图相加
out = sum(out)
# 对原始输入x进行另一个卷积操作
cv2 = self.cv2(x)
# 将卷积后的结果与加权并相加后的特征图相加,得到最终输出
out = out + cv2
return out
class DilatedConvBlock(nn.Module):
def __init__(self, in_channels, out_channels, dilation):
super(DilatedConvBlock, self).__init__()
# 使用与膨胀因子相同的padding因子,即可确保输入、输出特征图大小一致。
self.dilated_conv = nn.Conv2d(in_channels, out_channels, kernel_size=3, padding=dilation, dilation=dilation)
self.relu = nn.ReLU()
def forward(self, x):
out = self.relu(self.dilated_conv(x))
return out
class MultiDilatedConvModel(nn.Module):
def __init__(self, in_channels, out_channels, dilations):
super(MultiDilatedConvModel, self).__init__()
self.conv_blocks = nn.ModuleList()
for dilation in dilations:
self.conv_blocks.append(DilatedConvBlock(in_channels, out_channels, dilation))
def forward(self, x):
out = []
for conv_block in self.conv_blocks:
out.append(conv_block(x))
return out
class FEM(nn.Module):
def __init__(self, in_channels, out_channels, dilations=[1, 3, 5]):
super(FEM, self).__init__()
self.multi_dilation = MultiDilatedConvModel(in_channels, out_channels, dilations)
def forward(self, x):
out = self.multi_dilation(x)
return tuple(out)
class AF_FPN(nn.Module):
def __init__(self, in_channels, out_channels, num_outs, image_size=640,
start_level=0, end_level=-1, conv_cfg=None, norm_cfg=None,
activation=None):
super(AF_FPN, self).__init__()
assert isinstance(in_channels, list)
self.in_channels = in_channels
self.out_channels = out_channels
self.num_ins = len(in_channels)
self.num_outs = num_outs
self.fp16_enabled = False
if end_level == -1:
self.backbone_end_level = self.num_ins
assert num_outs >= self.num_ins - start_level
else:
# if end_level < inputs, no extra level is allowed
self.backbone_end_level = end_level
assert end_level <= len(in_channels)
assert num_outs == end_level - start_level
self.start_level = start_level
self.end_level = end_level
self.lateral_convs = nn.ModuleList()
for i in range(self.start_level, self.backbone_end_level):
l_conv = ConvModule(in_channels[i], out_channels, 1, conv_cfg=conv_cfg,
norm_cfg=norm_cfg, activation=activation, inplace=False)
self.lateral_convs.append(l_conv)
# AAM
self.aam = AAM(feature_map_shape=image_size // 16, in_channels=in_channels[-1], out_channels=out_channels)
# FEM
self.fem = FEM(in_channels=out_channels, out_channels=out_channels)
self.avp = nn.ModuleList()
self.avp.append(nn.AdaptiveAvgPool2d(image_size // 4))
self.avp.append(nn.AdaptiveAvgPool2d(image_size // 8))
self.avp.append(nn.AdaptiveAvgPool2d(image_size // 16))
self.init_weights()
# default init_weights for conv(msra) and norm in ConvModule
def init_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
xavier_init(m, distribution="uniform")
def forward(self, inputs):
assert len(inputs) == len(self.in_channels)
# build laterals
laterals = [
lateral_conv(inputs[i + self.start_level]) for i, lateral_conv in enumerate(self.lateral_convs)
]
M6 = self.aam(inputs[-1])
laterals[-1] = M6 + laterals[-1]
# Single FEM Output
laterals_0 = self.fem(laterals[0])
laterals_1 = self.fem(laterals[1])
laterals_2 = self.fem(laterals[2])
# Add FEM-Output
laterals[0] = laterals[0] + laterals_0[0] + laterals_0[1] + laterals_0[2]
laterals[1] = laterals[1] + laterals_1[0] + laterals_1[1] + laterals_1[2]
laterals[2] = laterals[2] + laterals_2[0] + laterals_2[1] + laterals_2[2]
# build top-down path
used_backbone_levels = len(laterals)
for i in range(used_backbone_levels - 1, 0, -1):
laterals[i - 1] += F.interpolate(laterals[i], scale_factor=2, mode="bilinear")
# build outputs
outs = [
# self.fpn_convs[i](laterals[i]) for i in range(used_backbone_levels)
laterals[i] for i in range(used_backbone_levels)
]
return tuple(outs)
if __name__ == '__main__':
in_channels=[176, 352, 704]
out_channels=128
num_outs=5
activation='LeakyReLU'
af_fpn = AF_FPN(in_channels=in_channels, out_channels=out_channels, num_outs=num_outs, activation=activation)
torch.save(af_fpn.state_dict(), "af_fpn.ckpt")
input = (torch.randn((1, in_channels[0], 160, 160)),
torch.randn((1, in_channels[1], 80, 80)),
torch.randn((1, in_channels[2], 40, 40))
)
output = af_fpn(input)
print(f"len(output):{len(output)}")
# 以下输出的特征图大小为原特征图大小的1/8、1/16与1/32。
print(f"output[0].shape:{output[0].shape} || output[1].shape:{output[1].shape} || output[2].shape:{output[2].shape}")
4、本设计参考的论文和算法分享
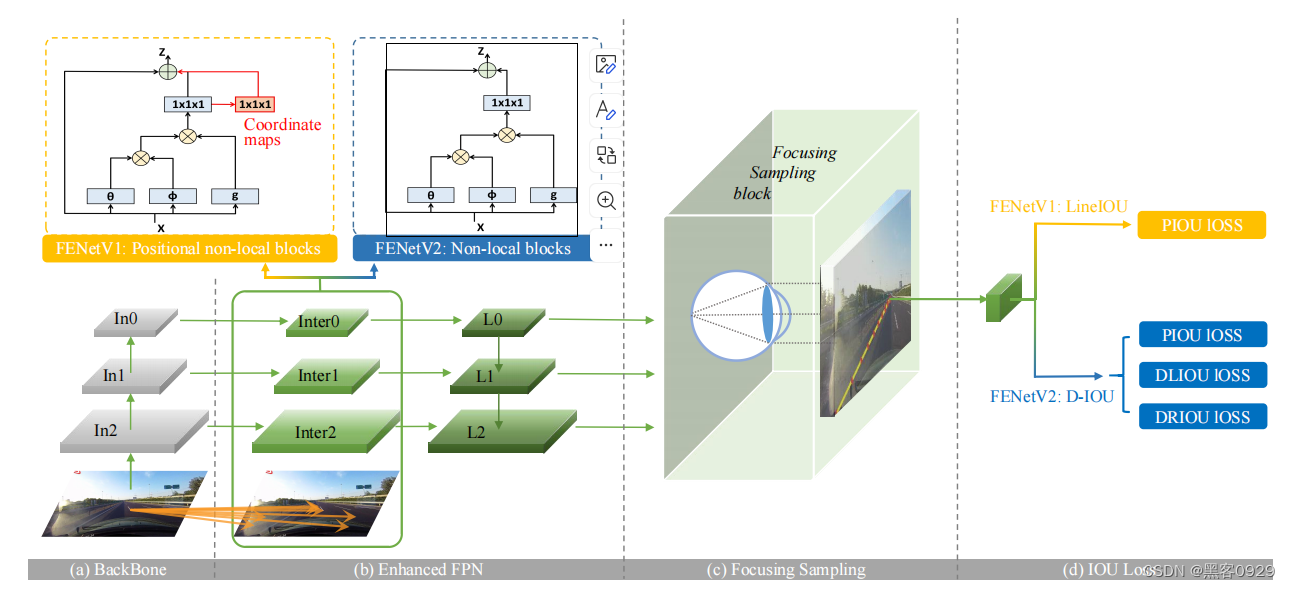
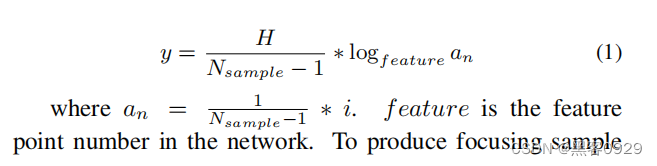
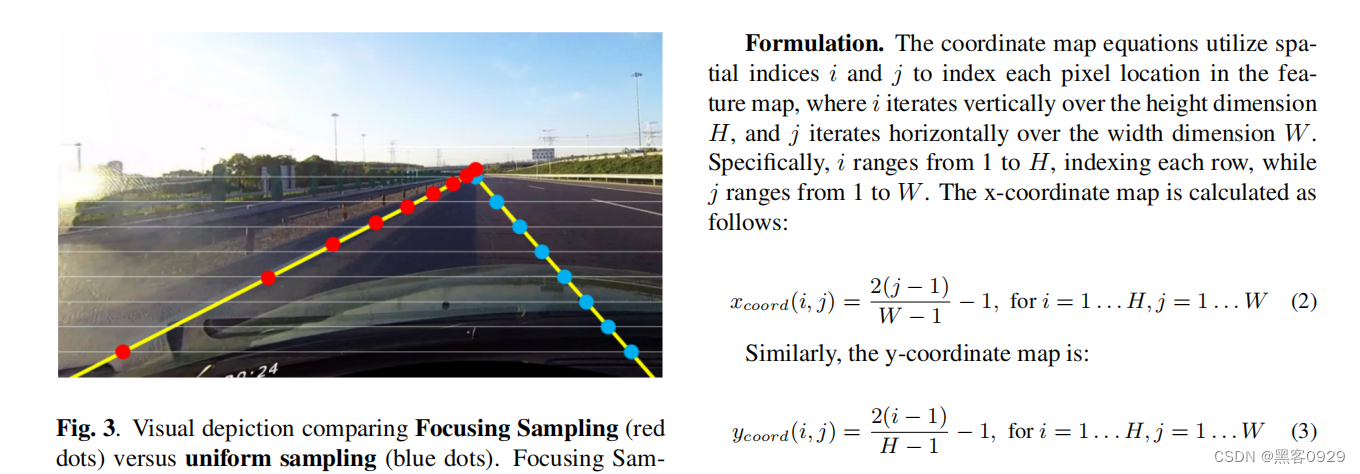


- 数据集转换和实验代码结构如下:

第三:基于YOLOV5的路面障碍物检测算法
-
主界面
GUI界面,我们采用PyQt5来搭建。关于PyQt5的介绍如下:
PyQt5 是 Riverbank Computing 开发的 GUI 小部件工具包的最新版本。 它是 Qt 的 Python 接口,是最强大和流行的跨平台 GUI 库之一。 PyQt5 是 Python 编程语言和 Qt 库的混合体。 本介绍性教程将帮助您在 PyQt 的帮助下创建图形应用程序。
'''视频检测'''
def open_video_button(self):
if self.timer_camera4.isActive() == False:
imgName, imgType = QFileDialog.getOpenFileName(self, "打开视频", "", "*.mp4;;*.AVI;;*.rmvb;;All Files(*)")
self.cap_video = cv2.VideoCapture(imgName)
flag = self.cap_video.isOpened()
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, u"Warning", u"请检测相机与电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
# self.timer_camera3.start(10)
self.show_camera2()
self.open_video.setText(u'关闭视频')
else:
# self.timer_camera3.stop()
self.cap_video.release()
self.label_show_camera.clear()
self.timer_camera4.stop()
self.frame_s=3
self.label_show_camera1.clear()
self.open_video.setText(u'打开视频')
def detect_video(self):
if self.timer_camera4.isActive() == False:
flag = self.cap_video.isOpened()
if flag == False:
msg = QtWidgets.QMessageBox.warning(self, u"Warning", u"请检测相机与电脑是否连接正确",
buttons=QtWidgets.QMessageBox.Ok,
defaultButton=QtWidgets.QMessageBox.Ok)
else:
self.timer_camera4.start(30)
else:
self.timer_camera4.stop()
self.cap_video.release()
self.label_show_camera1.clear()
def show_camera2(self): #显示视频的左边
#抽帧
length = int(self.cap_video.get(cv2.CAP_PROP_FRAME_COUNT)) #抽帧
print(self.frame_s,length) #抽帧
flag, self.image1 = self.cap_video.read() #image1是视频的
if flag == True:
width=self.image1.shape[1]
height=self.image1.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(self.image1, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(self.image1, (int(width * height_new / height), height_new))
show = cv2.cvtColor(show, cv2.COLOR_BGR2RGB)
showImage = QtGui.QImage(show.data, show.shape[1], show.shape[0],3 * show.shape[1], QtGui.QImage.Format_RGB888)
self.label_show_camera.setPixmap(QtGui.QPixmap.fromImage(showImage))
else:
self.cap_video.release()
self.label_show_camera.clear()
self.timer_camera4.stop()
self.label_show_camera1.clear()
self.open_video.setText(u'打开视频')
def show_camera3(self):
flag, self.image1 = self.cap_video.read()
self.frame_s += 1
if flag==True:
# if self.frame_s % 3 == 0: #抽帧
# face = self.face_detect.align(self.image)
# if face:
# pass
# dir_path = os.getcwd()
# camera_source = dir_path + "\\data\\test\\video.jpg"
#
# cv2.imwrite(camera_source, self.image1)
# print("im01")
# im0, label = main_detect(self.my_model, camera_source)
label, im0 = self.myv5.detect(self.image1)
# print("imo",im0)
# print(label)
if label=='debug':
print("labelkong")
# print("debug")
# im0, label = slef.detect()
# print("debug1")
width = im0.shape[1]
height = im0.shape[0]
# 设置新的图片分辨率框架
width_new = 700
height_new = 500
# 判断图片的长宽比率
if width / height >= width_new / height_new:
show = cv2.resize(im0, (width_new, int(height * width_new / width)))
else:
show = cv2.resize(im0, (int(width * height_new / height), height_new))
im0 = cv2.cvtColor(show, cv2.COLOR_RGB2BGR)
# print("debug2")
showImage = QtGui.QImage(im0, im0.shape[1], im0.shape[0], 3 * im0.shape[1], QtGui.QImage.Format_RGB888)
self.label_show_camera1.setPixmap(QtGui.QPixmap.fromImage(showImage))
-
源码结构
这里你需要知道的是,关于YOLOV5算法原理和项目结构在Github上面有详细的介绍,前面我也给你介绍了,忘记了回头去看一下,搞清楚先,网址如下:
https://github.com/ultralytics/yolov5
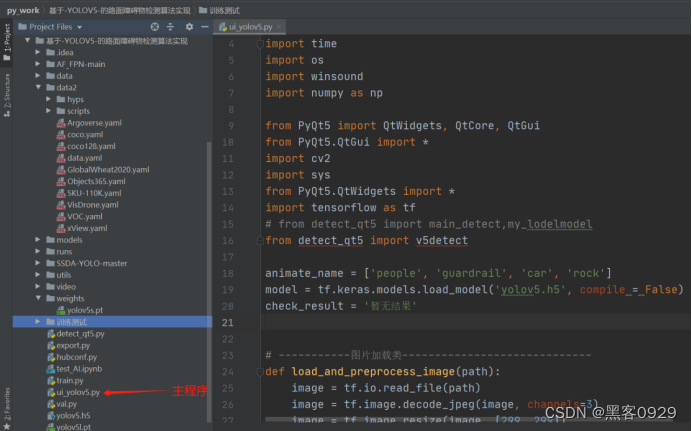
- 本设计的项目结构如下,基于YOLOV5算法设计的
- 算法优化
参考论文:
SSDA-YOLO: Semi-supervised Domain Adaptive YOLO for Cross-Domain Object Detection
翻译:SSDA-YOLO:用于跨域目标检测的半监督域自适应 YOLO

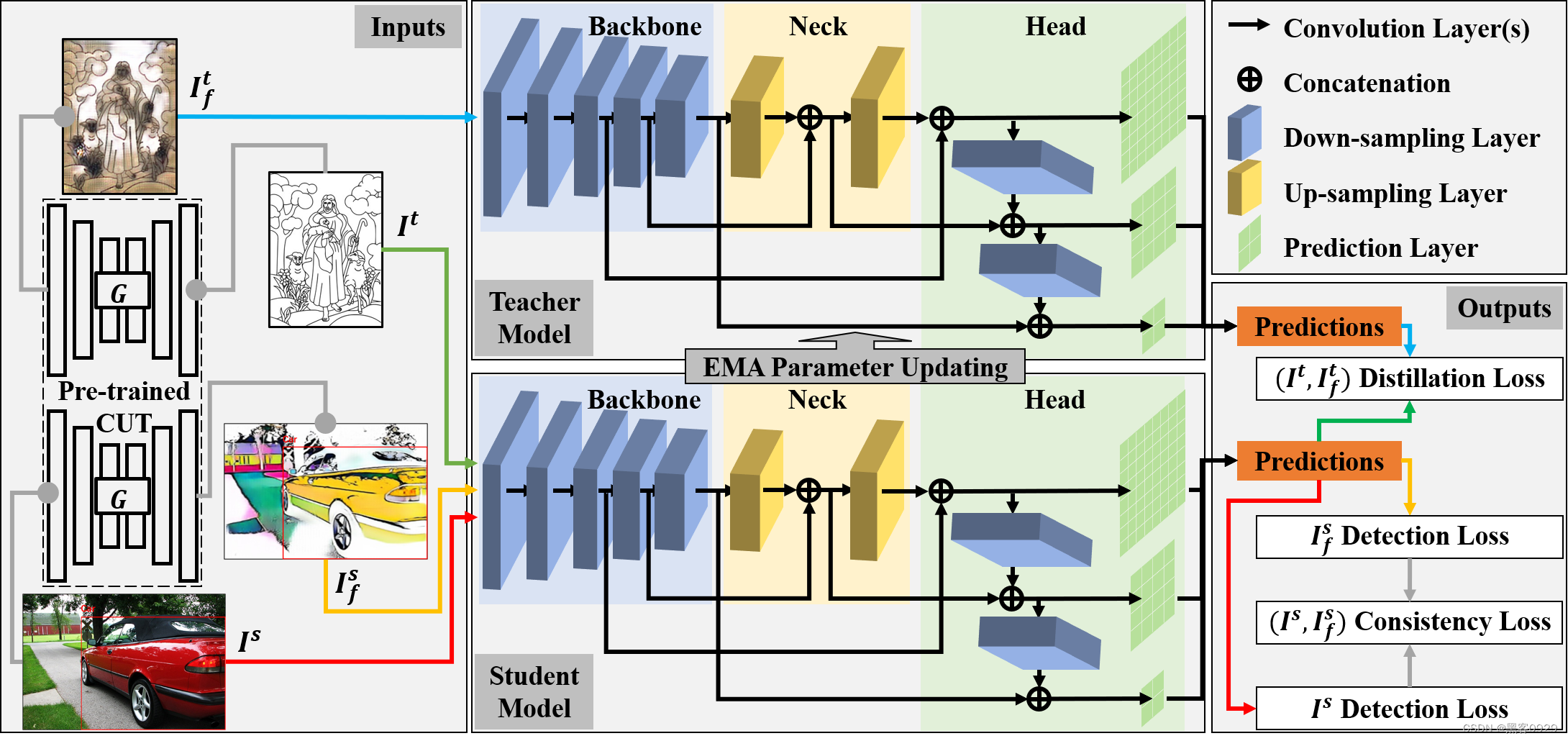
- 实现代码如下:

- 核心思想:
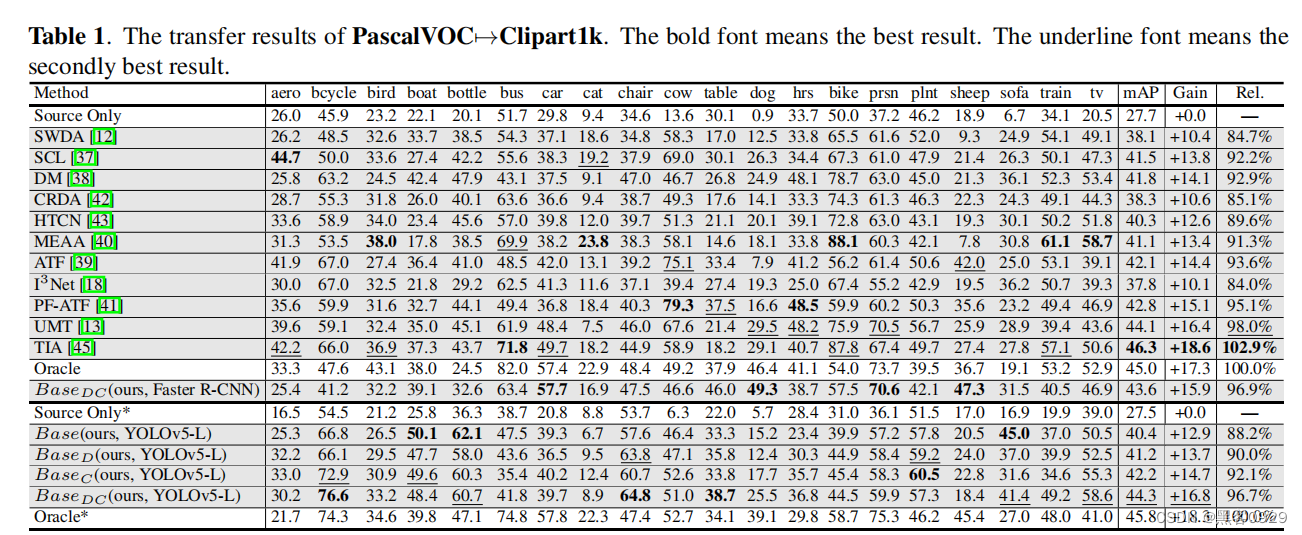
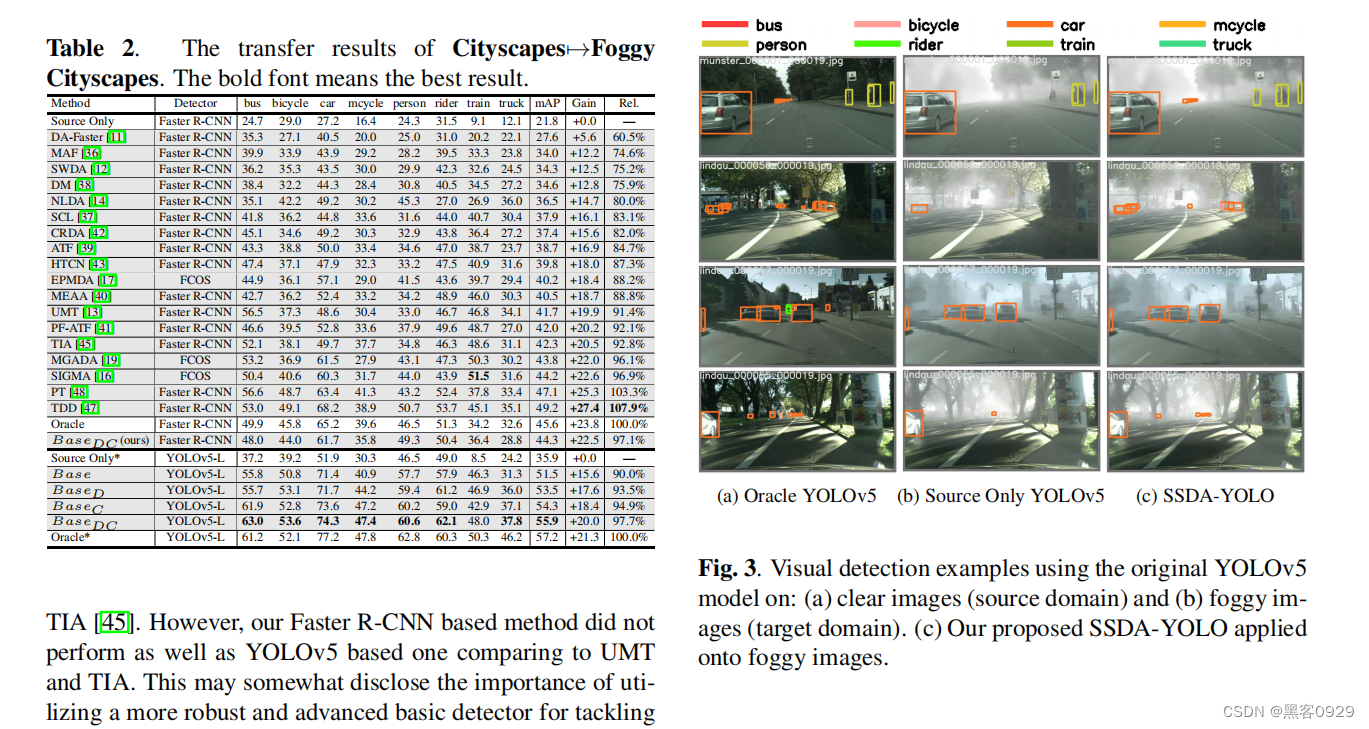
域自适应目标检测 (DAOD) 旨在缓解跨域差异导致的传输性能下降。然而,现有的DAOD方法大多以过时且计算密集型的两级Faster R-CNN为主,这并不是工业应用的首选。在本文中,我们提出了一种基于半监督域自适应 YOLO (SSDA-YOLO) 的新型方法,通过将紧凑的单级强探测器 YOLOv5 与域自适应相结合来提高跨域检测性能。具体来说,我们将知识蒸馏框架与平均教师模型相结合,以帮助学生模型获得未标记目标域的实例级特征。我们还利用场景风格转移来交叉生成不同域的伪图像,以弥补图像级差异。此外,还提出了一种直观的一致性损失,以进一步调整跨域预测。我们在公共基准上评估 SSDA-YOLO,包括 PascalVOC、Clipart1k、Cityscapes 和 Foggy Cityscapes。
- 测试结果如下
左边视频界面,右边实时检测结果,
-
第四:交流请联系



 |  |
写作大纲思路如下:仅供参考
第一章 引言
- 研究背景:介绍路面障碍物检测在智能交通系统中的重要性。
- 研究目的:明确本文旨在研究和改进基于YOLOV5的路面障碍物检测算法。
- 研究意义:阐述算法改进对提高交通安全和推动自动驾驶技术的价值。
第二章 YOLOV5算法原理及结构
- YOLOV5算法简介。
- YOLOV5算法结构解析。
- YOLOV5在障碍物检测中的优势和特点。
第三章 算法改进与优化
- 针对路面障碍物检测的算法改进策略。
- 多尺度特征融合的优化方法。
- 模型结构和训练策略的优化。
第四章 实验平台搭建与数据集处理
- 实验平台简介:硬件配置、软件环境等。
- 数据集采集与标注流程。
- 数据集预处理与增强技术。
第五章 性能评估与对比分析
- 实验设置与参数调整。
- 性能评估指标:准确率、召回率、F1分数等。
- 与其他先进算法的对比分析。
第六章 实际应用与挑战分析
- 基于YOLOV5的路面障碍物检测算法在实际应用中的潜力和限制。
- 面临的挑战和问题分析。
- 解决策略与未来研究方向。
第七章 结论与展望
- 总结研究成果与贡献。
- 对未来研究的展望。
参考文献
[此处插入参考文献]