在深度学习的实际应用中,数据集的不足常常是一个难题。为了应对这个问题,迁移学习成为了一种常见的解决方案。通过在一个大型基础数据集(如ImageNet)上预训练模型,然后将这个模型应用到特定任务上,可以显著提升模型的性能。在这篇博客中,我们将详细介绍如何使用迁移学习的方法,基于ResNet50模型对ImageNet数据集中的狼和狗图像进行分类。该方法不仅能够节省训练时间,还能提高模型的准确性。
为什么使用迁移学习?
- 数据不足:在实际应用中,获取大量标注数据集往往是困难的。迁移学习通过在大型数据集上预训练模型,然后将其应用到特定任务上,可以有效解决数据不足的问题。
- 节省时间和计算资源:从头开始训练一个深度神经网络需要大量的计算资源和时间,而迁移学习可以通过使用预训练模型,大大减少训练时间和计算量。
数据准备
为什么要进行数据增强?
- 提高模型泛化能力:数据增强通过对训练数据进行随机变换(如裁剪、翻转等),可以生成更多的训练样本,帮助模型更好地泛化到未见过的数据。
- 防止过拟合:数据增强可以增加数据的多样性,减少模型过拟合的风险,从而提高模型在验证集和测试集上的表现。
首先,我们需要下载用于分类的狗与狼数据集。数据集中的图像来自ImageNet,每个分类有大约120张训练图像和30张验证图像。下载并解压数据集到当前目录下:
from download import download
dataset_url = "https://mindspore-website.obs.cn-north-4.myhuaweicloud.com/notebook/datasets/intermediate/Canidae_data.zip"
download(dataset_url, "./datasets-Canidae", kind="zip", replace=True)
数据集的目录结构如下:
datasets-Canidae/data/
└── Canidae
├── train
│ ├── dogs
│ └── wolves
└── val
├── dogs
└── wolves
加载数据集
使用mindspore.dataset.ImageFolderDataset接口来加载数据集,并进行相关图像增强操作:
import mindspore as ms
import mindspore.dataset as ds
import mindspore.dataset.vision as vision
# 数据集目录路径
data_path_train = "./datasets-Canidae/data/Canidae/train/"
data_path_val = "./datasets-Canidae/data/Canidae/val/"
def create_dataset_canidae(dataset_path, usage):
data_set = ds.ImageFolderDataset(dataset_path, num_parallel_workers=4, shuffle=True)
mean = [0.485 * 255, 0.456 * 255, 0.406 * 255]
std = [0.229 * 255, 0.224 * 255, 0.225 * 255]
scale = 32
if usage == "train":
trans = [
vision.RandomCropDecodeResize(size=224, scale=(0.08, 1.0), ratio=(0.75, 1.333)),
vision.RandomHorizontalFlip(prob=0.5),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
else:
trans = [
vision.Decode(),
vision.Resize(224 + scale),
vision.CenterCrop(224),
vision.Normalize(mean=mean, std=std),
vision.HWC2CHW()
]
data_set = data_set.map(operations=trans, input_columns='image', num_parallel_workers=4)
data_set = data_set.batch(18)
return data_set
dataset_train = create_dataset_canidae(data_path_train, "train")
dataset_val = create_dataset_canidae(data_path_val, "val")
数据集可视化
从训练数据集中获取一批图像并进行可视化:
import matplotlib.pyplot as plt
import numpy as np
data = next(dataset_train.create_dict_iterator())
images = data["image"]
labels = data["label"]
class_name = {0: "dogs", 1: "wolves"}
plt.figure(figsize=(5, 5))
for i in range(4):
data_image = images[i].asnumpy()
data_label = labels[i]
data_image = np.transpose(data_image, (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
data_image = std * data_image + mean
data_image = np.clip(data_image, 0, 1)
plt.subplot(2, 2, i+1)
plt.imshow(data_image)
plt.title(class_name[int(labels[i].asnumpy())])
plt.axis("off")
plt.show()

训练模型
本章使用ResNet50模型进行训练。通过设置pretrained参数为True来下载预训练模型并将权重参数加载到网络中。
构建ResNet50网络
from mindspore import nn, train
from mindspore.common.initializer import Normal
from typing import Type, Union, List, Optional
class ResidualBlockBase(nn.Cell):
# 省略代码...
class ResidualBlock(nn.Cell):
# 省略代码...
def make_layer(last_out_channel, block: Type[Union[ResidualBlockBase, ResidualBlock]], channel: int, block_nums: int, stride: int = 1):
# 省略代码...
class ResNet(nn.Cell):
# 省略代码...
def _resnet(model_url: str, block: Type[Union[ResidualBlockBase, ResidualBlock]], layers: List[int], num_classes: int, pretrained: bool, pretrianed_ckpt: str, input_channel: int):
# 省略代码...
def resnet50(num_classes: int = 1000, pretrained: bool = False):
# 省略代码...
固定特征进行训练
为什么要冻结除最后一层之外的所有网络层?
- 固定特征提取器:冻结网络的早期层可以将它们作为固定特征提取器使用,这些层已经在大型数据集上学到了丰富的特征表示。通过只训练最后一层,我们可以专注于特定任务的学习,提高分类的准确性。
- 减少计算量:冻结大部分网络层意味着在训练过程中不需要计算这些层的梯度,从而减少了计算量,加快了训练速度。
冻结除最后一层之外的所有网络层,通过设置requires_grad == False来实现:
net_work = resnet50(pretrained=True)
# 重置全连接层和平均池化层
in_channels = net_work.fc.in_channels
head = nn.Dense(in_channels, 2)
net_work.fc = head
avg_pool = nn.AvgPool2d(kernel_size=7)
net_work.avg_pool = avg_pool
# 冻结除最后一层外的所有参数
for param in net_work.get_parameters():
if param.name not in ["fc.weight", "fc.bias"]:
param.requires_grad = False
opt = nn.Momentum(params=net_work.trainable_params(), learning_rate=0.001, momentum=0.9)
loss_fn = nn.SoftmaxCrossEntropyWithLogits(sparse=True, reduction='mean')
def forward_fn(inputs, targets):
logits = net_work(inputs)
loss = loss_fn(logits, targets)
return loss
grad_fn = ms.value_and_grad(forward_fn, None, opt.parameters)
def train_step(inputs, targets):
loss, grads = grad_fn(inputs, targets)
opt(grads)
return loss
model1 = train.Model(net_work, loss_fn, opt, metrics={"Accuracy": train.Accuracy()})
训练和评估
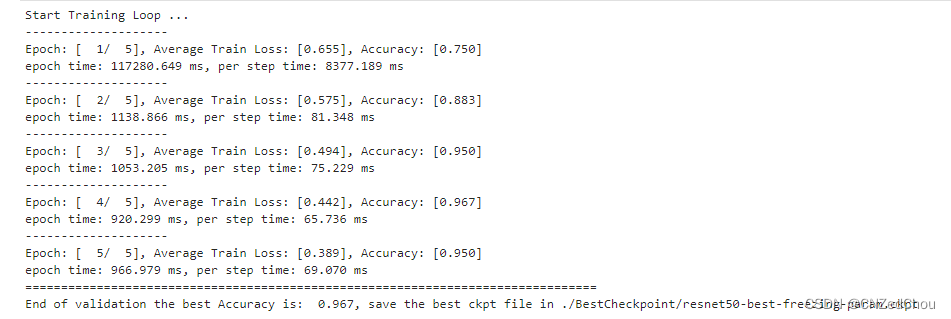
开始训练模型,并保存评估精度最高的ckpt文件:
num_epochs = 5
data_loader_train = dataset_train.create_tuple_iterator(num_epochs=num_epochs)
data_loader_val = dataset_val.create_tuple_iterator(num_epochs=num_epochs)
best_ckpt_path = "./BestCheckpoint/resnet50-best-freezing-param.ckpt"
best_acc = 0
for epoch in range(num_epochs):
losses = []
net_work.set_train()
epoch_start = time.time()
for i, (images, labels) in enumerate(data_loader_train):
labels = labels.astype(ms.int32)
loss = train_step(images, labels)
losses.append(loss)
acc = model1.eval(dataset_val)['Accuracy']
epoch_end = time.time()
print(f"Epoch: {epoch+1}, Loss: {sum(losses)/len(losses)}, Accuracy: {acc}, Time: {epoch_end - epoch_start}s")
if acc > best_acc:
best_acc = acc
ms.save_checkpoint(net_work, best_ckpt_path)
print(f"Best Accuracy: {best_acc}, Model saved at {best_ckpt_path}")
可视化模型预测
使用训练好的模型对验证集进行预测,并可视化结果:
def visualize_model(best_ckpt_path, val_ds):
net = resnet50()
in_channels = net.fc.in_channels
head = nn.Dense(in_channels, 2)
net.fc = head
avg_pool = nn.AvgPool2d(kernel_size=7)
net.avg_pool = avg_pool
param_dict = ms.load_checkpoint(best_ckpt_path)
ms.load_param_into_net(net, param_dict)
model = train.Model(net)
data = next(val_ds.create_dict_iterator())
images = data["image"].asnumpy()
labels = data["label"].asnumpy()
class_name = {0: "dogs", 1: "wolves"}
output = model.predict(ms.Tensor(data['image']))
pred = np.argmax(output.asnumpy(), axis=1)
plt.figure(figsize=(5, 5))
for i in range(4):
plt.subplot(2, 2, i + 1)
color = 'blue' if pred[i] == labels[i] else 'red'
plt.title('predict:{}'.format(class_name[pred[i]]), color=color)
picture_show = np.transpose(images[i], (1, 2, 0))
mean = np.array([0.485, 0.456, 0.406])
std = np.array([0.229, 0.224, 0.225])
picture_show = std * picture_show + mean
picture_show = np.clip(picture_show, 0, 1)
plt.imshow(picture_show)
plt.axis('off')
plt.show()
visualize_model(best_ckpt_path, dataset_val)
通过迁移学习,我们成功地将ResNet50应用于狼狗分类任务,并且通过冻结部分网络层来减少计算量,显著提升了训练速度。
