Java八股
Hashmap
底层实现:
Java7基于:哈希表:数组+链表
Java8基于:数组+链表+红黑树
它使用哈希函数将键映射到数组的索引位置,如果多个键映射到同一个索引(碰撞),则使用链表来存储这些键值对。
如果选择合适的哈希函数,put()和get()方法可以在常数时间内完成。但在对HashMap进行迭代时,需要遍历整个table以及后面跟的冲突链表。因此对于迭代比较频繁的场景,不宜将HashMap的初始大小设的过大。
有两个参数可以影响HashMap的性能:初始容量(inital capacity)和负载系数(load factor)。初始容量指定了初始table的大小,负载系数用来指定自动扩容的临界值。当entry的数量超过capacity*load_factor:初始容量*负载系数 时,容器将自动扩容并重新哈希。对于插入元素较多的场景,将初始容量设大可以减少重新哈希的次数。
将对象放入到HashMap或HashSet中时,有两个方法需要特别关心: hashCode()和equals()。hashCode()方法决定了对象会被放到哪个bucket里,当多个对象的哈希值冲突时,equals()方法决定了这些对象是否是“同一个对象”。所以,如果要将自定义的对象放入到HashMap或HashSet中,需要**@Override** hashCode()和equals()方法。
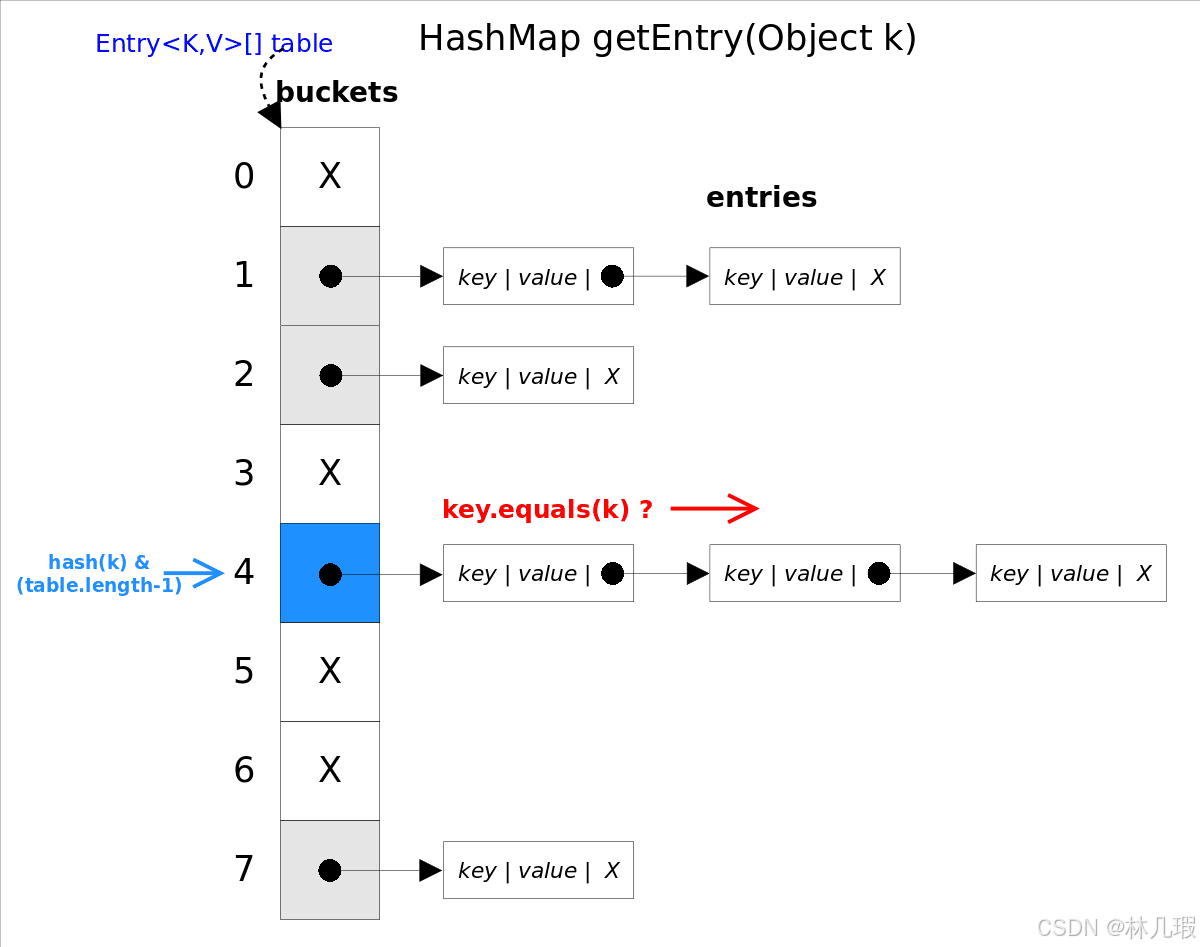
get()方法
get(Object key)方法根据指定的key值返回对应的value,该方法调用了getEntry(Object key)得到相应的entry,然后返回entry.getValue()。因此getEntry()是算法的核心。 算法思想是首先通过hash()函数得到对应bucket的下标,然后依次遍历冲突链表,通过key.equals(k)方法来判断是否是要找的那个entry。
put()方法
put(K key, V value)方法是将指定的key, value对添加到map里。该方法首先会对map做一次查找,看是否包含该元组,如果已经包含则直接返回,查找过程类似于getEntry()方法;如果没有找到,则会通过addEntry(int hash, K key, V value, int bucketIndex)方法插入新的entry,插入方式为头插法。
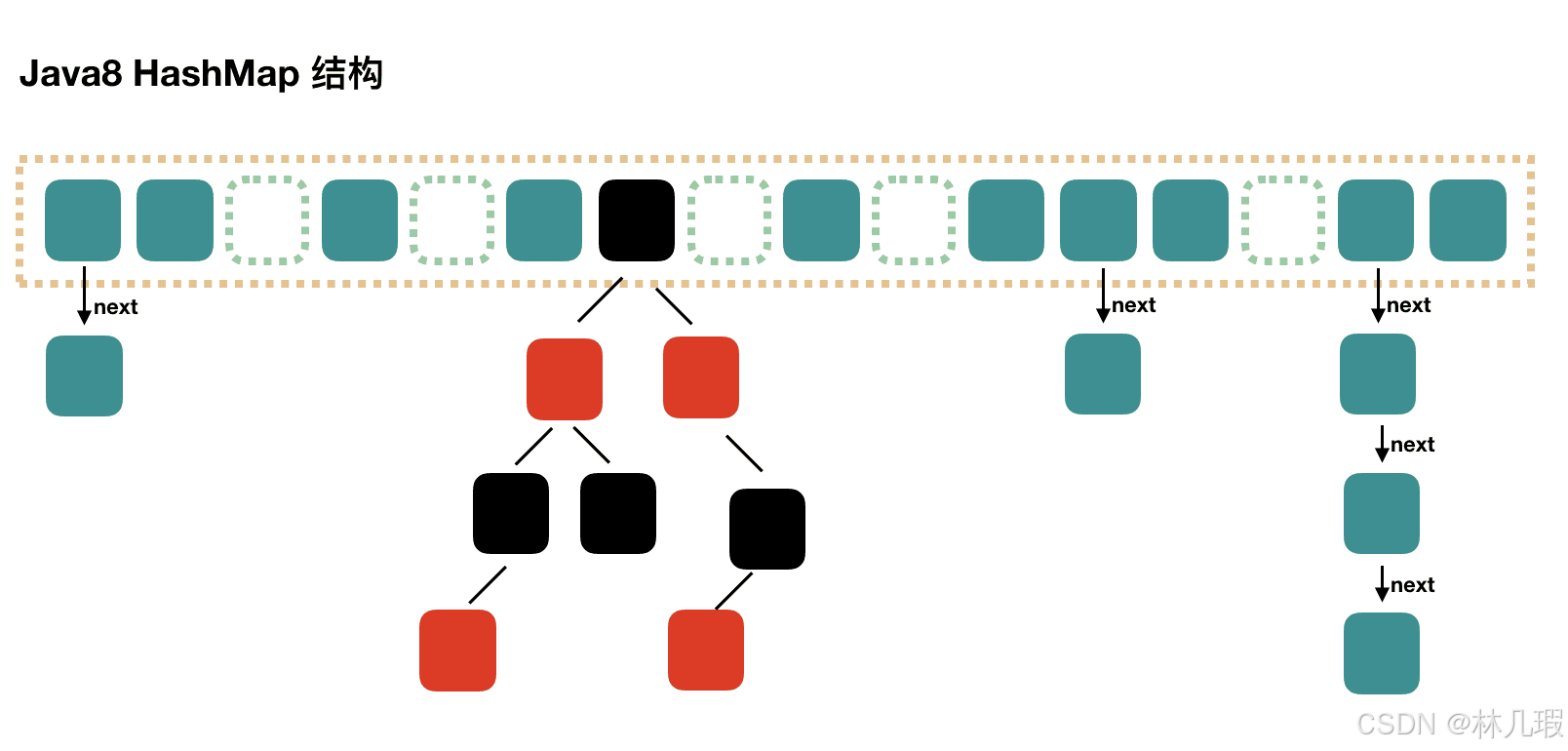
Java8 Hashmap
Java7 HashMap 的介绍,我们知道,查找的时候,根据 hash 值我们能够快速定位到数组的具体下标,但是之后的话,需要顺着链表一个个比较下去才能找到我们需要的,时间复杂度取决于链表的长度,为 O(n)。
在 Java8 中,当链表中的元素达到了 8 个时,会将链表转换为红黑树,在这些位置进行查找的时候可以降低时间复杂度为 O(logN)。
CocurrentHashMap的实现
Hashtable之所以效率低下主要是因为其实现使用了synchronized关键字对put等操作进行加锁,而synchronized关键字加锁是对整个对象进行加锁,也就是说在进行put等修改Hash表的操作时,锁住了整个Hash表,从而使得其表现的效率低下。
Java使用了分段锁机制实现ConcurrentHashMap.
简而言之,ConcurrentHashMap在对象中保存了一个Segment数组,即将整个Hash表划分为多个分段;而每个Segment元素,即每个分段则类似于一个Hashtable;这样,在执行put操作时首先根据hash算法定位到元素属于哪个Segment,然后对该Segment加锁即可。因此,ConcurrentHashMap在多线程并发编程中可是实现多线程put操作。接下来分析JDK1.7版本中ConcurrentHashMap的实现原理
每次需要加锁的操作锁住的是一个 segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
concurrencyLevel: 并行级别、并发数、Segment 数,怎么翻译不重要,理解它。默认是 16,也就是说 ConcurrentHashMap 有 16 个 Segments,所以理论上,这个时候,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。
再具体到每个 Segment 内部,其实每个 Segment 很像之前介绍的 HashMap。Segment 数组不可以扩容,所以负载因子是给每个 Segment 内部使用的。Segment 内部是由数组+链表组成的。
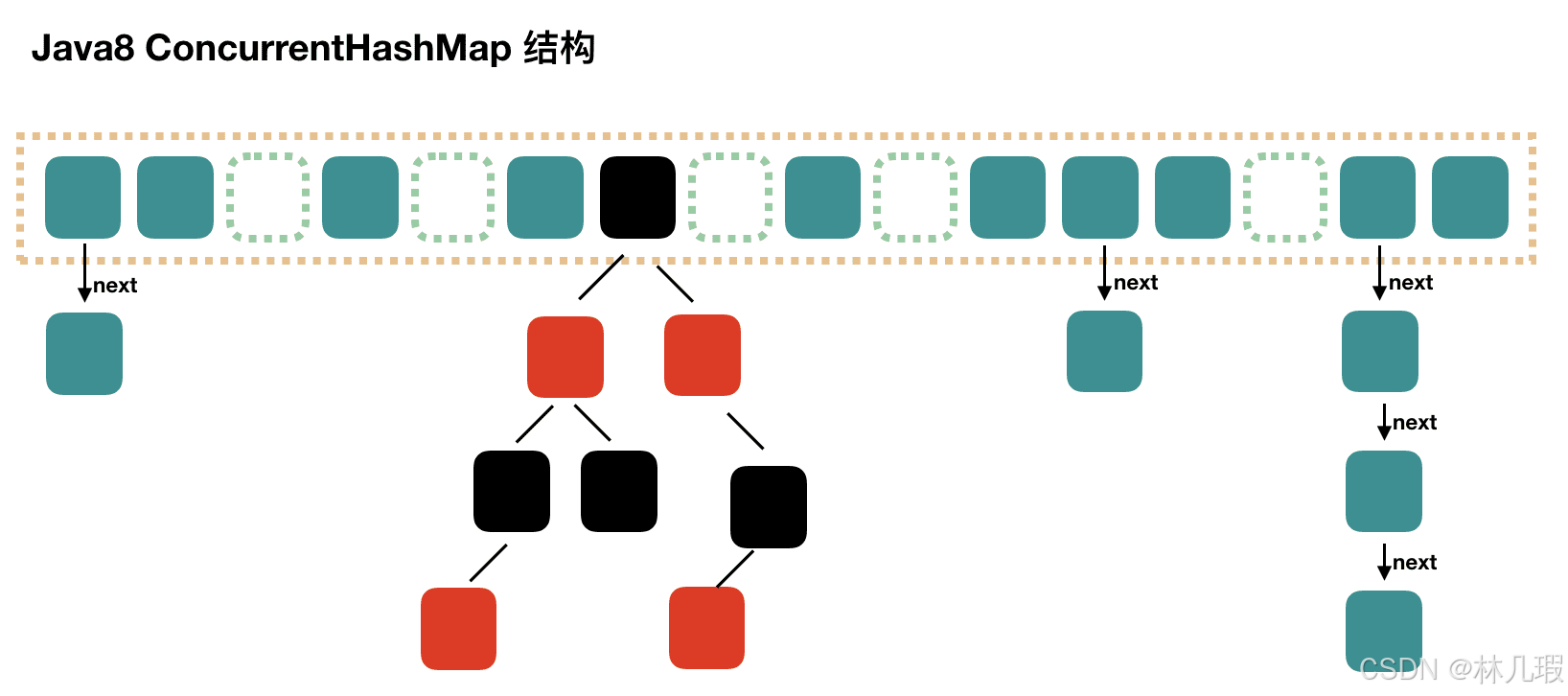
在JDK1.8中,ConcurrentHashMap的实现原理摒弃了这种设计,而是选择了与HashMap类似的数组+链表+红黑树的方式实现,而加锁则采用CAS和synchronized实现。
线程安全
线程安全是指多个线程在同时访问共享资源时,程序的行为依然保持正确,避免因为并发操作导致数据不一致或错误。一个程序或方法是线程安全的,意味着它在多线程环境中可以被多个线程同时访问而不会导致问题。
线程安全的实现方式:
- 互斥锁(锁机制): 使用
synchronized关键字或显式的Lock类来保证多个线程访问共享资源时,只有一个线程能够访问,其他线程必须等待锁被释放。例如,Java 中的ReentrantLock是一种显式锁,可以灵活控制锁的获取与释放。 - 原子操作: 使用原子类(如
AtomicInteger、AtomicLong)通过 CAS(比较并交换)机制来确保操作的原子性,避免竞争条件。这些类在进行增、减、赋值等操作时无需加锁,且能够保证线程安全。 - volatile 关键字: 使用
volatile来确保线程之间的变量可见性。当一个线程修改了被volatile修饰的变量时,其他线程能够立即看到这个更新,而不是使用本地缓存的旧值。 - 不可变对象: 使用不可变对象也是实现线程安全的方式之一。因为不可变对象一旦创建就不会改变,所以多个线程可以安全地共享这些对象,不需要额外的同步措施。比如说被final修饰和String类。字符串的任何修改操作都返回一个新的字符串对象,而不会改变原来的字符串。
- 线程本地存储(ThreadLocal): 每个线程维护自己的一份变量副本,互不干扰,避免竞争条件。
ThreadLocal提供了一种将变量与线程绑定的机制,使得每个线程都有自己的独立变量副本。ThreadLocal是 Java 中的一个类,用于创建线程本地存储。
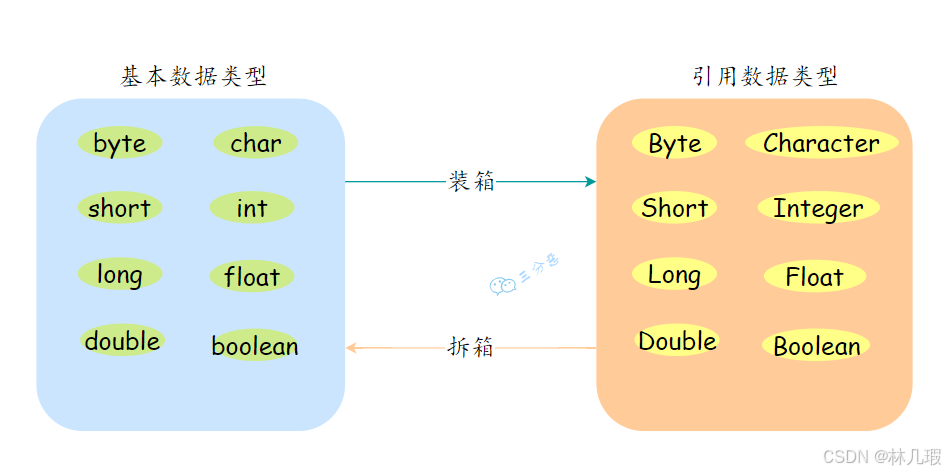
Int 和 Integer 的区别?装箱和拆箱
- 装箱:将基本数据类型转换为包装类型(Byte、Short、Integer、Long、Float、Double、Character、Boolean)。
- 拆箱:将包装类型转换为基本数据类型。
缓存池
- new Integer(123) 每次都会新建一个对象
- Integer.valueOf(123) 会使用缓存池中的对象,多次调用会取得同一个对象的引用。 Java 8 中,Integer 缓存池的大小默认为 -128~127。
基本类型对应的缓冲池如下:
- boolean values true and false
- all byte values
- short values between -128 and 127
- int values between -128 and 127
- char in the range \u0000 to \u007F
在使用这些基本类型对应的包装类型时,就可以直接使用缓冲池中的对象。
比如,这样的两个Integer用了缓冲池中的对象是相等的。
Integer m = 123;
Integer n = 123;
System.out.println(m == n); // true
但是如果是new了一个变量的话,就是不等的。
Integer x = new Integer(123);
Integer y = new Integer(123);
System.out.println(x == y); // false
valueOf会使用缓冲池中的对象:
Integer z =Integer.valueOf(123);
Integer k =Integer.valueOf(123);
System.out.println(z == k);// true
字符串常量池 怎么在底层新建新建字符串 怎么引用已有字符串
String 被声明为 final,因此它不可被继承。
内部使用 char 数组存储数据,该数组被声明为 final,这意味着 value 数组初始化之后就不能再引用其它数组。并且 String 内部没有改变 value 数组的方法,因此可以保证 String 不可变。
String, StringBuffer and StringBuilder
1. 可变性
- String 不可变
- StringBuffer 和 StringBuilder 可变
2. 线程安全
- String 不可变,因此是线程安全的
- StringBuilder 不是线程安全的
- StringBuffer 是线程安全的,内部使用 synchronized 进行同步
字符串常量池(String Constant Pool)是 Java 中用于存储字符串常量的特殊内存区域。字符串常量池 有助于优化内存使用,因为相同的字符串只存储一次。使用字符串字面量创建字符串时,会首先检查常量池中是否已有相同的字符串。如果不存在,则在常量池中创建一个新的字符串对象。使用 new 关键字创建的字符串对象不在常量池中,在堆内存中。
字符串常量池的工作原理
- 字符串字面量:通过字符串字面量(例如
"Hello")创建的字符串会被存储在常量池中。 - 使用
new关键字:如果使用new String("Hello")创建字符串,Java 会在堆内存中创建一个新的字符串对象,而不是常量池中已有的字符串。
public class StringPoolExample {`
`public static void main(String[] args) {`
`// 使用字符串字面量创建字符串`
`String str1 = "Hello";`
`String str2 = "Hello"; // str2 引用常量池中的同一对象`
// 使用 new 关键字创建字符串
String str3 = new String("Hello"); // str3 是一个新的对象,存储在堆内存中
// 输出地址
System.out.println("str1 地址: " + System.identityHashCode(str1));
System.out.println("str2 地址: " + System.identityHashCode(str2));
System.out.println("str3 地址: " + System.identityHashCode(str3));
// 比较内容
System.out.println("str1.equals(str2): " + str1.equals(str2)); // true
System.out.println("str1.equals(str3): " + str1.equals(str3)); // true
// 比较引用
System.out.println("str1 == str2: " + (str1 == str2)); // true, 引用相同
System.out.println("str1 == str3: " + (str1 == str3)); // false, 引用不同
}
}
字符串字面量:String str1 = "Hello"; 和 String str2 = "Hello"; 会将 "Hello" 字符串存储在常量池中,str1 和 str2 指向相同的对象。
使用 new 关键字:String str3 = new String("Hello"); 会在堆内存中创建一个新的字符串对象,str3 指向这个新对象。
System.identityHashCode():用于获取对象的哈希码,以显示不同字符串的地址。
内容比较:str1.equals(str2) 和 str1.equals(str3) 比较字符串的内容,返回 true。
引用比较:str1 == str2 返回 true,因为它们指向同一对象,而 str1 == str3 返回 false,因为 str3 是一个新的对象。
抽象类和接口的区别?
抽象类使用 abstract 关键字定义,不能被实例化,只能作为其他类的父类。普通类没有 abstract 关键字,可以直接实例化。抽象类可以包含抽象方法和非抽象方法。抽象方法没有方法体,必须由子类实现。普通类只能包含非抽象方法。
定义方式:抽象类可以包含方法的实现和字段,抽象类可以有构造方法。而接口只能包含抽象方法(Java 8 之后可以有默认方法和静态方法),接口主要用于定义一组方法规范,没有具体的实现细节。
继承方式:一个类可以继承一个抽象类,但可以实现多个接口。接口可以多继承,一个接口可以继承多个接口,使用逗号分隔。
interface InterfaceC extends InterfaceA, InterfaceB {
void methodC();
}
访问修饰符:抽象类的方法可以有不同的访问修饰符(public、protected、private),而接口的方法默认是 public。
用途:抽象类更多地是用来为多个相关的类提供一个共同的基础框架,包括状态的初始化,而接口则是定义一套行为标准,让不同的类可以实现同一接口,提供行为的多样化实现。
两个list的底层 扩容过程
ArrayList()
是顺序容器,即元素存放的数据与放进去的顺序相同。允许放入null元素,底层通过数组实现。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。
size(), isEmpty(), get(), set()方法均能在常数时间内完成,add()方法的时间开销跟插入位置有关,addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
为追求效率,ArrayList没有实现同步(synchronized),如果需要多个线程并发访问,用户可以手动同步。
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。数组扩容通过一个公开的方法ensureCapacity(int minCapacity)来实现。
数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。
LinkedList()
LinkedList同时实现了List接口和Deque接口,也就是说它既可以看作一个顺序容器,又可以看作一个队列(Queue),同时又可以看作一个栈(Stack)。
LinkedList底层通过双向链表实现。
removeFirst(), removeLast(), remove(e), remove(index)
深拷贝(Deep Copy)和浅拷贝(Shallow Copy)
1. 浅拷贝(Shallow Copy)
类似一个快捷方式。
- 定义:浅拷贝是指复制对象的基本属性(如基本数据类型),拷贝的是基本数据类型的值。但对于引用类型的属性(如对象、数组等),它只复制引用,而不复制实际的对象。
- 影响:如果原对象和复制对象中有引用类型的属性,修改其中一个对象的引用类型属性会影响另一个对象,因为它们指向同一个对象。
2. 深拷贝(Deep Copy)
直接拷贝一个全新的副本。互相修改互不影响。
- 定义:深拷贝是指复制对象及其所有引用的对象,创建原对象及其引用对象的完整副本。每个属性都是独立的对象。
- 影响:原对象和复制对象之间完全独立,修改一个对象的属性不会影响另一个对象。