2015 Densebox Unifying landmark localization with end to end object detection
Lichao Huang, Yi Yang CVPR, 2015 PDF
Abstract
Our contribution is two-fold.
- First, we show that a single
FCN, if designed and optimized carefully, can detect multiple different objects extremely accurately and efficiently. - Second, we show that when incorporating with landmark localization during multi-task learning,
DenseBoxfurther improves object detection accuracy.
1. Introduction
In this work, we focus on one question: To what extent can an one-stage FCN perform on object detection? To this end, we present a novel FCN based object detector, DenseBox, that does not require proposal generation and is able to be optimized end-to-end during training. Although similar to many existing sliding window fashion FCN detection frameworks, DenseBox is more carefully designed to detect objects under small scales and heavy occlusion. We train DenseBox and apply careful hard negative mining techniques to boostrap the detection performance. To make it even better, we further integrate landmark localization into the system through joint multi-task learning.
2. Related Work
The literature on object detection is vast. Before the success of deep convolutional neural networks [18], the widely used detection systems are based on a combination of independent components. First, handcrafted image features such as HOG, SIFT, and Fisher Vector are extracted at every location and scale of an image. Second, object models such as pictorial structure model (PSM) and deformable part-based model (DPM) allow object parts (e.g. head, torso, arms and legs of human) to deform with geometric constraints. Finally, a classifier such as boosting methods [39], linear SVM, latent SVM, or random forests decides whether a candidate window shall be detected as containing an object.
3. DenseBox for Detection
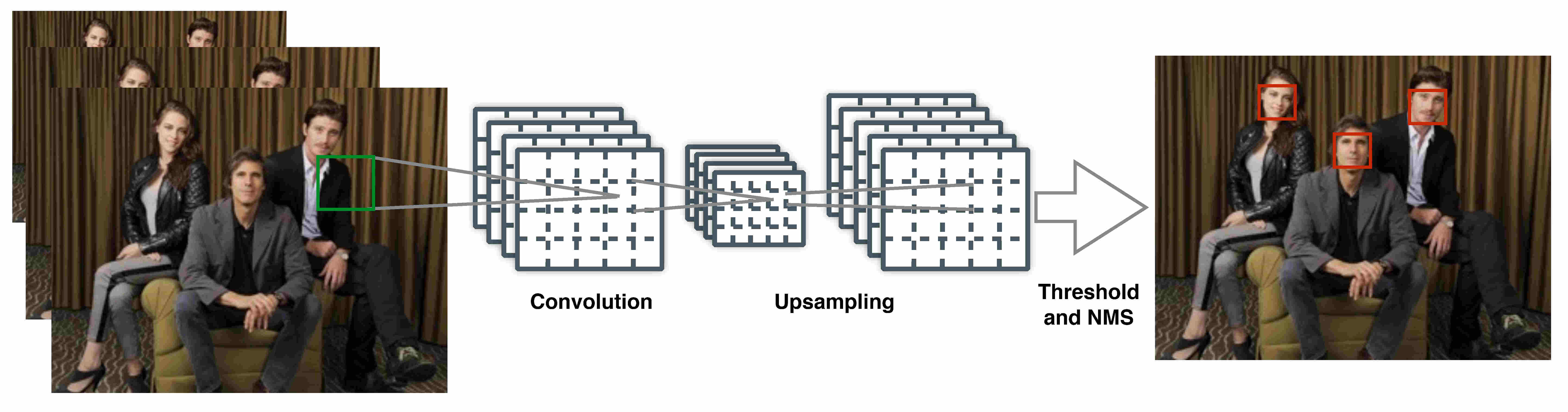
DenseBox 中目标检测的所有组件都由全卷积网络组成(除了非极大值抑制步骤),因此不需要生成区域提议。在测试阶段,DenseBox 接受
m
×
n
m\times n
m×n 的图像输入,输出特征图
(
5
×
m
4
×
n
4
)
(\displaystyle 5 \times \frac{m}{4}\times \frac{n}{4})
(5×4m×4n)描述一个带有 5 维向量的边界框
t
^
i
=
{
s
^
,
d
x
^
t
=
x
i
−
x
t
,
d
y
^
t
=
y
i
−
y
t
,
d
x
^
b
=
x
i
−
x
b
,
d
y
^
b
=
y
i
−
y
b
}
\hat{t}_{i}=\left\{\hat{s}, \hat{d x}^{t}=x_{i}-x_{t}, \hat{d y}^{t}=y_{i}-y_{t}, \hat{d x}^{b}=x_{i}-x_{b}, \hat{d y}^{b}=y_{i}-y_{b}\right\}
t^i={s^,dx^t=xi−xt,dy^t=yi−yt,dx^b=xi−xb,dy^b=yi−yb},
s
^
\hat{s}
s^ 代表分类置信度,后四维向量为像素位置到目标边界的距离,最后,将所有像素的输出转化为带有分类置信度的预测框,经过 NMS 处理后进行最后的输出。
3.1. Ground Truth Generation
It is unnecessary to put the whole image into the network for training because it would take most computational time in convolving on background. A wise strategy is to crop large patches containing faces and sufficient background information for training. In this paper, we train our network on single scale, and apply it to multiple scales for evaluation.
Generally speaking, our proposed network is trained in a segmentation-like way. In training, the patches are cropped and resized to 240 × 240 240 × 240 240×240 with a face in the center roughly has the height of 50 50 50 pixels. The output ground truth in training is a 5 5 5-channel map sized 60 × 60 60 × 60 60×60 , with the down-sampling factor of 4 4 4. The positive labeled region in the first channel of ground truth map is a filled circle with radius r c r_c rc, located in the center of a face bounding box. The radius r c r_c rc is proportional to the bounding box size, and its scaling factor is set to be 0.3 0.3 0.3 to the box size in output coordinate space, as show in Fig 2. The remaining 4 4 4 channels are filled with the distance between the pixel location of output map between the left top and right bottom corners of the nearest bounding box.

Note that if multiple faces occur in one patch, we keep those faces as positive if they fall in a scale range(e.g. 0.8 to 1.25 in our setting) relative to the face in patch center. Other faces are treated as negative samples. The pixels of first channel, which denote the confidence score of class, in the ground truth map are initialized with 0, and further set to 1 if within the positive label region. We also find our ground truth generation is quite similar to the segmentation work by Pinheiro et. al. In their method, the pixel label is decided by the location of object in patch, while in DenseBox, the pixel label is determined by the receptive field. Specifically, if the output pixel is labeled to 1 if it satisfies the constraint that its receptive field contains an object roughly in the center and in a given scale. Each pixel can be treated as one sample , since every 5-channel pixel describe a bounding box.
3.2. Model Design
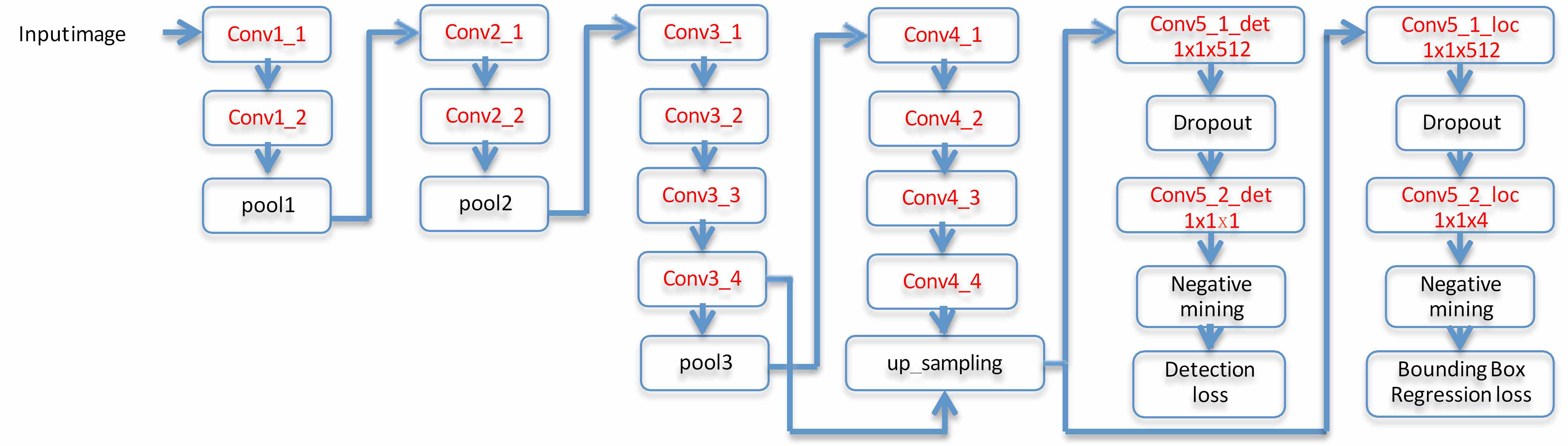
Our network architecture illustrated in Fig 3 is derived from the VGG 19 model used for image classification. The whole network has
16
16
16 convolution layers, with the first
12
12
12 convolution layers initialized by VGG 19 model. The output of conv4_4 is feed into four
1
×
1
1 \times 1
1×1 convolution layers, where the first two convolution layers output 1-channel map for class score, and the second two predict the relative position of bounding box by
4
4
4-channel map. The last
1
×
1
1 \times 1
1×1 convolution layers act as fully connected layers in a sliding-window fashion.
Figure 3: Network architecture of DenseBox. The rectangles with red names contain learnable parameters
Multi-Level Feature Fusion. Recent works indicate that using features from different convolution layers can enhance performance in task such as edge detection and segmentation. Part-level feature focus on local details of object to find discriminative appearance parts, while object-level or high-level feature usually has a larger receptive field in order to recognize object. The larger receptive field also brings in context information to predict more accurate result. In our implementation, we concatenate feature map from conv3_4 and conv4_4. The receptive field (or sliding window size) of conv3_4 is 48 × 48, almost the same size of the face size in training, and the conv4_4 have a much larger receptive field, around 118 × 118 in size, which could utilize global textures and context for detection. Note that the feature map size of conv4_4 is half of the map generated by conv3_4, hence we use a bilinear up-sampling layer to transform them to the same resolution.
3.3. Multi-Task Training.
We use the ImageNet pre-trained VGG 19 network to initialize DenseBox. Actually, in initialization, we only keep the first 12 convolution layers(from conv1_1 to conv4_4), and the other layers in VGG 19 are replaced by four new convolution layers with xavier initialization.
Like Fast R-CNN, our network has two sibling output branches. The first outputs the confidence score y ^ \hat{y} y^ (per pixel in the output map) of being a target object. Given the ground truth label y ∗ ∈ { 0 , 1 } y^*\in\{0,1\} y∗∈{0,1} , the classification loss can be defined as follows.
L c l s ( y ^ , y ∗ ) = ∥ y ^ − y ∗ ∥ 2 \mathcal{L}_{c l s}\left(\hat{y}, y^{*}\right)=\left\|\hat{y}-y^{*}\right\|^{2} Lcls(y^,y∗)=∥y^−y∗∥2
Here we use L 2 L_2 L2 loss in both face and car detection task. We did not try other loss functions such as hinge loss or cross-entropy loss, which seems to be a more appropriate choice, as we find the simple L 2 L_2 L2 loss work well in our task.
The second branch of outputs the bounding-box regression loss, denoted as
L
l
o
c
L_{loc}
Lloc.
L
loc
(
d
^
,
d
∗
)
=
∑
i
∈
{
t
x
,
t
y
,
b
x
,
b
y
}
∥
d
^
i
−
d
i
∗
∥
2
\mathcal{L}_{\text {loc }}\left(\hat{d}, d^{*}\right)=\sum_{i \in\{t x, t y, b x, b y\}}\left\|\hat{d}_{i}-d_{i}^{*}\right\|^{2}
Lloc (d^,d∗)=i∈{tx,ty,bx,by}∑∥∥∥d^i−di∗∥∥∥2
3.3.1. Balance Sampling
The process of selecting negative samples is one of the crucial parts in learning. If simply using all negative samples in a mini-batch will bias prediction towards negative samples as they dominate in all samples. In addition, the detector will degrade if we penalize loss on those samples lying in the margin of positive and negative region. Here we use a binary mask for each output pixel to indicate whether it is selected in training.
- Ignoring Gray Zone. 灰色区域被定义为正负区域之间的过渡区域. 灰色区域不应被视为正样本或者负样本,这个区域的损失为0. 对于一个非正样本点,如果其半径为 2 的范围内存在正样本点,则归入灰色区域,ignore flag f i g n = 1 f_{ign}=1 fign=1.
- Hard Negative Mining. 在训练过程中,根据
L
c
l
s
(
y
^
,
y
∗
)
\mathcal{L}_{c l s}\left(\hat{y}, y^{*}\right)
Lcls(y^,y∗) 将样本排序,取
t
o
p
1
%
top\,1\%
top1% 作为
hard-negative,使得网络重点学习难分样本。在训练中,保持正负样本比例为 1 : 1 1:1 1:1 . 在所有的负样本中,一半是从hard-negative样本中抽取的,剩下的一半是从non-hard negative样本中随机抽取的。将选中的正负样本设置一个标记 f s e l = 1 f_{sel}=1 fsel=1. - Loss with Mask. 针对每一个样本 t ^ i = { y ^ i , d ^ i } \hat{t}_{i}=\left\{\hat{y}_{i}, \hat{d}_{i}\right\} t^i={y^i,d^i} 设置掩码 M ( t ^ i ) = { 0 f i g n i = 1 or f s e l i = 0 1 otherwise M\left(\hat{t}_{i}\right)= \begin{cases}0 & f_{i g n}^{i}=1 \text { or } f_{s e l}^{i}=0 \\ 1 & \text { otherwise }\end{cases} M(t^i)={01figni=1 or fseli=0 otherwise ,则多任务损失可以表示为:
L d e t ( θ ) = ∑ i ( M ( t ^ i ) L c l s ( y ^ i , y i ∗ ) + λ l o c [ y i ∗ > 0 ] M ( t ^ i ) L l o c ( d ^ i , d i ∗ ) ) \mathcal{L}_{d e t}(\theta)=\sum_{i}\left(M\left(\hat{t}_{i}\right) \mathcal{L}_{c l s}\left(\hat{y}_{i}, y_{i}^{*}\right)+\lambda_{l o c}\left[y_{i}^{*}>0\right] M\left(\hat{t}_{i}\right) \mathcal{L}_{l o c}\left(\hat{d}_{i}, d_{i}^{*}\right)\right) Ldet(θ)=i∑(M(t^i)Lcls(y^i,yi∗)+λloc[yi∗>0]M(t^i)Lloc(d^i,di∗))
- Other Implementation Details. In training, an input patch is considered to be “positive patch” if it contains an object centered in the center at a specific scale. These patches only contain negative samples around the positive samples. To fully explore the negative samples in the whole dataset, we also randomly crop patches at random scale from training images, and resize them to the same size and feed them to the network. We call this kind of patch as“random patch”, and the ratio of “positive patch” and “random patch” in training is 1:1. In addition, to further increase the robustness of our model, we also randomly jitter every patch before feeding them into the network. Specifically, we apply left-right flip, translation shift (of 25 pixels), and scale deformation (from [0.8, 1.25]).
3.4. Refine with Landmark Localization.

基于上面的设计,只需堆叠几层就可以在 DenseBox 中实现地标定位。此时损失如下:
L
f
u
l
l
(
θ
)
=
λ
d
e
t
L
d
e
t
(
θ
)
+
λ
l
m
L
l
m
(
θ
)
+
L
r
f
(
θ
)
\mathcal{L}_{f u l l}(\theta)=\lambda_{d e t} \mathcal{L}_{d e t}(\theta)+\lambda_{l m} \mathcal{L}_{l m}(\theta)+\mathcal{L}_{r f}(\theta)
Lfull(θ)=λdetLdet(θ)+λlmLlm(θ)+Lrf(θ)