时间语义 & WaterMark
一、Flink中的时间语义
1. 三种时间语义
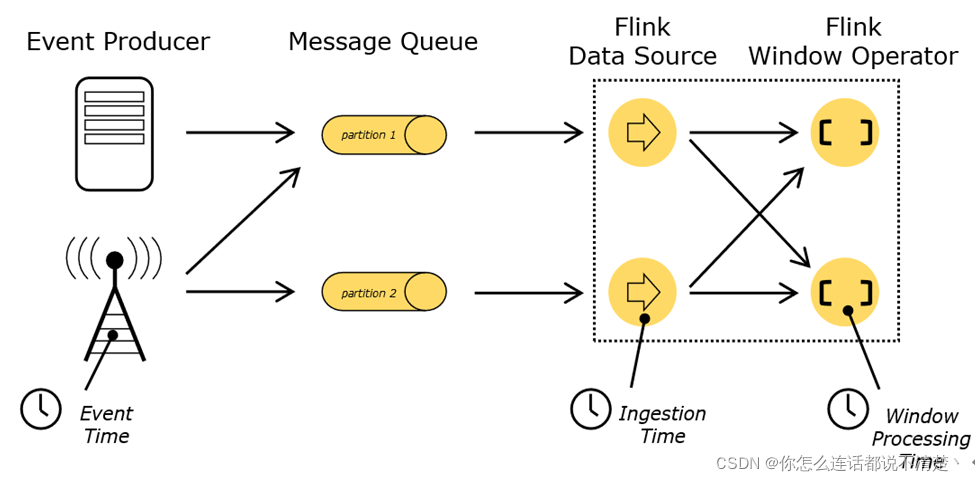
- Event Time: 是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
- Ingestion Time: 是数据进入Flink的时间。(Source读进来的时间)
- Processing Time: 是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
2.时间语义的使用
设置flink作业所使用的的时间语义
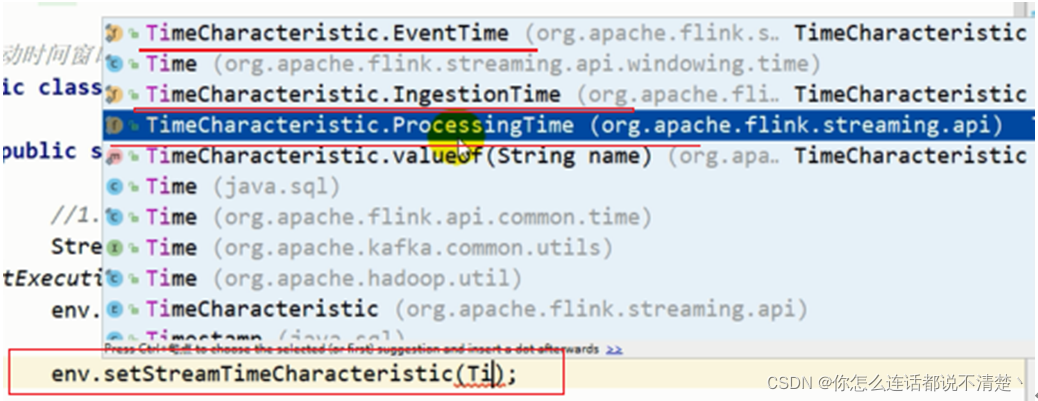
- flink默认使用处理时间,如果想要使用事件时间语义,如上图所示,可以在env中可以设置。
- 对于处理时间和进入时间只需要在env设置即可,但是如果使用事件时间,那么还需要在DataStream中从数据中提取时间戳 作为事件时间。
- 当env设置了事件时间语义,但是数据中不带有时间戳的时候,就使用Ingestion Time代替eventTime;
- 对于flink来说,数据进入系统的时间顺序和处理的时间顺序基本是一致的,没差别;并且Flink只有ProcessingTime和EventTime的窗口分配器,因此ingestion time是不会使用的
3.事件时间的功能
基于事件时间,能够将数据进行重新排序,解决数据的乱序问题。
- 对于kafka来说,其自身因为网络波动问题就容易造成乱序,比如生产者在生产数据的时候,是异步发送的,没有发送成功的数据没有接收到ack就会重新发送,这就会产生乱序。
- 在Spark中只有处理时间,无法解决乱序问题。
二、Watermark
1. 数据乱序
我们知道,流处理从事件产生,到流经source,再到operator,中间是有一个过程和时间的,虽然大部分情况下,流到operator的数据都是按照事件产生的时间顺序来的,但是也不排除由于网络、分布式等原因,导致乱序的产生,所谓乱序,就是指Flink接收到的事件的先后顺序不是严格按照事件的Event Time顺序排列的。
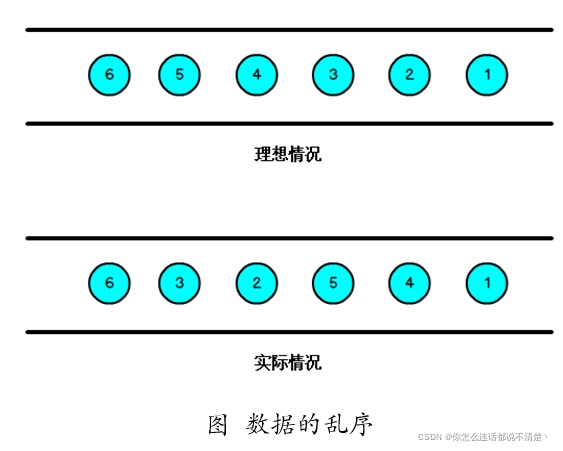
数据乱序的本质:
数据被处理的时间 和 数据生成的时间顺序不一致。后生成的数据被先处理。
- 处理时间:就是系统时间
- 数据生成时间:数据在生成的时候,自带的时间戳
数据乱序的后果:
对于时间窗口来说,如果按照处理时间来闭合窗口,就会导致迟到的数据丢失。
比如:系统时间为9:05的时候关闭窗口,那么9:04分产生的数据迟到了,就会丢失
数据乱序解决方案:
这时候我们会想到,如果按照事件生成的时间顺序来处理事件,不就没有乱序了;
按照事件时间来决定窗口的关闭会引入新的问题:
比如:9:05分产生的数据迟迟未到,那么[9:00,9:05)窗口永远不会闭合
总结
- 可以使用事件时间语义数据乱序的问题
- 单纯使用事件时间语义会引发窗口迟迟不闭合的可能! 占用内存
2. waterMark的提出
waterMark要解决的问题
- 问题1: 按照处理时间关闭窗口会丢失数据
- 问题2: 按照事件时间关闭窗口会导致窗口闭合时间不确定
必须要引入一个机制,保证一个特定的时间后,必须触发窗口闭合,进行运算输出。这个特别的机制,就是Watermark。
3. waterMark的作用
-
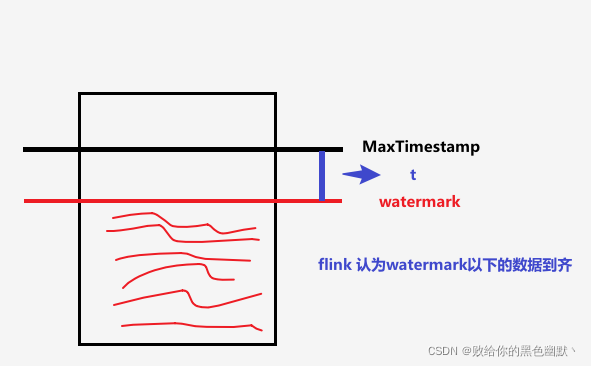
waterMark作为水位线,是一种 衡量Event Time进展的机制。数据流中的Watermark用于表示时间戳小于Watermark的数据,都已经到达了,因此,window的执行也是由Watermark触发的(因为flink认为水位线以前的数据都到齐了,可以计算输出了)。
-
Watermark可以理解成一个延迟触发机制,我们可以设置Watermark的延迟时长t,每次系统会校验已经到达的数据中最大的
maxEventTime,然后认定eventTime<=maxEventTime - t的所有数据都已经到达,如果有窗口的停止时间 <=maxEventTime – t,那么这个窗口被触发执行。
4. WaterMark的特点
public final class Watermark extends StreamElement {
/**The watermark that signifies end-of-event-time. */
public static final Watermark MAX_WATERMARK = new Watermark(Long.MAX_VALUE);
/** The timestamp of the watermark in milliseconds. */
private final long timestamp;
}
- Watermark 本质是在数据流中插入特殊数据
StreamElement,也在算子之间进行传输,并遵循waterMark专属的传输规则 - WaterMark就是时间戳 (timestamp属性)
- 值只能单调递增,来保证时间在向前推进
- 如果要按照事件时间来处理,必须要指定waterMark
- Watermark的值应该等于数据流最大乱序时间
5. waterMark生成规则
Watermark等于当前所有到达数据中的maxEventTime - 延迟时长
在引入waterMark的时候,我们会设置一个延迟时长t,延迟时长就是我们所认为数据最大迟到时间,比方说t = 5s,意味着我们认为一条数据不会迟到超过5s。
Watermark就是是基于数据携带的时间戳减去延迟时长 t 生成的;
6. waterMark生成演示
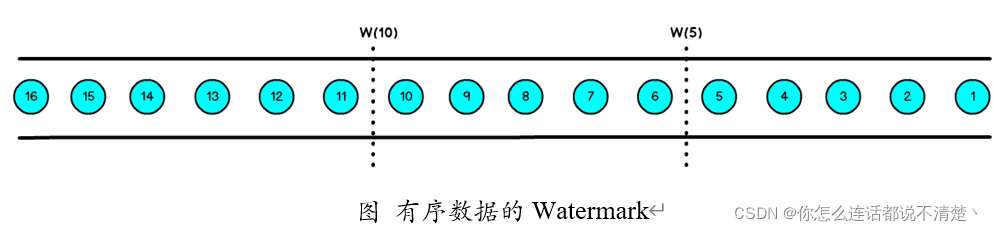
1.有序流的Watermarker如下图所示:(Watermark设置为0)
2.乱序流的Watermarker如下图所示:(Watermark设置为2)
再次说明: waterMark根据当前遇到过的数据中最大EventTime来计算,只能单调递增
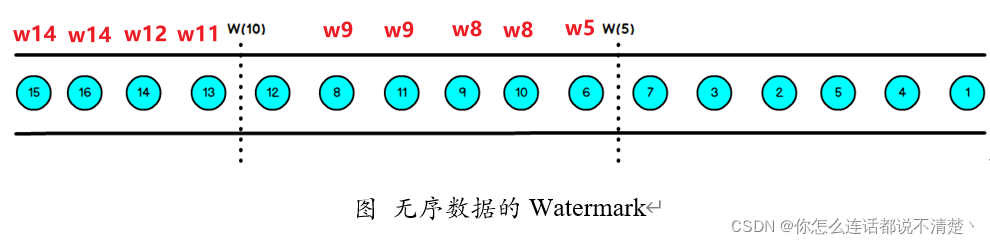
上图中,我们设置的允许最大延迟到达时间为2s,所以时间戳为7s的事件对应的Watermark是5s,时间戳为12s的事件的Watermark是10s,如果我们的窗口1是1s~5s,窗口2是6s~10s,那么时间戳为7s的事件到达时的Watermarker恰好触发窗口1,时间戳为12s的事件到达时的Watermark恰好触发窗口2。
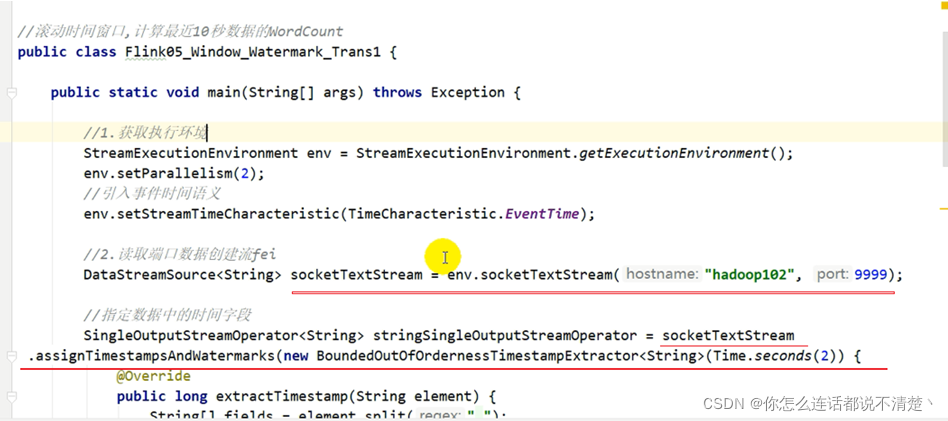
7. 如何在代码中引入waterMark
- 第一步:给env引入时间语义,指定按照事件时间
- 第二步:指定数据当中时间字段,作为事件时间
public class _01_waterMark {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//todo 第一步:引入事件时间语义
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> source = env.socketTextStream("hadoop102", 9999);
//todo 第二步:提取流中的数据的时间字段作为事件时间
SingleOutputStreamOperator<String> stringSingleOutputStreamOperator = source.assignTimestampsAndWatermarks(
//周期性waterMark 有界无序 参数是最大乱序时间
new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
@Override
//todo 抽取事件中的时间戳,element是事件
public long extractTimestamp(String element) {
String[] fields = element.split(",");
return Long.parseLong(fields[1]) * 1000L;
}
}
);
SingleOutputStreamOperator<Tuple2<String, Integer>> map = stringSingleOutputStreamOperator.map(
new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
String[] fields = value.split(",");
return new Tuple2<String, Integer>(fields[0], 1);
}
}
);
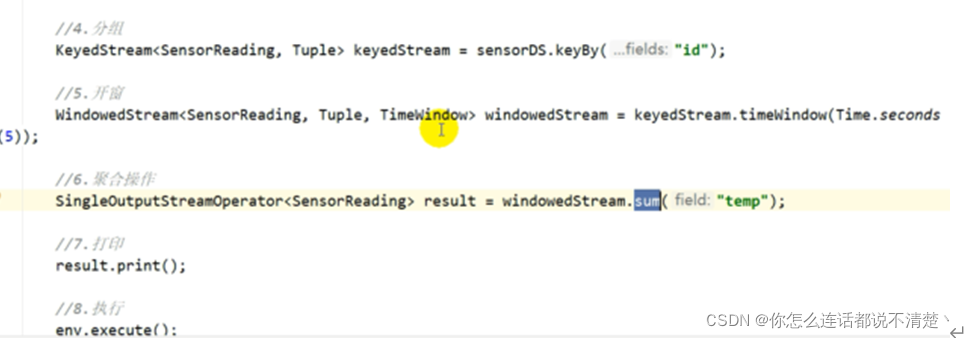
KeyedStream<Tuple2<String, Integer>, Tuple> kb =map.keyBy(0);
//todo 创建窗口
WindowedStream<Tuple2<String, Integer>, Tuple, TimeWindow> window =
kb.timeWindow(Time.seconds(5));
SingleOutputStreamOperator<Tuple2<String, Integer>> result = window.sum(1);
result.print();
env.execute();
}
}
8. waterMark分配器
DataStream的assignTimestampsAndWatermarks方法用来提取事件时间和指定watermark,其参数是waterMark分配器;
waterMark分配器有两种类型,以下两个都是接口,且都继承自TimestampAssigner
- AssignerWithPeriodicWatermarks : 周期性生成watermark
- AssignerWithPunctuatedWatermarks:断点式生成watermark

8.1 周期性watermark戳提取器
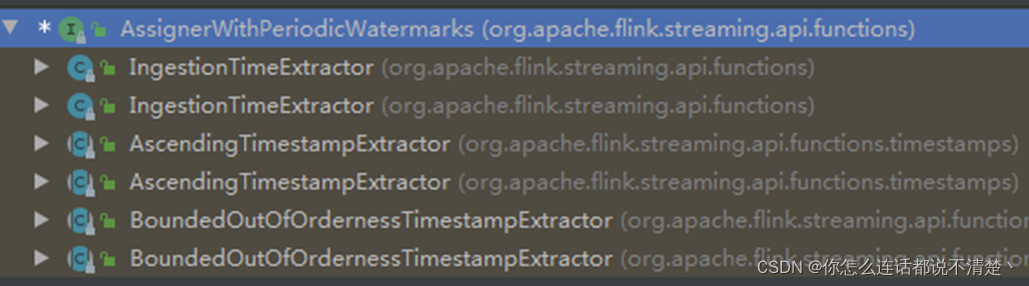
1.周期性提取器特点
- 每隔一段时间往Stream中插入waterMark
- 也就是说waterMark的生成时间和数据没有关系,但是watermark的值和数据是有关系的;
2.waterMark的生成周期(何时生成)
- 默认每200ms在DataStream中插入WaterMark
- 可以使用ExecutionConfig.setAutoWatermarkInterval()方法进行设置。
// 每隔5秒产生一个watermark
env.getConfig.setAutoWatermarkInterval(5000);
产生watermark的逻辑 每隔5秒钟,Flink会调用
3.waterMark值的生成规则(生成何值)
查看AssignerWithPeriodicWatermarks的getCurrentWatermark()方法:

- 返回当前水印
- 系统定期调用此方法来检索当前水印
- 该方法可能返回null,表示没有新的水印可用。
- 只有当返回的水印为非空且其时间戳大于之前发出的水印时,才会
emit返回的水印(保证升序)。 - 如果当前水印仍然与前一个相同,则表示自前一次调用此方法以来,事件时间没有发生任何进展。
- 如果返回空值,或者返回的水印的时间戳小于上次发出的水印的时间戳,则不会生成新的水印。
- 调用此方法和生成水印的时间间隔取决于
ExecutionConfig.getAutoWatermarkInterval()
5.自定义周期性时间戳分配器
public static class MyPeriodicAssigner implements AssignerWithPeriodicWatermarks<SensorReading>{
private Long bound = 60 * 1000L; // 延迟一分钟
private Long maxTs = Long.MIN_VALUE; // 当前最大时间戳
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(maxTs - bound);
}
@Override
public long extractTimestamp(SensorReading element, long previousElementTimestamp) {
maxTs = Math.max(maxTs, element.getTimestamp());
return element.getTimestamp();
}
}
5.常用周期提取器实现类
8.1.1 有序时间戳提取器
应用场景: 用流的方式处理没有乱序的离线数据
flink提供的实现类:AscendingTimestampExtractor
使用方式如下:
DataStream<SensorReading> dataStream = …
dataStream.assignTimestampsAndWatermarks(
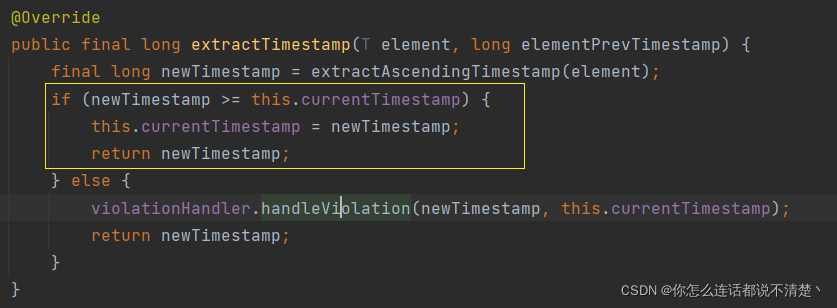
new AscendingTimestampExtractor<SensorReading>() {
@Override
public long extractAscendingTimestamp(SensorReading element) {
return element.getTimestamp() * 1000;
}
});
时间提取方式:
waterMark生成策略:

8.1.2 乱序提取器
BoundedOutOfOrdernessTimestampExtractor( 有界无序时间戳提取器)
dataStream.assignTimestampsAndWatermarks(
new BoundedOutOfOrdernessTimestampExtractor<SensorReading>
(Time.milliseconds(1000)) {
@Override
public long extractTimestamp(element: SensorReading): Long = {
return element.getTimestamp() * 1000L;
}
}
);
说明:
- 泛型是输入的数据类型
- 参数是最大无序事件时间差,也就是
MaxTimeStamp - t = waterMark中的t - extractTimestamp方法用来提取事件中的事件时间
/**
* This is a {@link AssignerWithPeriodicWatermarks} used to emit Watermarks that lag behind the element with
* the maximum timestamp (in event time) seen so far by a fixed amount of time, <code>t_late</code>. This can
* help reduce the number of elements that are ignored due to lateness when computing the final result for a
* given window, in the case where we know that elements arrive no later than <code>t_late</code> units of time
* after the watermark that signals that the system event-time has advanced past their (event-time) timestamp.
* */
public abstract class BoundedOutOfOrdernessTimestampExtractor<T> implements AssignerWithPeriodicWatermarks<T> {
private static final long serialVersionUID = 1L;
/** The current maximum timestamp seen so far. */
private long currentMaxTimestamp;
/** The timestamp of the last emitted watermark. */
private long lastEmittedWatermark = Long.MIN_VALUE;
/**
* The (fixed) interval between the maximum seen timestamp seen in the records
* and that of the watermark to be emitted.
*/
private final long maxOutOfOrderness;
public BoundedOutOfOrdernessTimestampExtractor(Time maxOutOfOrderness) {
if (maxOutOfOrderness.toMilliseconds() < 0) {
throw new RuntimeException("Tried to set the maximum allowed " +
"lateness to " + maxOutOfOrderness + ". This parameter cannot be negative.");
}
this.maxOutOfOrderness = maxOutOfOrderness.toMilliseconds();
this.currentMaxTimestamp = Long.MIN_VALUE + this.maxOutOfOrderness;
}
public long getMaxOutOfOrdernessInMillis() {
return maxOutOfOrderness;
}
/**
* Extracts the timestamp from the given element.
*
* @param element The element that the timestamp is extracted from.
* @return The new timestamp.
*/
public abstract long extractTimestamp(T element);
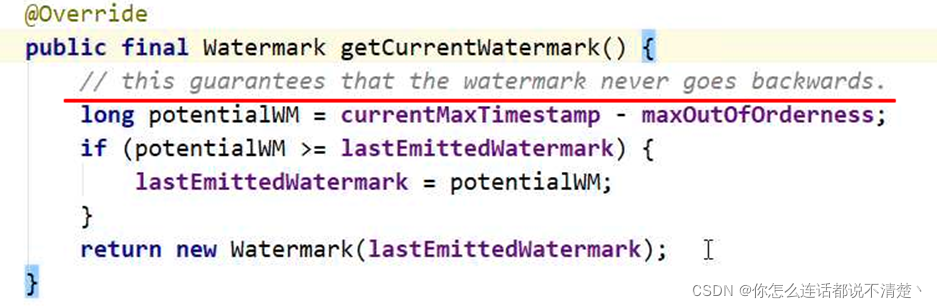
@Override
public final Watermark getCurrentWatermark() {
// this guarantees that the watermark never goes backwards.
long potentialWM = currentMaxTimestamp - maxOutOfOrderness;
if (potentialWM >= lastEmittedWatermark) {
lastEmittedWatermark = potentialWM;
}
return new Watermark(lastEmittedWatermark);
}
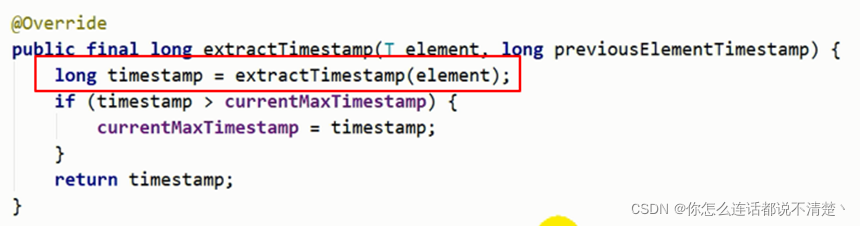
@Override
public final long extractTimestamp(T element, long previousElementTimestamp) {
long timestamp = extractTimestamp(element);
if (timestamp > currentMaxTimestamp) {
currentMaxTimestamp = timestamp;
}
return timestamp;
}
}
生成WaterMark 的方法getCurrentWatermark():
1.从每一个element中获取timestamp,也就是eventTime
2.用eventTime 减去我们设置的最大乱序时间:
- 如果值大于上一次发射的waterMark,也就是lastEmittedWatermark,就会更新lastEmittedWatermark,并且返回新的waterMark;
- 如果值 < lastEmittedWatermark,只返回lastEmittedWatermark;
时间戳提取方法:
extractTimestamp(T element),需要自己实现
(2)断点式watermark戳提取器
- 没有实现类,需要手动实现
- 数据来了才插入一个WaterMark
两种提取器对比:
实际开发中,使用周期性更好,如果数据高峰期,断点式会给系统增加处理压力,周期性稳定,如果数据稀疏时,插入断点式更好,但是综合来说,周期性在稀疏时给系统增加的压力不大,高峰时增加的压力小于断点式,所以周期性更好。
9. 乱序数据不丢失的三重保证
flink就是基于事件时间语义结合以下三个方法来处理乱序问题的:

1.滚动窗口允许迟到数据和侧输出流
测试1 :
滚动窗口,窗口5s,watermark2s,允许迟到2s
测试1:
测试2:
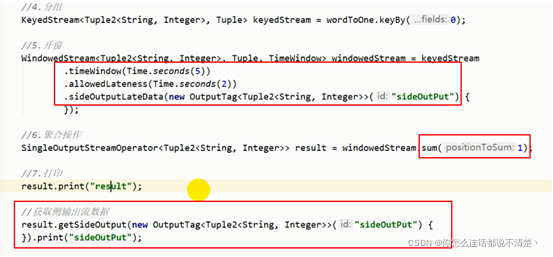

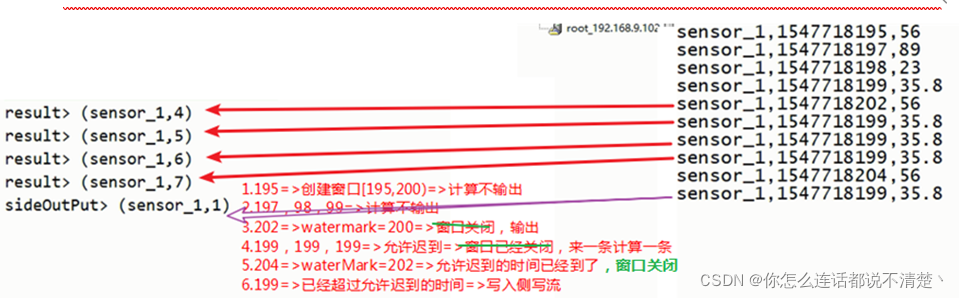
滚动窗口的三重保证总结
(1)首先窗口的计算、输出、关闭是三个独立事件,可以分开执行
(2)当前窗口中做的计算是增量计算,就是来一条数据计算一条;
注意两个关键时间点:
- waterMark到达窗口的endTime
- waterMark到达endTime + lateness
[1]三重保障的第一重:waterMark延迟输出;
- 当waterMark到达200的时候,将窗口中所有数据的累积计算结果做一次性输出,由于有allowedLateness,窗口不会关闭。
- 特点:来一条参与窗口计算一条,不输出,不关闭窗口
[2] 三重保障的第二重: allowedLateness延迟窗口关闭:
- 当waterMark到达200(原本窗口关闭时间)是不会关闭窗口的,只是会做一次输出。
- 窗口在waterMark在到达202的时候才会关闭,在窗口关闭之前,任何进入这个窗口的数据仍然会参与窗口中的累积计算,并且来一条数据计算一次并且输出一次。
- 特点:来一条参与窗口计算一条,并输出,关闭窗口
[3] 三重保障的第三重:侧输出流;
- 当waterMark到达202之后,窗口真正的关闭了,数据就会进入侧输出流了,不参与窗口中的累积计算,只会计算当前这条数据,并且计算结束就输出到侧输出流;
- 特点:窗口已经关闭,来一条,单独计算一条,输出一条,
侧输出流的目的:为什么不直接设置大一点迟到时间或者是waterMark gap,而设置测输出流呢?
- 如果增加waterMark gap,会拖很久才能看到输出
- 如果增加lateness,会增加窗口关闭时间,timeWindow对象是在堆内存的,窗口迟迟不关闭,会一直占用内存。
- 数据迟到遵循正则分布,90%的数据迟到时间不超过3s,10%的数据能迟到30s(假设)这意味着WaterMark+迟到时间就按照3s来设置,否则窗口只为了等那么一两条迟到数据等待30s不值得,直接输出到侧输出流中
- 相当于牺牲了一点当时计算的准确性,保证了时效性。
2.滑动窗口允许迟到数据和侧输出流
- 对于滑动窗口的侧输出流,必须等到这条数据的所有窗口都关闭,才会将数据放进侧输出流;
- 生产环境中,如果用滑动窗口,一般就不会使用侧输出流和允许迟到数据了,因为如果在所有窗口关闭之前,A窗口关闭之后。此时来了窗口A的数据就会丢失,只有所以后窗口关闭之后,才会进入侧输出流。
- 所以对于滑动窗口来说,不能保证数据的完整性=》滑动窗口的三重保障不行
测试
windowsize=6,slide=2,watermark=2
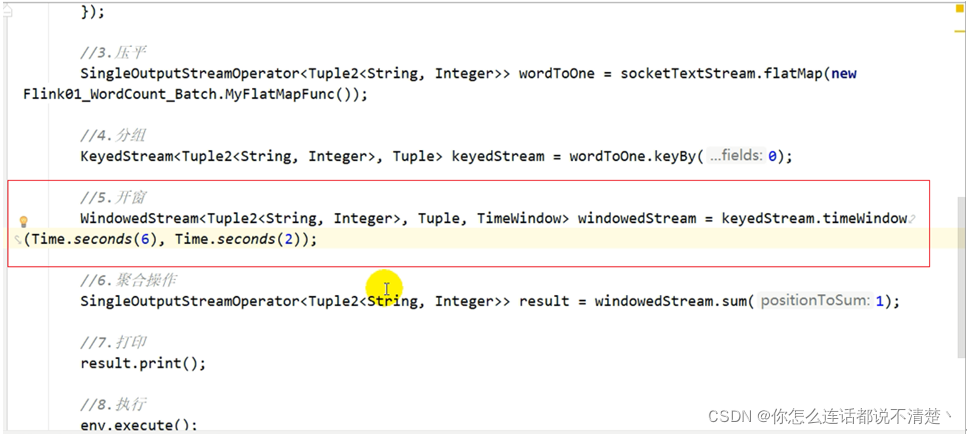

- 199 --> 创建3个窗口 => 最后一个窗口的startTime = 199 - 199%2 = 198
[194,200),[196,202), [198,204),三个窗口 - 206=>waterMark=204=>三个窗口都关闭
3. Session窗口的waterMark
会话间隔5s,watermark为2s

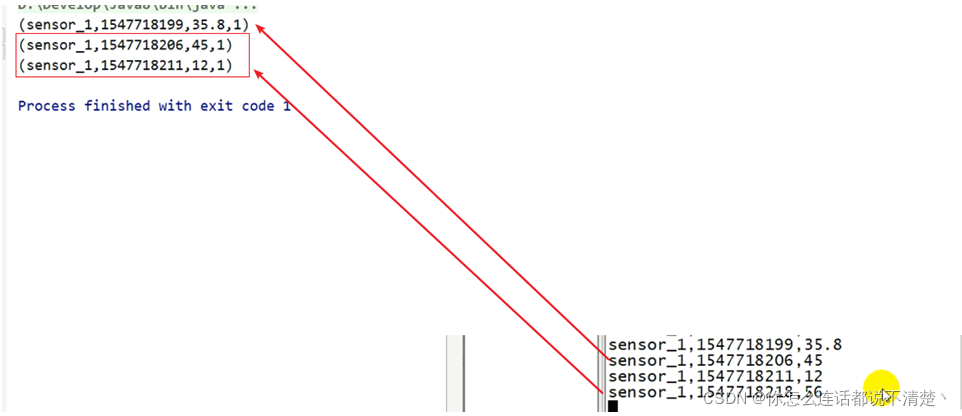
- 199 => 会话5s,窗口关闭时间 = 204
- 206 =>会话5s,窗口关闭时间 = 211 ;waterMark = 204 触发上面的窗口的关闭;
- 211=>会话5s,窗口关闭时间 = 216;waterMark = 209 上面的窗口不会关闭;
- 218:waterMark = 216 出发窗口关闭,将206和211一起输出
10. waterMark的传递
(1)WaterMark发射机制
官方说明:

1.waterMark的生成: 对于周期性waterMarkAssigner来说,waterMark Assigner的getCurrentWaterMark()方法会按照间隔时间被调用来生成waterMark
2.waterMark的发射: 当前Task的waterMark不为null且大于以前的waterMark才会被发送
比如 :
t = 2
199 => wm = 197
202 => wm = 200
然后后面一直没有新事件产生,那么就会一直产生为200的waterMark;或者说有198,那么会生成198,但是只要是<=以前的waterMark,那么就不会往下游发送。
(2)waterMark传递机制
(1)1个task有n个并行度,那么就会存储n个waterMark
(2)如何确定task的waterMark?
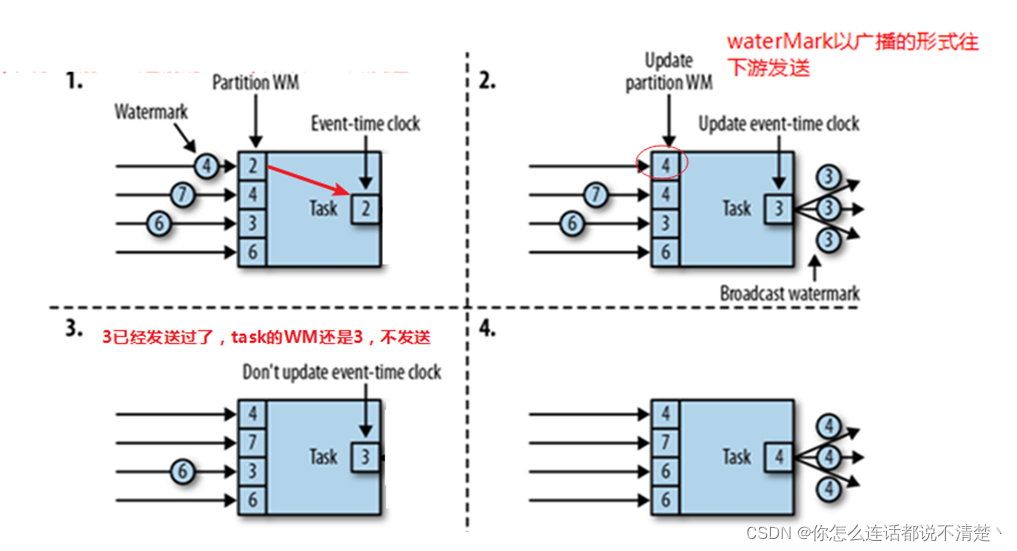
- 所有并行度中waterMark的最小值
含义:表示上游所有并行度中该waterMark之前的数据都到达,再开始计算
(3)waterMark如何传递?
- 当下游有多个并行度的时候,wm是以广播的形式向下游传播
- 注意一点,wm的传递和数据本身的传递是不同的,数据遵循设置的传输过程,wm只做广播
总结:
- waterMark的发射时机:waterMark 大于之前的waterMark时才会发送
- waterMark的传递:如果是oneToone,则一对一传输;否则就是广播
(3)waterMark传递测试
https://mp.weixin.qq.com/s/vlT_XQ8Zn2scoBpeqfdaDg
代码1:在SocketStream上提取时间戳
测试条件:
并行度设置为2
设置两秒延迟,滚动窗口5s
执行结果:

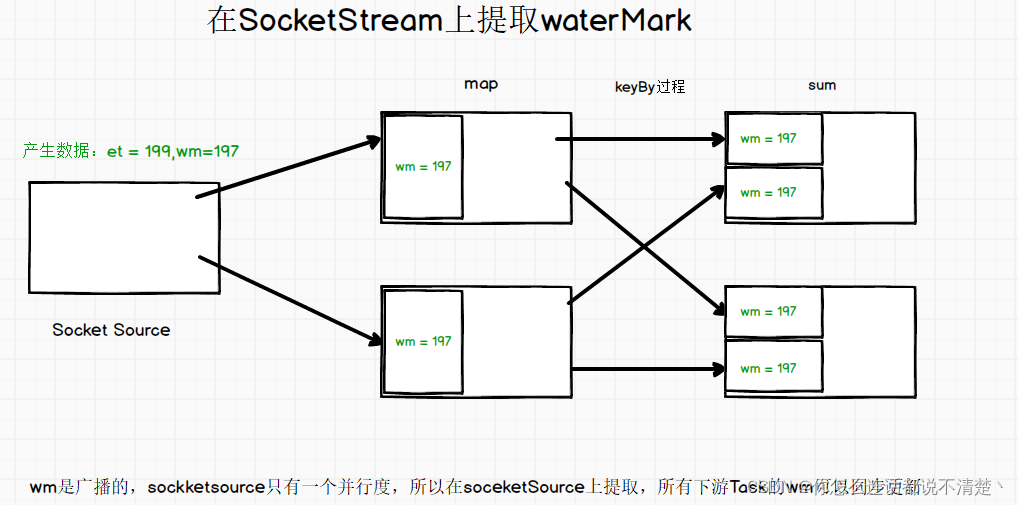
代码2:在map算子后提取waterMark
执行结果:
原因:
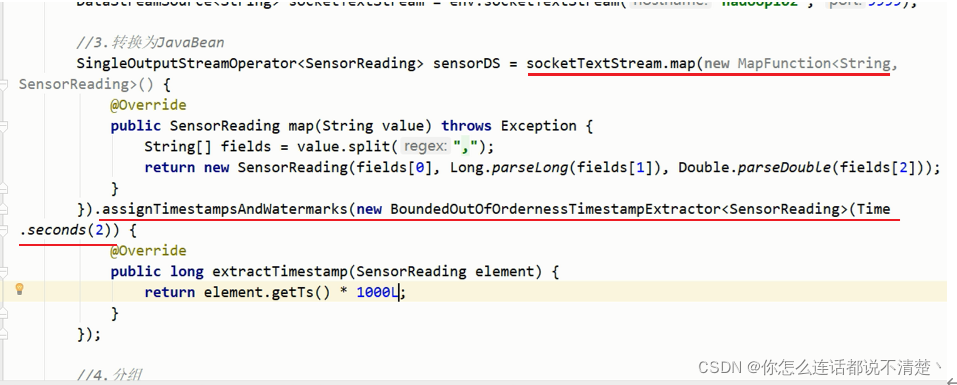

**source 轮询将消息发送给下游的mapTask的slot **
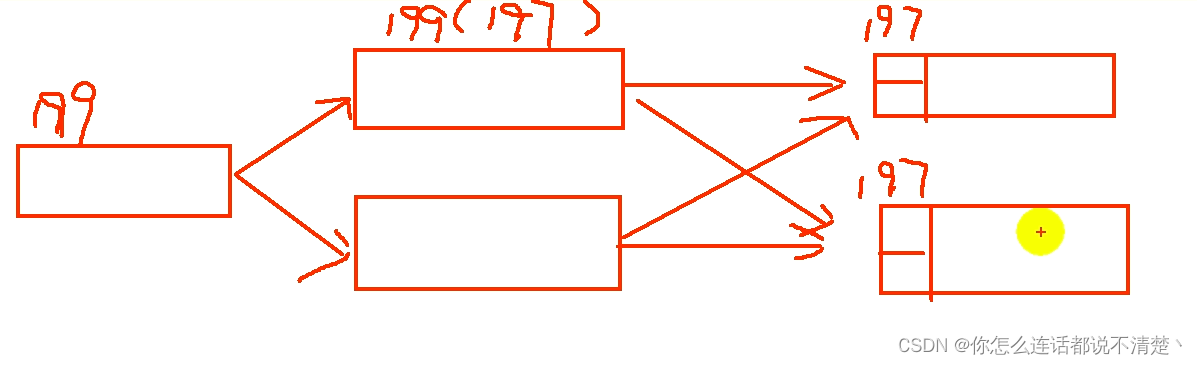
第一条数据: 199,只发往map1,此时在map上提取wm,map1产生wm=197,map2产生wm=MIN
第二条数据203:
由于task的wm是所有并行度最小的,所以最后一个task的wm仍然为197,此时不会触发计算;
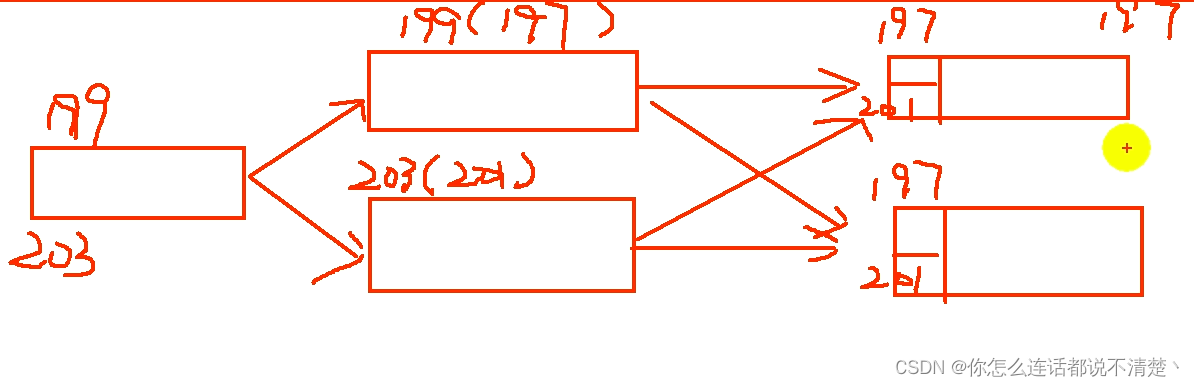
第三条203:
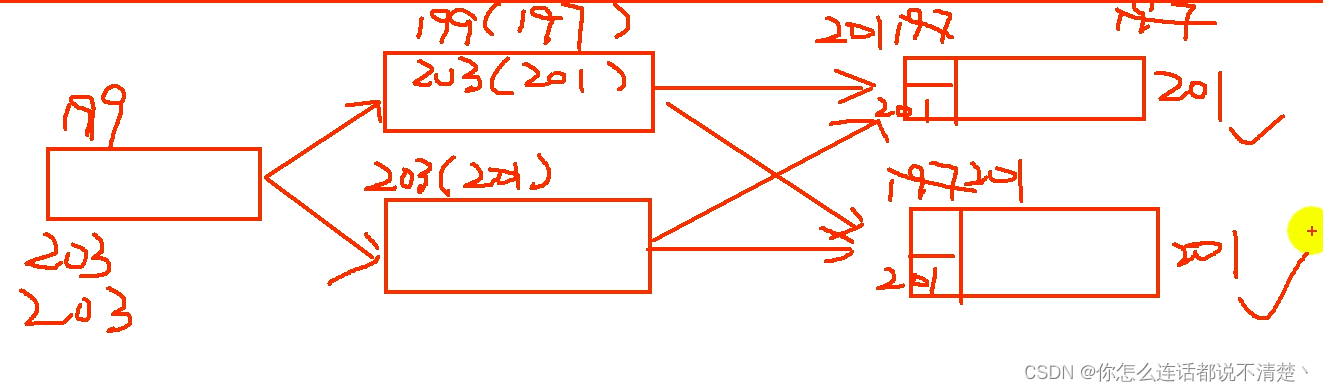
11. waterMark源码解析
从waterMark提取开始分析
(1)以BoundedOutOfOrdernessTimestampExtractor类为例解析
每个元素都会经过这个方法来提取事件时间
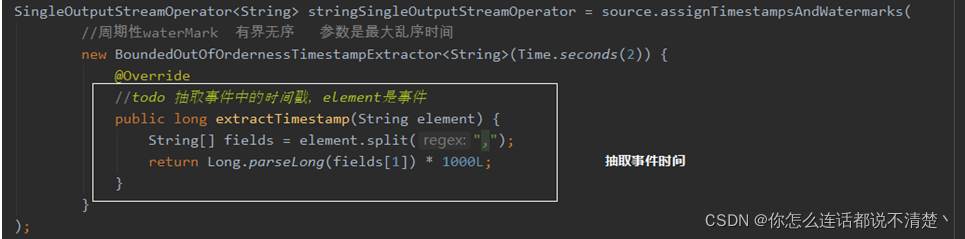
(2)提取事件时间戳
如果有事件的时间戳>MaxcurrentTimeStap,更新,否则不更新
(3)获取WaterMark值
只有最大的事件时间戳 - 乱序时间 >= 最后一次提交的WaterMark,才会更新最后一次提交的WaterMark,否则周期性生成的waterMark一直是上次提交的WaterMark(也不会变小) 。waterMark一旦增大,就不会变小了,最多保持一致。
结合WaterMark构造方法来看:
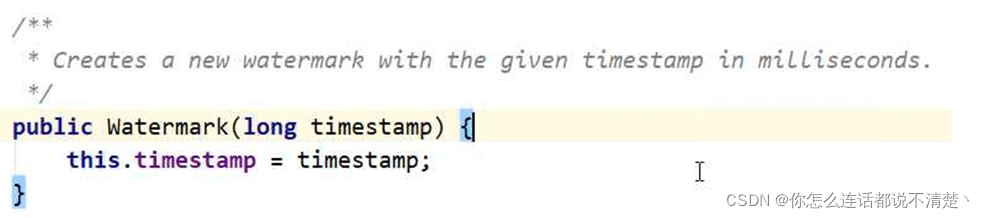
- 所以WaterMark值的推进是由最大的事件时间戳来推动的,比如一个[195,200)的窗口,设置的乱序时间为2s,如果没有事件的时间戳能够达到202,这个窗口就一直不会关闭。
- WaterMark和当前所有事件中最大的时间戳保持同步,即使后面来的事件时间变小了,waterMark的生成是不会变小的。
(4)谁来调用getCurrentWaterMark
每一个算子都对应streamOperator的一个实现类
TimeStampAndPeriodicWaterMarksOperator类
(这个类是在dataStream中提取事件时间后的Stream类)
(1)生命周期方法Open中:
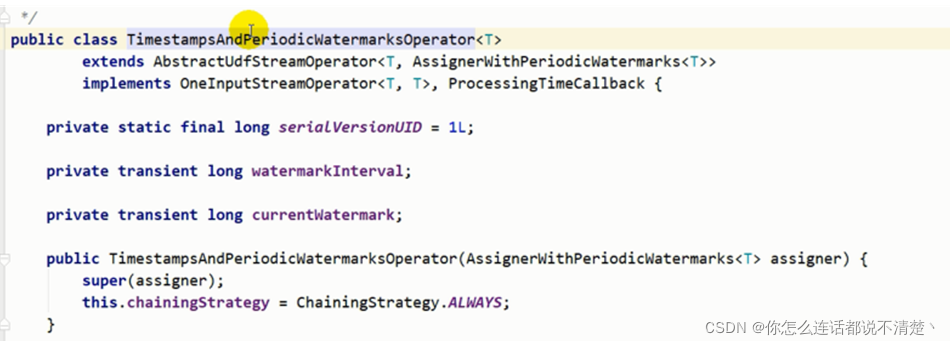
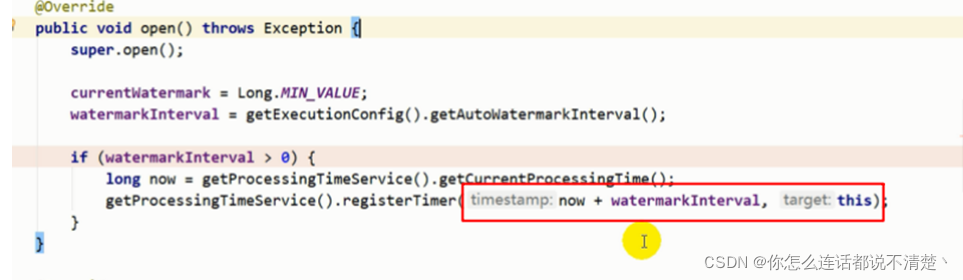
- 在open方法中注册了一个定时器, 基于当前处理时间注册的,闹钟响的时间为现在+waterMarkInterval(waterMark生成间隔时间)。
- 只有waterMarkInterval > 0的时候才会设置闹钟
(2)闹钟方法中:
闹钟响了=> 调用getCurrentWatermark()获取waterMark,如果waterMark大于现在的waterMark,提交新的waterMark。
并且再次设置闹钟,以此往复。(闹钟里面设置闹钟)
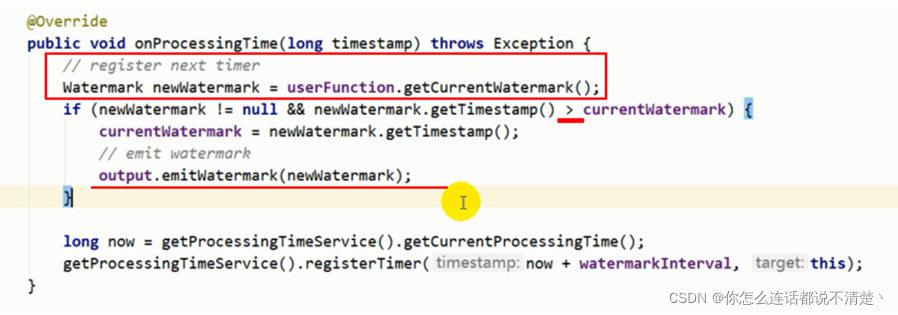
- waterMark的生成是>= ,waterMark的发送是>,只发送更大的 也就是说lastEmittedWaterMark的更新是大于等于的时候就更新,但是发送只是在>的时候发送。