在介绍我们这次的论文之前,我们先来思考一些问题:
- 在NST中,什么是风格图像中的风格信息? 个人理解,风格图像中的风格信息指的是风格图像中的色彩、纹理、笔触等因素,这些因素的不同组合使得图像呈现出不同的风格信息。
- 那么,再进一步的思考,我们怎样提取这些风格图像中的风格信息呢? 在深度学习没有出现之前,大多数是利用图像处理和滤波来实现的,例如高斯滤波或者双边滤波;有了深度学习以后,开始从图像中提取高维的特征信息来表示风格信息,例如2015年Gatys提出利用Gram矩阵来表示图像中的风格信息,并且这一想法使其成为NST的基石和开山之作。
- 那么,再思考一个问题,为什么Gram矩阵可以表示图像中的风格信息? 推荐给大家一篇博客:(高能预警!)为什么Gram矩阵可以代表图像风格?带你揭开图像风格迁移的神秘面纱!,我觉得博主对于这个问题分析比较透彻,伙伴们可以去学习一下。简单来说,图像的风格迁移是在不断缩小生成图像和内容图像,生成图像和风格图像的距离,那么对于内容图像和风格图像来说,需要忽略特征的位置,减小分布的差异。也就是说,图像的风格迁移可以看作内容图像到风格图像的分布对齐过程。更进一步地,如果我们将内容图像集合和风格图像集合看作两个域,那么这就是域迁移的问题了。
既然对风格信息有了基础的了解,那么大佬们通过其中的一个小痛点(笔触的大小影响风格迁移的效果么?) 来展开这篇论文。这个项目的链接大佬们也同时给出了【项目链接】,发表于2018ECCV。此外,打个小小的广告,我们关于NST的论文和代码介绍放在了专栏里,感兴趣伙伴们可以自行前往食用深度学习艺术与专栏。
本篇论文地址:https://arxiv.org/abs/1802.07101
论文代码地址:https://github.com/LouieYang/stroke-controllable-fast-style-transfer
论文项目地址:https://yongchengjing.com/StrokeControllable
0. Pre-analysis
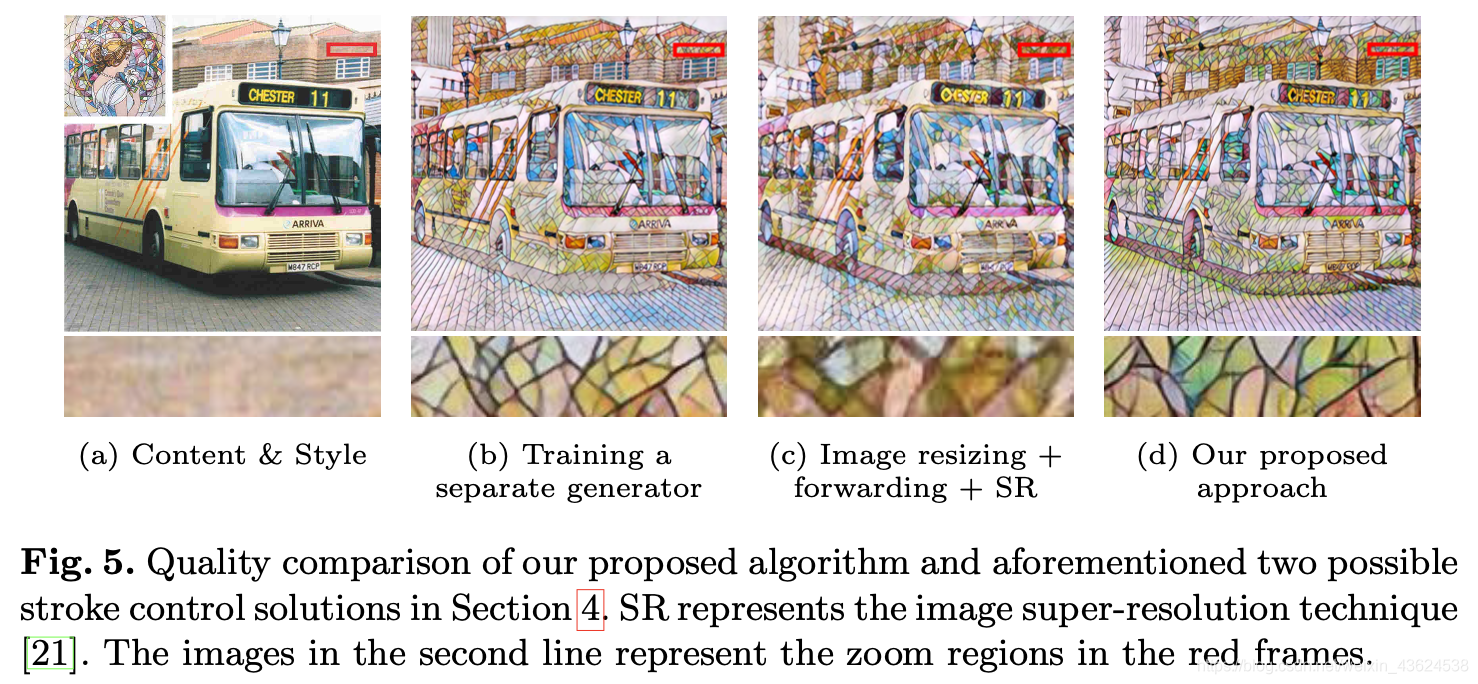
论文在正式介绍自己的网络之前,为了使自己的论证更有力(这可能就是发顶会的严谨性吧),利用不同的笔触(实际上是内容图像和风格图像的比例不同)证明了风格图像比例大小确实会产生不同的风格迁移效果,如下图所示。可以看出,Small stroke size的风格迁移图像纹理较为细致,对于一些细节刻画比较到位,而Large stroke size的风格迁移后的图像可以保留比较完整的色块信息,而我们的目标是想得到混合笔触的风格迁移效果,如Mixed stroke size所示的效果。
1. Proposed Approach
1.1 Network Architecture
这篇论文所提出来的网络结构主要有三个部分。主要如下:
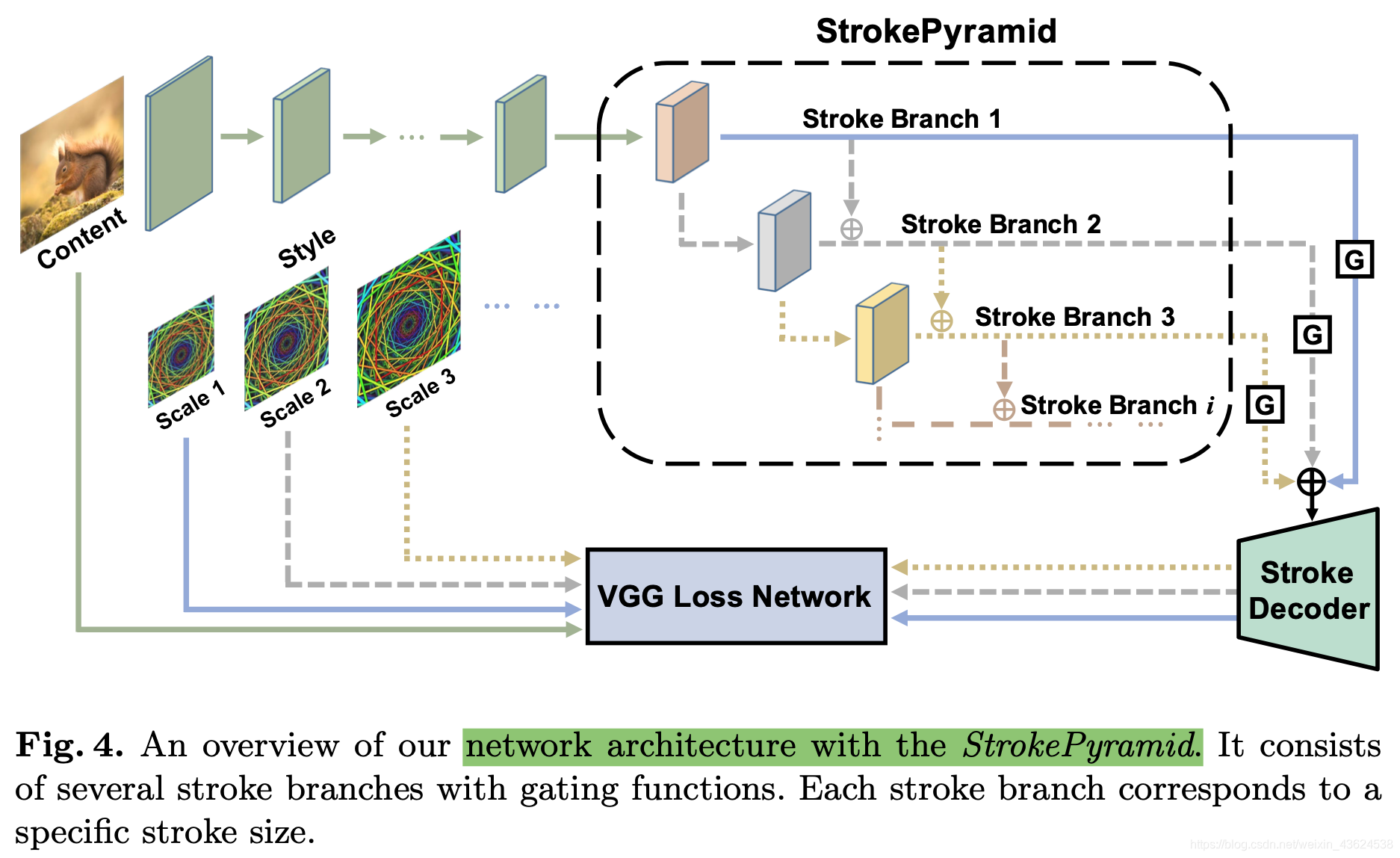
- StrokePyramid Module 笔触金字塔模块:改变卷积大小,使得每个笔触分支的感受野都比前一个分支大。此外,还在相邻两个笔触分支之间鼓励笔触一致性(stroke consistency,指的是笔画方向、配置等的一致性)。
- Pre-encoder Module 预编码器模块:提供了一些层用来共享不同笔触风格分支之间的权重来学习内容图像的语义和风格图像的基本表现。
- Stroke-decoder Module 笔触解码器模块:根据相应的笔触大小将笔触结果解码成风格结果。
此外,定义了一个门函数gating function G,用来决定哪一个笔触特征需要去解码,一并输入到笔触解码模块中。

1.2 Loss Function
Neural Style Transfer风格算法中,一般来讲,Loss损失主要由内容损失、风格损失和正则化损失三部分构成。内容损失一般是基于VGG提取的特征,提取某一层的内容图像和生成图像的特征值差,风格损失一般是基于Gram矩阵来代表风格之间的不同,正则化损失一般是利用L1/L2正则化来表示。在本文中,损失函数主要分为三个部分:语义损失(Semantic Loss)、笔触损失(Stroke Loss)和正则化损失(Variation Regularization Loss)。
Semantic Loss语义损失定义为:
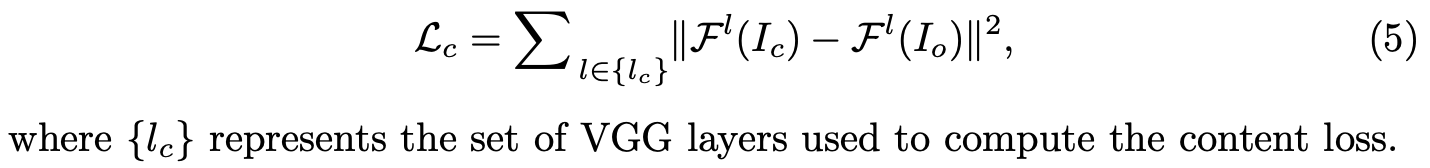
先定义了Gram矩阵的计算方式,而后将Stroke Loss笔触损失定义为:
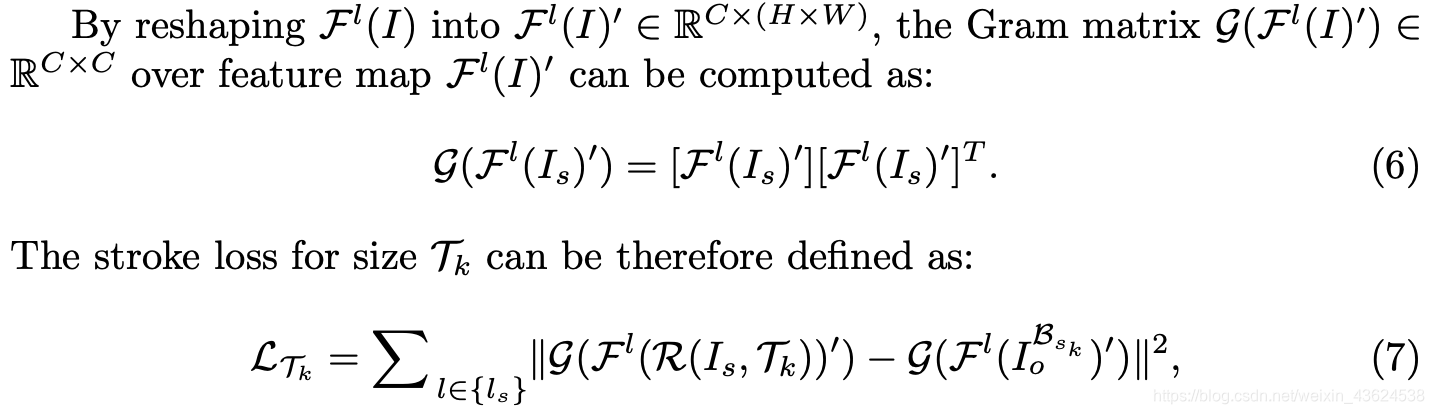
因此,总损失定义为,
α
\alpha
α、
β
\beta
β和
γ
\gamma
γ为超参数:
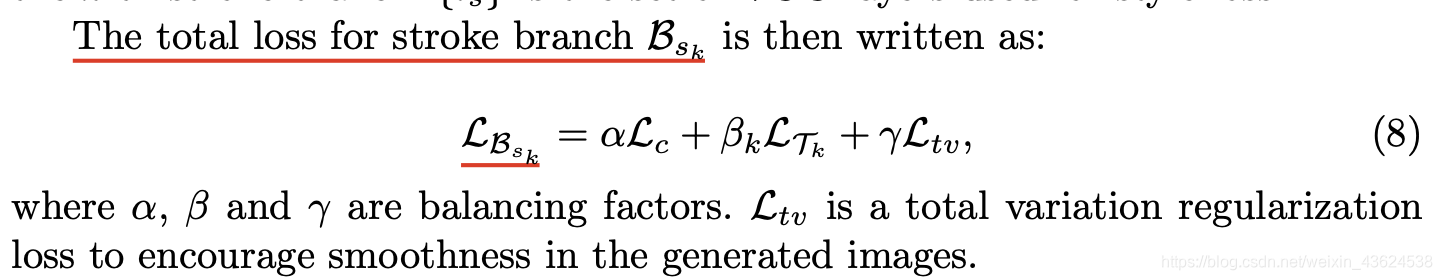
1.3 Other Details
在论文中,作者还详细地介绍了训练策略,在这里就不展开了,有兴趣的伙伴可以自己翻阅原论文和相关博客。
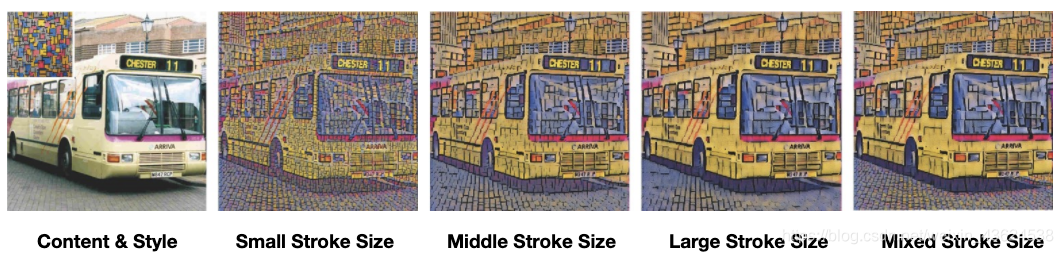
在实验中,作者主要是通过Qualitative Evaluation和Quantitative Evaluation来证明自己的算法可以达到SOTA的效果,包括训练曲线分析、平均损失分析等等。作者在文中也提到了算法可以允许空间笔触大小来控制风格迁移,如下图所示,但是作者给出的Github代码中似乎没有这个功能,有兴趣的大佬可以自己复现一下。

2. 代码详解
2.1 每个.py文件介绍
train.py:定义main函数,包括参数的传入,创建tf的图,调用和训练Model,传入内容图像和风格图像等;
model.py:定义了n种笔触大小(论文种用的768、512和256的风格图像大小,和内容图像大小的比例是1.5、1和0.5),风格层和内容层,定义了DataLoader类和Model类;
class DataLoader:训练的时候用了2014COCO数据集或者从MSCOCO中随机抽取2000张图像。
Model:定义模型的前向传播过程和loss损失计算方式。
2.2 部分代码重点备注
2.2.1 Tensorflow使用GPU训练现存占用问题
Tensorflow在训练时默认占用所有的GPU显存,我们可以通过几种方式来解决这个问题:
1.在tf.Session()的时候通过tf.GPUOptions作为可选配置参数来制定需要分配的显存比例(只能均匀作用于所有的GPU,无法对不同的GPU设置不同的上限),例如:
gpu_options = tf.GPUOptioins(per_process_gpu_memory_fraction=0.33) # 占用1/3的显存
sess = tf.Session(config = tf.ConfigProto(gpu_option=gpu_options))
2.按需增长的指定所有GPU内存,例如:
config = tf.ConfigProto()
config.gpu_options.allow_growth = True
sess = tf.Session(config=config)
3.指定可见的服务器(但是指定的可见服务器也会所有被占满),例如:
export CUDA_VISIBLE_DEVICES = 0,1
2.2.2 for i in xrange() 和range()的区别
Python2中使用的for i in xrange() 和for i in range(),前者类型是生成器,后者类型是个列表,但是在Python3中的range是Python2中饿xrange的概念。两者在作用上没有什么太大的区别,都会遍历区间内的所有数,只是xrange()更加节约空间。
x = range(0,3) # Python3
print(type(x)) # Output:<class 'range'>
print(x) # output:range(0,3)