讲解关于slam一系列文章汇总链接:史上最全slam从零开始,针对于本栏目讲解(02)Cartographer源码无死角解析-链接如下:
(02)Cartographer源码无死角解析- (00)目录_最新无死角讲解:https://blog.csdn.net/weixin_43013761/article/details/127350885
文末正下方中心提供了本人
联系方式,
点击本人照片即可显示
W
X
→
官方认证
{\color{blue}{文末正下方中心}提供了本人 \color{red} 联系方式,\color{blue}点击本人照片即可显示WX→官方认证}
文末正下方中心提供了本人联系方式,点击本人照片即可显示WX→官方认证
一、前言
通过前面几篇博客的分析,目前只有一个疑问没有解答了,如下:
疑问
1
:
\color{red}疑问1:
疑问1: global_submap_poses 等价于 PoseGraph2D::data_.global_submap_poses_2d 是何时进行优化的。
同时,上一篇博客中有如下几部分的代码并没有进行详细讲解,首先是 ConstraintBuilder2D::DispatchScanMatcherConstruction() 函数中构建 FastCorrelativeScanMatcher2D 对象时:
// 生成一个将初始化匹配器的任务, 初始化时会计算多分辨率地图, 比较耗时
scan_matcher_task->SetWorkItem(
[&submap_scan_matcher, &scan_matcher_options]() {
// 进行匹配器的初始化, 与多分辨率地图的创建
submap_scan_matcher.fast_correlative_scan_matcher =
absl::make_unique<scan_matching::FastCorrelativeScanMatcher2D>(
*submap_scan_matcher.grid, scan_matcher_options);
});
另外就是 ConstraintBuilder2D::ComputeConstraint() 函数中如下两部分代码:
// 节点与全地图进行匹配
kGlobalConstraintsSearchedMetric->Increment();
if (submap_scan_matcher.fast_correlative_scan_matcher->MatchFullSubmap(
constant_data->filtered_gravity_aligned_point_cloud,
options_.global_localization_min_score(), &score, &pose_estimate)) {
CHECK_GT(score, options_.global_localization_min_score());
CHECK_GE(node_id.trajectory_id, 0);
CHECK_GE(submap_id.trajectory_id, 0);
kGlobalConstraintsFoundMetric->Increment();
kGlobalConstraintScoresMetric->Observe(score);
}
// 节点与局部地图进行匹配
kConstraintsSearchedMetric->Increment();
if (submap_scan_matcher.fast_correlative_scan_matcher->Match(
initial_pose, constant_data->filtered_gravity_aligned_point_cloud,
options_.min_score(), &score, &pose_estimate)) {
// We've reported a successful local match.
CHECK_GT(score, options_.min_score());
kConstraintsFoundMetric->Increment();
kConstraintScoresMetric->Observe(score);
}
不难看出,其都涉及到 FastCorrelativeScanMatcher2D 这个类,其就是分支定界算法的核心实现,为了大家容易理解后续的代码,先来讲解一下理论基础。
二、基本理论
假设现在有一帧点云数据,以及建立好的地图,如下图所示:
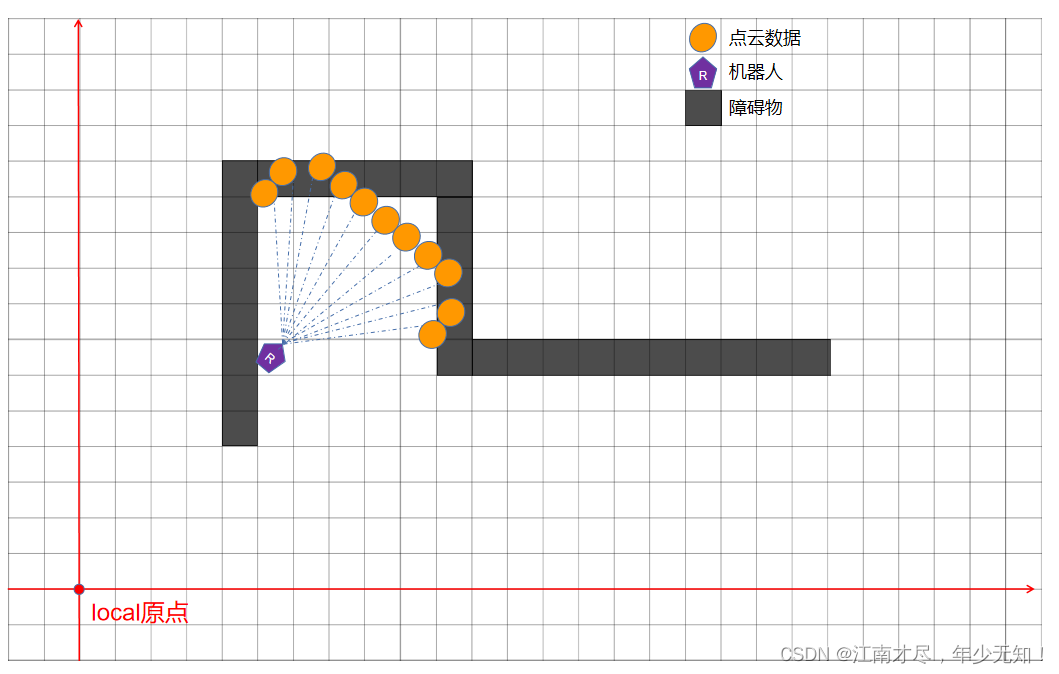
在分析前端的时候,有如下两篇博客:
(02)Cartographer源码无死角解析-(49) 2D点云扫描匹配→相关性暴力匹配1:SearchParameters
(02)Cartographer源码无死角解析-(50) 2D点云扫描匹配→相关性暴力匹配2:RealTimeCorrelativeScanMatcher2D
其时通过一种暴力匹配的方式,对机器人位姿进行多个维度上(角度.位置)的遍历,强制获得匹配效果最好的位姿,可想而知该方式的效率十分低下,且随着 角度,位置 这两个维度的扩打,其计算量增加是十分恐怖的。那么有没有什么什么好的方式可以降低计算量呢?有的,那就是分支定界算法,等明白原理之后,就知道为什么翻译过来叫分支定界算法了。
如上图所示,我们把地图中的障碍物扩大一圈,变成如下模样:
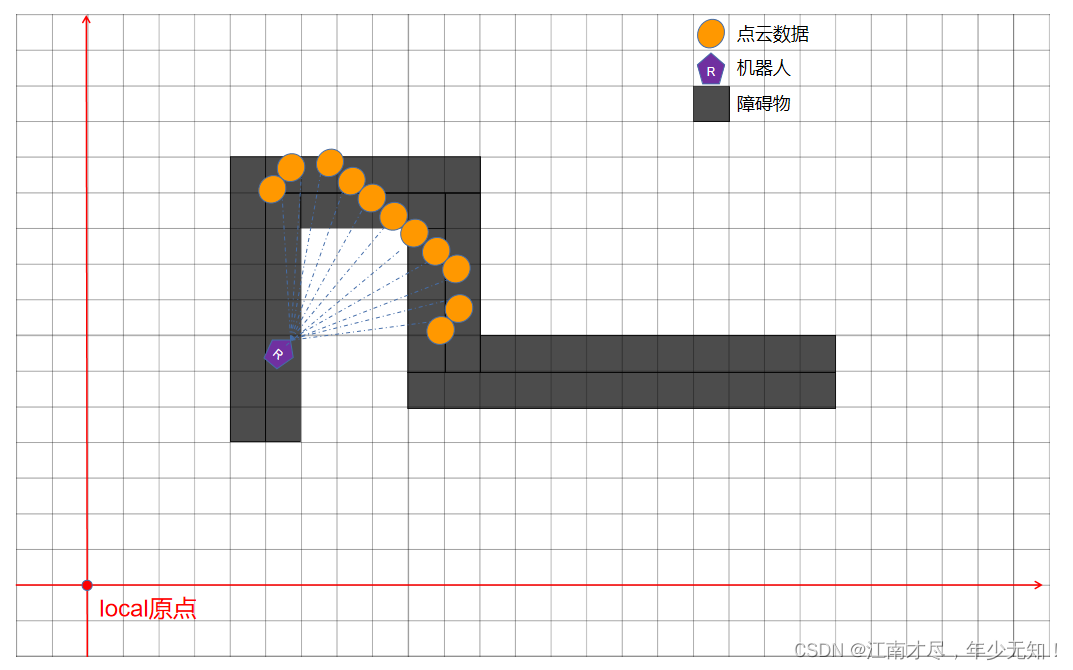
此时我们发现,点云好像匹配上了,虽然还不是那么完美。我们即第一幅图机器人匹配的位置为
R
o
b
o
t
1
t
r
a
c
k
i
n
g
l
o
c
a
l
\mathbf {Robot1}^{local}_{tracking}
Robot1trackinglocal,使用该地图匹配获得的位姿记为
R
o
b
o
t
2
t
r
a
c
k
i
n
g
l
o
c
a
l
\mathbf {Robot2}^{local}_{tracking}
Robot2trackinglocal,且我们在把障碍物扩大一圈,记获得得位姿为
R
o
b
o
t
3
t
r
a
c
k
i
n
g
l
o
c
a
l
\mathbf {Robot3}^{local}_{tracking}
Robot3trackinglocal, 如下图所示:
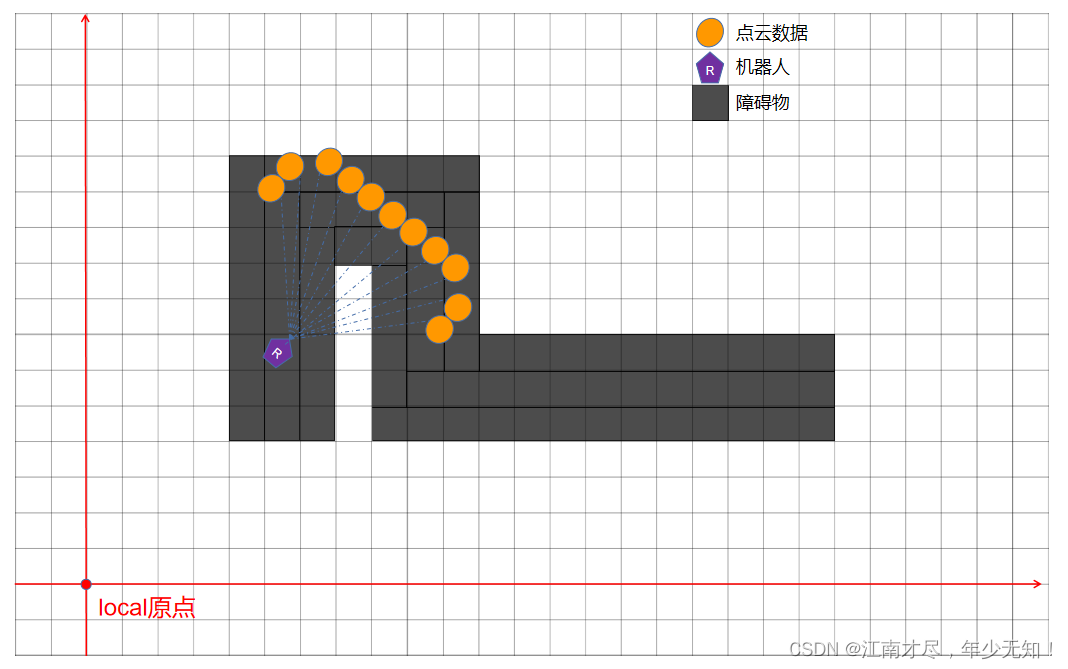
可以看到此时
R
o
b
o
t
3
t
r
a
c
k
i
n
g
l
o
c
a
l
\mathbf {Robot3}^{local}_{tracking}
Robot3trackinglocal 位姿下,点云数据可以说匹配得很好了,但是,这个位置与真实位姿相差似乎太远了,真实的位姿应该是这样的:
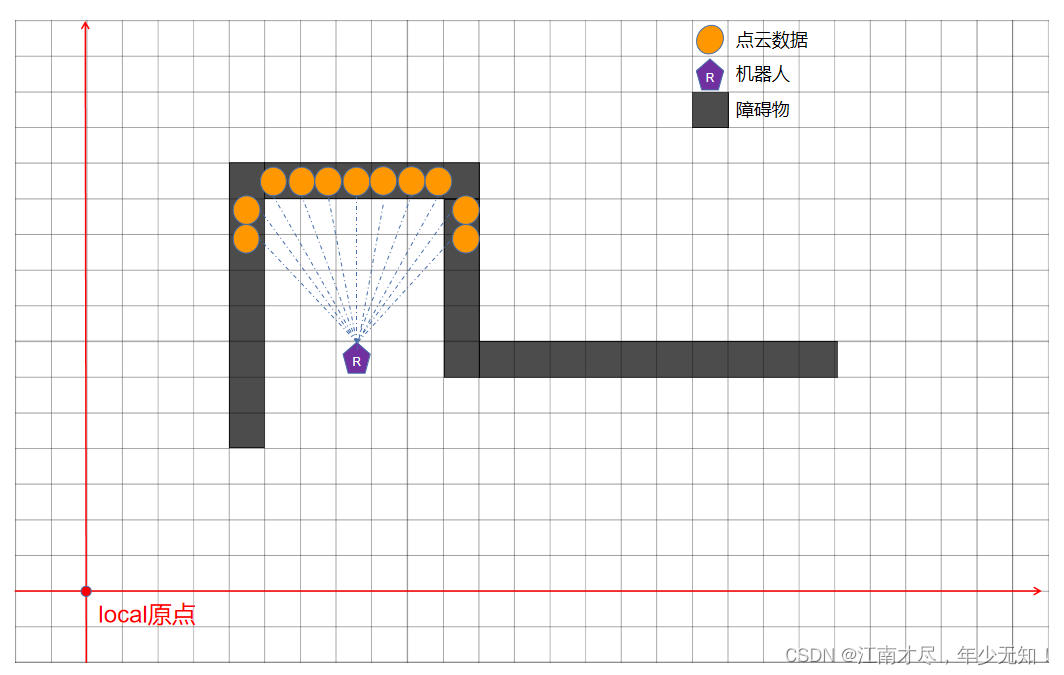
这里我们记期待的位姿为 R o b o t _ g t t r a c k i n g l o c a l \mathbf {Robot\_{gt}}^{local}_{tracking} Robot_gttrackinglocal。那么如何能让 R o b o t 3 t r a c k i n g l o c a l \mathbf {Robot3}^{local}_{tracking} Robot3trackinglocal 的位姿,逐步逼近 R o b o t _ g t t r a c k i n g l o c a l \mathbf {Robot\_{gt}}^{local}_{tracking} Robot_gttrackinglocal 呢?这个时候本人能想到的办法就是, R o b o t 3 t r a c k i n g l o c a l \mathbf {Robot3}^{local}_{tracking} Robot3trackinglocal 作为初始值,在 图3 中进行暴力相关性匹配,获得最优位姿,这里记为 R o b o t 3 _ b t t r a c k i n g l o c a l \mathbf {Robot3\_{bt}}^{local}_{tracking} Robot3_bttrackinglocal,然后再以其为初值,在 图2 中进行暴力相关性扫描匹配,获得最有位姿,记录为 R o b o t 2 _ b t t r a c k i n g l o c a l \mathbf {Robot2\_{bt}}^{local}_{tracking} Robot2_bttrackinglocal,就一直这样下去,知道获得 R o b o t 1 _ b t t r a c k i n g l o c a l \mathbf {Robot1\_{bt}}^{local}_{tracking} Robot1_bttrackinglocal,举例比较简单,只设置了三层。这样,我们就逐步逼近 R o b o t _ g t t r a c k i n g l o c a l \mathbf {Robot\_{gt}}^{local}_{tracking} Robot_gttrackinglocal 了,大致流程如下:
R o b o t 3 _ b t t r a c k i n g l o c a l → R o b o t 2 _ b t t r a c k i n g l o c a l → R o b o t 1 _ b t t r a c k i n g l o c a l → R o b o t _ g t t r a c k i n g l o c a l (01) \color{Green} \tag{01} \mathbf {Robot3\_{bt}}^{local}_{tracking} \to ~ \mathbf {Robot2\_{bt}}^{local}_{tracking} \to ~ \mathbf {Robot1\_{bt}}^{local}_{tracking} \to ~ \mathbf {Robot\_{gt}}^{local}_{tracking} Robot3_bttrackinglocal→ Robot2_bttrackinglocal→ Robot1_bttrackinglocal→ Robot_gttrackinglocal(01)很明显这种方式计算量降低了,随着图层的增加,扫描匹配是以一种线性的方式郑增加,而单独的使用暴力相关性匹配,扩大搜索范围,增加算力可以说接近于几何式。但是,该方式的缺陷也比较明显,那就是要构建很多个图层,其是十分消耗内存的,加为了扩大障碍物的面积,也需要消耗一定算力。
当然,到这里为止都是我的猜测,本人并没有分析源码,所以也无法保证源码就一定是这样做的。其叫做分支定界的原因,应该是把图层比喻成了枝干,每个图层都做一次优化,优化都是有限的,可以说是一个边界,所以称为分支定界算法,哈哈,当然,这也是我的猜测,仅作参考(实际上分支定界并非这么简易,其中涉及到很多巧妙的思想)。下面就可以正式的分析源码了。
三、核心要点
使用分支定界的算法的前提是需要存在多张不同分辨率地图,这里的分辨率,并非严格意义上图像分辨率,而是障碍物的宽度大小不一致,分别表示不同的分辨率,宽度越大表示其分辨率越低。如前面的图3就是低分辨率,图1就高分辨率。后续过程中,地图的张数称为树的深度,比如,对于初始的 grid,为其生成7张地图,则认为该树的深度就是7。
根据前面 图1、图2、图3 的变化,可以知道构建多分辨率地图的主要过程就是对被占用的像素进行加宽。源码中使用到了滑动窗口,先沿 x 轴进行滑动,增加障碍物在x轴的宽度,再沿y轴滑动,增加y障碍物在y轴的宽度 。这里还及到比较核心的一个类,那就是 SlidingWindowMaximum,其也是在 fast_correlative_scan_matcher_2d.cc 文件中实现的,其主要存在三个函数,以及一个核心成员变量 non_ascending_maxima_, 其是要给双端队列,申明如下:
class SlidingWindowMaximum {
public:
// 添加值, 会将小于填入值的其他值删掉, 再将这个值放到最后
void AddValue(const float value) {
while (!non_ascending_maxima_.empty() &&
value > non_ascending_maxima_.back()) {
non_ascending_maxima_.pop_back();
}
non_ascending_maxima_.push_back(value);
}
// 删除值, 如果第一个值等于要删除的这个值, 则将这个值删掉
void RemoveValue(const float value) {
// DCHECK for performance, since this is done for every value in the
// precomputation grid.
DCHECK(!non_ascending_maxima_.empty());
DCHECK_LE(value, non_ascending_maxima_.front());
if (value == non_ascending_maxima_.front()) {
non_ascending_maxima_.pop_front();
}
}
// 获取最大值, 因为是按照顺序存储的, 第一个值是最大的
float GetMaximum() const {
// DCHECK for performance, since this is done for every value in the
// precomputation grid.
DCHECK_GT(non_ascending_maxima_.size(), 0);
return non_ascending_maxima_.front();
}
void CheckIsEmpty() const { CHECK_EQ(non_ascending_maxima_.size(), 0); }
private:
// Maximum of the current sliding window at the front. Then the maximum of the
// remaining window that came after this values first occurrence, and so on.
std::deque<float> non_ascending_maxima_;
};
该类可以通过其 AddValue() 函数往队列 non_ascending_maxima_ 增加元素,如果传入的值为 value,其会删除掉原本队列中所有小于 value 的值。且把该值放到队列的最末端。如果想删除一个值,则调用 RemoveValue() 函数,首先保证 value 小于等于队列第一个元素。小于的话,不作任何操作,如果 value 等于等于队列第一个元素,则删除队列的第一个元素。大概就是,non_ascending_maxima_ 中不存在重复的元素,删除一个与 value 相等的元素即可。
可以通过 GetMaximum() 获得队列的最大值,本质上就是队列第一个元素,因为添加元素时,会把小于 value 的删除,保留的都是大于 value的,添加第一个元素时直接添加,添加第二个元素,如果比第一个大,则第一个就被删除,第二个元素就排到第一了。如果比第一个小,则直接排到队列的后面了,依次类推。
总的来说,non_ascending_maxima_ 添加元素是按降序,删除元素元素只会移除第一个元素(如果第一个元素与传入的值相等),也就是删除元素时,其与最大值相等,则删除该最大值。
四、PrecomputationGrid2D
通过前面的介绍,把 non_ascending_maxima_ 看作一个滑动窗口,首先来看一下 src/cartographer/cartographer/mapping/internal/2d/scan_matching/fast_correlative_scan_matcher_2d.h 文件,该文件中主要有三个类,分别为 PrecomputationGrid2D,PrecomputationGridStack2D,FastCorrelativeScanMatcher2D。从命名上很容易猜出他们的关系,PrecomputationGrid2D 表示一个分辨率的地图,那么 PrecomputationGridStack2D 中包含多个 PrecomputationGrid2D 实例,即包含多种分辨率的地图。具体细节先不讨论,直接进入到 fast_correlative_scan_matcher_2d.cc 文件,找到 PrecomputationGrid2D 的构造函数。
1、构造函数
首先构造函数需要传递的参数如下:
// 构造不同分辨率的地图
PrecomputationGrid2D::PrecomputationGrid2D(
const Grid2D& grid, const CellLimits& limits, const int width,
std::vector<float>* reusable_intermediate_grid)
: offset_(-width + 1, -width + 1),
wide_limits_(limits.num_x_cells + width - 1,
limits.num_y_cells + width - 1),
min_score_(1.f - grid.GetMaxCorrespondenceCost()), // 0.1 min_score_
max_score_(1.f - grid.GetMinCorrespondenceCost()), // 0.9 max_score_
cells_(wide_limits_.num_x_cells * wide_limits_.num_y_cells) {
CHECK_GE(width, 1);
CHECK_GE(limits.num_x_cells, 1);
CHECK_GE(limits.num_y_cells, 1);
const int stride = wide_limits_.num_x_cells;
// First we compute the maximum probability for each (x0, y) achieved in the
// span defined by x0 <= x < x0 + width.
std::vector<float>& intermediate = *reusable_intermediate_grid;
intermediate.resize(wide_limits_.num_x_cells * limits.num_y_cells);
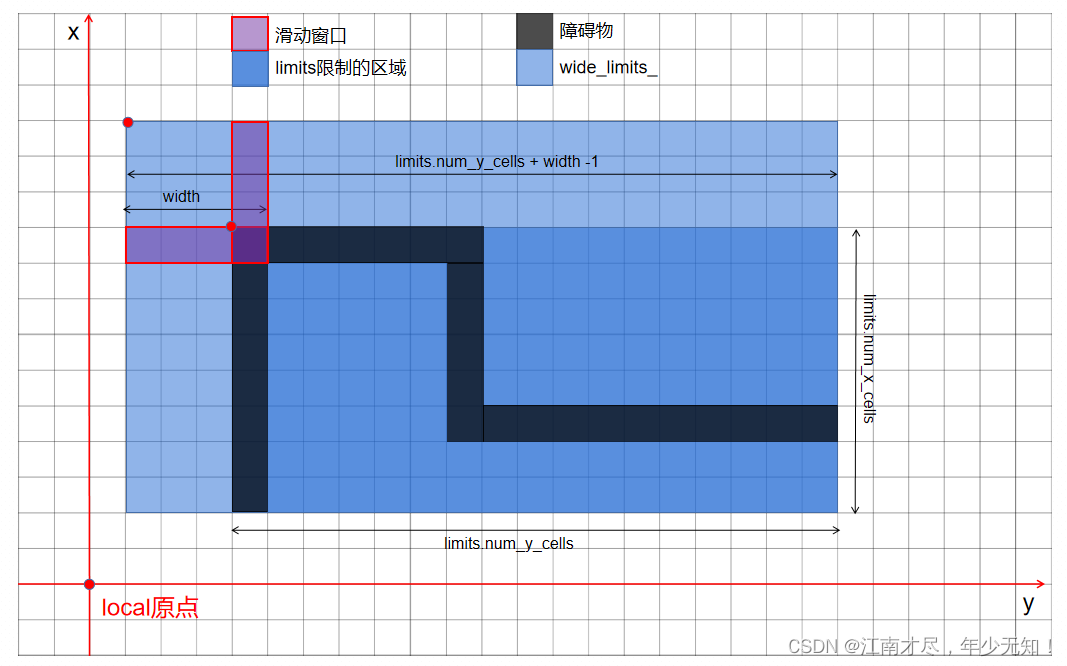
grid 主要存储的地图栅格未被占用的栅格值,limits 描述了 grid 再 local 系的位置与范围。width 需要重点关注一下,其表示滑动窗口的大小。reusable_intermediate_grid 翻译过来时被重复利用的中间 grid,具体作用后续进行分析。
为了方便理解上面的参数,所有绘画了如下图示:
首先深蓝色 limits 限制的区域就是grid对应的地图,滑动窗口大小为 width,且为了其实从左上角第一个栅格开始滑动,这里构建了一个 wide_limits_ 限制区域(深蓝加浅蓝),注意一下其时成员变量。min_score_、max_score_ 跟别表示栅格最小与最大的被占用概率。cells_ 时用于存储 wide_limits_ 对应区域的栅格值的。intermediate 大小与 wide_limits_ 一致,用于存储中间值,后面会了解到其具体作用。
2、沿x轴滑动→进地图
// 对每一行从左到右横着做一次滑窗, 将滑窗后的地图放在intermediate(临时数据)中
for (int y = 0; y != limits.num_y_cells; ++y) {
SlidingWindowMaximum current_values;
// 获取 grid 的x坐标的索引: 首先获取 (0, y)
current_values.AddValue(
1.f - std::abs(grid.GetCorrespondenceCost(Eigen::Array2i(0, y))));
// Step: 1 滑动窗口在x方向开始划入地图, 所以只进行 填入值
// intermediate的索引x + width - 1 + y * stride的范围是 [0, width-2] 再加上 y * stride
// grid的索引 x + width 的坐标范围是 [1, width-1]
for (int x = -width + 1; x != 0; ++x) {
intermediate[x + width - 1 + y * stride] = current_values.GetMaximum();
if (x + width < limits.num_x_cells) {
current_values.AddValue(1.f - std::abs(grid.GetCorrespondenceCost(
Eigen::Array2i(x + width, y))));
}
}
首先固定y轴,然后创建一个新的 SlidingWindowMaximum 实例 current_values,然后添加第一个元素,也就是上图中深蓝色区域左上角第一个栅格被占用的概率,接着就是对x轴一列一列的进行滑窗操作了。需要注意的是,每列的滑窗都是从该列的 -width + 1 处开始的,为了方便理解,把图示中栅格被占用的概率简单假设一下,如下所示:
可以很明显的看到,初始滑动窗口只有0.8一个值,所以第一次执行 intermediate[x + width - 1 + y * stride] = current_values.GetMaximum()之后, intermediate第2列(从0开始)的第1个元素就也被赋值成0.8了。执行过程大致如下:
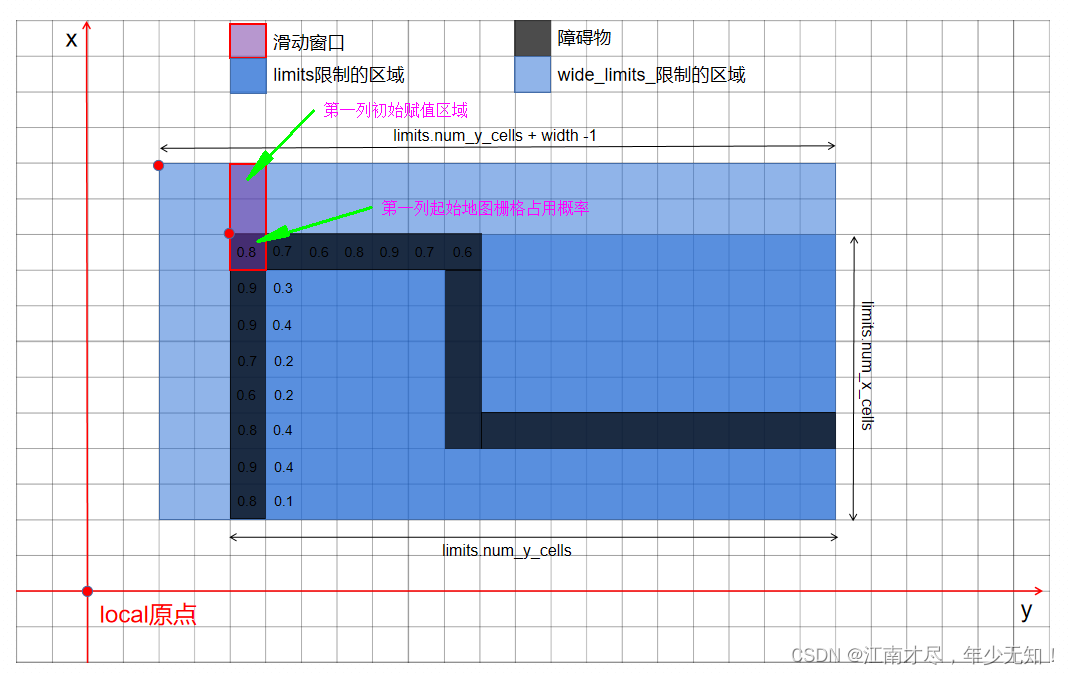
#第一执行循环 for (int x = -width + 1; x != 0; ++x) {
一列x轴数据: 0.8 0.9 0.9 0.7 0.6 0.9 0.9 0.8
初始滑窗值: 0.8 x x
intermediate存储 0.8 x x ......
添加后滑窗值 0.9 x x
#第二次执行循环 for (int x = -width + 1; x != 0; ++x) {
一列x轴数据: 0.8 0.9 0.9 0.7 0.6 0.9 0.9 0.8
初始滑窗值 0.9 x x
intermediate存储: 0.8 0.9 x ......
添加后滑窗值 0.9 0.9 x
执行两次之后,就不会执行该循环了 因为这个例子中 width=3,根据判断条件 x=2,与x=1时都会执行,当x=0时,该循环就不会被执行了。
2、沿x轴滑动→地图中间
通过上上面的操作,滑窗已经由原来的 wide_limits_ 进入到 limits 的限制区域了,如下所示:
上图中,滑动窗口右边的红色数字,才是滑动窗口存储的值。对于中间部分,对应如下代码:

// Step: 2 滑动窗口已经完全在地图里了, 滑窗进行一入一出的操作
// x + width - 1 + y * stride 的范围是 [width-1, limits.num_x_cells-2] 再加上 y * stride
// grid的索引 x + width 的坐标范围是 [width, limits.num_x_cells-width-1]
for (int x = 0; x < limits.num_x_cells - width; ++x) {
intermediate[x + width - 1 + y * stride] = current_values.GetMaximum();
current_values.RemoveValue(
1.f - std::abs(grid.GetCorrespondenceCost(Eigen::Array2i(x, y))));
current_values.AddValue(1.f - std::abs(grid.GetCorrespondenceCost(
Eigen::Array2i(x + width, y))));
}
起始和与前面的操作差不多,不过这里在往滑动窗口添加元素的时候,同时还会删除滑窗中的元素。也就是说,等到滑动窗 current_values 执行 width 次 AddValue 操作后,就开始执行删除操作了,这里同样拿上面的例子进行演示:
#第一次执行for (int x = 0; x < limits.num_x_cells - width; ++x) {
一列x轴数据: 0.8 0.9 0.9 0.7 0.6 0.9 0.9 0.8
初始滑窗值 0.9 0.9 x
intermediate存储: 0.8 0.9 0.9 ......
删除后滑窗值 0.9 0.9 x
添加后滑窗值 0.9 0.9 0.9
需要注意源码中,删除的元素是 grid.GetCorrespondenceCost(Eigen::Array2i(x, y)),添加元素的是 std::abs(grid.GetCorrespondenceCost(Eigen::Array2i(x + width, y))。可以知道 Eigen::Array2i(x, y) 与 Eigen::Array2i(x + width, y) 先隔两个坐标,即初始为 (0.9 0.9 x),删除时,传入的值为0.8,所以根据前面对 current_values.RemoveValue() 函数的分析,其不会删除任何元素。
#第二次执行for (int x = 0; x < limits.num_x_cells - width; ++x) {
一列x轴数据: 0.8 0.9 0.9 0.7 0.6 0.9 0.9 0.8
初始滑窗值 0.9 0.9 0.9
intermediate存储: 0.8 0.9 0.9 0.9 ......
删除后滑窗值 0.9 0.9 x
添加后滑窗值 0.9 0.9 0.7
按照这种规则一致执行下去,直到 x 到达 limits.num_x_cells - width 位置,此时就不会再执行了,因为接下来就要出地图了。
3、沿x轴滑动→出地图
我觉得有的朋友可能已经猜到了,出地图应该就是队列只减不增,是吧。
// Step: 3 滑动窗口正在划出, 一次减少一个值, 所以intermediate的宽度比grid多 width-1
// x + width - 1 + y * stride 的范围是 [limits.num_x_cells-1, limits.num_x_cells+width-1] 再加上 y * stride
// grid 的索引 x的范围是 [limits.num_x_cells-width, limits.num_x_cells-1]
for (int x = std::max(limits.num_x_cells - width, 0);
x != limits.num_x_cells; ++x) {
intermediate[x + width - 1 + y * stride] = current_values.GetMaximum();
current_values.RemoveValue(
1.f - std::abs(grid.GetCorrespondenceCost(Eigen::Array2i(x, y))));
}
// 理论上, 滑窗走完地图的一行之后应该是空的, 经过 只入, 一出一入, 只出, 3个步骤
current_values.CheckIsEmpty();
是的,答对了。这里就不进行演示。
4、沿y轴滑动
完成沿x轴滑动之后,就是固定x轴,沿y轴滑动了,其实代码都差不多了,这里就不在重复演示了,需要注意的是,y轴的滑窗是基于 沿 x 轴滑窗后的结果,即基于 intermediate 的。
5、注意
新构建出来的地图尚格值存储于 PrecomputationGrid2D::cells_,需要知道其先对于传入的参数 grid,其 x 与 y 轴分别增加了 width 大小的。当然,这里仅仅是构建了一张更粗分辨率的地图。还有就是 PrecomputationGrid2D::ComputeCellValue() 这个函数,其作用是把概率 概率[0.1, 0.9]转成[0, 255]之间的值。也就是说,PrecomputationGrid2D::cells_ 存储的值都缩放到了 [0, 255] 之间,且值约大,则表示被占用的可能性就越大。
五、PrecomputationGridStack2D
前面的 PrecomputationGridStack2D 虽然很核心,但是其只构建了单分辨率地图,该类才是构建多分辨率地图的关键所在,主要关心其构造函数,如下:
// 构造多分辨率地图
PrecomputationGridStack2D::PrecomputationGridStack2D(
const Grid2D& grid,
const proto::FastCorrelativeScanMatcherOptions2D& options) {
CHECK_GE(options.branch_and_bound_depth(), 1);
// param: branch_and_bound_depth 默认为7, 确定 最大的分辨率, 也就是64个栅格合成一个格子
const int max_width = 1 << (options.branch_and_bound_depth() - 1); // 64
precomputation_grids_.reserve(options.branch_and_bound_depth());
// 保存地图值
std::vector<float> reusable_intermediate_grid;
const CellLimits limits = grid.limits().cell_limits();
// 经过滑窗后产生的栅格地图会变宽, x方向最多会比原地图多max_width-1个格子
reusable_intermediate_grid.reserve((limits.num_x_cells + max_width - 1) *
limits.num_y_cells);
// 分辨率逐渐变大, i=0时就是默认分辨率0.05, i=6时, width=64,也就是64个格子合成一个值
for (int i = 0; i != options.branch_and_bound_depth(); ++i) {
const int width = 1 << i;
// 构造不同分辨率的地图 PrecomputationGrid2D
precomputation_grids_.emplace_back(grid, limits, width,
&reusable_intermediate_grid);
}
}
branch_and_bound_depth 参数默认为7,其共构建 6 个不同分辨率的地图。如下:
precomputation_grids_[0] width=1 原始地图构建的分辨率地图
precomputation_grids_[1] width=2 可以简单理解,比原始地图构建的分辨率地图
增加x,y增加2-1=1个像素,且每 2x2=4 个像素的像素值都用他们中最大的来代替(略有区别)
precomputation_grids_[2] width=4 可以简单理解,比原始地图构建的分辨率地图
增加x,y增加4-1=1个像素,且每 4x4=16 个像素的像素值都用他们中最大的来代替(略有区别)
precomputation_grids_[3] width=8 可以简单理解,比原始地图构建的分辨率地图
增加x,y增加8-1=1个像素,且每 8x8=64 个像素的像素值都用他们中最大的来代替(略有区别)
precomputation_grids_[4] width=16 可以简单理解,比原始地图构建的分辨率地图
增加x,y增加16-1=1个像素,且每 16x16=256 个像素的像素值都用他们中最大的来代替(略有区别)
precomputation_grids_[5] width=32 可以简单理解,比原始地图构建的分辨率地图
增加x,y增加32-1=1个像素,且每 32x32=1024 个像素的像素值都用他们中最大的来代替(略有区别)
precomputation_grids_[6] width=64 可以简单理解,比原始地图构建的分辨率地图
增加x,y增加64-1=1个像素,且每 64x64=4096 个像素的像素值都用他们中最大的来代替(略有区别)
也就是说,加上原始地图构建分辨率地图,那么共有7个不同分辨率的地图。precomputation_grids_ 层即越大,说明其分辨率越粗。
这样,对于PrecomputationGridStack2D构建多分辨率的过程就讲解完成了,下面就是正式讲解分支顶界算法了。