1、开启慢查询日志
首先,第一步,你需要去查看一下 Redis 的慢日志(slowlog)。
Redis 提供了慢日志命令的统计功能,它记录了有哪些命令在执行时耗时比较久。
查看 Redis 慢日志之前,你需要设置慢日志的阈值。例如,设置慢日志的阈值为 5 毫秒,并且保留最近 500 条慢日志记录:
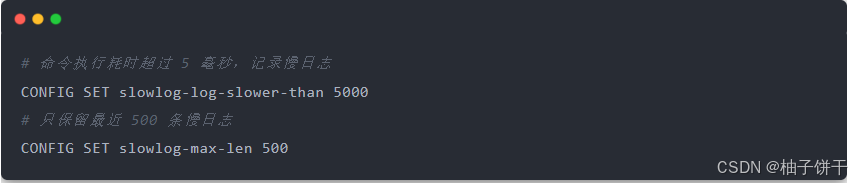
设置完成之后,所有执行的命令如果操作耗时超过了 5 毫秒,都会被 Redis 记录下来。
此时,你可以执行以下命令,就可以查询到最近记录的慢日志:
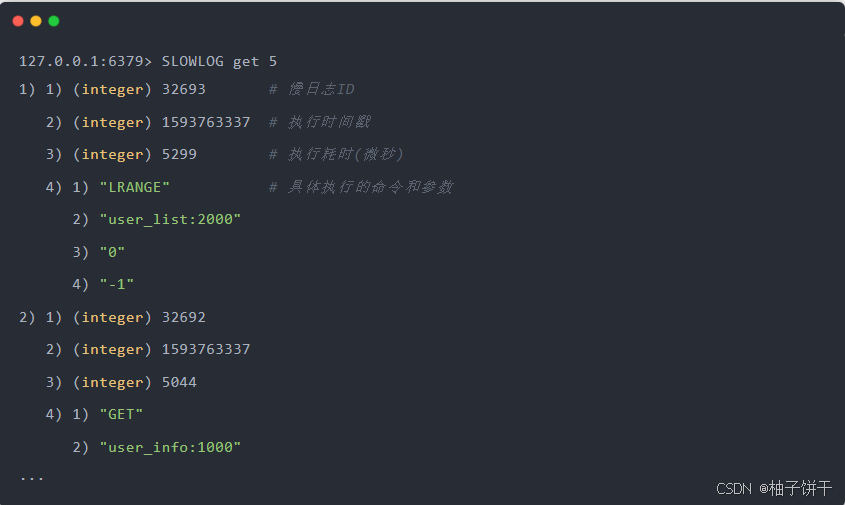
通过查看慢日志,我们就可以知道在什么时间点,执行了哪些命令比较耗时。
上面结果分析展示:
第一种情况导致变慢的原因在于,Redis 在操作内存数据时,时间复杂度过高,要花费更多的 CPU 资源。
第二种情况导致变慢的原因在于,Redis 一次需要返回给客户端的数据过多,更多时间花费在数据协议的组装和网络传输过程中。
2、避免使用O(N) 等复杂命令
如果你的应用程序执行的 Redis 命令有以下特点,那么有可能会导致操作延迟变大:
经常使用 O(N) 以上复杂度的命令,例如 SORT、SUNION、ZUNIONSTORE 聚合类命令
使用 O(N) 复杂度的命令,但 N 的值非常大
另外,我们还可以从资源使用率层面来分析,如果你的应用程序操作 Redis 的 OPS(即每秒操作次数) 不是很大,但 Redis 实例的 CPU 使用率却很高,那么很有可能是使用了复杂度过高的命令导致的。
除此之外,我们都知道,Redis 是单线程处理客户端请求的,如果你经常使用以上命令,那么当 Redis 处理客户端请求时,一旦前面某个命令发生耗时,就会导致后面的请求发生排队,对于客户端来说,响应延迟也会变长。
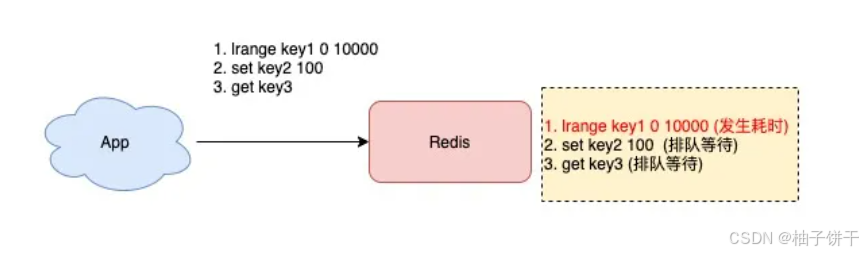
3、以上问题处理方法
尽量不使用 O(N) 以上复杂度过高的命令,对于数据的聚合操作,放在客户端做
执行 O(N) 命令,保证 N 尽量的小(推荐 N <= 300),每次获取尽量少的数据,让 Redis 可以及时处理返回