CUDA Stream
This section describes static aspects of the CUSW_UNIT_STREAM unit’s architecture.
OVerview of software element architechure
和stream相关的其它Unit主要有Channel,Sync,Memmgr
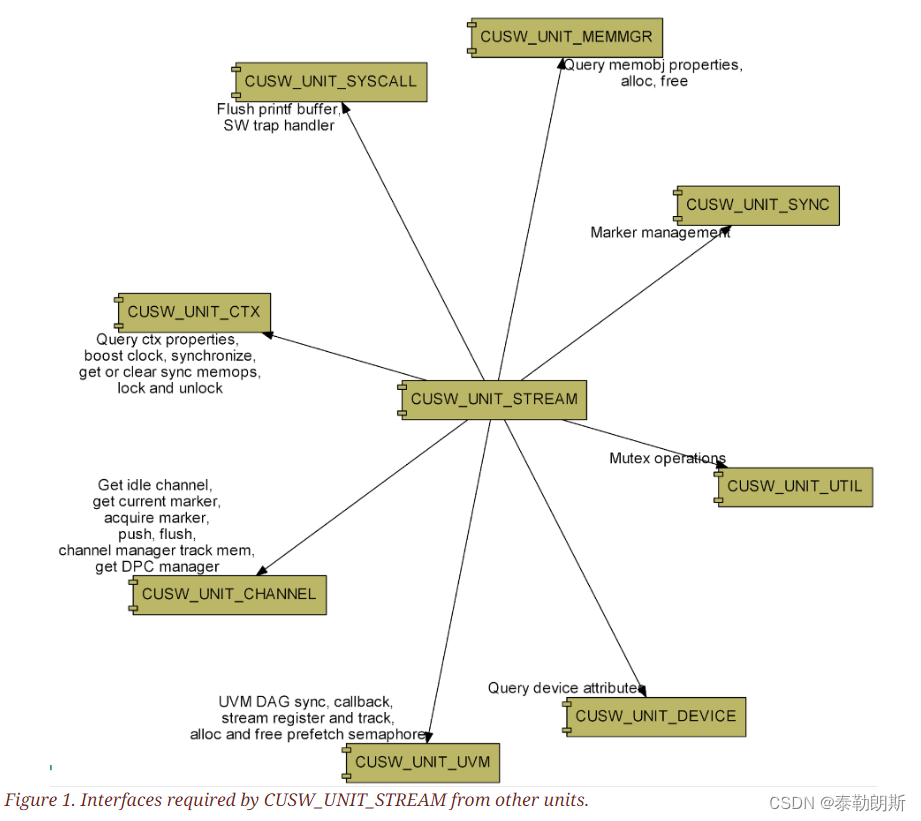
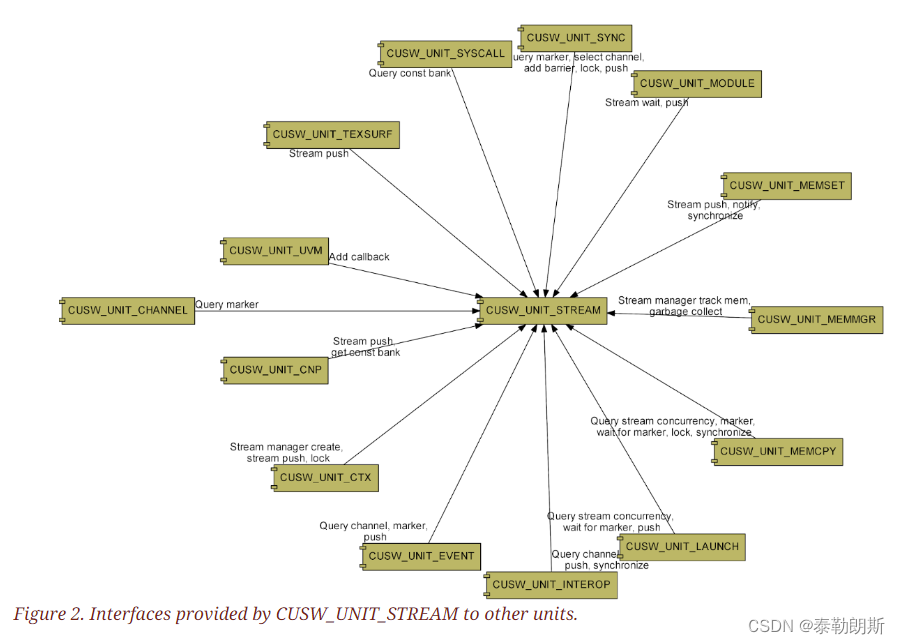
Abstractions
Stream
A CUDA stream is a software FIFO queue that allows commands like kernel launch and memcpy to be enqueued in it. The enqueued commands are always executed in the order in which they were enqueued into the stream. This ordering is also referred to as the stream order.
A stream allows following basic operations: * Create and destroy a stream. * Enqueue a wait in the stream for a given marker, a CPU semaphore, or a CUDA event. * Enqueue a wait in one stream on the last work enqueued in another stream. * Synchronize the stream on the CPU i.e. block the calling CPU thread till all work on the stream is done. * Add a CPU callback to the stream. A user-provided callback function is called when the stream execution reaches the callback position in the stream. * Attach a managed memory allocation (UVM memory object) to a stream. * Query stream properties.
Stream Handle
Streams at the CUDA API level are represented using opaque handles. These handles need to be mapped to the driver internal stream structure before the driver can use them.
The CUDA API allows users to explicitly create streams and get a CUDA API level handle. It also allows using implicit streams for enqueueing commands. For the implicit stream there is no API-level handle.
A stream handle can be converted to and from the internal stream handle (stream struct pointer) used within the CUDA driver.
Explicit stream handles map directly to a corresponding internal stream objects. Implicit stream handle maps to either the context wide implicit stream (the null stream) or to a per-thread null stream stored in the thread local storage.
Stream Manager
Stream manager creates and maintains a pool of streams. It also maps commands from a stream to different channels.
To enqueue commands in a stream the caller has to: 1. Begin stream push to get a channel to push commands on. 2. Push commands to the channel. 3. End the stream push.
Stream manager exposes the following additional functions: * Create and destroy stream manager for a context. * Track specified memory objects for a stream push. * Make space in a channel to push commands.
Func
Stream order
Each stream remembers a marker for previous work pushed on it. This marker is acquired before pushing the next work in the stream. This ensures that the stream order is maintained.
Stream Push
Since stream order is in-order it is beneficial to push one stream’s work on the same channel that the stream last used. On the other hand, different streams are independent of each other so enqueueing work from different streams in different channels lets their work run in parallel.
Stream Pool
The pool of streams is used to allocate and deallocate streams. The deallocated streams are put on a free list and reused for future allocations as far as possible. If there are not enough free streams in the pool to satisfy new allocations then the pool size is increased by allocating new memory.
Code
define
关于Stream的结构体,特别要注意两个变量QMD和MARKER
其中QMD是用来追踪kernel用的,MARKER是用来保序的。
CUqmd *qmds[NUM_QMD_PER_STREAM];
CUctxMarker* marker;
详细代码:
streamPool
struct CUIstreamPool_st {
// the owning context
CUctx *ctx;
// a mutex controlling access to the stream lists
CUImutex mutex;
NvBool inStreamCreate;
// a flag set when we have created a NULL-stream independent stream
NvBool allowConcurrentLaunchesOnNullStream;
// Streams are partitioned between these lists, see comment at
// cuiStreamDestroyInternal.
CUIstream *activeHead;
CUIstream *detachedHead;
int detachedCount;
CUIstream *freeHead;
int freeCount;
};
/**
* \brief Create the stream pool for a context.
* \private
*/
CUresult cuiStreamPoolCreate(CUIstreamPool **outPool, CUctx *ctx);
/**
* \brief Destroy the stream pool
* \private
*/
void cuiStreamPoolDestroy(CUIstreamPool *pool);
CUresult
cuiStreamPoolCreate(CUIstreamPool **outPool, CUctx *ctx)
{
CUIstreamPool *pool = NULL;
CU_TRACE_FUNCTION();
pool = (CUIstreamPool *)malloc(sizeof(*pool));
if (NULL == pool) {
return CUDA_ERROR_OUT_OF_MEMORY;
}
memset(pool, 0, sizeof(*pool));
pool->ctx = ctx;
cuiMutexInitialize(&pool->mutex, CUI_MUTEX_ORDER_STREAM_POOL, CUI_MUTEX_RECURSIVE);
*outPool = pool;
return CUDA_SUCCESS;
}
void
cuiStreamPoolDestroy(CUIstreamPool *pool)
{
CUIstream *stream;
CU_TRACE_FUNCTION();
// early-out if no pool exists
if (NULL == pool) {
return;
}
cuiMutexLock(&pool->mutex);
while (pool->activeHead) {
cuiStreamDetach_UnderLock(pool->activeHead);
}
while ((stream = pool->detachedHead) != NULL) {
(void)cuiStreamSynchronize(stream);
cuiStreamReclaimDetached(stream);
}
while (pool->freeCount > 0) {
cuiStreamDestroyInternal(pool->freeHead, NV_TRUE);
}
cuiMutexUnlock(&pool->mutex);
cuiMutexDeinitialize(&pool->mutex);
memset(pool, 0, sizeof(*pool));
free(pool);
}
Stream
/**
* \brief Stream
*
*/
struct CUIstream_st {
//! owning context
CUctx *ctx;
//! the stream pool to which the stream belongs
CUIstreamPool *streamPool;
//! public handle (if one exists -- if this is NULL, that does not
//! make this the NULL stream)
CUstream publicHandle;
//! is this the context's NULL stream?
NvBool isNullStream:1;
//! is this the context's barrier stream?
NvBool isBarrierStream:1;
//! Should this stream sync with the NULL stream?
NvBool syncWithNullStream:1;
//! For user-selectable launch priority. Can be used on devices that
//! support SKED task priorities (GK110 and later Kepler devices).
//! Also remember originally requested priority for late-attaching
//! tools to be able to query & display to the user.
int priority;
//! Priority requested by the user on stream creation.
int priorityRequested;
//! Id is unique per process for the process's lifetime, used by
//! Pointers to per-stream QMD's associated to this stream and an index
//! to keep track of the next QMD we better use.
CUqmd *qmds[NUM_QMD_PER_STREAM];
NvU64 nextQmdIndex;
// a) post-mortem analysis tools to disambiguate streams that
// have the same handle.
// b) the UVM driver to track and optimize page migrations by
// associating managed allocations with streams.
NvU64 streamID;
//! previous pointers in whatever list this stream is in
//! in the stream pool
CUIstream *prev;
//! next pointers in whatever list this stream is
//! in the stream pool
CUIstream *next;
//! a marker tracking this stream's last work issued.
// - this is updated
// - when work is pushed
// - when new dependencies are added (e.g, stream-wait-event).
// - n.b, this does not include waiting on the NULL stream
// - this marker is acquired before each new push on this stream
CUctxMarker* marker;
//! mutex to be held before updating the stream's marker
CUImutex markerMutex;
//! True if streamBeginPush(CUI_PUSH_SKIP_STREAM_ACQUIRE) was used but
//! channelAcquireStreamMarker() has not yet been called during the push
NvBool markerAcquirePending;
//! Last channel in each channel pool that was used by this stream.
CUnvchannel* channelOfLastWork[CU_CHANNEL_USE_COUNT];
//! Last channel pool that was used by this stream.
CUchannelUse poolOfLastWork;
//! a counter used in streamBeginPush early-out of re-acquiring the
//! NULL stream
NvU64 beginPushCountOfLastWork;
//! The last time this stream acquired the barrier stream.
NvU64 beginPushCountOfLastBarrierStreamAcquire;
//! The latest push on the texHdrUpdateStream that this stream
//! has acquired.
NvU64 beginPushCountOfLastTexHdrStreamAcquire;
//! The current param const bank in the pipeline
CUIconstBankPoolNode *currentParamBank;
//! The pipeline of param const banks
CUIconstBankPoolNode *paramBankPipeline[CUI_STREAM_LAUNCH_PIPELINE_DEPTH];
NvU32 paramBankPipelineIndex;
CUIconstBank *constBanks;
void *halLaunchDataAllocation;
//! Const bank depth that this stream will use.
//! CUDA Graphs require the banks to be known ahead of time even if
//! real streams use const bank pipelining
NvU32 constBankPipelineDepth;
//! Uvm tracking data
CUIstreamUvmTracking uvmTracking;
//! Graph tracking data
CUIstreamGraphTracking graphTracking;
//! Stream capture tracking data
//! All fields except graph are protected as part of the capture using
//! cuiGraphLockForCapture(capture.graph).
struct {
// This field is not protected by any lock or atomic. It is
// undefined behavior for use of a stream to race with a change
// to its capture status.
CUIgraph *graph;
CUIgraphNodeSet nextPushDeps;
// Linked list of streams capturing into the same graph
// (The head is at graph->capture.origin)
CUIstream *prev;
CUIstream *next;
} capture;
// Linked list of all the streams that are capturing
// (The head is at ctx->streamManager->streamPool)
CUIstream *captureStreamPrev;
CUIstream *captureStreamNext;
// UVM semaphore
CUsema *uvmPrefetchSema;
NvU32 nextUvmPrefetchSemaReleaseValue;
// CPU semaphore
CUsema *cpuSema;
NvU32 nextCpuSemaReleaseValue;
// Callback mutex and pointer to last uncalled callback from this stream
// To optimize the callbacks we keep only the first uncalled callback in
// DPC and remaining form essentially a linked list. We store here the tail
// of the list to be able to append to it.
// Callback mutex protects this linked list and related fields in
// CUIuserStreamCbData.
CUImutex callbackMutex;
CUIuserStreamCbData *lastUncalledCallback;
enum CUIstreamStatus_enum status;
NvU32 smDisableMaskUpper;
NvU32 smDisableMaskLower;
struct {
//! The channel used for the current streamBeginPush/EndPush pair
CUnvchannel *channel;
//! - note that this is not necessarily in sync with the channel
//! manager's "current push channel" (e.g, during a makespace)
} currentPush;
//! Shared shmem enabled
NvBool sharedShmemEnabled;
// Scheduling flags to control wait behaviour
// See CUstream_flags_enum CU_STREAM_SCHED* for details
NvU32 schedFlags;
// Wait behavior for ctxMarkerWait on a stream
// See CUctxMarkerWaitBehavior_enum for details
CUctxMarkerWaitBehavior blockingSyncBehavior;
};
/**
* \brief Create a stream in specified context
*
* \detailDescription cuiStreamCreate function creates a stream
* in the pool with the stream parameters \p param.
*
* \param[out] outStream The stream created
* \param[in] ctx The context
* \param[in] params The parameters to create stream.
* \additionalNotes
* \noteReentrant{pool->mutex, streamPool}
*
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamCreate(CUIstream **outStream, CUctx *ctx, const CUstreamCreateParams *params);
/**
* \brief Slate a stream for asynchronous destruction or reuse
*
* \detailDescription cuiStream function detaches stream i.e deregisters the
* stream from the uvm and flushes the stream's marker.
*
* \param[in] stream The stream to detach
*
* \return void
*
* \additionalNotes
* \noteReentrant{streamPool->mutex, streamPool}
* \additionalNotes
* The function sets the stream's status to STREAM_STATUS_DETACHED.
*
*/
CUDA_TEST_EXPORT void cuiStreamDetach(CUIstream *stream);
CUresult
cuiStreamCreate(CUIstream **outStream, CUctx *ctx, const CUstreamCreateParams *params)
{
CUIstreamPool *pool = ctx->streamManager->streamPool;
CUresult status = CUDA_SUCCESS;
CU_TRACE_FUNCTION();
cuiMutexLock(&pool->mutex);
pool->inStreamCreate = NV_TRUE;
status = cuiStreamCreate_UnderLock(outStream, pool, params);
pool->inStreamCreate = NV_FALSE;
cuiMutexUnlock(&pool->mutex);
return status;
}
Stream中和Marker相关
/**
* \brief Get the completion marker of the last work
*
* \detailDescription cuiStreamGetCompletionMarkerOfLastWork function returns the
* marker with the current stream's marker.
*
* \param[out] marker The completion marker of the last work.
* \param[in] stream the stream
*
* \return CUresult the result of the function.
*
* \retval
* ctxMarkerCopy
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamGetCompletionMarkerOfLastWork(CUctxMarker *marker, CUIstream *stream);
/**
* \brief Get the dependency marker of the next work
*
* \detailDescription cuiStreamGetDependencyMarkerOfNextWork function returns
* the marker which has a copy of the stream marker and the barrier stream's
* marker if the stream has not acquired the recent barrier Stream. It also
* updates the marker with the null stream barrier if the stream sync with null
* Stream and the null stream barrier has not been acquired.
*
* \param[out] marker The marker of the next work.
* \param[in] stream The stream on which to operate
*
* \return CUresult The result of the function
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_OUT_OF_MEMORY
*
* \additionalNotes
* This function is re-entrant and takes the stream lock when updating the
* marker from the stream->marker.
* \additionalNotes
* This function also takes the stream lock on the nullStream and the
* barrierStream when updating the marker with the corresponding details.
*
* \endfn
*/
// This will differ from the completion marker for a blocking stream if there
// is a null stream or barrier stream barrier after the last work and not yet
// acquired in the stream.
CUDA_TEST_EXPORT CUresult cuiStreamGetDependencyMarkerOfNextWork(CUctxMarker *marker, CUIstream *stream);
/**
* \brief Add marker as a barrier in stream
* \detailDescription cuiStreamWaitMarker waits on the \p marker in the stream
* i.e it updates the stream's marker with the marker's work.
*
* \param[in] stream The stream on which the work is done
* \param[in] marker The marker on which to wait.
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_OUT_OF_MEMORY
*
* \additionalNotes
* cuiStreamWaitMarker is re-entrant and takes the lock on stream's ctx before
* updating any of the context fields.
* \additionalNotes
* \notesync
* \additionalNotes
* If stream is the NULL stream, it adds a null stream barrier.
* \additionalNotes
* If stream is the Barrier Stream, it adds a barrier stream barrier.
* \additionalNotes
* If the stream type is such that it should sync with the NULL stream, then
* update the nullStreamBarrier marker with nullStream's marker and also
* update the nullStream's marker with the current marker.
* \additionalNotes
* If the context of the stream and marker are different then cross-device
* synchronization is done.
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamWaitMarker(CUIstream *stream, CUctxMarker *marker);
/**
* \brief Make one stream wait on another
*
* \detailDescription cuiStreamWaitStream function waits on the streamToSignal
* complete all its current state i.e it gets marker of next work on the current
* stream and waits on this marker on the other stream i.e streamToWait.
*
* \param[in] streamToWait The stream to wait
* \param[in] streamToSignal The stream to signal
* \param[in] type The stream wait type.
*
* \return CUresult the result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_OUT_OF_MEMORY
*
* \additionalNotes If the ctx of the streams are not equal and the dmal type
* are rm for both and the type is CUI_STREAM_WAIT_TYPE_SIGNALER_RELEASES, it
* writes the semaphores in markerToAcquire.
* \additionalNotes
* refer cuiStreamGetDependencyMarkerOfNextWork
*
*/
CUresult cuiStreamWaitStream(CUIstream *streamToWait, CUIstream *streamToSignal, CUIstreamWaitType type);
/**
* \brief Make a stream wait on an event
*
* \detailDescription cuiStreamWaitEvent function waits on the event in the
* stream. It handles it differently if the event is IPC and not.
*
* \param[in] stream The stream which should wait
* \param[in] event The streams waits on this event.
* \param[out] eventUvmNodeSnapshot_out The uvm node snapshot which should be
* updated.
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_INVALID_VALUE
* \retval CUDA_ERROR_NOT_SUPPORTED
*
* \additionalNotes
* Events created from eglSync do not have marker associated with it.
* This function calls into EGL's export API to get the latest nvrmSync object.
* It then calls the cuiEGLEnqueueNvRmSyncAndInvalidateL2Cache which enqueues the nvrmSync on the stream
* and closes the nvrmSync object.
* \additionalNotes
* This function is re-entrant, it reads event's marker to the marker and waits
* on the marker on this stream, refer ::cuiStreamWaitMarker
* \additionalNotes
* For IPC events, It gets the address for IPC pool and does a semaphore acquire
* on that address as IPC event's do not have any marker.
*
* \endfn
*/
CUresult cuiStreamWaitEvent(CUIstream *stream, CUevent event, CUIuvmDagNodeId *eventUvmNodeSnapshot_out);
/**
* \brief Make a stream wait exclusively on a CPU semaphore.
* \detailDescription cuiStreamClearMarkerAndAddCpuSema function waits
* on the cpu semaphore on the stream i.e stream's marker is updated with
* the CPU semaphore. All other stream's marker entries are removed.
*
* CPU semaphore must not be released until all entries of previous stream
* marker are completed. It is also caller responsibility that they are
* flushed.
*
* \param[in] stream The stream on which to operate
* \param[in] markerEntry The cpu marker entry to wait for.
*
* \return CUresult The result of the function
*
* \retval CUDA_SUCCESS
*
* \additionalNotes
* If the stream's type is such that it should be synced with Null Stream,
* true, then the nullStream waits on the cpu Semaphore i.e nullStream's marker
* is updated with the cpuSemaphore.
*
* \additionalNotes
* If the stream is not barrier stream, then the barrier stream waits on the cpu
* Semaphore i.e barrierStream's marker is updated with the cpu semaphore.
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamClearMarkerAndAddCpuSema(CUIstream *stream, CUctxMarkerCpuSema *markerEntry);
/**
* \brief Make one stream wait exclusively on another
*
* \detailDescription cuiStreamClearMarkerAndWaitOnStream waits on the current
* work in another stream, i.e. it replaces the marker of streamToWait with the
* marker representing the completion of the last work pushed to streamOfSignal.
* All other marker entries in streamToWait's marker are removed.
*
* The caller must ensure that the current marker of streamToSignal cannot
* complete until all the work in streamToWait's marker has completed, typically
* via a previous cuiStreamWaitStream in the opposite direction. Additionally,
* it is the caller's responsibility that all of the existing entries of
* streamToWait's marker are flushed.
*
* \param[in] streamToWait The stream to wait
* \param[in] streamOfSignal The stream that the signal is on
*
* \return CUresult the result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_OUT_OF_MEMORY
*
* \additionalNotes
* If the stream's type is such that it synchronizes with the null Stream,
* then the null stream is made to wait on pending work from streamToSignal.
*
* \additionalNotes
* If the stream is not the barrier stream, then the barrier stream is made to
* wait on the pending work from streamToSignal.
*
* \endfn
*/
CUresult cuiStreamClearMarkerAndWaitOnStream(CUIstream *streamToWait, CUIstream *streamOfSignal);
Stream 操作相关
/**
* \brief Get status of a stream (re-entrant)
* \detailDescription cuiStreamQuery function returns the marker status
* of the stream.
*
* \param[in] pStream The stream on which to query
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_NOT_READY
*
* \additionalNotes
* \noteReentrant{stream, stream->marker}
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamQuery(CUIstream *pStream);
/**
* \brief Get status of a stream and notify internal tracking
*
* \detailDescription cuiStreamUserQuery function gets the
* status of the stream and also notifies internal tracking.
*
* \param[in] pStream The stream on which to query.
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
*
* \additionalNotes
* \notesync
*
* \endfn
*/
CUresult cuiStreamUserQuery(CUIstream *pStream);
/**
* \brief Synchronize on last work enqueued in stream (re-entrant)
*
* \detailDescription cuiStreamSynchronize gets the marker of the stream and
* waits on the marker till the marker has been completed.
*
* \param[in] stream The stream to synchronize.
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
*
* \additionalNotes
* The function expects that stream->status is not equal to STREAM_STATUS_FREE.
* \additionalNotes
* \noteReentrant{marker, stream->marker}.
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamSynchronize(CUIstream *stream);
/**
* \brief Synchronize on last work enqueued in stream and notify internal tracking
*
* \detailDescription cuiStreamUserSync function synchronizes on the stream and notifies
* the dmal and the uvm about the synchronization.
*
* \param[in] stream The stream to on which to synchronize
* \param[in] uvmNotify Notify the uvm driver if it is true
*
* \return CUresult The result of the function
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_LAUNCH_FAILED
* \retval CUDA_ERROR_LAUNCH_TIMEOUT
* \retval CUDA_ERROR_LAUNCH_OUT_OF_RESOURCES
* \retval CUDA_ERROR_ILLEGAL_ADDRESS
* \retval CUDA_ERROR_ECC_UNCORRECTABLE
* \retval CUDA_ERROR_MAP_FAILED
* \retval CUDA_ERROR_UNMAP_FAILED
* \retval CUDA_ERROR_NOT_INITIALIZED
* \retval CUDA_ERROR_DEINITIALIZED
* \retval CUDA_ERROR_UNKNOWN
*
*
* \endfn
*/
CUresult cuiStreamUserSync(CUIstream *stream, NvBool uvmNotify);
/**
* \brief Notify internal tracking if stream sync was triggered by user
*
* \detailDescription cuiStreamNotifyUserSynchronized function notifies the dmal
* about the sync and updates the UVM dag and notifies the uvm driver about the
* sync.
*
* \param[in] stream The stream on which to operate
* \param[in] snapshotId The uvm node
* \param[in] uvmNotify Notify the uvm driver if it is true.
*
* \return CUresult the result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_UNKNOWN
*
* \additionalNotes
* Update UVM DAG only if uvmNotify is set.
*
*
* \endfn
*/
CUresult cuiStreamNotifyUserSynchronized(CUIstream *stream, CUIuvmDagNodeId snapshotId, NvBool uvmNotify);
/**
* \brief Add a callback which will execute when currently enqueued work is finished
*
* \detailDescription cuiStreamAddCallback function adds a callback which must
* get executed once the current work on the stream has been completed. It
* creates a callbackManager for the streamManager.
*
* \param[in] stream The internal stream on which to add
* \param[in] hStream The public handle of the stream.
* \param[in] callback The callback function
* \param[in] userData The data from the user.
* \param[in] flags To notify uvm or ECC check should be done.
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_OUT_OF_MEMORY
* \retval CUDA_ERROR_NOT_SUPPORTED It is not supported on Mods platform.
*
* \additionalNotes
* Returns CUDA_ERROR_OUT_OF_MEMORY if allocation of the CUIuserStreamCbData_st fails.
* \additionalNotes
* If the stream is NULL stream, then update the Null Stream Barrier.
*
*/
CUresult cuiStreamAddCallback(CUIstream *stream, CUstream hStream, CUIuserStreamCb fn, void *userData, unsigned int flags);
/**
* \brief Attach managed memory to a stream, automatically detaches it from the
* previously
*
* \detailDescription cuiStreamAttachManagedMem function attaches a memory to a
* stream and detaches it from the previous stream. It tries to do an eager
* attach on the stream if the stream has completed on gpu. If it does not
* eagerly attach it adds a callback on the stream. It expects that \p stream to
* be valid.
*
* \param[in] stream The stream on which to attach the memory.
* \param[in] dptr The pointer of the managed memory to be attached..
* \param[in] size The size of the memory.
* \param[in] flags The flags for attaching.
*
* \return CUresult the result of The function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_INVALID_VALUE If the memobj of the pointer is NULL or
* it is not managed memory or the memobj's device pointer is not dptr.
*
* \additionalNotes
* If the memdesc is CU_MEM_SHARING_CUDA_MEMOBJ, then the memobjGetSource on the
* memobj should be valid.
* \additionalNotes
* Re-entrant and takes the stream lock.
* \additionalNotes
* \noteasync
* \additionalNotes
* It sets the eagerlyAttached to true depending on it attached the memory or
* not.
*
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamAttachManagedMem(CUIstream *stream, NvU64 dptr, size_t size, unsigned int flags);
/**
* \brief Prefetch memory to a device in stream
*
* \detailDescription cuiStreamPrefetchMem function prefetches the memory on the
* stream. It should acquire all the work on the stream, null stream and the
* barrier stream before prefetch operation on the stream. It does the prefetch
* operation and the stream waits on the uvm semaphore.It also notes the last
* prefetch location.
*
* \param[in] stream The stream
* \param[in] dptr The pointer of the memory to be prefetched.
* \param[in] size The size of the memory.
* \param[in] device The device.
*
* \return CUresult The result of the function.
*
* \retval CUDA_SUCCESS
* \retval CUDA_ERROR_OUT_OF_MEMORY
*
* \additionalNotes
* The uvm prefetch semaphore is not allocated for MPS.
* \additionalNotes
* For non-mps clients, If the stream's work is completed by gpu, then do a
* prefetch of the memory.
* \additionalNotes
* For non-mps systems, since the uvm semaphore is allocated, the stream marker
* is updated to wait for the UVM semaphore.
* \additionalNotes
* For non-mps clients, If the stream is NULL stream and the work on the stream is
* completed by gpu, then add null stream barrier.
* \additionalNotes
* If the stream is not completed by gpu, then add a callback which does
* prefetch on the memory.
*
* \endfn
*/
CUresult cuiStreamPrefetchMem(CUIstream *stream, NvU64 dptr, size_t size, CUdev *device);
bank 相关
/**
* \brief Retrieve a constant bank from a stream
*
* \detailDescription cuiStreamGetConstBank function retrieves the
* constant bank from the stream at a particular index.
*
* \param[in] stream The stream
* \param[in] index The index of the backing
*
* \return CUIconstBank The constant bank.
*
* \endfn
*/
CUIconstBank cuiStreamGetConstBank(CUIstream *stream, NvU32 index);
/**
* \brief Retrieve the constant banks from a stream
*
* \detailDescription cuiStreamGetConstBanks function retrieves the
* constant banks from the stream
*
* \param[in] stream The stream
*
* \return CUIconstBank The pointer to the array of constant banks.
*
* \endfn
*/
CUIconstBank* cuiStreamGetConstBanks(CUIstream *stream);
其它
/**
* \brief Get the channel that was last used by this stream.
* \detailDescription cuiStreamGetChannelOfLastWork returns the channel on which
* the last work was submitted.
*
* \param[in] stream The stream on which to operated
*
* \return CUnvchannel The channel pointer on which the last work was submitted.
*
* \endfn
*/
CUDA_TEST_EXPORT CUnvchannel *cuiStreamGetChannelOfLastWork(CUIstream *stream);
/**
* \brief Set the smDisableMask for the stream
*
* \detailDescription cuiStreamSetSmDisableMask function sets the stream's
* smDisableMaskUpper and smDisableMaskLower fields with the parameters passed.
*
* \param[out] stream The stream on which to operate.
* \param[in] smDisableMaskUpper Disable mask upper 32 bits
* \param[in] smDisableMaskLower Disable mask lower 32 bits
*
*
* \endfn
*/
void cuiStreamSetSmDisableMask(CUIstream *stream, NvU32 smDisableMaskUpper, NvU32 smDisableMaskLower);
/*
* \brief Allocate QMD's for a stream
*
* \param[in] stream The stream on which to allocate QMD's.
* \endfn
*/
CUDA_TEST_EXPORT CUresult cuiStreamAllocateQMDs(CUIstream *stream);
/**
* \brief Get a QMD to use for a launch
* \endfn
*/
CUDA_TEST_EXPORT CUqmd *cuiStreamGetQmdForLaunch(CUIstream *stream);
//! Advance the launch pipeline to the next stage
void cuiStreamAdvanceLaunchPipeline(CUIstream* stream);
//! Acquire the stream's last work in the current push
void cuiStreamAcquireLastWork(CUnvCurrent **pnvCurrent, CUIstream *stream, NvU32 flags);
//! Flag values to control scope of effects in ::cuiStreamPoolInvalidateCaptures
typedef enum CUIcaptureInvalidateScope_enum {
//! Only invalidate captures initiated from the calling thread and which are not relaxed mode
CUI_CAPTURE_INVALIDATE_LOCAL,
//! Same as ::CUI_CAPTURE_INVALIDATE_LOCAL with the addition of captures initiated from other threads with global mode
CUI_CAPTURE_INVALIDATE_GLOBAL,
//! Invalidate all captures in the context regardless of mode
CUI_CAPTURE_INVALIDATE_ALL
} CUIcaptureInvalidateScope;
//! Invalidate captures in streams from a context
//! tlsCaptureData is used to determine if captures are owned by the calling thread. It is required
//! if and only if scope != CUI_CAPTURE_INVALIDATE_ALL.
void cuiStreamPoolInvalidateCaptures(CUIstreamPool *pool, CUIcaptureInvalidateScope scope,
NvBool includeNonblocking, CUItlsStreamCaptureData *tlsCaptureData);
/*
* \brief Calculate the SKED priority for a stream
* \endfn
*/
NvU32 cuiStreamGetSkedPriority(CUIstream *stream);