1.集群环境
cdh版本 5.13.2
jdk 1.8
zookeeper 3.4.5
kafka 2.1.0
flume 1.6.0(相当于原生Apache flume 1.7,支持source源TAILDIR)
2.日志数据模拟
2.1 pom.xml、java代码
java代码可去资源中下载
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xxxx.java</groupId>
<artifactId>java-log-collector</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<logback.version>1.0.7</logback.version>
<slf4j.version>1.7.26</slf4j.version>
</properties>
<dependencies>
<!--阿里巴巴开源json解析框架-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.51</version>
</dependency>
<!--日志生成框架-->
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-core</artifactId>
<version>${logback.version}</version>
</dependency>
<dependency>
<groupId>ch.qos.logback</groupId>
<artifactId>logback-classic</artifactId>
<version>${logback.version}</version>
</dependency>
</dependencies>
<!--编译打包插件-->
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<!--指定jar包主类-->
<!--<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
<configuration>
<archive>
<manifest>
<mainClass>appClient.AppMain</mainClass>
</manifest>
</archive>
</configuration>
</plugin>-->
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<mainClass>appClient.AppMain</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>2.2 部署java
maven打包,选择含所有依赖的jar上传hadoop01、hadoop02。后台运行java程序
方法1:
cd /home/spark/jars/myJars
nohup java -classpath java-log-collector-1.0-SNAPSHOT-jar-with-dependencies.jar appClient.AppMain 参数1 参数2 > /home/spark/logs/java-log-collector.log 2>&1 &
(参数1:每条消息间隔,默认0;参数2:消息数量,默认1000)
方法2:(需要在pom.xml中添加“指定jar包主类”插件)
java -Djava.ext.dirs=$JAVA_HOME/jre/lib/ext:/home/spark/jars/libJars/java -jar /home/spark/jars/myJars/java-log-collector-1.0-SNAPSHOT.jar > /home/spark/logs/java-log-collector.log
将相关依赖包上传至集群环境,参考:https://blog.csdn.net/w47_csdn/article/details/80254459
3.flume配置、拦截器
3.1版本1.6、1.7配置
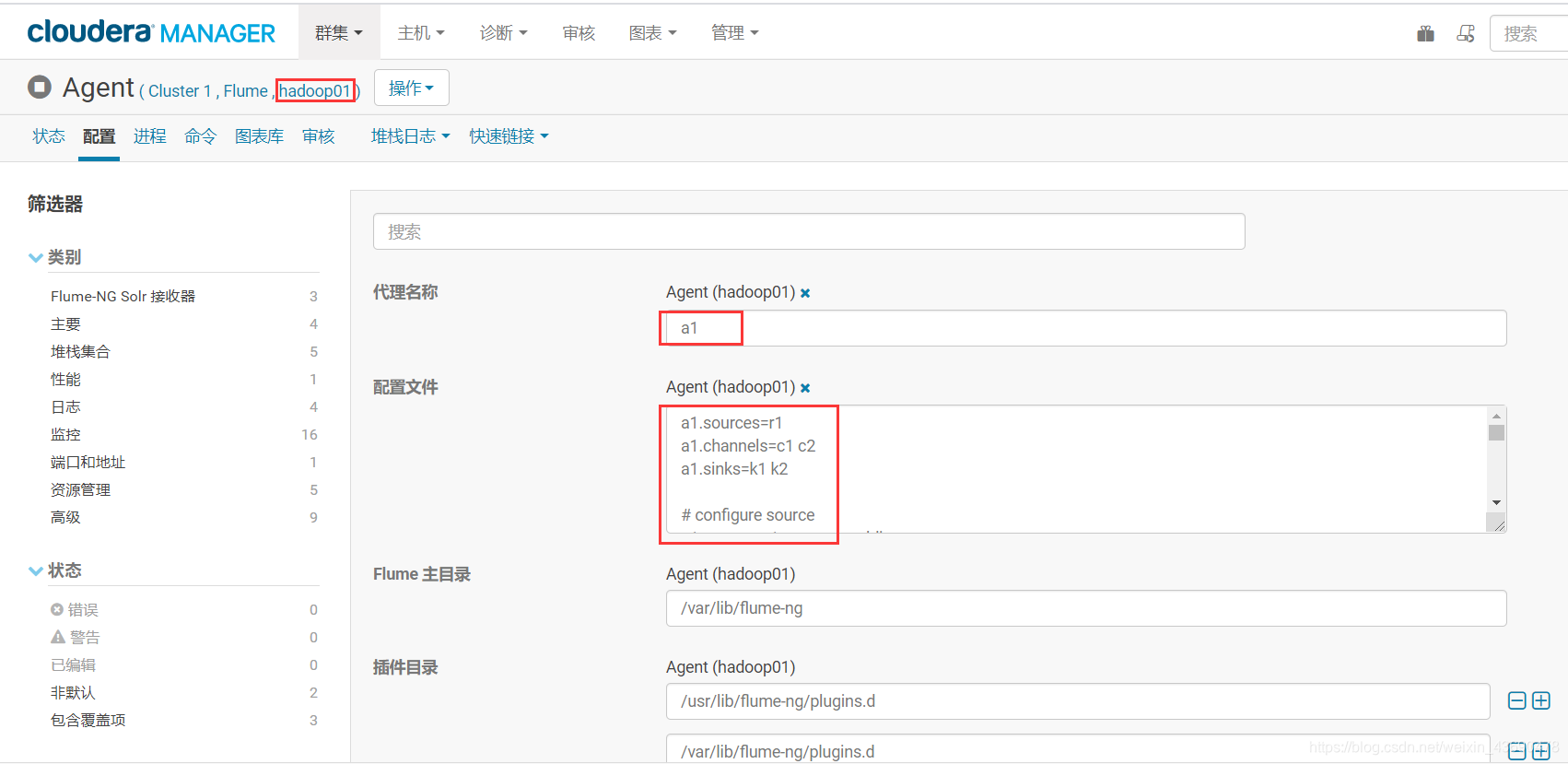
#flume-kafka配置(flume版本为1.6.0,不支持断点续传)
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
# configure source
a1.sources.r1.type = spooldir
a1.sources.r1.spoolDir = /tmp/logs
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = LogEtlInterceptor$Builder
a1.sources.r1.interceptors.i2.type = LogTypeInterceptor$Builder
# selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=10000
a1.channels.c1.byteCapacityBufferPercentage=20
a1.channels.c2.type = memory
a1.channels.c2.capacity=10000
a1.channels.c2.byteCapacityBufferPercentage=20
# configure sink
# start-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic = topic_start
a1.sinks.k1.brokerList = hadoop01:9092,hadoop02:9092,hadoop03:9092
#每个批处理的消息数量,默认值100条
a1.sinks.k1.batchSize = 20
a1.sinks.k1.requiredAcks = 1
a1.sinks.k1.channel = c1
# event-sink
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.topic = topic_event
a1.sinks.k2.brokerList = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sinks.k2.batchSize = 20
a1.sinks.k2.requiredAcks = 1
a1.sinks.k2.channel = c2#flume-kafka配置(source源TAILDIR为flume 1.7的新特性。支持断点续传)
a1.sources=r1
a1.channels=c1 c2
a1.sinks=k1 k2
# configure source
a1.sources.r1.type = TAILDIR
a1.sources.r1.positionFile = /var/log/flume-ng/log_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /tmp/logs/.*log.*
a1.sources.r1.fileHeader = true
a1.sources.r1.channels = c1 c2
#interceptor
a1.sources.r1.interceptors = i1 i2
a1.sources.r1.interceptors.i1.type = LogEtlInterceptor$Builder
a1.sources.r1.interceptors.i2.type = LogTypeInterceptor$Builder
# selector
a1.sources.r1.selector.type = multiplexing
a1.sources.r1.selector.header = topic
a1.sources.r1.selector.mapping.topic_start = c1
a1.sources.r1.selector.mapping.topic_event = c2
# configure channel
a1.channels.c1.type = memory
a1.channels.c1.capacity=10000
a1.channels.c1.byteCapacityBufferPercentage=20
a1.channels.c2.type = memory
a1.channels.c2.capacity=10000
a1.channels.c2.byteCapacityBufferPercentage=20
# configure sink
# start-sink
a1.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.topic = topic_start
a1.sinks.k1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
#每个批处理的消息数量,默认值100条
a1.sinks.k1.kafka.flumeBatchSize = 2000
a1.sinks.k1.kafka.producer.acks = 1
a1.sinks.k1.channel = c1
# event-sink
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.topic = topic_event
a1.sinks.k2.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sinks.k2.kafka.flumeBatchSize = 2000
a1.sinks.k2.kafka.producer.acks = 1
a1.sinks.k2.channel = c2查看偏移量文件/var/log/flume-ng/log_position.jso
3.2自定义拦截器
3.2.1 pom.xml配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.xxxx.flume</groupId>
<artifactId>flume-interceptor</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.flume</groupId>
<artifactId>flume-ng-core</artifactId>
<version>1.6.0</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>3.2.2 拦截器java代码
拦截器1:实现数据简单清洗
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
public class LogEtlInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
//etl
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
//校验
if (log.contains("start")) {
if (LogUtils.validateStart(log)) {
return event;
}
} else {
if (LogUtils.validateEvent(log)) {
return event;
}
}
return null;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> events1 = new ArrayList<>();
for (Event event : events) {
Event event1 = intercept(event);
if (event1 != null) {
events1.add(event1);
}
}
return events1;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new LogEtlInterceptor();
}
@Override
public void configure(Context context) {
}
}
}
拦截器2:根据body中的数据给header添加值
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import java.nio.charset.Charset;
import java.util.ArrayList;
import java.util.List;
import java.util.Map;
public class LogTypeInterceptor implements Interceptor {
@Override
public void initialize() {
}
@Override
public Event intercept(Event event) {
// 将body里的数据根据类型,写到header
//获取body数据
byte[] body = event.getBody();
String log = new String(body, Charset.forName("UTF-8"));
//获取header
Map<String, String> headers = event.getHeaders();
//判断启动日志、事件日志
if (log.contains("start")) {
headers.put("topic","topic_start");
} else {
headers.put("topic","topic_event");
}
return event;
}
@Override
public List<Event> intercept(List<Event> events) {
ArrayList<Event> events1 = new ArrayList<>();
for (Event event : events) {
Event event1 = intercept(event);
events1.add(event1);
}
return events1;
}
@Override
public void close() {
}
public static class Builder implements Interceptor.Builder {
@Override
public Interceptor build() {
return new LogTypeInterceptor();
}
@Override
public void configure(Context context) {
}
}
}3.2.3 上传jar,分发到hadoop02、hadoop03
cd /opt/cloudera/parcels/CDH/lib/flume-ng/lib
scp flume-interceptor-1.0-SNAPSHOT.jar hadoop02:$PWD
scp flume-interceptor-1.0-SNAPSHOT.jar hadoop03:$PWD
注意:
PWD表示变量,需大写,小写是操作指令。
修改jar权限 chmod 777 flume-interceptor-1.0-SNAPSHOT.jar
4.修改集群上的配置
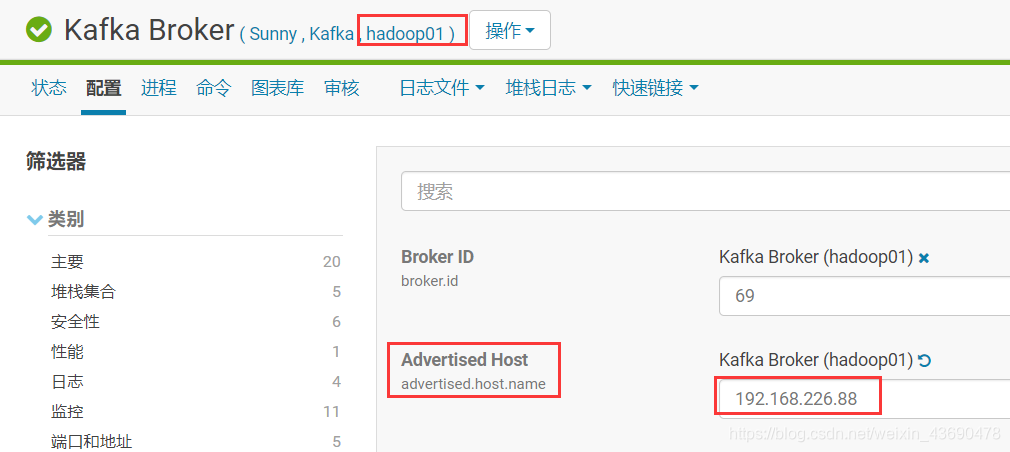
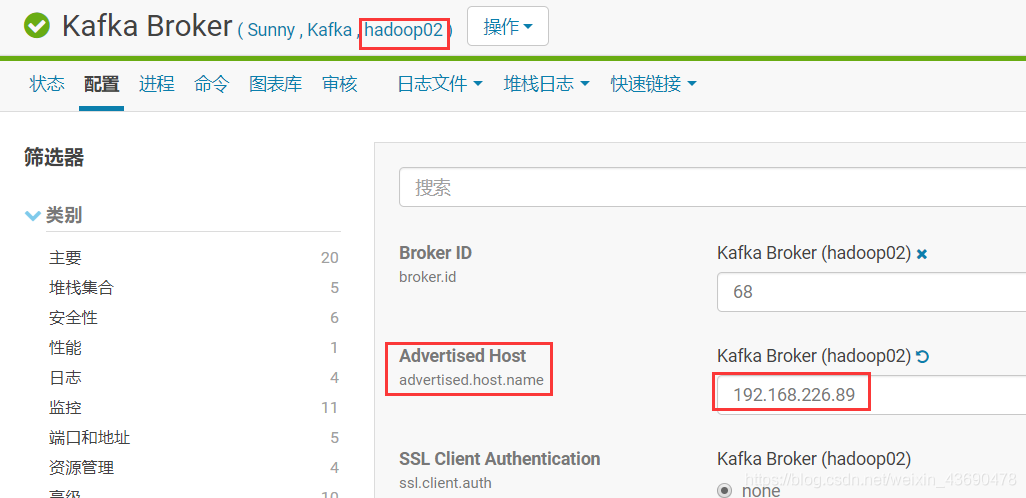
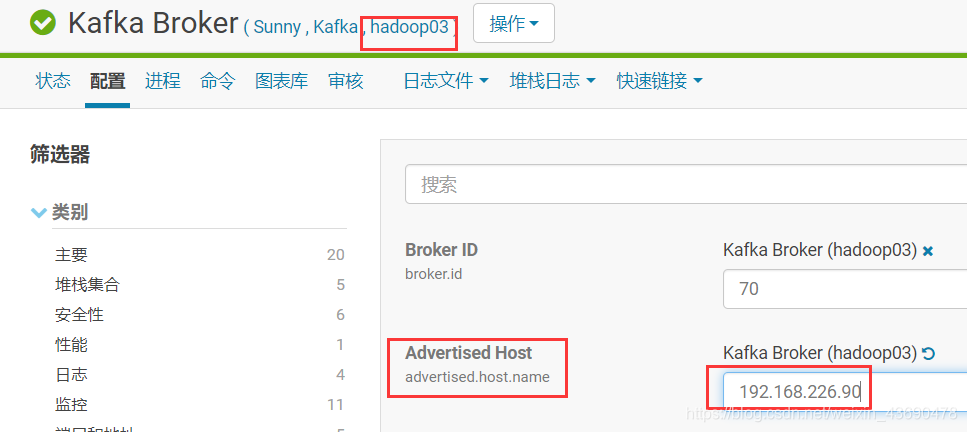
4.1 修改hadoop01、hadoop02上的配置
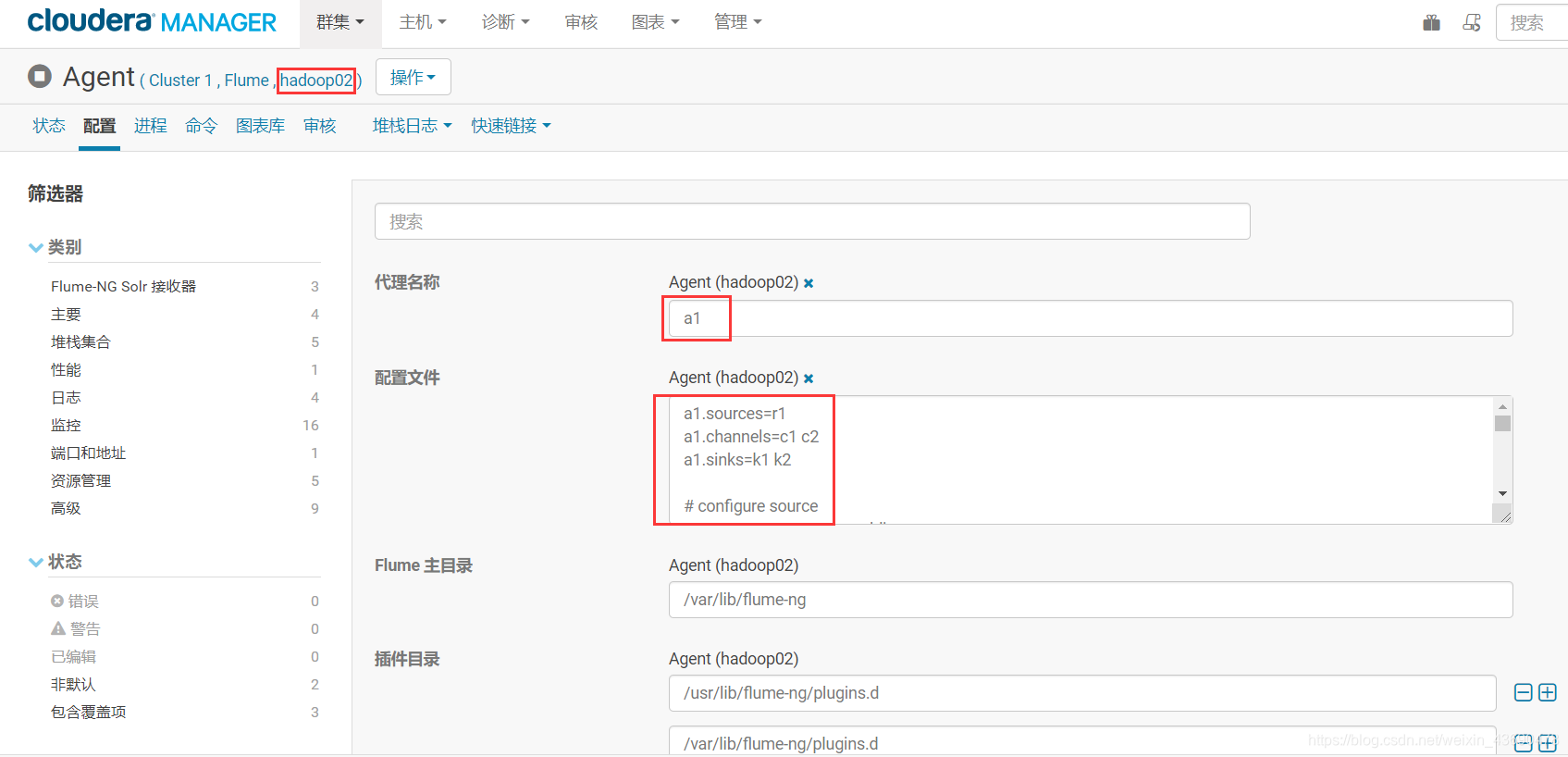
根据选项3.1中的配置信息,复制到下图 “配置文件” 选项,hadoop01,hadoop02配置一致
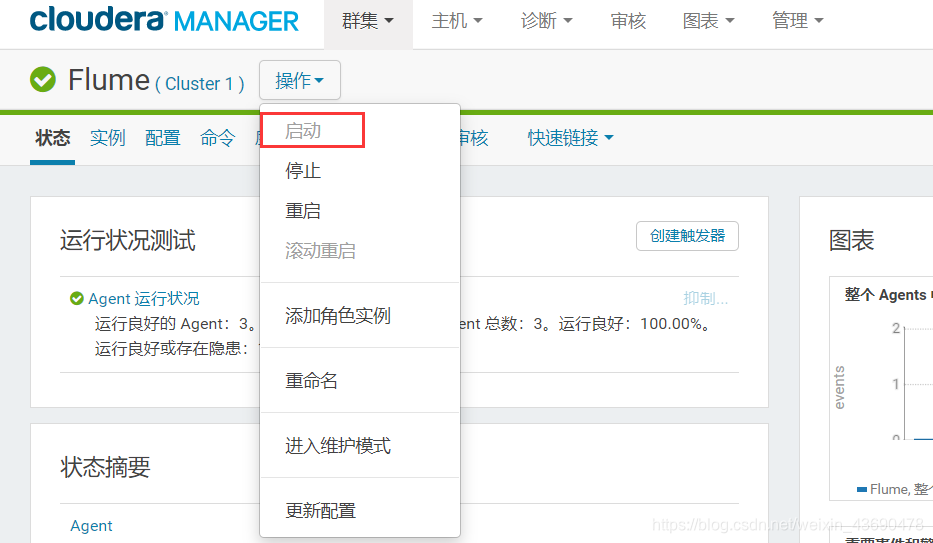
4.2启动flume
5.flume-kafka测试
5.1创建kafka-topic
cd /opt/cloudera/parcels/KAFKA/lib/kafka/bin
./kafka-topics.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --create --replication-factor 1 --partitions 1 --topic topic_start
./kafka-topics.sh --zookeeper hadoop01:2181,hadoop02:2181,hadoop03:2181 --create --replication-factor 1 --partitions 1 --topic topic_event
5.2通过shell消费topic下的数据
./kafka-console-consumer.sh --bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic topic_start --from-beginning
./kafka-console-consumer.sh --bootstrap-server hadoop01:9092,hadoop02:9092,hadoop03:9092 --topic topic_event --from-beginning
6.flume-kafka-hdfs测试(hadoop03)
6.1配置文件
flume1.6.0、flume1.7.0配置如下:
#flume版本为1.6
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.zookeeperConnect = hadoop01:2181,hadoop02:2181,hadoop03:2181
a1.sources.k1.brokerList = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sources.r1.topic=topic_start
a1.sources.r1.groupId = flume
a1.sources.r1.kafka.consumer.timeout.ms = 100
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.zookeeperConnect = hadoop01:2181,hadoop02:2181,hadoop03:2181
a1.sources.k1.brokerList = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sources.r2.topic=topic_event
a1.sources.r2.groupId = flume
a1.sources.r2.kafka.consumer.timeout.ms = 100
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/spark/data/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /home/spark/data/flume/flumeData/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /home/spark/data/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = home/spark/data/flume/flumeData/behavior2
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /tmp/kafka-flume-hdfs/topic_start/%Y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = logstart-
#控制文件夹,每10s生成一个新文件夹
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /tmp/kafka-flume-hdfs/topic_event/%Y-%m-%d/%H%M/%S
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
#不要产生大量小文件(rollInterval:10s生成新文件; rollSize:128M; rollCount:表示events数量,即每个文件消息条数,0表示关闭此选项)
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
#控制输出文件类型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2#flume版本为1.7.0
## 组件
a1.sources=r1 r2
a1.channels=c1 c2
a1.sinks=k1 k2
## source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sources.r1.kafka.topics=topic_start
## source2
a1.sources.r2.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r2.batchSize = 5000
a1.sources.r2.batchDurationMillis = 2000
a1.sources.r2.kafka.bootstrap.servers = hadoop01:9092,hadoop02:9092,hadoop03:9092
a1.sources.r2.kafka.topics=topic_event
## channel1
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /home/spark/data/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /home/spark/data/flume/flumeData/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## channel2
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /home/spark/data/flume/checkpoint/behavior2
a1.channels.c2.dataDirs = /home/spark/data/flume/flumeData/behavior2
a1.channels.c2.maxFileSize = 2146435071
a1.channels.c2.capacity = 1000000
a1.channels.c2.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /tmp/kafka-flume-hdfs/topic_start/%Y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = logstart-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = second
##sink2
a1.sinks.k2.type = hdfs
a1.sinks.k2.hdfs.path = /tmp/kafka-flume-hdfs/topic_event/%Y-%m-%d/%H%M/%S
a1.sinks.k2.hdfs.filePrefix = logevent-
a1.sinks.k2.hdfs.round = true
a1.sinks.k2.hdfs.roundValue = 10
a1.sinks.k2.hdfs.roundUnit = second
## 不要产生大量小文件
a1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k2.hdfs.rollInterval = 10
a1.sinks.k2.hdfs.rollSize = 134217728
a1.sinks.k2.hdfs.rollCount = 0
## 控制输出文件是原生文件。
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k2.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = lzop
a1.sinks.k2.hdfs.codeC = lzop
## 拼装
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1
a1.sources.r2.channels = c2
a1.sinks.k2.channel= c2注意:检查点checkpoint目录和数据目录需要更改读写权限。
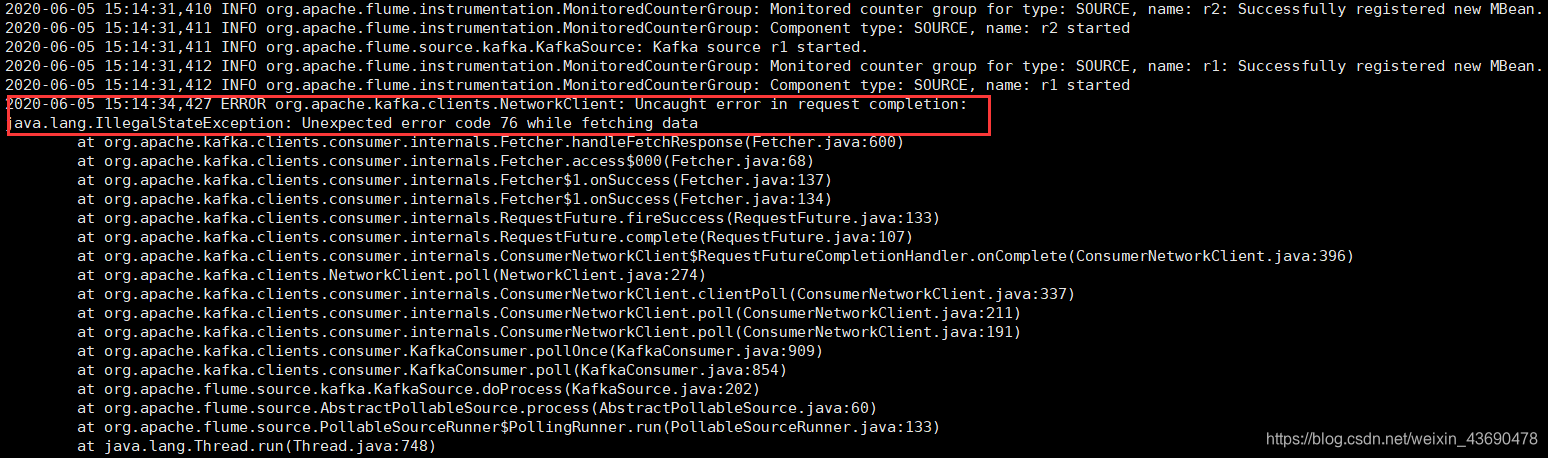
6.2错误记录
cdh5.13.2的flume版本为1.6.0,相当于原生Apache flume1.7.0
如果集群上版本1.6以下。flume对接kafka时候,需修kafka各节点配置:
flume1.7不需要设置,否则会报错,如下:
ERROR org.apache.kafka.clients.NetworkClient: Uncaught error in request completion:
java.lang.IllegalStateException: Unexpected error code 76 while fetching data
参考:
http://flume.apache.org/releases/content/1.6.0/FlumeUserGuide.html
http://flume.apache.org/releases/content/1.7.0/FlumeUserGuide.html