Generative Adversarial Nets
-
生成器主要从一个低维度的数据分布中不断拟合真实的高维数据分布,而判别器主要是为了区分数据是来源于真实数据还是生成器生成的数据,他们之间相互对抗,不断学习,最终达到Nash均衡,即任何一方的改进都不会导致总体的收益增加,这个时候判别器再也无法区分是生成器生成的数据还是真实数据。
-
-
通过对抗过程来估计生成模型,在这个框架中,我们同时训练两个模型:
-
用来拟合数据分布的生成网络G
-
用来判断输入是否“真实”的判别网络D。
-
在训练过程中,生成网络G通过接受一个随机的噪声来尽量模仿训练集中的真实图片去“欺骗”D,而D则尽可能的分辨真实数据和生成网络的输出,从而形成两个网络的博弈过程。理想的情况下,博弈的结果会得到一个可以“以假乱真”的生成模型。
-
生成网络尽可能生成逼真样本,判别网络则尽可能去判别该样本是真实样本,还是生成的假样本。
-
-
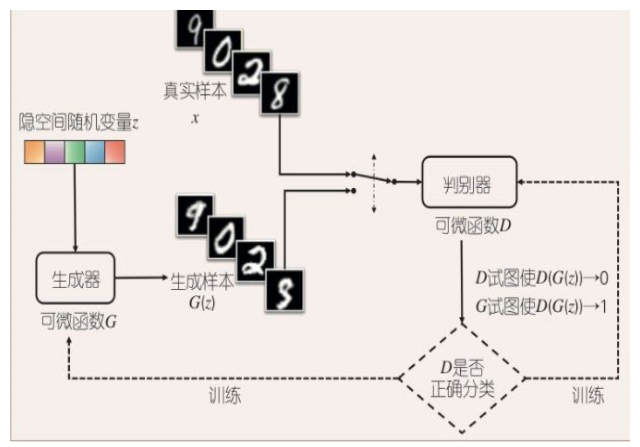
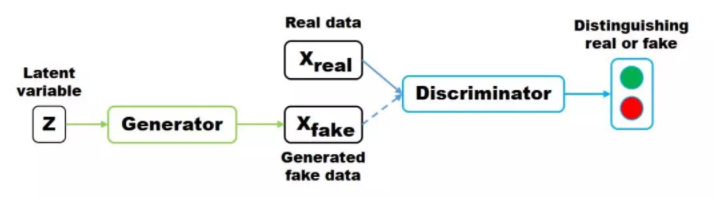
隐变量 z (通常为服从高斯分布的随机噪声)通过 Generator 生成 Xfake, 判别器负责判别输入的 data 是生成的样本 Xfake 还是真实样本 Xreal。
- 在统计学中,隐变量或潜变量指的是不可观测的随机变量。隐变量可以通过使用数学模型依据观测得的数据被推断出来。
-
优化的目标函数如下:
- x表示真实图片,z表示输入G网络的噪声,而G(z)表示G网络生成的图片。 - D(x)表示D网络判断**真实图片是否真实**的概率(因为x就是真实的,所以对于D来说,这个值越接近1越好)。而D(G(z))是D网络判断G生成的图片的是否真实的概率。 - G的目的:上面提到过,D(G(z))是**D网络判断G生成的图片是否真实的概率**,G应该希望自己生成的图片“越接近真实越好”。也就是说,G希望D(G(z))尽可能得大,这时V(D, G)会变小。因此我们看到式子的最前面的记号是min_G。 - D的目的:D的能力越强,D(x)应该越大,D(G(x))应该越小。这时V(D,G)会变大。因此式子对于D来说是求最大(max_D) - 对于判别器 D 来说,这是一个二分类问题,V(D,G) 为二分类问题中常见的交叉熵损失。最小化 V(D,G) 的最大值。 - 为了保证 V(D,G) 取得最大值,所以我们通常会训练迭代k次判别器,然后再迭代1次生成器(不过在实践当中发现,k 通常取 1 即可)。 - 当生成器 G 固定时,我们可以对 V(D,G) 求导,求出最优判别器 D*(x): - - 把最优判别器代入上述目标函数,可以进一步求出在最优判别器下,生成器的目标函数等价于优化 Pdata(x) , Pg(x) 的 JS 散度(JSD, Jenson Shannon Divergence)。 - **JS散度**度量了两个概率分布的相似度,基于KL散度的变体,解决了KL散度非对称的问题。 > - JS散度是对称的,其取值是0到1之间。 > - - 相对熵又称KL散度,如果我们对于同一个随机变量 x 有两个单独的概率分布 P(x) 和 Q(x),我们可以使用 KL 散度(Kullback-Leibler (KL) divergence)来衡量这两个分布的差异 。 > - 在机器学习中,P往往用来表示样本的真实分布,Q用来表示模型所预测的分布,那么KL散度就可以计算两个分布的差异,也就是Loss损失值。 > - KL散度公式中可以看到Q的分布越接近P(Q分布越拟合P),那么散度值越小,即损失值越小。 > - KL散度不是对称的; > - - 交叉熵是用来衡量两个 概率分布 的距离(也可以叫差别)。 > - 有两个概率分布p(x)和q(x),通过q来表示p的交叉熵为:(注意,p和q呼唤位置后,交叉熵是不同的) > - > - 交叉熵值越低,表示两个概率分布越靠近。 - > - 信息熵是衡量随机变量分布的**混乱程度**,是随机分布各事件发生的信息量的期望值,随机变量的取值个数越多,状态数也就越多,信息熵就越大,混乱程度就越大。 > - 信息熵是用于刻画消除随机变量X的不确定性所需要的总体信息量的大小。 > - 当随机分布为均匀分布时,熵最大;信息熵**推广到多维领域,则可得到联合信息熵**;条件熵表示的是在 X 给定条件下,Y 的条件概率分布的熵对 X 的期望。 > - 相对熵可以用来**衡量两个概率分布之间**的差异。 > - 交叉熵可以来衡量在给定的真实分布下,使用非真实分布所指定的策略消除系统的不确定性所需要付出的努力的大小。 - 对于生成器 G 来说,为了尽可能欺骗 D,所以需要最大化生成样本的判别概率 D(G(z)),即最小化 log(1-D(G(z))) - 当 G,D 二者的 capacity 足够时,模型会收敛,二者将达到纳什均衡。此时,Pdata(x)=Pg(x),判别器不论是对于 Pdata(x) 还是 Pg(x) 中采样的样本,其预测概率均为 1/2,即生成样本与真实样本达到了难以区分的地步。 - 纳什平衡,又称为非合作赛局博弈,是在非合作博弈状况下的一个概念解,在博弈论中有重要地位,以约翰·纳什命名。 如果某情况下**无一参与者可以通过独自行动而增加收益**,则此策略组合被称为纳什均衡点。-
经典 GAN 的判别器有两种 loss,在训练时候理论上会对训练gan网络导致障碍
- 在判别器达到最优的时候,等价于最小化生成分布与真实分布之间的 JS 散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及 JS 散度的突变特性,使得生成器面临梯度消失的问题。
- 在判别器达到最优的时候,等价于最小化生成分布与真实分布之间的 JS 散度,由于随机生成分布很难与真实分布有不可忽略的重叠以及 JS 散度的突变特性,使得生成器面临梯度消失的问题。
- 在最优判别器下,等价于既要最小化生成分布与真实分布直接的 KL 散度,又要最大化其 JS 散度,相互矛盾,导致梯度不稳定,而且 KL 散度的不对称性使得生成器宁可丧失多样性也不愿丧失准确性,导致 **collapse mode 现象** - - 具体来说,给定了一个z,当z发生变化的时候,对应的G(z)没有变化,那么在这个局部,GAN就发生了mode collapse,也就是不能产生不断连续变化的样本。 - 为了解决这个问题,最直接的是我们可以**给流型的切向量加上一个正交约束**(Orthonormal constraint),从而避免这种局部的维度缺陷。 - > - 为了避免前面提到的由于优化 maxmin 导致 mode 跳来跳去的问题,UnrolledGAN 采用修改生成器 loss 来解决。具体而言,UnrolledGAN 在更新生成器时更新 k 次生成器,参考的 Loss 不是某一次的 loss,是判别器后面 k 次迭代的 loss。 > - DRAGAN 则引入博弈论中的无后悔算法,改造其 loss 以解决 mode collapse问题 . > - EBGAN 则是加入 VAE 的重构误差以解决 mode collapse。 - 泛化性和mode collapse 的关系 - 这两个问题是不同的,一个是在研究能不能生成新样本,一个是研究生成样本的多样性。 - 从某种意义上,泛化性可以看作是**因**,而mode collapse是它表现出来的**现象**。 -
-
-
GAN 相比于其他生成式模型,有两大特点:
- 不依赖任何先验假设。传统的许多方法会假设数据服从某一分布,然后使用极大似然去估计数据分布。
- 生成 real-like 样本的方式非常简单。GAN 生成 real-like 样本的方式通过生成器(Generator)的前向传播
-
作用领域:图像生成/合成(从现有数据集生成新图像的任务)。
- generator:神经网络或是函数
- 输入一个向量,输出一个高维向量(image)
- discriminator:神经网络或是函数
- 输入一个高维向量(image),输出一个标量判定,值越大表示越真实
- generator:神经网络或是函数
-
structured learning approach
- bottom up:从一个个小组件生成开始,有小到大。容易失去全局结构表达含义(可以用作generator)
- top down:从整体到细节的思路(可以用作discriminator)
-
在训练过程中,**生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。**这样,G和D构成了一个动态的“博弈过程”。
-
**在最理想的状态下,**G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
-
- 鉴别模型,用于学习确定样本是来自模型分布还是来自数据分布。
- 生成模型可以被认为类似于一组伪造者
- 关系:生成器试图制造假币并在不被发现的情况下使用,而鉴别模型类似于警察,他们试图检测假币。这个游戏(生成对抗网络)中的竞争促使两个团队改进他们的方法,直到假冒品与真品无法区分为止。
- 网络选择:生成模型通过多层感知器传递随机噪声生成样本的特殊情况,而判别模型也是多层感知器。
-
G和D之间的对抗情况
-
-
黑色的线表示数据x的实际分布,绿色的线表示数据的生成分布,蓝色的线表示生成的数据对应在判别器中的分布效果
- 对于图a,D还刚开始训练,本身分类的能力还很有限,有波动,但是初步区分实际数据和生成数据还是可以的。
- 图b,D训练得比较好了,可以很明显的区分出生成数据。
- 图c:绿色的线与黑色的线的偏移,蓝色的线下降了,也就是生成数据的概率下降了。那么,由于绿色的线的目标是提升概率,因此就会往蓝色线高的方向移动。那么随着训练的持续,由于G网络的提升,G也反过来影响D的分布。
- 图d符合我们最终想要的训练结果。到这里,G网络和D网络就处于纳什均衡状态,无法再进一步更新了。
-
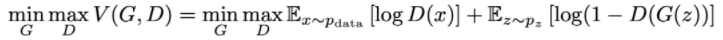
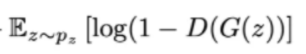
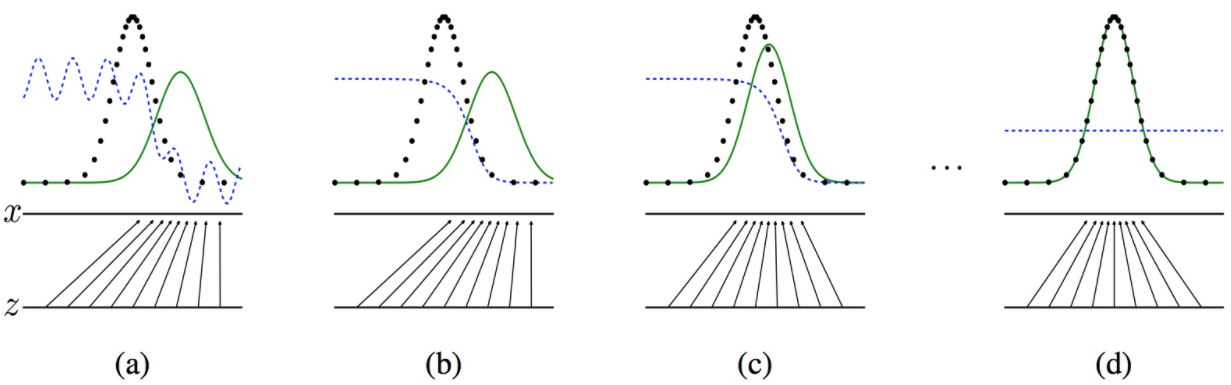
GAN的收敛问题
- 第一,梯度消失问题,原始GAN使用分类误差作为真实分布与生成分布相近度的度量,这种方法在最优判别器的条件下,**生成器的损失函数等价于最小化真实分布与生成分布之间的JS散度。**然而,已被证明,当真实分布与生成分布的重叠区域可忽略时,JS散度为一常数,此时生成器获得的梯度为0。
- 第二,模式崩塌问题,也就是说生成器可能生成同样的数据而不是多样的数据。
- 这个问题主要原因是,在优化时使用梯度下降的方法,实际上不区分min-max和max-min,这导致生成器希望多生成一些重复但是很安全的样本。
- 而我们希望生成样本尽量与真实样本的多样性一致。这些问题可以通过设计更好的网络结构、差异的度量方式或者一些训练的trick来解决,一般都会结合使用。例如WGAN就是通过使用Wasserstein距离来代替JS散度,同时使用了权值裁剪的trick,实现了很好的效果。
古德费罗的GAN的展望
- 条件生成模型,即根据给定的条件和随机分布,生成特定的数据。
- 通过训练一个给定 x,预测 z 的辅助网络,用于样本之间的相似度检测。
- 可以训练一个 shared model,给定任意子条件和随机分布,生成该条件对应的样本。
- 半监督学习:当训练数据有限时,可以使用 discriminator 的特征或者 G 网络来提升分类器的性能。
- 在训练的过程中,如果可以确定一个更好的 z 的分布,则训练速度和模型性能都会大大提升。
VAE
-
变分自编码器我们将定义一个不易处理的密度函数,通过附加的隐变量 z 对密度函数进行建模。
-
VAE 原理图
-
变分自编码器可用于对先验数据分布进行建模。
-
它包括两部分:编码器和解码器。
- 编码器将数据分布的高级特征映射到数据的低级表征,低级表征叫作本征向量(latent vector)。
- 解码器吸收数据的低级表征,然后输出同样数据的高级表征。
-
在自动编码器中,需要输入一张图片,然后将一张图片编码之后得到一个隐含向量,这比原始方法的随机取一个随机噪声更好,因为这包含着原图片的信息,然后隐含向量解码得到与原图片对应的照片。
-
但是这样其实并不能任意生成图片,因为没有办法自己去构造隐藏向量,所以它需要通过一张图片输入编码才知道得到的隐含向量是什么,这时就可以通过变分自动编码器来解决这个问题。
- 解决办法就是在编码过程给它增加一些限制,迫使其生成的隐含向量能够粗略的遵循一个标准正态分布,这就是其与一般的自动编码器最大的不同。
- 这样生成一张新图片就比较容易,只需要给它一个标准正态分布的随机隐含向量,这样通过解码器就能够生成想要的图片,而不需要给它一张原始图片先编码。
-
在 VAE 中,真实样本X通过神经网络计算出均值方差(假设隐变量服从正态分布),然后通过采样得到采样变量 Z 并进行重构。VAE 和 GAN 均是学习了隐变量 z 到真实数据分布的映射。
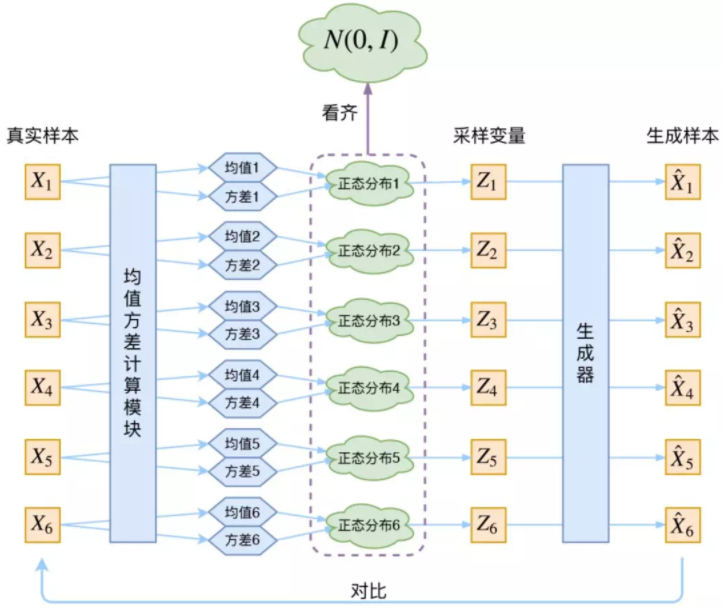
GAN与VAE的结合
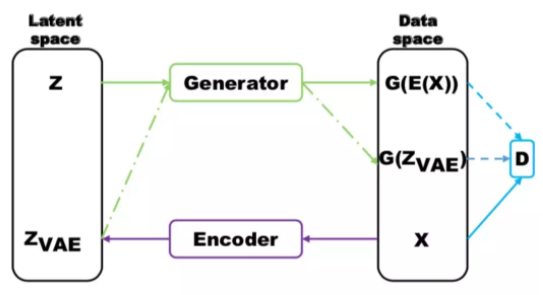
- GAN 相比于 VAE 可以生成清晰的图像,但是却容易出现 mode collapse 问题。VAE 由于鼓励重构所有样本,所以不会出现 mode collapse 问题。
- 代码重构(英语:Code refactoring)指对软件代码做任何更动以增加可读性或者简化结构而不影响输出结果。 软件重构需要借助工具完成,重构工具能够修改代码同时修改所有引用该代码的地方。在极限编程的方法学中,重构需要单元测试来支持。
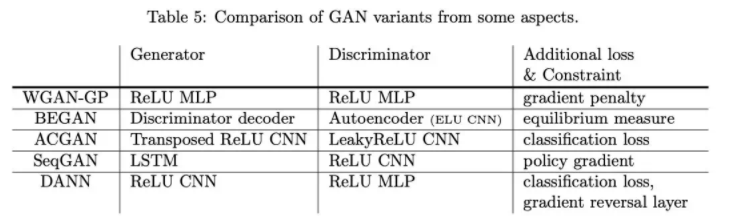
比较有名的一些 GAN 的模型结构及其施加的额外约束。
-
-
- MLP(多层感知器)
- 单层感知器(Single Layer Perceptron)是最简单的ANN人工神经网络。它包含输入层和输出层,而输入层和输出层是直接相连的。单层感知器仅能处理线性问题,不能处理非线性问题。
- MLP多层感知器是一种前向结构的ANN人工神经网络**, 多层感知器(MLP)能够处理**非线性可分离的问题。
- MLP多层感知器(Multi-layerPerceptron)是一种前向结构的人工神经网络ANN,映射一组输入向量到一组输出向量。
- MLP可以被看做是一个有向图,由多个节点层组成,每一层全连接到下一层。除了输入节点,每个节点都是一个带有非线性激活函数的神经元。
- 使用BP反向传播算法的监督学习方法来训练MLP。MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。
- LSTM
- 长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。LSTM能够在更长的序列中有更好的表现。
- LSTM内部主要有三个阶段:
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
- 具体来说是通过计算得到的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-WkeNYZ5F-1637459504402)(https://www.zhihu.com/equation?tex=z%5Ef)] (f表示forget)来作为忘记门控,来控制上一个状态的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-St9dL0pg-1637459504403)(https://www.zhihu.com/equation?tex=c%5E%7Bt-1%7D)] 哪些需要留哪些需要忘。
- 选择记忆阶段。这个阶段将这个阶段的输入有选择性地进行“记忆”。主要是会对输入 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VpUH1Xnx-1637459504405)(https://www.zhihu.com/equation?tex=x%5Et)] 进行选择记忆。哪些重要则着重记录下来,哪些不重要,则少记一些。当前的输入内容由前面计算得到的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TAdZASPJ-1637459504406)(https://www.zhihu.com/equation?tex=z+)] 表示。而选择的门控信号则是由 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-3wDLhVjD-1637459504407)(https://www.zhihu.com/equation?tex=z%5Ei)] (i代表information)来进行控制。
- 输出阶段。这个阶段将决定哪些将会被当成当前状态的输出。主要是通过 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-bNpswK5Y-1637459504408)(https://www.zhihu.com/equation?tex=z%5Eo)] 来进行控制的。并且还对上一阶段得到的 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CI6DhA8g-1637459504409)(https://www.zhihu.com/equation?tex=c%5Eo)] 进行了放缩(通过一个tanh激活函数进行变化)。
- 忘记阶段。这个阶段主要是对上一个节点传进来的输入进行选择性忘记。简单来说就是会 “忘记不重要的,记住重要的”。
- 通过门控状态来控制传输状态,记住需要长时间记忆的,忘记不重要的信息;而不像普通的RNN那样只能够以一种记忆叠加方式。对很多需要“长期记忆”的任务来说,尤其好用。
- GRU
- GRU(Gate Recurrent Unit)是循环神经网络(Recurrent Neural Network, RNN)的一种。和LSTM(Long-Short Term Memory)一样,也是为了解决长期记忆和反向传播中的梯度等问题而提出来的。
- 相比LSTM,使用GRU能够达到相当的效果,并且相比之下更容易进行训练,能够很大程度上提高训练效率,因此很多时候会更倾向于使用GRU。
- MLP(多层感知器)
生成式模型对比
- 自回归模型通过对概率分布显式建模来生成数据;
- VAE 和 GAN 均是:假设隐变量 z 服从某种分布,并学习一个映射 X=G(z) ,实现隐变量分布 z 与真实数据分布 Pdata(x) 的转换;
- GAN 使用判别器去度量映射 X=G(z) 的优劣,而 VAE 通过隐变量 z 与标准正态分布的 KL 散度和重构误差去度量。
GAN与强化学习的关系
-
强化学习是一种试错方法,其目标是让软件智能体在特定环境中能够采取回报最大化的行为。
- 强化学习在马尔可夫决策过程环境中主要使用的技术是动态规划(Dynamic Programming)。
- 流行的强化学习方法包括自适应动态规划(ADP)、时间差分(TD)学习、状态-动作-回报-状态-动作(SARSA)算法、Q 学习、深度强化学习(DQN);其应用包括下棋类游戏、机器人控制和工作调度等。
-
强化学习的目标是对于一个智能体,给定状态 s,去选择一个最佳的行为 a (action)。通常的可以定义一个价值函数 Q(s,a) 来衡量,对于状态 s,采取行动 a 的回报是 Q(s,a),显然,我们希望最大化这个回报值。
-
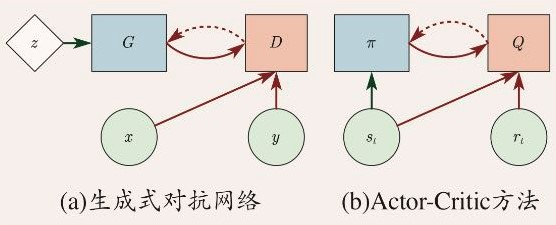
- 对于GAN来说,z输入给G,然后由D判断G的输出究竟对不对。而对于Actor-Critic,会将环境中的状态输入给π,然后由π 来输出给Q,也就是由评判者(Critic)去评判策略。增强学习和GAN的区别就在于这个z和,因为环境的状态具有一定的随机性, 只需要输入一个状态就够了,而在GAN中,状态与随机信号被分离开来。
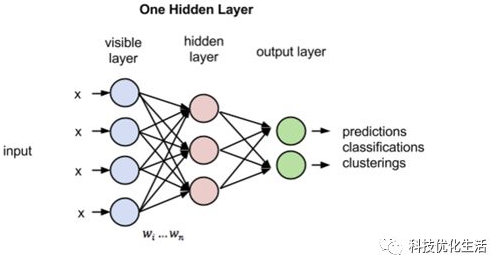
MLP神经网络的结构和原理
-
基于生物神经元模型可得到多层感知器MLP的基本结构,最典型的MLP包括包括三层:输入层、隐层和输出层,MLP神经网络不同层之间是全连接的(全连接的意思就是:上一层的任何一个神经元与下一层的所有神经元都有连接)。
-
MLP多层感知器(Multi-layerPerceptron)是一种前向结构的人工神经网络ANN,映射一组输入向量到一组输出向量。
- MLP可以被看做是一个有向图,由多个节点层组成,每一层全连接到下一层。
- 除了输入节点,每个节点都是一个带有非线性激活函数的神经元。
- 使用BP反向传播算法的监督学习方法来训练MLP。
- MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。
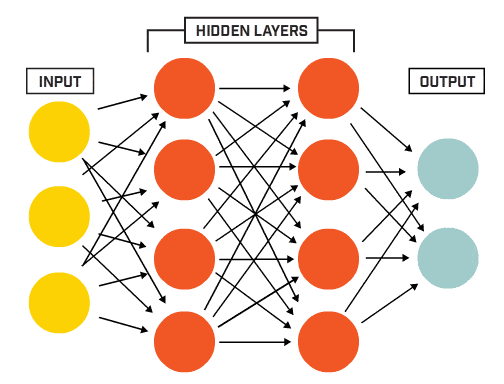
(Multi-layerPerceptron)是一种前向结构**的人工神经网络ANN,映射一组输入向量到一组输出向量。
- MLP可以被看做是一个有向图,由多个节点层组成,每一层全连接到下一层。
- 除了输入节点,每个节点都是一个带有非线性激活函数的神经元。
- 使用BP反向传播算法的监督学习方法来训练MLP。
- MLP是感知器的推广,克服了感知器不能对线性不可分数据进行识别的弱点。