1 目标检测的背景
作为机器视觉领域的核心问题之一,目标检测的任务是找出图像中所有的目标(物体),并确定它们的位置和大小。由于各类物体有不同的外观,形状,姿态,加上成像时光照,遮挡等因素的干扰,目标检测一直是机器视觉领域最具有挑战性的问题。因此,从本质上来说,目标检测包含两个主要任务:物体图像的识别和物体在图像中的定位。目前,目标检测主要应用于行人检测、车辆检测、人脸识别、医疗图像检测等。
目标检测的核心问题可以总结为三点:1)图像中物体类别的区分;2)目标在图像中位置的确定;3)目标大小形状变化的考虑。按照算法是否需要中间产生候选区域(region proposals),目前的目标检测算法可以大致分为两类,即two-stage与one-stage;之前还有multi-stage系列的算法,不过由于速度和准确度上的差距,已经很少被使用。
two-stage检测算法将检测问题划分为两个阶段,首先产生候选区域,然后对位置精修后进行候选区域分类。two-stage检测算法识别错误率低,漏识别率也较低,但速度较慢,不能满足实时检测场景,比如视频目标检测中。
one-stage检测算法不需要产生候选区域阶段,直接产生物体的类别概率和位置坐标值,经过单次检测即可直接得到最终的检测结果,因此有着更快的检测速度,但是一般识别精度和准确度上比two-stage的算法要差一些。
按照上述对于算法的分类,主流的two-stage与one-stage目标检测算法如表所示。
| One-stage算法 | Two-stage算法 |
|---|---|
| YOLO V1、YOLO V2、YOLO V3 | Fast R-CNN、Faster R-CNN |
| G-CNN | HyperNet、MS-CNN、PVANet |
| R-SSD、DSSD、DSOD、FSSD | MR-CNN、FPN、CRAFT |
| RON | CoupleNet、Mask R-CNN |
| OHEM、Soft-NMS |
2 所用Faster-RCNN与YOLO V3模型结构
针对上述两个系列two-stage与one-stage算法,分别选取其代表性的目标检测算法Faster-RCNN与YOLO V3,下面分别对两个算法的原理进行一个简单的介绍,并会介绍一下实际采用的Faster-RCNN与YOLO V3的一些结构和特点。
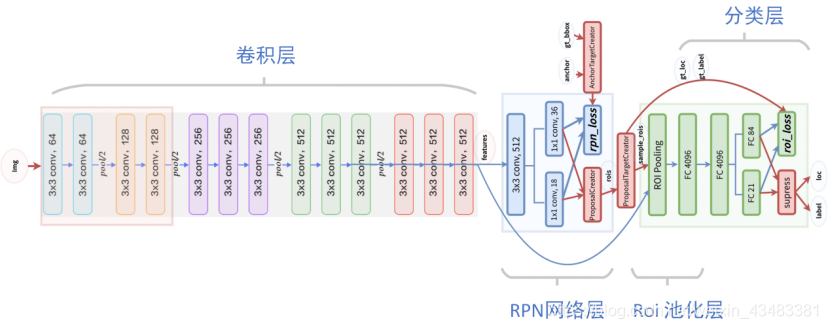
Faster-RCNN是two-stage检测算法的重要组成,其后续的很多改进目标检测算法也保留了Faster-RCNN的一些特点。网络结构如图,与标准的Faster-RCNN模型一样,也包括4个大的组成部分,分别是用于提取图像特征的VGG16卷积层、生成候选区域的RPN网络层、收集feature maps和proposals的Roi 池化层以及最后用于图像分类和计算bounding box回归的分类层。
YOLO V3是第三代的YOLO目标检测算法,是对于前两代YOLO算法的革新。针对YOLO V1与V2的对于小目标物体检测识别率低的问题,YOLO V3以牺牲小部分的运行时间为代价,换来了检测准确率很大的提升。在YOLO V3中主要采用了三个改进:1)使用多级预测解决颗粒度粗,对小目标无力的问题。YOLO V3具有3个detection,分别是1个下采样的、feature map为13 * 13的,还有2个上采样的eltwise sum,feature map为26*26,52*52的。2)使用了logistic loss函数作为新的损失函数,使得YOLO V3可以对重叠区域进行分类和框选。3)网络结构进行了加深,使用简化的residual block 取代了原来 1×1 和 3×3的blockblock,并将原来的darknet-19变成了darknet-53。本次也是采用了这样的模型结构。
3 设置与结果
围绕Faster-RCNN和YOLO V3两个数据集展开,都使用VOC数据集对两种模型进行训练,并比较其在测试集上的表现程度,其中Faster-RCNN使用的VGG16模型权重进行的初始化,YOLO V3使用的darknet53模型权重进行初始化。由于计算资源有限(MX150 显卡),无法对于VOC数据集进行充分的训练,训练不完全的模型也无法代表其模型真实能力,因此使用已经训练好的模型对其在VOC2007测试集上的表现进行评估,结果如表所示。
| 目标检测模型 | mAP |
|---|---|
| Faster-RCNN | 0.705 |
| YOLO V3 | 0.858 |
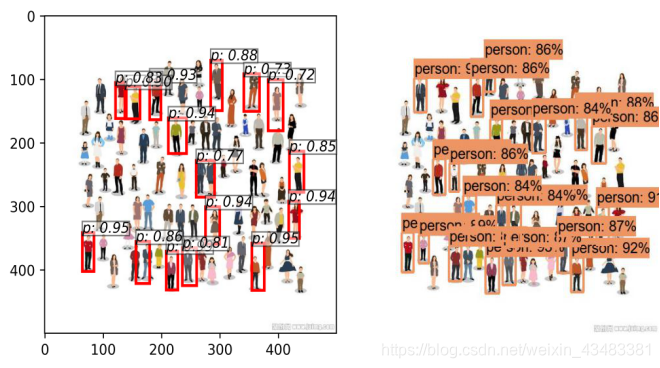
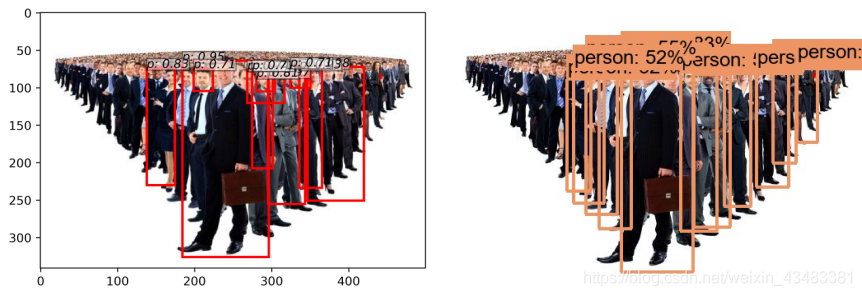
从mAP值角度,Faster-RCNN在VOC测试集上的表现不如YOLO V3。为了更好地探索和研究两种算法对于目标检测任务的效果,本次针对实际的一些图片,对于这两种模型的目标检测效果进行直观比较,两种模型的检测结果如图所示,其中左边代表示Faster-RCNN结果,右边代表YOLO V3结果。

4 代码
由于两个模型都是源于多年前的论文,pytorch架构没有将其进行集成,因此需要从头开始自己搭建和调试,所以代码比较庞大,放到了github上:
YOLO V3
Faster-RCNN
源码在windows10 + python3.7的环境下可以运行,默认是GPU pytorch,但是需要下载一些第三方库,可以直接运行。
5 总结
总的来说,本次实验获得了以下两点结论:
1)YOLO V3算法相比于V1 与V2确实有了很大的改进,尤其是在小物体检测以及重叠物体检测方面,具有了很大的突破,但是其泛化能力可能会过强。
2)One-stage算法由其算法结构决定了其准确率一般会低于two-stage算法,但是一般这两者之间的准确率差距不会太大,而YOLO等one-stage算法凭借其更快的前向传播速度,使其应用可能会更加广泛。