需求:
- 选择一个最简单的细分方向,初步了解AI图像识别的训练、测试过程
- TensorFlow、PyTorch、c,三种代码方案,先从TensorFlow入手
- 探讨最基本问题的优化问题
总结:
- 基于TensorFlow的python代码库自带了mnist 训练数据集、测试数据集。避免了自己去收集图像、标注的问题。
- 利用chatgpt逐步完善代码,输出图像(字符方式、bmp方式)辅助分析
- x为0-9的图像、y为对应数字标签0-9,train训练集60000个,test测试集10000个
- 实际测试结果能达到98%成功识别率,但是剩下的2%错得也很离谱,有优化的空间。
- 每次训练、测试的结果,存在差别,并不是完全一样的结果,TensorFlow算法中可能存在随机数
- 测试失败的数字2中,部分与训练集比较类似,直观看起来不应该失败
代码和注释
# 环境: 20241030 win10 vs2022 python3.9.13
# 安装tensorflow: pip install tensorflow
# vs2022时,在 C:\Program Files (x86)\Microsoft Visual Studio\Shared\Python39_64\Scripts 下运行
import os
import numpy as np
import PIL.Image as Image
# 显示图像
#import matplotlib.pyplot as plt
# oneDNN: Intel 推出的一款深度学习性能优化库,可以加速深度学习计算。
# 1启用/0禁用 oneDNN 优化
os.environ['TF_ENABLE_ONEDNN_OPTS'] = '1'
# 第一次import tensorflow耗时较长
import tensorflow as tf
from tensorflow.keras import layers, models
# 检查GPU是否可用
print("Num GPUs Available: ", len(tf.config.list_physical_devices('GPU')))
def display_mnist_image_console(image):
# 设置字符映射,空格代表最暗,#代表最亮
chars = " .:-=+*#%@"
# 归一化图像到0-9的整数范围
normalized_image = (image / 255 * (len(chars) - 1)).astype(int)
# 使用字符映射显示图像
for row in normalized_image:
print("".join(chars[pixel] for pixel in row))
def save_mnist_image_as_bmp(image, filename="1.bmp"):
"""
将MNIST图像保存为BMP格式
Args:
image: MNIST图像数据,形状为(28, 28)
filename: 保存的文件名
"""
# 确保图像数据在0-255范围内
image = np.clip(image, 0, 255).astype(np.uint8)
# 将图像数据转换为PIL Image对象
img = Image.fromarray(image, 'L') # 'L'表示灰度图像
# 保存图像
img.save(filename)
# 定义MNIST数据集的下载地址
mnist_url = "https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz"
# 检查本地是否存在MNIST数据集文件
data_dir = os.path.dirname(os.path.abspath(__file__))
data_file = os.path.join(data_dir, "mnist.npz")
if not os.path.exists(data_file):
print(f"本地未找到MNIST数据集,正在从 {mnist_url} 下载...")
# 使用tensorflow自带的下载函数下载数据集
tf.keras.utils.get_file(filename="mnist.npz", origin=mnist_url, extract=True)
else:
print(f"本地已存在MNIST数据集,将使用本地文件 {data_file}")
# 加载MNIST数据集
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()
x_test_original = x_test.copy() # 创建 x_test 的备份
# 下载mnist.npz文件,解压后是x_train.npy x_test.npy等4个文件
# .npy 文件是 NumPy(Numerical Python)的一种自描述二进制文件格式。
# 输出数据集基本信息
# x图像、y标签,train训练集60000个,test测试集10000个
print(f"训练集图像形状:{x_train.shape},数据类型{x_train.dtype};标签形状:{y_train.shape},数据类型{y_train.dtype}")
print(f"测试集图像形状:{x_test.shape},数据类型{x_test.dtype};标签形状:{y_test.shape},数据类型{y_test.dtype}")
# 输出更多详细信息
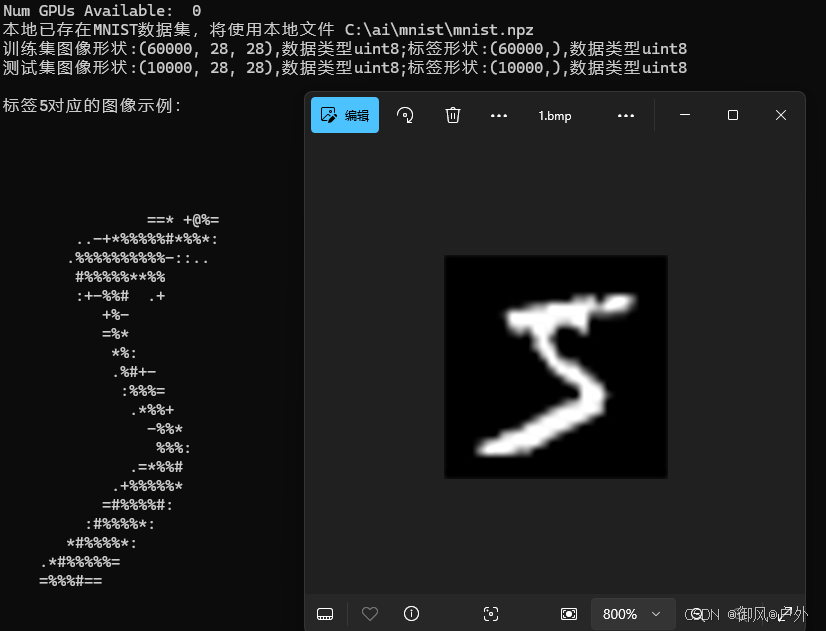
print(f"\n标签{y_train[0]}对应的图像示例:")
#print(x_train[0]) # 这个图像示例是数字5的28*28的灰度图
display_mnist_image_console(x_train[0])
save_mnist_image_as_bmp(x_train[0])
# 输出图像的最小值和最大值
print(f"\n训练集图像像素值的最小值:{np.min(x_train)};最大值:{np.max(x_train)}") # 0 - 255
# x图像 归一化
x_train, x_test = x_train / 255.0, x_test / 255.0
# 定义一个简单的CNN模型
model = models.Sequential([ # Sequential: 创建一个顺序模型,即神经网络的层按顺序堆叠。
layers.Flatten(input_shape=(28, 28)), # Flatten: 将输入的 28x28 的二维图像展平为一维向量,以便输入到全连接层。
layers.Dense(128, activation='relu'), # Dense: 全连接层,神经元之间全连接。128: 输出神经元的数量,即隐藏层的神经元数量。activation='relu': 使用 ReLU 作为激活函数,引入非线性。
layers.Dropout(0.2), # Dropout 层,随机丢弃部分神经元,防止过拟合。每次训练时,随机丢弃 20% 的神经元。
layers.Dense(10, activation='softmax') # Dense(10, activation='softmax'): 输出层,有 10 个神经元,对应 10 个数字分类。使用 softmax 激活函数,将输出转换为概率分布。
])
# 编译模型
model.compile(optimizer='adam', # 使用 Adam 优化器,一种常用的优化算法。
loss='sparse_categorical_crossentropy', # 使用稀疏分类交叉熵作为损失函数,适用于多分类问题且标签是整数的情况。
metrics=['accuracy']) # 评估指标为准确率。
# 训练模型
model.fit(x_train, y_train, epochs=5) # 训练 5 个 epoch,每个 epoch 遍历一遍整个训练集。训练5次。
# 评估模型的性能,并输出损失和准确率。
# 损失(loss): 模型在测试集上的平均损失值,反映了模型预测值与真实值之间的差异。损失越小,说明模型预测越准确。
# 准确率(accuracy): 模型在测试集上预测正确的样本比例,直接反映了模型的分类性能。
#model.evaluate(x_test, y_test) # 评估模型的性能,并输出损失和准确率。
loss, accuracy = model.evaluate(x_test, y_test, verbose=0)
print(f"\n模型评估 - 损失: {loss:.4f}, 准确率: {accuracy:.4f}")
# 预测测试集标签
predictions = model.predict(x_test)
predicted_labels = np.argmax(predictions, axis=1)
# 初始化错误样本计数
wrong_count = 0
total_count = len(x_test)
# 遍历测试集,输出识别错误的样本
print("\n识别错误的样本:")
for i in range(len(x_test)):
if predicted_labels[i] != y_test[i]: # 判断是否识别错误
wrong_count += 1
print(f"\n样本索引: {i} 模型预测结果: {predicted_labels[i]}, 正确结果: {y_test[i]}")
display_mnist_image_console(x_test_original[i]) # 显示图像
# 输出错误样本总数和总样本数
print(f"\n总共 {total_count} 个样本,识别错误 {wrong_count} 个")
# 总共 10000 个样本,识别错误 222 个。 部分识别错误的明显不应该错。
示例图像:
识别错误的图像举例:
输出指定img列表到bmp文件

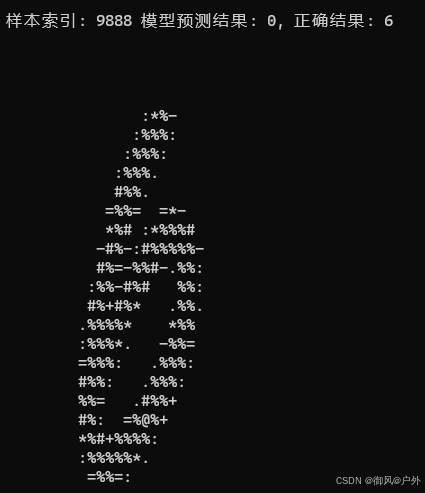
def save_images_to_bmp(images, labels, filename, max_per_row=50):
"""
将图像保存到 BMP 文件中,每行最多 max_per_row 张图像。
:param images: 图像数组,形状为 (n, 28, 28)
:param labels: 标签数组,形状为 (n,)
:param filename: 保存的 BMP 文件名
:param max_per_row: 每行最大图像数量
"""
img_count = len(images)
rows = (img_count + max_per_row - 1) // max_per_row
img_width, img_height = 28, 28
# 创建画布
canvas_width = max_per_row * img_width
canvas_height = rows * img_height
canvas = Image.new("L", (canvas_width, canvas_height), color=255) # 灰度图
# 绘制每张图片
for idx, img in enumerate(images):
x_offset = (idx % max_per_row) * img_width
y_offset = (idx // max_per_row) * img_height
# img_pil = Image.fromarray((img * 255).astype(np.uint8)) # 恢复像素值范围 0-255
img_pil = Image.fromarray(img, 'L')
canvas.paste(img_pil, (x_offset, y_offset))
# 保存到文件
canvas.save(filename)
print(f"保存 {filename} 成功!")
# 遍历训练集,分类存储
print("\n遍历训练集,分类存储:")
train_images = {i: [] for i in range(10)}
for i in range(len(x_train)):
label = y_train[i] # 标签
train_images[label].append(x_train[i])
# 保存训练集图像
for digit in range(10):
# 保存正确分类的样本
if train_images[digit]:
save_images_to_bmp(
train_images[digit],
[digit] * len(train_images[digit]),
f"train_{digit}.bmp"
)
# 预测测试集标签
predictions = model.predict(x_test)
predicted_labels = np.argmax(predictions, axis=1)
# 初始化错误样本计数
wrong_count = 0
total_count = len(x_test)
# 初始化存储字典
correct_images = {i: [] for i in range(10)}
wrong_images = {i: [] for i in range(10)}
# # 遍历测试集,输出识别错误的样本
# print("\n识别错误的样本:")
# for i in range(len(x_test)):
# if predicted_labels[i] != y_test[i]: # 判断是否识别错误
# wrong_count += 1
# print(f"\n样本索引: {i} 模型预测结果: {predicted_labels[i]}, 正确结果: {y_test[i]}")
# display_mnist_image_console(x_test_original[i]) # 显示图像
# 遍历测试集,分类存储识别结果
print("\n识别错误的样本统计汇总:")
for i in range(len(x_test)):
label = y_test[i] # 真实标签
predicted = predicted_labels[i] # 模型预测结果
if predicted == label:
correct_images[label].append(x_test_original[i])
else:
wrong_images[label].append(x_test_original[i])
wrong_count += 1
print(f"样本索引: {i} 模型预测结果: {predicted_labels[i]}, 正确结果: {y_test[i]}")
# display_mnist_image_console(x_test_original[i]) # 显示图像
# 保存图像
for digit in range(10):
# 保存正确分类的样本
if correct_images[digit]:
save_images_to_bmp(
correct_images[digit],
[digit] * len(correct_images[digit]),
f"test_{digit}.bmp"
)
# 保存错误分类的样本
if wrong_images[digit]:
save_images_to_bmp(
wrong_images[digit],
[digit] * len(wrong_images[digit]),
f"test_error_{digit}.bmp",
max_per_row=10
)
以数字2为例,以下分别为训练集图像、测试集通过的图像、测试集失败的图像: