这里目录标题
1.简介
- Flink 简介 + 运行架构 + 程序与 DataFlow数据流
- 链接: https://blog.csdn.net/weixin_43660536/article/details/120126980.
2、Flink 搭建
- Flink 1.9.3 搭建:
- https://blog.csdn.net/weixin_43660536/article/details/120089661..
3、Flink 运行架构
4、程序与数据流(DataFlow)
- Flink 简介 + 运行架构 + 程序与 DataFlow数据流
- 链接: https://blog.csdn.net/weixin_43660536/article/details/120126980.
5、Flink 流处理API
- Flink 流处理 API 详解
https://blog.csdn.net/weixin_43660536/article/details/120142486.
6、Window 窗口机制
-
转换和滚动聚合一次处理一个事件产生输出事件并可能更新状态。但是,有些操作必须收集并缓冲数据以计算其结果。
-
例如,考虑不同流之间的连接或整体聚合这样的操作,例如中值函数。为了在无界流上高效运行这 些操作符,我们需要限制 这些操作维护的数据量。
-
窗口还可以在语义上实现关于流的比较复杂的查询。
-
我们已经看到了滚动聚合的方式,以聚合值编码整个流的历史数据来为每个事件提供低延迟的结果。
6.1、策略
- 窗口操作不断从无限事件流中创建有限的事件集,好让我们执行有限集的计算。
- 通常会基于数据属性或基于时间的窗口来分配事件。
- 窗口的行为由一组策略定义。
- 窗口策略决定何时创建新的窗口以及要分配的事件属于哪个窗口,以及何时对窗口中的元素进行求值。
- 一旦触发条件得到满足,窗口的内容将会被发送到求值函数,求值函数会将计算逻辑应用于窗口中的元素。
- 求值函数可以是sum或minimal或自定义的聚合函数。 求值策略可以根据时间或者数据属性计算
6.2、类型
- Window 可以分成两类:
- 基于数据驱动:(Count Window,例如:每一百个元素)按照指定的数据条数生成一个 Window,与时间无关。
- 基于时间驱动:(Time Window,例如:每30秒钟)按照时间生成 Window。
- 基于不同事件驱动的窗口又可以分成以下几类:
- 翻滚窗口(Tumbling Window,无重叠)
- 滑动窗口(Sliding Window,有重叠)
- 会话窗口(Session Window,活动间隙)
- 全局窗口 (Global Window 全局窗口)
6.3、Windows API
- 窗口分配器 —— window() 方法
- 用 .window() 来定义一个窗口,去做一些聚合或者其它处理操作。
- 注意 window () 方法必须在 keyBy 之后才能用。
- 提供了更加简单的 .timeWindow 和 .countWindow 方法,用于定义时间窗口和计数窗口。
在实际案例中Keyed Window 使用最多,所以我们需要掌握Keyed Window的算子,
- 在每个窗口算子中包含了
- Windows Assigner、
- Windows Trigger(窗口触发器)、
- Evictor(数据剔除器)、
- Lateness(时延设定)、
- Output (输出标签)
- Windows Function,
- 其中Windows Assigner和Windows Functions是所有窗口算子 必须指定的属性,其余的属性都是根据实际情况选择指定.
code:
stream.keyBy(...)是Keyed类型数据集
.window(...)//指定窗口分配器类型
[.trigger(...)]//指定触发器类型(可选)
[.evictor(...)] // 指定evictor或者不指定(可选)
[.allowedLateness(...)] //指定是否延迟处理数据(可选)
[.sideOutputLateData(...)] // 指定Output lag(可选)
.reduce/aggregate/fold/apply() //指定窗口计算函数
[.getSideOutput(...)] //根据Tag输出数据(可选)
intro:
Windows Assigner : 指定窗口的类型,定义如何将数据流分配到一个或多个窗口
Windows Trigger : 指定窗口触发的时机,定义窗口满足什么样的条件触发计算
Evictor : 用于数据剔除
allowedLateness : 标记是否处理迟到数据,当迟到数据达到窗口是否触发计算
Output Tag: 标记输出标签,然后在通过getSideOutput将窗口中的数据根据标签输出
Windows Function: 定义窗口上数据处理的逻辑,例如对数据进行Sum操作
-
Flink要操作窗口,先得将StreamSource 转成WindowedStream.
方法名: 描述 window
KeyedStream → WindowedStream可以在已经分区的KeyedStream上定义 Windows,即K,V格式的数据。 WindowAll
DataStream → AllWindowedStream对常规的DataStream上定义Window,即非 K,V格式的数据 Window Apply
WindowedStream → DataStream
AllWindowedStream → DataStream将函数应用于整个窗口中的数据。 Window Reduce
WindowedStream → DataStream对窗口里的数据进行”reduce”减少聚合统计 Aggregations on windows
WindowedStream → DataStream对窗口里的数据进行聚合操作:
windowedStream.sum(0);
windowedStream.sum(“key”);
6.3.1. 滚动窗口(Tumbling Window)
- 滚动窗口是将事件分配到固定大小的不重叠的窗口中。
- 特点:时间对齐,窗口长度固定,没有重叠。
- 当通过窗口的结尾时,全部事件被发送到求值函数进行处理。
- 基于计数的翻滚窗口,每四个元素一个窗口。
- 基于时间的滚动窗口,将事件收集到窗口中每10分钟触发一次计算。

- 基于事件驱动
//基于事件驱动,每100个事件,划分一个窗口
dataStream.keyBy(0)
.countWindow(100)
.sum(1)
.printToErr();
- 基于时间驱动
//基于时间驱动,每隔1分钟划分一个窗口
dataStream.keyBy(0)
.timeWindow(Time.minutes(1))
.sum(1)
.printToErr();
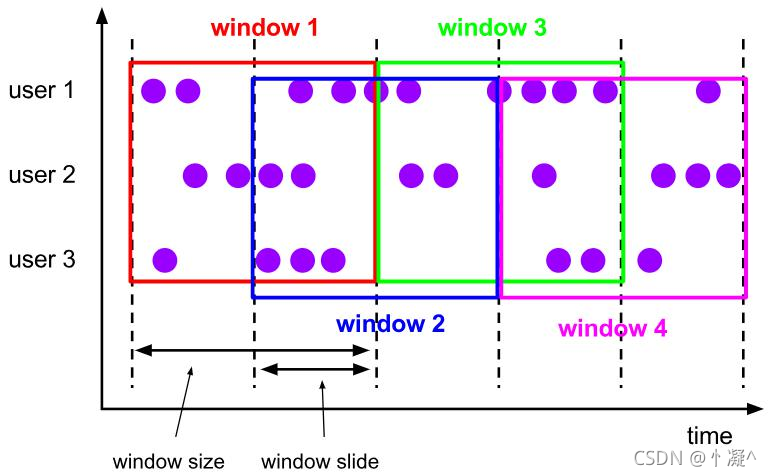
6.3.2. 滑动窗口(Sliding Window)
-
滑动窗口是固定窗口的更广义的一种形式;
-
滑动窗口将事件分配到固定大小的可重叠的窗口中去。
-
特点:时间对齐,窗口长度固定,可以有重叠。
-
通过提供窗口的长度和滑动距离来定义滑动窗口。滑动距离定义了创建新窗口的间隔。
- 基于时间驱动
//基于时间驱动,每隔30s计算一下最近一分钟的数据
mapStream
.keyBy(0)
.timeWindow(Time.minutes(1),Time.seconds(30))
.sum(1)
.printToErr();
- 基于事件驱动
//基于事件驱动,每10个元素触发一次计算,窗口里的事件数据最多为100个
mapStream
.keyBy(0)
.countWindow(100,10)
.sum(1)
.printToErr();
6.3.3. 会话窗口(session windown)
- 会话窗口在常见的真实场景中很有用,一些场景既不能使用滚动窗口也不能使用滑动窗口。
- 由一系列事件组合一个指定时间长度的 timeout 间隙组成,类似于 web 应用的 session,
- 也就是一段时间没有接收到新数据就会生成新的窗口。
- 会话窗口会定义一个间隙值来区分不同的会话。间隙值的意思是:用户一段时间内不活动,就认为用户的会话结束了。
- 特点:时间无对齐。

- 基于会话驱动
//基于会话驱动,通过会话Session Gap来区分
source
.keyBy(0)
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(30)))
.sum(1)
.print(System.currentTimeMillis() + ":");
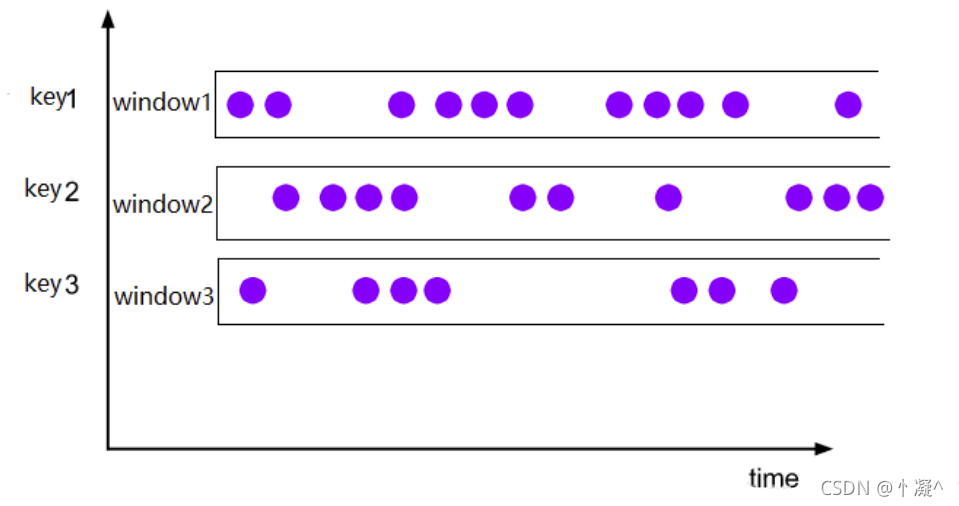
6.3.4. 全局窗口(Global Windows)
- 将所有数据分配到单个窗口中计算结果,窗口没有起始和结束时间。
- 窗口需要借助于Triger来触发计算,如果不对Global Windows指定Triger,窗口是不会触发计算的。
- 使用Global Windows需要非常慎重,用户需要指定对应的触发器,同时还需要有指定相应的数据清理机制,否则数据将一直留在内存中。
//.windowAll()
//.timeWindowAll()
//.countWindowAll()
//简单的字符串--每5个操作男生女生各有多少人
streamSource.countWindowAll(5).apply(new AllWindowFunction<String, String, GlobalWindow>() {
@Override
public void apply(GlobalWindow globalWindow, Iterable<String> iterable, Collector<String> collector) throws Exception {
int man = 0;
int woman = 0;
Iterator<String> iterator = iterable.iterator();
while (iterator.hasNext()) {
if (iterator.next().equals("w")) {
woman++;
} else {
man++;
}
}
collector.collect("man:" + man);
collector.collect("woman:" + woman);
}
}).print();
6.4、 window窗口聚合函数
- Flink提供了两大类窗口函数,分别为增量聚合函数和全量窗口函数。
- 增量聚合窗口是基于中间结果状态计算最终结果的,即窗口中只维护一个中间结果状态,,不要缓存所有的窗口数据。
- 全量窗口函数,需要对所有进入该窗口的数据进行缓存,等到窗口触发时才会遍历窗口内所有 数据,进行结果计算。
6.4.1. 增量聚合函数
包括:ReduceFunction、AggregateFunction和FoldFunction
streamSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
}).keyBy(0).countWindow(5).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> all, Tuple2<String, Integer> each) throws Exception {
System.out.println("Hello06ReduceFunction.reduce[" + all + "][" + each + "]");
all.setField(all.f1 + each.f1, 1);
return all;
}
}).print();
6.4.2. 全量窗口函数
- 包括:ProcessWindowFunction
streamSource.map(new MapFunction<String, Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> map(String s) throws Exception {
return Tuple2.of(s, 1);
}
}).keyBy(0).countWindow(5).process(new ProcessWindowFunction<Tuple2<String, Integer>, Object, Tuple, GlobalWindow>() {
@Override
public void process(Tuple key, Context context, Iterable<Tuple2<String, Integer>> iterable, Collector<Object> collector) throws Exception {
System.out.println("Hello07ProcessFunction.process[" + key + "]");
//计算平均结果
int sum = 0;
int count = 0;
Iterator<Tuple2<String, Integer>> iterator = iterable.iterator();
while (iterator.hasNext()) {
Tuple2<String, Integer> tuple2 = iterator.next();
sum += tuple2.f1;
count++;
}
//计算平均值并进行收集
collector.collect(key + "--" + (sum * 1.0 / count));
}
}).print();
6.5、其他 API
-
.trigger()——触发器定义window 什么时候关闭,触发计算并输出结果
-
.evitor()——移除器定义移除某些数据的逻辑
-
.allowedLateness()——允许处理迟到的数据 -
.sideOutputLateData()——将迟到的数据放入侧输出流 -
.getSideOutput()——获取侧输出流

7、时间语义与watermark
- 在流处理中,窗口操作与两个主要概念密切相关:时间语义和状态管理。
- 时间也许是流处理最重要的方面。即使低延迟是流处理的一个有吸引力的特性,它的真正价值不仅仅是快速分析。
- 真实世界的系统,网络和通信渠道远非完美,流数据经常被推迟或无序(乱序)到达。
- 理解如何在这种条件下提供准确和确定的结果是至关重要的。
7.1、时间语义
-
Event Time:事件时间 ;
- 事件时间是流中的事件实际产生(发生)的时间。事件时间基于流中的事件所包含的时间戳。
- 事件时间使得计算结果的过程不需要依赖处理数据的速度。
-
Ingestion Time:数据进入Flink的时间
-
Processing Time:处理时间;
- 执行操作算子的本地系统时间,与机器相关。
- 处理时间的窗口包含了一个时间段内来到机器的所有事件。
-
乱序数据的影响
- 当 Flink 以
Event Time模式处理数据流时,它会根据数据里的时间戳来处理基于时间的算子。 - 由于网络、分布式等原因,会导致乱序数据的产生。
- 乱序数据会让窗口计算不准确。
- 当 Flink 以
7.2、watermark 水位线
- Watermark 是一种衡量 Event Time 进展的机制,可以设定延迟触发 。
- Watermark 是用于处理乱序事件的,而正确的处理乱序事件,通常用 Watermark 机制结合 window 来实现;本质上也是一种时间戳。
- watermark 用来让程序自己平衡延迟和结果正确性 。
- 水位线是全局进度的度量标准。线提供了一种结果可信度和延时之间的妥协。
- 激进的水位线设置可以保证低延迟,但结果的准确性不够。
- 水位线设置的过于宽松,计算的结果准确性会很高,
7.2.2. Watermark原理
-
watermark 是一条特殊的数据记录 。
-
watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退 。
-
watermark 与数据的时间戳相关。
-
在 Flink 的窗口处理过程中,如果数据没有全部到达,则继续等待该窗口中的数据全部到达才开始处理。
-
这种情况下就需要用到水位线(WaterMarks)机制,它能够衡量数据处理进度(表达数据到 达的完整性),保证事件数据(全部)到达 Flink 系统,或者在乱序及延迟到达时,也能够像预期一样计算出正确并且连续的结果。
-
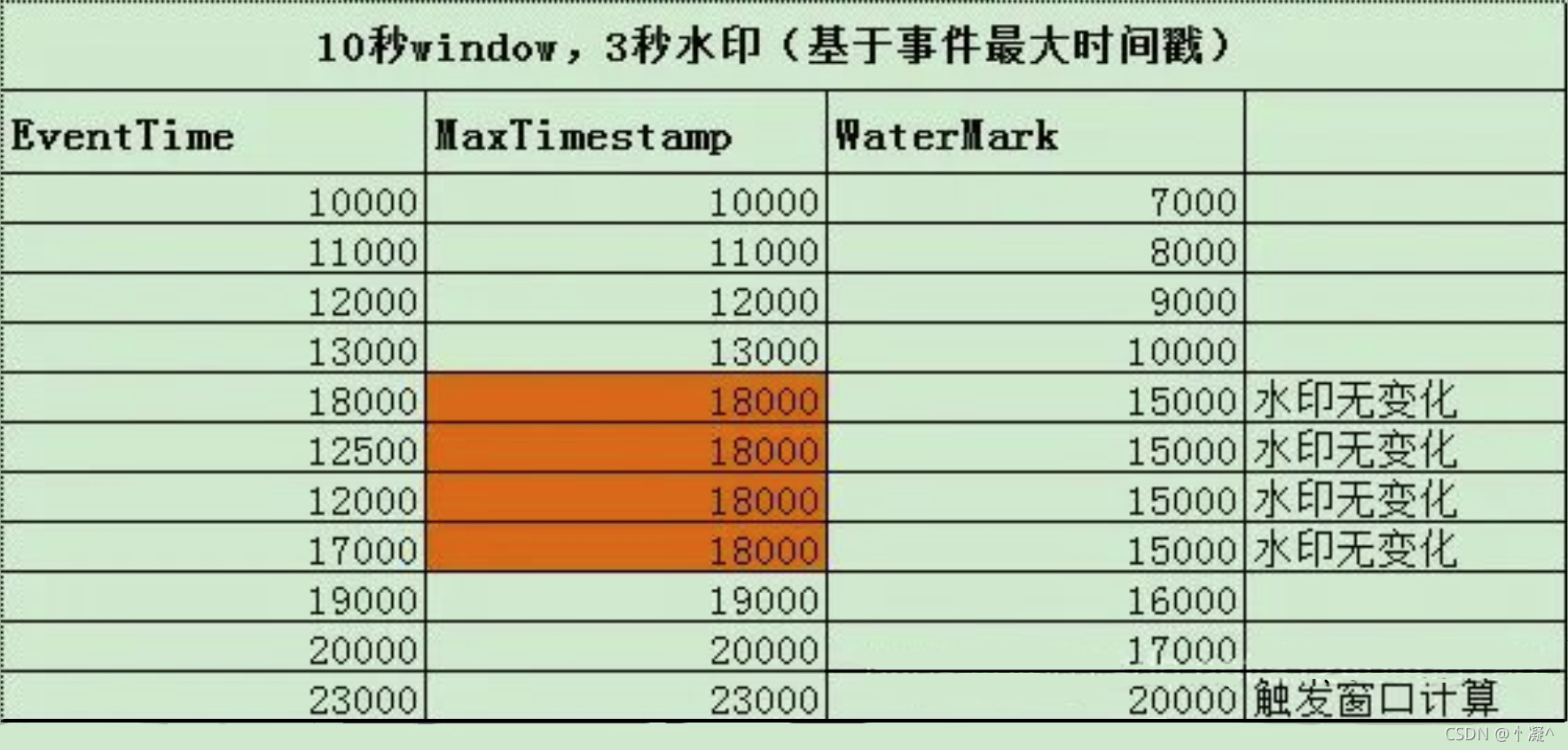
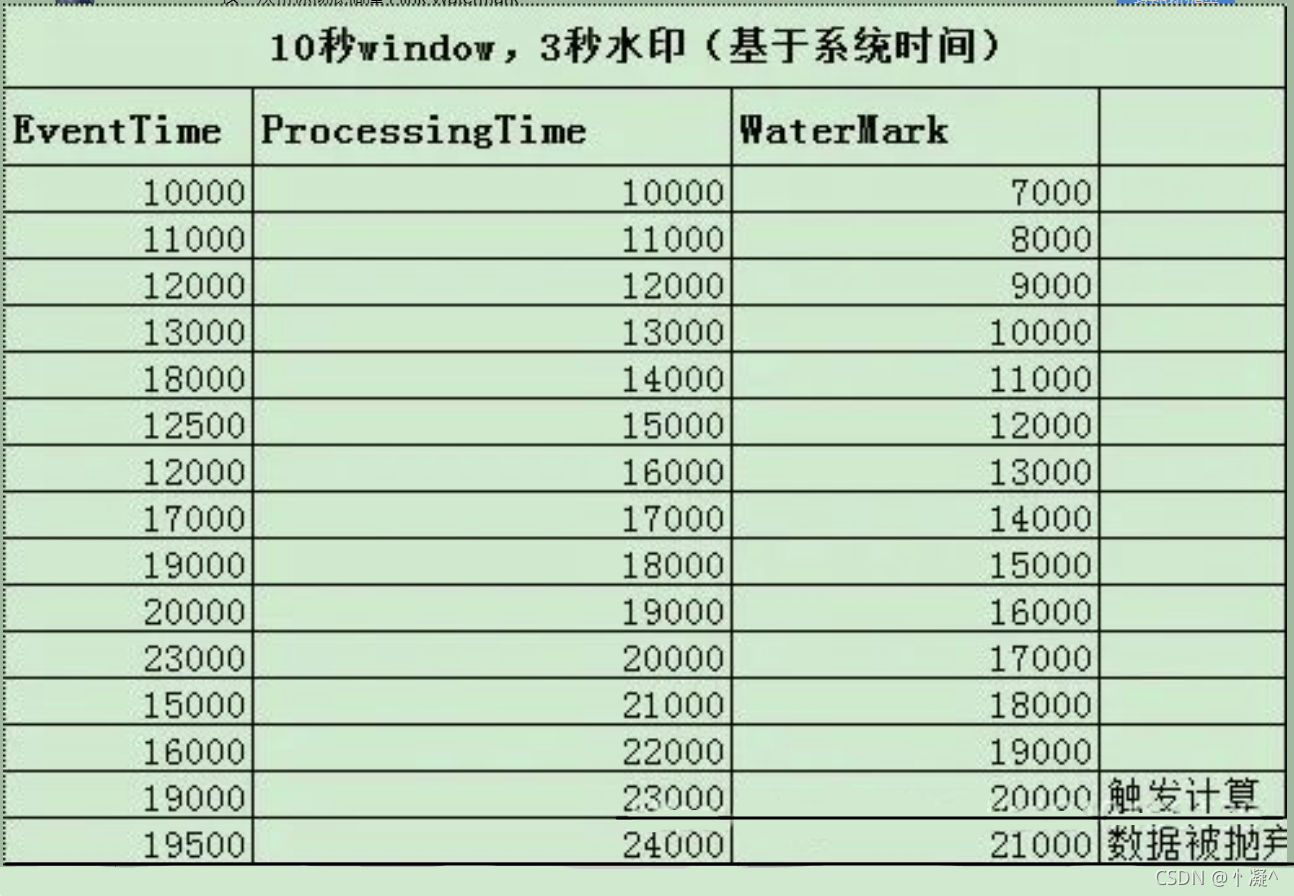
当任何 Event 进入到 Flink系统时,会根据当前最大事件时间产生 Watermarks 时间戳。
-
如果有
窗口的结束时间 <= WaterMark(maxEventTime – t(设置的延迟时间)),那么这个窗口被触发执行。 -
7.2.3. Watermark三种使用情况
-
Flink内部传播水位线的策略可以归纳为3点:
-
首先,水位线是以广播的形式在算子之间进行传播
-
Long.MAX_VALUE表示事件时间的结束,即未来不会有数据到来了
-
/** * 当一个source关闭时,会输出一个Long.MAX_VALUE的水位线,当一个算子接收到该水 位线时, * 相当于接收到一个信号:未来不会再有数据输入了 */ @PublicEvolving public final class Watermark extends StreamElement { //表示事件时间的结束 public static final Watermark MAX_WATERMARK = new Watermark(9223372036854775807L); } -
单个分区的输入取最大值,多个分区的输入取最小值
-
-
本来有序的Stream中的Watermark
-
乱序事件中的Watermark
- 频繁出现乱 序或迟到的情况,这种情况就需要使用Watermarks来应对。
-
并行数据流中的Watermark
- 在多并行度的情况下,Watermark会有一个对齐机制,这个对齐机制会取所有Channel中最 小的Watermark。
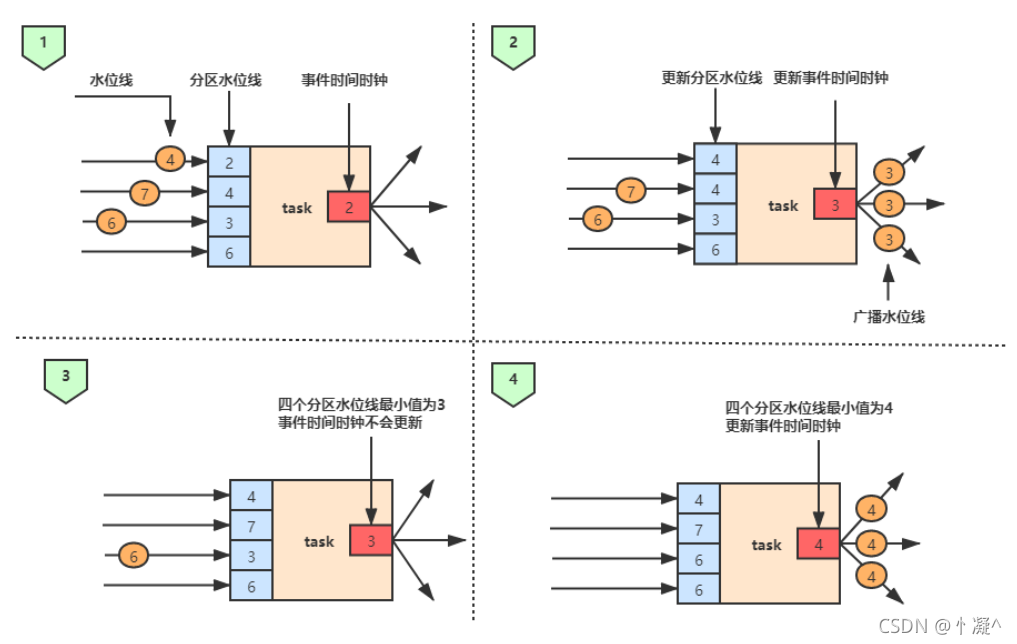
7.2.4. Watermark的产生方式
-
一种方式为在数据源完成的,即利用SourceFunction在应用读入数据流的时候分配时间戳与水位线。
-
通过实现接口的自定义函数,该方式又包括两种实现方式:
-
//给源数据添加水位线 andWatermarks = dataStream.assignTimestampsAndWatermarks(new PunctuatedWaterMark()).setParallelism(1); -
周期性生成水位线,即实现AssignerWithPeriodicWatermarks接口,
- 周期性的生成 watermark:每隔2秒产生一个watermark。
- 默认周期是200毫秒,可以使用
ExecutionConfig.setAutoWatermarkInterval()方法进行设置 - 升序和前面乱序的处理 BoundedOutOfOrderness ,都是基于周期性 watermark 的。
val env = StreamExecutionEnvironment.getExecutionEnvironment env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime) // 每隔 5 秒产生一个 env.getConfig.setAutoWatermarkInterval(5000) //给源数据添加水位线 SingleOutputStreamOperator<String> andWatermarks = dataStream.assignTimestampsAndWatermarks(new PeriodicWaterMark()).setParallelism(1); class PeriodicWaterMark implements AssignerWithPeriodicWatermarks<String> { //数据允许的延迟情况 long maxLateTime = 5000; //当前系统最大的时间 long currentMaxTimestamp = Long.MIN_VALUE; //水印产生,周期性产生,默认200ms,基于自己业务的时间容忍度去产生水印,因为要通过水印来解决数据的延迟/乱序问题 @Override public Watermark getCurrentWatermark() { long watermarkTimeStamp = System.currentTimeMillis() - maxLateTime; System.out.println("PeriodicWaterMark.getCurrentWatermark[" + long2date(watermarkTimeStamp) + "]"); //本次水位线的位置 Watermark waterMark = new Watermark(watermarkTimeStamp); return waterMark; } /** * 从事件中抽取时间,假设数据格式为 hello,1630034287000 * * @param element * @param previousElementTimestamp * @return */ @Override public long extractTimestamp(String element, long previousElementTimestamp) { long eventTimestamp = Long.valueOf(element.split(",")[1]); System.out.println("PeriodicWaterMark.extractTimestamp事件时间[" + long2date(eventTimestamp) + "]"); return eventTimestamp; } private String long2date(long time) { return new SimpleDateFormat("yyyy-MM-dd HH:mm:ss - SSS").format(new Date(time)); } }- 定点生成水位线,即实AssignerWithPunctuatedWatermarks接口。
- 没有时间周期规律,间断式地生成 watermark。
- 基于某些事件(指示系统进度的特殊元祖或标记)触发水位线的生成与发 送,
//给源数据添加水位线 SingleOutputStreamOperator<String> andWatermarks = dataStream.assignTimestampsAndWatermarks(new PunctuatedWaterMark()).setParallelism(1); class PunctuatedWaterMark implements AssignerWithPunctuatedWatermarks<String> { @Override public Watermark checkAndGetNextWatermark(String line, long l) { if (line != null && "hello".equals(line)) { return new Watermark(System.currentTimeMillis()); } else { return null; } } @Override public long extractTimestamp(String line, long previousElementTimestamp) { long timestamp = System.currentTimeMillis(); System.out.println("[" + line + "][" + timestamp + "]"); return timestamp; } } -
7.2.5. watermark 迟到数据
水位线可能会大于后来数据的时间戳,这就意味着数据有延迟,关于延迟数据的处理,Flink提供了一些机制,具体如下:
- 直接将迟到的数据丢弃
- 根据迟到的事件更新并发出结果
- allowedLateness( Time.seconds(1)) 迟到的数据依然可以计算进行计算
//给源数据添加水位线
SingleOutputStreamOperator<String> andWatermarks = dataStream.assignTimestampsAndWatermarks(new HelloPeriodicWaterMark()).setParallelism(1);
//开始处理数据
andWatermarks.map(word -> Tuple2.of(word.split(",")[0], (int) (Long.parseLong(word.split(",")[1]) % 1000)))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0)
.timeWindow(Time.seconds(3))
//设置allowedLateness()方法 迟到的数据也可以计算
.allowedLateness(Time.seconds(1))
.sum(1)
.print();
- 将迟到的数据输出到单独的数据流中(侧输出),即使用sideOutputLateData(new OutputTag<>())方法实现侧输出
//需要提前声明侧输出的容器
OutputTag<Tuple2<String, Integer>> lateOutputTag = new OutputTag<Tuple2<String, Integer>>("late") {};
//给源数据添加水位线
SingleOutputStreamOperator<String> andWatermarks = dataStream.assignTimestampsAndWatermarks(new HelloPeriodicWaterMark()).setParallelism(1);
//开始处理数据
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = andWatermarks.map(word -> Tuple2.of(word.split(",")[0], (int) (Long.parseLong(word.split(",")[1]) % 1000)))
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0)
.timeWindow(Time.seconds(3))
.allowedLateness(Time.seconds(1))
//使用sideOutputLateData()方法
.sideOutputLateData(lateOutputTag)
.sum(1);
sum.print("sum:");
sum.getSideOutput(lateOutputTag).print("side:");
8、状态管理State
9、ProcessFunction API(底层API)
- Flink state状态 与 ProcessFunction API 详解
- https://blog.csdn.net/weixin_43660536/article/details/120142911.
10、容错机制CheckPoint
13、Flink 反压机制
- Flink 容错机制 与 反压机制 详解
- https://blog.csdn.net/weixin_43660536/article/details/120143143.