Pre-Trained Image Processing Transformer阅读笔记
Abstract
我们研究了底层计算机视觉任务(如去噪,超分辨率和去雨),开发了IPT。只通过一个预训练好的模型,IPT在各种低水平的benchmark上达到state-of-the-art的水平。
1 Introduction
图像处理是更全局的图像分析,或者是计算机视觉系统的低级部分 的一个组成部分。图像处理的结果很大程度上影响后续的对图像数据的识别和理解。
[56, 22]应用基于self-attention的模型来捕捉图像上的全局信息。
2 Related Works
2.1 Image Processing
2.2 Transformer
将Transformer引入CV领域,主要有两种方式,一是在传统卷积神经网络中引入self-attention。另一种是用self-attention完全替代CNN。
3 Image Processing Transformer
3.1 IPT architecture
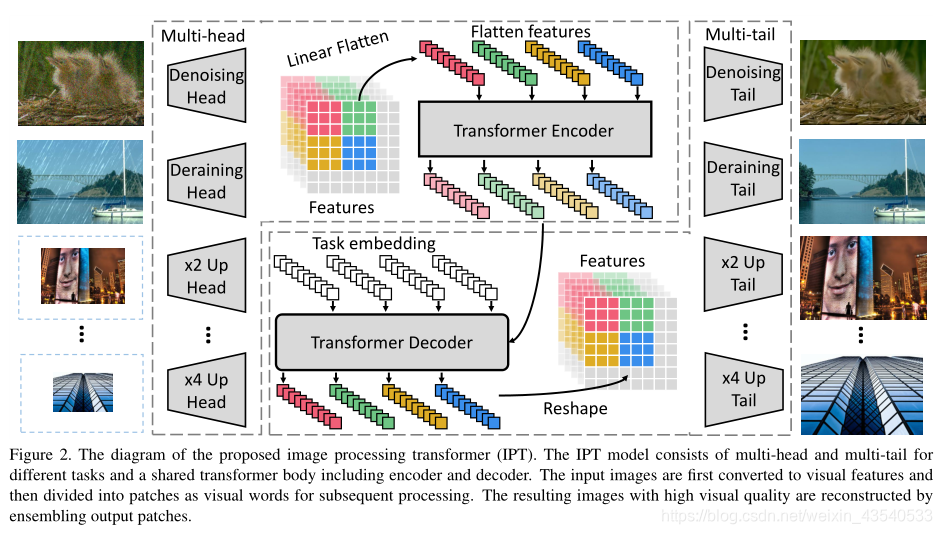
IPT架构整体由四部分构成,
- 头部用于从输入的损坏图像(例如,有噪声的图像和低分辨率图像)中提取特征。
- 编码器-解码器转换器用于恢复输入数据中丢失的信息
- 尾部用于将特征映射到恢复的图像中
Heads. 使用多头分别处理不同每个任务。每个头由三个卷积层组成。输入图像为 x ∈ R 3 × H × W x \in R^{3\times H\times W} x∈R3×H×W,输出为具有 C C C通道和相同高度和宽度的特征图, f H ∈ R C × H × W f_H \in R^{C\times H\times W} fH∈RC×H×W,其中通常 C = 64 C=64 C=64。计算公式为, f H = H i ( x ) f_H =H^i(x) fH=Hi(x),其中 H i ( i = 1 , . . . , N t ) H^i(i={1, . . ., N^t}) Hi(i=1,...,Nt), i i i表示第 i i i个任务。 N t N_t Nt表示任务数。
Transformer encoder. 特征输入transformer之前,将其分割成多个小patches, 每一个patch被视为一个单词。即, f H ∈ R C × H × W f_H \in R^{C\times H\times W} fH∈RC×H×W被reshape成 f p i ∈ R P 2 × C , i = 1 , . . . , N f_{p_i}\in R^{P^{2} \times C}, i = {1, . . . , N} fpi∈RP2×C,i=1,...,N,其中 N = H W P 2 N=\frac {HW}{P^2} N=P2HW,为patch的数量,即序列长度。为每个patch添加可学习的位置编码 E P i ∈ R P 2 × C E_{P_i} \in R^{P^2 \times C} EPi∈RP2×C。 直接相加, E P i + f P i E_{P_i} + f_{P_i} EPi+fPi。transformer内部遵循原始结构,包括一个MHSA和一个FFN
encoder的输出 f E i ∈ R P 2 × C f_{E_i} \in R^{P^2 \times C} fEi∈RP2×C与encoder的输入 f p i f_{p_i} fpi相同。
Transformer decoder.
encoder的输出,作为decoder的输入,decoder由两层MHSA和一个FFN组成。与原始decoder不同的是,使用了特定任务的embedding作为decoder的附加输入。特定任务的embedding, E t i ∈ R P 2 × C , i = 1 , . . . , N t E^i_t \in R^{P^2 \times C}, i= {1, ... , N_t} Eti∈RP2×C,i=1,...,Nt
Tails. 使用多尾来处理不同的任务。输出 f T f_T fT的结果图像大小为 3 × H ′ × W ′ 3\times H' \times W' 3×H′×W′,比如在2倍超分辨率任务中, H ′ = 2 H , W ′ = 2 W H'=2H, W'=2W H′=2H,W′=2W。
3.2 Pre-training on ImageNet
除了transformer的结构外,成功训练模型的一个关键因素是大规模的训练数据集。通过ImageNet退化变换为适合7个不同任务的数据集。
以监督方式学习我们的IPT的损失函数可以表述为
L s u p e r v i s e d = ∑ i = 1 N t L 1 ( I P T ( I c o r r u p t e d i ) , I c l e a n ) L_{supervised}=\sum_{i=1}^{N_t}{L_1(IPT(I^i_{corrupted}), I_{clean})} Lsupervised=i=1∑NtL1(IPT(Icorruptedi),Iclean)
L1表示重建所需图像的常规L1损失
4 Experiments
消融研究的大量实验表明,当使用大规模数据集来解决图像处理问题时,基于变压器的模型比卷积神经网络具有更好的性能。
Datasets.
Training & Fine-tuning. 使用32个 NVIDIA Tesla V100,使Adam优化器。
4.1 Super-resolution
而我们的模型生成的超分辨率图像可以很好地从低分辨率图像中恢复细节
4.2 Denoising
4.3 Deraining
4.4 Generalization Ability
4.5 Ablation Study
**Impact of data percentage. **
Impact of contrastive learning.
5 Conclusions and Discussions
然后,使用监督和自监督方法训练IPT模型,这种方法显示出为低级图像处理捕获内在特征的强大能力。