目录
一、前言概述
小文件是指文件size小于HDFS上block大小的文件。这样的文件会给Hadoop的扩展性和性能带来严重问题。
首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每个对象约占150byte,如果有1000 0000个小文件,每个文件占用一个block,则namenode大约需要2G空间。如果存储1亿个文件,则namenode需要20G空间。这样namenode内存容量严重制约了集群的扩展。
其次,访问大量小文件速度远远小于访问几个大文件。HDFS最初是为流式访问大文件开发的,如果访问大量小文件,需要不断的从一个datanode跳到另一个datanode,严重影响性能。
最后,处理大量小文件速度远远小于处理同等大小的大文件的速度。每一个小文件要占用一个slot,而task启动将耗费大量时间甚至大部分时间都耗费在启动task和释放task上。
hadoop自带的解决小文件问题的方案(以工具的形式提供),包括Hadoop Archive,Sequence file和CombineFileInputFormat;
二、Hadoop Archive方案(HAR)
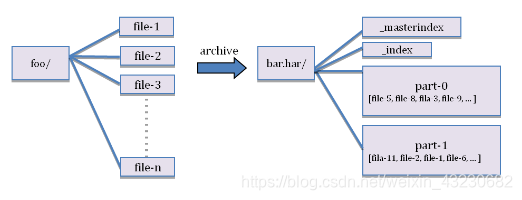
Hadoop Archive或者HAR,是一个高效地将小文件放入HDFS块中的文件存档工具,它能够将多个小文件打包成一个HAR文件,这样在减少namenode内存使用的同时,仍然允许对文件进行透明的访问。
案例实操:
第一步:创建归档文件
(注意:归档文件一定要保证yarn集群启动,本质启动mr程序,所以需要启动yarn )
把某个目录 /small_files 下的所有小文件存档成 /big_files/myhar.har :
hadoop archive -archiveName myhar.har -p /small_files /big_files [hadoop@weekend110 datas]$ hdfs dfs -ls /small_files
20/08/06 03:40:07 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 10 items
-rw-r--r-- 1 hadoop supergroup 80 2020-08-06 03:30 /small_files/t1.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:30 /small_files/t10.txt
-rw-r--r-- 1 hadoop supergroup 632 2020-08-06 03:30 /small_files/t2.txt
-rw-r--r-- 1 hadoop supergroup 1509 2020-08-06 03:30 /small_files/t3.txt
-rw-r--r-- 1 hadoop supergroup 38 2020-08-06 03:30 /small_files/t4.txt
-rw-r--r-- 1 hadoop supergroup 98 2020-08-06 03:30 /small_files/t5.txt
-rw-r--r-- 1 hadoop supergroup 69 2020-08-06 03:30 /small_files/t6.txt
-rw-r--r-- 1 hadoop supergroup 62 2020-08-06 03:30 /small_files/t7.txt
-rw-r--r-- 1 hadoop supergroup 88 2020-08-06 03:30 /small_files/t8.txt
-rw-r--r-- 1 hadoop supergroup 93 2020-08-06 03:30 /small_files/t9.txt
[hadoop@weekend110 datas]$ hdfs dfs -mkdir /big_files
[hadoop@weekend110 datas]$ hadoop archive -archiveName myhar.har -p /small_files /big_files
20/08/06 03:35:30 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
20/08/06 03:35:31 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.2.100:8032
20/08/06 03:35:33 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.2.100:8032
20/08/06 03:35:33 INFO client.RMProxy: Connecting to ResourceManager at weekend110/192.168.2.100:8032
20/08/06 03:35:34 INFO mapreduce.JobSubmitter: number of splits:1
20/08/06 03:35:35 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1596678262767_0001
20/08/06 03:35:36 INFO impl.YarnClientImpl: Submitted application application_1596678262767_0001
20/08/06 03:35:36 INFO mapreduce.Job: The url to track the job: http://weekend110:8088/proxy/application_1596678262767_0001/
20/08/06 03:35:36 INFO mapreduce.Job: Running job: job_1596678262767_0001
20/08/06 03:35:56 INFO mapreduce.Job: Job job_1596678262767_0001 running in uber mode : false
20/08/06 03:35:56 INFO mapreduce.Job: map 0% reduce 0%
20/08/06 03:36:09 INFO mapreduce.Job: map 100% reduce 0%
20/08/06 03:36:18 INFO mapreduce.Job: map 100% reduce 100%
20/08/06 03:36:18 INFO mapreduce.Job: Job job_1596678262767_0001 completed successfully
20/08/06 03:36:18 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=859
FILE: Number of bytes written=233827
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number o