目录
Transformer介绍
Tansformer具有两个突出的贡献:
1.自注意力机制,允许网络捕获序列元素之间的“长期”信息和依赖关系;
2.在无监督的大数据集上进行预训练,然后用小样本数据集微调到目标任务。
自注意力机制
自注意力机制估计预测任务中所有实体两两之间的相关性;
自注意力层通过聚合来自完整输入序列的全局信息更新序列的每个组成部分。
自注意力机制模块
自注意力机制是如何将序列中的每个实体关联起来的?
1、用
X
∈
R
n
×
d
X\in \mathbb{R}^{n\times d}
X∈Rn×d表示
n
n
n个实体
(
x
1
,
x
2
,
.
.
.
,
x
n
)
(x_1,x_2,...,x_n)
(x1,x2,...,xn)的序列,其中
d
d
d表示维度。(自注意力机制的目标是根据全局上下文信息对每个实体进行编码捕获所有
n
n
n个实体之间的交互。)
2、定义三个权重矩阵
W
Q
,
W
K
,
W
V
W^Q,W^K,W^V
WQ,WK,WV,通过矩阵生成三个向量(查询向量
Q
=
X
W
Q
Q=XW^Q
Q=XWQ、键向量
K
=
X
W
K
K=XW^K
K=XWK和值向量
V
=
X
W
V
V=XW^V
V=XWV)。
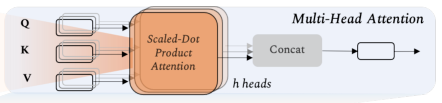
3、然后值自关注层的输出表示为:
Z
=
s
o
f
t
m
a
x
(
Q
K
T
d
q
)
V
Z=softmax(\frac{QK^T}{\sqrt{d_q}})V
Z=softmax(dqQKT)V
如图所示,首先计算键向量和查询向量的点积,然后使用softmax进行归一化,获得注意力分数。接着通过注意力分数获得值向量的权重,从而得到自注意力后的特征图像。
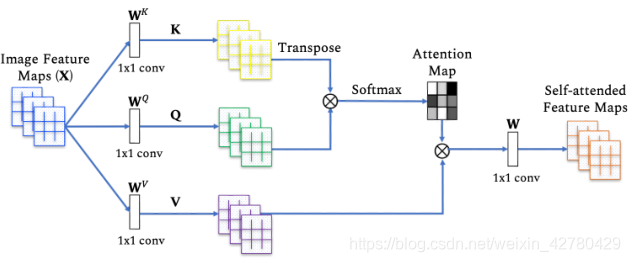
带掩膜的自注意力机制
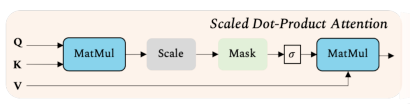
多头注意力机制
为了表示输入序列
X
X
X中的不同实体之间的多种复杂关系,多头注意力机制包含了多个自注意力模块,每个块都具有可学习的权重矩阵(
W
Q
,
W
K
,
W
V
W^Q,W^K,W^V
WQ,WK,WV),然后将输出的多个权重矩阵合并到一个权重矩阵上。
预训练模型
基于自注意力的Transformer模型通常采用两阶段训练。
1、以有监督或无监督的方式,对大规模数据集(有时有几个可用数据集的组合)执行预训练。
2、使用中小型数据集对预训练的权重进行调整,以适应下游任务。
自监督学习(SSL)
基于自监督学习的预训练提高了模型的可扩展性和通用性。自监督学习可分为两种:
1、填补空白,即尝试预测图像中的遮挡数据、时间视频序列中的未来或过去帧、预测借口任务(?)。
2、通过对比学习,施加自监督约束。
自监督学习提供了一种很有前途的学习范例,可以从大量随时可用的非注释数据中进行学习。
借口任务
在基于自监督预训练阶段,训练模型以通过解决结构任务来学习底层数据的有意义表示。借口任务的伪标签是基于数据属性和任务定义自动生成的。
借口任务大致分类:
a)合成图像或视频(给定条件输入)的生成性方法。
b)利用于此时图像补丁或视频帧之间关系的基于上下文的方法。
c)利用多个数据模态的跨模态方法。
其中,生成性方法包括:蒙版图像建模、图像彩色化、图像超分辨率以及图像生成。
已于上下文的借口方法包括:图像块上的拼接、遮蔽图像分类、预测几何变换或验证视频帧的时间序列等。
跨模态方法包括:验证两个模态(例如,文本和图像、音频和视频或RGB和流)的对应关系。
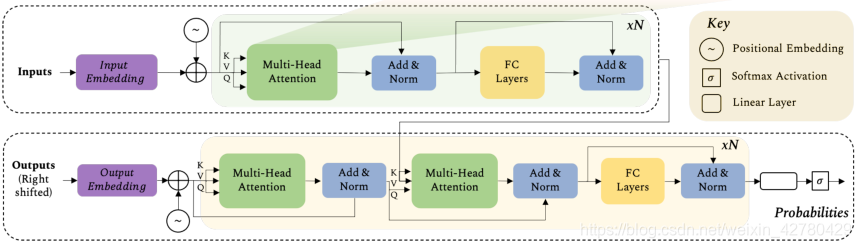
Transformer模型
Transformer模型具有编码器-解码器结构。
编码器由6个相同的块构成,每个块具有两个子层(多头自关注网络和简单的位置全连接前馈网络)。在每个块之后采用层归一化一起的剩余连接。两个子层在模型中是分离的,即自关注层仅执行聚集,而前馈层执行变换。
解码器结构与编码器类似。