一、安装
python下载地址:Welcome to Python.org
windows安装验证:

Linux安装:
安装依赖:yum -y install wget zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gcc make zlib zlib-devel libffi-devel
下载python:wget https://www.python.org/ftp/python/3.12.4/Python-3.12.4.tgz
解压python包:tar -xvf Python-3.12.4.tgz
安装python:cd Python-3.12.4
./configure --prefix=/usr/local/python3.12.4
make&&make install
创建软链接:rm -f /usr/bin/python
ln -s /usr/local/python3.12.4/bin/python3.12 /usr/bin/python
修改yum依赖,避免yum依赖python无法使用:
vi /usr/libexec/urlgrabber-ext-down
将首行/usr/bin/python改成/usr/bin/python2
vi /usr/bin/yum
将首行/usr/bin/python改成/usr/bin/python2
pycharm下载地址:PyCharm: the Python IDE for data science and web development (jetbrains.com)
二、语法
python严格区分大小写
换行等同于语句的结束
一条语句分多行时通过\连接
严格缩进,只能使用空格,不能使用tab缩进
使用# content进行单行注释说明,使用"""content"""进行多行注释说明,通常多行注释出现在首行
三、基本数据类
1.变量和标识符
变量无需先声明,可直接赋值再使用
变量无固定类型,可任意赋值,任意修改
标识符包含字母,数字,_构成,但不能以数字开头,且大小写敏感(可以使用中文,但不太完善),英文字母尽可能小写
避免命名以关键字和保留字冲突
命名规范:下划线命名法,大驼峰命名法
2.数值
分类:整数,浮点数,复数
所有的整数均为int类型,且没有大小限制
数字可以使用_分割,输出时_会被忽略
十进制数字不能以0开头,二进制以0b开头,八进制以0o开头,十六进制以0x开头
在python中所有打印出来的数字均是10进制展示
浮点数均是float类型,对浮点数进行运算结果不精确
3.字符串
字符串必须使用引号引起来
如要保留字符串原格式使用三重引号,即'''或"""
转义字符\
制表符\t,换行符\n
字符串使用+拼接只能与字符串拼接
拼接方法:print('a = ',a)或print('a = ' + a)
占位符%s:b = 'hello %s' %'tom'
b = 'hello %s and %s' %('tom', 123)
b = 'hello %s' % a
%d表示整数
%f表示浮点数
格式化:%3s表示最短3个字符,不够前补空格
说明:若数字的长度小于字符的长度,则直接输出字符
%3.5s表示最短3个字符,最长5个字符
%.2f表示保留两位小数(会进行四舍五入,小数位不足用0补齐)
快速格式化f:c = f 'hello {b}'
说明:字符串、数字和浮点数均可使用,不关注类型和精度,原样输出
说明:格式化或者快速格式化同样适用于通过表达式得到的结果,只要结果与类型一致即可
字符串与数字相乘会重复数字次的字符串
4.布尔和空值
a = True b = False
布尔值实际也属于整型,True是1,False是0
空值None,用来表示不存在
5.类型检查
type(a)该函数会将检查结果作为返回值返回
6.类型比较
单类型对标:isinstance(对象, 类型)
多类型比较:isinstance(对象, (类型1, 类型2...))
说明:多类型比较是指该对象是都是多个类型中的一个,满足一个即返回True
四、对象
1.对象的结构
id:标识对象的唯一性,可通过id(a)方法获取a的标识值,在python中是对象的内存地址;对象一旦创建,id固定无法改变
type:标识对象所属的类型,决定了对想具有哪些功能,可通过type(a)方法获取a的类型,python是强类型语言,对象创建后无法改变
value:对象中存储的具体数据,分为可变对象和不可变对象,之前接触的值如1,a,True等均是不可变对象
2.变量和对象
示例:a=3
3表示对象,a表示变量,变量存储在一个单独的区域(一列变量名,一列值),通过变量存储对象的id值来建立变量和对象两者的关系
特别的b=a,实际是把变量a的值赋予给变量b的值,相当于变量a和变量b都指向同一个对象
3.类型转换
类型转换不是改变对象本身的类型,而是将对象的值转换成新的对象
类型转换的函数int(),float(),str(),bool()
int规则:对于boolean的按照之前的对应关系转换;浮点数直接取整(不会四舍五入);合法的整数字符串可转换成整数,不合法的直接报错valueerror(小数字符串转换整形同样报错);其他不可转换的类型同样报错valueerror
float规则:基本和int规则一致
str规则:将所有对象转换成字符串
bool规则:对于所有表示空性的对象(如0、''、None等)都会转换成False,其余的转换成True
五、运算符
1.算数运算符
+:进行加法运算
-:进行减法运算
*:进行乘法运算,字符串是重复打印n次字符串
/:进行除法运算(结果通常为float)
//:进行取整运算(不进行四舍五入)
%:进行取模运算(即取余)
**:进行指数运算
2.赋值运算符
=、+=、-=、*=、/=、%=、**=、//=
3.比较运算符
==:判断内容是否相等
!=:判断内容是否不相等
>:判断内容是否左边大于右边
<:判断内容是否左边小于右边
>=:判断内容是否左边大于等于右边
<=:判断内容是否左边小于等于右边
六、常用方法
1.print()
作用:控制台打印括号内的内容
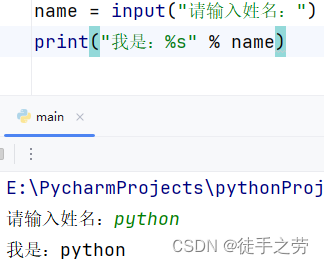
2.input()
作用:接收控制台的输入内容,括号内可添加提示内容,最终的输出结果是string类型
示例:
3.range()
作用:提供一个可以一个个取出的序列
示例:range(num1, num2, step)
说明:
方式1:只指定一个num1时,默认从0开始到num1结束的数字序列,左闭右开
方式2:指定两个num1和num2时,获得一个从num1开始到num2结束的数字序列,左闭右开
方式3:指定三个num1,num2和step(默认为1)时,获得一个从num1开始,每次步进step,直到num2或即将超过num2结束的数字序列,左闭右开
七、逻辑语句
1.if
语法:
if 条件:
dosomething
2.if else
语法:
if 条件成立:
dosomething
else:
dootherthing
3.if elif else
语法:
if 条件1:
dosomething
elif 条件2:
dosomething
else:
dosomething
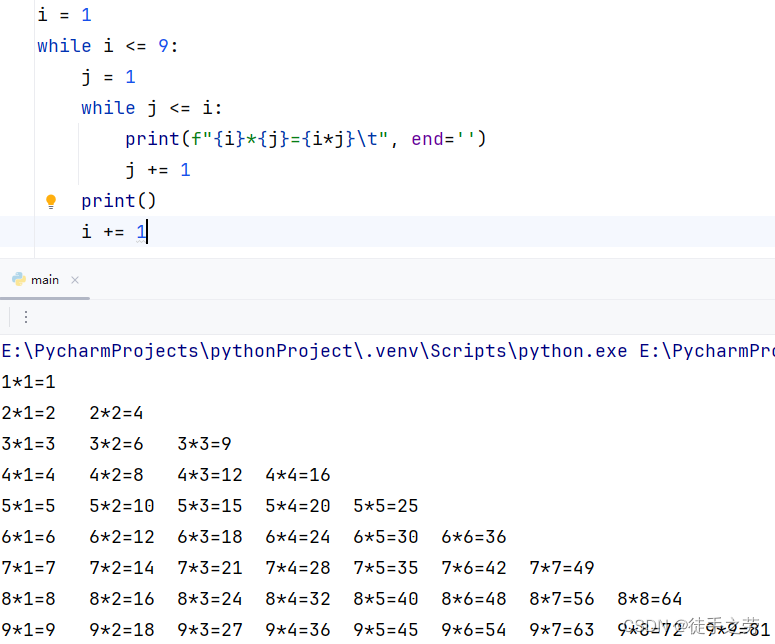
4.while
语法:
while 条件:
dosomething
特别的:print语句输出不换行print("xxx", end='')
示例:
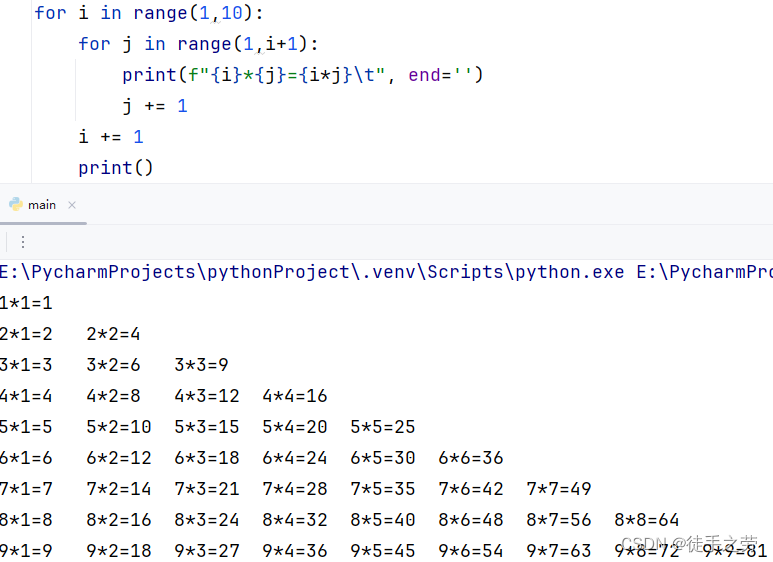
5.for
语法:
for i in 数据序列:
dosomething
特别说明:变量i的作用域就是for循环内部,但实际在for循环外部依旧可以使用,即规范上不允许,实际可以调用到
示例:
6.continue和break
作用:continue跳过本次循环,break直接结束循环(结束嵌套break的for循环,但不会结束更外层的for循环)
八、函数
作用:减少代码重复性,提高程序复用性,提高开发效率
特别的:建议使用多行注释的方式对函数进行文档说明
1.语法
def 函数名(形式参数):
函数体
return 返回值
说明:参数的个数可以是0个,可以是多个,中间用,隔开,且参数和返回值可省略
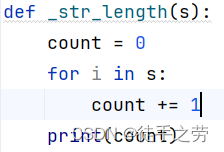
2.入参
函数实际调用时,传入实际参数即可,需注意实际参数数量需和形式参数数量相同
作用:将实际参数代入方法的到指定结果
示例:
3.返回值
关键字:return
作用:将方法执行结果返回给方法调用者
说明:方法中return语句后的代码不会被执行
示例:

4.None
方法无return语句时,实际返回的是None类型,表示空的,无实际意义的意思
使用场景:
1.方法无返回值时
2.用在if判断上,None等同于False
3.声明无内容的变量
5.作用域
函数中变量(也成为局部变量)的作用域,只能在函数体内部生效,外部调用会立即报错
全局变量即定义在函数外部的变量(注意,函数体内也可以声明一个和全局变量同名的局部变量,注意区分)
示例:

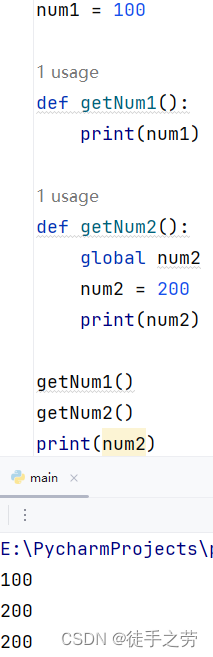
6.global关键字
作用:使函数内部声明的变量成为全局变量,不一定要和原本的全局变量保持一致(但规范上不允许,实际依旧可以调用的到)
示例:

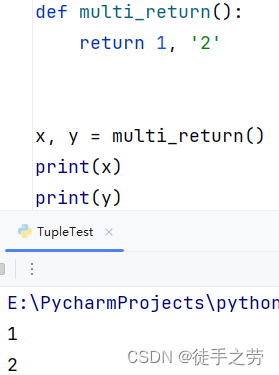
7.多返回值
语法:
def multi_return():
return 1, '2'
x, y = multi_return()
示例:
8.多种入参形式
1)位置参数
根据位置一一对应传递参数
声明方式:
def test(name, age, gender)
test('xxx', 10, 'x')
2)关键字参数
声明方式:
def test(name, age, gender)
test(name='xxx', age=10, gender='x')
注:函数调用时如果有位置参数,位置参数必须在关键字参数之前,关键字参数没有先后顺序
3)缺省参数
对参数设置默认值,可传参也可不传参,但缺省参数需要写到最后
声明方式:
def test(name, age, gender='x')
test('xxx', 10)
test('xxx', 10, 'x')
4)不定长参数
可变参数,分为位置传递的不定长和关键字传递的不定长
位置传递的不定长
声明方式:
def test(*args)
test('xxx', 20)也可以test('xxx')
说明:实际参数会被接收到一个元组中,即(args)
关键字传递的不定长
声明方式:
def test(**args)
test(name='xxx', age=20)也可以test(name='xxx')
说明:实际参数会以K-V键值对被接收到一个字典中,即{args}
9.lambda匿名函数
函数作为参数传递
语法:
def compute(x, y)
return x + y
def test(compute)
sum = compute(1, 2)
print(sum)
说明:传递的是计算逻辑,而不是数据
lambda匿名函数
语法:
def test(compute)
sum = compute(1, 2)
print(sum)
test(lambda x, y: x+y)
说明:效果同上函数作为参数传递,只不过lambda定义的函数是匿名的,无法二次使用,且只支持一行代码的场景
九、数据容器
容器是一个可以容纳多份数据的数据类型,数据可以是不同类型且支持容器嵌套
1.列表list
定义方式:a = []或a = list()
事先填充数据:[元素1, 元素2, ...],元素也可以是list类型
元素的容纳上限为2**63-1,支持容纳不同类型的元素,元素存储有序且允许重复
通过下标获取列表数据:a[下标索引],下标索引由0开始,也可以反向获取,下标索引由-1开始
示例:a[0],a[1],a[...]或a[-1],a[-2],a[...]
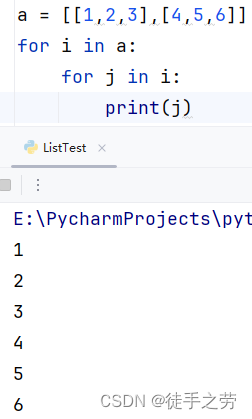
嵌套列表:a[0][0]
示例:
常用操作:方法的调用使用对象名.方法名(参数)
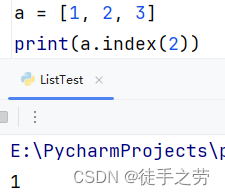
查询元素:
查询指定元素的下标值,不存在报错ValueError
语法:列表.index(元素)
示例:
插入元素:
在列表的指定位置插入元素值,指定位置及之后的元素自动后移
语法:列表.insert(下标, 元素)
示例:

追加单个元素:
在列表的末尾增加元素
语法:列表.append(元素)
示例:
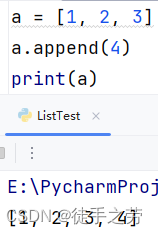
追加多个元素:
在列表末尾追加一批元素,一般指定的数据容器,会将容器内的数据取出,逐个依次追加
语法:列表.extend(其他数据容器)
示例:
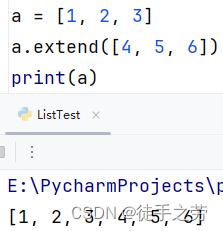
删除元素:
删除指定下标的元素
语法:del 列表[下标]或列表.pop[下标]
注:pop方法可以返回被删除的元素值,通常用于日志打印等
示例:
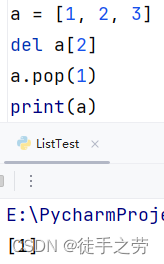
删除匹配到的首个出现的元素
语法:列表.remove(元素)
示例:
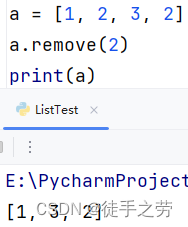
清空列表:
清空列表的整个内容
语法:列表.clear()
示例:
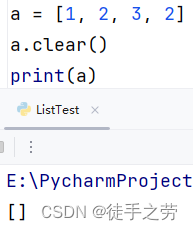
修改元素:
修改指定下标的元素值
语法:列表[下标] = 元素
示例:

统计元素个数:
统计某个元素的数量
语法:列表.count(元素)
示例:
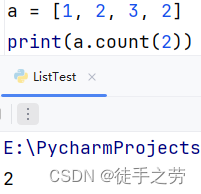
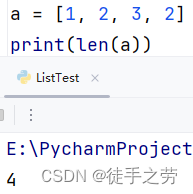
统计列表的元素数量
语法:len(列表)
示例:
遍历方法:while或for实现
2.元组tuple
相比于list,tuple的内容在定义后不可被修改
元素可以是不同类型且可以重复
定义方式:a = (1, 2, 3, ...)
特别的如果元组中的数据只有一个,需要元素后面有一个逗号,否则定义的将不是元组类型,而是str类型,示例:(1, )
空元组:()或tuple()
通过下标获取元组元素:a[0]...
常用操作:
查询数据:
查询指定元素的下标
语法:元组.index(元素)
示例:
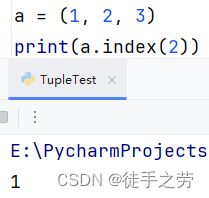
统计数据个数:
查询指定元素出现的次数
语法:元组.count(元素)
示例:
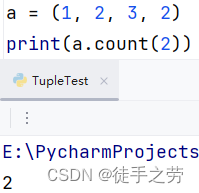
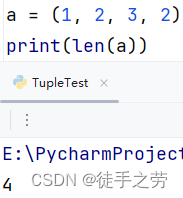
统计元组的元素数量
语法:len(元组)
示例:
3.字符串str
字符串存储数据的方式实际也和容器一样,同样也支持下标获取元素,但不支持修改元素,强行修改得到的会是一个新的字符串对象
示例:
常见操作:
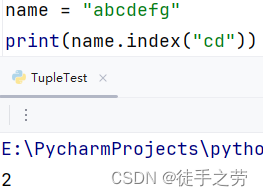
查询元素:
查询指定元素在原字符串中的起始下标
语法:字符串.index(元素)
示例:
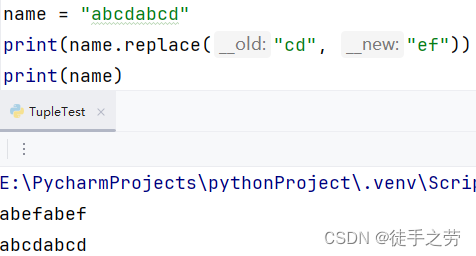
替换元素:
将指定字符串中的全部元素1替换成元素2。得到的是一个新的字符串
语法:字符串.replace(元素1, 元素2)
示例:
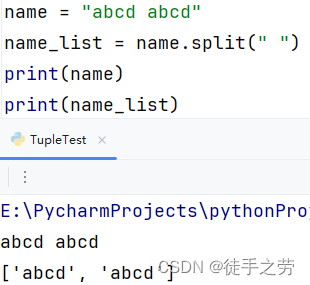
字符串的分割:
将字符串根据分隔符分割,存入列表对象中,原字符串不变
语法:字符串.split(分隔符)
说明:不添加分割符默认为空格或换行符
示例:
字符串的规整:
删除字符串前后的空格或指定字符串
语法:字符串.strip()或字符串.strip(字符串)
示例:

说明:删除指定字符串前后的字符串时,实际是按单个字符取匹配的,只要前后同个数的字符所包含的内容和指定字符串一样都将会被删除
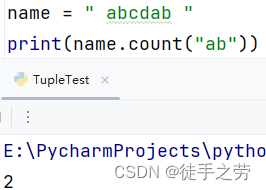
统计次数:
统计指定字符串在字符串中出现的次数
语法:字符串.count(字符串)
示例:
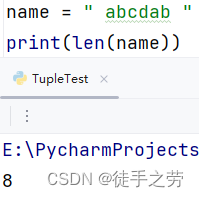
统计字符串的长度
语法:len(字符串)
示例:
4.容器的切片
序列是指内容连续,有序,可以使用下标索引的一类数据容器,如列表,元组,字符串
切片是指从一个序列列中取出一个子序列
语法:序列[起始下标:结束下标:步长]
说明:起始下标可以留空,表示从头部开始;结束下标表示结束位置(切片结果不含结束位置),可以留空,表示到结尾结束;步长表示取元素的间隔,为负表示反向取,默认为1,可省略不写
示例:a[1:3]表示由1起始到3结束,步长为1
a[:]表示从头起始到尾结束,步长为1
a[:2]表示从头起始到尾结束,步长为2
a[::-1]表示从头起始到尾结束,步长为-1
a[3:1:-1]表示从3起始到1结束,步长为-1
5.集合set
相比于列表、元组和字符串集合不支持元素重复(可以传入但会自动去重),且无序
定义方式:a = {元素1, 元素2, 元素3, ...}或a = set()
常用操作:
因为无序所以不支持下标索引访问,但允许修改
添加操作:
添加新元素
语法:集合.add(元素)
示例:
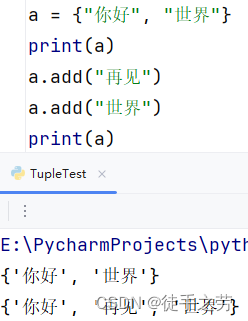
移除元素:
删除指定元素
语法:集合.remove(元素)
示例:
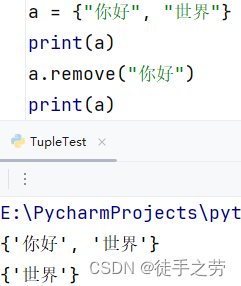
取出元素:
随机取出(删除)一个元素
语法:集合.pop()
示例:
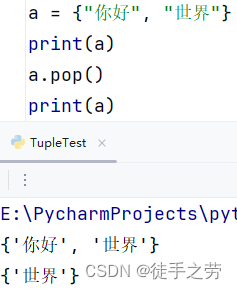
清空集合:
清空集合内元素
语法:集合.clear()
示例:
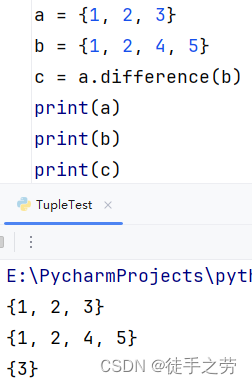
取出两个集合的差集:
取出集合前者有的而后者没有的
语法:集合1.difference(集合2)
示例:
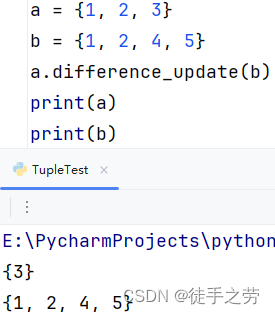
消除两个集合的差集:
消除集合前者中两个集合相同的元素
语法:集合1.differenec_update(集合2)
示例:
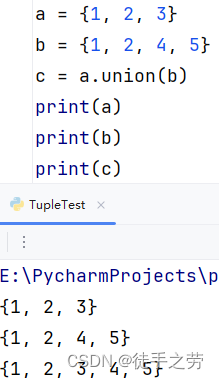
合并集合:
将两个集合合并成一个新集合
语法:集合1.union(集合2)
示例:
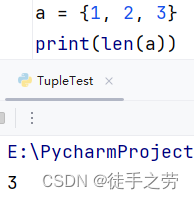
统计集合元素数量:
语法:len(集合)
示例:
6.字典dict
通过K-V的形式存储元素的容器,可以容纳不同类型的元素
定义方式:a = {key: value, key: value, ...}或a = {}或a = dict()
说明:字段中的key不允许重复,后者会覆盖前者;字典可以嵌套
常用操作:
通过key获取value:
语法:字典[key]
示例:
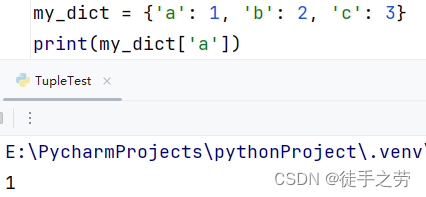
获取嵌套字典的数据:
语法:字典[key1][key2]
示例:
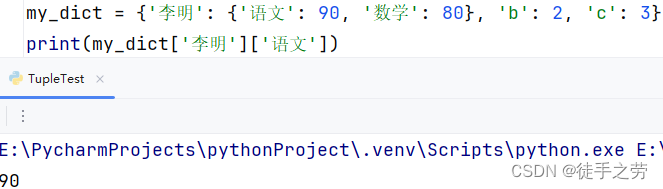
新增元素:
语法:字典[key] = value
示例:
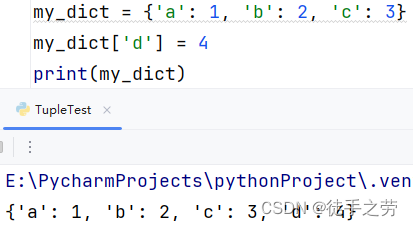
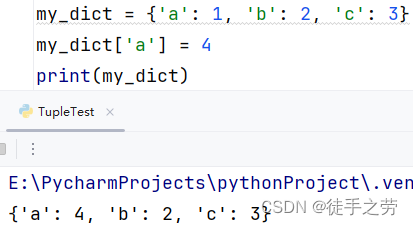
更新元素:
语法:字典[key] = value
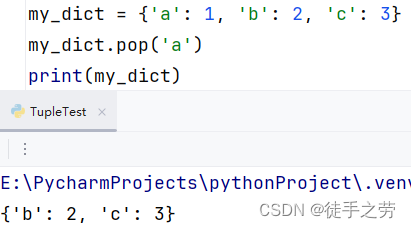
删除元素:
语法:字典.pop(key)
示例:
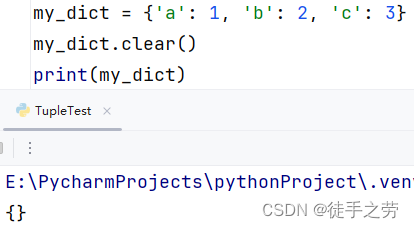
清空字典:
语法:字典.clear()
示例:
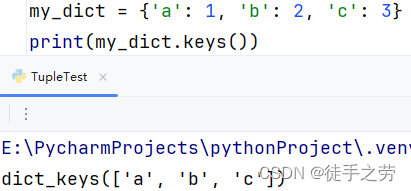
获取全部key:
多用于字典的遍历
语法:字典.keys()
示例:
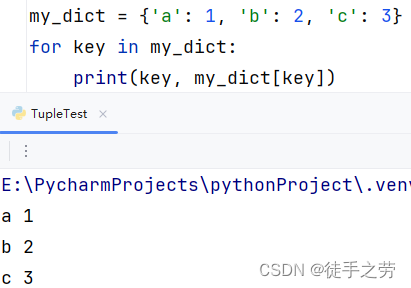
遍历字典:
直接使用key进行遍历
示例:
统计元素数量:
语法:len(字典)
示例:
7.通用操作
统计容器元素个数:len(容器)
统计容器最大元素:max(容器),说明:str分字符比较,字典只比较key值
统计容器最小元素:min(容器),说明:str分字符比较,字典只比较key值
将容器转换成列表:list(容器),说明:str分字符存储,字典只存储key值
将容器转换成字符串:str(容器),说明:各集合类型格式化输出
将容器转成成元组:tuple(容器),说明:同list
将容器转换成集合:set(容器),说明:同list
给容器元素排序:sorted(容器, reverse=True),说明:返回一个列表对象,默认升序,reverse=True用于反转降序,可不写
指定容器元素排序规则:容器.sort(key=排序函数, reverse=True),说明:对调用容器根据排序函数进行排序,reverse=True用于反转降序
示例:
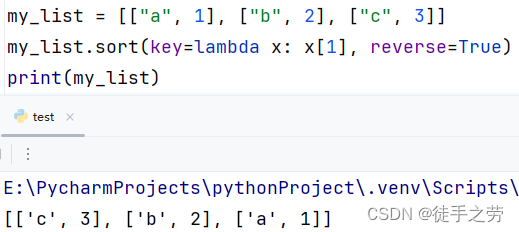
特别的:str的大小比较通过ASCII码来比较字符的大小
十、文本操作
1.文件编码
机器识别的是二进制内容,其他可用的编码如UTF-8、GBK、BIG5等
2.文件的读取
open()可以打开一个已经存在的文件或者创建一个新文件
语法:file = open(name, mode, encoding)
说明:name指定需要打开的目标文件名字符串,包含文件在所在的具体路径
mode设置打开文件的模式,只读r,写入w或追加a
encoding设置编码格式,推荐使用UTF-8
常用方法:
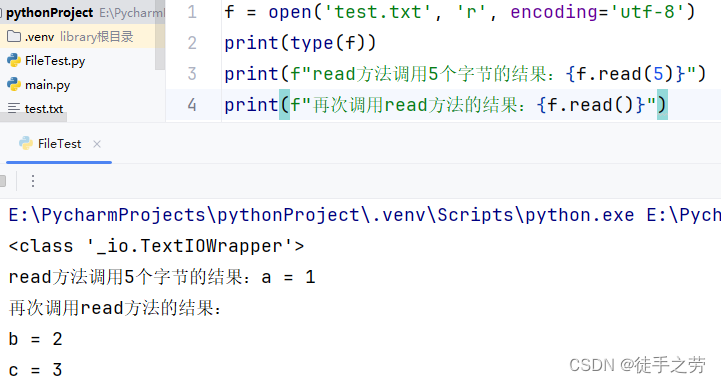
read()
语法:
文件对象.read(num)
读取指定字节长度的文件内容,未传入num则表示读取文件所有内容,读取结果为字符串类型,如果程序中连续掉用多次read方法,首次调用read后的位置会被记录,再次调用会从该位置开始
示例:
readlines()
语法:
文件对象.readlines()
按照行的形式将文件内容一次性读取,返回一个列表,每行数据是一个元素,同样的read方法也会影响readlines读取的起始位置
示例:

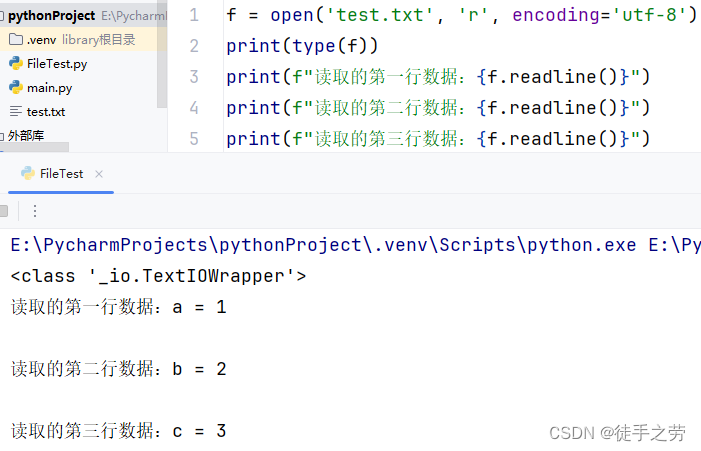
readline()
语法:
文件对象.readline()
一次读取一行内容,读取结果为字符串类型
示例:
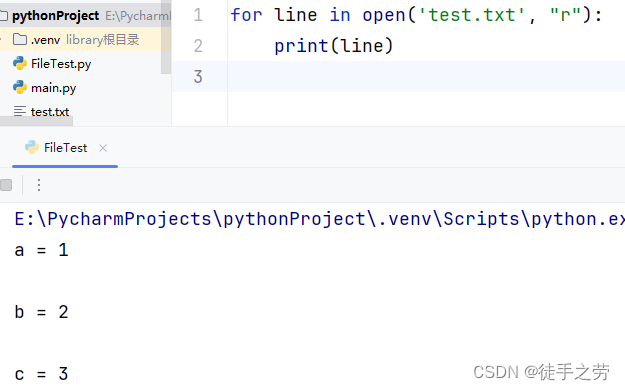
for循环读取文件行
语法:
for line in open(name, mode)
示例:
文件的关闭
语法:
文件对象.close()
文件的操作会持续占用这个文件,如果不关闭,该文件会一直被python占用,如果占用文件的程序执行结束,文件会被释放占用
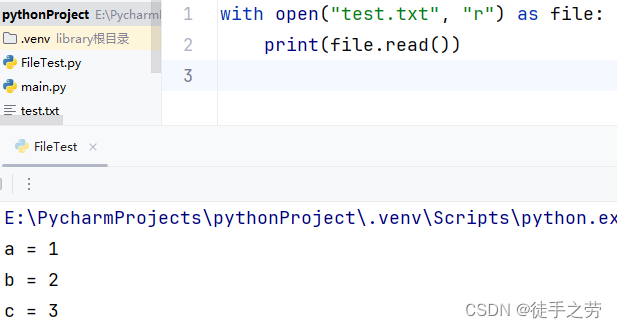
with open
语法:
with open(name, mode) as f:
with open在语句块执行完成后会自动执行close方法
示例:
3.文件的写出
语法:
file = open('filename', 'w', encoding="UTF-8")
file.write('content')
file.flush()
说明:w模式写入文件,如果文件不存在会自动创建,与追加模式a唯一的区别是w模式会将原文件内容清空后再写入,而a模式只会在文件尾追加写入内容;write方法是将要写的内容写入到内存当中,flush方法是将内存中的内容刷新到实际硬盘文件当中去,实际close方法也会主动调用flush刷新内容到硬盘文件当中去
十一、异常操作
1.异常的概念
当python解释器遇到一个错误时,会无法继续进行导致程序中断,控制台会打印错误的信息,这就是异常,注:异常发生之后的代码不会被执行
2.异常的捕获
捕获常规异常语法:
try:
可能发生异常的代码
except:
异常出现时执行的代码
或指定异常捕获语法:
try:
可能发生异常的代码
except ErrorName as e:
异常出现时执行的代码
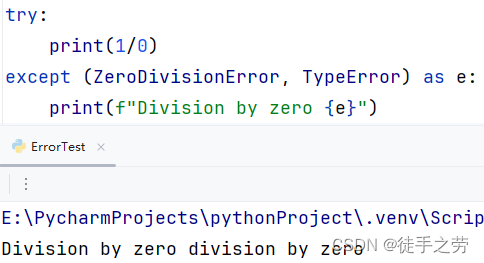
或捕获多个异常语法
try:
可能发生异常的代码
except (ErrorName1, ErrorName2) as e:
异常出现时执行的代码
示例:
或捕获所有异常:
try:
可能发生异常的代码
except Exception as e:
异常出现时执行的代码
说明:该写法效果同第一种写法(捕获常规异常)
可选写法:
try:
可能发生异常的代码
except:
异常出现时执行的代码
else:
无异常时需要执行的代码
finally:
无论异常是否出现,均需要执行的代码
3.异常的传递性
如果一个方法调用了一个会抛出异常的方法,则该方法也捕获到此异常,如果待用的方法没有处理该异常,则程序会因为异常中断
十二、模块和包
1.模块的概念
模块是一个Python文件,能定义函数,类和变量,模块里也能包含可执行的代码
2.模块的使用
语法:[from 模块名] import [模块|类|变量|函数|*] [as 别名]
示例:

3.自定义模块
自定义一个python文件,定义一个函数,在需要使用的python文件中import之前的模块即可使用该模块中定义的函数,需要注意的是如果不同的模块中定义了一个同名的函数,只有最后被import的模块中的同名函数会生效(函数在被from的时候就会被加载,如果里面执行了函数或者输出了语句将会直接被执行)
4.main变量和all变量
语法:if __name__ == '__main__':
执行语句块
说明:主要用于一个文件中定义的执行语句在本文件被直接执行时才可以调用,在from中不会被主动执行的场景
语法:__all__ = []
说明:主要用于from 模块 import *场景中,该场景下如果模块中定义了__all__变量,则import *只能调用__all__列表表量中定义的内容
5.包的概念
包是一个文件夹,这个文件夹包含了一个__init__.py文件和多个模块文件
6.自定义包
示例:
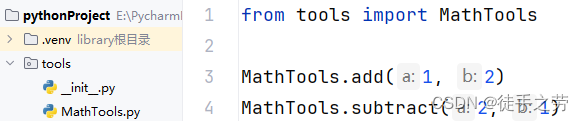
说明:也可以使用from 包名.模块名 import 函数导入指定的函数,特别的__init__.py用来定义__all__变量指定import *场景下默认导入的模块
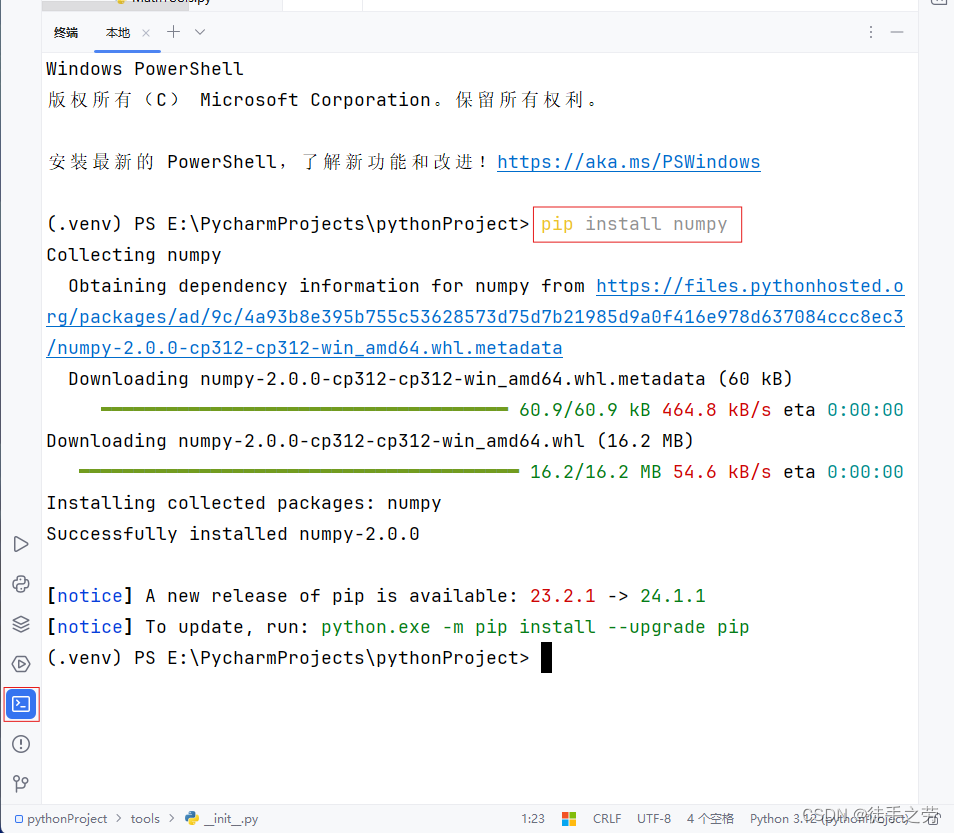
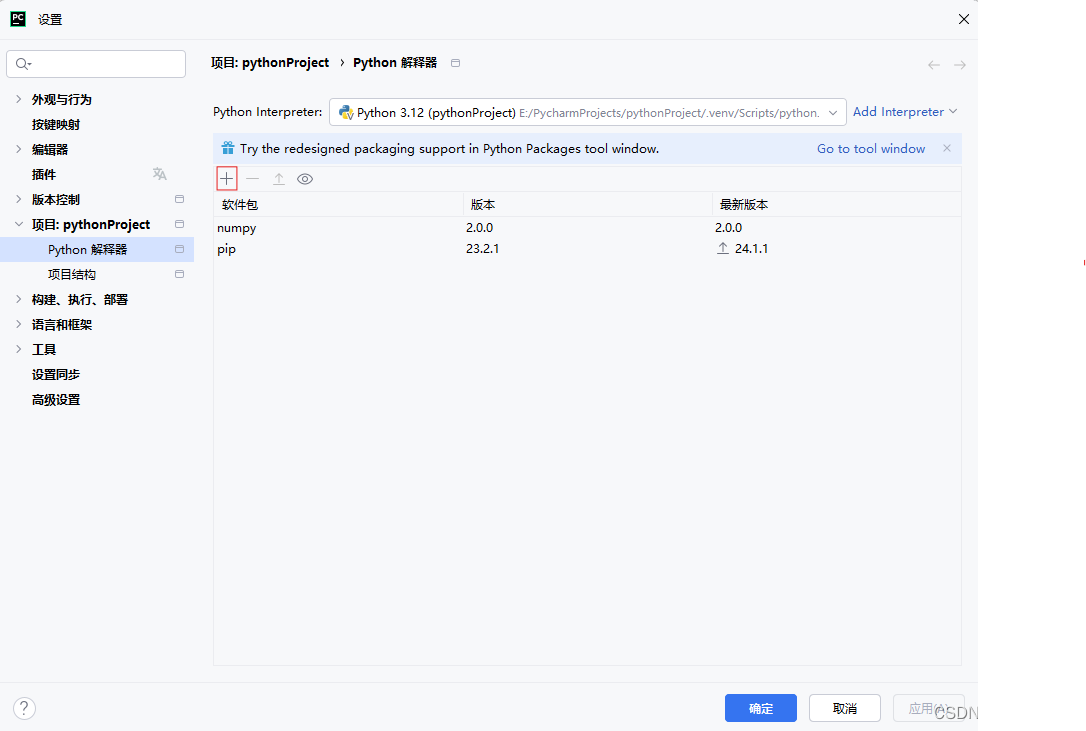
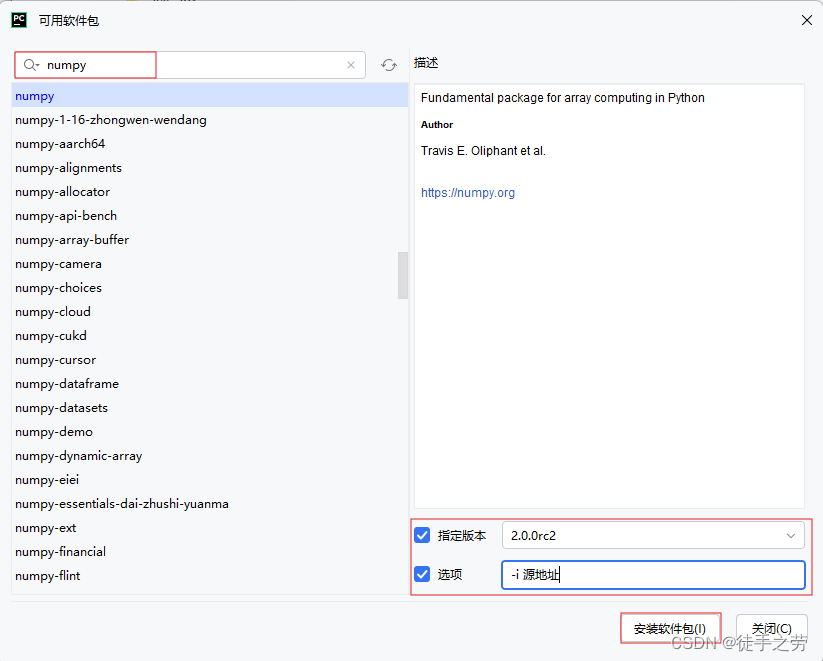
7.安装第三方包
语法:pip install 包名称或指定目标源下载pip install -i 源地址 包名称
pycharm安装示例:
方法一
方法二
十三、可视化案例
1.json数据格式化
json作为一种数据中转格式用于在不用语言之间传递数据,其类型是str,其格式类似于python中的字典或者列表中全是字典
使用内置json模块使用dumps或loads方法来实现数据格式的转换
示例:
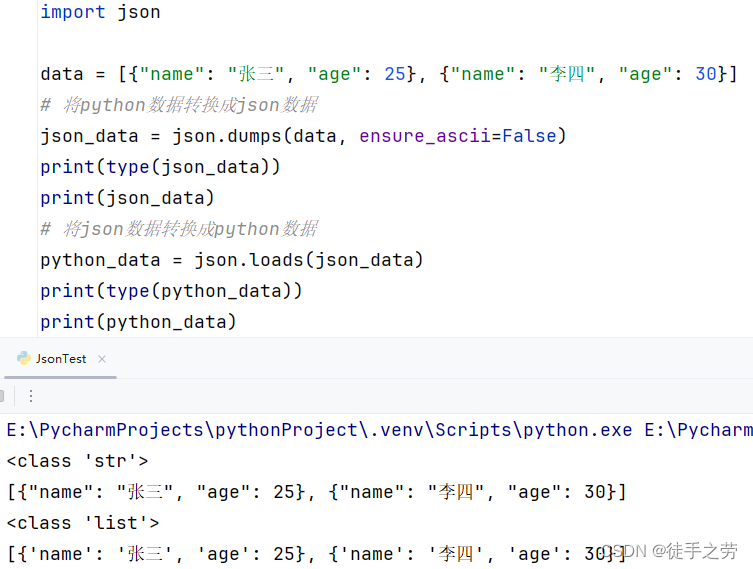
说明:ensure_ascii=False是为了确保中文正常转换
2.pyecharts使用
pyecharts衍生于echarts,是用于数据可视化的图标设计
文档说明:pyecharts - A Python Echarts Plotting Library built with love.
画廊文档说明:中文简介 - Document (pyecharts.org)
包的安装:pip install pyecharts
全局设置选项:set_global_opts()
3.折线图
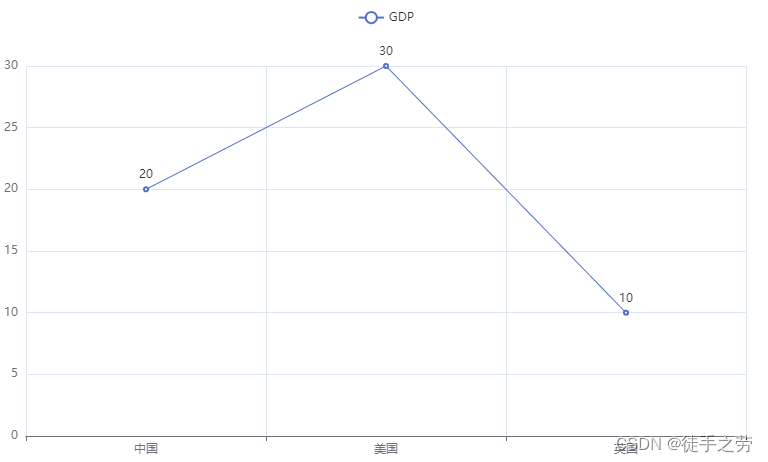
示例:
from pyecharts.charts import Line
line = Line()
line.add_xaxis(["中国", "美国", "英国"])
line.add_yaxis("GDP", [20, 30, 10])
line.render()
说明:render中可以声明需要生成的html文件名,如line.render("折线图.html")

设置全局设置选项后
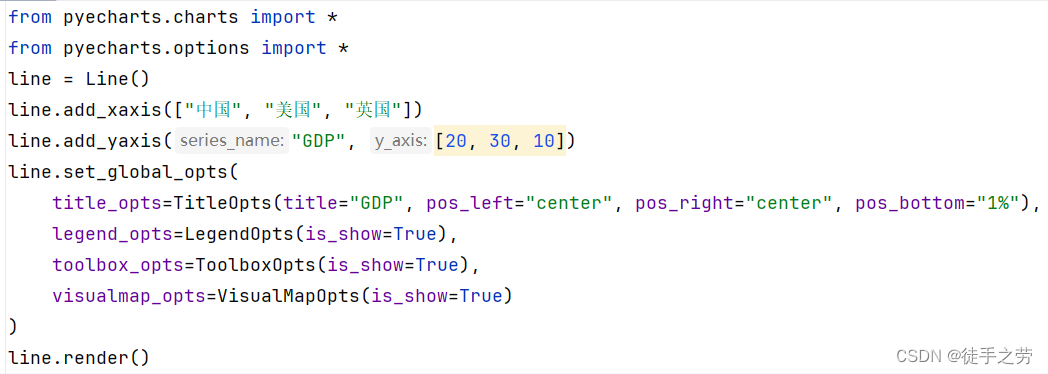

说明:详细的全局设置选项参数说明可以查看:全局配置项 - pyecharts - A Python Echarts Plotting Library built with love.
特别的,设置系列选项如下示例,当数据太多影响查看时,该设置可以隐藏数字只看折线,相对直观
4.分布图
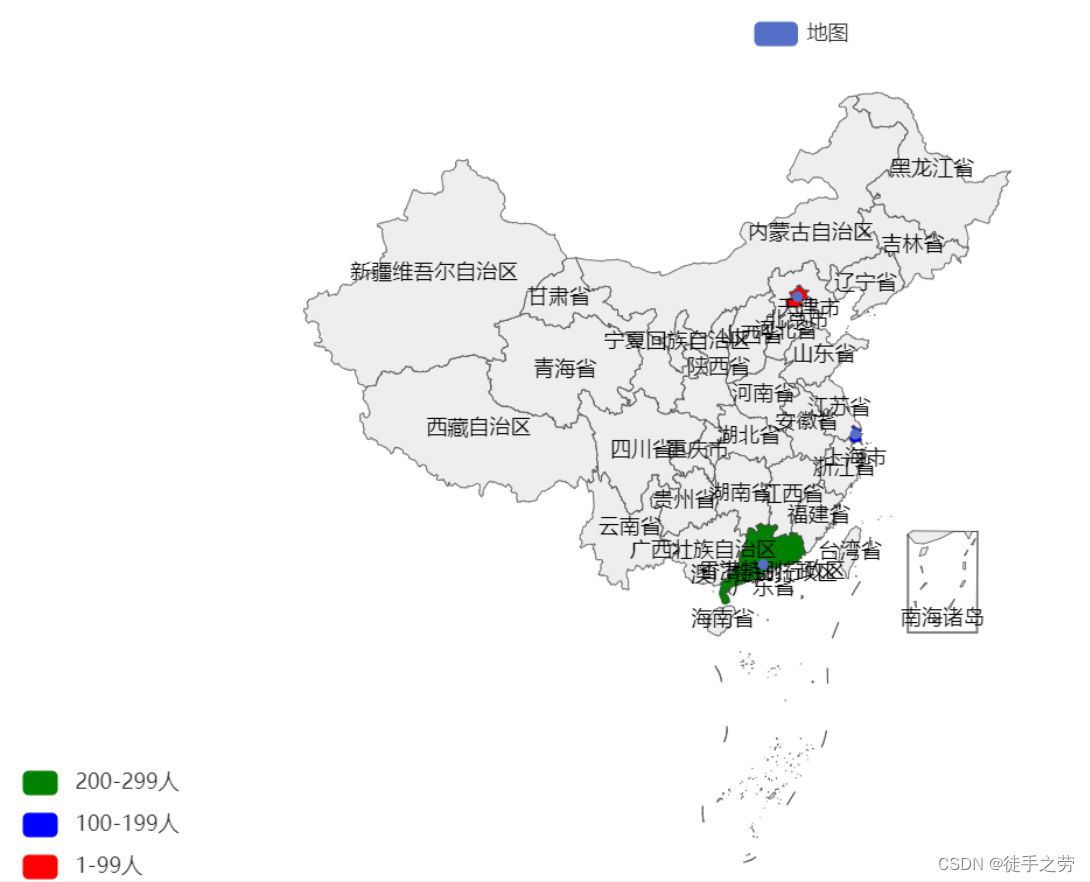
地图分布图:
from pyecharts.charts import Map
from pyecharts.options import VisualMapOpts
maps = Map()
data = [("北京市", 99),("上海市", 199),("广东省", 299)]
maps.add("地图", data, "china")
maps.render()
说明:指定省份时可以直接声明对应省份名maps.add("地图", data, "陕西")
设置全局配置项示例:

说明:color可以通过十六位码表示,比如"color":"#CCFFFF"
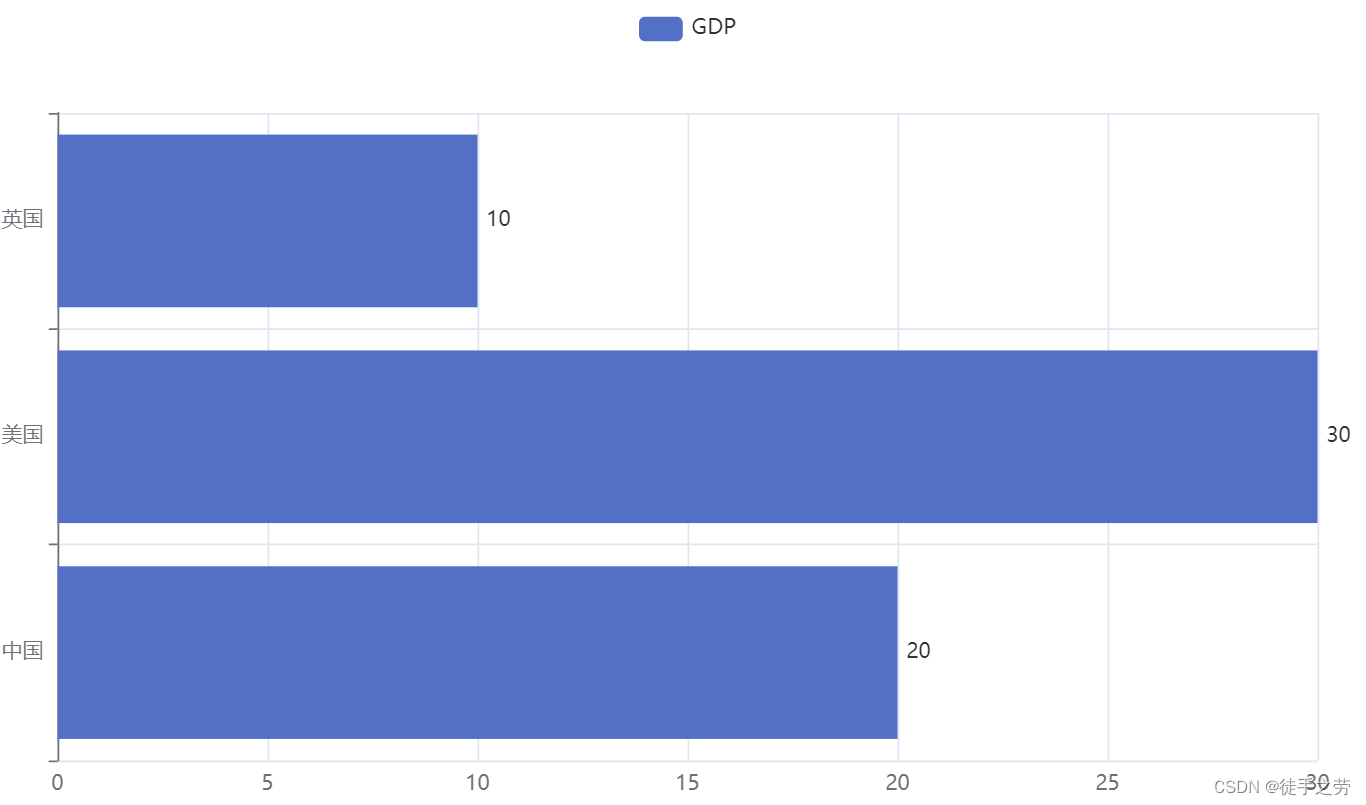
5.柱状图
示例:
from pyecharts.charts import Bar
bar = Bar()
bar.add_xaxis(["中国", "美国", "英国"])
bar.add_yaxis("GDP", [20, 30, 10])
bar.render()
示例:

基于时间线的柱状图示例:
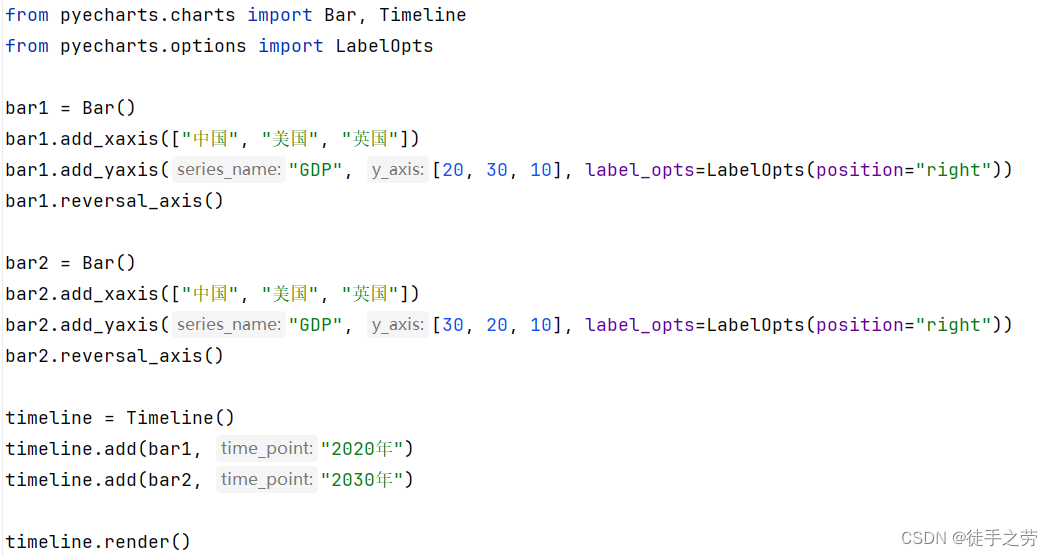
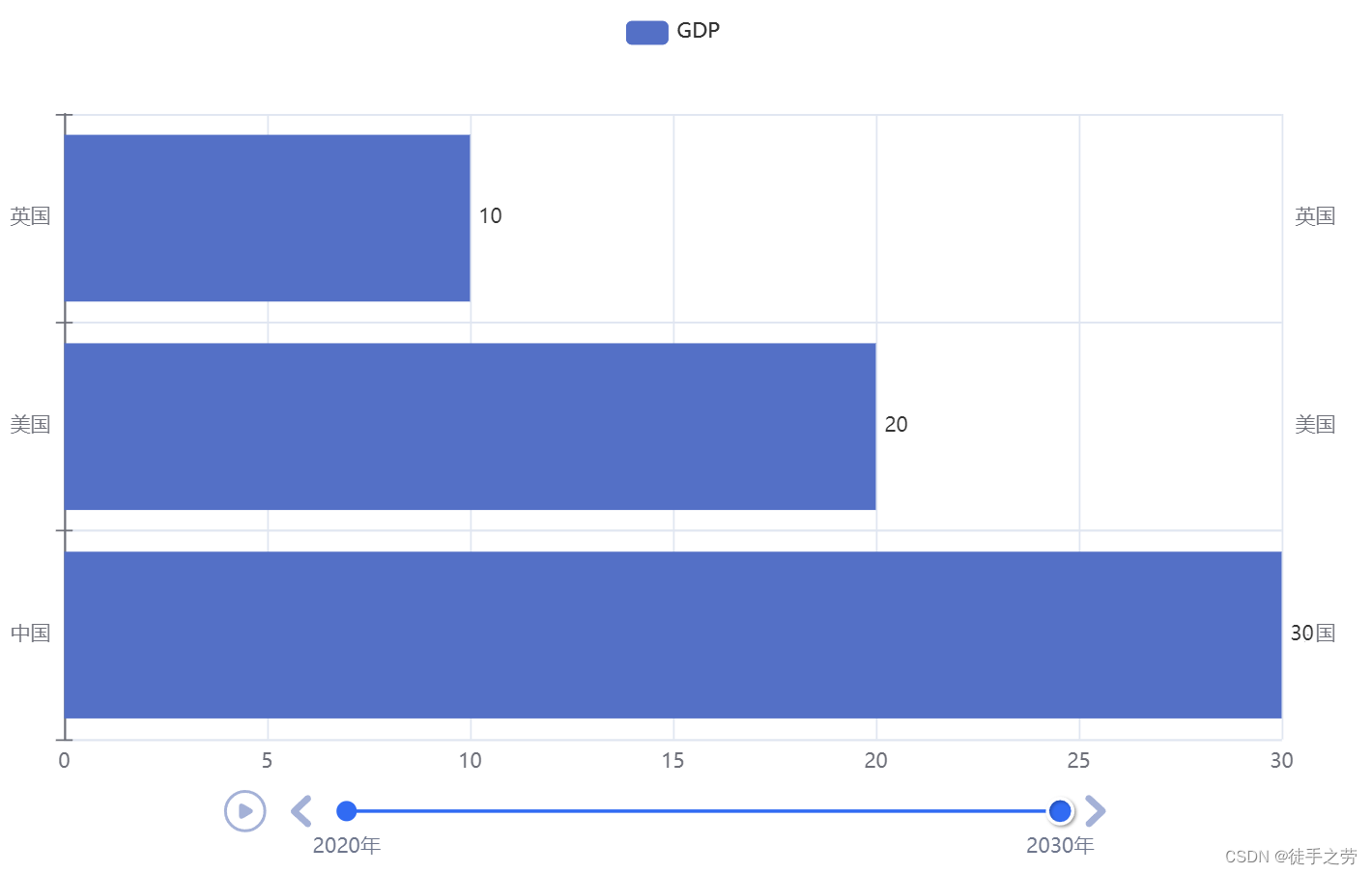
特别的可以设置自动播放的属性:

设置主题颜色:
from pyrcharts.globals import ThemeType
timeline = Timeline({"theme": ThemeType.LIGHT})
十四、对象
1.对象的定义
对象实际就是一个类
语法:
class Human:
name = None
gender = None
id = None
使用:
zhangsan = Human()
zhangsan.name = "张三"
zhangsan.gender = "男"
zhangsan.id = 1111111
2.成员方法
实际是类中定义的方法
语法:
class Human:
name = None
def eat(self, 参数):
print(f"{self.name}正在吃饭")
说明:eat方法中self参数是必须存在的,后续的参数根据需要添加即可
使用:
zhangsan = Human()
zhangsan.name = "张三"
zhangsan.eat()
说明:传入参数是忽略self参数
3.类和对象
类是对现实对象的一个描述,包含对象的属性和行为,对象又是一个类的实际体现,具有明确的属性值和方法
4.构造方法
__init__()方法是构造方法,可以实现创建对象时自动执行,通常用来将参数传递给init方式来做初始化
语法:
class Human:
name = None
gender = None
id = None
def __init__(self, name, gender, age):
self.name = name
self.gender = gender
self.age = age
说明:开始的成员变量实际可以省略,在init方法中在声明的同时做了赋值操作
使用:
zhangsan = Human("张三", "男", 1111111)
5.其他内置方法
__str__(self):自定义对象内容的输出,类似于java的toString方法
语法:
def __str__(self):
return f"content"
使用:
print(对象)
__lt__(self, 对象):用于当前对象做是否小于指定对象的比较时的判断依据
语法:
def __lt__(self, other):
return self.xxx < other.xxx
使用:
print(对象1 < 对象2)
说明:<可以比较,同样>也就适用
__le__(self, 对象):用于当前对象做是否小于等于指定对象的比较时的判断依据
说明:说明:<=可以比较,同样>=也就适用
语法:同__lt__
__eq__(self, 对象):用于当前对象做是否等于指定对象的比较时的判断依据
语法:同__lt__
说明:==默认会比较内存地址
6.封装
类中的私有变量和私有方法均以__开头,私有变量和私有方法无法被对象直接调用,只能使用在该类的其他非私有方法中
7.继承
新的类继承已有类的属性和方法并加以扩展
单继承:
语法:
class Human:
name = None
id = None
def eat(self):
print("正在吃饭")
class Man(Human):
gender = man
def work(self):
print("正在赚钱")
说明:Man(Human)表示Man子类继承了Human父类
使用:
people = Man()
print(people.name)
多继承:
语法:
class 类名(父类1, 父类2, ...):
类内容体或pass
说明:pass表示该类内容体是空的,用于补充语法
补充:继承中的优先级按照默认由左往右的顺序,先继承的保留,后继承的被覆盖
复写:
即子类重新定义父类中已有的同名属性或方法
补充:在子类中调用已被复写的父类同名方法可以使用
父类名.成员变量或super().成员变量
父类名.成员方法(self)或super().成员方法()
8.类型注解
3.5版本引入,以便在数据交互的时候进行数据类型的注解
基础数据类型注解:
a: int = 1
b: str = "test"
c: float = 3.14159
类对象类型注解:
class Human:
pass
man: Human = Human()
容器类型注解:
a: list = [1, 2, 3]
a: list[int] = [1, 2, 3]
a: tuple[str, int, bool] = ("test", 111, True)
a: dict[str, int] = {"test": 111}
说明:tuple中需要把每个元素的类型都标记出来,dict的注解需要分别指定k和v的类型
补充:以上的注解方式统一可以通过注释的方式来注解,如下
语法:
# type: int
# type: dict[str, int]
类型注解通常用于无法直接辨别类型的位置,对于已知类型的地方可以不使用
类型注解仅仅只用于提示,不会影响代码的运行
方法形参的类型注解:
def 函数方法名(形参名: 类型, 形参名: 类型, ...):
pass
方法返回值类型注解:
def 函数方法名(形参名: 类型, 形参名: 类型, ...) -> 返回值类型:
pass
Union类型注解:
格式:
导包:from typing import Union
Union[类型, 类型, ...]
a: list[Union[str, int]] = [1, "test"]
a: dict[str, Union[int, str]] = {"test": 111, "text": "nihao"}
def 函数方法名(形参名: Union[类型, 类型, ...]) -> Union[类型, 类型, ...]:
pass
9.多态
构建的父类对象有多个复写同一方法的子类,在其他方法声明中传入的是父类类型,实际调用时传入的是子类对象,这种现象就叫做多态
示例:
class Animal:
def speak(self):
pass
class Dog(Animal):
def speak(self):
print("汪")
class Cat(Animal):
def speak(self):
print("喵")
def test(animal: Animal):
animal.speak()
dog = Dog()
test(dog)
抽象方法:如示例中Animal类中的speak方法,方法体是空实现的方法称为抽象方法
抽象类:含有抽象方法的类称之为抽象类