2021年的车道线检测新方法。
官方公开视频、论文、源码:
https://www.bilibili.com/video/BV1664y1o7wg
https://arxiv.org/abs/2008.13719
https://github.com/ZJULearning/resa
(该视频对现有车道线检测方法进行了分类、归纳总结,很完善。建议食用)
基于深度学习的车道线检测方法可分为如下几类:
- 实例分隔。例:LaneNet
- 语义分隔。例:SCNN
- 网格化。
- 多项式。
- 基于Anchor。
本方法是延续了SCNN的思路。将车道线检测当作语义分隔问题来处理的。
摘要
为什么通用场景下的语义分隔方法在车道线检测时不适用?
- 严重的遮挡、磨损的车道线
- 车道线标注的内在稀疏性(相较于图像中其他像素很稀疏)
而本文所述方法(RESA: Recurrent Feature-Shift Aggregator for Lane Detection)可以使用普通CNN提取初步特征后丰富车道特征。
RESA利用了车道线的强形状先验信息和捕获了像素间跨行、列的空间信息。
它将特征图的切片在垂直和水平方向上反复移动,并使每个像素都能收集全局信息。
提出了一种双向上采样解码器,在上采样阶段结合了粗粒度和细粒度特征。 它可以将低分辨率特征图细化为像素级预测。
在CULane和Tusimple数据集上进行了验证。
引言
车道线检测很重要,但是现有挑战也很多。
将车道线检测作为语义分割问题的一般形式:这些方法通过编码器-解码器框架解决了该问题。 他们首先使用CNN作为编码器,将语义信息提取到特征图中,然后使用上采样解码器将特征图恢复到其原始大小,最后执行逐像素预测。
但这些方法的问题如下:由于车道线的稀薄和长属性,带注释的通道像素的数量远远少于背景像素。(类别不均衡) 这些方法通常难以提取微妙的车道特征,并且可能会忽略先验的强形状或车道之间的高度相关性,从而导致检测性能较差。
但遮挡严重时,我们只能用常识去推断车道线。因此,普通CNN提取的低质量特征往往会忽略掉微妙的车道特征。
SCNN提出空间卷积的特征,尝试在特征图中的相邻行或列之间传递信息。然而,这种类似于RNN的架构是耗时的。同时,在相邻行或列之间顺序传递信息需要进行多次迭代,并且在长距离传播期间信息可能会丢失。
本文的RESA在特征图中收集信息,并更直接,更有效地传递空间信息。如图1所示,RESA可以通过循环地移动特征图的切片来垂直和水平地聚合信息。RESA将首先在垂直和水平方向上对特征图进行切片,然后使每个切片的特征接收与某个跨度相邻的另一个切片的要素。 每个像素分几步同时更新,最终每个位置都可以在整个空间中收集信息。这样,信息可以在特征图中的像素之间传播。

- 信息并行传递,时间消耗低。
- stride设置不同,在传播过程中,不同特征图的切片可以聚合到一起而没有信息损失。
- 该模块可简单并入其他网络中。
本文还提出了 the Bilateral Up-Sampling Decoder (BUSD),双边上采样解码器。BUSD有两个分支:一个分支用于捕获粗粒度特征,另一分支是捕获细细节特征。粗支路直接应用双线性上采样并产生模糊图像。相比之下,细分支通过转置卷积实现上采样,然后是两个non-bottleneck模块以修复细微的损失。 结合两个分支,我们的解码器可以将低分辨率特征图精确地恢复为逐像素预测。
相关工作
车道线检测
两类:传统方法和基于深度学习的方法。
传统方法优缺点无需再说。
基于深度学习的方法在上述视频中大体提到。还有一个FastDraw方法可以学一下。
利用空间信息
在神经网络中利用空间信息的一些尝试:
spatial Recurrent Neural Networks (RNNs):这些RNN在图像上水平和垂直传递空间变化的上下文信息。
Graph LSTM:为语义对象解析提供信息传播途径。
SCNN:将传统的逐层卷积泛化为特征图中的逐片卷积,从而使消息能够在同一层的行和列之间的像素之间传递。SCNN将消息作为残差进行传播,并且比以前的工作更易于训练,但是在远距离传播过程中仍然遭受昂贵的计算和信息丢失的困扰。
RESA:比SCNN具有更高的计算效率,同时可以以不同的步幅从切片特征中收集信息以避免信息丢失。
方法
网络架构
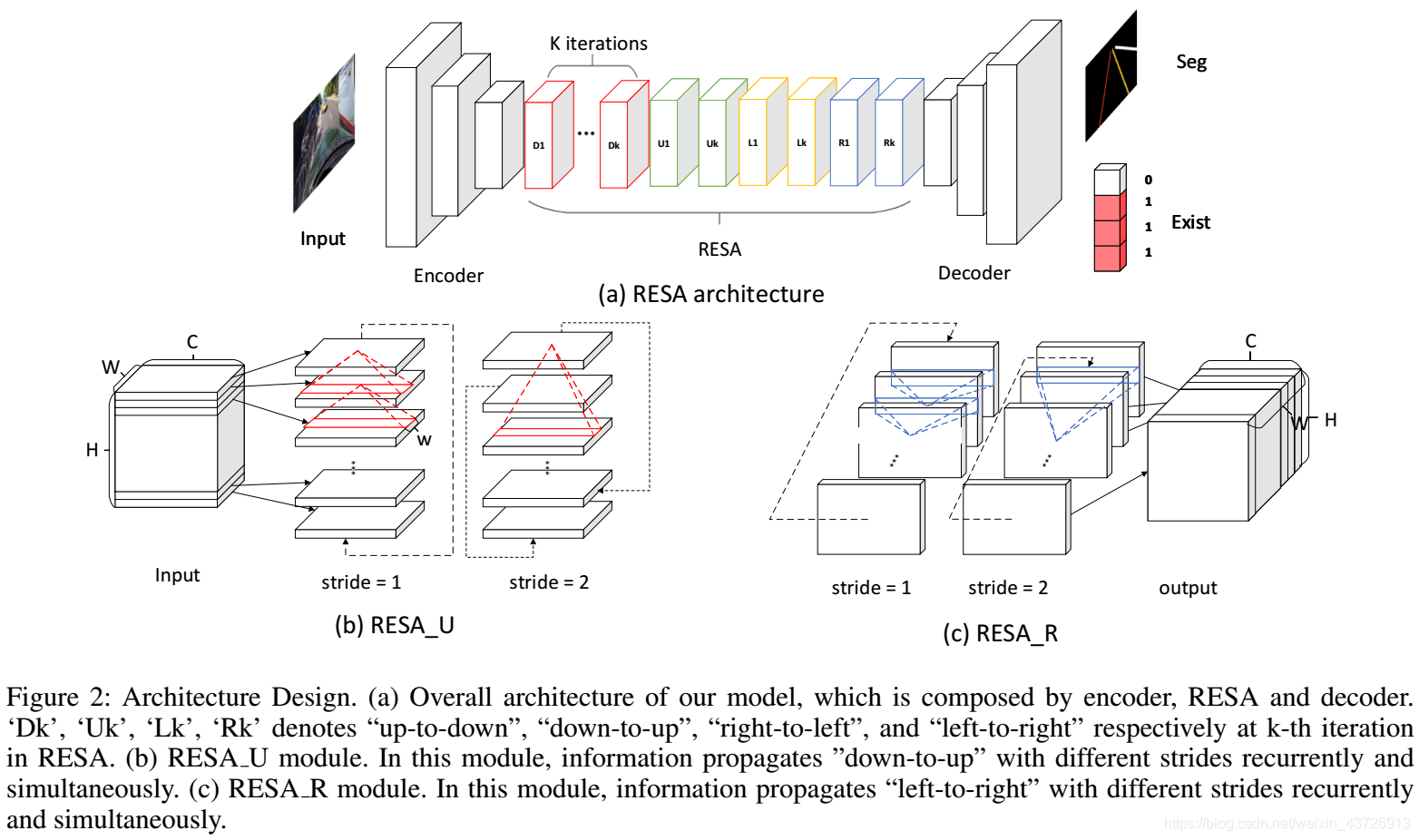
如图2(a)所示。三个组件:编码器、聚合器、解码器。
- 编码器:骨架网络(VGG、ResNet等),用于提取特征。原始图片会变成1/8尺寸的特征图。
- RESA:收集空间特征。在每次迭代中,特征图的切片都会在4个方向上反复移动,并在垂直和水平方向传递信息。 最后,RESA需要进行K次迭代,以确保每个位置都可以接收整个特征图中的信息。
- 解码器:双向上采样模块。每个块两次上采样,最后将1/8特征图恢复到原始大小。 双向上采样解码器由粗粒度分支和细粒度分支组成。
经过解码器上采样后,输出特征图将用于预测每个车道的存在和概率分布。 紧随其后的是全连接层以进行存在预测,并将执行二进制分类。 将针对车道概率分布预测进行逐像素预测,这与语义分割任务相同。
RESA
假设有一个3D特征图向量X的尺寸C x H x W(通道数、行数、列数)。
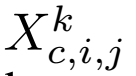
RESA的进一步计算定义如下:
其中,
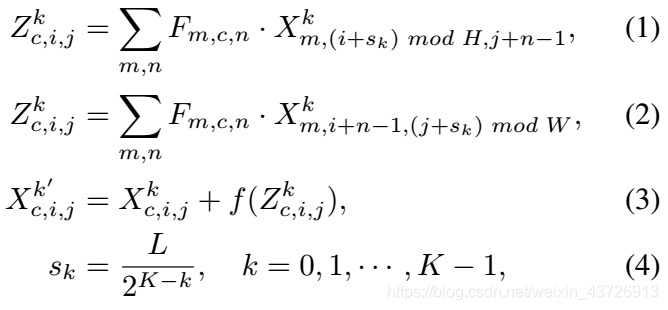

k是迭代次数;L代表等式1和2中的W和H。
f:非线性激活函数。RELU。
带有下标’的X:更新后的元素
sk:第k次迭代中的步长。(由迭代次数k决定,使得信息传递距离是动态的。)
等式1和2分别展示了垂直和水平方向的信息传递公式。
F:一组一维卷积。尺寸是
Nin:输入通道数
Nout:输出通道数
w:卷积核宽度
Nin和Nout都等于C。
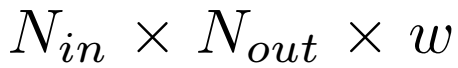
等式1和2中的Z是信息传递的立即结果。
正如图2(b)和图2(c)中所示,特征图X在水平方向被分为H个切片,在垂直方向被分为W个切片。
我们仅通过索引计算即可实现递归特征转换信息的传递,而无需其他复杂的操作。
信息传递有4个方向(见图2)。具有相同偏移步长的卷积层权重在相同方向上的所有切片上共享。
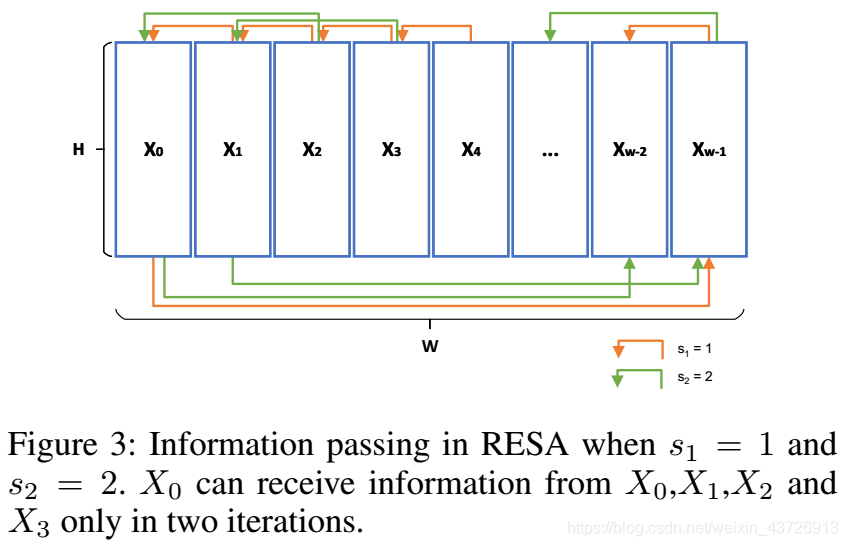
以“右到左”信息传递为例:如图3所示,
在k=0次迭代,s1=1;每一列的Xi可以接收到Xi+1的转换特征。由于反复移动,尾部的列也可以接收另一侧的特征。(即Xw-1可接收X0的转换特征。)
在k=1次迭代,s2=2;每一列的Xi可以接收到Xi+2的转换特征。
以X0为例,X0在第二次迭代中接收X2的信息,考虑到X0已经接收了X1的信息(在第一次迭代中);并且X2也接收了X3的信息(第一次迭代中);现在X0在两次迭代中便接收了X0、X1、X2、X3的信息。
下一次迭代类似上述过程。
在所有K次迭代之后,当最终k = K时,每个Xi都可以在整个特征图中聚合信息。
分析
RESA在4个方向上循环应用特征转换操作,并使每个位置都可以感知和聚合同一特征图中的所有空间信息。 车道检测是一项高度依赖周围线索的任务。 例如,一个车道被多辆汽车遮挡,但是我们仍然可以从其他车道,汽车方向,道路形状或其他视觉线索中推断出它。
RESA优点如下:
- 计算效率高。传统信息传递方法(马尔科夫随机场/条件随机场)是一种全连接的方式,计算密集且冗余。SCNN方法是一种类似于RNN的结构,复杂度随着空间大小的增加而线性增加,并且顺序传播不能充分利用计算资源。而RESA的复杂度是空间尺寸的log级别,每次迭代中,所有位置以并行方式进行更新,在
次迭代后,每个位置可以聚合来自整个特征图的空间信息。
- 特征信息聚合高效。每个位置可以聚合来自整个特征图的空间信息,且此过程没有信息损失。如图5所示,由于SCNN仅将特征信息传递给相邻的元素,并且在传播过程中丢失信息,因此RESA的性能比SCNN更好。
- 易于组合到其他网络中。1.实现很简单,只需要在特征图中进行索引操作即可。2.不会更改输入特征图的形状(理想的位置是在提取特征CNN之后,如VGG、ResNet、MobileNet)。3.计算时间几乎可被忽略。
双向上采样解码器
上采样特征图到输入尺寸。大多数解码器利用双线性上采样(bilinear upsampling)过程来恢复最终的逐像素预测,这很容易获得粗略结果,但可能会丢失细节。一些方法使用堆叠卷积运算和反卷积运算来获得精确的上采样结果。我们组合他们,得到双向上采样解码器(Bilateral Up-Sampling Decoder ,BUSD)。解码器由两个分支组成,一个分支是恢复粗粒度特征,另一个是修复细微的损耗。如图4所示,输入将通过两个分支,并且将产生通道数量减半的2x上采样输出。 通过这些堆叠的解码器块后,RESA生成的1/8特征图将恢复为与输入图像相同的大小。
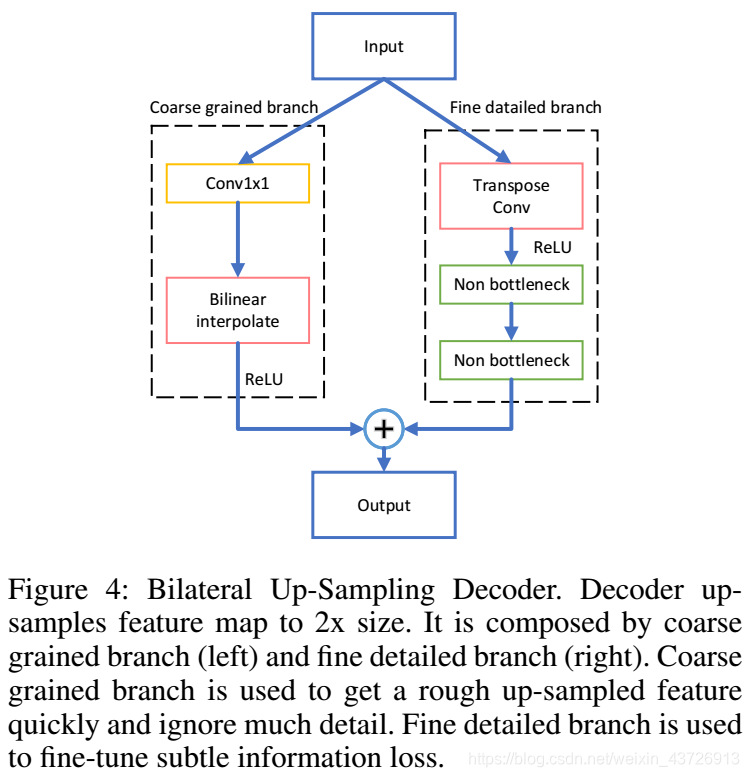
粗粒度分支
粗粒度分支将从最后一层快速输出粗略向上采样的特征,这可能会忽略细节。设计了一条简单而浅的路径。 我们首先应用1×1卷积来减少
通道数乘以输入特征图的2倍,然后是BN。 双线性插值直接用于对输入特征图进行上采样。 最后,执行ReLU。
(关于一些细节,还是要结合代码来看)
细粒度分支
细细节分支用于微调来自粗粒度分支的信息丢失,并且路径比另一个更深。 我们使用步幅为2的转置卷积对特征图进行上采样,并同时将通道数减少2倍。 与粗粒度分支中使用的类似设计一样,对ReLU进行上采样。 Non-bottleneck块由具有BN和ReLU的四个3×1和1×3卷积组成,可以保持特征图的形状并以分解的方式有效地提取信息。 在上采样操作之后,我们堆叠了两个non-bottleneck。
实验
数据集
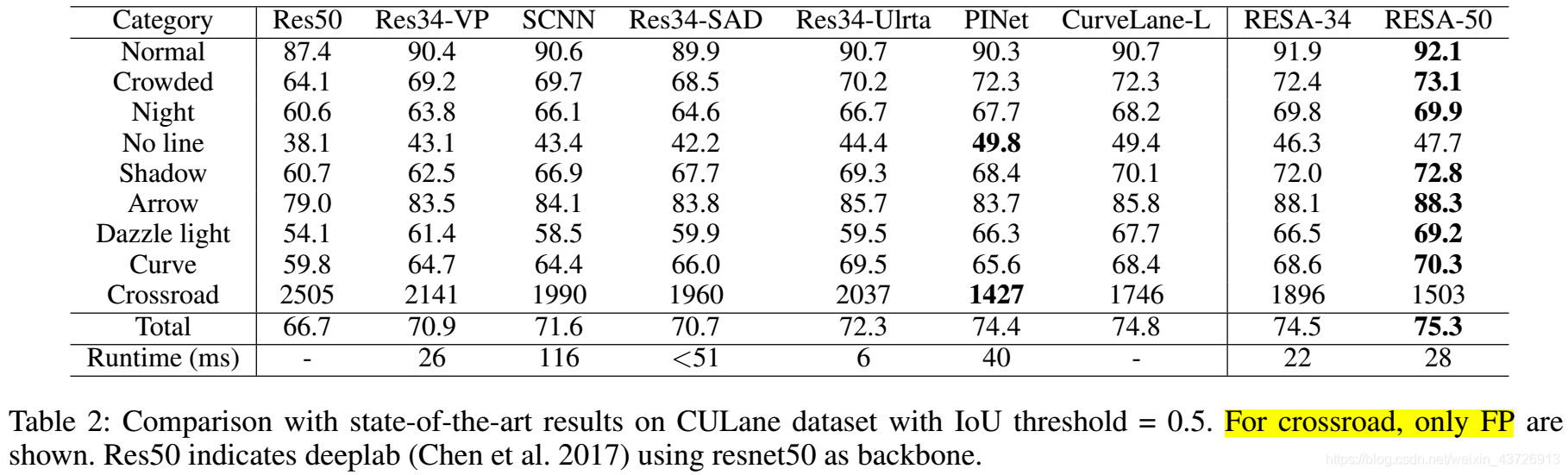
包含TuSimple和CULane两个数据集。TuSimple可参考我的介绍,场景十分简单,只包含高速公路下稳定的光照情况。CULane数据集包含场景复杂些,有55小时,包含9种不同场景,包括市区中的正常人群,人群,弯道,夜晚,夜晚,无线和箭头等。

CULane
每条车道线被理解为30像素宽的线。计算预测和真值的IoU。预测车道线的IoU**大于阈值(0.5)**被认为是 true positives (TP)。
F1-measure同样作为评价指标,计算公式如下:
其中,
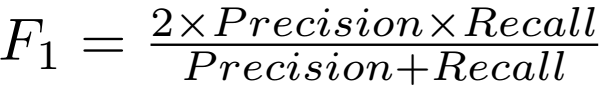
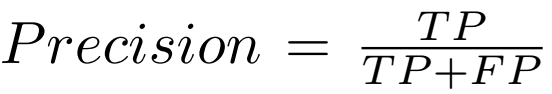
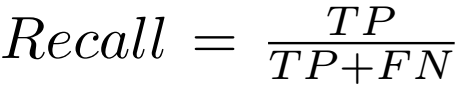
FP和FN分别代表false positive 和 false negative。
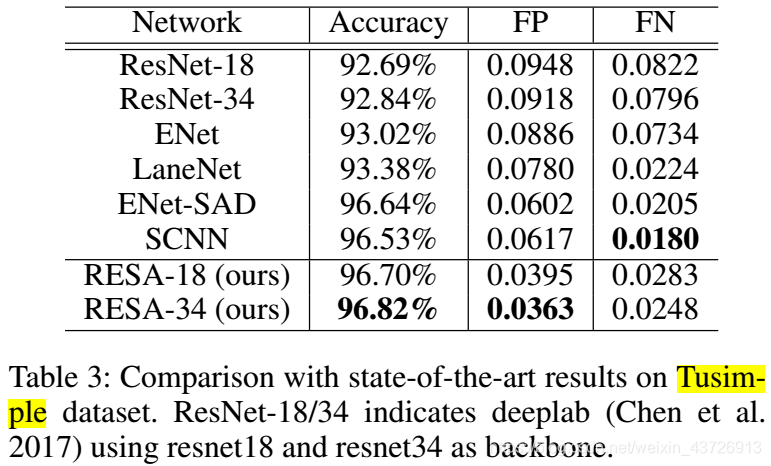
Tusimple
评价指标是准确率,定义如下。
其中,
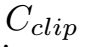
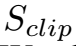
同样也计算FP和FN。
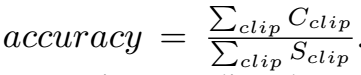
参数的设置
类似于SAD(自蒸馏)那篇论文,我们首先将原始图像进行resize:288 × 800 for CULane and 368 × 640 for Tusimple。
SGD:momentum 0.9,weight decay 1e-4
learning rate: 2.5e-2 for CULane; 2.0e-2 for Tusimple
我们在前500batches中使用warmup策略,然后应用多项式学习率衰减策略,将power设置为0.9。
损失函数:与SCNN类似。采用segmentation BCE 损失 和 existence classification CE 损失。(考虑到背景和车道线的类别不均衡,背景的segmentation损失的权重为0.4。
batch size:CULane是8 ;Tusimple是4。
TuSimple数据集的训练epoch总数设置为50,而CULane数据集的训练epoch总数设置为12。
Ubuntu下,4个NVIDIA 2080Ti GPU(11G内存)进行训练;Pytorch1.1。
使用ResNet和VGG作为骨架网络;在ResNet中,我们添加了额外的1×1卷积以将输出通道减少到128。VGG的修改与SCNN相同。
主要结果

消融实验
每个组件的影响
baseline:选择ResNet-34作为backbone网络,从主干中提取特征图后,就像SCNN一样,使用双线性插值直接对特征图进行8倍采样。输出作为回归问题,并最终获得每个车道线的概率分布。
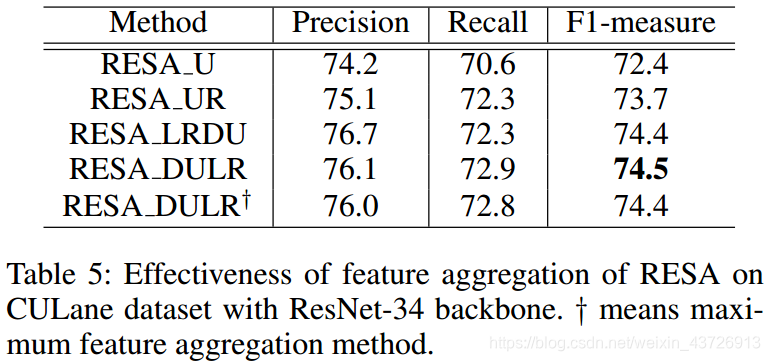
我们用双边上采样解码器代替双线性插值,然后逐步在主干和解码器之间插入RESA。如表4所示。

特征聚合的有效性
RESA方向的影响。
RESA迭代次数
从理论上讲,随着迭代的增加,特征图的每个切片都可以聚合更多的信息,从而有助于获得更好的性能。但是,更多的迭代会导致更多的计算时间成本。 这是性能和计算资源之间的折衷方案。 为了在两者之间取得平衡,我们选择迭代= 4作为最终选择。

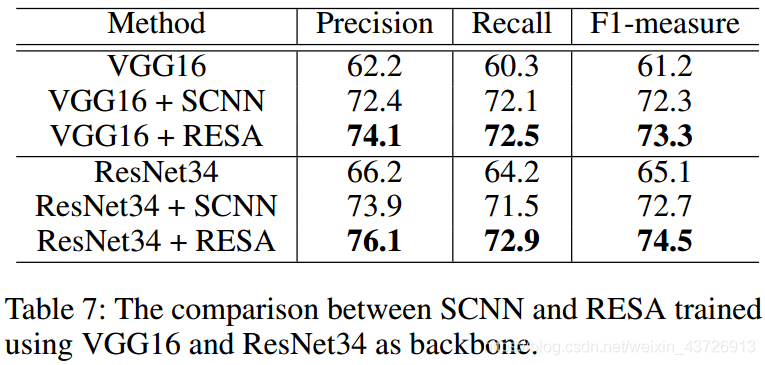
RESA和SCNN的比较
SCNN已经表明,消息传递方案可以提高车道检测性能,但是更多的参数只会带来很小的改进。 因此,我们将RESA与SCNN进行了比较,以验证我们方法的有效性。
计算效率
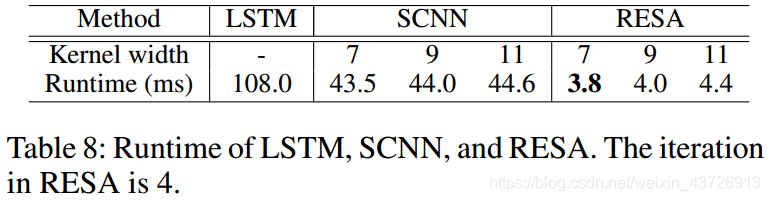
我们还进行了实验,以比较我们的方法与LSTM,SCNN的运行时间。 这些方法的运行时间记录为1000次运行的平均时间。 我们使用不同的卷积核宽度(7、9、11)来比较效率。 SCNN以顺序的方式传播信息,即,一个分片直到从上一个分片接收到信息后才将信息传递给下一个分片。 因此,由于顺序计算,这种消息传递需要大量的计算成本。 相反,我们的RESA以并行方式传递信息。
代码解读
准备阶段
- 克隆RESA仓库
git clone https://github.com/zjulearning/resa.git
此目录标记为$RESA_ROOT。
- 创建一个conda虚拟环境并激活它(conda是可选的)
conda create -n resa python=3.8 -y
conda activate resa
- 安装依赖
#首先安装pytorch,您的系统中的cudatoolkit版本应该相同。 (您也可以使用pip安装pytorch和torchvision)
conda install pytorch torchvision cudatoolkit=10.1 -c pytorch
#也可以通过pip工具安装
pip install torch torchvision
#安装python包
pip install -r requirements.txt
- 数据准备
下载CULane和Tusimple。 然后将它们提取到$ CULANEROOT和$ TUSIMPLEROOT。 创建到data目录的链接。
cd $RESA_ROOT
mkdir -p data
ln -s $CULANEROOT data/CULane
ln -s $TUSIMPLEROOT data/tusimple
对于CULane,您应具有以下结构:
$CULANEROOT/driver_xx_xxframe # data folders x6
$CULANEROOT/laneseg_label_w16 # lane segmentation labels
$CULANEROOT/list # data lists
对于Tusimple,您应具有以下结构:
$TUSIMPLEROOT/clips # 数据文件夹
$TUSIMPLEROOT/lable_data_xxxx.json # 这里说有4个这样的json文件,我重新下载了一下数据集,发现还是3个
$TUSIMPLEROOT/test_tasks_0627.json # 测试任务的json文件
$TUSIMPLEROOT/test_label.json # 测试标签json文件
对于Tusimple,未提供语义标注信息,因此我们需要根据json标注生成语义信息。
python scripts/generate_seg_tusimple.py --root $TUSIMPLEROOT
#这将产生语义标签
(这里好像是在tools文件夹下,即应:
python tools/generate_seg_tusimple.py --root $TUSIMPLEROOT )
- 安装CULane评价工具
此工具需要OpenCV C ++。 请按照此处安装OpenCV C ++。 或者只是使用命令sudo apt-get install libopencv-dev安装opencv。
然后编译CULane的评估工具。
cd $RESA_ROOT/runner/evaluator/culane/lane_evaluation
make
cd -
请注意,默认的opencv版本是3。如果使用opencv2,请在Makefile中将OPENCV_VERSION:= 3修改为OPENCV_VERSION:= 2。
训练
运行如下脚本:
python main.py [configs/path_to_your_config] --gpus [gpu_ids]
例如:
python main.py configs/culane.py --gpus 0 1 2 3
测试
运行如下脚本:
python main.py c[configs/path_to_your_config] --validate --load_from [path_to_your_model] [gpu_num]
例如:
python main.py configs/culane.py --validate --load_from culane_resnet50.pth --gpus 0 1 2 3
python main.py configs/tusimple.py --validate --load_from tusimple_resnet34.pth --gpus 0 1 2 3
我们在CULane和Tusimple数据集上提供了两个经过训练的ResNet模型。
下载性能最佳的模型(Tusimple:GoogleDrive / BaiduDrive(code:s5ii),CULane:GoogleDrive / BaiduDrive(code:rlwj))
(Google那个好像需要权限什么的,百度云盘还是可以的。)
引用信息
@misc{zheng2020resa,
title={RESA: Recurrent Feature-Shift Aggregator for Lane Detection},
author={Tu Zheng and Hao Fang and Yi Zhang and Wenjian Tang and Zheng Yang and Haifeng Liu and Deng Cai},
year={2020},
eprint={2008.13719},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
代码解读
于tusimple数据集
数据准备里面第4步的最后一个操作。
python tools/generate_seg_tusimple.py --root $TUSIMPLEROOT
该代码解读如下:
import json
import numpy as np
import cv2
import os
import argparse
TRAIN_SET = ['label_data_0313.json', 'label_data_0601.json']
VAL_SET = ['label_data_0531.json']
TRAIN_VAL_SET = TRAIN_SET + VAL_SET
TEST_SET = ['test_label.json']
def gen_label_for_json(args, image_set):
H, W = 720, 1280
SEG_WIDTH = 30
save_dir = args.savedir
os.makedirs(os.path.join(args.root, args.savedir, "list"), exist_ok=True)
list_f = open(os.path.join(args.root, args.savedir, "list", "{}_gt.txt".format(image_set)), "w")
json_path = os.path.join(args.root, args.savedir, "{}.json".format(image_set))
with open(json_path) as f:
for line in f:
label = json.loads(line)
# ---------- clean and sort lanes -------------
lanes = []
_lanes = []
slope = [] # identify 0th, 1st, 2nd, 3rd, 4th, 5th lane through slope
for i in range(len(label['lanes'])):
l = [(x, y) for x, y in zip(label['lanes'][i], label['h_samples']) if x >= 0] # 一条有效的车道线的点
if (len(l)>1):
_lanes.append(l)
slope.append(np.arctan2(l[-1][1]-l[0][1], l[0][0]-l[-1][0]) / np.pi * 180) # 计算角度
_lanes = [_lanes[i] for i in np.argsort(slope)] # np.argsort:排序,输出索引。https://blog.csdn.net/qq_38486203/article/details/80967696
slope = [slope[i] for i in np.argsort(slope)] # 这里是对车道线排序
idx = [None for i in range(6)]
for i in range(len(slope)):
if slope[i] <= 90:
idx[2] = i
idx[1] = i-1 if i > 0 else None
idx[0] = i-2 if i > 1 else None
else:
idx[3] = i
idx[4] = i+1 if i+1 < len(slope) else None
idx[5] = i+2 if i+2 < len(slope) else None
break
for i in range(6):
lanes.append([] if idx[i] is None else _lanes[idx[i]])
# ---------------------------------------------
img_path = label['raw_file']
seg_img = np.zeros((H, W, 3))
list_str = [] # str to be written to list.txt
for i in range(len(lanes)):
coords = lanes[i]
if len(coords) < 4:
list_str.append('0')
continue
for j in range(len(coords)-1):
cv2.line(seg_img, coords[j], coords[j+1], (i+1, i+1, i+1), SEG_WIDTH//2)
list_str.append('1')
seg_path = img_path.split("/")
seg_path, img_name = os.path.join(args.root, args.savedir, seg_path[1], seg_path[2]), seg_path[3]
os.makedirs(seg_path, exist_ok=True)
seg_path = os.path.join(seg_path, img_name[:-3]+"png")
cv2.imwrite(seg_path, seg_img)
seg_path = "/".join([args.savedir, *img_path.split("/")[1:3], img_name[:-3]+"png"])
if seg_path[0] != '/':
seg_path = '/' + seg_path
if img_path[0] != '/':
img_path = '/' + img_path
list_str.insert(0, seg_path)
list_str.insert(0, img_path)
list_str = " ".join(list_str) + "\n"
list_f.write(list_str)
def generate_json_file(save_dir, json_file, image_set):
with open(os.path.join(save_dir, json_file), "w") as outfile:
for json_name in (image_set):
with open(os.path.join(args.root, json_name)) as infile:
for line in infile:
outfile.write(line)
def generate_label(args):
save_dir = os.path.join(args.root, args.savedir)
os.makedirs(save_dir, exist_ok=True)
generate_json_file(save_dir, "train_val.json", TRAIN_VAL_SET)
generate_json_file(save_dir, "test.json", TEST_SET)
print("generating train_val set...")
gen_label_for_json(args, 'train_val')
print("generating test set...")
gen_label_for_json(args, 'test')
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--root', required=True, help='The root of the Tusimple dataset')
parser.add_argument('--savedir', type=str, default='seg_label', help='The root of the Tusimple dataset')
args = parser.parse_args()
generate_label(args)
该文件就是生成了语义标注信息。
测试
跑代码会报如下错误。
.local/lib/python3.8/site-packages/torch/cuda/init.py:104: UserWarning:
GeForce RTX 3060 Ti with CUDA capability sm_86 is not compatible with the current PyTorch installation.
The current PyTorch install supports CUDA capabilities sm_37 sm_50 sm_60 sm_70 sm_75.
If you want to use the GeForce RTX 3060 Ti GPU with PyTorch, please check the instructions at https://pytorch.org/get-started/locally/
warnings.warn(incompatible_device_warn.format(device_name, capability, " ".join(arch_list), device_name))
原因如下:
30 系列显卡是新一代架构,新驱动不支持 cuda 9 以及 cuda 10,所以必须安装 cuda 11。
因此要使用-nightly来重新安装pytorch。
详见:
https://blog.csdn.net/weixin_43896241/article/details/108979744
import os
import os.path as osp
import time
import shutil
import torch
import torchvision # 针对这里出现的ModuleNotFoundError: No module named 'torchvision'。
# 解决方案:https://github.com/pytorch/pytorch/issues/12525
# conda install torchvision -c pytorch
import torch.nn.parallel
import torch.backends.cudnn as cudnn
import torch.nn.functional as F
import torch.optim
import cv2
import numpy as np
import models
import argparse
from utils.config import Config
from runner.runner import Runner
from datasets import build_dataloader
def main():
args = parse_args()
os.environ["CUDA_VISIBLE_DEVICES"] = ','.join(str(gpu) for gpu in args.gpus)
cfg = Config.fromfile(args.config) # 生成了配置文件
cfg.gpus = len(args.gpus) # 关于__getattr__和__setattr__:https://blog.csdn.net/weixin_42233629/article/details/85723073
cfg.load_from = args.load_from
cfg.finetune_from = args.finetune_from
cfg.work_dirs = args.work_dirs + '/' + cfg.dataset.train.type # cfg.dataset.train.type:会多次调用魔术方法。
cudnn.benchmark = True # 增加程序的运行效率。https://blog.csdn.net/Ibelievesunshine/article/details/99471258
cudnn.fastest = True #
runner = Runner(cfg)
if args.validate:
val_loader = build_dataloader(cfg.dataset.val, cfg, is_train=False)
runner.validate(val_loader)
else:
runner.train()
def parse_args():
parser = argparse.ArgumentParser(description='Train a detector')
parser.add_argument('config', help='train config file path') # 位置参数。表示这个位置一定要这个文件。https://docs.python.org/zh-cn/3/library/argparse.html?highlight=add_argument#argparse.ArgumentParser.add_argument
parser.add_argument(
'--work_dirs', type=str, default='work_dirs',
help='work dirs')
parser.add_argument(
'--load_from', default=None,
help='the checkpoint file to resume from')
parser.add_argument(
'--finetune_from', default=None,
help='whether to finetune from the checkpoint')
parser.add_argument(
'--validate',
action='store_true',
help='whether to evaluate the checkpoint during training') # 关于action参数:
# 如果是store_true,那么命令行不输入次参数时是False;输入时是True
# 如果是store_false,那么命令行不输入次参数时是Ture;输入时是False
# (即输入时不变,不输入时取反)
parser.add_argument('--gpus', nargs='+', type=int, default='0') # nargs=' '+' 表示参数可设置一个或多个
parser.add_argument('--seed', type=int,
default=None, help='random seed')
args = parser.parse_args()
return args
if __name__ == '__main__':
main()
main.py文件导入的'configs/tusimple.py'如下:
net = dict(
type='RESANet',
)
backbone = dict(
type='ResNetWrapper',
resnet='resnet34',
pretrained=True,
replace_stride_with_dilation=[False, True, True],
out_conv=True,
fea_stride=8,
)
resa = dict(
type='RESA',
alpha=2.0,
iter=5,
input_channel=128,
conv_stride=9,
)
decoder = 'BUSD'
trainer = dict(
type='RESA'
)
evaluator = dict(
type='Tusimple',
thresh = 0.60
)
optimizer = dict(
type='sgd',
lr=0.020,
weight_decay=1e-4,
momentum=0.9
)
total_iter = 80000
import math
scheduler = dict(
type = 'LambdaLR',
lr_lambda = lambda _iter : math.pow(1 - _iter/total_iter, 0.9)
)
bg_weight = 0.4
img_norm = dict(
mean=[103.939, 116.779, 123.68],
std=[1., 1., 1.]
)
img_height = 368
img_width = 640
cut_height = 160
seg_label = "seg_label"
dataset_path = './data/tusimple'
test_json_file = './data/tusimple/test_label.json'
dataset = dict(
train=dict(
type='TuSimple',
img_path=dataset_path,
data_list='train_val_gt.txt',
),
val=dict(
type='TuSimple',
img_path=dataset_path,
data_list='test_gt.txt'
),
test=dict(
type='TuSimple',
img_path=dataset_path,
data_list='test_gt.txt'
)
)
loss_type = 'cross_entropy'
seg_loss_weight = 1.0
batch_size = 4
workers = 12
num_classes = 6 + 1
ignore_label = 255
epochs = 300
log_interval = 100
eval_ep = 1
save_ep = epochs
log_note = ''
main.py文件from utils.config import Config解读如下:
# Copyright (c) Open-MMLab. All rights reserved.
import ast
import os.path as osp
import shutil
import sys
import tempfile
from argparse import Action, ArgumentParser
from collections import abc
from importlib import import_module
from addict import Dict
from yapf.yapflib.yapf_api import FormatCode
BASE_KEY = '_base_'
DELETE_KEY = '_delete_'
RESERVED_KEYS = ['filename', 'text', 'pretty_text']
def check_file_exist(filename, msg_tmpl='file "{}" does not exist'):
if not osp.isfile(filename):
raise FileNotFoundError(msg_tmpl.format(filename))
class ConfigDict(Dict):
def __missing__(self, name): # 关于此魔术方法https://blog.csdn.net/qq_43168521/article/details/103150464。https://www.cnblogs.com/geeklove01/p/8747653.html。还是不太懂。。。
raise KeyError(name)
def __getattr__(self, name):
try:
value = super(ConfigDict, self).__getattr__(name)
except KeyError:
ex = AttributeError(f"'{self.__class__.__name__}' object has no "
f"attribute '{name}'")
except Exception as e:
ex = e
else:
return value
raise ex
def add_args(parser, cfg, prefix=''):
for k, v in cfg.items():
if isinstance(v, str):
parser.add_argument('--' + prefix + k)
elif isinstance(v, int):
parser.add_argument('--' + prefix + k, type=int)
elif isinstance(v, float):
parser.add_argument('--' + prefix + k, type=float)
elif isinstance(v, bool):
parser.add_argument('--' + prefix + k, action='store_true')
elif isinstance(v, dict):
add_args(parser, v, prefix + k + '.')
elif isinstance(v, abc.Iterable):
parser.add_argument('--' + prefix + k, type=type(v[0]), nargs='+')
else:
print(f'cannot parse key {prefix + k} of type {type(v)}')
return parser
class Config:
"""A facility for config and config files.
It supports common file formats as configs: python/json/yaml. The interface
is the same as a dict object and also allows access config values as
attributes.
Example:
>>> cfg = Config(dict(a=1, b=dict(b1=[0, 1])))
>>> cfg.a
1
>>> cfg.b
{'b1': [0, 1]}
>>> cfg.b.b1
[0, 1]
>>> cfg = Config.fromfile('tests/data/config/a.py')
>>> cfg.filename
"/home/kchen/projects/mmcv/tests/data/config/a.py"
>>> cfg.item4
'test'
>>> cfg
"Config [path: /home/kchen/projects/mmcv/tests/data/config/a.py]: "
"{'item1': [1, 2], 'item2': {'a': 0}, 'item3': True, 'item4': 'test'}"
"""
# 上面的注释的意思呢,就是说
# 用于配置和配置文件的工具。
# 它支持常见的文件格式作为config,如:python/json/yaml。
# 该接口与dict对象相同,还允许将配置值作为属性访问。
@staticmethod
def _validate_py_syntax(filename):
with open(filename) as f:
content = f.read() # 读取配置文件configs/tusimple.py中的内容
try:
ast.parse(content) # 把源码解析为AST节点。
except SyntaxError:
raise SyntaxError('There are syntax errors in config '
f'file {filename}')
@staticmethod
def _file2dict(filename):
filename = osp.abspath(osp.expanduser(filename)) # osp.expanduser:在linux下面,一般如果你自己使用系统的时候,是可以用~来代表"/home/你的名字/"这个路径的.但是python是不认识~这个符号的,如果你写路径的时候直接写"~/balabala",程序是跑不动的.所以如果你要用~,你就应该用这个os.path.expanduser把~展开.https://www.zhihu.com/question/48161511
# osp.abspath:获取当前脚本的完整路径。https://blog.csdn.net/liuskyter/article/details/99936955
check_file_exist(filename)
if filename.endswith('.py'): # 检查字符串是否以标点符号 ('.py') 结尾: https://www.w3school.com.cn/python/ref_string_endswith.asp
with tempfile.TemporaryDirectory() as temp_config_dir: # tempfile:本模块主要提供了产生临时文件或临时目录,支持所有操作系统平台。创建临时文件时,不再使用进程ID来命名,而使用6位随机字符串进行命名。
# tempfile.TemporaryDirectory():官方文档:创建并返回一个临时目录。这与mkdtemp具有相同的行为,但可以用作上下文管理器。退出上下文后,该目录及其包含的所有内容都将被删除。
temp_config_file = tempfile.NamedTemporaryFile(
dir=temp_config_dir, suffix='.py') # tempfile.NamedTemporaryFile:创建并返回一个临时文件。这里面两个参数用于说明文件的目录和格式
temp_config_name = osp.basename(temp_config_file.name) # os.path.basename(path):返回路径 path 的基本名称。
shutil.copyfile(filename,
osp.join(temp_config_dir, temp_config_name)) # shutil.copyfile(src, dst):将名为 src 的文件的内容(不包括元数据)拷贝到名为 dst 的文件并以尽可能高效的方式返回 dst。 src 和 dst 均为路径类对象或以字符串形式给出的路径名。
temp_module_name = osp.splitext(temp_config_name)[0] # os.path.splitext(path):将路径 path 拆分为一对,即 (root, ext),使 root + ext == path。其中 ext 为空或以英文句点开头,且最多包含一个句点。路径前的句点将被忽略,例如 splitext('.cshrc') 返回 ('.cshrc', '')。
sys.path.insert(0, temp_config_dir)
Config._validate_py_syntax(filename) #
mod = import_module(temp_module_name) # 在执行相对导入时,` package `参数是必需的。它指定要使用的包作为锚点,从这个锚点将相对导入解析为绝对导入。
sys.path.pop(0)
cfg_dict = {
name: value
for name, value in mod.__dict__.items() # 把mod(congfig/tusimple.py)中的数据导入
if not name.startswith('__')
}
# delete imported module
del sys.modules[temp_module_name]
# close temp file
temp_config_file.close()
elif filename.endswith(('.yml', '.yaml', '.json')):
import mmcv
cfg_dict = mmcv.load(filename)
else:
raise IOError('Only py/yml/yaml/json type are supported now!')
cfg_text = filename + '\n'
with open(filename, 'r') as f:
cfg_text += f.read()
if BASE_KEY in cfg_dict:
cfg_dir = osp.dirname(filename)
base_filename = cfg_dict.pop(BASE_KEY)
base_filename = base_filename if isinstance(
base_filename, list) else [base_filename]
cfg_dict_list = list()
cfg_text_list = list()
for f in base_filename:
_cfg_dict, _cfg_text = Config._file2dict(osp.join(cfg_dir, f))
cfg_dict_list.append(_cfg_dict)
cfg_text_list.append(_cfg_text)
base_cfg_dict = dict()
for c in cfg_dict_list:
if len(base_cfg_dict.keys() & c.keys()) > 0:
raise KeyError('Duplicate key is not allowed among bases')
base_cfg_dict.update(c)
base_cfg_dict = Config._merge_a_into_b(cfg_dict, base_cfg_dict)
cfg_dict = base_cfg_dict
# merge cfg_text
cfg_text_list.append(cfg_text)
cfg_text = '\n'.join(cfg_text_list)
return cfg_dict, cfg_text # cfg_dict:字典数据结构
# cfg_text:多了一行“/home/wenqiang/resa/configs/tusimple.py”,同样也和这个文件数据结构一致。
@staticmethod
def _merge_a_into_b(a, b):
# merge dict `a` into dict `b` (non-inplace). values in `a` will
# overwrite `b`.
# copy first to avoid inplace modification
b = b.copy()
for k, v in a.items():
if isinstance(v, dict) and k in b and not v.pop(DELETE_KEY, False):
if not isinstance(b[k], dict):
raise TypeError(
f'{k}={v} in child config cannot inherit from base '
f'because {k} is a dict in the child config but is of '
f'type {type(b[k])} in base config. You may set '
f'`{DELETE_KEY}=True` to ignore the base config')
b[k] = Config._merge_a_into_b(v, b[k])
else:
b[k] = v
return b
@staticmethod
def fromfile(filename):
cfg_dict, cfg_text = Config._file2dict(filename)
return Config(cfg_dict, cfg_text=cfg_text, filename=filename)
@staticmethod
def auto_argparser(description=None):
"""Generate argparser from config file automatically (experimental)
"""
partial_parser = ArgumentParser(description=description)
partial_parser.add_argument('config', help='config file path')
cfg_file = partial_parser.parse_known_args()[0].config
cfg = Config.fromfile(cfg_file)
parser = ArgumentParser(description=description)
parser.add_argument('config', help='config file path')
add_args(parser, cfg)
return parser, cfg
def __init__(self, cfg_dict=None, cfg_text=None, filename=None):
if cfg_dict is None:
cfg_dict = dict()
elif not isinstance(cfg_dict, dict):
raise TypeError('cfg_dict must be a dict, but '
f'got {type(cfg_dict)}')
for key in cfg_dict:
if key in RESERVED_KEYS:
raise KeyError(f'{key} is reserved for config file')
super(Config, self).__setattr__('_cfg_dict', ConfigDict(cfg_dict)) # 这个操作呢,简单理解就是调用/重载了Config的父类中的__setattr__这个魔术方法。
# 该魔术方法实现了将Config类设置一个_cfg_dict属性,并将cfg_dict实例为ConfigDict类。
super(Config, self).__setattr__('_filename', filename)
if cfg_text:
text = cfg_text
elif filename:
with open(filename, 'r') as f:
text = f.read()
else:
text = ''
super(Config, self).__setattr__('_text', text)
@property
def filename(self):
return self._filename
@property
def text(self):
return self._text
@property
def pretty_text(self):
indent = 4
def _indent(s_, num_spaces):
s = s_.split('\n')
if len(s) == 1:
return s_
first = s.pop(0)
s = [(num_spaces * ' ') + line for line in s]
s = '\n'.join(s)
s = first + '\n' + s
return s
def _format_basic_types(k, v, use_mapping=False):
if isinstance(v, str):
v_str = f"'{v}'"
else:
v_str = str(v)
if use_mapping:
k_str = f"'{k}'" if isinstance(k, str) else str(k)
attr_str = f'{k_str}: {v_str}'
else:
attr_str = f'{str(k)}={v_str}'
attr_str = _indent(attr_str, indent)
return attr_str
def _format_list(k, v, use_mapping=False):
# check if all items in the list are dict
if