K近邻模型
模型思想:
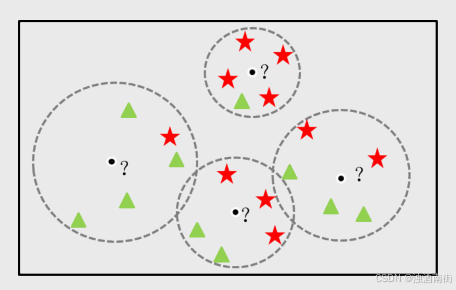
如图所示,模型的本质就是寻找k个最近样本,然后基于最近样本做预测。对于离散型的因变量来说,从k个最近的已知类别样本中挑选频率最高的类别用于未知样本的判断;对于连续的因变量来说,则是将k个最近的已知样本均值用作未知样本的预测。
模型执行步骤
1.确定未知样本近邻的个数k值
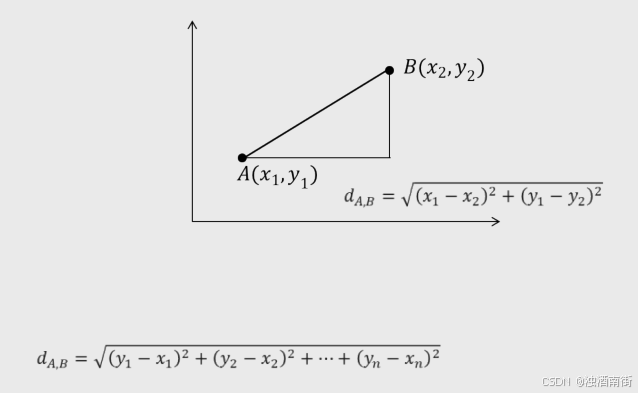
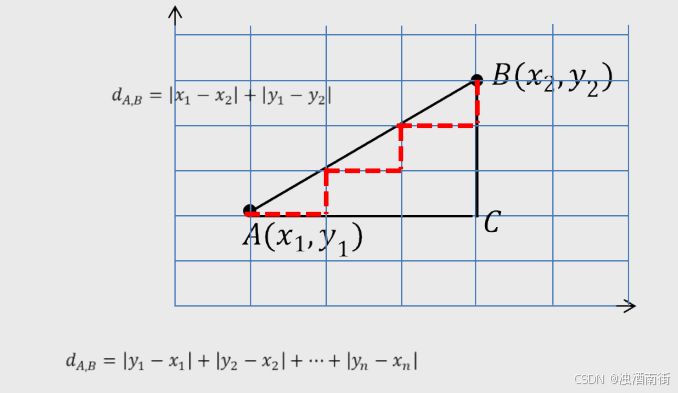
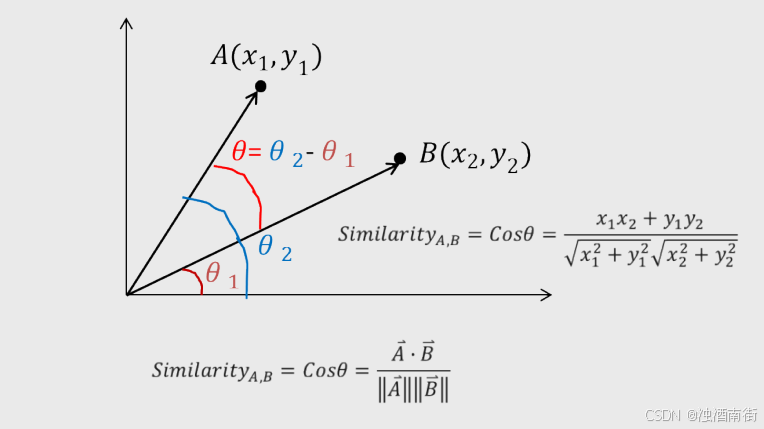
2.根据某种度量样本相似度的指标(如欧式距离)将每一个未知类别样本的最近k个已知样本搜寻出来,形成一个个簇。
3.对搜寻出来的已知样本进行投票,将各簇类别最多的分类用作未知样本点的预测。
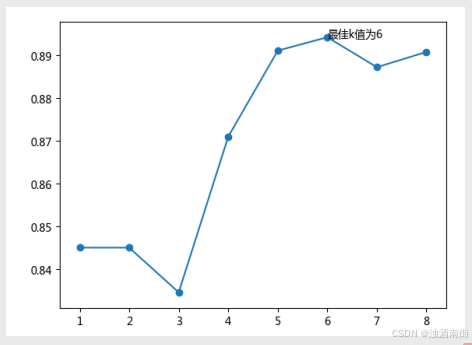
k值的选择
根据经验发现,不同的k值对模型的预测准确性会有比较大的影响,如果k值过于偏小,可能会导致模型的过拟合;反之,又可能会使模型进入欠拟合状态。
一种是设置k近邻样本的投票权重,使用KNN算法进行分类或预测时设置的k值比较大,担心模型发生欠拟合的现象,一个简单有效的处理办法就是设置近邻样本的投票权重,如果已知样本距离未知样本比较远,则对应的权重就设置的低一些,否则权重就高一些,通常可以将权重设置为距离的倒数。
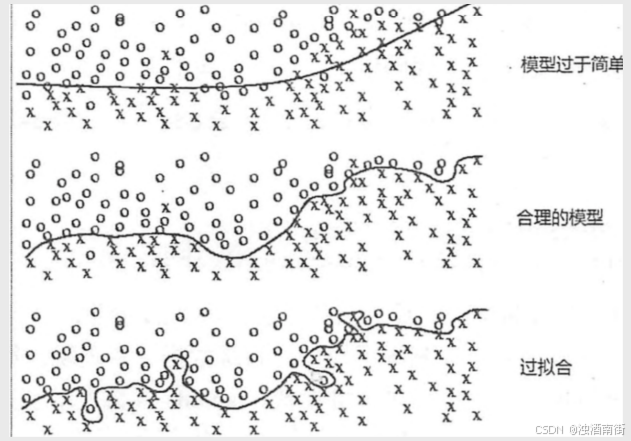
采用多重交叉验证法,该方法是目前比较流行的方案,其核心就是将k取不同的值,然后在每种值下执行m重的交叉验证,最后选出平均误差最小的k值。当然,还可以将两种方法的优点相结合,选出理想的k值。