文章目录
如果有理解错误的地方可以在评论指出,个人再做下功课
附上自己做的热点表缓存托管工具:https://gitee.com/vincent_jiao/jiaocache
Redis 过期的策略
可能有时候你会遇到一个场景,在 Redis 中大量的 key 明明已经过期了,结果发现 Redis 的占用还是很高?如果要明白为什么,那就要知道Redis 的过期策略。策略分为 2 种,定期删除与惰性删除。
定期删除
假设在 Redis 中存在 10w 个设置了过期的 key,如果此时 Redis 每隔指定毫秒每隔都扫描一遍看下有没有过期,那这个时候 Redis 基本就废了,CPU 负载会贼高,性能全花在了扫描过去可以上了。
而 Redis 使用定期删除,默认每隔 100ms 就随机抽取一些设置了过期时间的 key,检查是否过期,过期就删除。所以你会发现设置了过期时间但是为什么没有在指定时间点删除,就是因为这个。
惰性删除
定期删除会导致可能很多过期 key 没有被删除,那怎么办?所以这里就配合和惰性删除,在你获取某个 key 时候, redis 会检查一些这个 key 如果设置了过期时间并且删除了,那么就会删除掉,不会返回任何东西。
通过上面 2 中情况来保证 key 被干掉,但是还是有一种情况。如果 key 没被定期删除,也比较少访问这个 key 也没被惰性删除,然后导致大量的无效 key 堆积,导致内存贼高,最后直接超出内存耗尽,这个时候怎么办?这里就要用到淘汰机制了。
淘汰机制
如果 redis 内存占用超过了设置的阀值后,已经当不足以容纳新写入的数据时候,就会进行内存淘汰,策略如下:
- noeviction:新写入操作会报错。
- allkeys-lru:在键空间中,移除最近最少使用的 key(常用,下面有 LRU 算法原理说明)
- allkeys-random:随机移除某个 key,这个没必要使用吧。
- volatile-lru:只限于设置了 expire 的key,随机移除一个
- volatile-ttl:只限于设置了 expire 的key,优先删除剩余时间(time to live,TTL) 短的key。
- volatile-lru:只限于设置了 expire 的key, 优先删除最近最少使用(less recently used ,LRU) 的 key。
最近才知道在 5.0 时候又添加了 LFU (最少使用的)算法,为每个key维护一个计数器。每次key被访问的时候,计数器增大。计数器越大,可以等于访问越频繁。
LUR 算法原理简单说明
LUR 算法就是淘汰最少使用的数据,比如历史记录。核心思想就是 如果数据最近被访问过,那么将来被访问的几率也更高
比较常见的实现就是使用链表结构来实现,写数据时候就压栈,访问数据时候,将原本数据取出,再放入链表中的表头。这个时候就能保证最少使用会在表的尾部。如下图:
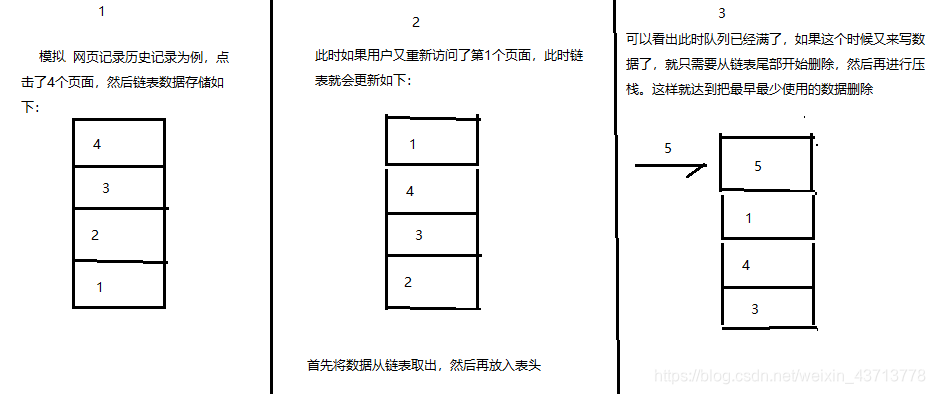
怎么保证 Redis 高可用?
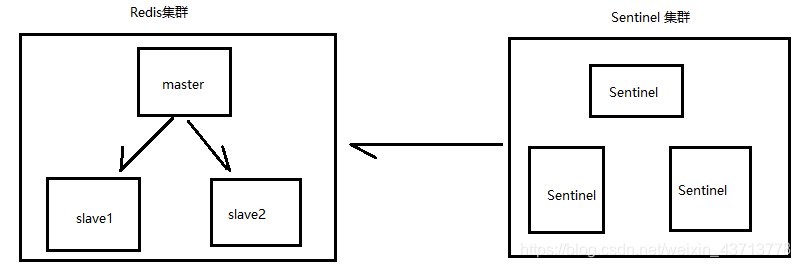
如果 Redis 要实现高可用,首先需要实现读写分离,为了避免读写分离中出现的 master 挂掉导致 redis 不可用。需要使用 哨兵机制(Sentinel )配合。来达到 master 挂掉后再从 slave 中选取一个作为主节点。此时还要再考虑一个问题,如果 Sentinel 为单节点,也挂掉了,那不就又会造成服务不同啊,所以 Sentinel 也要搭建集群。需要注意的是,redis 与 Sentinel 都要最少三个节点
主从复制原理
主从全量复制大致流程图:
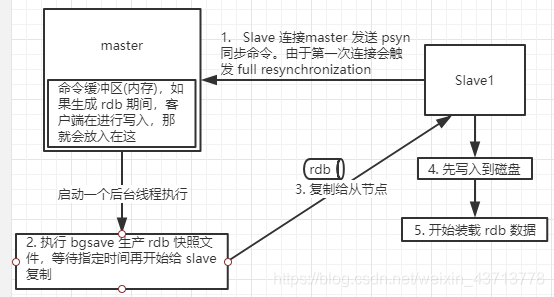
细节点的流程说明:
- slave 启动时候,就只是保存了 master 的信息包括 host 和 ip,但是复制的流程还没有开始
- slave 内部有个定时任务,每秒检查是有新的 master 要连接 和 复制,如果有就跟 master 建立 scoket 网络连接
- slave 给 master 节点发送 ping 命令,然后进行口令认证(如果有)
- 如果第一个连接到 master 就会触发 full resynchronization
- master 会启动一个后台线程执行 bgsave 命令生产 rdb 文件,然后再发给 slave
- slave 收到快照文件后,先写到磁盘。然后再装在 rdb 数据
在认识到复制过程后,再引入 2 个概念配置
无磁盘化复制
针对上图第 2 步时候,生产 rdb 时,可以在配置文件中指定生成 rdb 时候,是在内存中生成然后直接发送,还是先保存到磁盘中然后在发送过去。通过如下配置:
repl-diskless-sync:
no:会开启一个线程,在内存中生成 rdb
yes:子进程生成 rdb,然后落到磁盘,再发给slave
repl-diskless-sync-delay:等待多时秒后开始给 slave 发送rdb文件,设置这个时间因为,好不容易生成一个 rdb,要等待更多的 salve 重新连接后再复制过去(上图第2步时候,为什么说等待指定时间再给 slave)
内存缓冲区超出
继续看第 2 步,在生成 rdb 快照的过程中,客户端新来的 写命令 都会写到内存缓冲区中,客户端有2种情况会直接将将缓冲区写满(配合文件中设置),导致复制失败。默认为如下:
- 60s 内缓冲区大小一直超过 64m
- 或者内存缓冲区突然暴涨,超过了 256 m。
修改配置内容如下,需要根据实际情况配置:
client-output-buffer-limit slave 256MB 64MB 60
端点续传
上面是第一次时候复制说明会进行全量复制,如果要是主从突然断开了,然后又重新连接上了,这个时候该怎么同步怎?这里就要明白断点续传的原理了,在 redis 2.8 之前使用的是同步(sync) 之后就是命令传播方式(command propagate)
同步(sync)
这种方式性能不是太好,原理比较简单,基本类似于上面全量同步,就是在重新连接后,发送一个全量的 rdb 快照。假如在断开时候, master 就收到 2 个写命令,那这个时候如果弄一个全量的 rdb 文件发过去,那就太 2 了。而且这样代价也非常大。
- master 生成 rdb 会耗费服务器大量的 CPU、内存和磁盘IO
- master 发给 slave 时候会产生大量网络 IO
- slave 在载入 rdb 文件时候会阻塞处理命令的请求
命令传播方式(command propagate)
这里主要说明下命令传播方式,在了解命令传播方式时候,需要明白 3 个概念:
复制偏移量 (replication offset)
执行复制的双方(主、从)两端都会维护一个复制偏移量,从服务器在连接的时候,将 offset 发送过去,以此来判断这个从服务器是否与 master 数据一直,那么说了那么多,这个偏移量到底是啥玩意呢?如下图:

客户端发送添加命令 set key ‘a’,假设 ‘a’ 就 2 个字节,此时 master 的就是偏移量就等于 offset = 2,然后再向从服务器去发送 2 个字节,从服务器同步完后在此时偏移量为 2。