2020TPAMI:Prior Guided Feature Enrichment Network for Few-Shot Segmentation
文章链接:https://arxiv.org/pdf/2008.01449.pdf
代码地址:https://github.com/Jia-Research-Lab/PFENet
1. 摘要
动机:
- 由于不合理的利用高层语义特征(指Resnet layer4),使得模型对于未见过类的泛化能力很差。 — 提出无需训练的先验信息生成方法。
- 支持集和查询集存在的空间不一致性问题。----提出FEM:Feature Enrichment Module(特征强化模块)。
2. 文章的主要观点
- CANet 已经证明,简单的将高层语义运用到小样本分割的模型中会导致模型的性能下降。
- 本文使用ImageNet预训练的模型来提取支持集和查询集的高层语义特征,因为预训练模型是不需要训练的, 所以, 模型尽管在训练时用到了已见过类的高层语义特征, 但并没有是失去泛化到新类的能力。
- 查询集中的目标和支持集中的目标可能在大小, 姿势上相差较大, 称这种情况为空间不一致性。
- 类似CANet, 使用卷积来代替SG-One和PANet的余玄相似度进行特征的比较, 因为后者在比较复杂的特征时, 效果欠佳。
3. 模型
1.Prior Generation:先验生成
动机:CANet不使用高层信息, 原因是:高层语义信息更多的是对应的类别相关的语义信息。会更可能将一个像素点鉴别为已见过类。但是, 在U-Net等文章中发掘这些特征用来提供语义信息,做最终的预测。
这两种相反的观念促使本文想到,利用高层语义特征做小样本分割。
目的:利用高层特征产生预测图Yq, Yq中的一个像素点的值大则表示:支持集中该位置的特征至少与查询集中的一个特征点产生了响应。
首先得到查询集和支持集的高层特征, 支持集的特征要经过 mask average pooling。
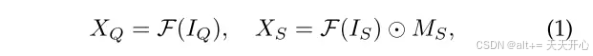
然后计算支持集中每个像素点所能在查询集中响应的最大值。
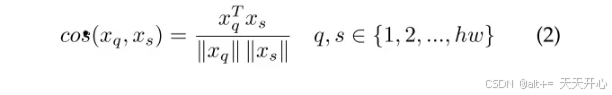
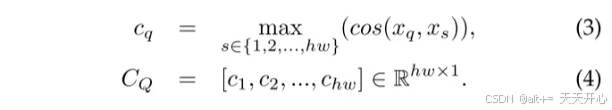
最后将Cq调整为 [h,w] 即可得到Yq。
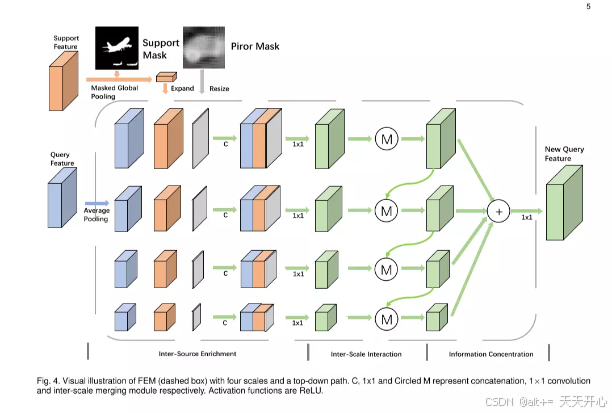
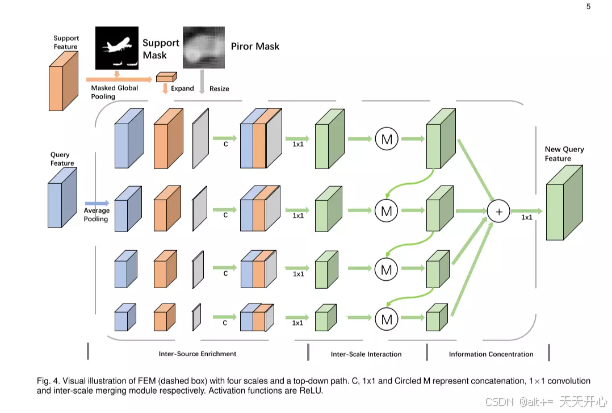
2.Feature Enrichment Module
动机: 由于查询集中的目标可能比支持集中大或者小, 因此像以前的方法一样使用全局平均池化是不合理的, 这样会造成空间的不一致性。一个可行的方法是使用PPM(金字塔场景解析网络)或者ASPP(空洞空间卷积池化金字塔),这两个网络能够有效的提取空间的多尺度信息。但是两个网络有以下两个不足点: 1.没有为每个尺度的信息进行增强。 2.每个尺度的信息当有层次结构。
于是本文提出FEM( feature enrichment module),水平角度融合了支持集特征, 查询集特征和先前的预测结果。 垂直角度利用了上下的信息通道去达到层次的结构。
结构:分为三个过程:
- 分成多尺度,并且在不同的尺度中将支持集,查询集,高层语义预测结果联系起来。
- 内部信息的融合, 有选择的将不同尺度的重要信息融合。
- 多尺度级联来产生最终的预测图。
3.FEM实现细节
Inter-Source Enrichment:
首先设定多个尺度的大小:
然后将提取的Xq,经过可适应池化, 生成不同的上述大小[Bi, Bi, C] 。再用n个不同尺度的扩展函数 将经过全局平均池化的Xs由[1, 1, C] 变为 [Bi, Bi, C]。Yq也对应的通过上下采样 变为对应的n个大小。

最后, 利用1*1卷积 将级联的三个特征图 转换为256维特征。
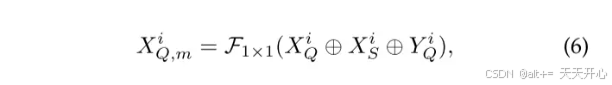
Inter-Scale Interaction:
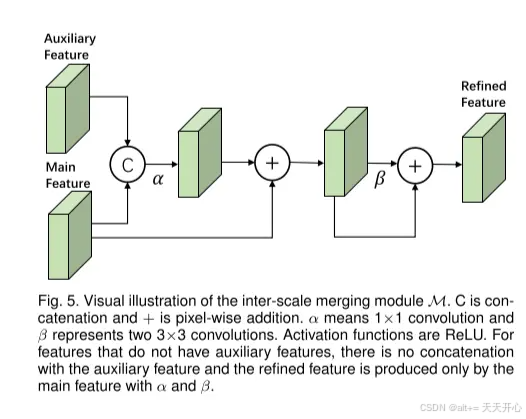
值得注意的是, 如果小目标在下采样中可能会消失。 通过一个上下信息通路,可以将语义丰富的特征尺度传递给语义粗糙的特征尺度。这样就实现了: 水平: 支持集,查询集信息交换。垂直: 不同尺度的信息交换。
M的结构:
Information Concentration:
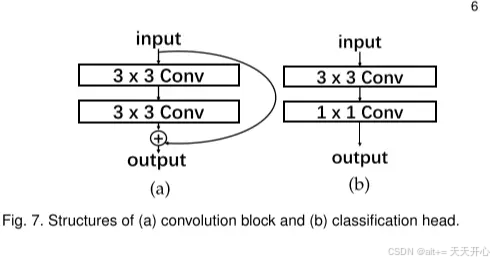
最后通过1*1卷积将这些特征融合起来即可。 为了达到较好的效果,为每个输出加了一个头结构(b):
为最后的输出 加上了(a) 结构。
损失函数:
L1是每个小输出的交叉熵, L2是最终预测图的交叉熵。
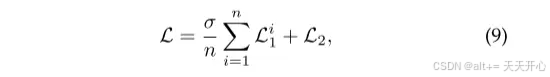
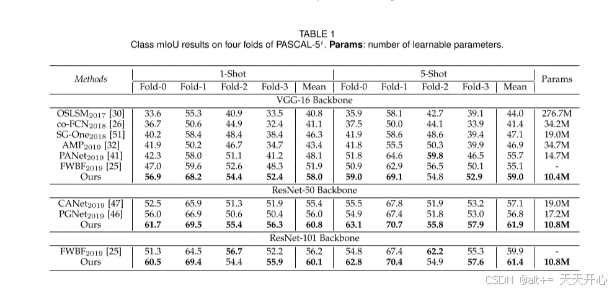
4. 实验结果

5. 评价
本文提出的模型性能有大幅度提升、且思路简单有效。此后许多小样本分割论文都引用了此文章,只能说不愧是PAMI的文章,论文和代码都非常完整和规范。