Multi-agent reinforcement learning for Markov routing games A new modeling paradigm for dynamic traffic assignment
这篇文章很久之前就搜到过,但是一直没读,最近有点lazy,然后这篇文章发表在TRC,最近好像一直在读TRC的文章。我对强化学习一直有很大兴趣,这篇文章把强化学习和动态分配结合到一起了,一起读一下吧。作者是哥伦比亚大学的,非常牛批!
背景&动机
当一个人在道路网络中动态选择路径时,其他人也可能这样做以争夺有限的道路资源。因此,同时对许多驾驶员的动态路线选择进行建模至关重要。本文旨在开发一种博弈论范式,对原子自私代理之间的动态路由博弈中的学习行为和系统平衡过程进行建模,同时考虑驾驶员之间的竞争。下面作者介绍了一些有关强化学习在交通领域的做法
基于强化学习的路线选择
根据如何定义代理的动作,可以将基于 RL 的路径选择模型大致分为两类。
第一类,代理的动作是一条路线,比如对于一个旨在从源节点到达目的地节点的智能体,她的动作空间是从源节点到目的地的 k 条最短路径。这些研究假设每个司机都会遵循她选择的路线直到到达目的地。然而,实际上,当驾驶员意识到某些替代路线上的交通状况可能会更好时,尤其是当他们在当前路线上遇到交通堵塞时,他们可能会偏离他们选择的路线。为了捕捉驾驶员的这种途中自适应行为,
第二类研究重点关注途中交通分配,或者从驾驶员角度进行路径选择(多智能体),在这些研究中,当前节点上的动作键是来自该节点的出站链接,换句话说,每个智能体在到达某个节点时都需要决定选择哪条出站链路,直到到达某个终端节点。这个途中决策过程捕捉了真实驾驶员的适应性行为。
不幸的是,单智能体强化学习无法捕捉自适应智能体之间的竞争。多智能体强化学习最近被用来解决多驾驶员路线选择任务尽管对多驾驶员交互进行建模,这些研究还是使用独立的多智能体表格 Q 学习,其中每个智能体都被视为独立的学习者,没有其他智能体的信息。独立学习者的假设存在两个问题。首先,假设智能体独立选择路线而不考虑与其他智能体的交互以及对交通网络的拥堵影响是不切实际的。其次,Q 学习的理论收敛保证不成立,因为环境不再是马尔可夫且平稳的。
为了填补上述研究空白,在本文中,我们将多智能体系统中的路由决策过程建模为马尔可夫博弈,其中一个人的收益函数取决于所有其他人的路由策略。
MARL 和多智能体马尔可夫博弈
作为 MARL 的博弈论框架,马尔可夫博弈是将类似 MDP 的环境推广到具有竞争目标的多个交互代理,其中环境根据代理的概率进行转换。行动。马尔可夫博弈通常被定义为一种非合作博弈,其中自利主体的目标是最大化自己的收益。在马尔可夫博弈中,一般采用纳什均衡的解概念(Hu and Wellman,1998)。在纳什均衡中,一个代理人的策略(即政策)是对其他代理人策略的最佳反应。 MARL 是一种高效且多功能的工具,可以求解每个智能体的最优策略。在这些开创性的研究中,Littman (1994) 提出了一种极小极大 Q 学习算法,用于求解零和博弈中两个目标相反的智能体的最优策略,而 Hu 和 Wellman (1998) 将其扩展到一般和博弈并提供了多智能体Q学习算法。
贡献
- 多智能体动态路由被建模为马尔可夫路由博弈(MRG),它考虑了自适应智能体之间的交互和交通拥堵。它能够利用部分或未知的信息结构和无模型环境对单个代理的路由行为进行建模,其中代理需要通过与其他代理和流量环境的重复交互来学习最优策略。
- 通过平均动作开发了一种高效的多智能体强化学习算法,该平均动作被定义为智能体进入链路后所选链路上的流量。平均动作的使用不仅捕获了智能体之间的竞争,而且还实现了价值共享和策略共享,这在计算上是有利的,特别是在具有大量智能体的大型问题中。
- 各种动态网络加载(DNL)模型被用作所提出的马尔可夫路由博弈的模拟环境。然后,我们证明了计算的马尔可夫均衡及其相关的动态用户均衡(DUE)的一致性。还演示了经典动态交通分配(DTA)范式和我们提出的游戏之间的联系。我们说明了开发的动态路由马尔可夫游戏描述了分析 DTA,假设环境转换动态和旅行或延迟时间函数形式的完整信息。
- 所开发的马尔可夫路由游戏的计算效率在中型和大型网络上得到了证明。
从单智能体的路由模型到多智能体
现在有 N N N 个智能体,其实就是N辆车,从源节点 O O O到汇节点 D D D。每个智能体都实时选择对自己最优的路线,最小化旅行成本函数来选择每个中间节点的最佳下一个到达边缘。交通系统根据所有智能体的行为和每个时间步的一些转移概率而演变。随着系统状态的更新,中间节点的智能体将选择下一个到达的边缘。该过程将继续,直到所有代理都到达目的地或计划时间范围终止。
当一个人解决自己的最优控制问题而其他人同时这样做时,就会形成拥塞(路由)博弈。我们假设这些代理仍然不知道系统演化动态。因此,他们必须学习游戏并通过与其他代理和交通环境的交互来在线选择他们的个人路由策略。结果是纳什均衡,它代表每个可控代理的可扩展的去中心化在线路由策略。
单智能体强化学习
作为垫脚石,作者首先引入单代理强化学习方法。在单智能体范围内,只有一个智能体与随机环境交互。deep Q-learning方法的目标是导出最优策略,使智能体通过遵循环境中的策略获得最大的预期累积奖励。
作者弄了一个Braess network,如下图所示,这里介绍一下Braess网络和悖论,不过作者在此处对此没有太多的涉及,只是单纯的一个网络;

Braess网络(Braess Network)是交通网络和网络理论中的一个重要概念,它以德国数学家Dietrich Braess的名字命名。Braess网络的核心思想是:在某些情况下,增加一条新的道路(或一条新的路径)到现有的交通网络中,反而会导致整体交通状况的恶化。这种现象被称为“Braess悖论”(Braess Paradox)。通过建立交通流量的数学模型,可以证明增加新的道路后,新的均衡状态下的通行时间比原始均衡状态更长。这是因为每个个体司机为了自己的利益选择最短路径,反而导致整体效率下降,这种现象类似于博弈论中的纳什均衡(Nash Equilibrium)。总结来说,Braess网络揭示了一个反直觉的现象:在某些条件下,增加资源或选项可能会导致系统性能下降,而不是改善。这一概念在优化和决策领域具有重要的理论和实践意义。
定义2.1
在这里的MDP过程(Markov decision process)也是和平常的一样有一个元组构成 ( S , A , R , P , γ ) (S,A,R,P,\gamma) (S,A,R,P,γ), S S S代表状态, A A A代表动作, R R R代表奖励, P P P代表转移概率, γ \gamma γ代表衰减因子,下面分条详细介绍各个元素
- s ∈ S s\in S s∈S,这里的 s s s状态时由节点和时间2个部分组成
- a ∈ A a\in A a∈A,这里的动作是由当前所在节点决定的,指的是下一个能去的边如, a = l n , n ′ a=l_{n,n^{\prime}} a=ln,n′指的就是从节点 n n n到节点 n ′ n' n′,允许的动作数量取决于智能体当前所在的节点决定的。
- P是转移到下一个状态的概率,一般来说PP通常对于代理来说是未知的。因此,智能体需要反复与环境交互以获得状态转换经验,即 ( s , a , s ′ ) (s,a,s') (s,a,s′)。
- r ∈ R r\in R r∈R,奖励函数 r t ′ ( s , a , s ′ ) r_{t'} (s, a, s') rt′(s,a,s′) 通常被选择为与状态转换 s → s′ 相关的一些负旅行成本。例如,rt′ (s, a, s′) = −(t′ − t),即负行程时间,并且 r t ′ ( s , a , s ′ ) = − d i s t ( n , n ′ ) r_{t'}(s,a,s') = −dist(n,n') rt′(s,a,s′)=−dist(n,n′),其中 d i s t ( n , n ′ ) dist(n,n′) dist(n,n′) 测量节点 n 和 n′ 之间的距离,即负行进距离。
- γ \gamma γ,衰减因子 γ \gamma γ用于对未来奖励进行折扣。当 $\gamma= 1 $时,智能体不会区分未来奖励和即时奖励。随着 γ 变小,智能体不太关心在遥远的未来收到的奖励,因此她的决策变得更加短视。在本研究中,我们取 $\gamma= 1 $,因为通常驾驶员的目标是尽量减少一次旅行的累积旅行成本。换句话说,他们对未来旅行成本和直接成本的评价是相似的。
- ρ = ∑ t = 0 T γ t r t . ρ \rho=\sum_{t=0}^T\gamma^tr_t.\rho ρ=∑t=0Tγtrt.ρ, 是折扣累积奖励。智能体的目标是通过导出最优策略来最大化 ρ \rho ρ。
然后作者介绍了包括Q-learning 以及DQN的一些概念,感兴趣的朋友可以额外去搜一些资料,这里就不过多赘述了。
作者接下来举了个例子,发现单智能体能在这个简单的交通网络上找到最优路径。
多智能体强化学习和马尔科夫游戏
单智能体Q-learning能找到最短路径,这是毋庸置疑的,但是它无法捕捉多智能体系统(MAS)中智能体之间的竞争。在单智能体强化学习问题中,只有一个智能体被放置在环境中来学习最优策略,从而最大化智能体的预期累积奖励。不幸的是,当多个智能体遵循这个最优策略时,他们的预期累积奖励可能会很低。例如,如果 Braess 网络中最初在节点 n0 处有 50 个智能体,则通过遵循最优策略(即最短路径 n0 → n2 → n1 → n3),它们的预期累积奖励为 -110。该奖励(即 -110)低于遵循另一条路线的奖励(例如,n0 → n1 → n3 产生的预期累积奖励为 -95)。也就是上面悖论所提到的,可能增加一条快速通道,大家都走那里,结果发现其实还变拥堵了,通行时间变慢了。所以作者这里提出来了一种多智能体deep Q-learning的学习方法,来捕捉智能体之间的竞争。
问题表述
与之前的单代理案例类似,我们介绍如何在图 1 所示的 Braess 网络上制定多代理路由问题。
由于多个代理的存在,多代理路由问题被表述为马尔可夫博弈(Littman,1994),它是马尔可夫决策过程对具有竞争目标的多个交互代理的推广,其中环境以概率方式进行转换对代理人的行动作出反应。
通过部分可观察的马尔可夫决策过程来表示马尔可夫博弈,该决策过程由元组 ( S , O 1 , O 2 , . . . , O N , A 1 , A 2 , . . . , A N , P , R 1 , R 2 , . . . , R N , N , γ ) (S,O_{1},O_{2},...,O_{N},A_{1},A_{2},...,A_{N},P,R_{1},R_{2},...,R_{N},N,\gamma) (S,O1,O2,...,ON,A1,A2,...,AN,P,R1,R2,...,RN,N,γ),其中 N 是智能体的数量,S 是环境状态空间。环境状态 s ∈ S s\in S s∈S 不是完全可观察的,相反每个智能体能观测到自的一部分(部分观测), o i ∈ O i o_i\in O_i oi∈Oi与S 相关, O i O_i Oi是智能体 i i i 的观测空间,与他的智能体构成了一个联合的观测空间 O = O 1 × O 2 × ⋯ × O N O=O_1\times O_2\times\cdots\times O_N O=O1×O2×⋯×ON,同理动作也是这样构成了一个联合的动作空间 A = A 1 × A 2 × ⋯ × A N A=A_{1}\times A_{2}\times\cdots\times A_{N} A=A1×A2×⋯×AN, P P P也是表示状态转移的概率, R i R_i Ri表示的是智能体 i i i的奖励函数, γ \gamma γ表示的是衰减因子。
智能体 i i i 的目标是通过导出最优策略 μ i ∗ μ^*_i μi∗ 来最大化其贴现的预期累积奖励。重复此过程,直到代理达到自己的最终状态。
由于其他智能体的存在,智能体 i 的 Q 值函数,即 Q i Q_i Qi,现在依赖于环境状态 s ∈ S s\in S s∈S 和所有智能体的联合动作 a ∈ A a\in A a∈A,即, Q i = Q i ( s , a ) Q_i=Q_i(\mathbf{s,a}) Qi=Qi(s,a)。类似地,智能体 i i i 的价值函数,也取决于环境状态 s s s。
在多智能体系统中,智能体 i i i 的最优策略表示为 μ i ∗ μ^*_i μi∗ ,定义为当其他智能体保持其策略不变时,第 i i i 个智能体对其他人策略的最佳响应。下面我们使用纳什均衡的概念介绍多智能体系统中最优策略的正式定义。
定义2.2
一组策略
μ
i
,
.
.
.
,
μ
N
\mu_i,...,\mu_N
μi,...,μN 是纳什均衡,如果每个策略都是对其他策略的最佳响应。换句话说,没有人可以通过单方面改变政策来改善她的价值函数,而所有其他人都保持其政策不变。也就是说,
∀
i
∈
{
1
,
.
.
.
,
N
}
\forall i\in\{1,...,N\}
∀i∈{1,...,N},主体
i
i
i 从任何状态
s
s
s 获得的值,
V
i
(
s
)
=
m
a
x
a
i
E
a
−
i
∼
A
E
s
′
∼
P
(
⋅
∣
s
,
a
)
[
r
i
(
s
,
a
,
s
′
)
+
γ
V
i
(
s
′
)
]
.
V_{i}(s)=max_{a_{i}}\mathbb{E}_{\mathbf{a}^{-i}\sim A}\mathbb{E}_{s^{\prime}\sim P(\cdot|s,\mathbf{a})}[r_{i}(s,\mathbf{a},s^{\prime})+\gamma V_{i}(s^{\prime})].
Vi(s)=maxaiEa−i∼AEs′∼P(⋅∣s,a)[ri(s,a,s′)+γVi(s′)].
在纳什均衡中,在所有其他智能体保持固定的情况下,每个智能体都最大化其价值函数。每个马尔可夫博弈在固定政策下都存在纳什均衡。
马尔可夫策略是仅取决于当前状态的策略。如果除了 i i i 之外的所有玩家都采用马尔可夫策略,那么玩家 i i i 的最佳响应就是马尔可夫策略。在本文中,我们主要关注马尔可夫策略,即从当前状态 s s s 到动作 a a a 的映射。
多智能体强化学习(MARL)是马尔可夫博弈的计算工具。接下来介绍关于MARL相关参数的一些设置:
- N N N,有 N 个可控自适应代理,用 {1, 2, … , N} 表示。请注意,在交通网络中,还存在不受本研究开发的学习算法控制的其他交通参与者。我们将那些无法控制的流量参与者视为背景流量。背景流量通过其对链路旅行成本的影响来影响可控代理的行为。例如,如果背景流量导致了链路上的交通堵塞,则可控代理很可能会避开该堵塞的链路。
- s ∈ S s\in S s∈S,环境状态由一些全局信息组成,例如代理的分布和每个链路上的流量状况。代理无法完全访问 s。
- o ∈ O o\in O o∈O,虽然环境状态 s s s 不能被智能体 i i i 观测到,但该智能体能够得出与 s s s 相关的私人观察值 o i ∈ O i o_i\in O_i oi∈Oi。所有主体的私有观察空间的笛卡尔积形成联合观察空间,即 O = O 1 × O 2 × ⋯ × O N O=O_1\times O_2\times\cdots\times O_N O=O1×O2×⋯×ON。本文中, o i o_i oi 由节点和时间两个部分组成,即 o i = ( n , t ) o_i = (n, t) oi=(n,t)。联合观察 o = ( o 1 , o 2 , ⋯ , o N ) o = (o_1, o_2, \cdots , o_N ) o=(o1,o2,⋯,oN)。
- a ∈ A a\in A a∈A,基于部分可观测的 o i o_i oi,智能体的动作集合由所有的出站包含来自节点 n 的所有出站链接。其实就是n节点能走的所有边组成
- P P P,是状态转移的概率
- r ∈ R r\in R r∈R,是对应的智能体 i i i在 t t t时间的奖励,与单智能体强化学习类似,奖励通常是一些负的旅行成本,例如路线选择中的旅行时间和旅行距离。
- γ \gamma γ,与单智能体强化学习类似设置为1
- ρ = ∑ t = 0 T γ t r t . ρ \rho=\sum_{t=0}^T\gamma^tr_t.\rho ρ=∑t=0Tγtrt.ρ, 是折扣累积奖励。智能体 i i i的目标是通过导出最优策略来最大化 ρ i \rho_i ρi。如果智能体 i i i 的目标是最大化 ρ i \rho_i ρi,那么智能体就是不合作且自私的;如果智能体 i 的目标是最大化所有智能体的平均折扣累积奖励 1 N ∑ i = 1 N ρ i \frac1N\sum_{i=1}^N{\rho_i} N1∑i=1Nρi,那么智能体就是合作的
由于其他智能体的共存,智能体
i
i
i 的
Q
Q
Q 函数,即
Q
i
Q_i
Qi 现在是环境状态
s
s
s 和动作
a
a
a 的联合函数,即
Q
i
=
Q
i
(
s
,
a
)
Q_i=Q_i(\mathbf{s},\mathbf{a})
Qi=Qi(s,a)
对每个智能体来说,他们都有单独的Q函数也有单独的价值函数,每个智能体的策略都是不一样的,这与其他的智能体都相互隔离开。这将多智能体强化学习与单智能体对应物区分开来,因为即使在多智能体强化学习的相同状态下,智能体也可能表现不同,而在单智能体强化学习的相同状态下,它们会选择相同的动作。
但是考虑到这是一个部分可观测的系统,即一个智能体并不能观测到整个网络的所有细节,所以实际上的
Q
Q
Q 函数是由下式组成,
Q
i
=
Q
i
(
o
i
,
o
−
i
,
a
i
,
a
−
i
)
Q_i=Q_i(o_i,o_{-i},a_i,a_{-i})
Qi=Qi(oi,o−i,ai,a−i)
其中,
o
−
i
,
a
−
i
o_{-i},a_{-i}
o−i,a−i代表着除了
i
i
i 之外的级联观测结果和级联动作。这就带来了一些问题,在一个非共享的的环境里,
i
i
i 是不知道
o
−
i
,
a
−
i
o_{-i},a_{-i}
o−i,a−i 这些信息的,并且如果移除了
o
−
i
,
a
−
i
o_{-i},a_{-i}
o−i,a−i 则会导致Q函数的收敛性不能保证,并且收敛也不会很稳定。
这个时候作者提出了一些办法,首先是共享Q函数。对于现实世界的多智能体问题,通常有超过数万个智能体。因此,为每个智能体维护一个 Q 函数(即 Q i Q_i Qi)在计算上是不可行的。利用智能体之间的某种同质性(例如,一些智能体共享相同的效用函数),作者将智能体分为 C C C 组,并且在每组内实现Q函数共享。共享的Q函数为 Q c ( o i , o − i , a i , a − i ) Q^c(o_i,o_{-i},a_i,a_{-i}) Qc(oi,o−i,ai,a−i)
为了解决这个问题,我们首先注意到 o − i , a − i o_{-i},a_{-i} o−i,a−i 记录了其他智能体的完整信息,从智能体 i i i 的角度来看,这些信息可能包含冗余信息。实际上,在路线选择的任务中,当前远离智能体i的智能体的观察和行动对智能体 i i i 的影响非常有限。对智能体 i i i 周围的交通状况产生影响的是附近的智能体。例如,智能体 i i i在某个节点选择一条链路后,直接影响的量就是所选链路上的流量。如果流量高,智能体 i i i 可能会在该链路上经历较高的旅行成本;如果流量较低,智能体 i i i 可能会平滑过渡到链路末端。因此,方程中的高维 o − i , a − i o_{-i},a_{-i} o−i,a−i 可以通过附近智能体的一些低维聚合信息来近似。
因此在这里作者引入了Mean Field Approximation(平均场近似)的概念,将这种聚合信息称为附近智能体的平均动作,并用
a
ˉ
i
\bar{a}_i
aˉi表示。方程中的 Q 函数(9) 因而变为
Q
c
(
o
i
,
o
−
i
,
a
i
,
a
−
i
)
≈
Q
c
(
o
i
,
a
i
,
a
ˉ
i
)
.
Q^c(o_i,o_{-i},a_i,a_{-i})\approx Q^c(o_i,a_i,\bar{a}_i).
Qc(oi,o−i,ai,a−i)≈Qc(oi,ai,aˉi).
所以接下来作者定义了正式定义路线选择背景下的平均动作。
定义2.3
平均动作 a ˉ i \bar{a}_i aˉi 定义为代理 i i i 选择的链路上的流量。请注意,流量是在代理 i i i 进入链路后立即计算的。
平均场多智能体深度 Q 学习
与单智能体强化学习不同,MAS中属于 c ∈ { 1 , 2 , . . . , C } c\in\{1,2,...,C\} c∈{1,2,...,C}中的的智能体不仅需要与环境交互还需要与其他的智能体相互交互。考虑到平均动作通常处于较大的离散或连续空间中,因此采用由 θ c \theta_{c} θc参数化的DQN,表示为 Q c ( o i , a i , a ˉ i ∣ θ c ) Q^c(o_i,a_i,\bar{a}_i|\theta_c) Qc(oi,ai,aˉi∣θc) 通常使用 Q c ( o i , a i , a ˉ i ) Q^c(o_i,a_i,\bar{a}_i) Qc(oi,ai,aˉi)来近似。
与上面的单智能体的DQN的损失函数类似,得到改进后的损失函数
L
(
θ
c
)
=
E
o
i
,
a
i
,
a
ˉ
i
,
o
i
′
[
(
r
i
+
γ
m
a
x
a
i
′
E
a
ˉ
i
′
∼
μ
−
i
∗
[
Q
c
(
o
i
′
,
a
i
′
,
a
ˉ
i
′
∣
θ
c
−
)
]
−
Q
c
(
o
i
,
a
i
,
a
ˉ
i
∣
θ
c
)
)
2
]
\mathcal{L}(\theta_{c})=\mathbb{E}_{o_{i},a_{i},\bar{a}_{i},o_{i}^{\prime}}\left[(r_{i}+\gamma max_{a_{i}^{\prime}}\mathbb{E}_{\bar{a}_{i}^{\prime}\sim\mu_{-i}^{*}}[Q^{c}(o_{i}^{\prime},a_{i}^{\prime},\bar{a}_{i}^{\prime}|\theta_{c}^{-})]-Q^{c}(o_{i},a_{i},\bar{a}_{i}|\theta_{c}))^{2}\right]
L(θc)=Eoi,ai,aˉi,oi′[(ri+γmaxai′Eaˉi′∼μ−i∗[Qc(oi′,ai′,aˉi′∣θc−)]−Qc(oi,ai,aˉi∣θc))2]
策略优化为
μ
i
∗
(
o
i
)
=
a
r
g
m
a
x
a
i
E
a
ˉ
i
∼
μ
−
i
∗
[
Q
c
(
o
i
,
a
i
,
a
ˉ
i
∣
θ
c
)
]
,
∀
o
i
∈
O
i
\mu_{i}^{*}(o_{i})=argmax_{a_{i}}\mathbb{E}_{\bar{a}_{i}\sim\mu_{-i}^{*}}[Q^{c}(o_{i},a_{i},\bar{a}_{i}|\theta_{c})],\forall o_{i}\in O_{i}
μi∗(oi)=argmaxaiEaˉi∼μ−i∗[Qc(oi,ai,aˉi∣θc)],∀oi∈Oi
其实这些都和DQN的一些优化差不多,就是针对性的进行了一些改进,大概的算法如下图所示

作为一种基于价值的方法,所开发的 MF-MA-DQL 算法不会遇到可变动作集的问题。可变操作集意味着允许的操作数量可能因状态而异。例如,上所示的 Braess 网络中,有 2 个从节点 n0 出发的出站链路,1 个从节点 n1 出发的出站链路,导致了动作集可变的问题。基于策略的方法,例如广泛使用的行动者批评家方法,并不自然地适合具有可变动作集的强化学习问题。主要原因是策略神经网络通常将状态作为输入并输出所有允许动作(即动作集)的概率分布。因此,可变的行动集可能会给维持政策网络的良好结构带来一些挑战。幸运的是,基于价值的方法自动处理可变动作集的问题,因为基于价值的方法计算一个状态下所有可能动作的期望 Q 值,并选择具有最高 Q 值的动作作为最优策略。
然后作者基于上面的那个小网络进行了一个模拟,这里也不赘述了。
用于模拟途中选择的马尔可夫博弈与数据生成机制无关。这里的数据指的是车辆行驶时的背景交通流量,以及影响出行选择的数据,包括但不限于链路上的行驶时间或延迟和/或行驶速度、节点处的排队延迟以及链路间的过渡流。路由流可能来自 DNL 等模型,也可能来自无模型仿真。在接下来的两节中,我们将首先利用现有 DNL 模型生成的数据,然后利用交通模拟器(其数据生成机制尚不清楚)生成的数据,演示所提出的路由游戏。
动态流量分配(DTA)和马尔可夫路由博弈(MRG)之间的联系
DTA是对网络上动态交通流的描述性建模,与交通流理论、出行行为和既定的出行需求相一致。它已被广泛用于模拟旅行者的路线选择行为。一般的DTA问题通常由两部分组成,即动态网络加载(DNL)模块和路由选择模型。
DNL
DNL。给定流量需求和路线选择,DNL 模块通过网络传播流量动态和/或流量拥塞。 DNL 模块中有两个组件,即链路模型和连接模型。链路模型用于将流入流量需求传播到出口,通常由延迟/延迟函数或出口流函数来描述。对于前者,文献中同时使用了线性延迟函数和非线性函数(例如广泛使用的BPR函数)。对于后者,有大量文献提出或使用各种退出流函数,例如 M-N 模型、点队列模型和细胞传输模型。交叉口模型用于确定交叉口的流量分布。
Route choice.
路线选择模型指导旅行者在到达节点/路口之前正确选择下一个前往链接。根据出行者的目标,通常有两类研究问题,即动态系统最优(DSO)和动态用户均衡(DUE)。 DSO 的目标是最小化所有旅行者的总或平均旅行成本,而 DUE 则描述了一种均衡状态,在这种状态下,任何个体旅行者都无法通过单方面偏离当前路线选择来降低其旅行成本。
现在我们讨论DTA 和本文提出的MRG 之间的区别和联系。一般来说,推导纳什均衡需要对系统演化动力学和博弈奖励有完美的了解。然而,所提出的 MRG 使用部分或未知的信息结构和随机无模型环境来模拟各个代理的路由行为。换句话说,在 MRG 中,智能体缺乏系统动力学的转移概率或路段的旅行时间函数的知识。因此,智能体需要通过与其他智能体和交通环境的重复交互来学习。这种设置模仿了这样的现实:我们通常不知道交通如何演变,也不知道旅行时间和拥堵之间的数学关系。这是本文提出的 DTA 模型和 MRG 之间的主要区别。 DTA 模型规定了系统演化动态以及使用每个链接或路线的旅行成本,而 MRG 不包含此类信息,因此需要代理根据交互生成的历史事件来学习和调整其策略。
除了DTA和MRG之间的区别之外,作者还指出了两者之间的联系。马尔可夫博弈是类 MDP 环境到多智能体系统的推广。代理的环境由其他代理和未知对象组成。换句话说,环境的随机性是由其他主体和未知来源的行为引起的。为了生成这样一个类似 MDP 的环境,我们不仅需要对所有智能体的马尔可夫策略进行建模,还需要对它们之间的交互进行建模。 DTA的各种DNL模型可以提供这样的环境。具体来说,DTA中有两个组成部分,即DNL模块和路径选择模型,马尔可夫博弈中有两个组成部分,即环境和代理。 DTA和马尔可夫博弈之间的联系是组件式的,如图2所示。DTA中的DNL可以用作马尔可夫博弈中的环境引擎,而DTA中的路线选择是由马尔可夫博弈中的代理做出的。此外,DTA 中 DNL 和路由选择之间的交互类似于马尔可夫博弈中环境和代理之间的交互。
总之,MRG 与 DNL 模型相结合描述了一种 DTA 模型,该模型对离散车辆(即原子代理(Roughgarden,2007))的决策过程而不是聚合交通流进行建模,交通动态演化被建模为随机转移概率,无需任何模型规范且采用离散时间步长,并且均衡结果是可预测的 DUE。
数值模拟
作者基本上拿了几个环境和传统方法比较了一下,基本上提出的MF-MA-DQL的方法都能收敛到和传统方法差不多的位置,说明作者的方法是有效的。
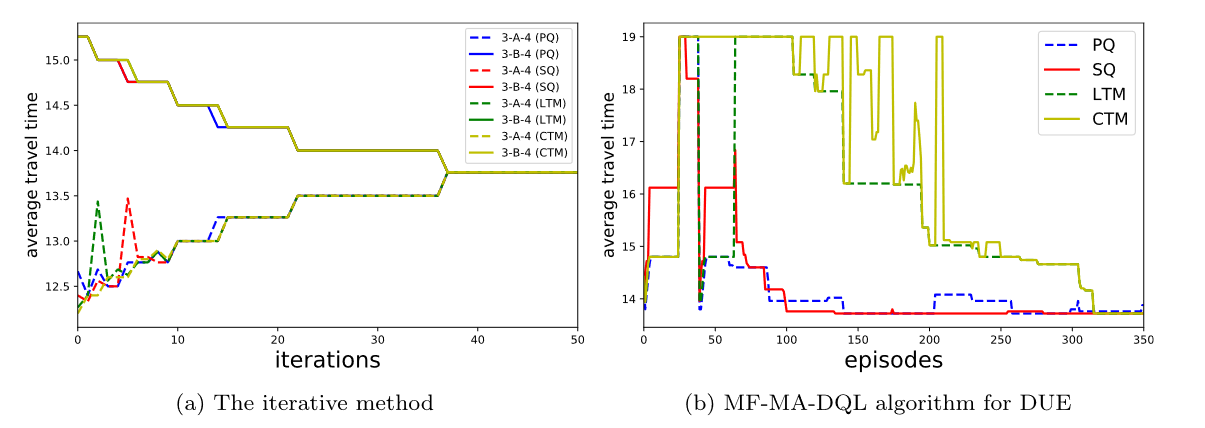
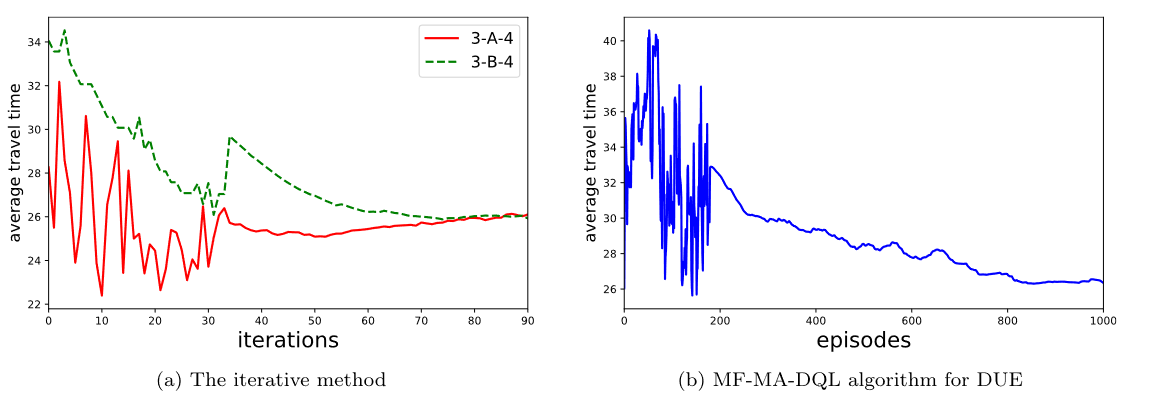
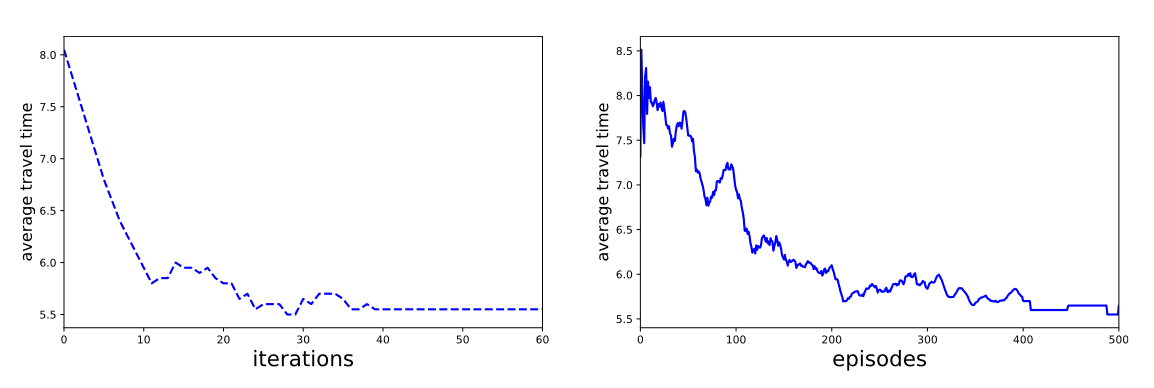
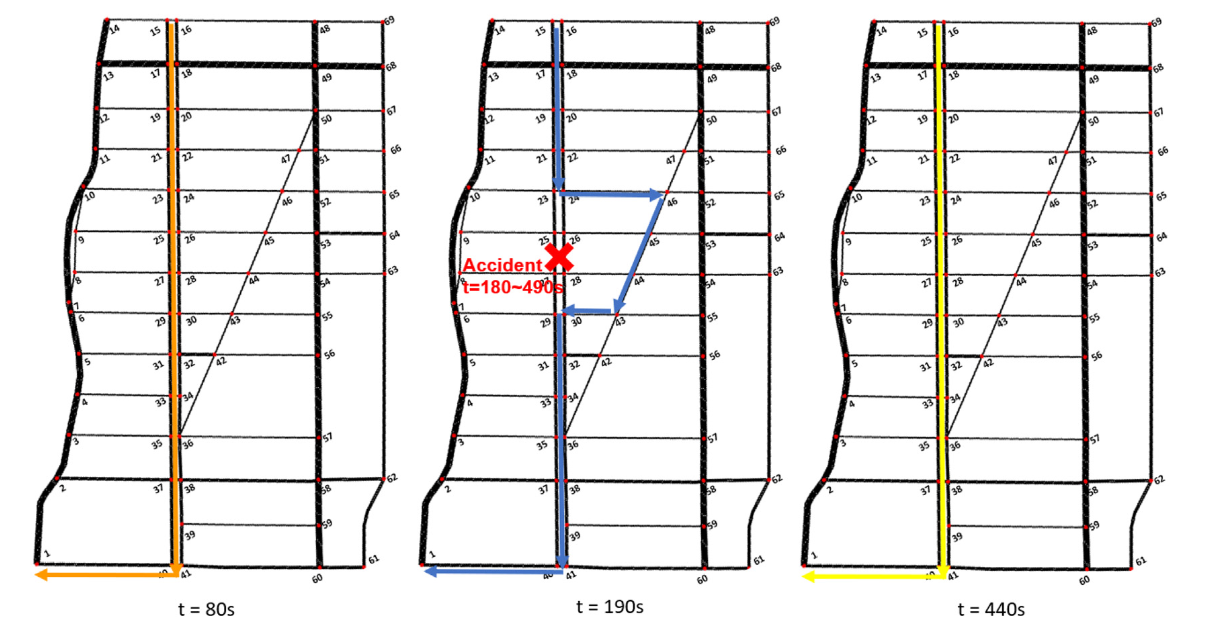
包括最后发生拥堵之后也会主动避开拥堵
说在最后
小灰一直在想,如何把强化学习和交通流分配结合起来,这份工作中感觉做得非常优秀。顶刊不愧是顶刊,感觉读别人的工作,感觉做得真的非常扎实,感觉作者应该做的方向是交通领域的,但是对于强化学习的相关知识感觉非常扎实,而且非常solid,自愧不如啊。继续努力吧!