文章目录
常见问题及解决方案
-
问题:文件编码错误
解决方案:使用encoding参数指定文件编码,例如encoding='utf-8'。 -
问题:读取大文件时内存不足
解决方案:使用chunksize参数逐块读取数据:for chunk in pd.read_csv('large_data.csv', chunksize=1000): process(chunk) # 自定义处理函数 -
问题执行脚本报错
PS D:\bsop\zhijianaiweb> & D:/Python/Python39/python.exe c:/Users/wangzq/Desktop/csv.py
Traceback (most recent call last):
File "c:\Users\wangzq\Desktop\csv.py", line 1, in <module>
import csv
File "c:\Users\wangzq\Desktop\csv.py", line 4, in <module>
writer = csv.writer(file)
AttributeError: partially initialized module 'csv' has no attribute 'writer' (most likely due to a circular import)
PS D:\bsop\zhijianaiweb>
这个错误通常脚本文件命名为 csv.py,导致 Python 试图从你的脚本中导入 csv 模块,而不是标准库中的 csv 模块。解决方法如下:
- 重命名你的脚本:将
csv.py更改为其他名字,例如csv_example.py。 - 删除
csv.pyc文件(如果存在):在同一目录下查找__pycache__文件夹,删除其中的csv.cpython-39.pyc文件。
使用 Python 处理 CSV 文件:全面指南
CSV(Comma-Separated Values)格式是一种广泛使用的数据交换格式,因其简单易懂而受到青睐。本文将介绍如何使用 Python 处理 CSV 文件,包括读取、写入、数据处理以及常用库的比较。
CSV 文件的基本概念
CSV 文件使用逗号分隔值,通常用于存储表格数据。每行代表一条记录,字段由逗号分隔。
使用内置 csv 模块
Python 提供了内置的 csv 模块,方便读取和写入 CSV 文件。
- 写入 CSV 文件:
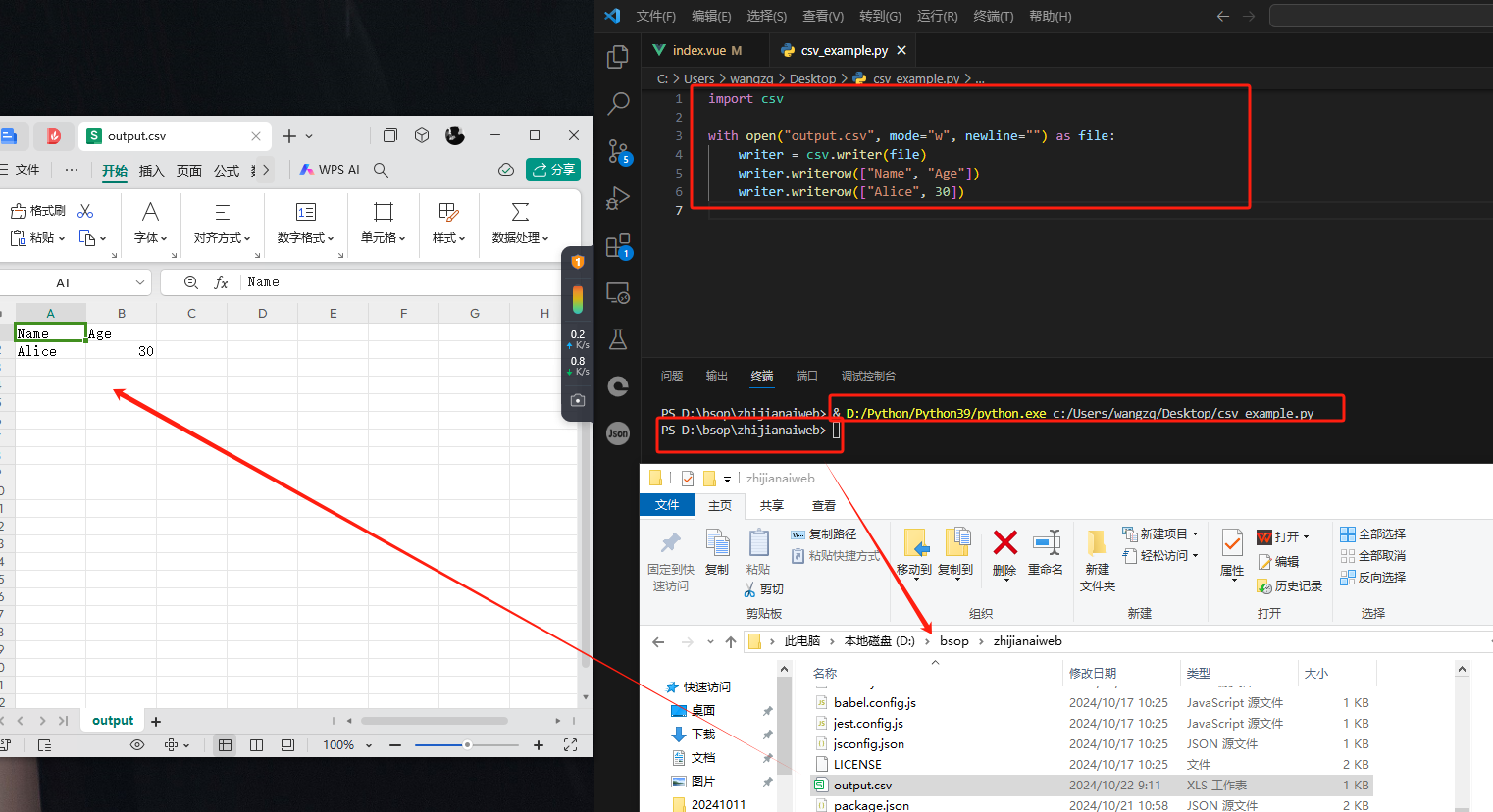
import csv
with open('output.csv', mode='w', newline='') as file:
writer = csv.writer(file)
writer.writerow(['Name', 'Age'])
writer.writerow(['Alice', 30])
- 读取 CSV 文件:
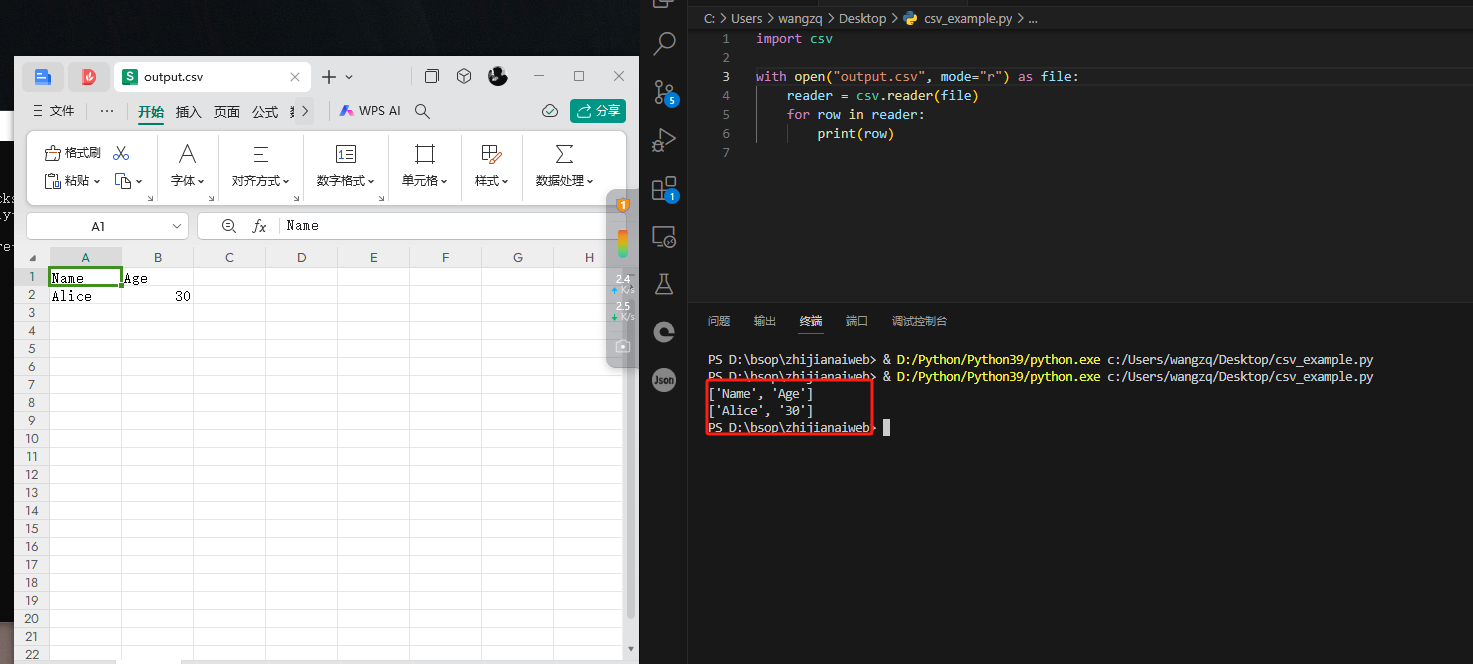
import csv
with open('data.csv', mode='r') as file:
reader = csv.reader(file)
for row in reader:
print(row)
使用 pandas 库
pandas 是一个强大的数据处理库,适合进行复杂的数据分析。
- 读取 CSV 文件:
import pandas as pd
df = pd.read_csv('data.csv')
print(df.head())
- 数据处理:可以轻松地进行数据过滤、修改和聚合。
# 过滤年龄大于25的人
filtered_df = df[df['Age'] > 25]
print(filtered_df)
# 统计年龄的平均值
average_age = df['Age'].mean()
print(f"Average Age: {average_age}")
- 写入 CSV 文件:
df.to_csv('filtered_output.csv', index=False)
处理缺失值
处理数据时,缺失值是常见问题。可以使用 fillna() 方法填充缺失值:
# 用0填充缺失值
df.fillna(0, inplace=True)
# 删除含有缺失值的行
df.dropna(inplace=True)
使用 DictReader 和 DictWriter
csv 模块还支持将 CSV 文件读取为字典格式,方便处理。
- 读取为字典:
import csv
with open('data.csv', mode='r') as file:
reader = csv.DictReader(file)
for row in reader:
print(row['Name'], row['Age'])
- 写入字典:
import csv
with open('output.csv', mode='w', newline='') as file:
fieldnames = ['Name', 'Age']
writer = csv.DictWriter(file, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({'Name': 'Bob', 'Age': 22})
案例分析
假设我们有一个包含员工信息的 CSV 文件 employees.csv,我们想要进行数据分析,比如找出薪水高于某个值的员工,并计算他们的平均薪水。
import pandas as pd
# 读取数据
df = pd.read_csv('employees.csv')
# 过滤薪水大于50000的员工
high_salary_df = df[df['Salary'] > 50000]
# 计算平均薪水
average_salary = high_salary_df['Salary'].mean()
print(f"Average Salary of High Earners: {average_salary}")
最佳实践
- 始终检查数据的完整性:读取数据后,检查缺失值和异常值。
- 使用相对路径:为保证代码的可移植性,使用相对路径读取文件。
- 文件格式:尽量确保 CSV 文件的格式统一,避免出现不同的分隔符或编码问题。
参考资源
性能比较
在处理大型 CSV 文件时,选择合适的库至关重要。csv 模块相对轻量,更适合简单读取和写入,而 pandas 提供了更丰富的数据操作功能,适合进行复杂分析。
结论
无论是使用内置的 csv 模块还是功能强大的 pandas 库,Python 都为处理 CSV 文件提供了灵活的解决方案。根据具体需求选择合适的方法,可以使数据处理更高效。