redis应用之缓存穿透、缓存击穿、缓存雪崩
记录一下redis应用中常见的三大问题。
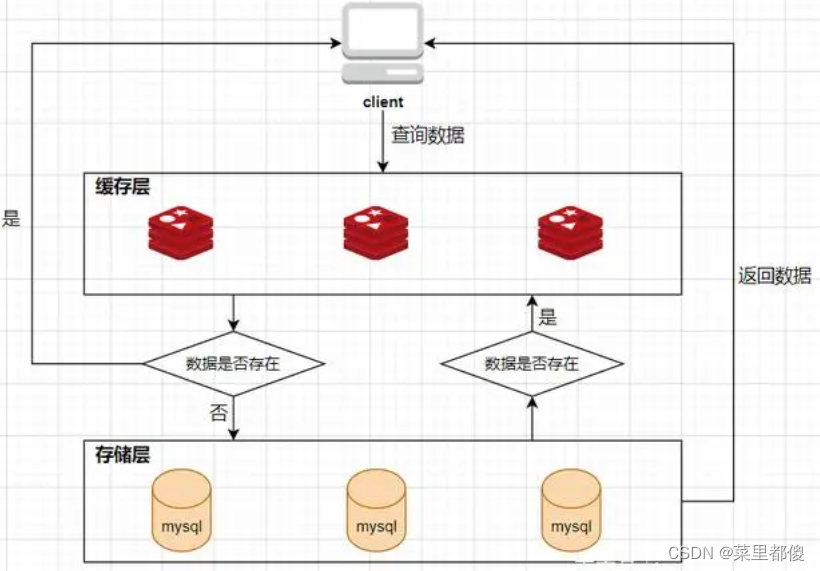
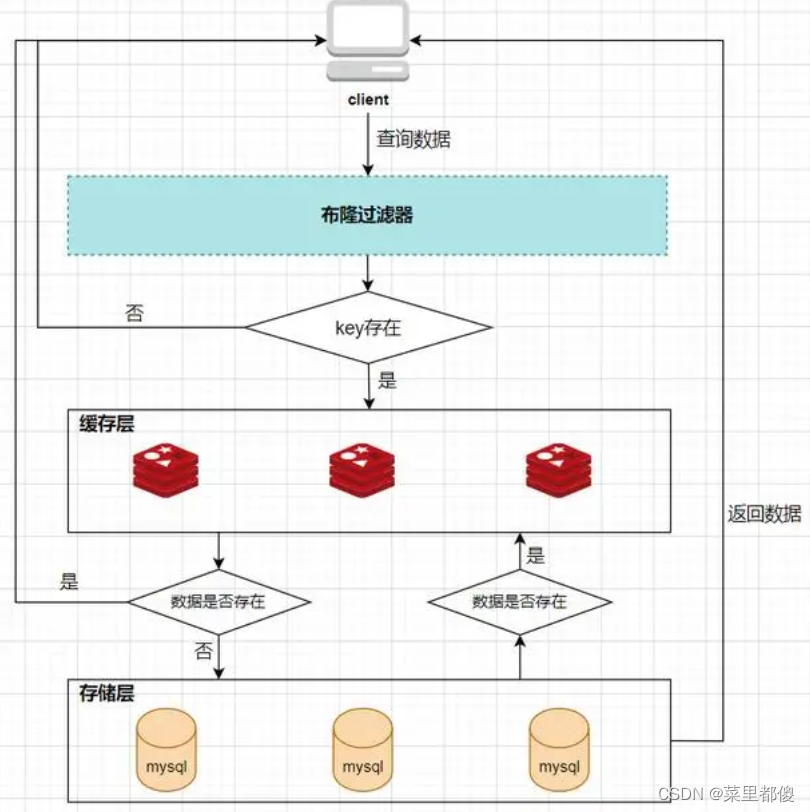
首先看一下应用redis作为缓存的系统数据访问的架构图:
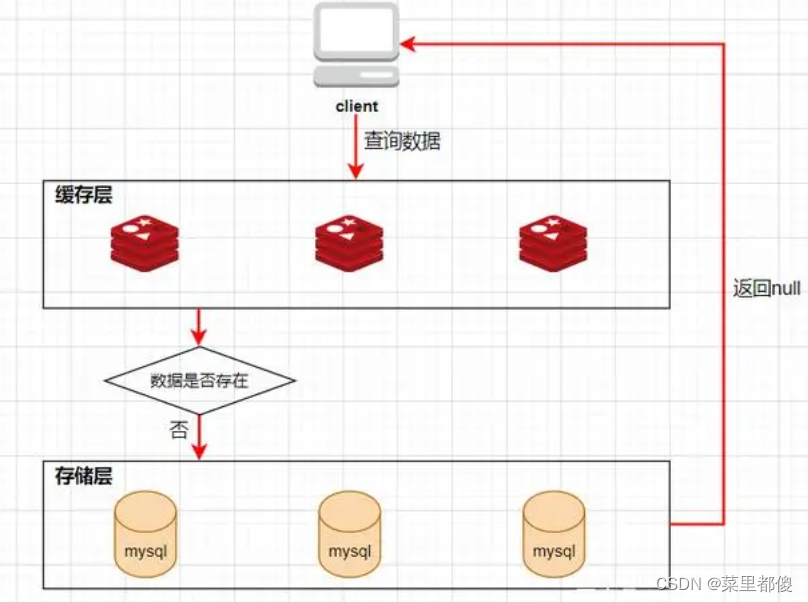
客户端发起一个查询请求的时候,首先去缓存中查询,如果数据在缓存中存在,则直接将缓存中的数据返回给客户端;如果数据在缓存中不存在,则继续查询数据库,如果数据在数据库中存在,则将该数据放入缓存中,并返回给客户端,如果数据在数据库中也不存在,则直接返回null给客户端。
一、什么是缓存穿透?
缓存穿透是指查询缓存和数据库都不存在的数据,导致每次查询都会透过缓存,直接查询数据库。
缓存穿透解决方案
1、缓存空对象
2、布隆过滤器
缓存空对象就是当数据库中查不到数据的时候,缓存一个空对象,然后给空对象设置一个很短的过期时间,从而达到减少数据库压力的目的。但这种解决方式有两个缺点:(1)缓存空对象浪费空间。(2)会导致数据库和缓存的数据不一致。
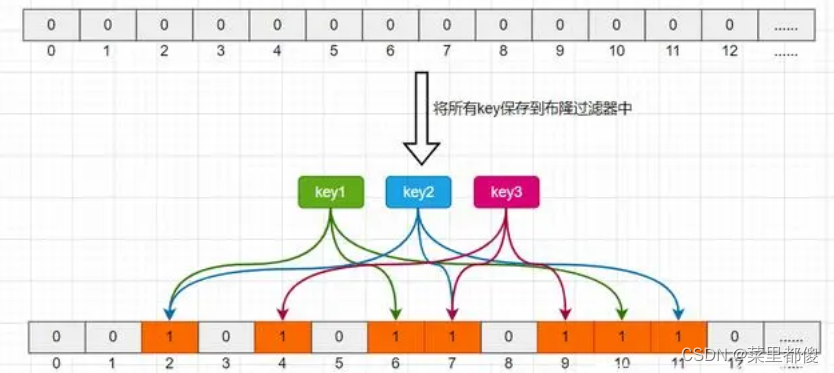
布隆过滤器是一种数据结构,相当于在客户端和缓存中间加了一个过滤器,布隆过滤器会对缓存中所有的key进行n次hash运算,这样可以得到n个位置,然后将这n个位置的元素置为1。但客户端查询时,也会对查询的key进行n次hash运算,得到n个位置,如果这n个位置全为1则,去缓存查询,否则返回空给客户端。
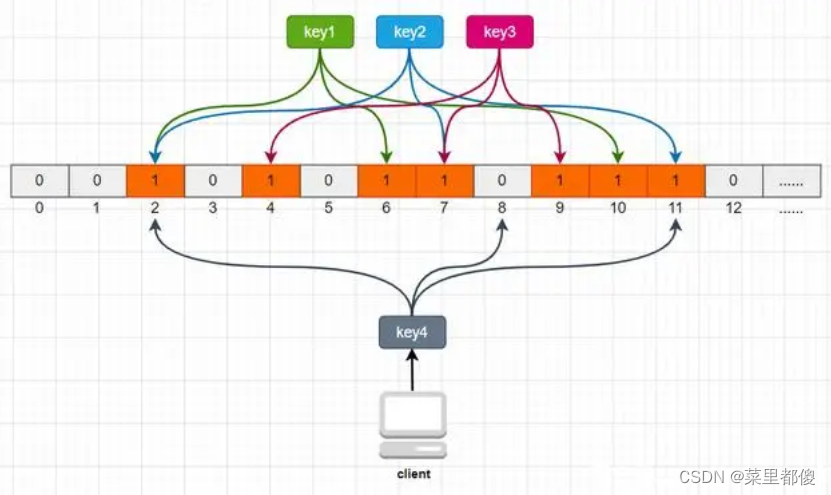
举个例子,比如我们一共有3个key,我们对这3个key分别进行3次hash运算,key1经过三次hash运算后的结果分别为2/6/10,那么就把布隆过滤器中下标为2/6/10的元素值更新为1,然后再分别对key2和key3做同样操作,结果如下图:
这样,当客户端查询时,也对查询的key做3次hash运算得到3个位置,然后看布隆过滤器中对应位置元素的值是否为1,如果所有对应位置元素的值都为1,就证明key在库中存在,则继续向下查询;如果3个位置中有任意一个位置的值不为1,那么就证明key在库中不存在,直接返回客户端空即可。如下图:
当客户端查询key4时,key4的3次hash运算中,有一个位置8的值为0,就说明key4在库中不存在,直接返回客户端空即可。
所以,布隆过滤器就相当于一个位于客户端与缓存层中间的拦截器一样,负责判断key是否在集合中存在。如下图:
布隆过滤器的好处就是解决了第一种缓存空值的不足,但布隆过滤器也存在缺陷,首先,它有误判的可能,比如在上面客户端查询key4的图中,假如key4经过3次hash运算得到的位置分别是2/4/6,由于这3个位置的值都是1,所以,布隆过滤器就认为key4在库中存在,进而继续向下查询了。所以,布隆过滤器判断存在的key实际上可能是不存在的,但布隆过滤器判断不存在的key是一定不存在的。它的第二个缺点就是删除元素比较难,比如现在要删除key2这个元素,那么需要将2/7/11三个位置的元素值改为0,但这样就会影响到key1和key3的判断。
2、什么是缓存击穿?
缓存击穿是指当缓存中的热点数据过期了,在该热点数据重新载入内存前有大量查询请求穿过缓存,直接查询数据库,导致数据库压力过大。
缓存击穿解决方案
(1)设置key永不过期。
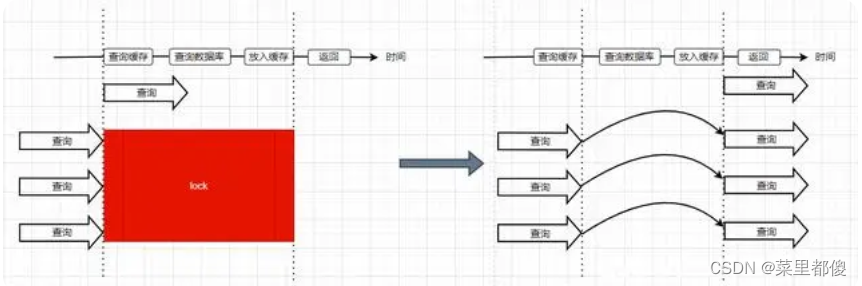
(2)使用分布式锁
第一种比较简单不再多说,第二种使用加分布锁的方式,锁对象是热点数据的key,同一时刻只能有一个线程获得锁对象,然后去查询数据库,把结果放到缓存中,释放锁。其他线程直接到缓存中取数据,不再需要查询数据库
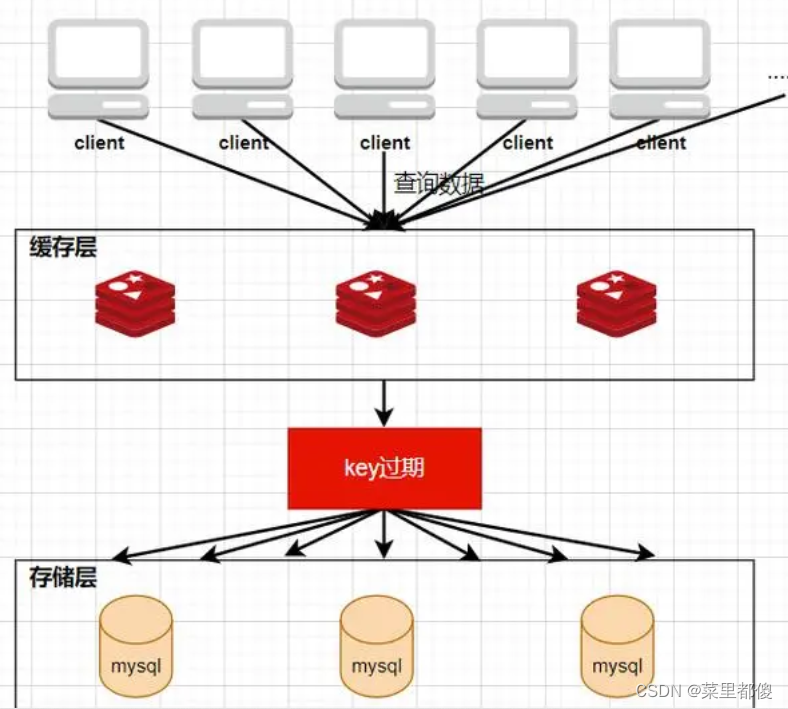
3、什么是缓存雪崩
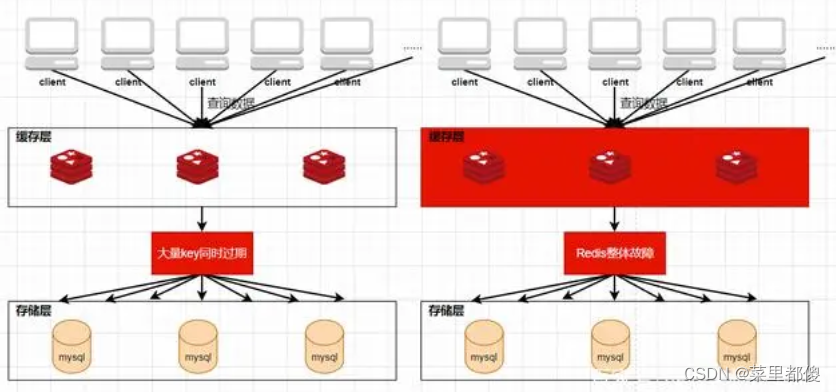
缓存雪崩是指当缓存中有大量的key在同一时刻过期,或者redis服务器宕机,导致大量的请求查询数据库,导致数据库压力加大。
缓存雪崩解决方案
(1)将每个key的过期时间打散,使他们的失效时间均匀分布
(2)部署redis时使用集群,主从复制,哨兵。