
前言
EfficientNetV1是Google在2019年发布的文章,这篇论文最主要的创新点是Model Scaling。论文提出了compound scaling,混合缩放,把网络缩放的三种方式:深度、宽度、分辨率,组合起来按照一定规则缩放,从而提高网络的效果。EfficientNet在网络变大时效果提升明显,把精度上限进一步提升。
学习资料:
- 论文题目:《EfficientNet:Rethinking Model Scaling for Convolutional Neural Networks》(《EfficientNet:对卷积神经网络的模型缩放的重新思考》)
- 原文地址:https://arxiv.org/pdf/1905.11946.pdf
- 官方源码: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
- 第三方PyTorch源码: GitHub - lukemelas/EfficientNet-PyTorch: A PyTorch implementation of EfficientNet and EfficientNetV2 (coming soon!)
前期回顾:
【轻量化网络系列(1)】MobileNetV1论文超详细解读(翻译 +学习笔记+代码实现)
【轻量化网络系列(2)】MobileNetV2论文超详细解读(翻译 +学习笔记+代码实现)
【轻量化网络系列(3)】MobileNetV3论文超详细解读(翻译 +学习笔记+代码实现)
【轻量化网络系列(4)】ShuffleNetV1论文超详细解读(翻译 +学习笔记+代码实现)
【轻量化网络系列(5)】ShuffleNetV2论文超详细解读(翻译 +学习笔记+代码实现)
目录
三、Compound Model Scaling—混合模型缩放
四、EfficientNet Architecture—EfficientNet结构
5.1 Scaling Up MobileNets and ResNets—扩大MobileNets与ResNets
5.2 ImageNet Results for EfficientNet—在ImageNet上的测试
5.3 Transfer Learning Results for EfficientNet—Efficient迁移学习
Abstract—摘要
翻译
卷积神经网络 (ConvNets) 通常是在固定资源预算下开发的,如果有更多资源可用,则可以扩大规模以提高准确性。 在本文中,我们系统地研究了模型缩放并确定仔细平衡网络深度、宽度和分辨率可以带来更好的性能。 基于这一观察,我们提出了一种新的缩放方法,该方法使用简单而高效的复合系数统一缩放深度/宽度/分辨率的所有维度。 我们证明了这种方法在扩大 MobileNets 和 ResNet 方面的有效性。
为了更进一步,我们使用神经架构搜索来设计一个新的基线网络并将其扩展以获得一系列模型,称为 EfficientNets,它比以前的 ConvNets 实现了更好的准确性和效率。 特别是,我们的 EfficientNet-B7 在 ImageNet 上达到了最先进的 84.3% 的 top-1 准确率,同时比现有最好的 ConvNet 小 8.4 倍,推理速度快 6.1 倍。 我们的 EfficientNets 在 CIFAR-100(91.7%)、Flowers (98.8%) 和其他 3 个迁移学习数据集上也能很好地迁移并达到最先进的精度,参数少了一个数量级。
精读
本文主要内容
(1)本文系统地研究了模型的缩放,发现平衡网络深度、宽度和分辨率可以带来更好的性能。
(2)本文提出了一种新的缩放方法,使用一个简单而高效的复合系数统一缩放深度/宽度/分辨率的所有维度。
(3)本文使用神经结构搜索来设计一个新的基线网络,并将其扩大到获得一个模型系列,称为EfficientNets。
(4)本文在数据集上进行实验,发现均能取得最先进的准确性,而参数却少了一个数量级。
一、Introduction—简介
翻译
扩大 ConvNets 被广泛用于实现更好的准确性。 例如,ResNet (He et al., 2016) 可以通过使用更多层从 ResNet-18 扩展到 ResNet-200; 最近,GPipe(Huang 等人,2018 年)通过将基线模型放大四倍,实现了 84.3% 的 ImageNet top-1 准确率。 然而,扩展 ConvNets 的过程从来没有被很好地理解,目前有很多方法可以做到。 最常见的方法是按深度(He 等人,2016 年)或宽度(Zagoruyko 和 Komodakis,2016 年)扩展 ConvNet。 另一种不太常见但越来越流行的方法是按图像分辨率放大模型(Huang et al., 2018)。 在之前的工作中,通常只缩放三个维度中的一个——深度、宽度和图像大小。 尽管可以任意缩放两个或三个维度,但任意缩放需要繁琐的手动调整,并且仍然经常产生次优的精度和效率。
在本文中,我们想研究和重新思考扩大 ConvNets 的过程。特别是,我们研究了一个核心问题:是否有一种原则性的方法来扩大 ConvNets 以实现更好的准确性和效率?我们的实证研究表明,平衡网络宽度/深度/分辨率的所有维度至关重要,令人惊讶的是,这种平衡可以通过简单地以恒定比率缩放每个维度来实现。基于这一观察,我们提出了一种简单而有效的复合缩放方法。与任意缩放这些因素的传统做法不同,我们的方法使用一组固定缩放系数统一缩放网络宽度、深度和分辨率。例如,如果我们想使用 2^N 倍的计算资源,那么我们可以简单地将网络深度增加 α ^N ,宽度增加 β ^N ,图像大小增加 γ ^N ,其中 α, β, γ 是由下式确定的常数系数对原始小模型的小网格搜索。图 2 说明了我们的缩放方法与传统方法之间的区别。
直观上,复合缩放方法是有意义的,因为如果输入图像更大,那么网络需要更多层来增加感受野和更多通道以在更大的图像上捕获更多细粒度的图案。 事实上,之前的理论(Raghu et al., 2017; Lu et al., 2018)和实证结果(Zagoruyko & Komodakis, 2016)都表明网络宽度和深度之间存在一定的关系,但据我们所知,我们 是第一个凭经验量化网络宽度、深度和分辨率三个维度之间关系的人。
我们证明我们的缩放方法在现有的 MobileNets(Howard 等人,2017;Sandler 等人,2018 年)和 ResNet(He 等人,2016 年)上运行良好。值得注意的是,模型缩放的有效性在很大程度上取决于基线网络;为了更进一步,我们使用神经架构搜索(Zoph & Le,2017 年;Tan 等人,2019 年)来开发一个新的基线网络,并对其进行扩展以获得一系列模型,称为 EfficientNets。图 1 总结了 ImageNet 的性能,其中我们的 EfficientNet 明显优于其他 ConvNet。特别是,我们的 EfficientNet-B7 超过了现有的最佳 GPipe 精度(Huang et al., 2018),但使用的参数减少了 8.4 倍,推理运行速度提高了 6.1 倍。与广泛使用的 ResNet-50 (He et al.,2016) 相比,我们的 EfficientNet-B4 将 top-1 的准确率从 76.3% 提高到 83.0% (+6.7%),并具有类似的 FLOPS。除了 ImageNet,EfficientNets 在 8 个广泛使用的数据集中的 5 个上也能很好地传输并实现最先进的精度,同时将参数减少高达现有 ConvNet 的 21 倍。
精读
之前扩大ConvNets的规模的方法
(1)通过深度和宽度扩大
(2)通过图像分辨率来放大模型
之前方法的不足
在以前的工作中,通常都是在深度,宽度,和图像大小三个维度其中之一进行缩放。任意缩放需要繁琐的人工调参,同时可能产生的是一个次优的精度和效率
本文方法
本文的方法是用一组固定的缩放系数来统一缩放网络的宽度、深度和分辨率。
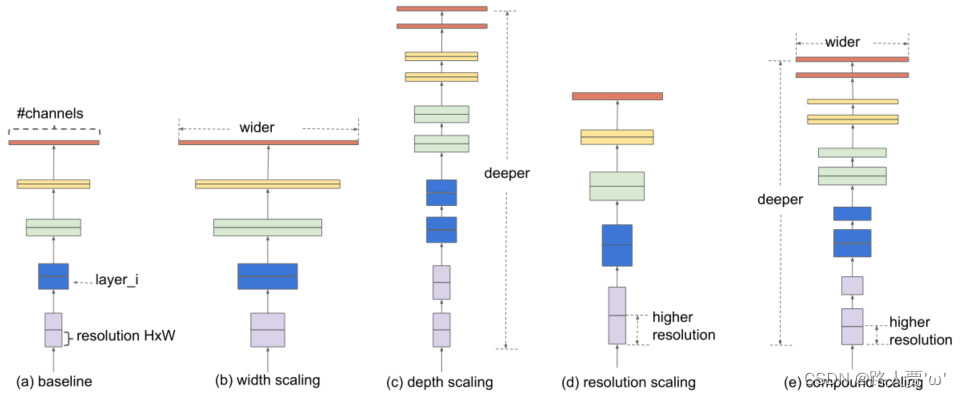
模型扩展的有效性在很大程度上取决于基线网络;为了更进一步,本文使用神经架构搜索来开发一个新的基线网络,并将其扩展以获得一个模型系列,称为EfficientNets。
网络性能对比图
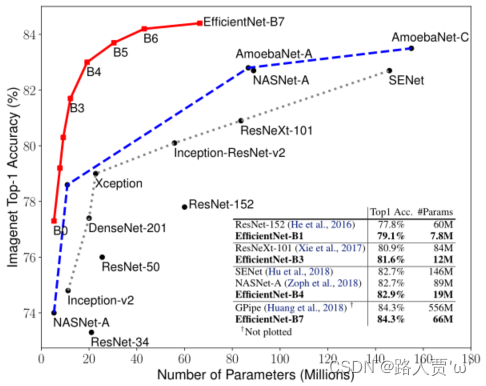
二、Related Work—相关工作
翻译
ConvNet Accuracy:自从 AlexNet(Krizhevsky 等人,2012 年)赢得 2012 年 ImageNet 竞赛以来,ConvNets 通过变得更大而变得越来越准确:而 2014 年 ImageNet 冠军 GoogleNet(Szegedy 等人,2015 年)实现了 74.8% 的 top-1 准确率,约为 6.8 M 个参数,2017 年 ImageNet 获胜者 SENet(Hu et al., 2018)在 145M 参数下达到了 82.7% 的 top-1 准确率。最近,GPipe (Huang et al., 2018) 使用 557M 参数进一步将最先进的 ImageNet top-1 验证准确率推到了 84.3%:它太大了,只能用专门的管道并行库进行训练通过划分网络并将每个部分分散到不同的加速器。虽然这些模型主要是为 ImageNet 设计的,但最近的研究表明,更好的 ImageNet 模型在各种迁移学习数据集(Kornblith 等人,2019 年)和其他计算机视觉任务(如对象检测)中也表现得更好(He 等人, 2016 年;谭等人,2019 年)。尽管更高的精度对于许多应用程序至关重要,但我们已经达到了硬件内存限制,因此进一步的精度提升需要更高的效率。
ConvNet Efficiency:深度卷积网络通常被过度参数化。模型压缩(Han 等人,2016 年;He 等人,2018 年;Yang 等人,2018 年)是一种通过以精度换取效率来减小模型大小的常用方法。随着手机变得无处不在,手工制作高效的移动尺寸 ConvNets 也很常见,例如 SqueezeNets(Iandola 等人,2016 年;Gholami 等人,2018 年)、MobileNets(Howard 等人,2017 年;Sandler 等人,2018 年)。 , 2018) 和 ShuffleNets (Zhang et al., 2018; Ma et al., 2018)。最近,神经架构搜索在设计高效的移动尺寸 ConvNet 方面变得越来越流行(Tan 等人,2019 年;Cai 等人,2019 年),并且通过广泛调整网络宽度、深度,实现了比手工制作的移动 ConvNets 更高的效率,卷积核类型和大小。然而,尚不清楚如何将这些技术应用于具有更大设计空间和更昂贵调整成本的更大模型。在本文中,我们旨在研究超越最先进精度的超大型 ConvNet 的模型效率。为了实现这个目标,我们求助于模型缩放。
Model Scaling:有多种方法可以针对不同的资源限制缩放 ConvNet:ResNet (He et al.,2016) 可以通过调整网络深度 (#layers) 缩小(例如,ResNet-18)或放大(例如,ResNet-200) ,而 WideResNet (Zagoruyko & Komodakis, 2016) 和 MobileNets (Howard et al., 2017) 可以按网络宽度 (#channels) 进行缩放。 众所周知,更大的输入图像尺寸将有助于提高准确性,但会带来更多 FLOPS 的开销。 尽管先前的研究(Raghu 等人,2017 年;Lin 和 Jegelka,2018 年;Sharir 和 Shashua,2018 年;Lu 等人,2018 年)表明网络深度和宽度对于 ConvNets 的表达能力都很重要,但它仍然是一个 如何有效地扩展 ConvNet 以实现更高的效率和准确性的开放性问题。 我们的工作系统地和实证地研究了网络宽度、深度和分辨率的所有三个维度的 ConvNet 缩放。
精读
ConvNet Accuracy—ConvNet的精度
- ConvNets近些年来一直通过变大而变得越来越准确,虽然更高的精度对于许多应用程序是至关重要的。
- 但过去的方法已经达到了硬件内存的限制,因此进一步提高精度需要更好的效率。
ConvNet Efficiency—ConvNet的效率
- 深度ConvNets经常被过度参数化。模型压缩是一种常见的方法,通过用准确性换取效率来减少模型的大小。
- 然而,此前的工作还不清楚如何将这些技术应用于具有更大设计空间和更昂贵成本的大型模型。
- 本文的目标是研究超过最先进精度的超大型卷积网络的模型效率。为了实现这一目标,本文采用了模型的缩放。
Model Scaling—模型缩放
- 尽管之前的研究表明,网络深度和宽度对ConvNets的表达能力都很重要,但如何有效地扩展ConvNet以实现更好的效率和准确性仍然是一个开放的问题。
- 本文研究了ConvNet在网络宽度、深度和分辨率三个维度上的扩展。
三、Compound Model Scaling—混合模型缩放
3.1 Problem Formulation—范式化问题
翻译
ConvNet 层 i 可以定义为一个函数:Yi=Fi(Xi),其中 Fi是算子,Yi 是输出张量,Xi 是输入张量,张量形状为 <H i , Wi , C i>^1,其中Hi和Wi 是空间维度,Ci 是通道维度。
ConvNet N 可以由 J 个组合层列表表示:。 在实践中,ConvNet 层通常被划分为多个阶段,每个阶段的所有层共享相同的架构:例如,ResNet (He et al., 2016) 有五个阶段,每个阶段的所有层都具有相同的卷积类型,除了 第一层执行下采样。因此,我们可以将ConvNet定义为:
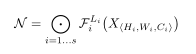
不像传统的卷积神经网络设计,总是聚焦于寻找最好的层数、结构,模型缩放则是在不改变基线模型结构的前提下对网络深度、宽度、分辨率进行扩展;一旦网络基础模型确定下来,缩放主要就是解决计算资源的约束问题;但每一层的搜索空间仍然很大;为了进一步减小搜索空间,本文将所有层都使用一个统一的缩放系数,目标就是在有限的计算资源限制下最大化提升模型精度,因此优化问题可以定义为: 其中d,w,r分别代表网络深度、宽度和分辨率的缩放系数。
精读
假设一个卷积层i 可以被定义为一个函数:Yi = Fi ( Xi )
其中的Xi表示输入的特征图,而Yi是输出特征矩阵,Fi就表示这i层的卷积操作。其中Xi的tensor形状为<Hi ,Wi ,Ci >,其中Hi与Wi为空间维度,Ci为通道维度。
而卷积网络可以由一系列这样的层结构组成:
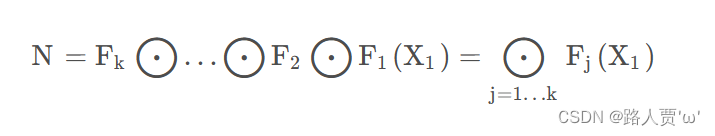
在实践中,ConvNet层往往被划分为多个阶段,每个阶段的所有层都具有相同的架构。
作者回顾了目前网络设计的套路,总结为以下的公式:
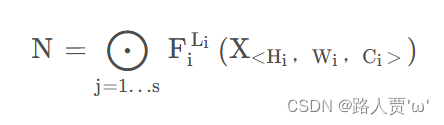
其中,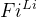
之前的网络设计注重模块化的设计,也就是对Fi的设计,比如ResNet中的Basic Block和Bottleneck Block。
但分别考虑每个阶段的变化,这个搜索空间无疑太大了,因此作者对整个模型采用一种统一的缩放策略,转化为一个优化问题,如下:
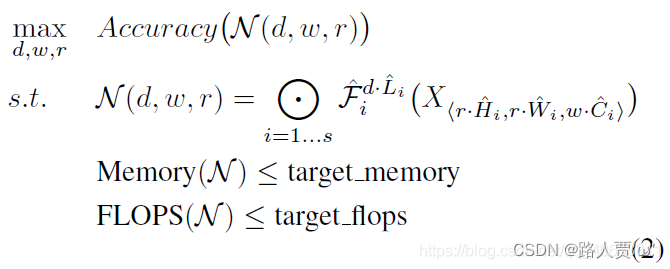
其中,d,w,r表示对宽度、深度、分辨率的缩放系数。
3.2 Scaling Dimensions—维度缩放
翻译
问题2的主要困难在于最优的d、w、r相互依赖,且各值在不同的资源约束下发生变化。由于这一困难,传统的方法主要在以下一个维度上缩放网络:
Depth ( d ): 缩放网络深度是许多卷积网最常用的方法。直觉是,更深的卷积神经可以捕捉到更丰富、更复杂的特征,并在新任务上很好地推广。然而,由于梯度消失问题,更深层次的网络也更难训练。尽管一些技术,如跳过连接和批处理归一化,缓解了训练问题,但非常深的网络的精度增益减少:例如,ResNet-1000具有与ResNet-101具有相似的精度,尽管它有更多的层。图3(中间)显示了我们对具有不同深度系数d的基线模型进行缩放的实证研究,进一步表明了非常深的ConvNets的精度回报递减。
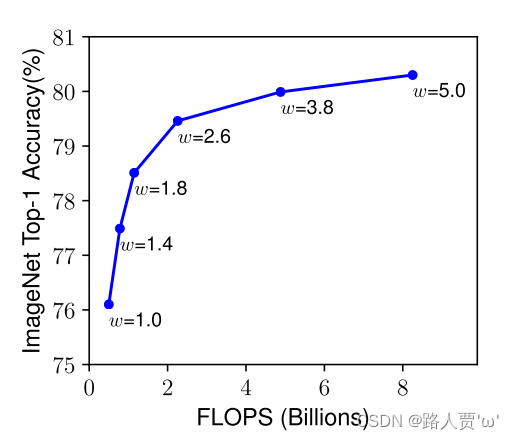
Width ( w ):缩放网络宽度通常用于小型模型,更广泛的网络往往能够捕获更细粒度的特征,并且更容易被训练。然而,非常宽但较浅的网络往往难以捕获更高层次的特征。我们在图3(左)中的经验结果显示,当网络越大,w变得越宽时,精度迅速饱和。
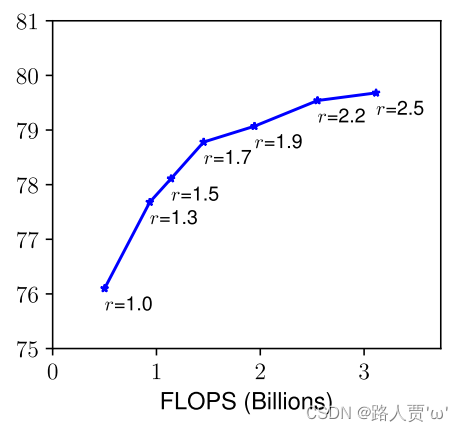
Resolution ( r ):对于更高分辨率的输入图像,ConvNets可以潜在地捕获更细粒度的模式。从早期的conv网络的224x224开始,现代的conv网络倾向于使用299x299(Szegedy等人,2016)或331x331(Zoph等人,2018)以获得更好的精度。最近,GPipe(Huangetal.,2018)以480x480的分辨率实现了最先进的ImageNet精度。更高的分辨率,如600x600,也被广泛用于目标检测ConvNets(He等人,2017;Lin等人,2017)。图3(右)显示了缩放网络分辨率的结果,其中更高的分辨率确实可以提高精度,但对于非常高的分辨率,精度增益会降低(r=1.0表示分辨率224x224,r=2.5表示分辨率560x560)。
Observation 1 – 放大网络宽度、深度或分辨率的任何维度都可以提高精度,但对于较大的模型,精度增益会降低。
精读
(1)Depth ( d )
缩放网络深度是一种常用的提高卷积网络精度的方法,但是由于梯度消失问题,更深层次的网络也更难训练。
下图显示了具有不同深度系数d的基线模型进行缩放的实证研究,表明了增加网络层数到一定深度时精度并不能随之增加。
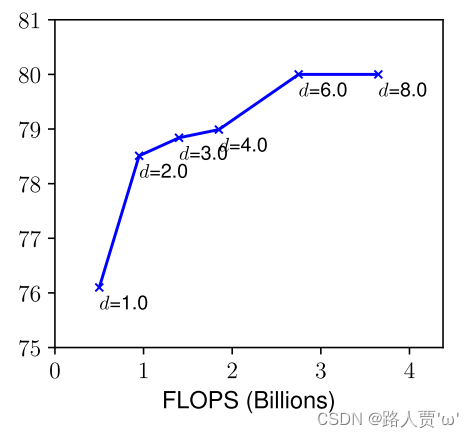
(2)Width ( w )
小型模型通常使用缩放网络宽度来提取更多的特征,然而,非常宽但较浅的网络往往难以捕获更高层次的特征。
下图结果显示,当网络越大,w变得越宽时,精度迅速饱和。
(3)Resolution ( r )
早期的图像大小以224×224开始,现在常使用299×299或者311×311。
最近的创新:480×480的分辨率和600×600的分辨率。
下图是缩放网络分辨率的结果,更高的分辨率的确提高了网络的精度,但对于非常高的分辨率来说,准确率的提高会减弱。
本文第一个结论: 扩大网络宽度、深度或分辨率的任何维度都能提高精确度,但对于更大的模型来说,精确度的提高会减弱。
3.3 Compound Scaling—混合缩放
翻译
我们凭经验观察到不同的缩放维度不是独立的。 直觉上,对于更高分辨率的图像,我们应该增加网络深度,这样更大的感受野可以帮助捕获更大图像中包含更多像素的相似特征。 相应地,我们也应该在分辨率较高时增加网络宽度,以便在高分辨率图像中以更多像素捕获更细粒度的图案。 这些直觉表明我们需要协调和平衡不同的缩放维度而不是传统的单维缩放。
为了验证我们的直觉,我们比较了不同网络深度和分辨率下的宽度缩放,如图 4 所示。如果我们只缩放网络宽度 w 而不改变深度 (d=1.0) 和分辨率 (r=1.0),精度会很快饱和。 随着更深 (d=2.0) 和更高分辨率 (r=2.0),宽度缩放在相同的 FLOPS 成本下实现了更好的精度。 这些结果使我们得出第二个观察结果:为了追求更好的精度和效率,在 ConvNet 缩放过程中平衡网络宽度、深度和分辨率的所有维度至关重要。
事实上,之前的一些工作(Zoph 等人,2018 年;Real 等人,2019 年)已经尝试任意平衡网络宽度和深度,但它们都需要繁琐的手动调整。
在本文中,我们提出了一种新的复合缩放方法,它使用复合系数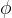
其中 α、β、γ 是可以通过小型网格搜索确定的常数。 直观地说,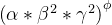
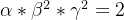
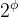
精读
对于更高分辨率的图像,应该增加网络深度,相应地,当分辨率更高时,也应该增加网络宽度。
猜想: 需要协调和平衡不同的缩放维度,而不是传统的单维缩放。
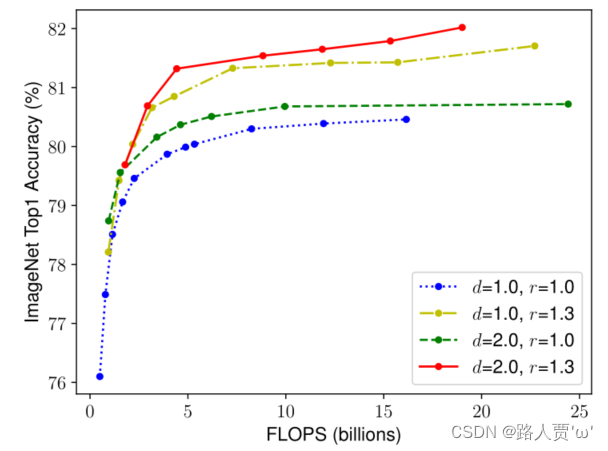
本文第二个结论: 为了追求更好的精度和效率,在连续网络缩放过程中平衡网络宽度、深度和分辨率的所有维度是至关重要的。
本文提出新的复合尺度方式
该方法利用复合系数φ来均匀尺度网络的宽度、深度和分辨率:
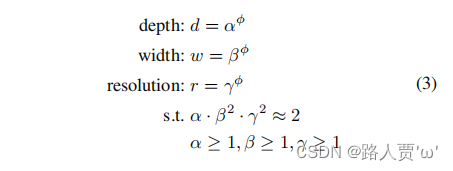
α,β,γ是可以通过小网格搜索确定的常数。
φ是一个用户指定的系数,它控制有多少资源可用于模型缩放,而α、β、γ则指定如何将这些额外的资源分别分配给网络宽度、深度和分辨率。
四、EfficientNet Architecture—EfficientNet结构
翻译
由于模型缩放不会改变基线网络中的层操作符,因此拥有一个良好的基线网络也是至关重要的。我们将使用现有的convnet来评估我们的缩放方法,但为了更好地证明我们的缩放方法的有效性,我们还开发了一个新的移动尺寸基线,称为EffificientNet。
受(Tanetal.,2019)的启发,我们通过利用多目标神经体系结构搜索来开发我们的基线网络,从而优化了准确性和失败。特别,我们使用相同的搜索空间(Tanetal.,2019),并使用作为优化目标,ACC(m)和FLOPS(m)表示模型m的准确性和运算次数,T是目标运算次数和w=-0.07是一个超参数控制精度和运算次数之间的权衡。不像(Tan等人,2019;Cai等人,2019),这里我们优化了运算规模,而不是延迟,因为我们没有针对任何特定的硬件设备。我们的搜索产生了一个高效的网络,我们称之为EffificientNet-B0.。由于我们使用了与(Tanetal.,2019)相同的搜索空间,因此该架构类似于MnasNotably通过直接围绕一个大型模型搜索α、β、γ,有可能获得更好的性能,但在较大的模型上,搜索成本变得更加昂贵。我们的方法通过在小基线网络上只进行一次搜索(步骤1)来解决这个问题,然后对所有其他模型使用相同的缩放系数(步骤2)来解决这个问题。
从EffificientNet-B0开始,我们应用我们的复合缩放方法,通过两个步骤进行扩展:
步骤1:我们首先修复了φ=1,假设可用资源的数量增加了一倍,并根据公式2和公式3对α、β、γ进行了一个小的网格搜索。特别地,在=2的约束下,EffificientNet-B0的最佳值为α=1.2,β=1.1,γ=1.15。
步骤2:然后我们将α、β、γ固定为常数,并使用公式3放大不同φ的基线网络,得到EffificientNet-b1到B7(详见表2)。
精读
EfficientNet-B0 baseline网络结构
EfficientNet-B0 baseline 网络的结构配置如下图所示:
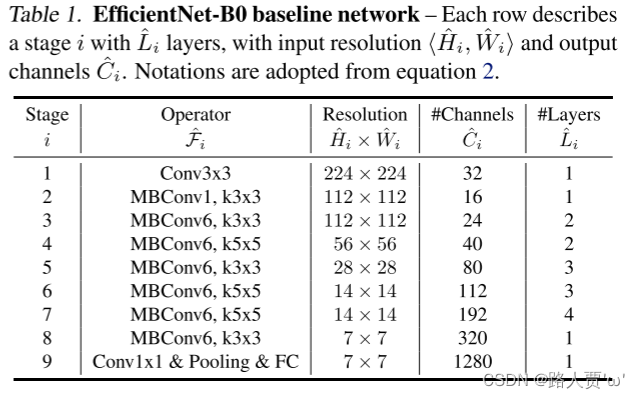
在 B0 中一共分为 9 个 stage,表中的卷积层后默认都跟有 BN 以及 Swish 激活函数。stage 1 就是一个 3×3 的卷积层。对于 stage 2 到 stage 8 就是在重复堆叠 MBConv。
MBConv 模块

(1)首先是一个 1×1 卷积用于升维,其输出 channel 是输入 channel 的 n 倍。
(2)紧接着通过一个 DW 卷积。
(3)然后通过一个 SE 模块,使用注意力机制调整特征矩阵。
(4)之后再通过 1×1 卷积进行降维。注意这里只有 BN,没有 swish 激活函数(其实就是对应线性激活函数)。
(5)最后跟一个dropout层。
注意的问题:
- 第一个1x1卷积升维后,输出的特征矩阵channel是输入特征矩阵channel的n倍,而这个n对应的就是Tabel1中的MBConv后面接的数字,当n为1时,实际上是没用这个1x1卷积的(不需要升维)。
- 第一个1x1卷积、DW后面都是接BN + Swish,而最后的1x1降维卷积是没用激活函数的,要用Identity函数。
- 这里的Droupout用的是Drop path,而不是传统的Dropout。
- 关于shortcut连接,当且仅当输入MBConv结构的特征矩阵和输出的特征矩阵的shape相同且DW卷积的stride=1时才使用。
详细的结构图如下:
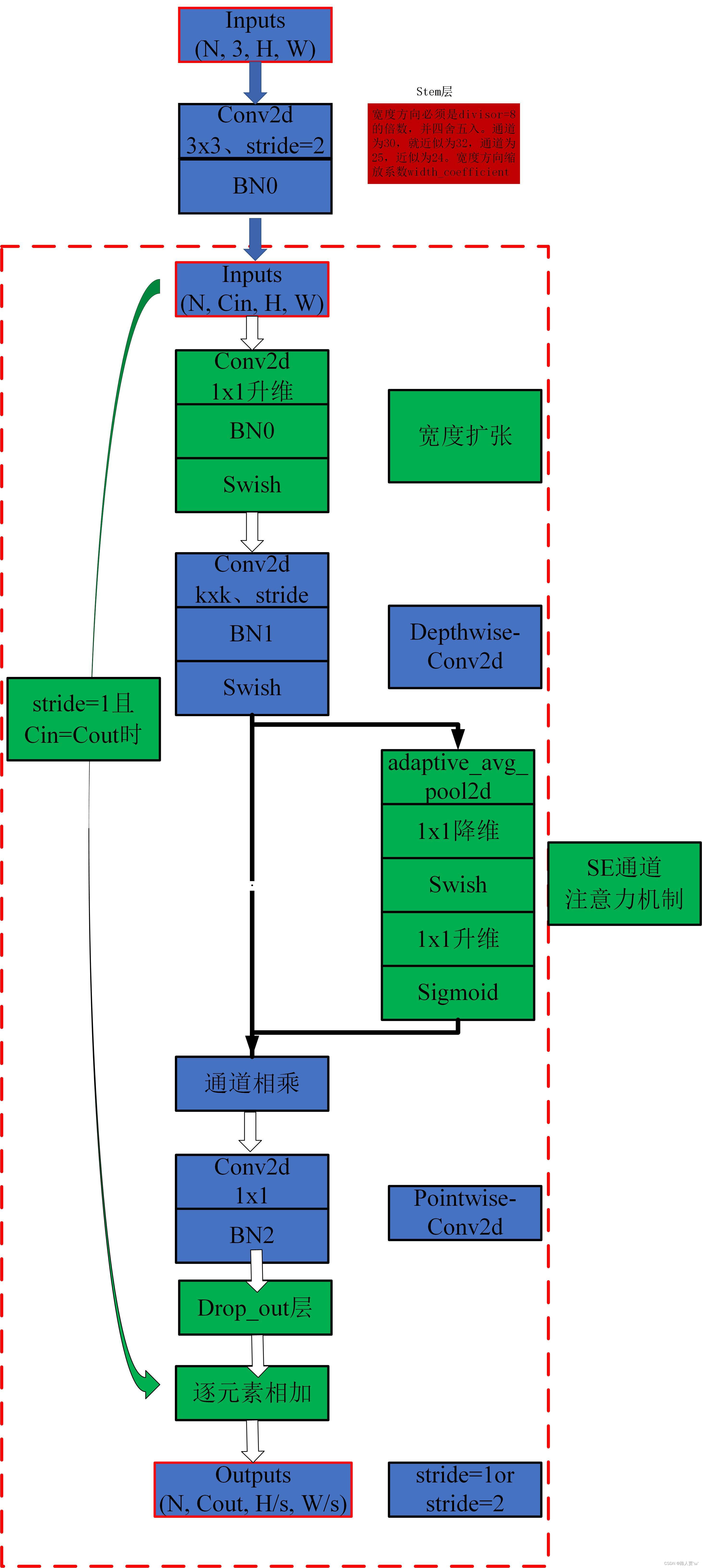
(图片来源:EfficentNet详解之MBConvBlock)
五、Experiments—实验
5.1 Scaling Up MobileNets and ResNets—扩大MobileNets与ResNets
翻译
作为概念的证明,我们首先将我们的尺度方法应用于广泛使用的MobileNets和ResNet。表3显示了以不同方式缩放它们的ImageNet结果。与其他单维缩放方法相比,我们的复合缩放方法提高了所有这些模型的精度,这表明我们提出的缩放方法对一般现有的卷积网的有效性。
精读
表3展示了缩放MobileNet和ResNet的结果
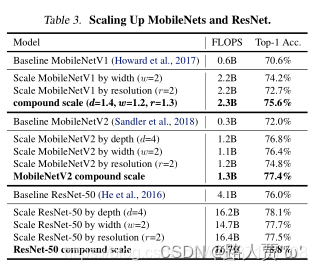
结论:与其他单维缩放方法相比,这个复合缩放方法提高了所有这些模型的准确性,表明了缩放方法对一般现有ConvNets的有效性。
5.2 ImageNet Results for EfficientNet—在ImageNet上的测试
翻译
我们在ImageNet上训练了类似的效率网模型,如(Tan等人,2019年):RMSProp优化器,衰减0.9,动量0.9;批范数动量0.99; 权重量衰减1e-5;初始学习率为0.256,每2.4epochs衰减0.97。我们还使用SiLU(Swish-1)激活、自动增强和随机深度,dropout层生存概率为0.8。众所周知,更大的模型需要更多的正则化,我们将dropout比率从EffificientNet-B0的0.2线性增加到B7的0.5。我们保留了从训练集中随机抽取的25k张图像作为一个小集,并在这个小集上执行EarilyStopping;然后,我们在原始验证集上评估EarlyStopping的检查点,以报告最终验证的准确性
表2显示了从相同的基线效率网络模型中缩放的所有效率网络模型的性能。我们的效率网模型通常比其他精度相似的网络参数和失败少一个数量级。特别是,我们的EffificientNet-b7在66M参数和37b计算规模时达到了84.3%的top1精度,准确度更高,但比之前最好的GPipe小8.4倍(Huangetal.,2018)。这些收益来自于更好的架构、更好的可伸缩性和为Efficientnet定制的更好的训练设置。
精读
训练参数:
- 优化器: RMSProp优化器
- 衰减率: 0.9
- 动量: 0.9
- 批范数动量: 0.99
- 权重量衰减: 1e-5
- 初始学习率: 0.256
- 衰减率/epoch: 每2.4epochs衰减0.97
表2展示了从相同baseline EfficientNet-B0缩放的所有EfficientNet模型的性能
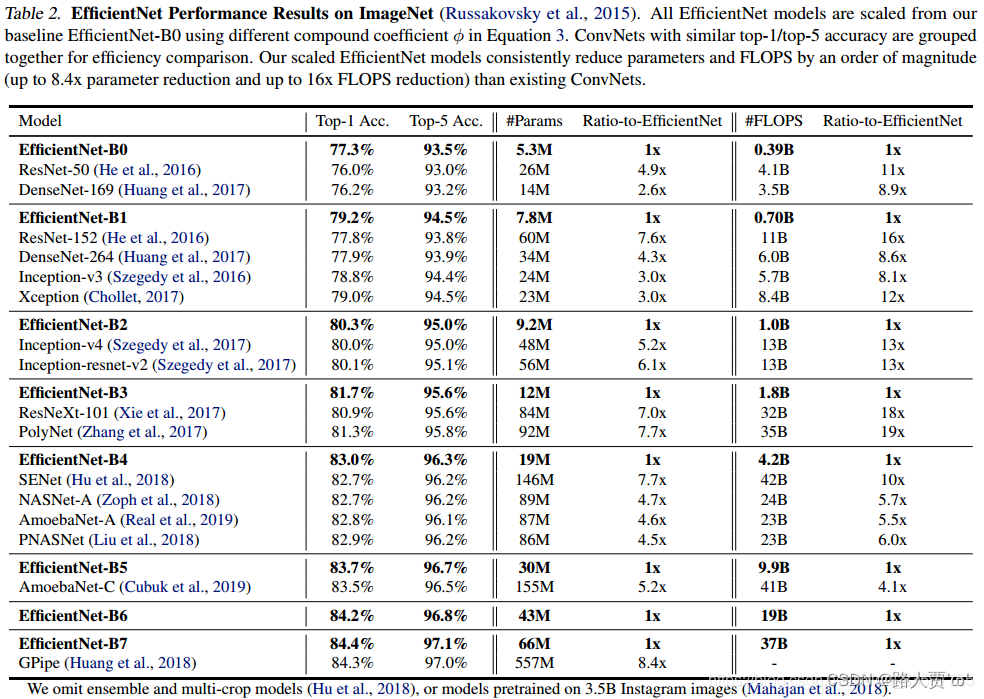
结论:通过对比可看出我们的网络模型比其他流行的网络模型精度更高,参数量更少,速度更快
图5显示了代表性ConvNets的参数-精度和FLOPS-精度曲线
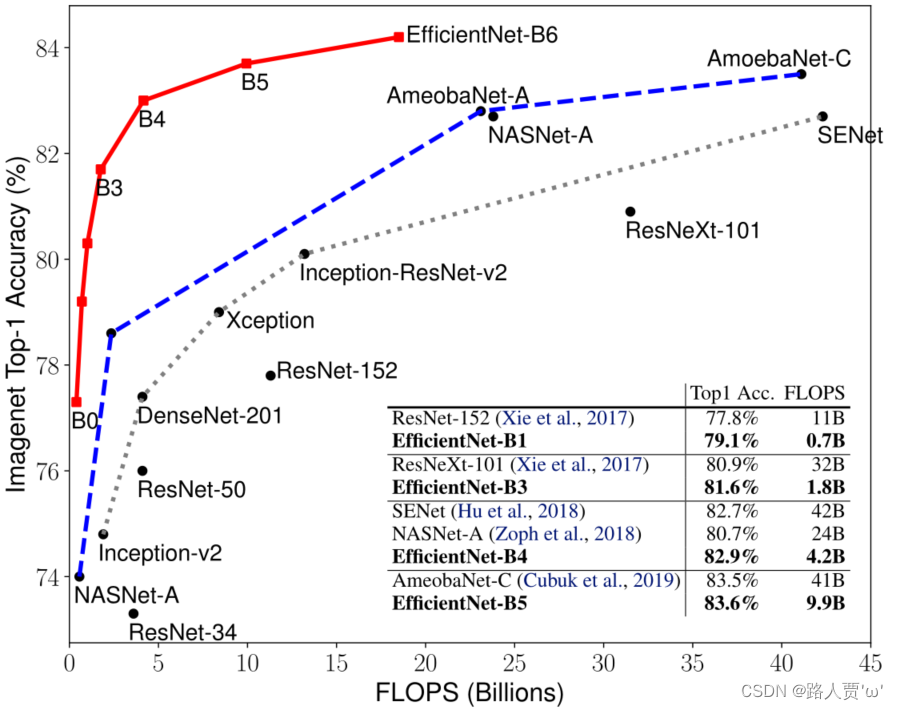
结论:与其他ConvNets相比,本文的按比例排列的EfficientNet模型以更少的参数和FLOPS获得了更好的精度。
表4测量了几个有代表性的CovNets在实际CPU上的推理延迟

结论:表明本文的EfficientNets在实际硬件上确实很快速
5.3 Transfer Learning Results for EfficientNet—Efficient迁移学习
翻译
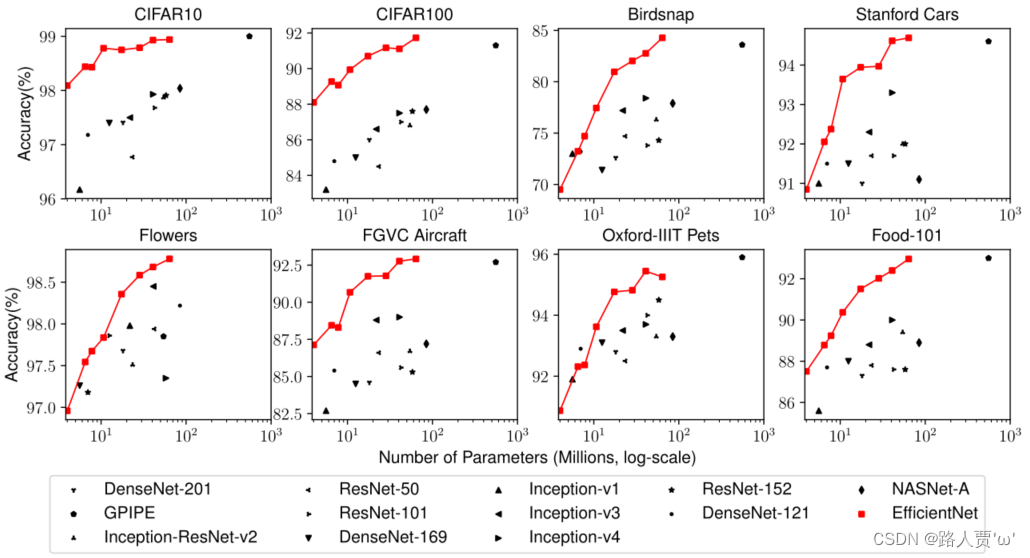
我们还在一系列常用的迁移学习数据集上评估了我们的 EfficientNet,如表 6 所示。我们从 (Kornblith et al., 2019) 和 (Huang et al., 2018) 中借用了相同的训练设置,它们采用 ImageNet 预训练检查点并在新数据集上进行微调。表 5 显示了迁移学习的性能:
(1) 与 NASNet-A (Zophet al., 2018) 和 Inception-v4 (Szegedy et al., 2017) 等公开可用模型相比,我们的 EfficientNet 模型以 4.7 倍的平均(最高 21 倍)参数实现了更好的精度减少。
(2) 与最先进的模型相比,包括动态合成训练数据的 DAT (Ngiam et al., 2018) 和 GPipe (Huang
et al., 2018) 使用专门的管道并行性进行训练,我们的 EfficientNet 模型在 8 个数据集中的 5 个中仍然超过其精度,但使用的参数减少了 9.6 倍 图 6 比较了各种模型的精度-参数曲线。
总的来说,我们的 EfficientNets 始终以比现有模型少一个数量级的参数实现更好的准确性,包括 ResNet(He 等人,2016)、DenseNet(Huang 等人,2017)、Inception(Szegedyet al.,2017)、和 NASNet(Zoph 等人,2018 年)。
精读
表6表现了在一些迁移学习的数据集上对EfficientNet进行了评估
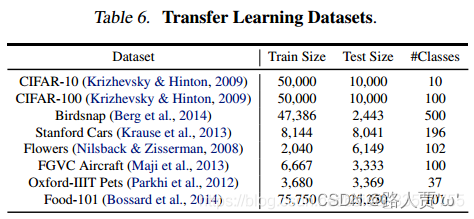
表5显示了迁移学习的性能
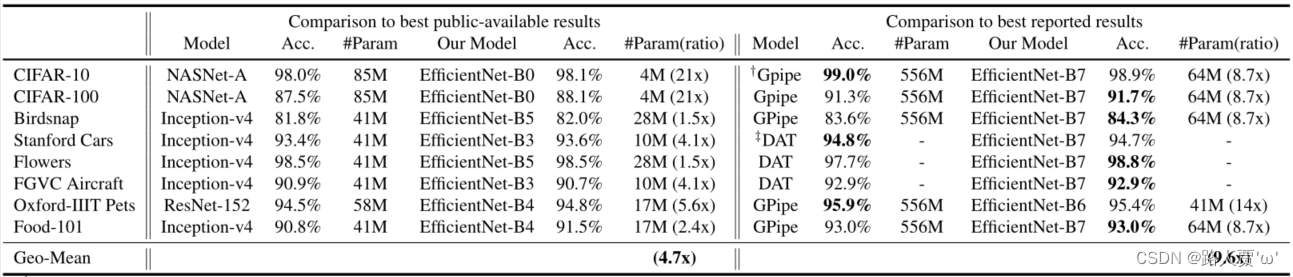
图6比较了各种模型的准确性-参数曲线
结论:本文的EfficientNets在参数较少的情况下,始终比现有的模型取得更好的准确性。
六、Discussion—讨论
翻译
为了区分我们提出的缩放方法对 EfficientNet 架构的贡献,图 8 比较了相同 EfficientNet-B0 基线网络的不同缩放方法的 ImageNet 性能。一般来说,所有缩放方法都以更多的 FLOPS 为代价来提高准确性,但我们的复合缩放方法可以比其他单维缩放方法进一步提高准确性,最多可提高 2.5%,这表明我们提出的复合缩放方法的重要性。为了进一步理解为什么我们的复合缩放方法比其他方法更好,图 7 比较了几个具有不同缩放方法的代表性模型的类激活图 (Zhou et al., 2016)。所有这些模型都从相同的基线进行缩放,其统计数据如表 7 所示。图像是从 ImageNet 验证集中随机挑选的。如图所示,复合缩放的模型倾向于关注具有更多物体细节的相关区域,而其他模型要么缺乏物体细节,要么无法捕捉图像中的所有物体。
精读
图8比较了不同缩放方法对同一EfficientNet-B0基线网络的ImageNet性能
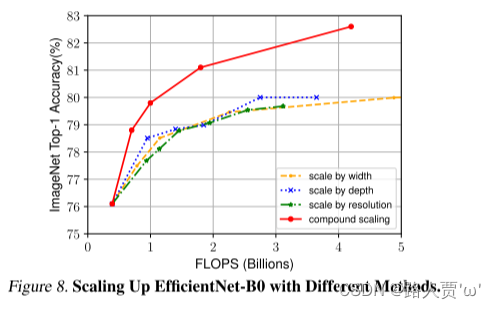
结论:之前的所有的缩放方法都是以更多的FLOPS为代价来提高准确性,但是本文的复合缩放方法可以进一步提高准确性。
图7比较了几个具有代表性的模型的不同缩放方法的类激活图
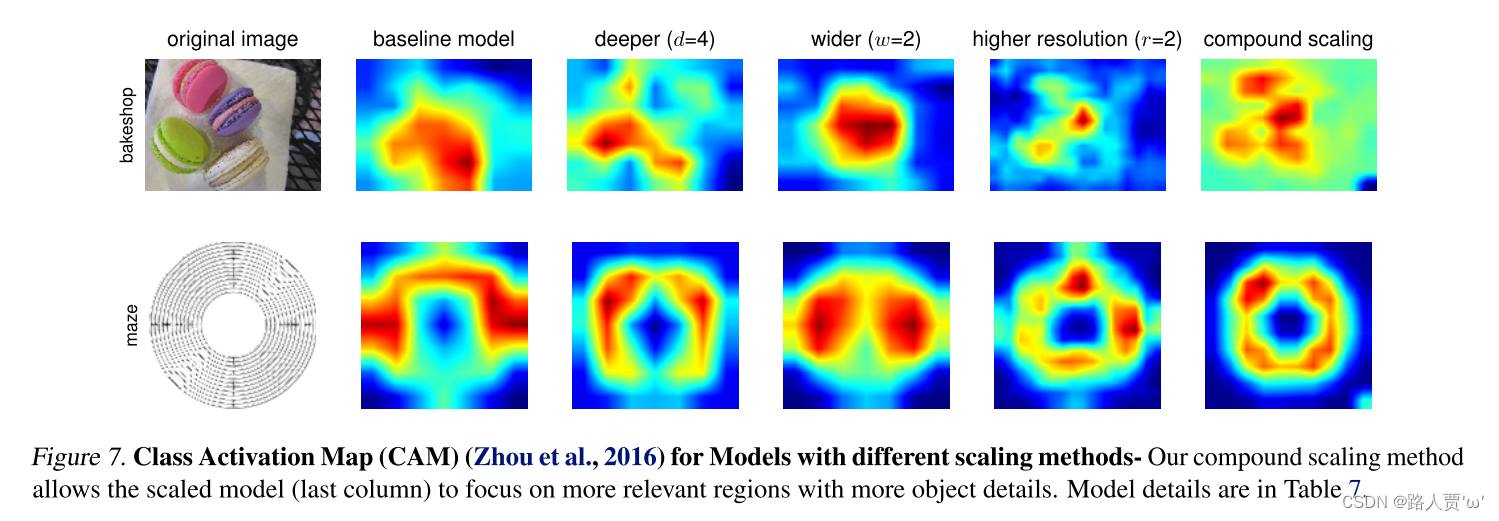
结论:复合缩放的模型倾向于关注具有更多物体细节的相关区域,而其他模型要么缺乏物体细节,要么无法捕获图像中的所有物体。
七、Conclusion—总结
翻译
在本文中,我们系统地研究了 ConvNet 缩放,并发现仔细平衡网络宽度、深度和分辨率是一个重要但缺失的部分,这阻碍了我们提高准确性和效率。为了解决这个问题,我们提出了一种简单高效的复合缩放方法,它使我们能够以更原则的方式轻松地将基线 ConvNet 扩展到任何目标资源约束,同时保持模型效率。在这种复合缩放方法的支持下,我们证明了移动大小的 EfficientNet 模型可以非常有效地扩展,在 ImageNet 和五个常用的传输上以更少的参数和 FLOPS 数量级超过最先进的精度 学习数据集。
精读
这篇论文作者系统地研究ConvNet的缩放,并确定仔细平衡网络宽度、深度和分辨率的重要性。
因此作者提出了一种简单而高效的复合缩放方法,使我们能够以更原则的方式轻松地将基线ConvNet缩放到任何目标资源约束,同时保持模型效率。
🌟代码实现
import torch.nn as nn
from typing import Optional, Callable
from torch import Tensor
from torch.nn import functional as F
from collections import OrderedDict
from functools import partial
import math
import copy
import torch
def _make_divisible(ch, divisor=8, min_ch=None):
"""
将ch调整到最近的8的倍数
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNActivation(nn.Sequential):
def __init__(self, in_planes: int, out_planes: int, kernel_size: int = 3,
stride: int = 1, groups: int = 1, # 正常卷积还是DW卷积
norm_layer: Optional[Callable[..., nn.Module]] = None, # BN
activation_layer: Optional[Callable[..., nn.Module]] = None):
padding = (kernel_size - 1) // 2
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if activation_layer is None:
activation_layer = nn.SiLU # alias Swish (torch>=1.7)
super(ConvBNActivation, self).__init__(
nn.Conv2d(in_channels=in_planes,
out_channels=out_planes,
kernel_size=kernel_size,
stride=stride,
padding=padding,
groups=groups,
bias=False),
norm_layer(out_planes),
activation_layer())
class SqueezeExcitation(nn.Module):
def __init__(self, input_c: int, expand_c: int, squeeze_factor: int = 4):
"""
:params input_c: MBConv中的输入feature map的channel
:params expand_c: MBConv中DW卷积的输出feature map的channel=第一个1x1卷积升维后的channel
:squeeze_factor: 第一个全连接层降维因子
"""
super(SqueezeExcitation, self).__init__()
squeeze_c = input_c // squeeze_factor # 第一个全连接层的节点个数
self.fc1 = nn.Conv2d(expand_c, squeeze_c, 1) # 使用卷积代替全连接层 效果一样 降维
self.ac1 = nn.SiLU() # Swish
self.fc2 = nn.Conv2d(squeeze_c, expand_c, 1) # 升维
self.ac2 = nn.Sigmoid()
def forward(self, x: Tensor) -> Tensor:
# 对每个channel进行全局平均池化 注意力机制 得到每个channel对应的权重
scale = F.adaptive_avg_pool2d(x, output_size=(1, 1))
# 再通过不断学习来优化权重
scale = self.fc1(scale)
scale = self.ac1(scale)
scale = self.fc2(scale)
scale = self.ac2(scale)
return scale * x
def drop_path(x, drop_prob: float = 0., traing: bool = False):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
This function is taken from the rwightman.
It can be seen here: DropBlock, DropPath
https://github.com/rwightman/pytorch-image-models/blob/master/timm/models/layers/drop.py#L140
"""
if drop_prob == 0. or not traing:
return x
keep_prob = 1 - drop_prob
shape = (x.shape[0],) + (1,) * (x.ndim - 1)
random_tensor = keep_prob + torch.rand(shape, dtype=x.dtype, device=x.device)
random_tensor.floor()
output = x.div(keep_prob) * random_tensor
return output
class DropPath(nn.Module):
"""
Drop paths (Stochastic Depth) per sample (when applied in main path of residual blocks).
"Deep Networks with Stochastic Depth", https://arxiv.org/pdf/1603.09382.pdf
"""
def __init__(self, drop_prob=None):
super(DropPath, self).__init__()
self.drop_prob = drop_prob
def forward(self, x):
return drop_path(x, self.drop_prob, self.training)
class MBConvConfig:
def __init__(self, kernel: int, in_planes: int, out_planes: int, expanded_ratio: int,
stride: int, use_se: bool, drop_rate: float, index: str, width_coefficient: float):
"""
params: kernel: MBConv中的DW卷积的kernel_size(对应图片中的k)
params: in_planes: MBConv模块的输入feature map的channel
params: out_planes: MBConv模块的输出feature map的channel
params: expanded_ratio: MBConv模块的第一个1x1卷积层的expand_rate 升维
params: stride: DW卷积的stride
params: use_se: 是否使用se模块 全部是True
params: drop_rate: MBConv模块的Dropout层的随机失活比率
params: index: 记录当前MBConv模块的名称 1a 2a 2b
params: width_coefficient: 网络宽度方向上的倍率因子 论文中的w
"""
self.in_planes = self.adjust_channels(in_planes, width_coefficient)
self.kernel = kernel
self.expanded_planes = self.in_planes * expanded_ratio # MBConv模块的第一个1x1卷积层的输出channel
self.out_planes = self.adjust_channels(out_planes, width_coefficient)
self.use_se = use_se
self.stride = stride
self.drop_rate = drop_rate
self.index = index
@staticmethod
def adjust_channels(channels: int, width_coefficient: float):
# 将channel*宽度倍率因子,再调整到8的整数倍
return _make_divisible(channels * width_coefficient, 8)
class MBConv(nn.Module):
def __init__(self, cnf: MBConvConfig, norm_layer: Callable[..., nn.Module]):
"""
params: cnf: MBConv层配置文件
params: norm_layer: BN结构
"""
super(MBConv, self).__init__()
if cnf.stride not in [1, 2]:
raise ValueError("illegal stride value.")
# 只有再DW卷积的stride=1 且 输入channel=输出channel才能进行shortcut连接
self.use_shortcut = (cnf.stride == 1 and cnf.in_planes == cnf.out_planes)
layers = OrderedDict() # 依次存储MBConv中的结构
activation_layer = nn.SiLU
# 第一个1x1卷积层 升维
# 只有当expanded_ratio=1时,expanded_planes=in_planes,没有升维,所以不需要这个1x1卷积层
if cnf.expanded_planes != cnf.in_planes:
layers.update({"expand_conv": ConvBNActivation(cnf.in_planes,
cnf.expanded_planes,
kernel_size=1,
norm_layer=norm_layer, # BN
activation_layer=activation_layer)}) # Swish
# DW卷积 groups=channel
layers.update({"dwconv": ConvBNActivation(cnf.expanded_planes,
cnf.expanded_planes,
kernel_size=cnf.kernel,
stride=cnf.stride,
groups=cnf.expanded_planes,
norm_layer=norm_layer, # BN
activation_layer=activation_layer)}) # Swish
# SE模块
if cnf.use_se:
layers.update({"se": SqueezeExcitation(cnf.in_planes,
cnf.expanded_planes)})
# 最后1x1卷积层
layers.update({"project_conv": ConvBNActivation(cnf.expanded_planes,
cnf.out_planes,
kernel_size=1,
norm_layer=norm_layer, # BN
activation_layer=nn.Identity)}) # Identity
self.block = nn.Sequential(layers)
self.out_channels = cnf.out_planes
self.is_strided = cnf.stride > 1 # 似乎没什么用
# 只有在使用shortcut连接时才使用dropout层
if cnf.drop_rate > 0 and self.use_shortcut:
# self.dropout = nn.Dropout2d(p=cnf.drop_rate, inplace=True)
self.dropout = DropPath(cnf.drop_rate)
else:
self.dropout = nn.Identity()
def forward(self, x: Tensor) -> Tensor:
result = self.block(x)
result = self.dropout(result)
if self.use_shortcut:
result += x
return result
class EfficientNet(nn.Module):
def __init__(self, width_coefficient: float, depth_coefficient: float, num_classes: int = 1000,
dropout_rate: float = 0.2, drop_connect_rate: float = 0.2,
block: Optional[Callable[..., nn.Module]] = None,
norm_layer: Optional[Callable[..., nn.Module]] = None):
"""
params: width_coefficient: 网络宽度上的倍率因子 对应论文中的 w
params: depth_coefficient: 网络深度上的倍率因子 对应论文中的 d
params: num_classes: 分类的类别个数
params: dropout_rate: stage9的FC层前面的Dropout的随即失活比率
params: drop_connect_rate: MBConv模块的Dropout层的随机失活比率 从0慢慢增长到0.2
params: block: MBConv模块
params: norm_layer: 普通的BN结构
"""
super(EfficientNet, self).__init__()
# 默认的B0网络配置文件 后面B1-B7都是在这个基础上乘以相应的深度、宽度、分辨率倍率因子
# stage2 - stage8
# kernel_size, in_channel, out_channel, exp_ratio, strides, use_SE, drop_connect_rate, repeats
# kernel_size: MBConv后面写的knxn
# in_channel/out_channel: 当前stage的第一个MBConv的输入/输出feature map的channel
# exp_ratio: 第一个1x1卷积的膨胀率 对应当前MBConvn
# strides: 当前stage的第一个
# use_SE: 默认每个stage都使用SE模块
# drop_connect_rate: MBConv模块的Dropout层的随机失活比率 选默认都是0.2 后面再调整
# repeats: MBConv在当前stage中重复的次数
default_cnf = [[3, 32, 16, 1, 1, True, drop_connect_rate, 1],
[3, 16, 24, 6, 2, True, drop_connect_rate, 2],
[5, 24, 40, 6, 2, True, drop_connect_rate, 2],
[3, 40, 80, 6, 2, True, drop_connect_rate, 3],
[5, 80, 112, 6, 1, True, drop_connect_rate, 3],
[5, 112, 192, 6, 2, True, drop_connect_rate, 4],
[3, 192, 320, 6, 1, True, drop_connect_rate, 1]]
def round_repeats(repeats):
# depth_coefficient代表depth维度上的倍率因子(仅针对Stage2到Stage8)
# 通过这个函数用depth_coefficient倍率因子动态的调整网络的深度(MBConv的重复次数)
return int(math.ceil(depth_coefficient * repeats))
if block is None:
block = MBConv
if norm_layer is None:
# patial方法搭建层结构,下次使用就不需要再传eps和momentum这两个参数了 会默认传入这两个值
norm_layer = partial(nn.BatchNorm2d, eps=1e-3, momentum=0.1)
# 通过这个函数用width_coefficient倍率因子动态的调整网络的宽度(channel)
# 具体做法: 将channel*宽度倍率因子,再调整到8的整数倍
adjust_channels = partial(MBConvConfig.adjust_channels, width_coefficient=width_coefficient)
# 初始化单个MB_config
MB_config = partial(MBConvConfig, width_coefficient=width_coefficient)
# 得到stage2-stage8所有MB模块的配置信息
b = 0 # 用于调整drop_connect_rate
num_blocks = float(sum(round_repeats(i[-1]) for i in default_cnf)) # 统计所以MB模块的重复次数
MBConv_configs = [] # 存放所以MB模块的配置文件
for stage, args in enumerate(default_cnf): # 遍历每个stage
cnf = copy.copy(args)
for i in range(round_repeats(cnf.pop(-1))): # 遍历每个stage中的MB模块
if i > 0:
cnf[-3] = 1 # 当i>0时,stride=1
cnf[1] = cnf[2] # 当i>0时,输入channel=输出channel=第一个MB模块的输出channel
# cnf[-1] *= b / num_blocks # update drop_connect_rate
cnf[-1] = args[-2] * b / num_blocks
index = str(stage + 1) + chr(i + 97) # 记录当前MB是属于第几个stage中的第几个MB结构
MBConv_configs.append(MB_config(*cnf, index))
b += 1
# 开始搭建整体网络结构
layers = OrderedDict()
# stage1
layers.update({"stem_conv": ConvBNActivation(in_planes=3,
out_planes=adjust_channels(32), # 通过width倍率因子调整
kernel_size=3,
stride=2,
norm_layer=norm_layer)})
# stage2-stage8
for cnf in MBConv_configs:
layers.update({cnf.index: block(cnf, norm_layer)})
# stage9
last_conv_input_c = MBConv_configs[-1].out_planes
last_conv_output_c = adjust_channels(1280) # 通过width倍率因子调整
layers.update({"top": ConvBNActivation(in_planes=last_conv_input_c,
out_planes=last_conv_output_c,
kernel_size=1,
norm_layer=norm_layer)})
self.features = nn.Sequential(layers)
self.avgpool = nn.AdaptiveAvgPool2d(1)
classifier = []
if dropout_rate > 0:
classifier.append(nn.Dropout(p=dropout_rate, inplace=True))
classifier.append(nn.Linear(last_conv_output_c, num_classes))
self.classifier = nn.Sequential(*classifier)
# 初始化权重
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out")
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x: Tensor) -> Tensor:
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
def efficientnet_b0(num_classes=1000):
# input image size 224x224
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.0,
dropout_rate=0.2,
num_classes=num_classes)
def efficientnet_b1(num_classes=1000):
# input image size 240x240
return EfficientNet(width_coefficient=1.0,
depth_coefficient=1.1,
dropout_rate=0.2,
num_classes=num_classes)
def efficientnet_b2(num_classes=1000):
# input image size 260x260
return EfficientNet(width_coefficient=1.1,
depth_coefficient=1.2,
dropout_rate=0.3,
num_classes=num_classes)
def efficientnet_b3(num_classes=1000):
# input image size 300x300
return EfficientNet(width_coefficient=1.2,
depth_coefficient=1.4,
dropout_rate=0.3,
num_classes=num_classes)
def efficientnet_b4(num_classes=1000):
# input image size 380x380
return EfficientNet(width_coefficient=1.4,
depth_coefficient=1.8,
dropout_rate=0.4,
num_classes=num_classes)
def efficientnet_b5(num_classes=1000):
# input image size 456x456
return EfficientNet(width_coefficient=1.6,
depth_coefficient=2.2,
dropout_rate=0.4,
num_classes=num_classes)
def efficientnet_b6(num_classes=1000):
# input image size 528x528
return EfficientNet(width_coefficient=1.8,
depth_coefficient=2.6,
dropout_rate=0.5,
num_classes=num_classes)
def efficientnet_b7(num_classes=1000):
# input image size 600x600
return EfficientNet(width_coefficient=2.0,
depth_coefficient=3.1,
dropout_rate=0.5,
num_classes=num_classes)
