问题描述
利用Word2Vec模型训练Word Embedding,根据小说中人物、武功、派别或者其他你感兴趣的特征,基于Word Embedding来进行聚类分析。
实验原理
Word Embedding
Harris 在 1954 年提出的分布假说( distributional hypothesis)为这一设想提供了理论基础:上下文相似的词,其语义也相似。而基于基于分布假说的词表示方法,根据建模的不同,主要可以分为三类:基于矩阵的分布表示、基于聚类的分布表示和基于神经网络的分布表示。而word embedding一般来说就是一种基于神经网络的分布表示。word embedding指的是将词转化成一种分布式表示,又称词向量。分布式表示将词表示成一个定长的连续的稠密向量。分布式表示的优点如下:
- 词之间存在相似关系:
是词之间存在“距离”概念,这对很多自然语言处理的任务非常有帮助。 - 包含更多信息:
词向量能够包含更多信息,并且每一维都有特定的含义。在采用one-hot特征时,可以对特征向量进行删减,词向量则不能。
Word2Vec模型
word2vec是只有一个隐层的全连接神经网络, 用来预测给定单词的关联度大的单词。或者说就是一个语言模型。
整体步骤如下:
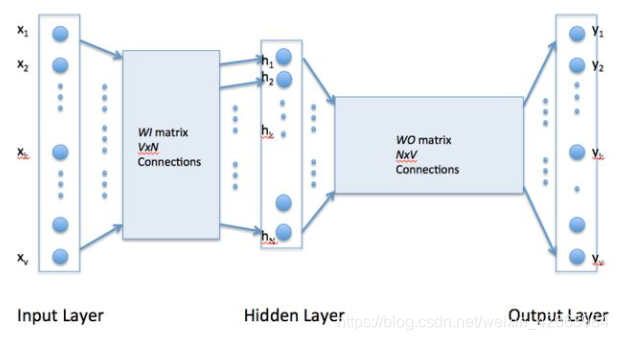
- 在输入层,一个词被转化为One-Hot向量。
- 在第一个隐层,输入的是一个 [公式] ( [公式] 就是输入的词向量, [公式] , [公式] 是参数),做一个线性模型,注意已这里只是简单的映射,并没有非线性激活函数,当然一个神经元可以是线性的,这时就相当于一个线性回归函数。
- 第三层可以简单看成一个分类器,用的是Softmax回归,最后输出的是每个词对应的概率
CBOW和Skip-Gram
Word2vec是一种可以进行高效率词嵌套学习的预测模型。其有两种变体是现在比较常用的,分别为:连续词袋模型(CBOW)及Skip-Gram模型。从算法角度看,这两种方法非常相似,其区别为CBOW根据源词上下文词汇(’the cat sits on the’)来预测目标词汇(例如,‘mat’),而Skip-Gram模型做法相反,它通过目标词汇来预测源词汇。
Skip-Gram模型采取CBOW的逆过程的动机在于:CBOW算法对于很多分布式信息进行了平滑处理(例如将一整段上下文信息视为一个单一观察量)。很多情况下,对于小型的数据集,这一处理是有帮助的。相比之下,Skip-Gram模型将每个“上下文-目标词汇”的组合视为一个新观察量,这种做法在大型数据集中会更为有效。本实验用CBOW来进行训练。
实验流程
数据预处理
与前一次实验相同,删去所有的隐藏符号,删除所有的非中文字符,不考虑上下文关系的前提下删去所有标点符号。以jieba库对中文语料进行分词。由实验要求得,需对数据库进行训练集的选取。在该实验当中,将测试集化为2000行语料,其余行列为训练集。
def get_data():
"""如果文档还没分词,就进行分词"""
outfilename_1 = "./cnews.train_jieba.txt"
outfilename_2 = "./cnews.test_jieba.txt"
if not os.path.exists('./cnews.train_jieba.txt'):
outputs = open(outfilename_1, 'w', encoding='UTF-8')
outputs_test = open(outfilename_2, 'w', encoding='UTF-8')
datasets_root = "../datasets"
catalog = "inf.txt"
test_num = 10
test_length = 20
with open(os.path.join(datasets_root, catalog), "r", encoding='utf-8') as f:
all_files = f.readline().split(",")
print(all_files)
for name in all_files:
with open(os.path.join(datasets_root, name + ".txt"), "r", encoding='utf-8') as f:
file_read = f.readlines()
train_num = len(file_read) - test_num
choice_index = np.random.choice(len(file_read), test_num + train_num, replace=False)
train_text = ""
for train in choice_index[0:train_num]:
line = file_read[train]
line = re.sub('\s', '', line)
line = re.sub('[\u0000-\u4DFF]', '', line)
line = re.sub('[\u9FA6-\uFFFF]', '', line)
if len(line) == 0:
continue
seg_list = list(jieba.cut(line, cut_all=False)) # 使用精确模式
line_seg = ""
for term in seg_list:
line_seg += term + " "
# for index in range len(line_seg):
outputs.write(line_seg.strip() + '\n')
for test in choice_index[train_num:test_num + train_num]:
if test + test_length >= len(file_read):
continue
test_line = ""
# for i in range(test, test + test_length):
line = file_read[test]
line = re.sub('\s', '', line)
line = re.sub('[\u0000-\u4DFF]', '', line)
line = re.sub('[\u9FA6-\uFFFF]', '', line)
seg_list = list(jieba.cut(line, cut_all=False)) # 使用精确模式
# line_seg = ""
for term in seg_list:
test_line += term + " "
outputs_test.write(test_line.strip() + '\n')
outputs.close()
outputs_test.close()
print("得到训练集与测试集!!!")
运用Word2Vec进行训练
本实验选用gensim.models包中的word2vec模块
fr = open('./cnews.train_jieba.txt', 'r', encoding='utf-8')
train = []
for line in fr.readlines():
line = [word.strip() for word in line.split(' ')]
train.append(line)
num_features = 300 # Word vector dimensionality
min_word_count = 10 # Minimum word count
num_workers = 16 # Number of threads to run in parallel
context = 10 # Context window size
downsampling = 1e-3 # Downsample setting for frequent words
sentences = word2vec.Text8Corpus("cnews.train_jieba.txt")
model = word2vec.Word2Vec(sentences, workers=num_workers,
vector_size=num_features, min_count=min_word_count,
window=context, sg=1, sample=downsampling)
model.init_sims(replace=True)
# 保存模型,供日後使用
model.save("model201708.model")
得到训练后的Word Embedding。代码中主要需要介绍的是word2Vec的参数:
- sentences:可以是一个·ist,对于大语料集,建议使用BrownCorpus,Text8Corpus或·ineSentence构建。
- sg: 用于设置训练算法,默认为0,对应CBOW算法;sg=1则采用skip-gram算法。
- vector_size:是指特征向量的维度,默认为100。大的size需要更多的训练数据,但是效果会更好. 推荐值为几十到几百。
- window:表示当前词与预测词在一个句子中的最大距离是多少
- alpha: 是学习速率
- seed:用于随机数发生器。与初始化词向量有关。
- min_count: 可以对字典做截断. 词频少于min_count次数的单词会被丢弃掉, 默认值为5
- max_vocab_size: 设置词向量构建期间的RAM限制。如果所有独立单词个数超过这个,则就消除掉其中最不频繁的一个。每一千万个单词需要大约1GB的RAM。设置成None则没有限制。
- sample: 高频词汇的随机降采样的配置阈值,默认为1e-3,范围是(0,1e-5)
- workers参数控制训练的并行数。
- hs: 如果为1则会采用hierarchica·softmax技巧。如果设置为0(defau·t),则negative sampling会被使用。
- negative: 如果>0,则会采用negativesamp·ing,用于设置多少个noise words
- cbow_mean: 如果为0,则采用上下文词向量的和,如果为1(defau·t)则采用均值。只有使用CBOW的时候才起作用。
- hashfxn: hash函数来初始化权重。默认使用python的hash函数
- iter: 迭代次数,默认为5
- trim_rule: 用于设置词汇表的整理规则,指定那些单词要留下,哪些要被删除。可以设置为None(min_count会被使用)或者一个接受()并返回RU·E_DISCARD,uti·s.RU·E_KEEP或者uti·s.RU·E_DEFAU·T的函数。
- sorted_vocab: 如果为1(defau·t),则在分配word index 的时候会先对单词基于频率降序排序。
- batch_words:每一批的传递给线程的单词的数量,默认为10000
Kmeans 聚类
在得到训练后的词向量后,用以下的代码进行进行聚类分析
from sklearn import cluster
model = Word2Vec.load('./model201708')
names=[]
for line in open("name.txt","r",encoding='utf-8'):
line = line.strip('\n')
names.append(line)
names = [name for name in names if name in model.wv]
name_vectors = [model.wv[name] for name in names]
n=5
label = cluster.KMeans(n).fit(name_vectors).labels_
print(label)
print("类别1:")
for i in range(len(label)):
if label[i]==0:
print(names[i],end=" ")
print("\n")
print("类别2:")
for i in range(len(label)):
if label[i]==1:
print(names[i],end=" ")
print("\n")
print("类别3:")
for i in range(len(label)):
if label[i]==2:
print(names[i],end=" ")
实验结果分析
model=word2vec.Word2Vec.load("model201708")
print(model.wv.most_similar("乔峰",topn=10))
可以得到与乔峰关系相近的10个词汇
[(‘阿朱’, 0.6001356244087219), (‘萧峰’, 0.5798439979553223), (‘谭公’, 0.5780234336853027), (‘徐长老’, 0.5723527669906616), (‘马夫人’, 0.5441627502441406), (‘白世镜’, 0.5374689698219299), (‘智光大师’, 0.5370376110076904), (‘单正’, 0.5330749750137329), (‘全冠清’, 0.529356837272644), (‘谭婆’, 0.5280649662017822)]
同理可以得到与“丐帮”关系相近的10个词汇
[(‘帮主’, 0.6566115617752075), (‘帮众’, 0.6347417831420898), (‘本帮’, 0.6123296022415161), (‘帮中’, 0.6082062721252441), (‘长老’, 0.605518102645874), (‘庄聚贤’, 0.602852463722229), (‘打狗棒’, 0.5936352610588074), (‘群丐’, 0.5883579254150391), (‘八袋’, 0.5772874355316162), (‘诸长老’, 0.5666619539260864)]
同理可得与“康熙”相近的10个词汇
[(‘小桂子’, 0.6369931697845459), (‘索额图’, 0.6071640253067017), (‘奴才’, 0.606919527053833), (‘多隆’, 0.5956133604049683), (‘韦小宝’, 0.5870310068130493), (‘皇上’, 0.5828980207443237), (‘奏章’, 0.5673301815986633), (‘圣明’, 0.5662021040916443), (‘鳌拜’, 0.5627511739730835), (‘小太监’, 0.5554134249687195)]
由
print(model.wv["乔峰"])
得到的乔峰的词向量为
[ 1.49412006e-01 9.56118926e-02 2.79738773e-02 3.89189161e-02
-8.19996521e-02 5.36061404e-03 -4.40436117e-02 4.55036126e-02
7.73312300e-02 3.52732395e-03 -3.23705673e-02 4.08476666e-02
1.21273911e-02 -1.01790130e-01 -3.94727699e-02 -5.89821599e-02
-7.85509031e-03 7.26036355e-02 -2.04718988e-02 -7.26664215e-02
-1.43713029e-02 -1.93852447e-02 -3.55836982e-03 9.54691544e-02
3.21483868e-03 -5.54708429e-02 7.84598142e-02 -1.69337299e-02
-3.69165987e-02 -1.25104740e-01 -8.63620192e-02 -3.24982367e-02
1.77138299e-02 -2.12620050e-02 -4.20787297e-02 -2.10921094e-02
-2.74492167e-02 -7.74300937e-03 2.90600732e-02 -2.00138055e-03
2.41106916e-02 -1.21984677e-02 -7.91274235e-02 -7.38678798e-02
-4.44453657e-02 -4.06974889e-02 2.74988748e-02 4.60834131e-02
3.45961973e-02 5.43271378e-02 -1.40856244e-02 7.30285868e-02
-4.20039147e-02 -2.75387447e-02 -3.33895199e-02 -6.36653155e-02
-5.57978973e-02 8.99591818e-02 7.14779645e-02 3.66864055e-02
1.39136627e-01 8.67456496e-02 -4.81074788e-02 1.32666687e-02
3.08356136e-02 -2.80002523e-02 -1.25182584e-01 6.98205903e-02
8.44252110e-03 2.29623728e-02 2.97485525e-03 -4.27276269e-03
6.06466196e-02 -3.40761442e-04 7.11240917e-02 4.13144892e-03
-5.17599359e-02 1.08823255e-02 6.61457852e-02 -6.01957515e-02
-1.53746950e-02 9.18206796e-02 -2.01797914e-02 6.37682155e-02
-2.00409279e-03 1.02603734e-01 7.06922915e-03 3.99543019e-03
-6.43277243e-02 9.92561206e-02 3.78838964e-02 -5.66128641e-03
-1.04267597e-02 3.03904694e-02 1.34196877e-02 1.17015615e-02
3.99792604e-02 4.24365364e-02 -3.68560851e-02 4.39626239e-02
5.25114052e-02 -5.59122255e-03 4.49614413e-02 2.31279712e-02
1.41054064e-01 -8.51972401e-02 -2.53510959e-02 2.13987771e-02
-3.06735747e-02 -7.71088526e-02 -2.65949406e-03 -4.34499141e-03
5.11790514e-02 -1.54129546e-02 -5.16234599e-02 6.66688979e-02
-3.14123742e-03 -3.85868666e-03 8.78591686e-02 -1.03151217e-01
1.95829533e-02 -1.90165360e-02 -1.86104551e-02 -1.08400974e-02
1.61571372e-02 2.03421828e-03 -9.90819465e-03 -4.59433720e-02
1.16808847e-01 -1.38775064e-02 -3.75289358e-02 1.23282569e-02
-5.46888597e-02 -1.60057917e-01 4.43841405e-02 9.87717509e-02
1.25040010e-01 -4.49852794e-02 4.16120812e-02 -9.17536765e-02
4.18203287e-02 -9.05395206e-03 1.18428662e-01 9.66214761e-02
-1.34022406e-03 1.29098035e-02 9.96011030e-03 5.68128601e-02
2.28949245e-02 -2.18119118e-02 6.42544776e-02 -2.83638500e-02
-2.62056780e-03 2.91736145e-02 1.26838153e-02 -2.30714045e-02
-3.40902768e-02 -4.70854677e-02 -8.55484977e-02 -1.91055723e-02
-8.11011270e-02 8.12237859e-02 3.62184122e-02 3.30797918e-02
3.86887752e-02 7.50240777e-03 -8.91101062e-02 -4.16882448e-02
9.20117795e-02 6.45235255e-02 -1.83269512e-02 8.27045813e-02
5.34004532e-02 6.88910633e-02 2.76899636e-02 7.08915964e-02
-3.38807628e-02 -1.83924530e-02 4.16900078e-03 1.27885520e-01
-6.77346289e-02 -6.20531105e-02 1.17858006e-02 -4.13165893e-03
1.50929382e-02 -6.68059066e-02 -2.47491226e-02 9.73152146e-02
-2.44104471e-02 -1.98467284e-01 6.69729561e-02 4.40069996e-02
-8.84904042e-02 7.81241048e-04 -2.78505438e-04 -2.50245314e-02
-5.61133958e-02 -6.61232695e-02 2.23954339e-02 -5.18201292e-02
-1.58402007e-02 4.49845120e-02 3.66336815e-02 -4.35774066e-02
6.94848299e-02 1.02090565e-02 -8.40116963e-02 4.80212308e-02
-6.99049160e-02 -2.31368765e-02 8.61393102e-03 -1.00556411e-01
-1.39819756e-01 2.83829328e-02 -5.77050783e-02 -1.12940697e-02
3.80281210e-02 6.06936514e-02 -1.94498245e-02 -1.47818979e-02
3.55016626e-02 -2.04083398e-02 3.91883925e-02 1.12217903e-01
2.51975060e-02 2.95107649e-03 1.06013544e-01 2.30079442e-02
-2.29791515e-02 -2.56495755e-02 1.57605987e-02 -7.26947039e-02
2.39037592e-02 -1.21727120e-02 -1.31051525e-01 -4.91776466e-02
-4.23773043e-02 1.66836698e-02 -1.53467106e-02 -1.52014107e-01
6.34454936e-02 -9.33196619e-02 6.03508539e-02 -3.97237614e-02
4.51983064e-02 -8.10895637e-02 -3.88888456e-02 1.30122597e-03
-6.57585077e-03 -9.76660997e-02 -4.70533893e-02 -6.61056787e-02
4.82768640e-02 -9.15978756e-03 -5.23277409e-02 6.00934178e-02
8.39000046e-02 1.13636432e-02 1.83682144e-02 1.91877149e-02
-3.87635082e-04 4.56842221e-02 3.65186334e-02 -1.21854998e-01
-8.98549042e-04 5.49026579e-02 -9.90595436e-05 1.64643917e-02
4.71519865e-03 3.48449498e-02 -5.12284487e-02 -2.29314733e-02
6.39457479e-02 3.20835896e-02 1.36690781e-01 1.09906485e-02
-7.47184828e-03 -6.80784788e-03 -4.36202772e-02 -2.28209328e-02
-9.84098539e-02 -3.50073539e-02 6.02847151e-02 2.78636720e-02
-5.06377742e-02 -4.35535833e-02 5.41143976e-02 6.54703751e-02
-3.84840518e-02 2.59492919e-02 2.46140100e-02 -5.07574268e-02
4.58420590e-02 -2.05117147e-02 1.23625234e-01 5.47722913e-02
4.67660371e-03 3.27725485e-02 5.25543429e-02 1.08103245e-01]
聚类结果如下:
类别1:
玄慈 神山上人 一灯大师 灵智上人 简长老
类别2:
宗赞王子 完颜洪熙 侯通海 哑梢公 梁长老 樵子
类别3:
鸠摩智 来福儿 耶律洪基 努儿海 宋长老 苏星河 苏辙 完颜阿古打 吴长风 枯荣长老 辛双清 严妈妈 余婆婆 岳老三 张全祥 单伯山 单季山 单叔山 单小山 单正
类别4:
完颜洪烈 拖雷 韩小莹 太皇太后 耶律洪基 智光大师
类别5:
木婉清 王语嫣 乔峰 萧峰 阿朱 阿紫 段誉 段正淳 钟灵 虚竹 游坦之 慕容复
由此可知,词向量的训练结果还是令人满意的。但是聚类的结果不尽人意,因为省略了过多的人名,这可能跟词向量的训练有关,和词向量的参数window有关。
总结
通过实验对词向量的概念更加清晰,也对Word2Vec模型的实践方法更加了解。对几个词汇进行聚类分析,可以看出Word2Vec模型的强大之处。然而Kmeans的聚类结果还是不尽人意,其中忽略了过多的人名,这可能跟一开始的训练的参数没有调好有关。
全面理解word2vec
gensim函数库的Word2Vec的参数说明
什么是 word embedding?
基于word2vec的k-means聚类