一.搭建RabbitMQ集群的原因
单个的RabbitMQ无法实现高可用性,为了实现RabbitMQ高可用性,我们选择给RabbitMQ搭建上集群。
二.RabbitMQ搭建集群的两种模式。
说道集群,我们脑中就会不由的想到,RabbitMQ消息集群中的实例数据都是怎么保存呢?是每个实例数据在每个集群上都保存一份还是怎么样?
其实这要看我们RabbitMQ集群是如何搭建的:
1.1 第一种:普通集群搭建法
1.1.1RabbitMQ的普通集群搭建法
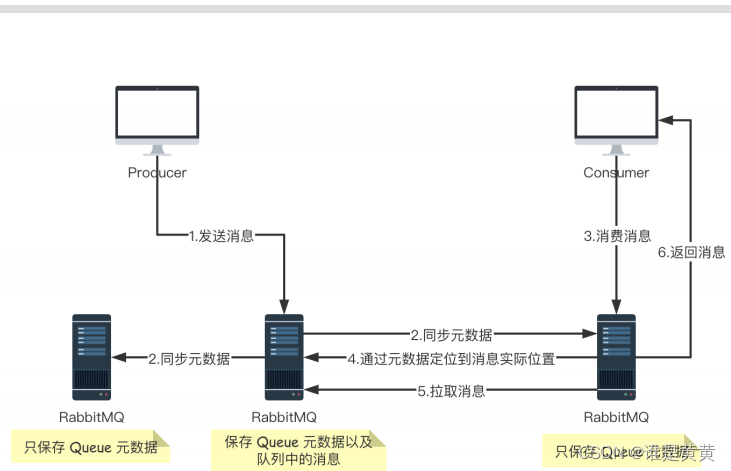
普通集群模式:就是将RabbitMQ部署到多台服务器上,每个服务器启动一个RabbitMQ实例,多个实例之间进行消息通信。
此时我们创建的队列Queue,它的元数据,(主要就是Queue的一些配置信息)会在所有的RabbitMQ实例中进行同步,但是队列中的消息只会存在于一个RabbitMQ实例上,而不会同步到其他队列中。
且当我们消费信息的时候,如果连接到了另外的一个实例,那么那个实例会通过元数据去定位到Queue所在的位置,然后访问Queue所在的实例,拉去数据过来发送给消费者。
这种集群可以提高RabbitMQ的消息吞吐能力,但是无法保证高可用,因为一旦一个RabbitMQ实例消亡了,消息就没办法继续访问了,如果消息队列做了持久化,那么等RabbitMQ实例回复后,就可以继续访问了,如果消息队列没做持久化的话,消息就会丢失。
流程图如下:
1.1.2 开始搭建普通RabbitMQ的普通集群
第一个创建命令值得注意的是:
普通集群搭建的核心方式:
1.-e就是他里面环境变量的参数,给他设置一个xxx_ERLANG_COOKIE的值,这个值取什么都是无所谓的
2.但是关键是这三个给他设置一个xxx_ERLANG_COOKIE的值都必须一样,就像此处的名都为:javaboy_rabbitmq_cookie
3.将来三个节点启动的时候,一旦进行内部通信,会发现三个的cookie都一样,就会自动的去形成一个集群
4.这里检查xxx_ERLANG_COOKIE的范围并不是检查所有的,而是有一个特定的范围
docker run -d --hostname rabbit01 --name mq01 -p 5671:5672 -p 15671:15672 -e RABBITMQ_ERLANG_COOKIE=“javaboy_rabbitmq_cookie” rabbitmq:3-management
第二个创建命令值得注意的是:
这里多了一个代码 --link mq01:mylink01 这个就叫做容器连接。
在容器内部建立一个连接,通过这个连接就可以直接访问到mylink01(容器访问的两种方式:一:暴露端口,-p 15671:15672 这种就是。二:容器连接,--link mq01:mylink01就是,类似于hostname,通过在内部建立一个连接,让容器通过这个连接直接访问,本质上也是一个网络请求)
docker run -d --hostname rabbit02 --name mq02 --link mq01:mylink01 -p 5672:5672 - p 15672:15672 -e RABBITMQ_ERLANG_COOKIE=“javaboy_rabbitmq_cookie” rabbitmq:3- management
docker run -d --hostname rabbit03 --name mq03 --link mq01:mylink02 --link mq02:mylink03
-p 5673:5672 -p 15673:15672 -e RABBITMQ_ERLANG_COOKIE=“javaboy_rabbitmq_cookie”
rabbitmq:3-management

linux中创建

注意:
1.配集群前要先把RabbitMQ容器给关掉
2.如果提示端口被占用了,就改一下上面的命令换一个端口。
3.如果错误就docker -rm 名/id把端口删了再来
4.注意空格问题

docker exec -ti mq02 /bin/bash 进入mq02
cat etc/hosts 查看hosts文件的配置
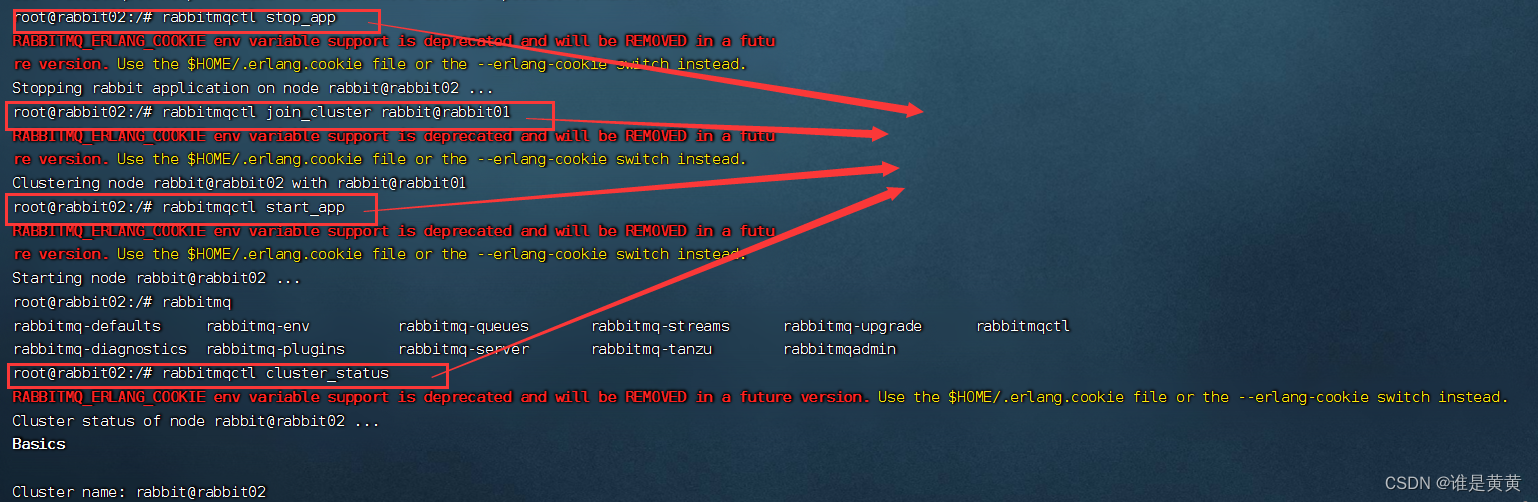
分别执行下面三条命令让mq02容器加入到集群中
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbit01
rabbitmqctl start_app
再去输入如下命令就可以去查看我们的集群的状态
rabbitmqctl cluster_status
接下来以同样的方式把mq01和mq03也加入到集群中
加入成功后查看RabbitMQ的网页
发现这个时候集群中已经有三个节点了。
1.1.3 用java代码来测试这个集群
1.1.3.1 搭建项目
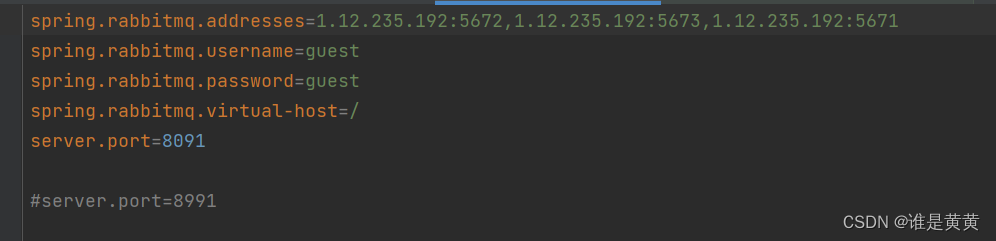
1.1.3.2 application配置
注意:根据自己的集群的配置来进行更改
spring.rabbitmq.addresses=1.12.235.192:5671,1.12.235.192:5672,1.12.235.192:5673
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.virtual-host=/
1.1.3.3 HelloConfig配置类
@Configuration
public class HelloConfig {
public static final String HELLO_QUEUE = "hello_queue";
@Bean
Queue helloQueue() {
return new Queue(HELLO_QUEUE, true, false, false);
}
}
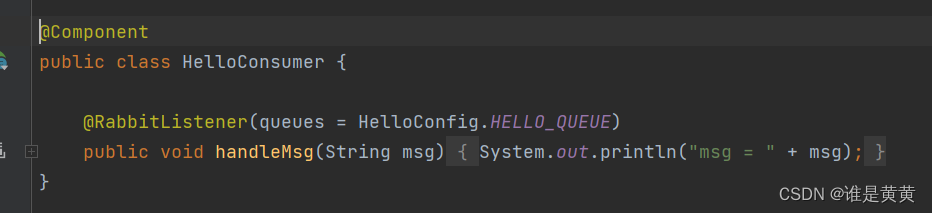
1.1.3.4 HelloConsumer消费者
@Component
public class HelloConsumer {
@RabbitListener(queues = HelloConfig.HELLO_QUEUE)
public void handleMsg(String msg) {
System.out.println("msg = " + msg);
}
}
1.1.3.5 测试类
@SpringBootTest
class ClusterDemoApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void contextLoads() {
rabbitTemplate.convertAndSend(HelloConfig.HELLO_QUEUE, "hello cluster");
}
}
1.1.3.5 如何测试
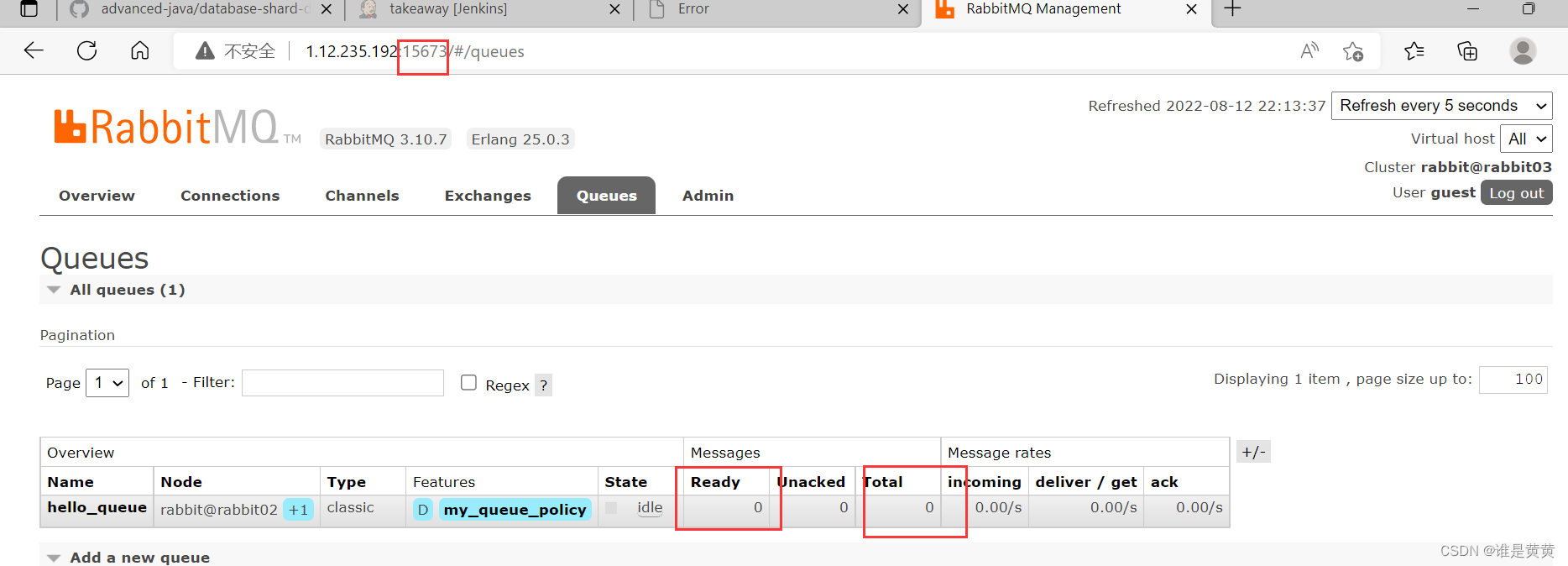
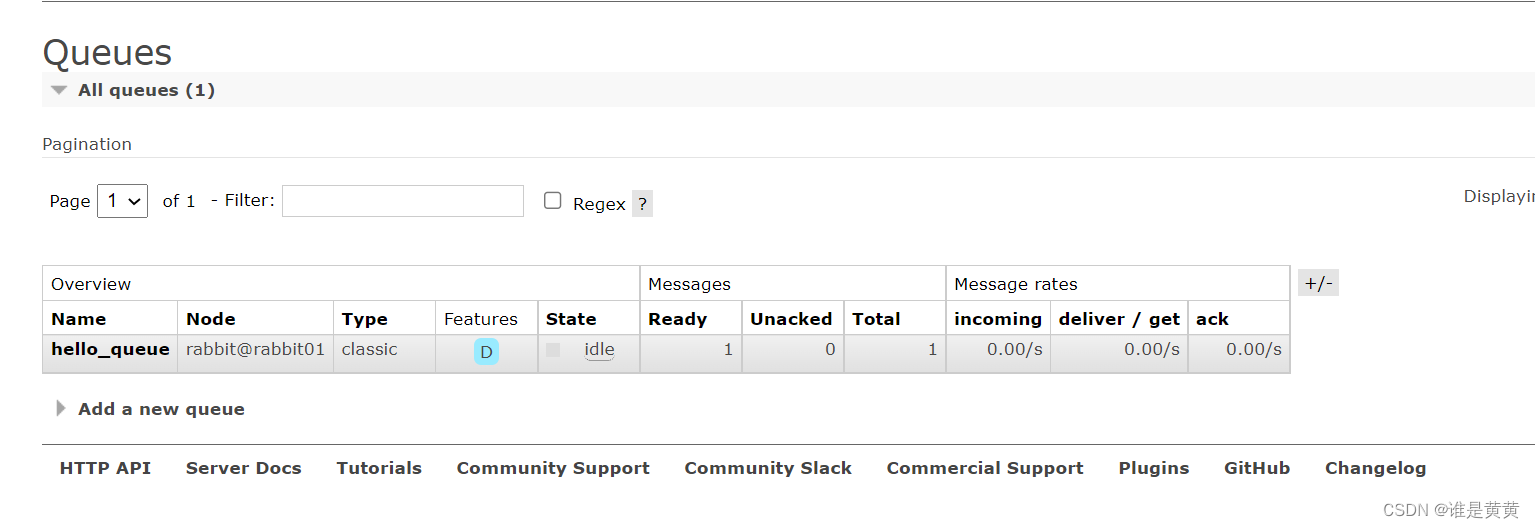
1.首先把消费者注入bean的注解注释掉,让消费者不起作用,然后开启生产者让其生产,然后开启测试类,去接收到一条生产者生产的消息,此时看向控制台并没有日志打印出来,看向RabbitMQ的界面发现
Ready 待处理消息为1
Total 总消息为1
即我们这条消息现在在交换机上面
然后我再把消费者类的注入bean容器的@component注解的注释打掉,让消费者类去注入bean容器,然后发送消息,当消息消费者启动后,这个方法中只收到了一条消息,进一步验证了我们搭建的 RabbitMQ 集群是没问题的。
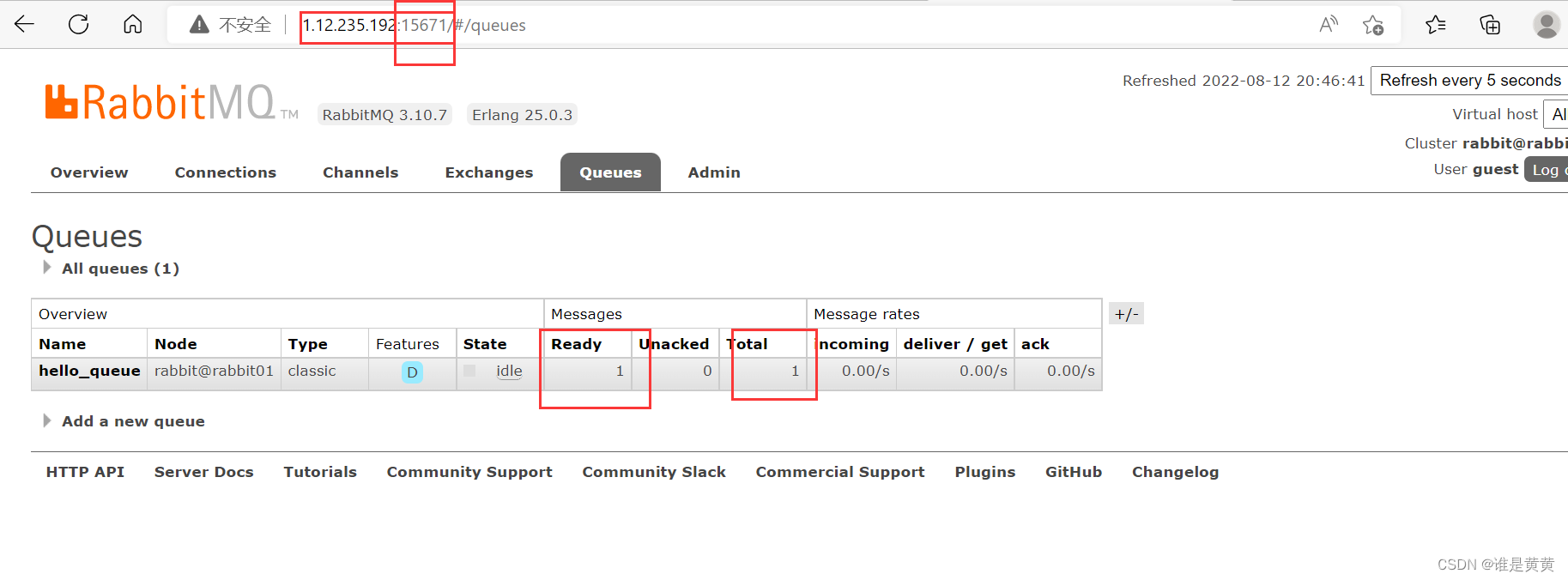
测试例子:
注释掉消费者然后让生产者去生产消息。
依旧是控制台没有打印

RabbitMQ界面显示队列中有一条代消费的消息
然后我们再去把linux中的mq01也就是15671对应的节点给他关掉

再去application中更改我们的端口,通过15673和15672端口

消费者注释也删掉
即上面让15672,和15673去消费队列中的消息看是否可以消费
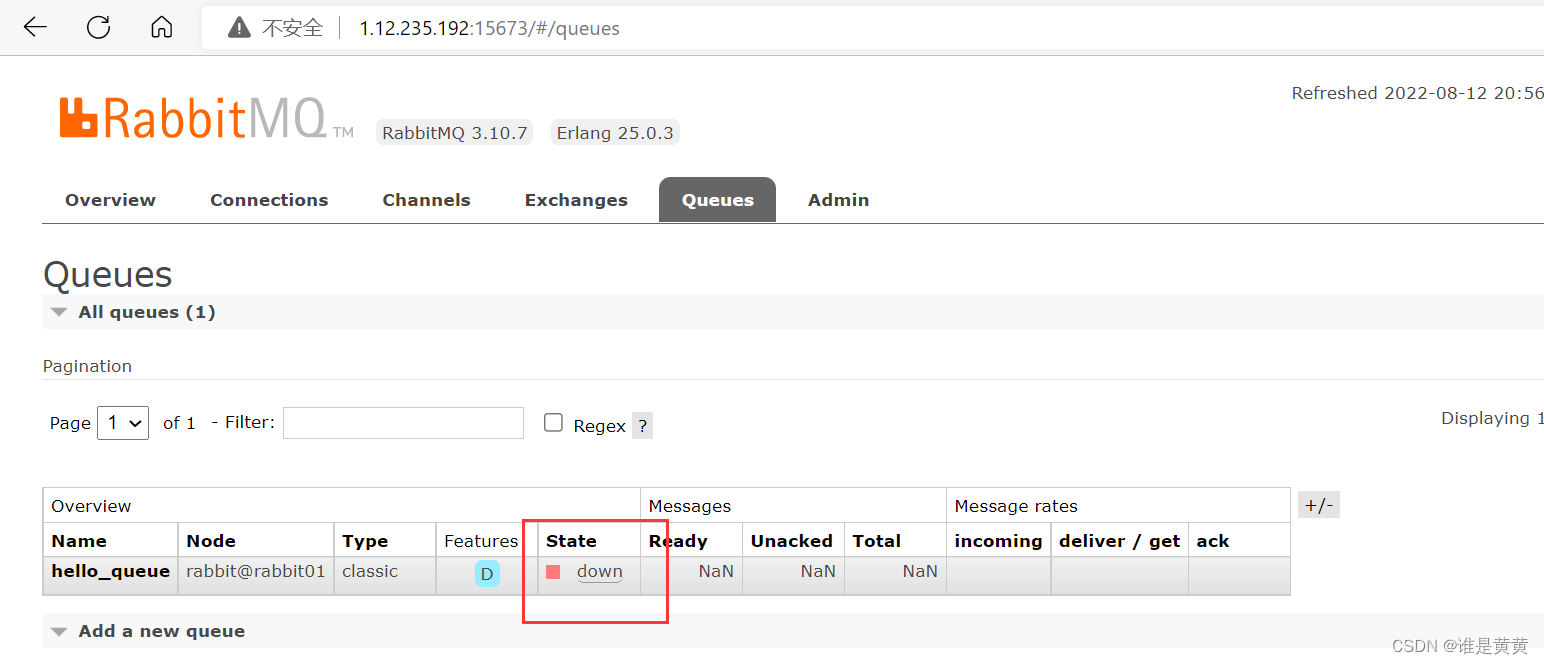
发现并没有进行消费
而且RabbitMQ也是显示down,即我们集群的状态出现了问题

再去linux里启动我们的mq01

然后再启动我们的项目,让消费者去消费
已经把存储的消息给消费了

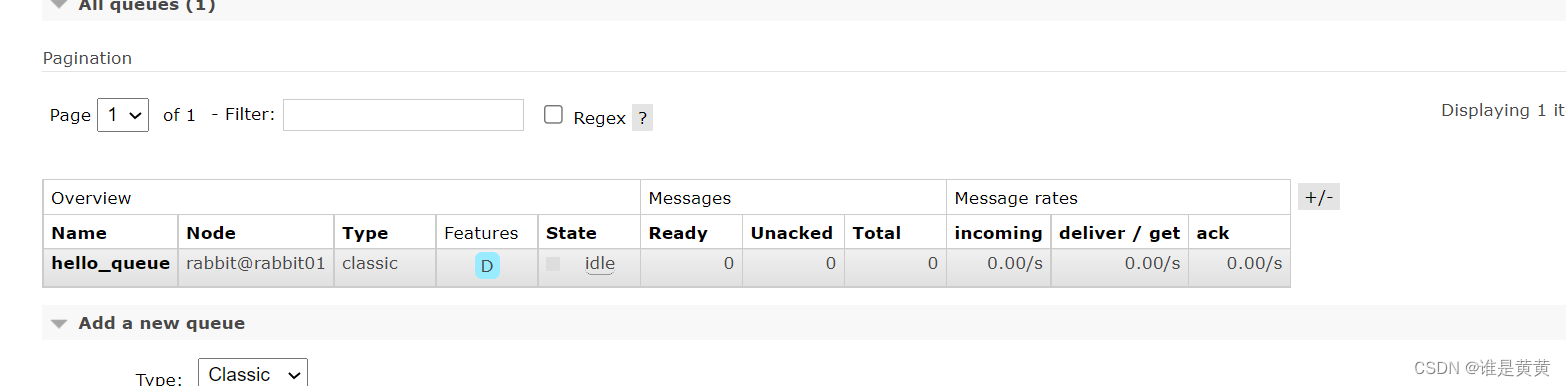
说明了普通集群中的消息是存储在mq01去共享给其他的节点的
1.1.3.6 如何进行反向测试
来自江南一点雨的例子
两个反面例子,证明消息并没有同步到其他的RabbitMQ上面。
1.确保三个 RabbitMQ 实例都是启动状态,关闭掉 Consumer,然后通过 provider 发送一条消息,发送成功之后,关闭 mq01 实例,然后启动 Consumer 实例,此时 Consumer 实例并不会消费消息,反而 会报错说 mq01 实例连接不上,这个例子就可以说明消息在 mq01 上,并没有同步到另外两个 MQ 上。相反,如果 provider 发送消息成功之后,我们没有关闭 mq01 实例而是关闭了 mq02 实例,那么你就 会发现消息的消费不受影响。
1.2 第二种:镜像集群搭建法
1.2.1 RabbitMQ的镜像集群搭建法
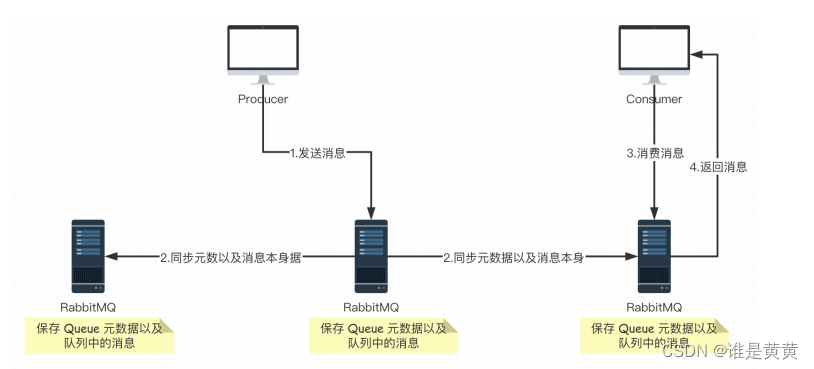
它和普通集群最大的区别在意Queue数据和原数据不再是单独存储在一台机器上,而是同时存储在多台机器上,也就是说,每个RabbitMQ实例都有一份自己的镜像数据。且每次在进行写入的时候(所有的机器),都会把自己写入的消息传到多台实例数据上去,即一台进行数据更改,其他也进行了数据更改。故此,一旦其中的一台机器发生了故障,其他机器还有一份副本数据可以继续提供服务,这样也就实现类高可用。
流程图如下:
1.2.2 开始搭建RabbitMQ的镜像集群搭建法
镜像集群模式的搭建,只需要在RabbitMQ网页上进行操作即可,(注意:RabbitMQ的前端可视化界面实际上也是一个插件而已,实际上就是快捷的再我们的linux里进行操作,所以,前端界面上能做到的,我们在linux通过代码也能做到)
1.2.2.1 网页配置镜像队列
点击Admin选项卡,然后点击右边的Policies,再点击Add/update a policy ,如下
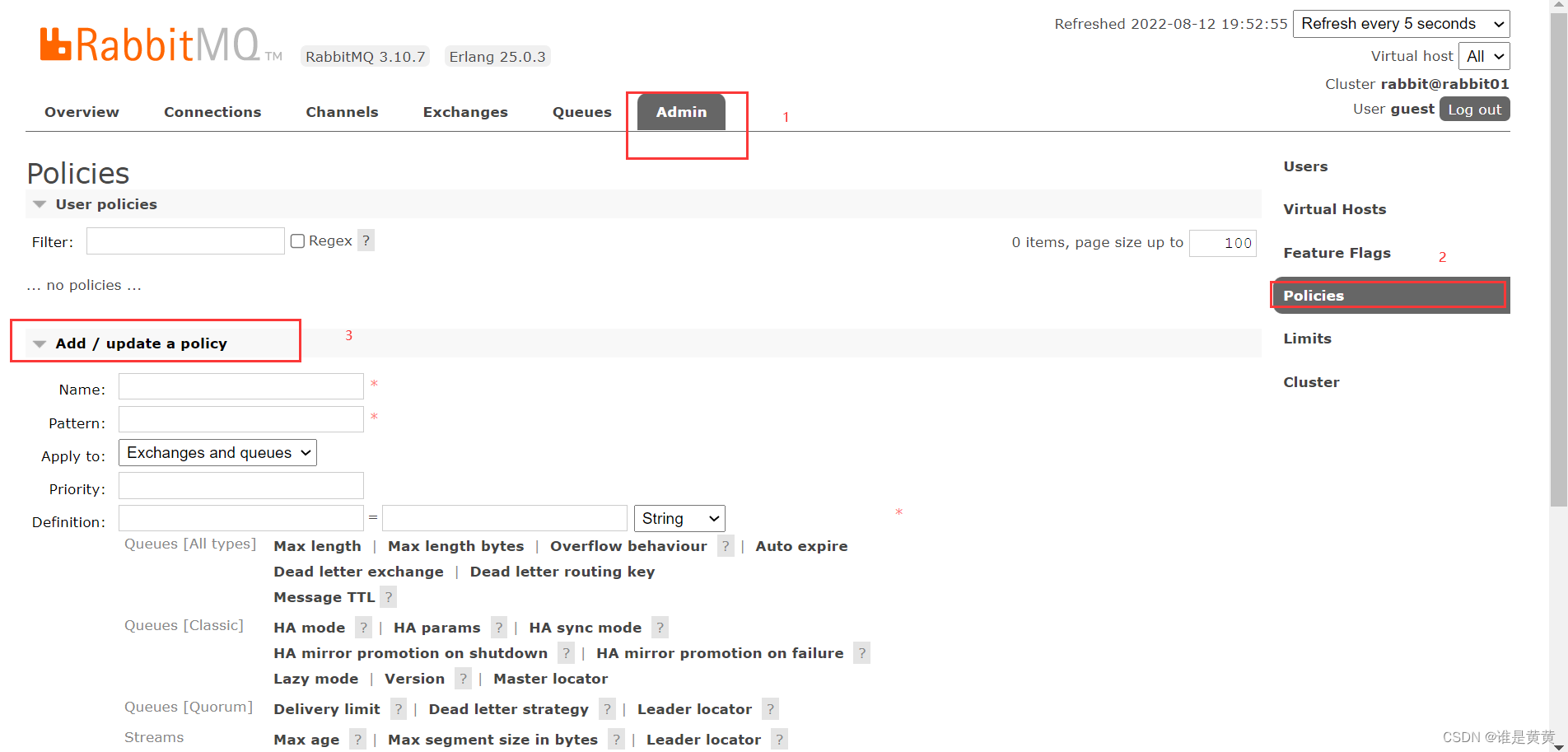
接下来添加一个策略,如下图:
各参数含义如下:
1.Name: policy 的名称。
2.Pattern: queue 的匹配模式(正则表达式)。
3.Definition:镜像定义,主要有三个参数:
3.1.ha-mode:指明镜像队列的模式,有效值为 all、exactly、nodes。其中 all 表示在集群中所有的节点上进行镜像(默认即此)exactly 表示在指定个数的节点上进行镜像,节点的个数由 ha-params 指定;nodes 表示在指定的节点上进行镜像,节点名称通过 ha-params 指定。
3.2.ha-params:ha-mode 模式需要用到的参数。
3.3.ha-sync-mode:进行队列中消息的同步方式,有效值为 automatic 和 manual。
4.priority 为可选参数,表示 policy 的优先级。
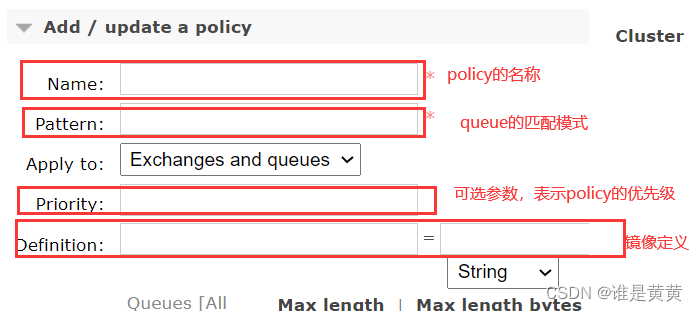
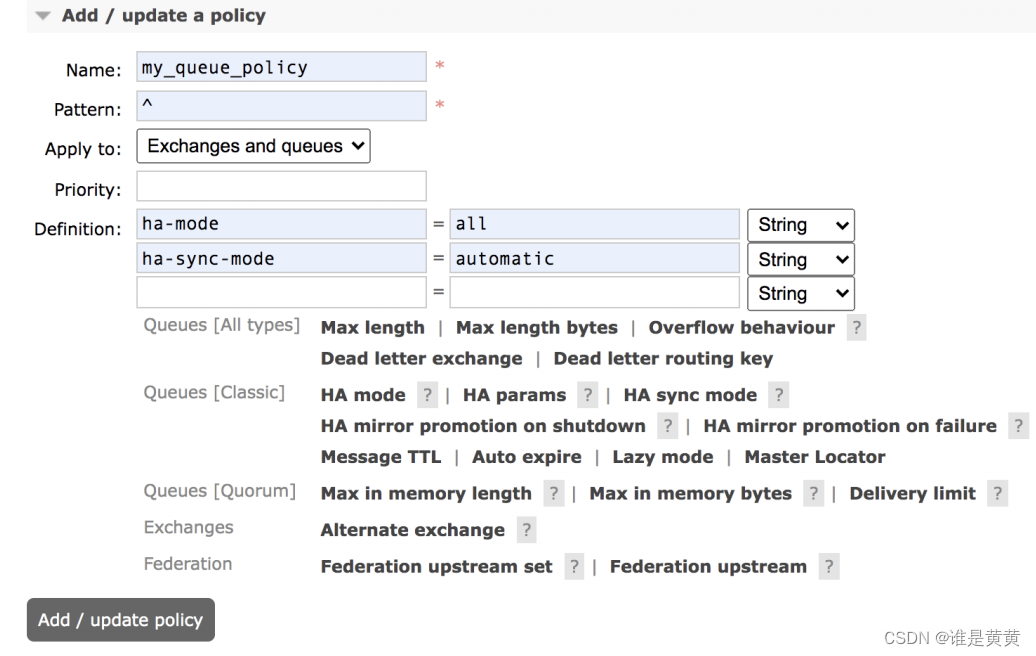
确认就是点击下面的Add
1.2.2.2 进行镜像集群的测试
首先沿用普通集群的java的配置,我们还是把消费者注释掉
然后再去启动我们的生产者,发现消费者控制台没打印,很好。进入我们的RabbitMQ去查看
注意:先进入15671端口,再进入15673,再进入15673.
发现每个里面都是收到了这个消息的。说明确实做到了消息同步,那么这种同步又是否和普通镜像的同步一样呢?
显然这里看不出来,我们现在先把这一条消息消费掉(启动消费者,把注释给删掉,把这条消息给消费掉)
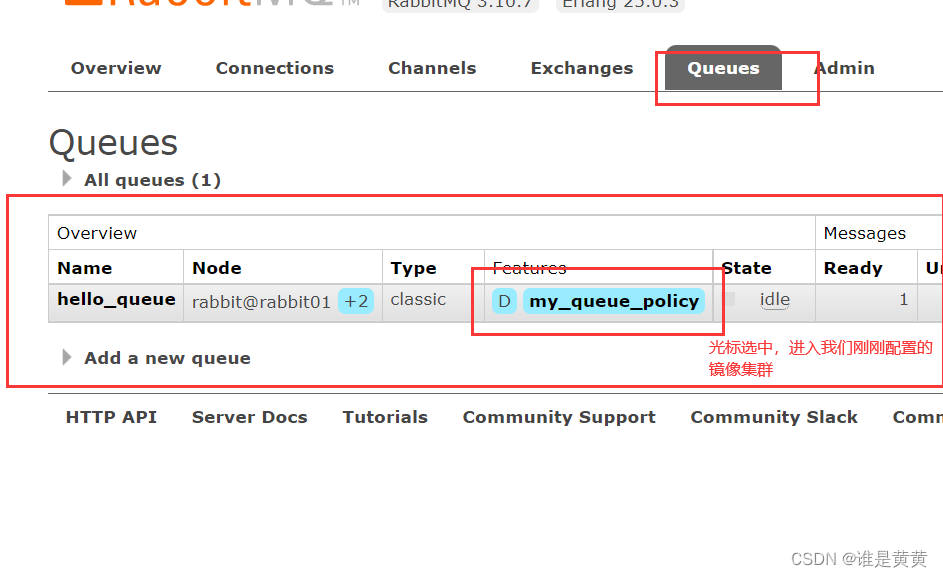
很好,我们把这条消息消费掉了

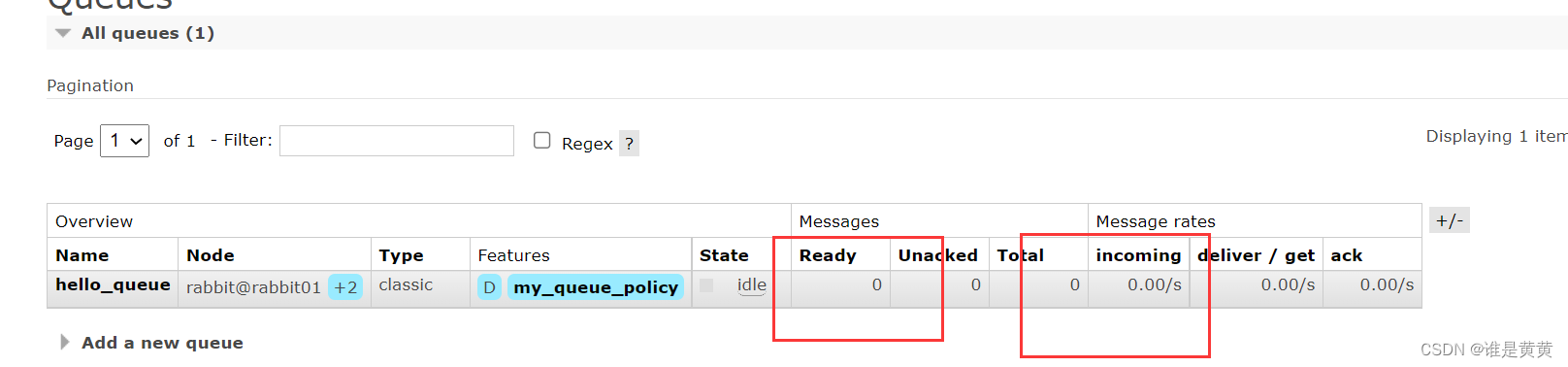
RabbitMQ界面上也没有显示有消息存在于队列中。
然后去我们的application中配置,只留下我们的RabbitMQ端口5671
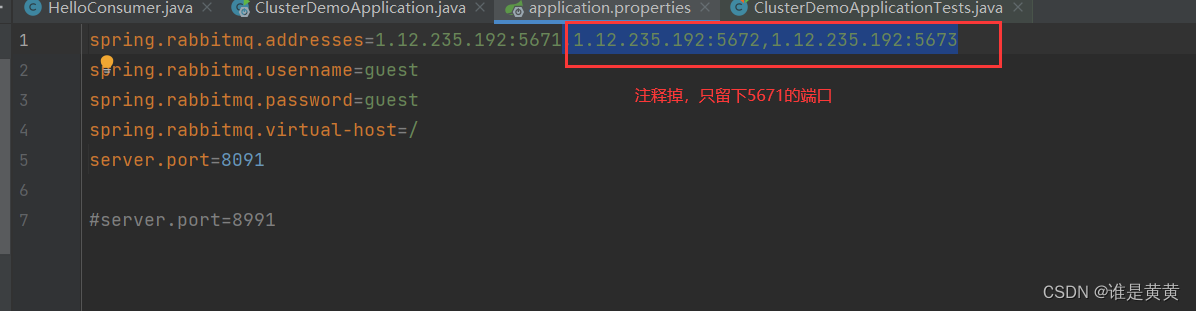
然后再去把消费者注释掉
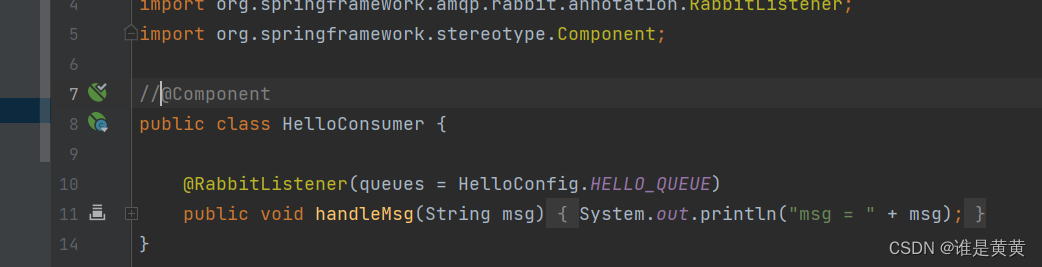
然后发消息
停掉linux中低端mq01
把端口都加上
消费者也放开

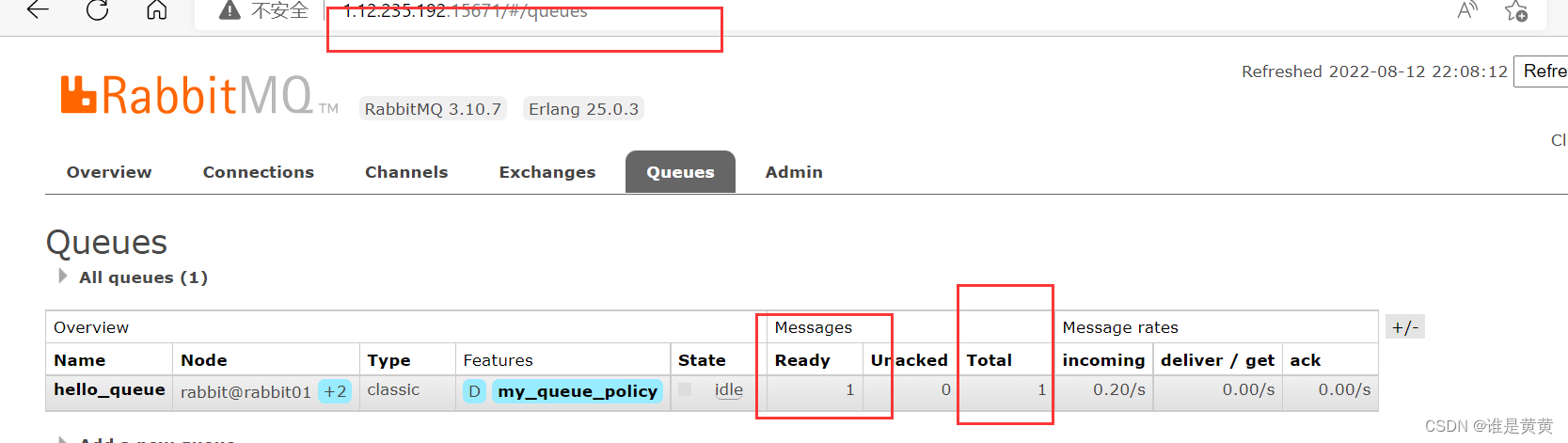

存在队列中的信息已经被消费了

15672
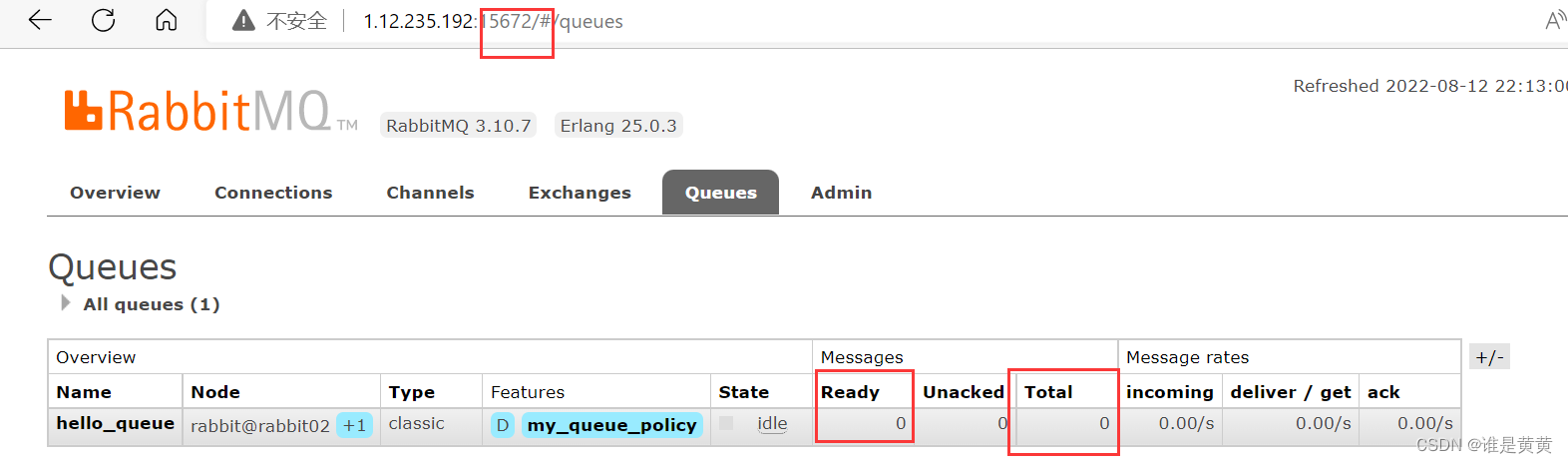
15673
发现跟普通集群不同的是,镜像集群中的队列被消费了,说明改消息是每个节点中都存储了一份的。