1. RewardBench 介绍
RewardBench: Evaluating Reward Models是一个专门用于评估 Reward Models(奖励模型) 的公开平台,旨在衡量模型在多种任务上的性能,包括 能力、可靠性、安全性 和推理能力。这一工具由 Allen Institute 提供,基于 Hugging Face 的 Spaces 平台,聚焦于 Reward Model 的对比和优化。
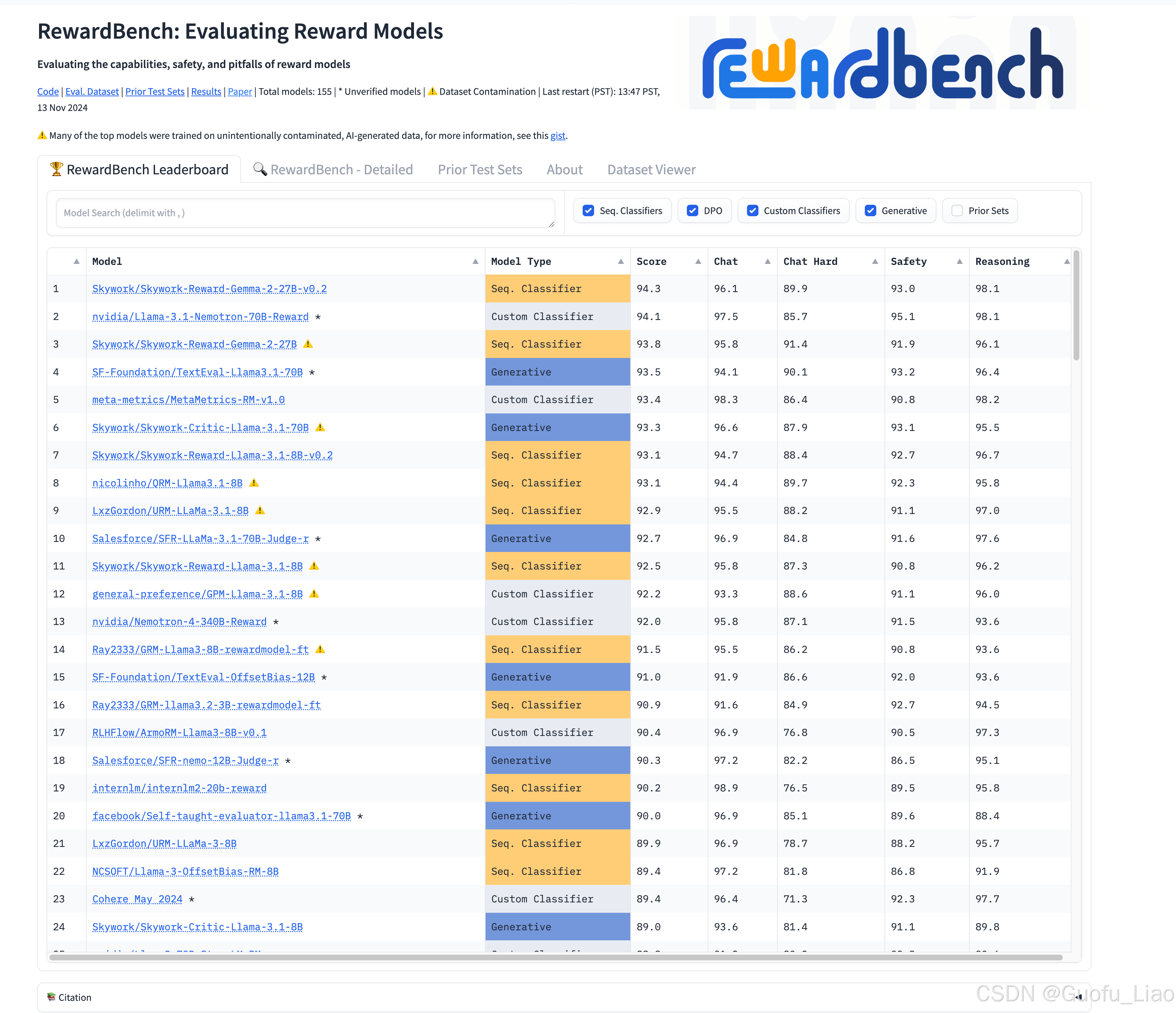
2. RewardBench 的主要功能
- 性能指标可视化:
- 提供多维度的评分,例如:
- Score(总体分数):综合模型的各项性能进行评估。
- Chat(聊天能力):评估模型在对话任务中的表现。
- Hard(复杂任务表现):衡量模型处理高难度任务的能力。
- Safety(安全性):考察模型在避免危险或有害回答方面的能力。
- Reasoning(推理能力):评估模型在逻辑推理、内容生成等任务中的表现。
- 模型分类:
- Seq. Classifiers(序列分类器):用于序列到标签的分类任务。
- Custom Classifiers(定制分类器):针对特定任务设计的分类器。
- Generative Models(生成模型):通过生成文本或分布完成任务。
- 对比与分析:
- 提供了不同类型模型的详细对比,涵盖开源社区中热门的 Reward Models,例如:
- Skywork/Reward-Gemma
- SF-Foundation/TextEval
- Salesforce/SFR-LLaMA
- 用户可以对比模型的任务表现,从而选择适合特定场景的模型。
- 透明性:
- 说明模型在评估数据集上的表现,明确指出是否存在数据污染等问题。
- 强调模型性能是在非刻意污染的公共数据集上测试的,数据来源清晰透明。
3. 适用场景
- 研究人员:
- 用于比较 Reward Models 的性能,选择最优模型或分析其不足之处。
- 针对任务优化模型架构或训练策略。
- 开发者:
- 快速评估模型在实际应用场景中的效果(如聊天机器人、问答系统等)。
- 挑选高安全性或推理能力强的模型应用于实际产品中。
- AI 社区:
- 促进模型公平对比,推动 Reward Models 的开源优化。
- 为 Reward Models 的开发与应用提供可靠基准。