1 介绍
年份:2023
期刊: CVPR
Luo Z, Liu Y, Schiele B, et al. Class-incremental exemplar compression for class-incremental learning[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2023: 11371-11380.
在类增量学习中,模型需要在有限的内存预算下,保存旧类别的示例(exemplars),并不断学习新类别。传统方法由于内存限制,只能保存少量示例,导致新旧类别数据不平衡,从而引发遗忘问题。本文提出通过压缩示例图像,增加示例数量,同时保留关键特征,缓解数据不平衡问题。
本文提出了一种基于回放的类增量学习(Class-Incremental Learning, CIL)算法,通过利用类别激活图(CAM)生成掩码来压缩旧类别的示例图像,从而在有限的内存预算下保存更多的示例。关键步骤包括:1) 使用CAM生成0-1掩码以定位图像中的判别性像素;2) 通过类增量掩码(CIM)模型自适应地优化掩码生成过程;3) 利用双层优化问题(Bilevel Optimization Problem, BOP)交替训练CIL模型和CIM模型。该算法属于基于回放的算法,并结合了基于注意力的机制(通过CAM)和基于优化的策略(通过BOP)。
2 创新点
- 提出了一种新的示例压缩方法
通过基于类别激活图(CAM)的掩码生成技术,仅对非判别性像素进行下采样,从而在不增加内存预算的情况下保存更多“多样本”压缩示例。这种方法突破了传统类增量学习中“少样本”示例的限制。 - 自适应掩码生成模型(CIM)
提出了一种类增量掩码(CIM)模型,能够自适应地生成针对不同类别和学习阶段的掩码。CIM通过参数化的掩码生成模型和双层优化问题(Bilevel Optimization Problem, BOP)进行端到端优化,解决了动态环境中最优掩码生成的挑战。 - 结合双层优化问题(BOP)进行训练
通过双层优化问题交替训练CIL模型和CIM模型,使得两者相互依赖且协同优化。这种优化策略能够动态调整掩码生成的参数,以适应不断增加的类别数量和学习阶段的变化。 - 针对高分辨率图像的优化
该方法特别适用于高分辨率图像数据集(如Food-101、ImageNet-100和ImageNet-1000),在这些数据集中,背景像素较多,通过压缩非判别性像素能够显著节省内存,同时保留关键的判别性特征。 - 显著提升类增量学习的性能
实验表明,使用CIM压缩的示例在多个高分辨率基准数据集上达到了新的最高准确率,例如在10阶段的ImageNet-1000上比现有最佳方法FOSTER高出4.8个百分点。这证明了该方法在缓解遗忘问题和提升模型性能方面的有效性。 - 作为一种即插即用的模块
CIM可以灵活地集成到现有的类增量学习方法中(如LUCIR、DER和FOSTER),并显著提升其性能。这种模块化的特性使得该方法具有广泛的适用性和扩展性。 - 针对不同大小目标的自适应策略
CIM能够根据目标的大小(小、中、大)自适应调整掩码生成策略,特别是对于小目标,由于其背景像素更多,因此从压缩中受益更大。
3 相关研究
类增量学习(Class-Incremental Learning, CIL)
- 正则化方法(Regularization-based methods)
- 这些方法通过在目标函数中加入正则化项来惩罚新旧模型之间的差异,以缓解遗忘问题。例如,通过比较输出logits [23, 36]、中间特征 [12, 17, 24, 39] 和预测热图 [10] 来实现。
- [23] Zhizhong Li and Derek Hoiem. Learning without Forgetting. PAMI, 2017.
- [36] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. iCaRL: Incremental Classifier and Representation Learning. CVPR, 2017.
- [12] Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled Outputs Distillation for Small-Tasks Incremental Learning. ECCV, 2020.
- [17] Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a Unified Classifier Incrementally via Rebalancing. CVPR, 2019.
- [24] Yaoyao Liu, Yingying Li, Bernt Schiele, and Qianru Sun. Online Hyperparameter Optimization for Class-Incremental Learning. AAAI, 2023.
- [10] Prithviraj Dhar, Rajat Vikram Singh, Kuan-Chuan Peng, Ziyan Wu, and Rama Chellappa. Learning without Memorizing. CVPR, 2019.
- [39] Christian Simon, Piotr Koniusz, and Mehrtash Harandi. On Learning the Geodesic Path for Incremental Learning. CVPR, 2021.
- 参数隔离方法(Parameter-isolation-based methods)
- 这些方法通过在每个新的增量阶段增加模型参数,防止新知识覆盖旧知识。一些方法通过逐步扩展神经网络的大小来学习新数据 [18, 37, 42, 45, 46],而另一些方法则通过冻结部分网络参数以保持旧类别的知识 [1, 21, 25, 47]。
- [18] Shenyang Huang, Vincent François-Lavet, and Guillaume Rabusseau. Neural Architecture Search for Class-Incremental Learning. arXiv, 2019.
- [37] Andrei A Rusu, Neil C Rabinowitz, Guillaume Desjardins, Hubert Soyer, James Kirkpatrick, Koray Kavukcuoglu, Razvan Pascanu, and Raia Hadsell. Progressive Neural Networks. arXiv, 2016.
- [42] Fu-Yun Wang, Da-Wei Zhou, Han-Jia Ye, and De-Chuan Zhan. FOSTER: Feature Boosting and Compression for Class-Incremental Learning. arXiv, 2022.
- [45] Ju Xu and Zhanxing Zhu. Reinforced Continual Learning. NeurIPS, 2018.
- [46] Shipeng Yan, Jiangwei Xie, and Xuming He. DER: Dynamically Expandable Representation for Class Incremental Learning. CVPR, 2021.
- [47] Friedemann Zenke, Ben Poole, and Surya Ganguli. Continual Learning through Synaptic Intelligence. ICML, 2017.
- 回放方法(Replay-based methods)
- 这些方法假设有限的内存预算允许保存少量旧类别的示例(exemplars),并使用这些示例在每个新阶段重新训练模型 [12, 17, 26, 27, 36, 43, 44]。这些方法通常包括两个步骤:在所有新类别数据和旧类别示例上训练模型,以及使用平衡子集进行微调 [12, 17, 25, 26, 46]。
- [12] Arthur Douillard, Matthieu Cord, Charles Ollion, Thomas Robert, and Eduardo Valle. Podnet: Pooled Outputs Distillation for Small-Tasks Incremental Learning. ECCV, 2020.
- [17] Saihui Hou, Xinyu Pan, Chen Change Loy, Zilei Wang, and Dahua Lin. Learning a Unified Classifier Incrementally via Rebalancing. CVPR, 2019.
- [26] Yaoyao Liu, Bernt Schiele, and Qianru Sun. RMM: Reinforced Memory Management for Class-Incremental Learning. NeurIPS, 2021.
- [27] Yaoyao Liu, Yuting Su, An-An Liu, Bernt Schiele, and Qianru Sun. Mnemonics Training: Multi-Class Incremental Learning without Forgetting. CVPR, 2020.
- [36] Sylvestre-Alvise Rebuffi, Alexander Kolesnikov, Georg Sperl, and Christoph H Lampert. iCaRL: Incremental Classifier and Representation Learning. CVPR, 2017.
- [43] Liyuan Wang, Xingxing Zhang, Kuo Yang, Longhui Yu, Chongxuan Li, Lanqing Hong, Shifeng Zhang, Zhenguo Li, Yi Zhong, and Jun Zhu. Memory Replay with Data Compression for Continual Learning. ICLR, 2022.
- [44] Yue Wu, Yinpeng Chen, Lijuan Wang, Yuancheng Ye, Zicheng Liu, Yandong Guo, and Yun Fu. Large Scale Incremental Learning. CVPR, 2019.
类别激活图(Class Activation Map, CAM)
- CAM是一种简单而有效的弱监督目标定位方法,仅使用图像级标签即可生成像素级掩码。通过特征图和分类器权重的组合,CAM能够定位图像中的前景目标 [49]。此外,还有CAM的改进版本,如Grad-CAM [38]、ReCAM [8] 和 AdvCAM [22]。本文基于原始的CAM实现,因为它计算简单高效。
- [49] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, and Antonio Torralba. Learning Deep Features for Discriminative Localization. CVPR, 2016.
- [38] Ramprasaath R Selvaraju, Michael Cogswell, Abhishek Das, Ramakrishna Vedantam, Devi Parikh, and Dhruv Batra. Grad-CAM: Visual Explanations from Deep Networks via Gradient-based Localization. ICCV, 2017.
- [8] Zhaozheng Chen, Tan Wang, Xiongwei Wu, Xian-Sheng Hua, Hanwang Zhang, and Qianru Sun. Class Re-activation Maps for Weakly-Supervised Semantic Segmentation. CVPR, 2022.
- [22] Jungbeom Lee, Eunji Kim, and Sungroh Yoon. Antiadversarially Manipulated Attributions for Weakly and Semisupervised Semantic Segmentation. CVPR, 2021.
双层优化问题(Bilevel Optimization Problems, BOP)
- BOP旨在解决嵌套优化问题,其中外层优化依赖于内层优化的结果。BOP在超参数选择 [29] 和元学习 [13] 等领域表现出色。在CIL任务中,已有工作利用BOP交替优化CIL模型和参数化示例 [27],或学习CIL模型中可塑和弹性分支的聚合权重 [25]。本文中,作者使用BOP来优化CIL模型和参数化的类增量掩码(CIM)模型,CIM作为CIL模型的一个插件分支,使用较少的额外参数,优化过程快速高效。
- [7] Can Chen, Xi Chen, Chen Ma, Zixuan Liu, and Xue Liu. Gradient-based Bi-level Optimization for Deep Learning: A Survey. arXiv, 2022.
- [13] Chelsea Finn, Pieter Abbeel, and Sergey Levine. Model-Agnostic Meta-Learning for Fast Adaptation of Deep Networks. ICML, 2017.
- [29] Dougal Maclaurin, David Duvenaud, and Ryan Adams. Gradient-based Hyperparameter Optimization through Reversible Learning. ICML, 2015.
- [40] Ankur Sinha, Pekka Malo, and Kalyanmoy Deb. A Review on Bilevel Optimization: From Classical to Evolutionary Approaches and Applications. IEEE Transactions on Evolutionary Computation, 2017.
4 算法
4.1 算法原理
4.1.1 核心原理:基于CAM的示例压缩
(1)类别激活图(CAM)
类别激活图(CAM)是一种弱监督目标定位方法,通过模型的特征图和分类器权重生成热图,定位图像中对分类有贡献的判别性区域(通常是前景目标)。CAM的生成公式为:
M CAM = A − min ( A ) max ( A ) − min ( A ) , A = ω y T F ( x ; θ ) M_{\text{CAM}} = \frac{A - \min(A)}{\max(A) - \min(A)}, \quad A = \omega_{y}^T F(x; \theta) MCAM=max(A)−min(A)A−min(A),A=ωyTF(x;θ)
其中, F ( x ; θ ) F(x; \theta) F(x;θ)是特征提取器的输出, ω y \omega_{y} ωy是对应类别的分类器权重。通过硬阈值化(hard thresholding),CAM可以生成一个0-1掩码,标记判别性像素。
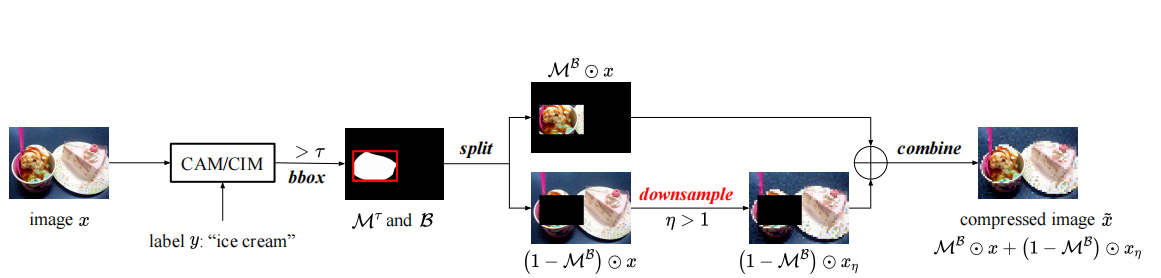
(2)样本压缩
基于CAM生成的掩码,算法仅对非判别性像素(背景区域)进行下采样,保留判别性像素的原始分辨率。具体步骤如下:
- 生成掩码:通过CAM生成0-1掩码,标记判别性像素。
- 生成边界框(BBox):计算掩码中所有1的最小外接矩形,用于界定判别性区域。
- 压缩图像:对边界框外的像素进行下采样,保留边界框内的像素。压缩后的图像可以表示为:
x ~ = M B ⊙ x + ( 1 − M B ) ⊙ x η \tilde{x} = M_B \odot x + (1 - M_B) \odot x_{\eta} x~=MB⊙x+(1−MB)⊙xη
其中, M B M_B MB是边界框对应的二值掩码, x η x_{\eta} xη是下采样后的图像。
4.1.2 自适应掩码生成(Class-Incremental Masking, CIM)
在类增量学习的动态环境中,不同类别和学习阶段需要不同的掩码生成策略。因此,本文提出了一个自适应掩码生成模型——类增量掩码(CIM),通过双层优化问题(Bilevel Optimization Problem, BOP)进行端到端优化。
(1)CIM网络设计
CIM通过在原始网络中添加一个可学习的激活函数分支(如Padé Activation Units, PAU),生成自适应掩码。该分支的权重直接从原始网络复制,仅激活函数是可学习的,从而实现对不同类别和阶段的自适应掩码生成。
(2)双层优化(Bilevel Optimization)
CIM的优化分为两个层次:
- 任务级优化(Task-level Optimization):优化CIL模型,训练新类别数据和压缩后的旧类别示例。
( θ i , ω i ) ← ( θ i , ω i ) − λ ∇ θ , ω L CIL ( E ~ 0 : i − 1 ∪ D i ; θ i , ω i ) (\theta_i, \omega_i) \leftarrow (\theta_i, \omega_i) - \lambda \nabla_{\theta,\omega} L_{\text{CIL}}(\tilde{E}_{0:i-1} \cup D_i; \theta_i, \omega_i) (θi,ωi)←(θi,ωi)−λ∇θ,ωLCIL(E~0:i−1∪Di;θi,ωi)
- 掩码级优化(Mask-level Optimization):优化CIM模型,生成自适应掩码,使得压缩后的示例在验证集上表现最优。
min ϕ i L val ( D i ; θ i ∗ , ω i ) + μ R ( ϕ i ) s.t. θ i ∗ = arg min θ i L train ( E ~ 0 : i − 1 ∪ D ~ i ( ϕ i ) ; θ i , ω i ) \begin{aligned} \min_{\phi_i} & \quad L_{\text{val}}(D_i; \theta_i^*, \omega_i) + \mu R(\phi_i) \\ \text{s.t.} & \quad \theta_i^* = \arg\min_{\theta_i} L_{\text{train}}(\tilde{E}_{0:i-1} \cup \tilde{D}_i(\phi_i); \theta_i, \omega_i) \end{aligned} ϕimins.t.Lval(Di;θi∗,ωi)+μR(ϕi)θi∗=argθiminLtrain(E~0:i−1∪D~i(ϕi);θi,ωi)
其中, R ( ϕ i ) R(\phi_i) R(ϕi)是正则化项,用于控制掩码的覆盖范围,减少内存占用。
4.2 算法步骤
输入
- 当前阶段的新类别数据 D i D_i Di
- 前一阶段保存的压缩示例 E ~ 0 : i − 1 \tilde{E}_{0:i-1} E~0:i−1
- 上一阶段的CIL模型参数 ( θ i − 1 , ω i − 1 ) (\theta_{i-1}, \omega_{i-1}) (θi−1,ωi−1)
- 上一阶段的CIM模型参数 ϕ i − 1 \phi_{i-1} ϕi−1
输出
- 当前阶段的压缩示例 E ~ i \tilde{E}_i E~i
- 更新后的CIL模型参数 ( θ i , ω i ) (\theta_i, \omega_i) (θi,ωi)
- 更新后的CIM模型参数 ϕ i \phi_i ϕi
步骤 1:初始化
- 使用上一阶段的参数初始化当前阶段的CIL模型和CIM模型:
( θ i , ω i ) ← ( θ i − 1 , ω i − 1 ) , ϕ i ← ϕ i − 1 (\theta_i, \omega_i) \leftarrow (\theta_{i-1}, \omega_{i-1}), \quad \phi_i \leftarrow \phi_{i-1} (θi,ωi)←(θi−1,ωi−1),ϕi←ϕi−1
步骤 2:任务级优化(Task-level Optimization)
- 使用压缩后的旧类别示例和新类别数据训练CIL模型:
( θ i , ω i ) ← ( θ i , ω i ) − λ ∇ θ , ω L CIL ( E ~ 0 : i − 1 ∪ D i ; θ i , ω i ) (\theta_i, \omega_i) \leftarrow (\theta_i, \omega_i) - \lambda \nabla_{\theta, \omega} L_{\text{CIL}}(\tilde{E}_{0:i-1} \cup D_i; \theta_i, \omega_i) (θi,ωi)←(θi,ωi)−λ∇θ,ωLCIL(E~0:i−1∪Di;θi,ωi)
其中, L CIL L_{\text{CIL}} LCIL是CIL任务的损失函数, λ \lambda λ是学习率。
步骤 3:生成掩码并压缩新类别数据
- 使用当前阶段的CIM模型为新类别数据生成掩码,并压缩新类别数据:
D ~ i ( ϕ i ) ← Compress ( D i , ϕ i ) \tilde{D}_i(\phi_i) \leftarrow \text{Compress}(D_i, \phi_i) D~i(ϕi)←Compress(Di,ϕi)
具体压缩过程如下:
- 通过CAM生成掩码:
M CAM = A − min ( A ) max ( A ) − min ( A ) , A = ω y T F ( x ; θ i ) M_{\text{CAM}} = \frac{A - \min(A)}{\max(A) - \min(A)}, \quad A = \omega_{y}^T F(x; \theta_i) MCAM=max(A)−min(A)A−min(A),A=ωyTF(x;θi)
- 应用硬阈值化生成0-1掩码 M τ = I ( M CAM > τ ) M_{\tau} = I(M_{\text{CAM}} > \tau) Mτ=I(MCAM>τ)。
- 计算掩码的边界框(BBox):
B = [ min h , min w ; max h , max w ] for ( h , w ) : M τ ( h , w ) = 1 B = [\min h, \min w; \max h, \max w] \quad \text{for} \ (h,w): M_{\tau}(h,w) = 1 B=[minh,minw;maxh,maxw]for (h,w):Mτ(h,w)=1
- 对边界框外的像素进行下采样:
x ~ = M B ⊙ x + ( 1 − M B ) ⊙ x η \tilde{x} = M_B \odot x + (1 - M_B) \odot x_{\eta} x~=MB⊙x+(1−MB)⊙xη
其中, M B M_B MB是边界框对应的二值掩码, x η x_{\eta} xη是下采样后的图像。
步骤 4:掩码级优化(Mask-level Optimization)
- 通过双层优化更新CIM模型参数:
- 内层优化:使用压缩后的数据训练临时CIL模型:
θ i + ← θ i − β 1 ∇ θ L CIL ( E ~ 0 : i − 1 ∪ D ~ i ( ϕ i ) ; θ i , ω i ) \theta_i^+ \leftarrow \theta_i - \beta_1 \nabla_{\theta} L_{\text{CIL}}(\tilde{E}_{0:i-1} \cup \tilde{D}_i(\phi_i); \theta_i, \omega_i) θi+←θi−β1∇θLCIL(E~0:i−1∪D~i(ϕi);θi,ωi)
- 外层优化:更新CIM模型参数,使得临时模型在原始数据上表现最优:
ϕ i ← ϕ i − β 2 ∇ ϕ [ L CE ( D i ; θ i + , ω i ) + μ R ( ϕ i ) + μ ′ L CE ( E ~ 0 : i − 1 ∪ D i ; θ i , ϕ i , ω i ) ] \phi_i \leftarrow \phi_i - \beta_2 \nabla_{\phi} \left[ L_{\text{CE}}(D_i; \theta_i^+, \omega_i) + \mu R(\phi_i) + \mu' L_{\text{CE}}(\tilde{E}_{0:i-1} \cup D_i; \theta_i, \phi_i, \omega_i) \right] ϕi←ϕi−β2∇ϕ[LCE(Di;θi+,ωi)+μR(ϕi)+μ′LCE(E~0:i−1∪Di;θi,ϕi,ωi)]
其中, L CE L_{\text{CE}} LCE是交叉熵损失, R ( ϕ i ) R(\phi_i) R(ϕi)是正则化项, μ \mu μ和 μ ′ \mu' μ′是权重。
步骤 5:选择并保存压缩示例
- 使用压缩后的数据选择新的示例保存到内存中:
E ~ i ← SelectExemplars ( D ~ i , budget ) \tilde{E}_i \leftarrow \text{SelectExemplars}(\tilde{D}_i, \text{budget}) E~i←SelectExemplars(D~i,budget)
示例选择方法可以采用特征聚类(如herding)。
步骤 6:输出结果
- 输出当前阶段的压缩示例、更新后的CIL模型和CIM模型参数:
Output: E ~ i , ( θ i , ω i ) , ϕ i \text{Output: } \tilde{E}_i, (\theta_i, \omega_i), \phi_i Output: E~i,(θi,ωi),ϕi
5 实验分析
1. 与现有方法的对比
- 实验结果表明,本文提出的CIM方法在多个类增量学习(CIL)基准数据集上显著优于现有方法。例如,在ImageNet-1000数据集的10阶段设置中,CIM方法比当前最佳方法FOSTER [42] 提高了4.8个百分点的准确率。
- 在Food-101和ImageNet-100数据集上,CIM方法也一致优于FOSTER,平均准确率分别提高了2.1和1.4个百分点。
- 在更严格的内存限制下(如ImageNet-1000的5k样本预算),CIM方法的提升更为显著,表明其在有限内存下保存更多高质量示例的能力。
2. 不同数据集的性能表现
- Food-101:在学习从零开始(LFS)和学习从一半(LFH)的设置中,CIM方法均优于基线方法。例如,在LFH设置的N=25时,CIM方法比FOSTER提高了3.3个百分点。
- ImageNet-100:在LFS设置中,CIM方法在N=10时比FOSTER提高了1.4个百分点。
- ImageNet-1000:在LFS设置中,CIM方法在5k样本预算下比FOSTER提高了4.5个百分点,而在20k样本预算下提高了1.0个百分点。
3. 不同协议下的性能
- 在学习从零开始(LFS)协议中,CIM方法在不同阶段数量(N=5, 10, 20)下均表现出色,尤其在阶段数量较多时提升更为明显。
- 在学习从一半(LFH)协议中,CIM方法在不同阶段数量(N=5, 10, 25)下也显著优于基线方法,表明其在动态环境中适应性强。
4. 消融研究
- 消融实验验证了CIM方法中各个组件的有效性:
- 压缩策略的有效性:使用随机激活区域压缩的方法优于不使用激活区域的方法,表明基于模型激活的压缩策略是有效的。
- 自适应掩码生成(CIM):通过双层优化生成的自适应掩码比手动选择阈值或固定阈值的方法表现更好。
- 全局双层优化(BOP):使用全局双层优化的CIM方法比联合训练或仅使用最后一层可学习激活函数的方法表现更好。
5. 与其他压缩方法的对比
- 与Mnemonics [27]和MRDC [43]的对比:CIM方法在所有设置下均优于这两种方法。Mnemonics固定了示例数量,而MRDC使用了均匀压缩策略,没有考虑不同类别在不同阶段的特性。
- CIM方法的优势:CIM通过自适应压缩策略,在不牺牲示例判别性的同时,增加了示例的数量和多样性。
6. 不同大小目标的性能
- 小目标受益更多:在ImageNet-100数据集中,CIM方法对小目标的提升最为显著,平均准确率提高了3.87个百分点。这是因为小目标的图像中背景像素更多,压缩后节省的内存更多。
- 中等和大目标也有所提升:对于中等和大目标,CIM方法分别提高了3.65和2.33个百分点,表明其对不同大小的目标均有效。
7. 结论
- CIM方法作为一种即插即用的模块,可以集成到现有的类增量学习方法中,显著提升其性能。
- 实验结果表明,CIM方法在缓解遗忘问题、提高模型泛化能力以及适应动态环境方面表现出色,尤其在高分辨率图像数据集上效果显著。
6 思考
(1)本文提出的方法基于类增量掩码(CIM),仅对图像中的非判别性像素进行下采样,保留判别性像素的原始分辨率。
- 选择性压缩:通过类别激活图(CAM)生成掩码,仅对背景或非判别性区域进行压缩,保留关键特征。
- 优势:在不增加内存预算的情况下,可以保存更多的示例,同时保留判别性特征,缓解数据不平衡问题。
(2)如何确保生成的掩码(mask)能够准确区分判别性像素和非判别性像素?
- 基于CAM的掩码生成:本文使用类别激活图(CAM)来生成掩码,CAM通过特征图和分类器权重的组合,能够高亮显示对分类任务有贡献的判别性像素(通常是前景目标)。通过硬阈值化,CAM可以生成0-1掩码,准确区分判别性像素和非判别性像素。
- 自适应阈值调整:为了适应不同类别和学习阶段的需求,本文提出了类增量掩码(CIM)模型。CIM通过双层优化问题(Bilevel Optimization Problem, BOP)动态调整掩码生成的阈值,从而更准确地定位判别性像素。
(3)自适应掩码生成模型(CIM)如何动态调整以适应不同类别和学习阶段的需求?
- 双层优化问题(Bilevel Optimization Problem, BOP):CIM通过双层优化动态调整掩码生成策略。内层优化训练一个临时模型,使用压缩后的数据进行训练;外层优化则根据临时模型在原始数据上的验证损失调整CIM的参数。这种优化方式能够根据不同的类别和学习阶段自适应地调整掩码生成策略。
- 可学习的激活函数:CIM模型在原始网络中添加了可学习的激活函数(如Padé Activation Units, PAU),这些激活函数能够根据不同的类别和学习阶段动态调整,从而生成更适应当前任务的掩码。
(4)在有限的内存预算下,如何平衡示例的数量和质量?
- 选择性压缩策略:本文提出的选择性压缩方法仅对非判别性像素进行下采样,保留判别性像素的原始分辨率。这种策略能够在不显著降低示例质量的情况下,大幅减少内存占用,从而保存更多的示例。
- 自适应压缩率:CIM模型能够根据不同的类别和学习阶段动态调整压缩率。例如,在学习阶段较早时,模型可能需要保留更多的判别性特征,因此压缩率较低;而在学习阶段较晚时,模型可以适当增加压缩率以保存更多的示例。
(5)如何处理压缩引入的伪影(compression artifacts),以避免对后续学习阶段的影响?
- 数据增强策略:为了缓解压缩引入的伪影,本文在训练过程中对部分数据应用相同的压缩策略。这种数据增强方法使模型能够学习到对压缩伪影的不变性,从而在后续学习阶段更好地适应压缩后的示例。
- 边界框优化:通过生成边界框(BBox)来限制压缩区域,减少压缩伪影的影响。边界框将判别性区域“重塑”为矩形,便于对背景区域进行统一的下采样操作,从而减少伪影的产生。
(6)算法在低分辨率数据集(如CIFAR-100)上的适用性如何?
- 低分辨率数据集的特点:低分辨率数据集(如CIFAR-100)的图像分辨率较低(32×32像素),背景像素较少,因此压缩的意义有限。在这种情况下,图像压缩可能不会带来显著的内存节省,甚至可能引入不必要的计算开销。
- 算法的局限性:本文的算法主要针对高分辨率图像数据集(如ImageNet),在低分辨率数据集上的适用性可能受到限制。例如,CIM模型在低分辨率图像上可能无法有效区分判别性像素和非判别性像素。
- 可能的改进方向:
- 调整压缩策略:对于低分辨率数据集,可以考虑调整压缩策略,例如减少压缩率或直接保存更多原始示例。
- 结合其他优化方法:在低分辨率数据集上,可以结合其他类增量学习方法(如参数隔离或正则化方法)来提升性能。
- 实验验证:在低分辨率数据集上进行实验,验证CIM方法的有效性,并根据实验结果调整算法。