0、人脸识别流程概述
人脸识别流程包括两个主要步骤:
-
Step1:人脸检测,确保我们处理的是正确的人脸区域
-
Step2:身份识别,确定该人脸的身份
0.1 人脸检测
人脸检测是从图像中定位人脸并抠出人脸区域的过程,这是人脸识别的第一步,用于确保后续的身份识别处理的是正确的人脸区域
因为人脸的类别少、形状比较固定、特征同样比较固定、周围环境也一般比较好,所以人脸检测其实是目标检测中最简单的任务
输入输出:
- 输入:一张图像
- 输出:所有人脸的坐标框
操作过程:
- 抠图:用深度学习模型提取人脸图像中的特征,识别出人脸的位置,并将其抠出来
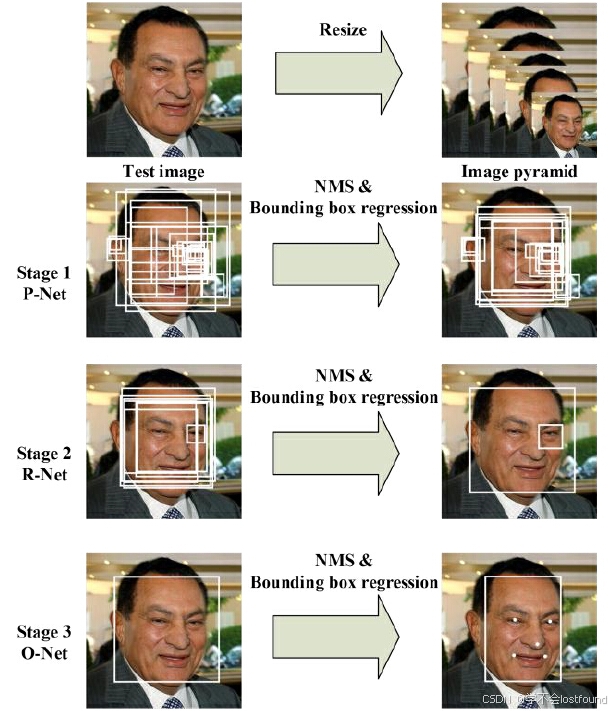
- MTCNN:一种流行的人脸检测算法,通过三个阶段(P-Net、R-Net、O-Net)逐步精细化人脸检测结果
技术细节:(海选-->淘汰赛-->决赛)
- P-Net:生成候选的人脸区域
- R-Net:对P-Net的结果进行筛选和调整
- O-Net:输出最终的人脸边界框和关键点位置
0.2 身份识别
身份识别是根据人脸图像判断其身份信息的过程,这一步骤通常涉及到人脸特征的提取和比较,所以比人脸检测稍复杂一点
操作过程:
- FaceNet:一种深度学习模型,用于从人脸图像中学习一个欧几里得空间中的嵌入表示,该表示可以用于直接比较人脸图像以确定身份
- 人脸向量对比:将待识别的人脸图像通过FaceNet模型转换为向量,然后与数据库中存储的人脸向量进行比较,以确定身份
技术细节:
- 特征提取:使用FaceNet等深度学习模型提取人脸特征
- 向量比较:使用余弦相似度等度量方法比较人脸向量的相似度
- 阈值判断:设定一个阈值,当相似度超过这个阈值时,认为两个人脸是同一人

1、MTCNN简介
1.1 背景
MTCNN(Multi-task Cascaded Convolutional Networks)最初是在2016年由Kaipeng Zhang、Zhanpeng Zhang、Zhifeng Li 和 Yu Qiao 提出的,他们在论文《Joint Face Detection and Alignment Using Multitask Cascaded Convolutional Networks》中介绍了这一算法,用于解决在无约束环境中人脸检测和对齐的挑战性问题(包括不同姿势、照明和遮挡的影响等问题)
1.2 概述
MTCNN是一种多任务级联卷积神经网络,它将人脸检测和人脸关键点定位结合起来,通过三个阶段的级联网络实现从粗到细的人脸检测过程
MTCNN的主要创新点在于将人脸检测和人脸关键点对齐相结合以提升检测指标,并对在线难样本挖掘(Online Hard Sample Mining,OHSM)算法进行了改进
1.3 网络结构
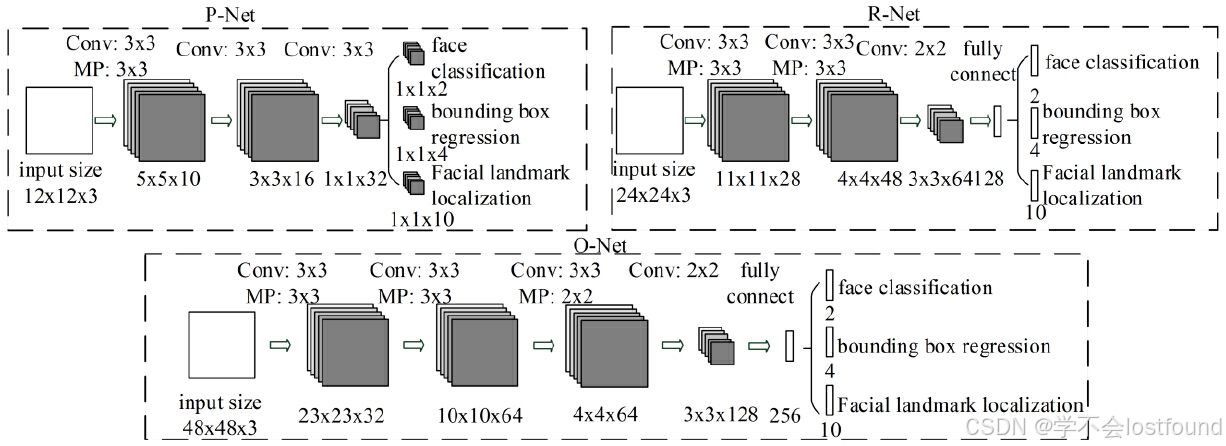
MTCNN由三个级联的网络组成:P-Net、R-Net、O-Net
(1)P-Net(Proposal Network):这是第一阶段,用于快速生成候选的人脸框(Bounding Boxes),特点:纯卷积网络,无全链接(精髓所在)
P-Net接收输入图像,通过卷积层提取特征,然后利用几个简单的卷积层进行人脸分类和边框回归
P-Net会输出大量的候选框,这些候选框可能包含人脸,但也可能包含大量误检
(2)R-Net(Refine Network):这是第二阶段,用于对P-Net输出的候选框进行进一步筛选和调整
R-Net接收P-Net的候选框作为输入,通过更复杂的网络结构,对候选框进行更加细致的分类和边框回归
R-Net会去除大部分误检的候选框,并调整剩余候选框的位置和大小,使其更接近真实的人脸位置
(3)O-Net(Output Network):这是第三阶段,也是最复杂的网络
O-Net接收R-Net输出的候选框,通过更深层次的卷积神经网络处理人脸区域,优化人脸位置和姿态,并进行最终的人脸分类、边框回归以及人脸关键点的定位
O-Net的输出通常还可以用于后续的人脸识别、表情分析等任务
1.4 推理逻辑
MTCNN的推理逻辑如下:
Step1:输入一张图片(不限尺寸):MTCNN接受任意尺寸的输入图片
Step2:构建图像金字塔:为了检测不同尺度的人脸,MTCNN构建了一个图像金字塔,它会生成一系列不同尺寸的图像,以覆盖不同大小的人脸
Step3:遍历金字塔,取出每一个级别的图像:对于图像金字塔中的每个级别的图像,MTCNN执行以下步骤:
-
把图像输入P-Net,得到P-Net的输出:P-Net是MTCNN的第一个阶段,它快速生成大量候选的人脸框,并给出人脸分类和边界框回归的初步预测
-
把P-Net的输出,resize 24 × 24,输入R-Net,得到R-Net的输出:P-Net的输出经过筛选和调整大小后,输入到R-Net,这是一个更为精细的网络,用于进一步筛选和调整人脸框的位置和大小
-
把R-Net的输出,resize 48 × 48,输入O-Net,得到O-Net的输出:R-Net的输出再次经过筛选和调整大小后,输入到O-Net,这是最终阶段的网络,用于精确地确定人脸框的位置和大小,并预测人脸关键点的位置
1.5 特点
- 高效性:通过级联的网络结构,MTCNN能够在保证检测精度的同时,显著提高检测速度
- 灵活性:MTCNN可以适应不同尺寸和分辨率的输入图像,具有较强的鲁棒性
2、MTCNN关键技术
MTCNN在人脸检测中使用了图像金字塔、IOU和NMS这几个关键技术,以下是相关介绍:
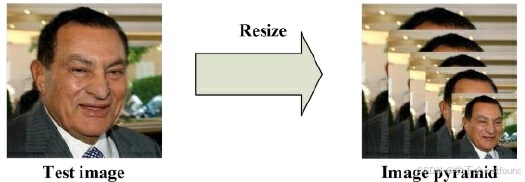
2.1 图像金字塔
MTCNN利用图像金字塔技术来检测不同尺寸的人脸
由于P-Net的建议框大小是固定的,只能检测12x12像素范围内的人脸,为了能够检测到更大尺寸的人脸,MTCNN回通过不断缩小图片以适应建议框的大小,形成图像金字塔,当下一次图像的最小边长小于12像素时,停止缩放,这样不仅可以在不同尺度的图像上进行人脸检测,还可以提高检测的准确性和鲁棒性
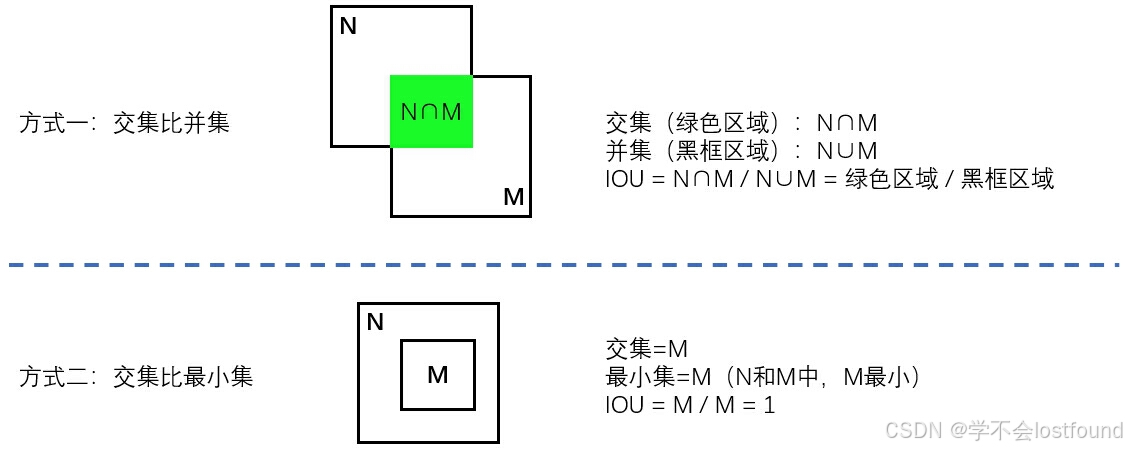
2.2 IOU(交并比)
IOU在MTCNN中用于计算两个边界框之间的重叠程度,MTCNN在O-Net阶段采用了两种方式计算IOU,以提高检测的准确性:
-
方式一:交集比并集(也就是【交集】除以【并集】)
-
方式二:交集比最小集(也就是【交集】除以【最小集】)
在处理大框套小框的情况时,第二种方式的IOU计算可以避免误检,因为这种方式更倾向于保留IOU值小的框(即:非重叠的框)
2.3 NMS(非极大值抑制)
NMS在MTCNN中用于去除预测结果中重复的边界框,保留最具代表性的边界框,以提高检测的准确性和效率
在P-Net、R-Net、O-Net的每个阶段后,都会应用NMS来筛选出最终的边界框,其工作原理如下:
-
Step1:根据每个边界框的置信度进行排序
-
Step2:选择置信度最高的边界框,计算它与其他所有边界框的IOU
-
Step3:如果IOU超过预设的阈值,则认为这两个框表示的是同一个目标
-
Step4:在确定两个边界框表示同一个目标后,NMS算法会保留置信度(即检测到目标的概率)较高的那个边界框,并“抑制”或删除置信度较低的那个边界框
-
Step5:重复上述过程,直到所有边界框都被处理,得到最终的边界框
MTCNN论文中提到了RNet和ONet的NMS阈值,默认分别为0.7,这些阈值可以根据实际需要进行调整,从而控制边界框的重叠程度
3、P-Net网络结构分析与实现
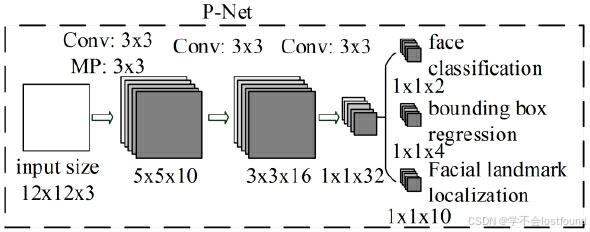
P-Net的具体网络结构如下:
-
输入层:12x12像素的RGB三通道彩色图像
-
第一层卷积:使用10个3x3的卷积核,步长为1,边缘填充数为0,输出10x10x10的特征图【(12 + 2*0 - 3) / 1 + 1 = 10】
-
第一层池化:3x3的最大池化,步长为2,边缘填充数为1,输出10x5x5的特征图【(10 + 2*1 - 3) / 2 + 1 = 5】
-
第二层卷积:使用16个3x3的卷积核,步长为1,边缘填充数为0,输出16x3x3的特征图【(5 + 2*0 - 3) / 1 + 1 = 3】
-
第三层卷积:使用32个3x3的卷积核,步长为1,边缘填充数为0,输出32x1x1的特征图【(3 + 2*0 - 3) / 1 + 1 = 1】
-
输出层:
-
face classification(人脸分类,卷积):使用2个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
bounding box regression(边界框回归,卷积):使用4个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
Facial landmark localization(面部标志点坐标):使用10个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
P-Net的网络结构实现:
# 引入pytorch和nn神经网络
import torch
import torch.nn as nn
class PNet(nn.Module):
"""
自定义一个PNet网络
"""
def __init__(self, in_channels=3, n_classes=32):
super().__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=10, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=10),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3,stride=2, padding=1),
nn.Conv2d(in_channels=10, out_channels=16, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=16),
nn.PReLU(),
nn.Conv2d(in_channels=16, out_channels=n_classes, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=n_classes),
nn.PReLU()
)
# 人脸概率输出
self.cls_out = nn.Conv2d(in_channels=n_classes, out_channels=2, kernel_size=1, stride=1, padding=0)
# 人脸框输出
self.reg_out = nn.Conv2d(in_channels=n_classes, out_channels=4, kernel_size=1, stride=1, padding=0)
# 人脸关键点坐标输出
self.local_out = nn.Conv2d(in_channels=n_classes, out_channels=10, kernel_size=1, stride=1, padding=0)
def forward(self, x):
"""
前向传播
"""
# 1. 先做特征抽取
x = self.feature_extractor(x)
# 2. 再做分类回归
cls_out = self.cls_out(x)
reg_out = self.reg_out(x)
local_out = self.local_out(x)
return cls_out, reg_out, local_out4、R-Net网络结构分析与实现
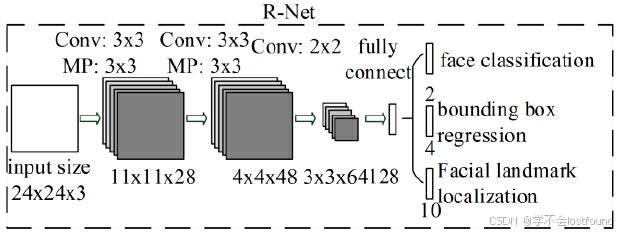
R-Net的具体网络结构如下:
-
输入层:24x24像素的RGB三通道彩色图像
-
第一层卷积:使用28个3x3的卷积核,步长为1,边缘填充数为0,输出28x22x22的特征图【(24 + 2*0 - 3) / 1 + 1 = 22】
-
第一层池化:3x3的最大池化,步长为2,边缘填充数为1,输出28x11x11的特征图【(22 + 2*1 - 3) / 2 + 1 = 11】
-
第二层卷积:使用48个3x3的卷积核,步长为1,边缘填充数为0,输出48x9x9的特征图【(11 + 2*0 - 3) / 1 + 1 = 9】
-
第二层池化:3x3的最大池化,步长为2,边缘填充数为0,输出48x4x4的特征图【(9 + 2*0 - 3) / 2 + 1 = 4】
-
第三层卷积:使用64个2x2的卷积核,步长为1,边缘填充数为0,输出64x3x3的特征图【(4 + 2*0 - 2) / 1 + 1 = 3】
-
展平+全连接:将64x3x3的特征图展平,连接到128维向量
-
输出层:
-
face classification(人脸分类,卷积):使用2个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
bounding box regression(边界框回归,卷积):使用4个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
Facial landmark localization(面部标志点坐标):使用10个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
R-Net的网络结构实现:
# 引入pytorch和nn神经网络
import torch
import torch.nn as nn
class RNet(nn.Module):
"""
自定义一个RNet网络
"""
def __init__(self, in_channels=3, n_classes=128):
super().__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=28, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=28),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False),
nn.Conv2d(in_channels=28, out_channels=48, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=48),
nn.PReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=False),
nn.Conv2d(in_channels=48, out_channels=64, kernel_size=2, stride=1, padding=0),
nn.BatchNorm2d(num_features=64),
nn.PReLU(),
nn.Flatten(),
nn.Linear(in_features=3 * 3 * 64, out_features=n_classes)
)
# 人脸概率输出
self.cls_out = nn.Conv2d(in_channels=n_classes, out_channels=2, kernel_size=1, stride=1, padding=0)
# 人脸框输出
self.reg_out = nn.Conv2d(in_channels=n_classes, out_channels=4, kernel_size=1, stride=1, padding=0)
# 人脸关键点坐标输出
self.local_out = nn.Conv2d(in_channels=n_classes, out_channels=10, kernel_size=1, stride=1, padding=0)
def forward(self, x):
"""
前向传播
"""
# 1. 先做特征抽取
x = self.feature_extractor(x)
# 2. 再做分类回归
cls_out = self.cls_out(x)
reg_out = self.reg_out(x)
local_out = self.local_out(x)
return cls_out, reg_out, local_out5、O-Net网络结构分析与实现
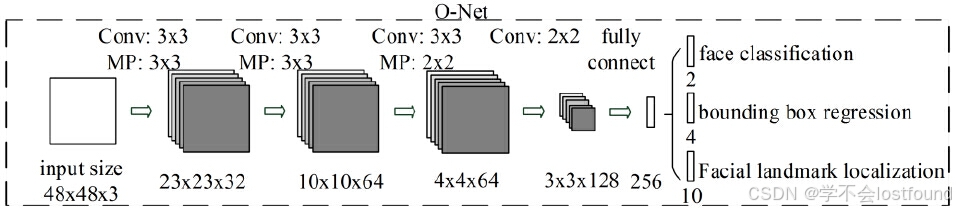
O-Net的具体网络结构如下:
-
输入层:48x48像素的RGB三通道彩色图像
-
第一层卷积:使用32个3x3的卷积核,步长为1,边缘填充数为0,输出32x46x46的特征图【(48 + 2*0 - 3) / 1 + 1 = 46】
-
第一层池化:3x3的最大池化,步长为2,边缘填充数为1,输出32x23x23的特征图【(46 + 2*1 - 3) / 2 + 1 = 23】
-
第二层卷积:使用64个3x3的卷积核,步长为1,边缘填充数为0,输出64x21x21的特征图【(23 + 2*0 - 3) / 1 + 1 =21】
-
第二层池化:3x3的最大池化,步长为2,边缘填充数为0,输出64x10x10的特征图【(21 + 2*0 - 3) / 2 + 1 = 10】
-
第三层卷积:使用64个3x3的卷积核,步长为1,边缘填充数为0,输出64x8x8的特征图【(10 + 2*0 - 3) / 1 + 1 =8】
-
第三层池化:2x2的最大池化,步长为2,边缘填充数为0,输出64x4x4的特征图【(8 + 2*0 - 2) / 2 + 1 = 4】
-
第四层卷积:使用128个2x2的卷积核,步长为1,边缘填充数为0,输出128x3x3的特征图【(4 + 2*0 - 2) / 1 + 1 = 3】
-
展平+全连接:将128x3x3的特征图展平,连接到256维向量
-
输出层:
-
face classification(人脸分类,卷积):使用2个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
bounding box regression(边界框回归,卷积):使用4个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
Facial landmark localization(面部标志点坐标):使用10个1x1的卷积核,步长为1,边缘填充数为0,输出2x1x1的特征图【(1 + 2*0 - 1) / 1 + 1 = 3】
-
O-Net的网络结构实现:
# 引入pytorch和nn神经网络
import torch
import torch.nn as nn
class ONet(nn.Module):
"""
自定义一个ONet网络
"""
def __init__(self, in_channels=3, n_classes=256):
super().__init__()
self.feature_extractor = nn.Sequential(
nn.Conv2d(in_channels=in_channels, out_channels=32, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1, ceil_mode=False),
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=3, stride=2, padding=0, ceil_mode=False),
nn.Conv2d(in_channels=64, out_channels=64, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(num_features=64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, ceil_mode=False),
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=2, stride=1, padding=0),
nn.BatchNorm2d(num_features=128),
nn.ReLU(),
nn.Flatten(),
nn.Linear(in_features=3 * 3 * 128, out_features=n_classes)
)
# 人脸概率输出
self.cls_out = nn.Conv2d(in_channels=n_classes, out_channels=2, kernel_size=1, stride=1, padding=0)
# 人脸框输出
self.reg_out = nn.Conv2d(in_channels=n_classes, out_channels=4, kernel_size=1, stride=1, padding=0)
# 人脸关键点坐标输出
self.local_out = nn.Conv2d(in_channels=n_classes, out_channels=10, kernel_size=1, stride=1, padding=0)
def forward(self, x):
"""
前向传播
"""
# 1. 先做特征抽取
x = self.feature_extractor(x)
# 2. 再做分类回归
cls_out = self.cls_out(x)
reg_out = self.reg_out(x)
local_out = self.local_out(x)
return cls_out, reg_out, local_out