首先问题出在cpu下的多线程,当你想要在多个线程下调用同一个cuda核函数的时候,你会发现效率很低,那么经过验证,的确,不管你有多少个线程,cuda总是将线程中的核函数放入默认流中进行队列方式的处理,相当于单线程,但是这个问题在cuda7后已经得到了解决,下面对这个问题进行一些测试。
这里使用了以下链接中的内容:
https://www.cnblogs.com/wujianming-110117/p/14091897.html
https://developer.nvidia.com/blog/gpu-pro-tip-cuda-7-streams-simplify-concurrency/
CUDA 7 Stream流简化并发性异构计算是指高效地使用系统中的所有处理器,包括 CPU 和 GPU 。为此,应用程序必须在多个处理器上并发执行函数。 CUDA 应用程序通过在 streams 中执行异步命令来管理并发性,这些命令是按顺序执行的。不同的流可以并发地执行它们的命令,也可以彼此无序地执行它们的命令。在不指定流的情况下执行异步 CUDA 命令时,运行时使用默认流。在 CUDA 7 之前,默认流是一个特殊流,它隐式地与设备上的所有其他流同步。CUDA 7 引入了大量强大的新功能 ,包括一个新的选项,可以为每个主机线程使用独立的默认流,这避免了传统默认流的序列化。本文将展示如何在 CUDA 程序中简化实现内核和数据副本之间的并发。
指定流是可选的;可以调用 CUDA 命令而不指定流(或通过将 stream 参数设置为零)。下面两行代码都在默认流上启动内核。
kernel<<< blocks, threads, bytes >>>(); // default stream kernel<<< blocks, threads, bytes, 0 >>>(); // stream 0在并发性对性能不重要的情况下,默认流很有用。在 CUDA 7 之前,每个设备都有一个用于所有主机线程的默认流,这会导致隐式同步。正如 CUDA C 编程指南中的“隐式同步”一节所述,如果主机线程向它们之间的默认流发出任何 CUDA 命令,来自不同流的两个命令就不能并发运行。
CUDA 7 引入了一个新选项, 每线程默认流 ,它有两个效果。首先,它为每个主机线程提供自己的默认流。这意味着不同主机线程向默认流发出的命令可以并发运行。其次,这些默认流是常规流。这意味着默认流中的命令可以与非默认流中的命令同时运行。
要在 nvcc7 及更高版本中启用每线程默认流,可以在包含 CUDA 头( cuda.h 或 cuda_runtime.h )之前,使用 nvcc 命令行选项 CUDA 或 #define 编译 CUDA_API_PER_THREAD_DEFAULT_STREAM 预处理器宏。需要注意的是:当代码由 nvcc 编译时,不能使用 #define CUDA_API_PER_THREAD_DEFAULT_STREAM 在. cu 文件中启用此行为,因为 nvcc 在翻译单元的顶部隐式包含了 cuda_runtime.h 。
具体方法是,右键项目属性中的CUDA C/C++(前提是你创建的是CUDA程序,不然没有这个选项)选项中的Command Line中添加--default-stream per-thread就可以。
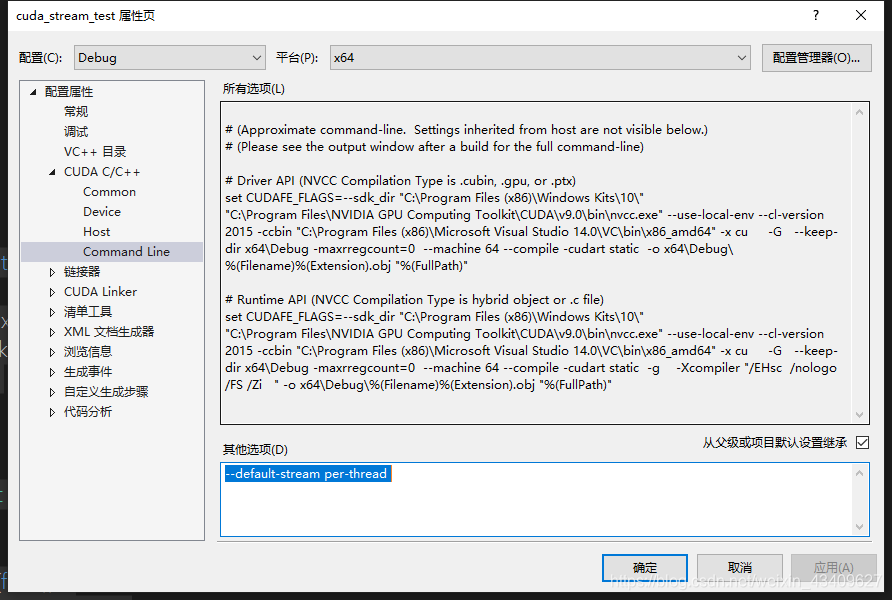
下面介绍测试方法:
1.以管理员身份打开Nsight Monitor
2.点击visual studio菜单中的Nsight,选择Start Perfoemance Analysis
3.勾选system和cuda选项
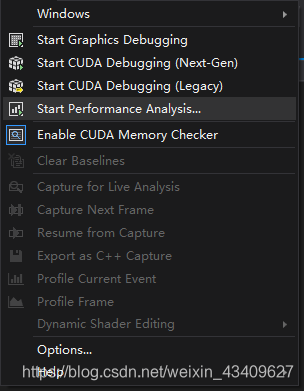
4.点击lanuch运行
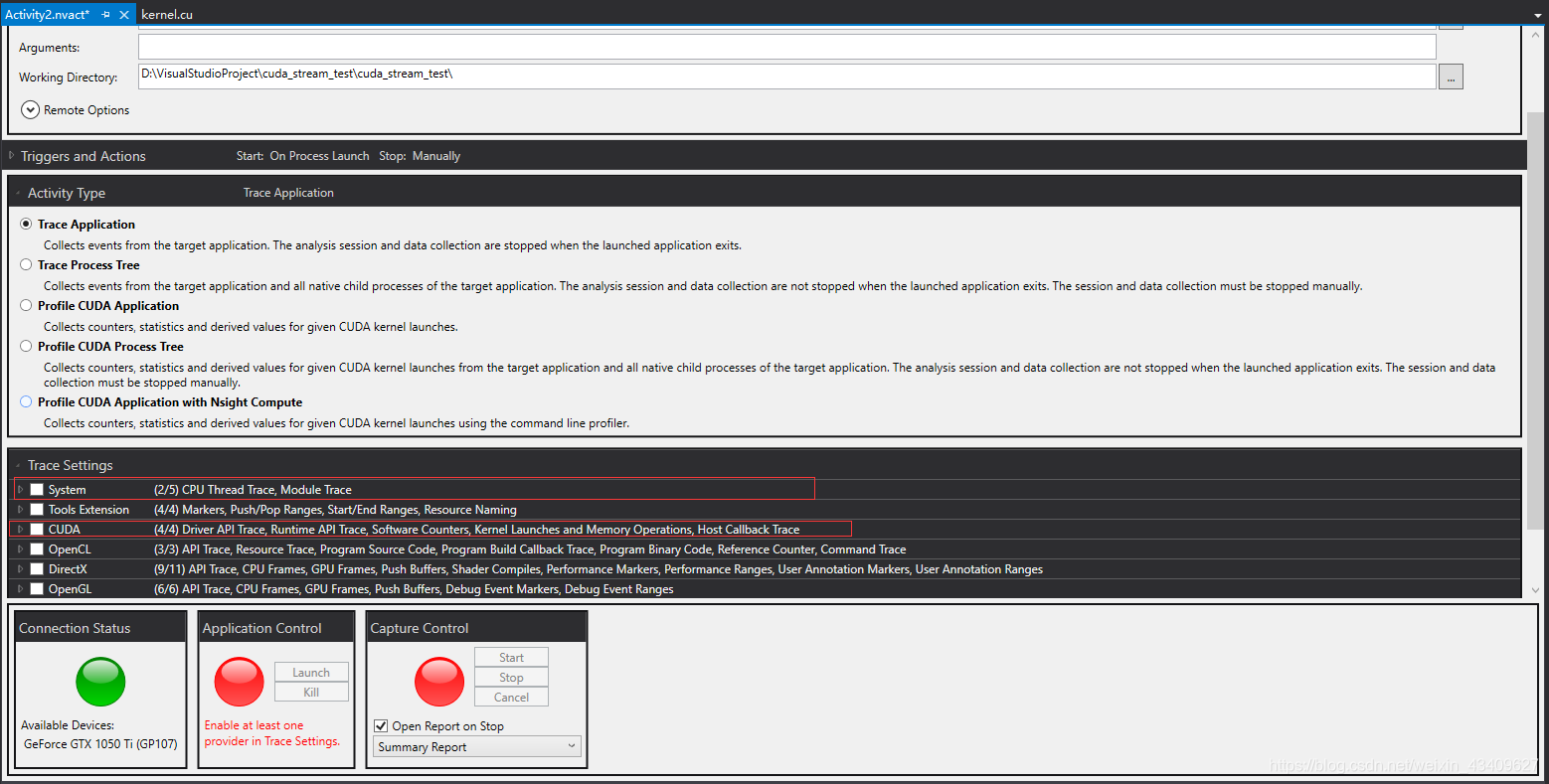
5.待运行完毕后,系统自动输出运行结果,点击timeline查看stream的使用情况
第一个例子是使用for循环测试多流,代码如下:
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#include <thread>
#include <stdio.h>
#include <thread>
#include <stdio.h>
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159, i));
}
}
int main()
{
const int num_streams = 8;
cudaStream_t streams[num_streams];
float *data[num_streams];
for (int i = 0; i < num_streams; i++) {
cudaStreamCreate(&streams[i]);
cudaMalloc(&data[i], N * sizeof(float));
// launch one worker kernel per stream
kernel << <1, 64, 0, streams[i] >> > (data[i], N);
// launch a dummy kernel on the default stream
kernel << <1, 1 >> > (0, 0);
}
cudaDeviceReset();
return 0;
}在不使用--default-stream per-thread编译命令时运行结果如下图:
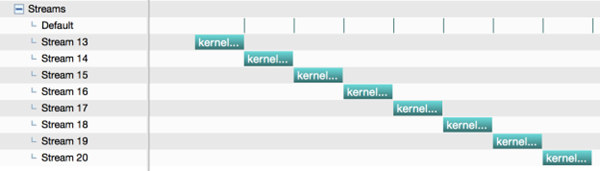
可以看到核函数并没有并发运行。
添加后:
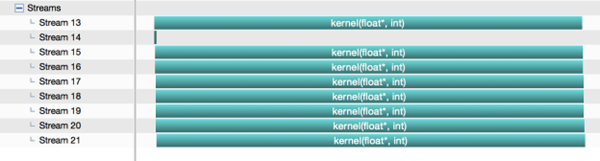
第二个例子使用多线程,代码如下:
const int N = 1 << 20;
__global__ void kernel(float *x, int n)
{
int tid = threadIdx.x + blockIdx.x * blockDim.x;
for (int i = tid; i < n; i += blockDim.x * gridDim.x) {
x[i] = sqrt(pow(3.14159, i));
}
}
void launch_kernel(cudaStream_t stream)
{
float *data;
cudaMalloc(&data, N * sizeof(float));
kernel << <1, 64,0, stream >> > (data, N);
//cudaStreamSynchronize(0);
return;
}
int main()
{
const int num_threads = 8;
std::thread threads[num_threads];
cudaStream_t streams[num_threads];
for (int i = 0; i < num_threads; i++) {
cudaStreamCreate(&streams[i]);
threads[i] = std::thread(launch_kernel, streams[i]);
}
for (int i = 0; i < num_threads; i++) {
threads[i].join();
}
cudaDeviceReset();
return 0;
}同样在不使用编译命令时运行结果如下图:

使用后如下图:

提示:
在为并发进行编程时,还需要记住以下几点。
1.对于每线程的默认流,每个线程中的默认流的行为与常规流相同,只要同步和并发就可以了。对于传统的默认流,这是不正确的。
2.--default-stream 选项是按编译单元应用的,确保将其应用于所有需要它的 nvcc 命令行。
3.cudaDeviceSynchronize() 继续同步设备上的所有内容,甚至使用新的每线程默认流选项。如果只想同步单个流,请使用 cudaStreamSynchronize(cudaStream_t stream) ,如的第二个示例所示。
4.从 CUDA 7 开始,还可以使用句柄 cudaStreamPerThread 显式地访问每线程的默认流,也可以使用句柄 cudaStreamLegacy 访问旧的默认流。请注意, cudaStreamLegacy 仍然隐式地与每个线程的默认流同步,如果碰巧在一个程序中混合使用它们。
5.可以通过将 cudaStreamCreate() 标志传递给 cudaStreamCreate() 来创建不与传统默认流同步的 非阻塞流 。