人机语音交互
人机语音交互的关键点一是唤醒词,之后就是语音活动检测,最后一步要解决“鸡尾酒会效应”。我正在探索语音活动检测的解决方案,遇到了这个工具包于是试了一下。这个项目是基于PyTorch的,与webrtcvad有着天壤之别,在嘈杂环境下解决语音活动检测还是得靠神经网络,而webrtcvad在嘈杂状态下是无法工作的,感兴趣的同学可以看一下,或许你们有更好的解决方案。
webrtcvad
# -*- coding: utf-8 -*-
import webrtcvad
import collections
import sys
import signal
import pyaudio
from array import array
from struct import pack
import wave
import time
class VCAD:
def __init__(self):
# 对音频数据进行定义
self.FORMAT = pyaudio.paInt16
self.CHANNELS = 1
self.RATE = 16000
self.CHUNK_DURATION_MS = 30 # supports 10, 20 and 30 (ms)
self.PADDING_DURATION_MS = 1500 # 1 sec jugement
self.CHUNK_SIZE = int(self.RATE * self.CHUNK_DURATION_MS / 1000) # chunk to read
self.CHUNK_BYTES = self.CHUNK_SIZE * 2 # 16bit = 2 bytes, PCM
self.NUM_PADDING_CHUNKS = int(self.PADDING_DURATION_MS / self.CHUNK_DURATION_MS)
# self.NUM_WINDOW_CHUNKS = int(240 / self.CHUNK_DURATION_MS)
self.NUM_WINDOW_CHUNKS = int(400 / self.CHUNK_DURATION_MS) # 400 ms/ 30ms ge
self.NUM_WINDOW_CHUNKS_END = self.NUM_WINDOW_CHUNKS * 2
self.START_OFFSET = int(self.NUM_WINDOW_CHUNKS * self.CHUNK_DURATION_MS * 0.5 * self.RATE)
def handle_int(self, sig, chunk):
global leave, got_a_sentence
leave = True
got_a_sentence = True
def record_to_file(self, path, data, sample_width):
"来自麦克风的记录并将结果数据输出到'path'"
# sample_width, data = record()
data = pack('<' + ('h' * len(data)), *data)
wf = wave.open(path, 'wb')
wf.setnchannels(1)
wf.setsampwidth(sample_width)
wf.setframerate(self.RATE)
wf.writeframes(data)
wf.close()
def normalize(self, snd_data):
"平均输出量"
MAXIMUM = 32767 # 16384
times = float(MAXIMUM) / max(abs(i) for i in snd_data)
r = array('h')
for i in snd_data:
r.append(int(i * times))
return r
def start(self):
pa = pyaudio.PyAudio()
vad = webrtcvad.Vad(3)
signal.signal(signal.SIGINT, self.handle_int)
got_a_sentence = False
leave = False
stream = pa.open(format=self.FORMAT,
channels=self.CHANNELS,
rate=self.RATE,
input=True,
start=False,
#input_device_index=2,
frames_per_buffer=self.CHUNK_SIZE)
while not leave:
ring_buffer = collections.deque(maxlen=self.NUM_PADDING_CHUNKS)
triggered = False
voiced_frames = []
ring_buffer_flags = [0] * self.NUM_WINDOW_CHUNKS
ring_buffer_index = 0
ring_buffer_flags_end = [0] * self.NUM_WINDOW_CHUNKS_END
ring_buffer_index_end = 0
buffer_in = ''
# WangS
raw_data = array('h')
index = 0
start_point = 0
StartTime = time.time()
print("* recording: ")
stream.start_stream()
while not got_a_sentence and not leave:
chunk = stream.read(self.CHUNK_SIZE)
# 增加 WangS
raw_data.extend(array('h', chunk))
index += self.CHUNK_SIZE
TimeUse = time.time() - StartTime
active = vad.is_speech(chunk, self.RATE)
sys.stdout.write('1' if active else '_')
ring_buffer_flags[ring_buffer_index] = 1 if active else 0
ring_buffer_index += 1
ring_buffer_index %= self.NUM_WINDOW_CHUNKS
ring_buffer_flags_end[ring_buffer_index_end] = 1 if active else 0
ring_buffer_index_end += 1
ring_buffer_index_end %= self.NUM_WINDOW_CHUNKS_END
# 起始点检测
if not triggered:
ring_buffer.append(chunk)
num_voiced = sum(ring_buffer_flags)
if num_voiced > 0.65 * self.NUM_WINDOW_CHUNKS:
sys.stdout.write(' Open ')
triggered = True
start_point = index - self.CHUNK_SIZE * 20 # 开始
# voiced_frames.extend(ring_buffer)
ring_buffer.clear()
# 结束点检测
else:
# voiced_frames.append(chunk)
ring_buffer.append(chunk)
num_unvoiced = self.NUM_WINDOW_CHUNKS_END - sum(ring_buffer_flags_end)
if num_unvoiced > 0.65 * self.NUM_WINDOW_CHUNKS_END or TimeUse > 10:
sys.stdout.write(' Close ')
triggered = False
got_a_sentence = True
sys.stdout.flush()
sys.stdout.write('\n')
# data = b''.join(voiced_frames)
stream.stop_stream()
print("* done recording")
got_a_sentence = False
# write to file
raw_data.reverse()
for index in range(start_point):
raw_data.pop()
raw_data.reverse()
raw_data = self.normalize(raw_data)
self.record_to_file("input.wav", raw_data, 2)
leave = True
stream.close()
pyannote 工具包安装
pip install pyannote.audio==1.1.1
https://github.com/pyannote/pyannote-audio
测试代码
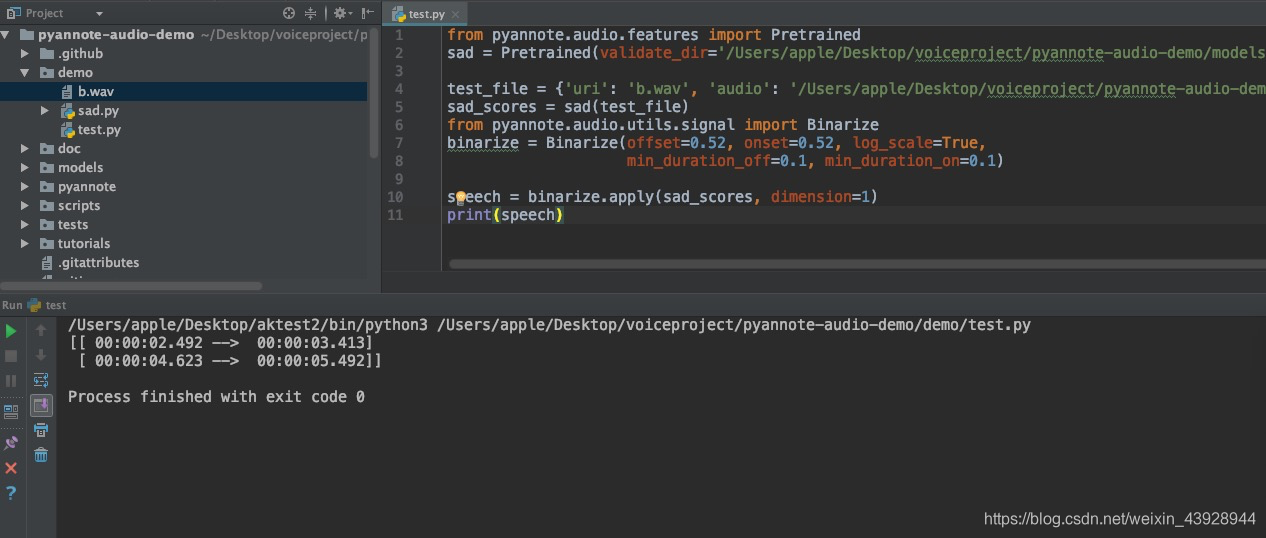
from pyannote.audio.features import Pretrained
sad = Pretrained(validate_dir='/Users/apple/Desktop/voiceproject/pyannote-audio-demo/models/sad/ami/712d7e3184/train/AMI.SpeakerDiarization.MixHeadset.train/validate/AMI.SpeakerDiarization.MixHeadset.development')
test_file = {'uri': 'b.wav', 'audio': '/Users/apple/Desktop/voiceproject/pyannote-audio-demo/demo/b.wav'}
sad_scores = sad(test_file)
from pyannote.audio.utils.signal import Binarize
binarize = Binarize(offset=0.52, onset=0.52, log_scale=True,
min_duration_off=0.1, min_duration_on=0.1)
speech = binarize.apply(sad_scores, dimension=1)
print(speech)
结果
挺准确的,但是这个工具包并不是我所期望的。
Speech activity detection
# obtain raw SAD scores (as `pyannote.core.SlidingWindowFeature` instance)
sad_scores = sad(test_file)
# binarize raw SAD scores
# NOTE: both onset/offset values were tuned on AMI dataset.
# you might need to use different values for better results.
from pyannote.audio.utils.signal import Binarize
binarize = Binarize(offset=0.52, onset=0.52, log_scale=True,
min_duration_off=0.1, min_duration_on=0.1)
# speech regions (as `pyannote.core.Timeline` instance)
speech = binarize.apply(sad_scores, dimension=1)
Speaker change detection
# obtain raw SCD scores (as `pyannote.core.SlidingWindowFeature` instance)
scd_scores = scd(test_file)
# detect peaks and return speaker homogeneous segments
# NOTE: both alpha/min_duration values were tuned on AMI dataset.
# you might need to use different values for better results.
from pyannote.audio.utils.signal import Peak
peak = Peak(alpha=0.10, min_duration=0.10, log_scale=True)
# speaker change point (as `pyannote.core.Timeline` instance)
partition = peak.apply(scd_scores, dimension=1)
Overlapped speech detection
# obtain raw OVL scores (as `pyannote.core.SlidingWindowFeature` instance)
ovl_scores = ovl(test_file)
# binarize raw OVL scores
# NOTE: both onset/offset values were tuned on AMI dataset.
# you might need to use different values for better results.
from pyannote.audio.utils.signal import Binarize
binarize = Binarize(offset=0.55, onset=0.55, log_scale=True,
min_duration_off=0.1, min_duration_on=0.1)
# overlapped speech regions (as `pyannote.core.Timeline` instance)
overlap = binarize.apply(ovl_scores, dimension=1)
感兴趣的话
- https://github.com/pyannote/pyannote-audio/tree/master/tutorials/pretrained/model
#demo源码
https://pan.baidu.com/s/1N-FwMAGt6-TnJTO7lQQyUg 密码: w3qf