Scrapy 框架的使用
一 Scrapy 框架的介绍
1.架构介绍
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架,其架构清晰, 榄块之 间的榈合程度低,可扩展性极强,可以灵活完成各种需求。 我们只需要定制开发几个模块就可以轻松 实现一个爬虫。
首先我们先看scrpay的框架的架构,如下图所示:
它可以分为以下几个部分。
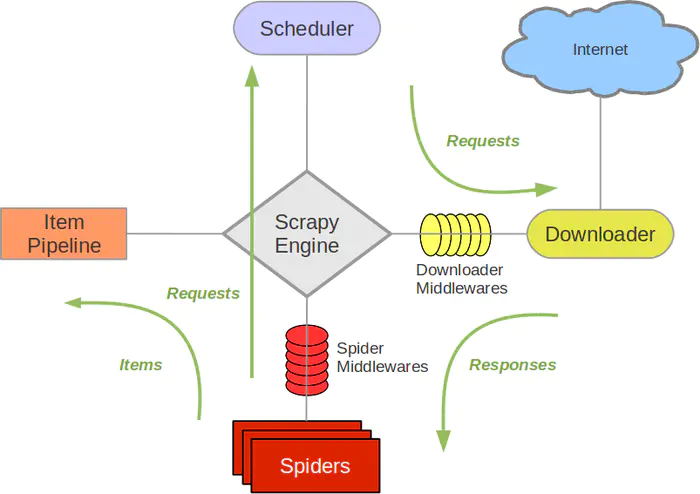
- Engine(引擎):处理整个系统的数据流、触发事务,是整个框架的核心。
- Spider(蜘蛛):它定义了网页的解析规则,主要负责提取所需要的数据和发起新的网络请求。
- Scheduler(调度器):负责接收引擎发送过来的请求,当引擎再次请求的时候将请求提供给引擎。
- Item Pipeline(管道):它主要负责将spider中的数据保存在存储中。
- Downloader Middlewares(下载中间件):位于引擎和下载器之间的钩子框架,主要处理引 擎与下载器之间的请求及响应。
- Spider Middlewares(Spider中间件):位于引擎和蜘蛛之间的钩子框架,主要处理蜘蛛输入的 响应和输出的结果及新的请求。
2.数据流
Scrapy 中的数据流由引擎控制,数据流的过程如下。
(I) Engine首先打开一个网站,向该 Spider请求要爬取的 URL。
(2) Engine 从 Spider 中获取到要爬取的 URL,并通过 Scheduler 以 Request 方式调度。
(3) Engine 向 Scheduler请求下一个要爬取的 URL。 l
(4) Scheduler返回下一个要爬取的 URL 给 Engine , Engine 收到URL后通过Downloader Middlewares 转 发给 Downloader下载。
(5)一旦页面请求下载完毕,Downloader返回 Response,并将其通过DownloaderMiddlewares 发送给 Engine。
(6) Engine接收到Response后,并将其通过 Spider Middlewares 发送给 Spider处理,进行网页的提取。
(7) Spider处理 Response,并返回爬取到的 Item或者发起 scrapy.Request 给 Engine。
(8) Engine将 Spider 返回的 Item 给 Item Pipeline,将新的 Request 给 Scheduler。
(9)重复第(2)步到第(8)步,直到 Scheduler 中没有更多的 Request, Engine关闭该网站,爬取结束。
3.项目结构目录介绍
- scrapy.cfg
- project/
- _ init _.py
- items.py
- middlewares.py
- pipelines.py
- settings.py
- spiders/
- _ init _.py
- spider1.py
- scrapy.cfg:它是scrapy项目的配置文件,其内定义了项目的配置文件路径 等内容。
- items.py:在它定义了所有的item。
- middlewares.py:它定义 Spider Middl巳wares 和 Downloader Middlewares 的实现。
- pipelines.py:它定义 Item Pipeline 的实现,所有的 Item Pipeline 的实现都可以放这里。
- settings.py:在它里面修改全局的配配置。
- spiders:里面包含了许多的spider。
二 Scrapy 入门
1.创建爬虫项目
创建一个新的项目文件,命令如下:
scrapy startproject firstspider #scrapy startproject [项目名称]
2.创建spider
使用命令行创建一个 Spider。 比如要生成 Quotes 这个 Spider,可以执行如下命令:
cd firstspider
scrapy genspider quotes quotes.toscrape.com
进入刚刚生成的firstspider项目目录里面,然后执行genspider命令,第一个参数是Spider(爬虫)名称,第二个参数是所要爬取的网站的域名。执行完此命令,在Spiders目录里面就会多出一个spider.py文件,它刚开始的文件内容如下:
import scrapy
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
pass
这里面有三个属性——name、allowed_domains、start_urls,还有一个方法parse。
- name,它是spider的名称,每个spider名称不同,它是用来区分每一个spider。
- allowed_domains,允许爬取的域名。
- start_urls,需要爬取的url列表也可以是单个的url。
- parse,它是 Spider 的一个方法。
3.创建item
创建item需要继承scrapy.Item,并定义类为scrapy.Field字段。通过观察所要爬取的网站,我们可以获取到text、author、tags。
代码如下:
class SpiderquotesItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
text=scrapy.Field()
author=scrapy.Field()
tags=scrapy.Field()
4.解析页面
<div class="quote" itemscope="" itemtype="http://schema.org/CreativeWork">
<span class="text" itemprop="text">“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”</span>
<span>by <small class="author" itemprop="author">Albert Einstein</small>
<a href="/author/Albert-Einstein">(about)</a>
</span>
<div class="tags">
Tags:
<meta class="keywords" itemprop="keywords" content="change,deep-thoughts,thinking,world">
<a class="tag" href="/tag/change/page/1/">change</a>
<a class="tag" href="/tag/deep-thoughts/page/1/">deep-thoughts</a>
<a class="tag" href="/tag/thinking/page/1/">thinking</a>
<a class="tag" href="/tag/world/page/1/">world</a>
</div>
</div>
通过观察网页的源代码,我们可以选择使用css或者xpath选择器来提取页面。这里我们使用css选择器,在parse方法里面定义提取规则,代码如下:
def parse(self, response):
quotes=response.css('.quote')
for quote in quotes:
item=SpiderquotesItem()
text=quote.css("span.text::text").extract_first()
#除了extract_first方法之外,我们还可以用get方法,和extract()[0]的这种方式
author=quote.css(".author::text").extract_first()
tags=quote.css(".tag::text").extract()
使用css选择器提取所有的quote,将其定义为quotes其类型是一个列表,通过遍历quotes的每一个元素quote,解析每一个quote的内容。
对于text的提取,通过观察html代码可以发现,它是由span标签包裹着并且只有一个class属性text,所以我们可以.text来获取,要取文本内容还要::text。前边代码提取到的是一个列表,需要进一步提取,还需要extract_first()方法获取第一个元素。
对于author也是类似的方法。
对于tags的提取观察页面会发现有多个tag,所以我们直接用extract方法来提取。
5.使用item
使用item前需要引入创建好的item,然后实例化。item类似是一个字典的形式,我们需要把刚刚解析出来的text、author、tags分别赋值给item中的text、author、tags。最后我们需要返回item。
parse方法改写如下:
import scrapy
from ..items import SpiderquotesItem
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes=response.css('.quote')
for quote in quotes:
item=SpiderquotesItem()
text=quote.css("span.text::text").extract_first()
author=quote.css(".author::text").extract_first()
tags=quote.css(".tag::text").extract()
item['text']=text
item['author']=author
item['tags']=tags
yield item
6.翻页
我们会发现页面上有一个next点击的按钮,如下图:
通过观察标签内容,会发现href的属性值为:/page/2/,完整的翻页链接为:http://quotes.toscrape.com/page/2/,通过这个链接我们可以构造下一个请求。

构造请求需要用到scrapy.Request,参数url、callback、meta等,这两个参数的说明入下:
url:下一个请求的url地址。
callback:回调函数。
meta:发起request需要传递的参数。
parse方法代码如下:
next=response.css(".pager .next a::attr('href')").extract_first()
url=response.urljoin(next)
yield scrapy.Request(url=url,callback=self.parse)
现在整个spider类的代码如下:
import scrapy
from ..items import SpiderquotesItem
class QuoteSpider(scrapy.Spider):
name = 'quote'
allowed_domains = ['quotes.toscrape.com']
start_urls = ['http://quotes.toscrape.com/']
def parse(self, response):
quotes=response.css('.quote')
for quote in quotes:
item=SpiderquotesItem()
text=quote.css("span.text::text").extract_first()
author=quote.css(".author::text").extract_first()
tags=quote.css(".tag::text").extract_first()
item['text']=text
item['author']=author
item['tags']=tags
yield item
next=response.css(".pager .next a::attr('href')").extract_first()
url=response.urljoin(next)
yield scrapy.Request(url=url,callback=self.parse)
7.运行
使用代码运行项目,命令如下:
scrapy crawl quote
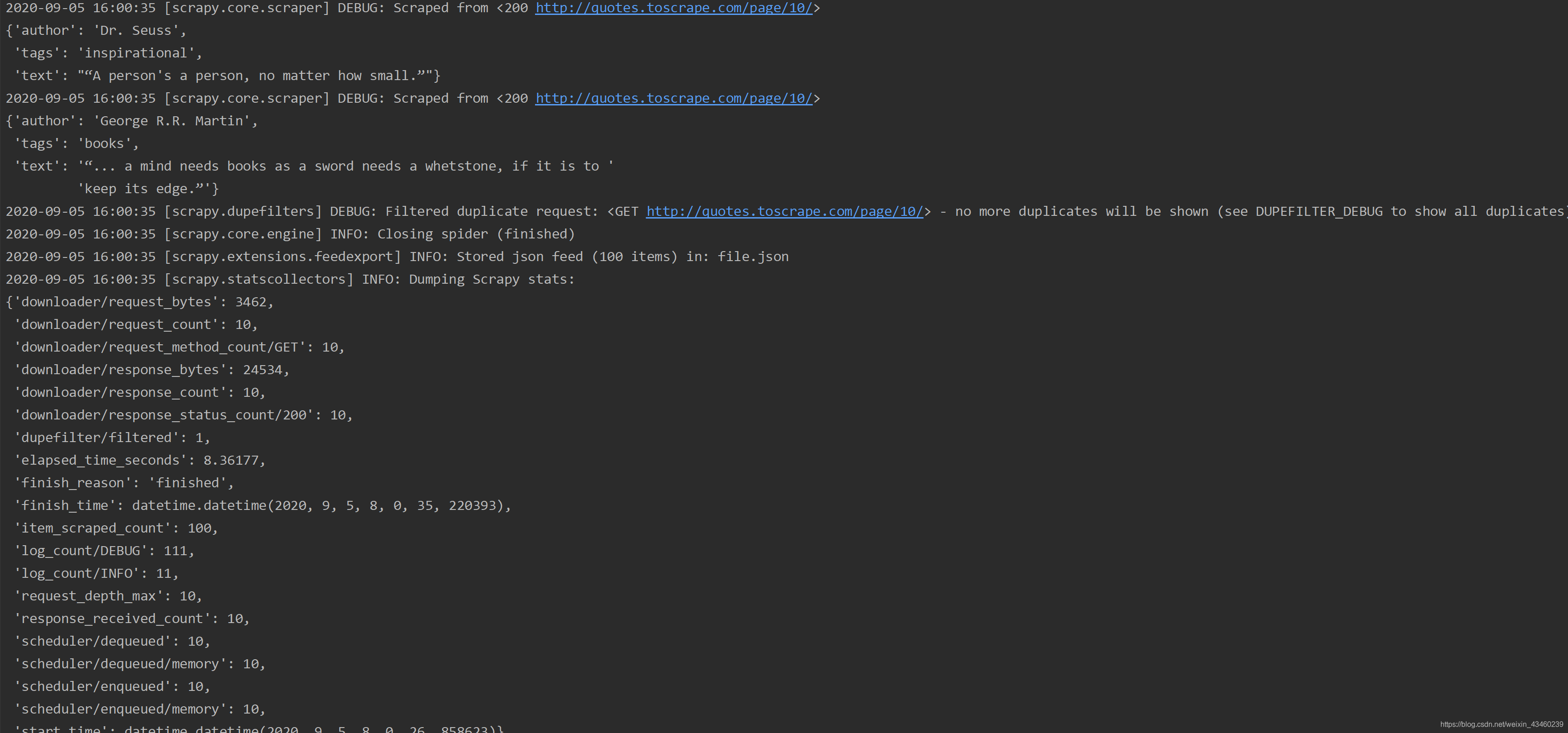
可以看到页面的输出结果
这里截取的是部分输出结果。
8.保存到文件
要想把提取的数据保存到文件中,可以执行下面的命令:
scrapy crawl quotes -o quotes.txt
命令运行后会发现项目文件夹下多了一个quote.txt的文件。
输出格式还支持很多种,例如 csv、 xml、 pickle、json、 marshal 等,还支持 ftp、 s3 等远程输出,另外 还可以通过自定义 ItemExporter来实现其他的输出。
例如,下面命令对应的输出分别为 csv、 xml、 pickle、 marshal 格式以及句远程输出 : 回
scrapy crawl quotes -o quotes.csv
scrapy crawl quotes -o quotes.xml
scrapy crawl quotes -o quotes.pickle
scrapy crawl quotes -o quotes.marshal
scrapy crawl quotes -o ftp://user:pass@ftp.example.com/path/to/quotes.csv
其中, 句输出需要正确配置用户名、密码、 地址、 输出路径,否则会报错。
9.使用item pipelines
在此处不过多介绍,只展示代码:
class SpiderquotesPipeline(object):
def open_spider(self,spider):
self.fp=open('file.txt',mode='a',encoding='utf8')
def process_item(self, item, spider):
text=item['text']
author=item['author']
tags=item['tags']
self.fp.write("%s,%s,%s\r\n"%(text,author,tags))
return item
def close_spider(self,spider):
self.fp.close()
10.全局配置
# Obey robots.txt rules
ROBOTSTXT_OBEY = False #默认为True,是否遵守robot协议
# Override the default request headers:
DEFAULT_REQUEST_HEADERS = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# Configure item pipelines
# See https://docs.scrapy.org/en/latest/topics/item-pipeline.html
ITEM_PIPELINES = {
'spiderquotes.pipelines.SpiderquotesPipeline': 300, #优先级,数字越小越先执行
}
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.135 Safari/537.36'