Flink项目开发实战总结
[1] 项目简介
本项目面向的对象是Flink初学者,通过模拟滴滴订单数据,实现基于Flink的流批一体系统。阅读并复现本文只要求对大数据处理平台有略微感性的认识即可。同时本文会以实际代码为引导,介绍Flink的三个关键环节:DataSource、Transformation、Sink。
当然在整个项目开发的过程中也遇到了很多问题,在本文中也都会给出解决方案。
PS:获取完整项目代码请私信联系,可把本文视为项目的操作手册与重点说明!
- 项目架构
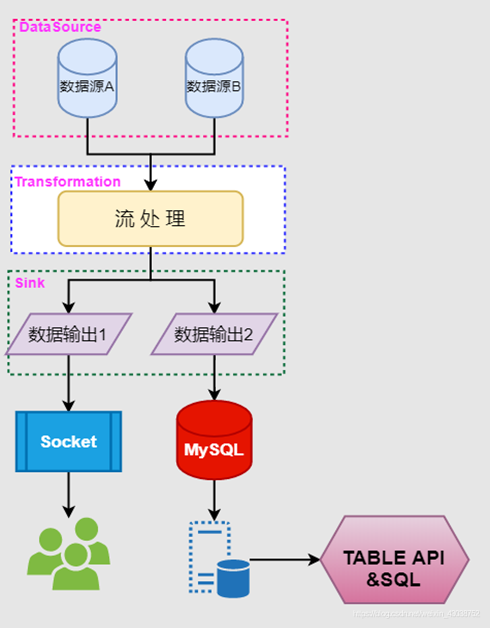
下图展示了项目的详细架构,本项目的特点如下: - 多源数据输入
- 多种流处理并行
- 多路Sink输出
- 流批一体的TABLE API & SQL
- 架构解析
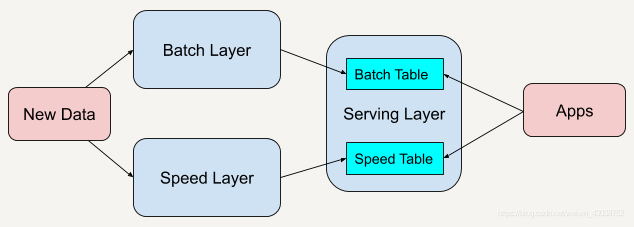
在对本架构进行介绍之前,有必要提一下大数据计算平台常见的两种架构,分别是lambda和kappa结构。
上图展示的是lambda架构。Lambda 架构总共由三层系统组成:批处理层(Batch Layer),速度处理层(Speed Layer),以及用于响应查询的服务层(Serving Layer)。在 Lambda 架构中,每层都有自己所肩负的任务。批处理层存储管理主数据集(不可变的数据集)和预先批处理计算好的视图。批处理层使用可处理大量数据的分布式处理系统预先计算结果。它通过处理所有的已有历史数据来实现数据的准确性。这意味着它是基于完整的数据集来重新计算的,能够修复任何错误,然后更新现有的数据视图。输出通常存储在只读数据库中,更新则完全取代现有的预先计算好的视图。速度处理层会实时处理新来的大数据。速度层通过提供最新数据的实时视图来最小化延迟。速度层所生成的数据视图可能不如批处理层最终生成的视图那样准确或完整,但它们几乎在收到数据后立即可用。而当同样的数据在批处理层处理完成后,在速度层的数据就可以被替代掉了。
使用 Lambda 架构时,架构师需要维护两个复杂的分布式系统,并且保证他们逻辑上产生相同的结果输出到服务层中。
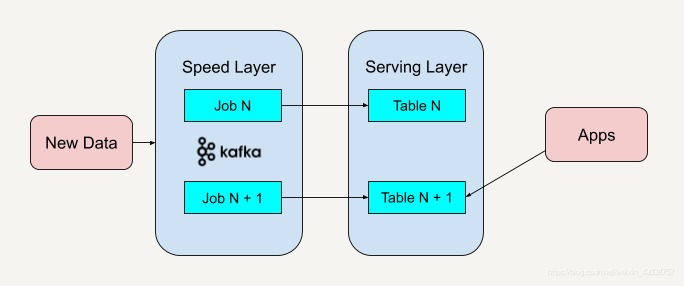
能不能改进 Lambda 架构中的速度层,使它既能够进行实时数据处理,同时也有能力在业务逻辑更新的情况下重新处理以前处理过的历史数据呢?像 Apache Kafka 这样的流处理平台是具有永久保存数据日志的功能的,通过平台的这一特性,可以重新处理部署于速度层架构中的历史数据。这是借助其他组件做到的这一步。
对于Flink来说,它完全可以实现lambda架构;同时Flink社区现在在对TABLE API和SQL的发展使得其实现kappa架构也很简单。
在本项目中,不仅有多源的数据输入(其中包括Kafka消息系统),多种流处理的方式,还有实时可视化展示(流的展示)、以及流的持久化和批量数据处理(TABLE API & SQL)。在这里你讲看到在实际业务场景中遇到的多种情况。以下进行分点详细介绍:
[2] Flink的数据源
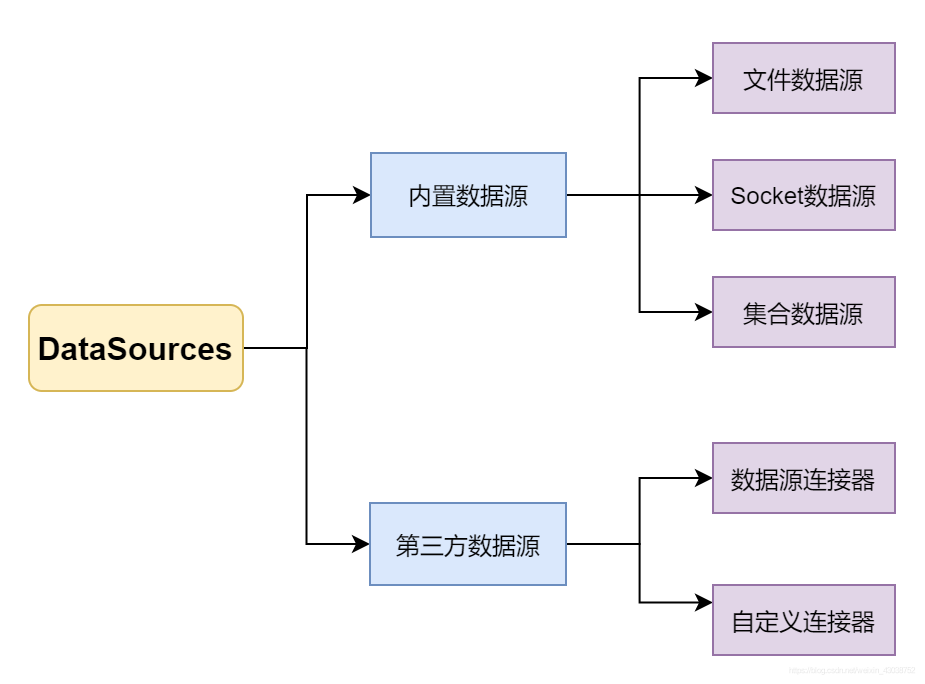
Flink的DataSource模块定义了DataStream API的数据输入操作,其实我们可以概略的把数据源分为内置数据源和第三方数据源。
从文件中读取数据源是比较常见的操作,Flink支持从文件中读取数据并以流的形式抛出;Socket是指Flink可以从指定的套接字读取数据,这在实际的工程上是比较常见的,但是往往会被Kafka组件的功能覆盖;集合数据源主要是用以调试本地的Flink应用,使用fromElements方法创建DataStream数据集。
第三方数据源往往是我们需要重点关注的技术,简而言之就是从HDFS、数据库(如ES、Mysql)、消息系统(如Kafka)等数据源中获取流数据。之所以称之为第三方数据源,主要是本身数据产生部件也是一个相对独立的部分。当然对于一些极为特殊的连接器,可以通过自定义的方法实现,这里不再详细介绍。
回到本项目,由于要验证多源流数据的机制,所以主要是采用了两种方法:
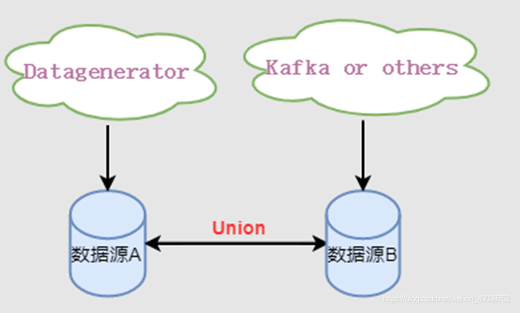
(1)基于类的流数据产生:
//产生订单数据 Orders 并充当数据源
public class Data_Source implements SourceFunction<OrdersDD> {
/*重写下面两个方法*/
private volatile boolean running = true;
@Override
public void run(SourceContext<OrdersDD> sourceContext) throws Exception {
long id = 0;
while (running){
OrdersDD one_data = new OrdersDD(id + 1);
//系统时间概念为事件时间的时候必须指定Timestamp和watermark
//sourceContext.collect(one_data);
sourceContext.collectWithTimestamp(one_data,one_data.getEventTime());
sourceContext.emitWatermark(new Watermark(id - 1L));
//产生数据进程休眠时间,决定了数据流的速度
Thread.sleep(6000);
id = id + 1L;
}
}
@Override
public void cancel() { running = false;}
}
简单说明一下,这里定义了一个模拟的滴滴订单数据POJO类OrdersDD。实现了一个叫做Data_Source的类的run方法,使用sourceContext.collectWithTimestamp方法向后抛出一个带有事件时间的一条数据(也就是一个订单数据)。
ok,接下来就是在流处理开端将其作为数据源了。
// 数据开始产生,使用的数据源是自动生成的,Data_Source对象伪造了数据
DataStreamSource<OrdersDD> orders = env.addSource(new Data_Source());
这是一种模拟的数据手段,在开发与测试时非常有用,它类似于上述数据源中的集合方法。不过,接下来介绍的这种方法实际上更加常见。
(2)基于kafka的流数据产生:
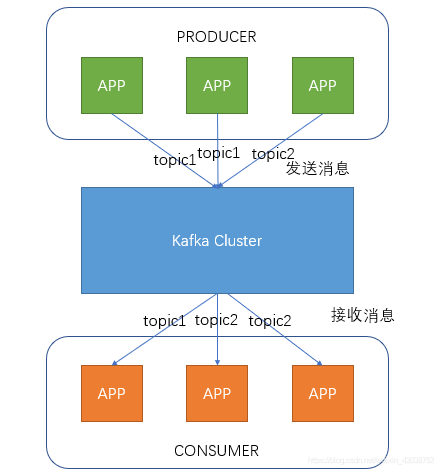
kafka的架构是典型的消费者—订阅者机制:
在kafka中主要是生产者(producer)、抽象的话题(Topic)和消费者(consumer)三个角色。关于kafka的搭建不在这里介绍(建议在开发时在单机上进行)。回到本项目:
- 生产者
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
// 2.0 配置 kafkaProducer
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<String>(
"127.0.0.1:9092", //broker列表
"XXX", //topic
(SerializationSchema<String>) new SimpleStringSchema()); // 消息序列化
//写入Kafka时附加记录的事件时间戳
producer.setWriteTimestampToKafka(true);
生产者需要配置的代理(setProperty),和一些关键的信息,写代码的时候可以将之作为一个模版来用。这里需要注意序列化的操作,指在消息进入Kafka之后数据格式的保留,比如当往kafka中塞一个数组或者一个pojo的类(这是很典型的),就需要按照对应的数据格式进行序列化。Kafka提供了复杂数据结构的序列化方法。
在Kafka中可以使用Avro机制。Avro是一种序列化框架,使用JSON来定义schema,shcema由原始类型(null,boolean,int,long,float,double,bytes,string)和复杂类型(record,enum,array,map,union,fixed)组成,schema文件以.avsc结尾,表示avro schema,有2种序列化方式
- 二进制方式:也就是Specific方式,定义好schema asvc文件后,使用编译器(avro-tools.jar)编译生成相关语言(java)的业务类,类中会嵌入JSON schema
- JSON方式:也就是Generic方式,在代码中动态加载schema asvc文件,将FieldName - FieldValue,以Map<K,V>的方式存储
须知,在序列化之后,模式和数据是并存的,这样在消费者获得数据之后就可以进行解析了。如下图所示:

- 消费者
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "127.0.0.1:9092");
properties.setProperty("group.id", "group_test");
properties.setProperty(FlinkKafkaConsumerBase.KEY_PARTITION_DISCOVERY_INTERVAL_MILLIS, "10");
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>("lsh", new SimpleStringSchema(), properties);
消费者部分的代码编写也是相对固定的,可以参考上面的代码。
//设置从最早的offset消费
//consumer.setStartFromEarliest();
//设置从最新的offset消费
consumer.setStartFromLatest();
以上代码是对从topic读取消息的时序进行规定。
DataStream<Tuple2<String, Long>> tuples_from_kafka = env.addSource(consumer).map(new MapFunction<String, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> map(String value) {
JSONObject jo = new JSONObject(value.replaceFirst("Orders","").replaceAll("=",":"));
return Tuple2.of(jo.get("driverId").toString(),1L) ;
}});
需要对从kafka读出来消息需要进行反序列化。但是要知道对于复杂的数据类型,即便是使用arvo机制,序列化与反序列化的操作也是繁复的。在生产者的部分,使用了最简单的字符串数据类型进行序列化,但是消费者的读取就比较被动,这里取巧将字符串转换为JSON对象,野路子大家可以参考一下。
[3] Flink的流处理
Flink有着完备的流处理方法(Transformation),其实和Spark、Storm等也比较类似,但是比Hadoop单纯的Map和Reduce更加便捷和丰富。在这里,将简要介绍基本的流处理,侧重介绍Flink的时间窗口机制。
(1)Flink的基本流处理方法:
//对流的第三种 transform
DataStream<OrdersDD> oreders_filter= orders.filter(new FilterFunction<OrdersDD>() {
@Override
public boolean filter(OrdersDD ordersDD) throws Exception {
//假定乘客数量大于等于3人为过载
return ordersDD.passengerCnt >= 3;
}
});
DataStream<Tuple2<Long, Integer>> tuples3 = oreders_filter.map(new MapFunction<OrdersDD, Tuple2<Long, Integer>>() {
@Override
public Tuple2<Long, Integer> map(OrdersDD ride1) {
return Tuple2.of(ride1.driverId, (ride1.passengerCnt-2));
}
});
KeyedStream<Tuple2<Long, Integer>, Long> keyedByPass = tuples3.keyBy(t -> t.f0);
// sum计数
DataStream<Tuple2<Long, Integer>> OverLoadCounts = keyedByPass.sum(1);
//输出数据模式
DataStream<String> passenger_final = OverLoadCounts.map(r -> r.toString());
先贴一段代码感受一下,Flink的流操作用起来十分简单。下面分点进行介绍:
- map
Map函数实现了对流数据中的每一个数据的清洗或者转换的作用,比如上述过程就将一个多个属性项的数据记录(OrdersDD)转换为一个Tuple2(这种数据结构是Flink中特有的)。Map函数可以在内部实现一个MapFunction函数,完成自定义的map操作。 - filter
filter算子可以按照条件对输入数据集进行筛选操作,内部通过实现一个FilterFunction函数进行,一般来说,过滤不改变数据的结构。 - keyBy
该算子可以按照指定的Key将输入的DataStream格式转换为KeyedStream,也就是在数据集中执行Partition操作。在集群上实际运行Flink应用时,这是提供并行化的主要一环。 - sum
sum是一个聚合(Aggregations)的操作,目前聚合包含了许多封装的操作,比如sum、min、max等,当然用户也可以定制指定的聚合操作。深入的方法不再进行介绍。
(2)Flink基于时间的窗口计算:
对于流数据处理,最大的特点就是数据具有时间上的属性。其实Spark、Storm等也都支持窗口计算。但是Flink的时概念和watermark更加有体系,为保证exactly once的机制提供了最基本的保证。
- Flink的几种时间概念
Flink根据时间产生的位置不同,将时间分为事件生成时间(Event time)、事件接入时间(Ingestion time)和事件处理时间(Processing time)。事件生成时间是每个独立事件在产生它的设备上发生的时间,需要显式的指明数据中的时间。其他的时间不必过多的关注。
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
在Flink中默认使用的是Process Time的时间,如果需要使用事件时间,需要指定应用使用的时间为EventTime,如上所示。
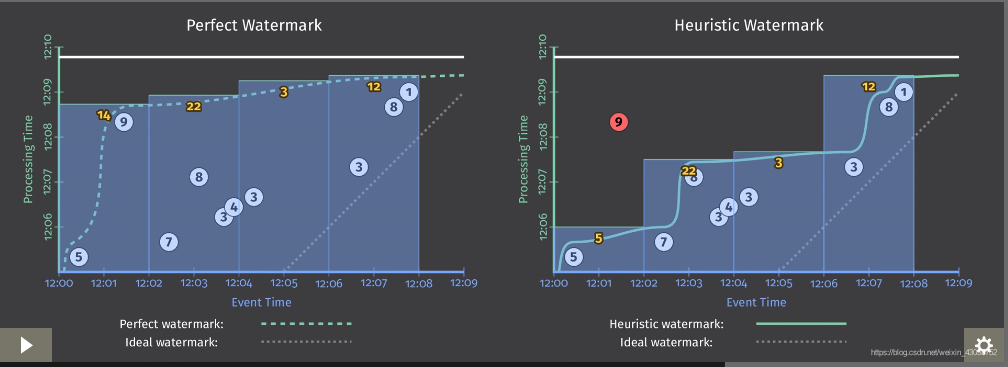
- 水位线(Watermark)的意义
watermark是用于处理乱序事件的,而正确的处理乱序事件,通常用watermark机制结合window来实现。我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的。虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、背压等原因,导致乱序的产生(out-of-order或者说late element)。但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark。如下图解释了其原理:
- 窗口的技术
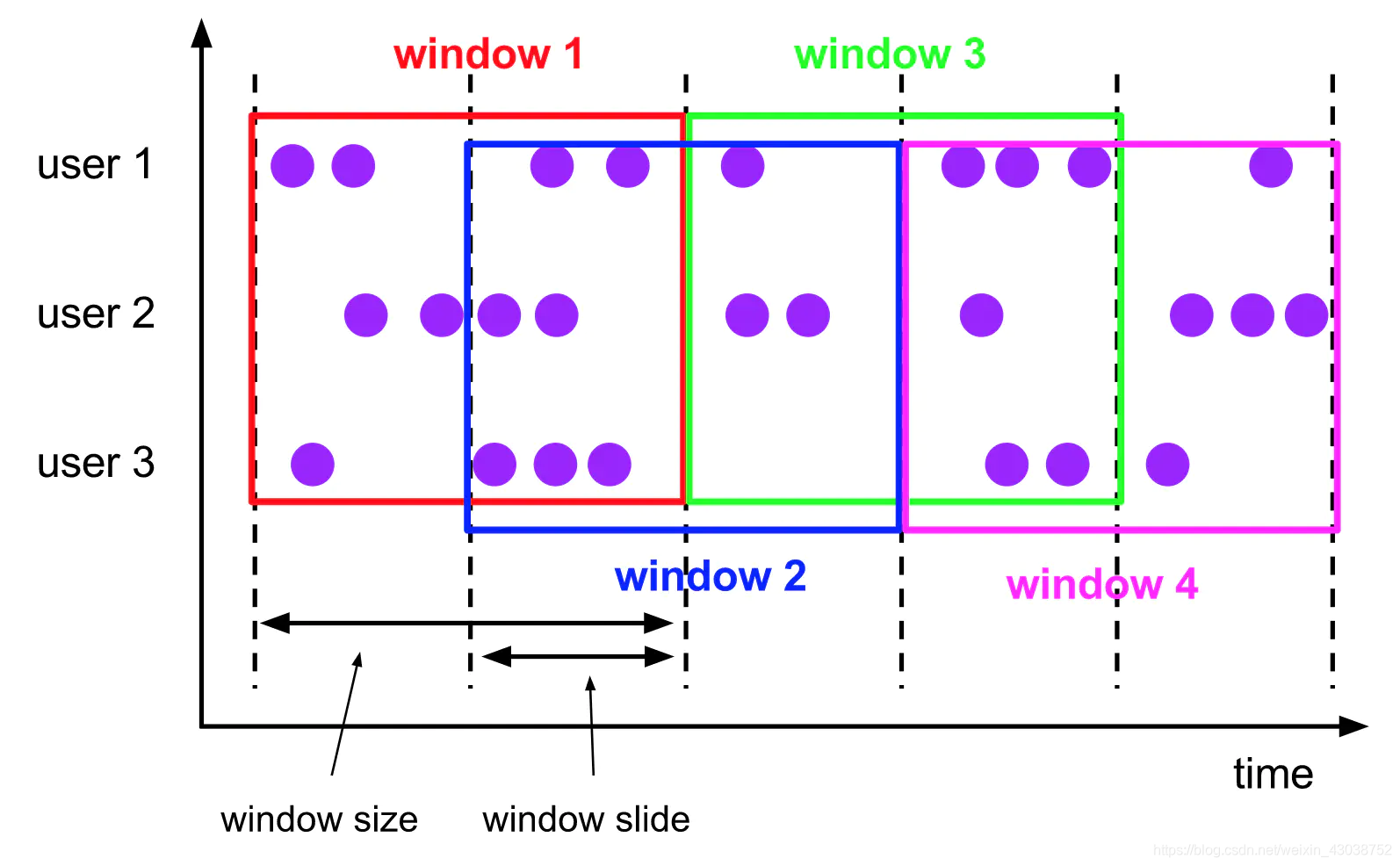
接下来就是最重要的窗口技术了。窗口技术就是按照固定的时间或者长度将数据流切分为不同的窗口,对窗口内的数据进行聚合运算,从而得到一定时间范围内的统计结果。
对于窗口计算,有两个组成部分是必须的,一者是窗口分配器类型(Windows Assigner),二者是计算算子(Windows Function)。同时,对于Windows Assigner而言,Flink需要判断上游数据集是不是KeyedStream类型(也就是有没有执行keyBy操作),如果是,那么需要执行的是window()方法指定分配器,否则执行的是windowsAll()来指定分配器。而Windows Assigner又分为2种,基于时间的窗口(TimeWindows)和基于数量的窗口(countWindows)。
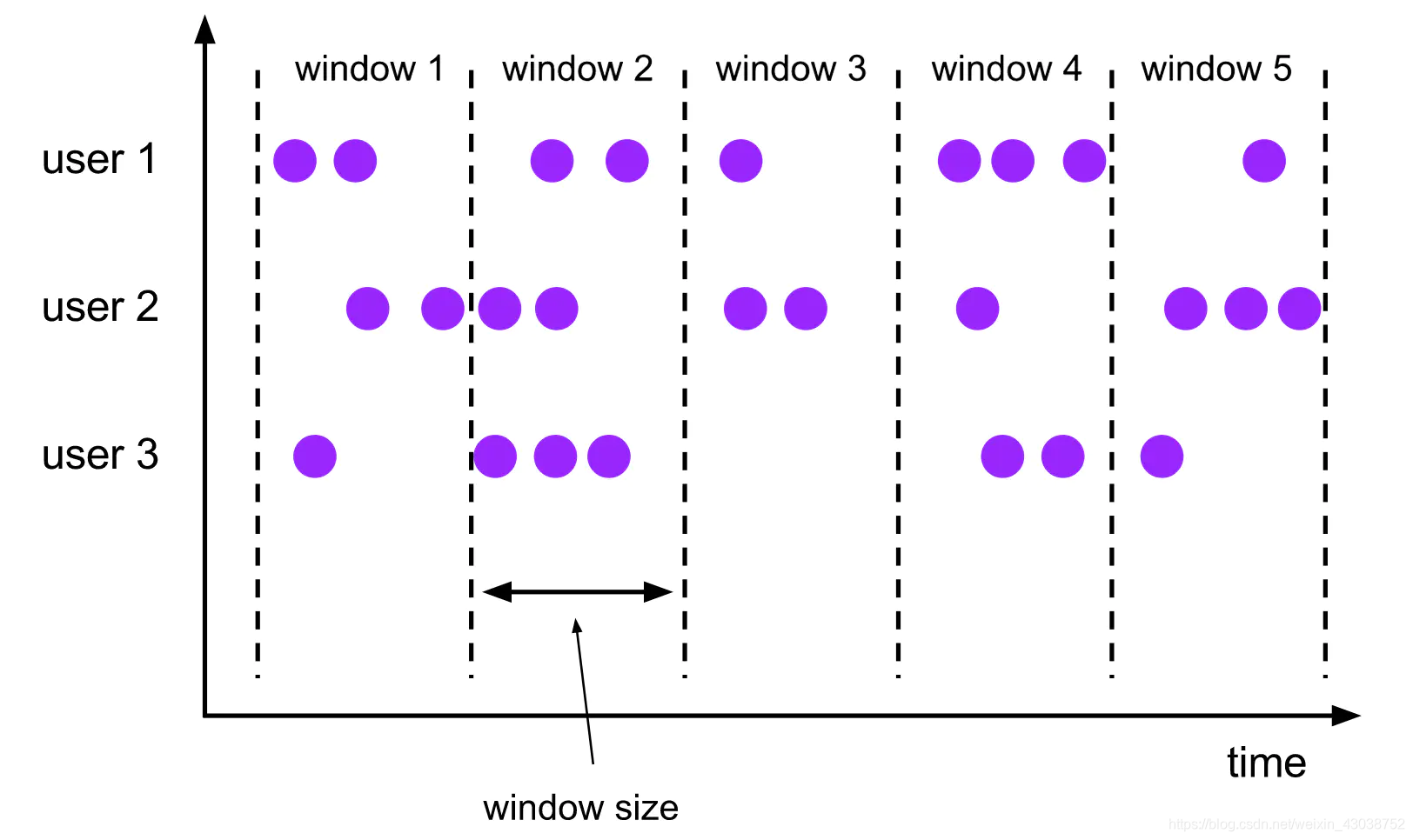
基于数量的窗口比较好理解,对于基于时间的窗口,根据Windows Assigner的不同,分为4大类,包括滚动窗口(Tumbling Windows)、滑动窗口(Sliding Windows)、会话窗口(Session Windows)、全局窗口(Global Windows),当然也可以通过继承WindowAssigner类来自定义窗口。这里主要介绍滚动窗口和滑动窗口:
滚动窗口是根据固定时间或者大小进行切分,且窗口和窗口之间的元素互不重叠,这对周期性数据统计计算比较合适,但是对于数据的前后之间存在相关性的则不太好。
滑动窗口是根据固定时间或者大小进行切分,但是在滚动窗口的基础上增加了窗口的滑动时间(Slide time),多引入一个参数之后就会带来窗口数据的重叠。接下来我们看代码:
SingleOutputStreamOperator<String> fare = kk
.keyBy(t -> t.f0)
// .countWindow(3).sum(1).map(r->r.toString()); //基于数量的窗口
.timeWindow(Time.milliseconds(5)) //滚动窗口
//.timeWindow(Time.seconds(20),Time.seconds(10)) //滑动窗口
//.timeWindow(Time.milliseconds(6),Time.milliseconds(2)) //滑动窗口
.sum(1)
.map(r -> r.toString());
如代码所示,这里对基于数量和基于时间的窗口计算都进行尝试。由于是模拟数据,所以这里给每个订单的事件时间是orderId,是单调递增的,不重复的(事实上这是一种很好的事件事件指定方法,在没有明显现实意义上的时间时,序号也是可以的)。这就导致了在使用Time.seconds()时发现总也没有结果,其实可以看出timewindow的参数是Time格式的,但是在要求显式指定事件时间的时候,要求的数据类型是long型:
//默认事件的时间是开始时间,返回long型时间
public Long getEventTime() { return rideId; }
格式的不对应,翻看源码可以很好的解决(在TumblingEventTimeWindows.class里):
public static TumblingEventTimeWindows of(Time size, Time offset) {
return new TumblingEventTimeWindows(size.toMilliseconds(), offset.toMilliseconds());
}
可以看到所有的时间都转换为毫秒数(long型),所以当使用Time.seconds()再转换为毫秒之后,窗口的大小太大,短时间内看不到效果。
接下来必须要对WaterMark进行介绍,因为它很重要:
sourceContext.emitWatermark(new Watermark(id - 1L));
//产生数据进程休眠时间,决定了数据流的速度
Thread.sleep(6000);
id = id + 1L;
在产生数据的时候就需要使用emitWatermark进行水位线约束:它指定的含义是这一个消息之后最晚到达的时间。
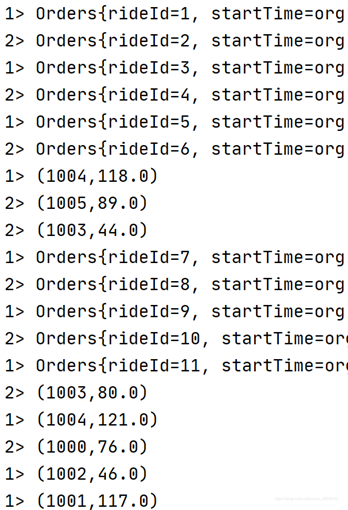
当使用滑动窗口为5、水位线由上面代码指定的时候,如下图所示结果:
如果你能看懂上述结果出现的原因,那你就理解了这个机制。提示一下,窗口大小为5,那么取值范围就是[0, 4.999]。不懂可以私信一起交流。
[4] Flink的Sink
经过各种数据的Transformation操作之后,最终形成用户需要的结果数据集。通常情况下,用户希望数据输出到外部介质或者下游的消息中间件中去,那么这就是Flink的DataSink操作。在Flink定义的第三方外部系统连机器中,支持Kafka、Cassandra、ES等,其实也可以输出到文件、Socket等。本项目采用的方法有到Socket和到远程数据库Mysql。
(1)写入Socket
Flink写到Socket并不是一个很常见的操作。但是在本项目中由于前端实时可视化的需要,采用了这种方法。先看代码:
//输出数据模式
DataStream<String> passenger_final = OverLoadCounts.map(r -> r.toString());
//序列化并写入端口65532
SerializationSchema<String> schema3 = new TypeInformationSerializationSchema<String>(Types.STRING, env.getConfig());
passenger_final.writeToSocket("127.0.0.1", 65532, schema3);
写入到端口使用的方法是writeToSocket():
@PublicEvolving
public DataStreamSink<T> writeToSocket(String hostName, int port, SerializationSchema<T> schema) {
DataStreamSink<T> returnStream = this.addSink(new SocketClientSink(hostName, port, schema, 0));
returnStream.setParallelism(1);
return returnStream;
}
很简单,只需要提供目标的hostname、port组成套接字即可,比较重要的是Schema这个参数。还记得在前面介绍Kafka时候序列化和反序列化的机制,这里也是一样,使用默认的序列化与反序列化机制,那么发送到端口的数据是字节流的形式,还原困难。所以这里使用map函数全部转换为String格式,而后使用TypeInformationSerializationSchema()方法完成序列化!
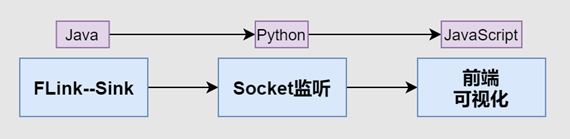
ok,现在有了写入端口的发送方,为了达到实时计算而可视化的目的,必须有从端口获取的接收方。这里我用了python的Socket库进行端口监听:
import socket,json
s1 = socket.socket() #创建套接字
s1.bind(('127.0.0.1',65532))
s1.listen(4)
#接收数据
conn1, add1 = s1.accept()
res = {}
res['order']={}
while(True):
d1 = conn1.recv(10000)
print(d1)
if len(d1)>15:
d1 = str(d1,encoding='utf-8').replace("\t","").replace("\n","").replace("\x0b",'').split(')(')
d10 = d1[0].replace("(","").split(',')
d11 = d1[1].replace(")", "").split(',')
res['order'][d10[0]] = d10[1]
res['order'][d11[0]] = d11[1]
else:
d1 = str(d1,encoding='utf-8').lstrip("\t(").lstrip("\n(").lstrip("\x0b(").rstrip(")").split(',')
res['order'][d1[0]] = d1[1]
print(res)
with open('data.json',mode='w',encoding='utf-8') as f:
json.dump(res,f)
在while死循环中对端口进行轮询,获取端口的数据进行进一步的操作,实际操作中会发现,端口中获取的数据中会有“\t”、“\n”等字符,这个问题我目前并没有找到具体的原因,不排除流数据的每个数据项之间的分隔符为这些特殊字符。
注意在启动程序时,先启动python的监听端,而后启动Flink应用。
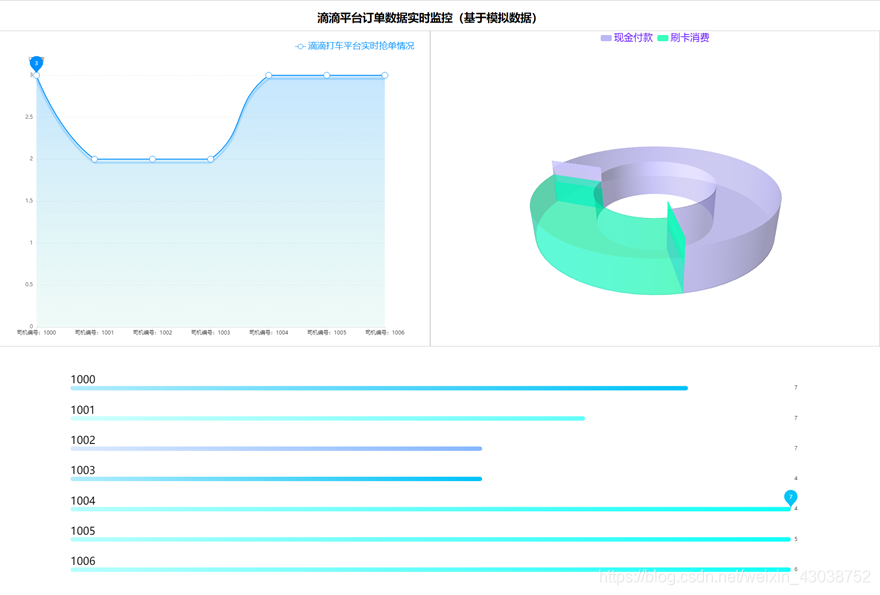
实时计算数据在前端进行展示:
前端做的比较简单,这里可以给大家提供几个好的技术方法:
- Vue.js + DB
- socket.js
- ajax + File
具体的技术细节不再过多介绍。
(2)持久化到远程mysql
将流数据实时写入mysql是一种持久化的手段,我的mysql安装在阿里云个人主机上。所以属于远程数据写入:
持久化写入到远程数据库
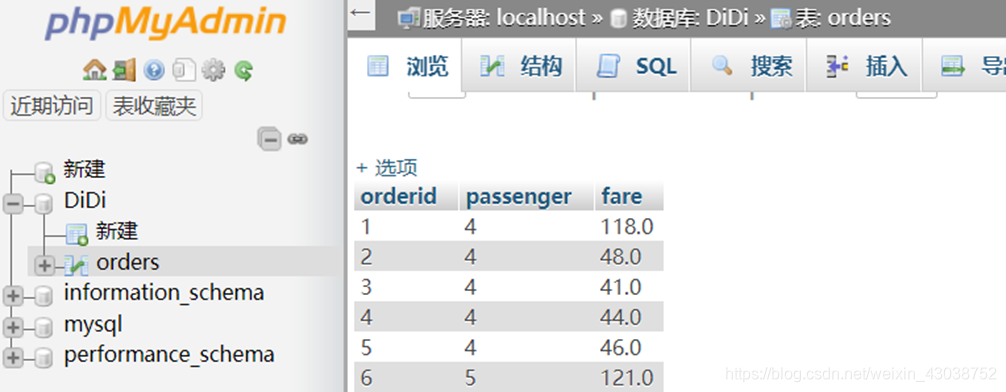
//sink到 mysql,持久化流数据
//env.enableCheckpointing(500L);//这一句不是必须的
SingleOutputStreamOperator<Row> rows = orders.map((MapFunction<OrdersDD, Row>) item -> {
Row row =new Row(3);//必须是这种格式
row.setField(0,String.valueOf(item.rideId));
row.setField(1,String.valueOf(item.passengerCnt));
row.setField(2,String.valueOf(item.fare));
return row;
});
rows.print();
String query = "INSERT INTO DiDi.orders (orderid,passenger,fare) VALUES (?,?,?)"; //问题点
JDBCOutputFormat jdbcOutput = JDBCOutputFormat.buildJDBCOutputFormat()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://1X3.XX.87.XX:33X6/DiDi")
.setQuery(query)
.setUsername("uXerX1")
.setPassword("1X3")
.setSqlTypes(new int[] { java.sql.Types.VARCHAR, java.sql.Types.VARCHAR, java.sql.Types.VARCHAR}) //问题点
.setBatchInterval(2) //问题点
.finish();
rows.writeUsingOutputFormat(jdbcOutput);
上述代码展示了写入mysql数据库的范式,query这个字符串指定了操作mysql的方式,一般写入数据库的都是类似。
首先指定SingleOutputStreamOperator < Row> 格式的数据,因为写入mysql必须转换为这种格式。JDBCOutputFormat.buildJDBCOutputFormat()后跟的属性是很多,主要是固定的范式。下面这个是值得注意的地方:
.setBatchInterval(2)
流数据写到远程数据库最开始出现写不进去的问题,排查之后发现是反压机制:流数据速度大于mysql接受数据的数据,原因是mysql是远程,受限于网络和mysql本身性能,很容易出现反压机制。
[5] 批处理架构的设计方案
Flink提供了丰富的Table API & SQL的编程接口,这是一种可以统一批处理和流处理的接口。先看代码,如下:
//数据库各个字段属性的声明
TypeInformation[] fieldTypes = new TypeInformation[] { BasicTypeInfo.STRING_TYPE_INFO, BasicTypeInfo.STRING_TYPE_INFO,BasicTypeInfo.STRING_TYPE_INFO };
String[] fieldNames = new String[] { "orderid", "passenger","fare" };
RowTypeInfo rowTypeInfo = new RowTypeInfo(fieldTypes, fieldNames);
//初始化环境并获得数据库数据
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
JDBCInputFormat jdbcInputFormat = JDBCInputFormat.buildJDBCInputFormat()
.setDrivername("com.mysql.jdbc.Driver")
.setDBUrl("jdbc:mysql://1X3.XX.87.XX:33X6/DiDi")
.setUsername("uXerX1").setPassword("1X3")
.setQuery("select orderid,passenger,fare from orders ")
.setRowTypeInfo(rowTypeInfo)
.finish();
DataSource<Row> s = env.createInput(jdbcInputFormat);
s.print();
//转变为Table数据
BatchTableEnvironment tableEnv = BatchTableEnvironment.create(env);
Table table = tableEnv.fromDataSet(s);
tableEnv.registerTable("Didi_orders",table);
//执行sql查询
Table result = tableEnv.sqlQuery("select fare from Didi_orders where passenger = '5'");
System.out.print("========print the result of my sqlquery=========");
tableEnv.toDataSet(result,Row.class).print();
代码实现的是从远程mysql数据库中获取批量数据,进行简单的sql查询的操作。对于流数据和批量数据,创建TableEnviroment的方式也有所不同。使用tableEnv.sqlQuery执行sql查询语句。
Table API & SQL有很多高级用法,本文作为Flink初级入门不再过多介绍。但是,一个趋势是flink正在试图通过Table API & SQL构建真正意义上的流批一体。读者掌握这一部分内容很重要。前面介绍了lambda的处理平台架构,如果你试图将Flink单纯的作为一个流处理的组件,其实也是没有问题的,批处理可以使用hadoop、Spark等来进行。
[6] 常见问题
- 80%的问题是版本不一致导致的,因此版本控制十分重要,包括Flink和其他组件的版本对应关系;
- 其他组件的安装与使用,如kafka等,先测试好每一个组件再做集成;
- 提交集群时代码需要做部分改动;
解决这些的关键法宝就是Flink中文手册【Link】和Flink中文社区【Link】~
当然,你也可以选择向我提问!
[7] 总结
Flink是现有的比较可用的大数据实时计算平台,已经在各大厂的实际业务中使用了。本文针对Flink的初学者,试图提供一个很容易上手的全流程项目。在文中只是引用了部分代码,完整代码,私信必回,免费提供读者交流。建议拿到完整代码后再看本文,你会体会更加深刻!
本文中的一些表述可能并不那么准确,一切以Flink官方文档为准!
欢迎大家交流指正!可私信交流~
2021年2月1日 仅以此博客纪念那个回不去家的年