【NLP高频面题 - LLM架构篇】大模型为何使用RMSNorm代替LayerNorm?
重要性:★★★ 💯
NLP Github 项目:
-
NLP 项目实践:fasterai/nlp-project-practice
介绍:该仓库围绕着 NLP 任务模型的设计、训练、优化、部署和应用,分享大模型算法工程师的日常工作和实战经验
-
AI 藏经阁:https://gitee.com/fasterai/ai-e-book
介绍:该仓库主要分享了数百本 AI 领域电子书
-
AI 算法面经:fasterai/nlp-interview-handbook#面经
介绍:该仓库一网打尽互联网大厂NLP算法面经,算法求职必备神器
-
NLP 剑指Offer:https://gitee.com/fasterai/nlp-interview-handbook
介绍:该仓库汇总了 NLP 算法工程师高频面题
大模型使用RMSNorm代替LayerNorm是为了降低计算量。
均方根归一化 (Root Mean Square Layer Normalization,RMS Norm)论文中提出,层归一化(Layer Normalization)之所以有效,关键在于其实现的缩放不变性(Scale Invariance),而非平移不变性(Translation Invariance)。
基于此,RMSNorm在设计时简化了传统层归一化的方法。它移除了层归一化中的平移操作(即去掉了均值的计算和减除步骤),只保留了缩放操作。
因此 RMSNorm 主要是在 LayerNorm 的基础上去掉了减均值这一项,其计算效率更高且没有降低性能。
RMS Norm针对输入向量 x,RMSNorm 函数计算公式如下:
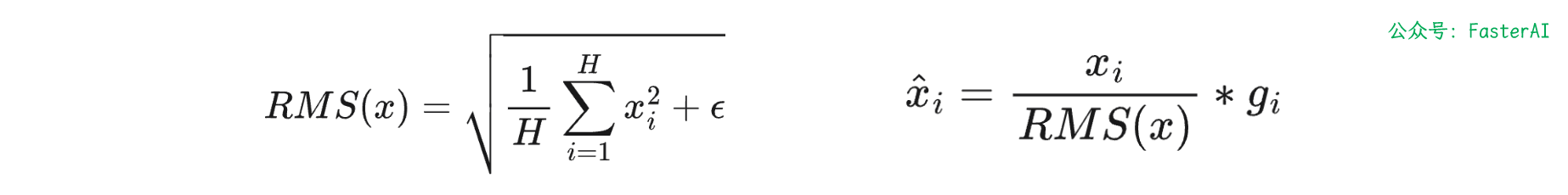
层归一化(LayerNorm)的计算公式:
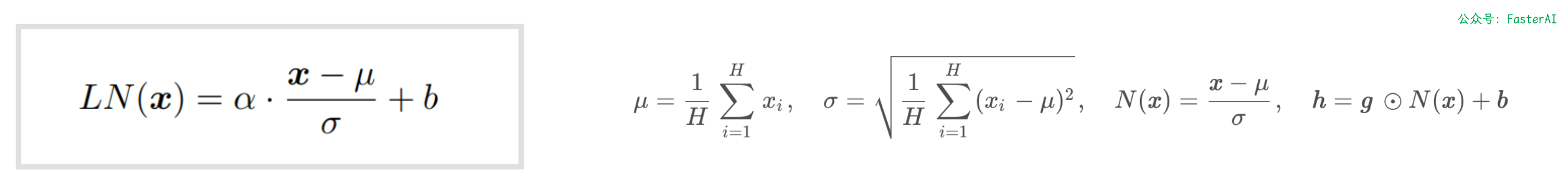
经过对比,可以清楚的看到,RMSNorm 主要是在 LayerNorm 的基础上去掉了减均值这一项,计算量明显降低。
RMSNorm 层归一化的代码实现:

NLP 大模型高频面题汇总
NLP基础篇
-
【NLP 面试宝典 之 模型分类】 必须要会的高频面题
-
【NLP 面试宝典 之 神经网络】 必须要会的高频面题
-
【NLP 面试宝典 之 主动学习】 必须要会的高频面题
-
【NLP 面试宝典 之 超参数优化】 必须要会的高频面题
-
【NLP 面试宝典 之 正则化】 必须要会的高频面题
-
【NLP 面试宝典 之 过拟合】 必须要会的高频面题
-
【NLP 面试宝典 之 Dropout】 必须要会的高频面题
-
【NLP 面试宝典 之 EarlyStopping】 必须要会的高频面题
-
【NLP 面试宝典 之 标签平滑】 必须要会的高频面题
-
【NLP 面试宝典 之 Warm up 】 必须要会的高频面题
-
【NLP 面试宝典 之 置信学习】 必须要会的高频面题
-
【NLP 面试宝典 之 伪标签】 必须要会的高频面题
-
【NLP 面试宝典 之 类别不均衡问题】 必须要会的高频面题
-
【NLP 面试宝典 之 交叉验证】 必须要会的高频面题
-
【NLP 面试宝典 之 词嵌入】 必须要会的高频面题
-
【NLP 面试宝典 之 One-Hot】 必须要会的高频面题
-
…