Contents
Introduction
- 作者提出 Multi-head Latent Attention (MLA),通过将 KV 压缩为 Compressed Latent KV,在减小 KV cache 的同时保持模型精度
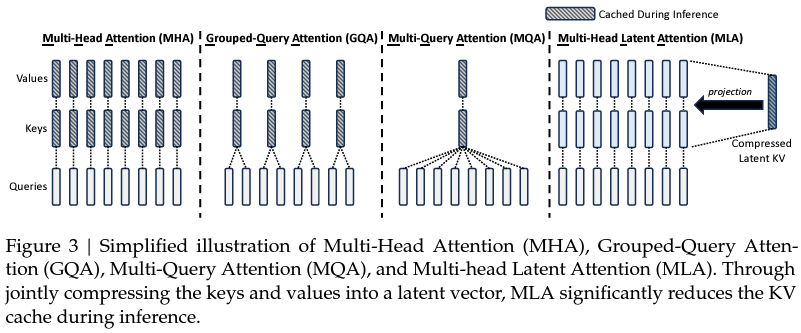
Method
Low-Rank Key-Value Joint Compression
- MLA 将 KV vectors
k
t
,
v
t
∈
R
d
h
n
h
\mathbf{k}_{t},\mathbf{v}_{t}\in\mathbb{R}^{d_{h}n_{h}}
kt,vt∈Rdhnh 压缩为 latent vector
c
t
K
V
∈
R
d
c
\mathbf{c}_{t}^{KV}\in\mathbb{R}^{d_c}
ctKV∈Rdc,从而在推理时仅需保存 latent vector
c
t
K
V
\mathbf{c}_{t}^{KV}
ctKV 而无需保存 KV cache (
d
c
≪
d
h
n
h
d_c\ll d_hn_h
dc≪dhnh,
d
h
d_h
dh 为 head dim,
n
h
n_h
nh 为 #heads)
c t K V = W D K V h t k t C = W U K c t K V v t C = W U V c t K V \begin{gathered} \mathbf{c}_{t}^{KV} =W^{DKV}\mathbf{h}_{t} \\ \mathbf{k}_{t}^{C} =W^{UK}\mathbf{c}_{t}^{KV} \\ \mathbf{v}_{t}^{C} =W^{UV}\mathbf{c}_{t}^{KV} \end{gathered} ctKV=WDKVhtktC=WUKctKVvtC=WUVctKV其中, W D K V ∈ R d c × d W^{DKV}\in\R^{d_c\times d} WDKV∈Rdc×d, W U K , W U V ∈ R d h n h × d c W^{UK},W^{UV}\in\R^{d_hn_h\times d_c} WUK,WUV∈Rdhnh×dc. 这样每个 token 对应的 KV cache 数据量由原来的 2 n h d h l 2n_hd_hl 2nhdhl 降低到了 d c l d_cl dcl, l l l 为 Transformer 层数,这样一来,在设计 LLM 架构参数时甚至可以把 d h d_h dh 设置得比 d / h n d/h_n d/hn 更大,这样不仅不会增加 KV cache,还可以进一步提升模型能力 - MLA 在推理时无需用
W
U
K
,
W
U
V
W^{UK},W^{UV}
WUK,WUV 重新计算出
k
t
C
,
v
t
C
\mathbf k_t^C,\mathbf v_t^C
ktC,vtC,而是将
W
U
K
,
W
U
V
W^{UK},W^{UV}
WUK,WUV 分别融到模型权重
W
Q
,
W
O
W^Q,W^O
WQ,WO 里,不会带来额外的推理开销
q t T k t C = ( W ( h ) Q h t ) T ( W ( h ) U K c t K V ) = ( ( W ( h ) U K ) T W ( h ) Q h t ) T c t K V \mathbf q_t^T\mathbf k^C_t=(W^Q_{(h)}\mathbf h_t)^T(W^{UK}_{(h)}\mathbf c_t^{KV})=\left(\left(W^{UK}_{(h)}\right)^TW^Q_{(h)}h_t\right)^T\mathbf c_t^{KV} qtTktC=(W(h)Qht)T(W(h)UKctKV)=((W(h)UK)TW(h)Qht)TctKV ( ∑ j = 1 t p j v j C ) T W ( h ) O = ( ∑ j = 1 t p j W ( h ) U V c j K V ) T W ( h ) O = ( ∑ j = 1 t p j c j K V ) T ( W ( h ) U V ) T W ( h ) O \left(\sum_{j=1}^t\mathbf p_j\mathbf v_j^C\right)^TW^O_{(h)}=\left(\sum_{j=1}^t\mathbf p_jW^{UV}_{(h)}\mathbf c_j^{KV}\right)^TW^O_{(h)}=\left(\sum_{j=1}^t\mathbf p_j\mathbf c_j^{KV}\right)^T\left(W^{UV}_{(h)}\right)^TW^O_{(h)} (j=1∑tpjvjC)TW(h)O=(j=1∑tpjW(h)UVcjKV)TW(h)O=(j=1∑tpjcjKV)T(W(h)UV)TW(h)O其中, W ( h ) Q , W ( h ) O ∈ R d h × d h n h W^Q_{(h)},W^O_{(h)}\in\R^{d_h\times d_hn_h} W(h)Q,W(h)O∈Rdh×dhnh, W ( h ) U K , W ( h ) U V ∈ R d h × d c W^{UK}_{(h)},W^{UV}_{(h)}\in\R^{d_h\times d_c} W(h)UK,W(h)UV∈Rdh×dc 为 head h h h 对应的权重参数
Decoupled Rotary Position Embedding
- 上述对 KV cache 的低秩压缩无法直接与 RoPE 兼容,因为 RoPE 要给
q
,
k
\mathbf q,\mathbf k
q,k 做内积之前进行旋转,这导致
W
U
K
W^{UK}
WUK 无法融到
W
Q
W^Q
WQ 里,每次推理时都需要重新从
c
K
V
\mathbf c^{KV}
cKV 计算
k
\mathbf k
k,从而增加大量推理开销。为此,MLA 采用 decoupled RoPE,给每个 attn 层额外增加 multi-head queries
q
t
,
i
R
∈
R
d
h
R
\mathbf{q}_{t,i}^{R}\in\mathbb{R}^{d_{h}^{R}}
qt,iR∈RdhR 和共享的 key
k
t
R
∈
R
d
h
R
\mathbf{k}_{t}^{R}\in\mathbb{R}^{d_{h}^{R}}
ktR∈RdhR 用于存储 RoPE 位置信息,这样只需要同时存储
c
K
V
\mathbf c^{KV}
cKV 和
k
R
\mathbf{k}^{R}
kR 即可,MLA 所需的 KV cache 数据量增加为
(
d
c
+
d
h
R
)
l
(d_c+d_h^R)l
(dc+dhR)l
[ q t , 1 R ; q t , 2 R ; . . . ; q t , n h R ] = q t R = R o P E ( W Q R h t ) , k t R = R o P E ( W K R h t ) , q t , i = [ q t , i C ; q t , i R ] , k t , i = [ k t , i C ; k t R ] , o t , i = ∑ j = 1 t S o f t m a x j ( q t , i T k j , i d h + d h R ) v j , i C , u t = W O [ o t , 1 ; o t , 2 ; . . . ; o t , n h ] , \begin{aligned} [\mathbf{q}_{t,1}^{R};\mathbf{q}_{t,2}^{R};...;\mathbf{q}_{t,n_{h}}^{R}]=\mathbf{q}_{t}^{R}& =\mathrm{RoPE}(W^{QR}\mathbf{h}_{t}), \\ \mathbf{k}_{t}^{R}& =\mathrm{RoPE}(W^{KR}\mathbf{h}_{t}), \\ \mathbf{q}_{t,i}& =[\mathbf{q}_{t,i}^{C};\mathbf{q}_{t,i}^{R}], \\ \mathbf{k}_{t,i}& =[\mathbf{k}_{t,i}^{C};\mathbf{k}_{t}^{R}], \\ \mathbf{o}_{t,i}& =\sum_{j=1}^{t}\mathrm{Softmax}_{j}(\frac{\mathbf{q}_{t,i}^{T}\mathbf{k}_{j,i}}{\sqrt{d_{h}+d_{h}^{R}}})\mathbf{v}_{j,i}^{C}, \\ \mathbf{u}_{t}& =W^{O}[\mathbf{o}_{t,1};\mathbf{o}_{t,2};...;\mathbf{o}_{t,n_{h}}], \end{aligned} [qt,1R;qt,2R;...;qt,nhR]=qtRktRqt,ikt,iot,iut=RoPE(WQRht),=RoPE(WKRht),=[qt,iC;qt,iR],=[kt,iC;ktR],=j=1∑tSoftmaxj(dh+dhRqt,iTkj,i)vj,iC,=WO[ot,1;ot,2;...;ot,nh],其中, W Q R ∈ R d h R n h × d , W K R ∈ R d h R × d W^{QR}\in\mathbb{R}^{d_{h}^{R}n_{h}\times d},W^{KR}\in\mathbb{R}^{d_{h}^{R}\times d} WQR∈RdhRnh×d,WKR∈RdhR×d
References
- DeepSeek-AI, et al. “DeepSeek-V2: A Strong, Economical, and Efficient Mixture-of-Experts Language Model.” arXiv preprint arXiv:2405.04434 (2024).
- 苏剑林. (May. 13, 2024). 《缓存与效果的极限拉扯:从MHA、MQA、GQA到MLA 》[Blog post]. Retrieved from https://kexue.fm/archives/10091