通过检索增强生成 (RAG) 应用程序的视角学习大型语言模型 (LLM)。
本系列博文
- 简介
- 数据准备
- 句子转换器
- 矢量数据库
- 搜索与检索
- 大语言模型
- 开源 RAG(本帖)
- 评估
- 服务LLM
- 高级 RAG
1. 简介

我们之前的博客文章广泛探讨了大型语言模型 (LLM),涵盖了其发展和广泛的应用。现在,让我们仔细看看这一旅程的核心:在本地构建 LLM 应用程序。
在这篇博文中,我们将使用 LangChain 创建一个基本的 LLM 应用程序。
之后,我们将继续在本地开发另外三个开源 LLM 应用程序。

让我们首先研究一下 LLM App Stack 中的工具。
我们将看到更多 LLM 应用得到实施,我们将开始看到更多此类应用具有生产氛围。这些包括但不限于 — 基本组件上的可观察性、数据版本控制和企业功能。
截至 2024 年 3 月更新,本文包含 8 个类别的 67 家公司:
- 法学硕士
- 法学硕士提供者
- 矢量数据库
- 嵌入模型
- 编排
- 品质调整
- 基础设施
- 数据工具
1.1. LLM
大型语言模型在人工智能领域风靡一时。它们使我们能够通过自然语言与人工智能合作,这是世界各地的研究人员和从业者几十年来一直在努力实现的目标。2014 年生成对抗网络的兴起,加上 2018 年 Transformer 的出现,以及多年来计算能力的提高,都促成了这一技术的出现。
说法学硕士将改变世界既不准确也不公平。法学硕士已经改变了世界。
- OpenAI(GPT)
- 驼羊
- 谷歌(双子座)
- 米斯特拉尔
- 决策人工智能
DeciLM-7B 是 Deci AI 的 LLM 系列中的最新产品。凭借其 70.4 亿个参数和针对高吞吐量进行优化的架构,它在 Open LLM 排行榜上取得了最高性能。它通过结合开源和专有数据集以及分组查询注意等创新技术来确保训练的多样性和效率。Deci 7B 支持 8192 个 token,并遵循 Apache 2.0 许可证。— Harpreet Sahota
- 符号人工智能
我们(创始人)来自电信行业,他们看到了对延迟敏感、低内存语言模型的需求。Symbl AI 具有独特的 AI 模型,专注于从端到端理解语音。它包括将语音转换为文本以及分析和理解所说的内容的能力。—— Surbhi Rathore
- 克劳德(Claude)
- 人工智能块
我们构建了 AI Bloks 来解决在私有云中实现企业 LLM 工作流自动化的问题。我们的产品生态系统拥有针对企业 LLM 工作流的最全面的开源开发框架和模型之一。我们有一个集成的 RAG 框架,其中包含 40 多个经过微调且对 CPU 友好的小型语言模型,旨在堆叠在一起以提供全面的解决方案。— Namee Oberst
- 阿尔西·艾
- 算盘人工智能
- 我们研究
- Upstage 的太阳能
法学硕士学费昂贵。发展中国家的情况更是如此。我们需要找到解决方案。这就是我们开发 Solar 的原因。Solar 足够小,可以装在芯片上,而且任何人都可以使用。— Sung Kim
1.2. 法学硕士提供者
- 亚马逊 (基岩)
- OctoAI
“当我们创办 OctoAI 时,我们知道模型只会越来越大,从而使 GPU 资源变得稀缺。这促使我们将系统专业知识集中在大规模高效地处理 AI 工作负载上。如今,OctoAI 通过与 OpenAI 兼容的 API 提供最新的文本生成和媒体生成基础模型,因此开发人员可以以经济高效的方案充分利用开源创新。” — Thierry Moreau
- 烟花人工智能
- 火星人
1.3. 矢量数据库
向量数据库是 LLM 堆栈的关键部分。它们提供了处理非结构化数据的能力。非结构化数据原本无法处理,但可以通过机器学习模型运行以生成向量嵌入。向量数据库使用这些向量嵌入来查找相似的向量。
- Milvus(这是我的项目!给它一个 GitHub 星星!)
Milvus 是一个开源向量数据库,旨在实现处理数十亿个向量。Milvus 面向企业级,还包含许多企业功能,如多租户、基于角色的访问控制和数据复制。—— Yujian Tang
- 威维特
- 色度
- 卡德兰特
- 阿斯特拉DB
- 孔径数据
“我们创建 Aperture Data 的目的是简化 DS/ML 团队与多模态数据类型的交互。我们最大的价值主张是,我们可以合并矢量数据、智能图表和多模态数据,通过一个 API 进行查询。” — Vishakha Gupta
- 松果
- 数据库
LanceDB 在您的应用中运行,无需管理任何服务器。零供应商锁定。LanceDB 是一款面向开发人员的 AI 开源数据库。它基于 DuckDB 和 Lance 数据格式。— Jasmine Wang
- ElasticSearch
- 齐利兹
Zilliz Cloud旨在解决非结构化数据问题。Zilliz Cloud 建立在高度可扩展、可靠且流行的开源矢量数据库 Milvus 之上,它使开发人员能够自定义矢量搜索,无缝扩展到数十亿个矢量,并且无需管理复杂的基础设施即可完成所有操作。— Charles Xie
1.4. 嵌入模型
嵌入模型是创建向量嵌入的模型。这些是 LLM 堆栈的关键部分,经常与 LLM 混淆。我认为这是 OpenAI 的命名约定 + 人们对学习这项新技术的强烈热情。LLM 可以用作嵌入模型,但嵌入模型早在 LLM 兴起之前就已经存在了。
- 拥抱脸
- 航行人工智能
“Voyage AI 提供通用、特定领域和微调的嵌入模型,具有最佳的检索质量和效率。”——马腾宇
- 混合面包
MixedBread 希望改变人工智能和人类与数据交互的方式。它拥有一支强大的研究和软件工程团队。—— Aamir Shakir
- 艾吉娜
1.5. 编排工具
围绕 LLM 出现了一整套全新的编排工具。主要原因是什么?LLM 应用程序的编排包括提示,这是一个全新的类别。这些工具是由“提示工程”和机器学习领域的前沿人士开发的。
- 骆驼指数
“我们在 ChatGPT 热潮的巅峰时期构建了 LlamaIndex 的第一个版本,以解决 LLM 工具最紧迫的问题之一——如何利用这种推理能力并将其应用于用户数据。如今,我们是一个成熟的 Python 和 TypeScript 数据框架,提供全面的工具/集成(150 多个数据加载器、50 多个模板、50 多个向量存储),可用于在您的数据上构建任何 LLM 应用程序,从 RAG 到代理。”—— Jerry Liu
- 朗链
- 草垛
- 语义核心
- 自动生成
- 飞特
“Flyte 正在利用容器化和 Kubernetes 来协调复杂、可扩展且可靠的工作流程,从而重新定义机器学习和数据工程工作流程的格局。Flyte 专注于可重复性和效率,为运行计算任务提供了一个统一的平台,使 ML 工程师和数据科学家能够轻松地跨团队和跨资源简化工作。您可以通过 Union.ai 在云端完全管理 Flyte,从而充分利用 Flyte 的强大功能”——Ketan Umare
- Flowise人工智能
Flowise 是一款基于 Langchain 和 LlamaIndex 构建的流程管理工具。开发 LLM 应用程序需要一整套全新的开发工具,这就是我们创建 Flowise 的原因:让开发人员能够在一个平台上构建、评估和观察他们的 LLM 应用程序。我们是第一个开辟低代码 LLM 应用程序构建器新领域的公司,也是第一个集成不同 LLM 框架的开源平台,允许开发人员根据自己的用例进行自定义。— Henry Heng
我们创建了一种新的配置语言 BAML,它针对表达 AI 功能进行了优化。BAML 提供内置类型安全、原生 VSCode 游乐场、任意模型支持、可观察性以及对 Python 和 Typescript 的支持。最重要的是,它是开源的!— Vaibhav Gupta
1.6. 质量调整工具
先构建应用程序,然后再考虑质量。但质量真的很重要。这些工具存在的原因在于:a) 许多基于 LLM 的结果都是主观的,但需要一种衡量方法;b) 如果您在生产中使用某些东西,您需要确保它是好的;c) 了解不同参数如何影响您的应用程序意味着您可以了解如何改进它。
- 阿里兹人工智能
“我的联合创始人 Aparna Dhinakaran 来自 Uber 的 ML 团队,我来自 TubeMogul,我们都意识到我们面临的最困难的问题是解决现实世界的 AI 问题并理解 AI 性能。Arize 拥有一群独特的人才,他们数十年来一直致力于 AI 系统性能评估、高度可用的可观察性工具和大数据系统。我们以开源为基础,并支持我们软件的社区版本Phoenix。”—— Arize AI首席执行官兼联合创始人Jason Lopatecki。
- WhyLabs
“WhyLabs 帮助 AI 从业者构建可靠且值得信赖的 AI 系统。随着我们的客户从预测用例扩展到 GenAI 用例,安全性和控制成为他们投入生产的最大障碍。为了解决这个问题,我们开源了 LangKit,这是一种使团队能够防止 LLM 应用程序中的滥用、错误信息和数据泄露的工具。对于企业团队,WhyLabs 平台位于 LangKit 之上,提供协作控制和根本原因分析中心 — Alessya Vijnic
- 深度检查
“我们创办 Deepchecks 是为了应对构建、调整和观察人工智能的巨大成本。我们的特色是为用户提供自动评分机制。这使我们能够结合质量和合规性等多种考虑因素来对 LLM 响应进行评分。” — Philip Tannor
- 困境
- 创世纪
TruEra 的 AI 质量解决方案可评估、调试和监控机器学习模型和大型语言模型应用程序,以实现更高的质量、可信度和更快的部署。对于大型语言模型应用程序,TruEra 使用反馈功能来评估没有标签的 LLM 应用程序的性能。结合深度可追溯性,这为任何 AI 应用程序带来了无与伦比的可观察性。TruEra 可在整个模型生命周期内工作,独立于模型开发平台,并可轻松嵌入到您现有的 AI 堆栈中。— Josh Reini
- 蜂蜜蜂巢
- 护栏 AI
- 梯度爆炸(RAGAS)
- BrainTrust 数据
BrainTrust Data 是一款强大的解决方案,用于评估以软件工程为中心的 LLM 应用程序。它允许快速迭代。与其他 MLOps 工具不同的是,它的评估集侧重于使用情况,并允许用户定义功能。— Albert Zhang
- 守护神人工智能
- 吉斯卡德
- 商
Quotient 提供了一个端到端平台,可以定量测试 LLM 应用程序中的变化。在 GitHub 上进行了多次讨论后,我们认为定量测试 LLM 应用程序是一个大问题。我们的特色是,我们为业务用例提供特定领域的评估。— Julia Neagu
- 伽利略
1.7. 数据工具
2012 年,数据是任何 AI/ML 应用中最好的朋友。2024 年,情况略有不同,但差别不大。数据质量仍然至关重要。这些工具可帮助您确保数据标记正确、使用正确的数据集,并轻松移动数据。
- 体素51
“模型的好坏取决于训练模型所用的数据,那么你的数据集里有什么呢?我们构建了 Voxel51,将您的非结构化数据组织到一个集中、可搜索且可可视化的位置,让您能够构建自动化程序,从而提高您提供给模型的训练数据的质量。” — Brian Moore
- 分布式虚拟控制器
- 閣下
在构建 Apple 的 ML 数据平台并看到 ML 团队因工具和流程无法扩展且与软件团队不一致而苦苦挣扎之后,我们创建了 XetHub。XetHub 将 Git 扩展到 100TB(每个存储库),并提供类似 GitHub 的体验,具有针对 ML 量身定制的功能(自定义视图、模型差异、自动摘要、基于块的重复数据删除、流式挂载、仪表板等)。— Rajat Arya
- 卡夫卡
- 艾尔字节
- 字节蜡
“Bytewax 首先填补了 Python 生态系统中 Python 原生流处理器的空白,该处理器已准备好投入生产。其次,它旨在通过易于使用且直观的 API 和简单的部署方式解决现有流处理工具的开发人员体验问题:`pip install bytewax && python -m bytewax.run my_dataflow.py`” — Zander Matheson
- 非结构化IO
在 Unstructured,我们正在构建数据工程工具,以便轻松地将非结构化数据从原始数据转换为可用于 ML 的数据。如今,开发人员和数据科学家将 80% 以上的时间花在数据准备上;我们的使命是让他们有时间专注于模型训练和应用程序开发。— Brian Raymond
- 火花
- 脉冲星
- 弗卢姆
- Flink
- Timeplus 的 Proton
- Apache NiFi
- 主动循环
- HumanLoop
- 超级链接
- Skyflow(隐私)
Skyflow 是一项数据隐私保险库服务,其灵感来自 Apple 和 Netflix 等公司使用的零信任方法。它隔离并保护敏感的客户数据,将其转换为非敏感引用以降低安全风险。Skyflow 的 API 通过排除敏感数据来确保隐私安全的模型训练,防止从提示或用户提供的文件中推断 RAG 等操作。— Sean Falconer
- 矢量流
- 戴奥斯
- 途径
- 法师人工智能
- 屈肌
1.8. 基础设施
2024 年 3 月,基础架构工具成为该堆栈的新增内容和革新,它们对于构建 LLM 应用至关重要。这些工具可让您先构建应用,然后将生产工作抽象到稍后。它们可让您提供、训练和评估 LLM 以及基于 LLM 的应用程序。
我创办 BentoML 是因为我看到高效运行和提供 AI 模型是多么困难。使用传统的云基础设施,处理繁重的 GPU 工作负载和处理大型模型可能是一件非常令人头疼的事情。简而言之,我们让 AI 开发人员能够非常轻松地启动和运行他们的 AI 推理服务。我们完全是开源的,并得到了一个始终做出贡献的优秀社区的支持。— Chaoyu Yang
- 数据块
- LastMile AI
- 泰坦机器学习
许多企业希望自行托管语言模型,但没有做好这项工作的基础设施。TitanML 提供了这种基础设施,让开发人员可以构建应用程序。它的特别之处在于,它专注于优化企业工作负载,如批量推理、多模式和嵌入模型。— Meryem Arik
- 确定性人工智能(被HPE收购)
- Pachyderm(被HPE收购)
- 保密思想
ConfidentialMind 正在为企业构建可部署的 API 堆栈。它的独特之处是什么?能够在本地部署所有内容,并利用开源工具即插即用。— Markku Räsänen
- 雪花
- Upstash
需要有一种方法来跟踪无状态工具的状态,并且需要在这个领域为开发人员提供服务。—— Enes Akar
- 解体
我们让非 AI 开发人员能够使用 AI,并为 AI 功能创建私有数据管道。 — Amir Houieh
- NVIDIA 的 NIM
- 帕雷亚
Parea 为 LLM 引入了不可知框架和模型,让构建和评估 LLM 应用程序变得更加容易。— Joel Alexander
以下是 RAG 应用程序的非常合适的架构:
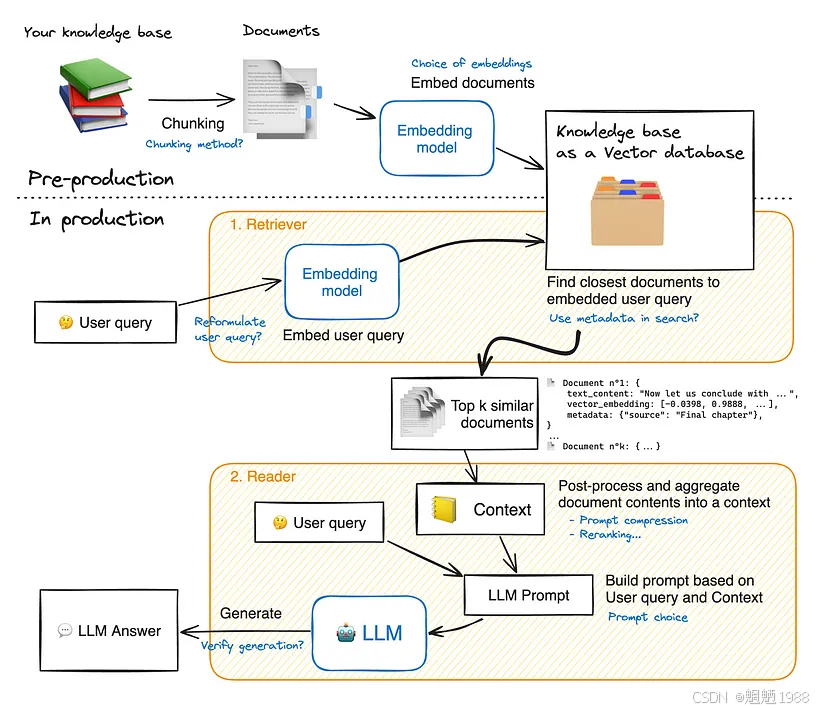
2. 从头开始构建 LLM 申请
HuggingFaceH4/zephyr-7b-beta我们将使用模型和 LangChain为项目的 GitHub 问题快速构建 RAG(检索增强生成) 。
以下是一个简单的例子:
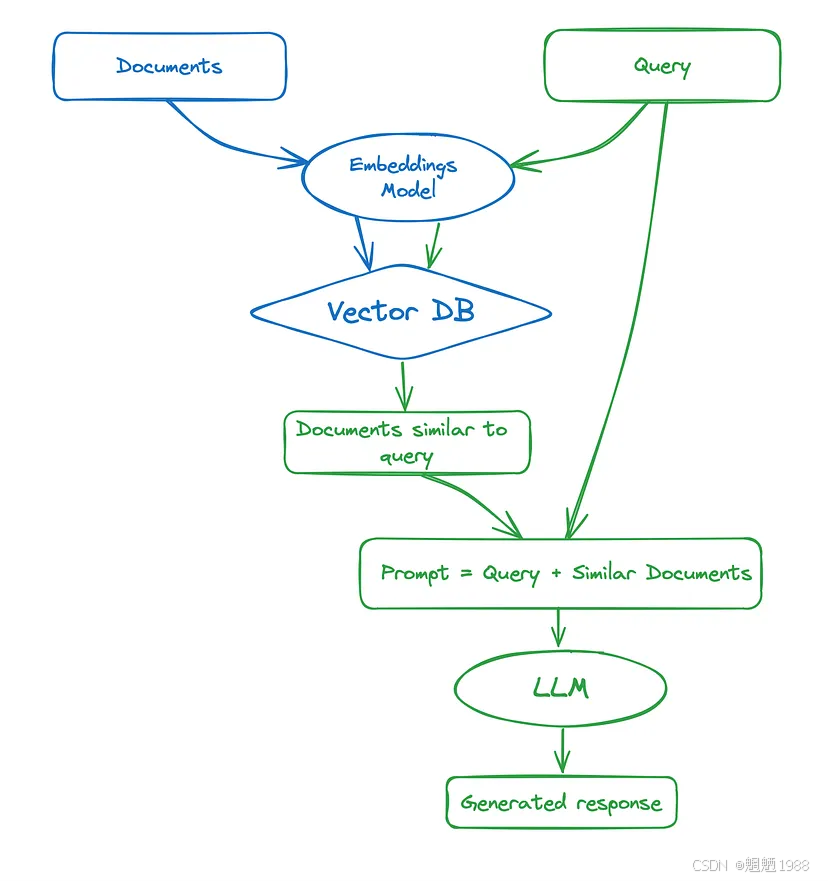
- 使用单独的嵌入模型将外部数据转换为嵌入向量,并将向量保存在数据库中。嵌入模型通常较小,因此定期更新嵌入向量比微调模型更快、更便宜、更容易。
- 同时,由于不需要进行微调,因此当 LLM 可用时,您可以自由地将其换成更强大的版本,或者在需要更快的推理时,将其切换到更小的精简版本。
让我们说明如何使用开源 LLM、嵌入模型和 LangChain 构建 RAG。
首先,让我们安装所需的依赖项:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">!pip install - <span style="color:#aa0d91">q</span> torch transformers 加速 bitsandbytes transformers sentence-transformers faiss-gpu</span></span></span></span><span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#007400"># 如果在 Google Colab 中运行,您可能需要运行此单元格以确保您使用 UTF-8 语言环境来安装 LangChain </span>
<span style="color:#aa0d91">import</span> locale
locale.getpreferredencoding = <span style="color:#aa0d91">lambda</span> : <span style="color:#c41a16">"UTF-8"</span></span></span></span></span><span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">!pip 安装<span style="color:#aa0d91">-q</span> langchain</span></span></span></span>2.1. 准备数据
在此示例中,我们将从PEFT 库的 repo中加载所有问题(包括打开的和关闭的)。
首先,您需要获取GitHub 个人访问令牌来访问 GitHub API。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">从 getpass<span style="color:#aa0d91">导入</span> <span style="color:#5c2699">getpass </span>
<span style="color:#3f6e74">ACCESS_TOKEN </span> = getpass( <span style="color:#c41a16">“YOUR_GITHUB_PERSONAL_TOKEN”</span> )</span></span></span></span>接下来,我们将加载huggingface/peft仓库中的所有问题:
- 默认情况下,拉取请求也被视为问题,这里我们选择通过设置将它们从数据中排除
include_prs=False - 设置
state = "all"意味着我们将加载打开和关闭的问题。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>langchain.document_loaders<span style="color:#aa0d91">导入</span>GitHubIssuesLoader
loader = GitHubIssuesLoader(repo= <span style="color:#c41a16">"huggingface/peft"</span> , access_token=ACCESS_TOKEN,
include_prs= <span style="color:#aa0d91">False</span> , state= <span style="color:#c41a16">"all"</span> )
docs = loader.load()</span></span></span></span>单个 GitHub 问题的内容可能比嵌入模型可以接收的输入内容更长。如果我们想嵌入所有可用内容,我们需要将文档分块为适当大小的部分。
最常见、最直接的分块方法是定义固定大小的块以及它们之间是否应该有重叠。保留块之间的一些重叠使我们能够保留块之间的一些语义上下文。推荐的通用文本分割器是 RecursiveCharacterTextSplitter ,我们将在这里使用它。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>langchain.text_splitter<span style="color:#aa0d91">导入</span>RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size= <span style="color:#1c00cf">512</span> , chunk_overlap= <span style="color:#1c00cf">30</span> )
chunked_docs = splitter.split_documents(docs)</span></span></span></span>2.2. 创建嵌入 + 检索器
现在所有文档都具有适当的大小,我们可以使用它们的嵌入创建一个数据库。
要创建文档块嵌入,我们将使用HuggingFaceEmbeddings和嵌入模型。Hub 上还有许多其他嵌入模型,您可以通过查看海量文本嵌入基准 (MTEB) 排行榜BAAI/bge-base-en-v1.5来关注表现最佳的模型。
为了创建向量数据库,我们将使用FAISSFacebook AI 开发的库。该库提供高效的相似性搜索和密集向量聚类,这正是我们在这里所需要的。FAISS 目前是海量数据集中 NN 搜索最常用的库之一。
我们将通过 LangChain API 访问嵌入模型和 FAISS。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>langchain.vectorstores<span style="color:#aa0d91">导入</span>FAISS
<span style="color:#aa0d91">从</span>langchain.embeddings<span style="color:#aa0d91">导入</span>HuggingFaceEmbeddings
db = FAISS.from_documents(chunked_docs,HuggingFaceEmbeddings
(model_name= <span style="color:#c41a16">"BAAI/bge-base-en-v1.5"</span> ))</span></span></span></span>我们需要一种方法来返回(检索)给定非结构化查询的文档。为此,我们将使用以作为主干的as_retriever方法:db
search_type="similarity"意味着我们想要在查询和文档之间执行相似性搜索search_kwargs={'k': 4}指示检索器返回前 4 个结果。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">检索器 = db.as_retriever(search_type = <span style="color:#c41a16">“相似性”</span>,search_kwargs = { <span style="color:#c41a16">“k”</span>:<span style="color:#1c00cf">4</span> })</span></span></span></span>现在已经设置了矢量数据库和检索器,接下来我们需要设置链的下一个部分 - 模型。
2.3. 负载量化模型
对于这个例子,我们选择了HuggingFaceH4/zephyr-7b-beta,一个小但功能强大的模型。
由于每周都会发布许多模型,您可能希望将此模型替换为最新和最好的模型。跟踪开源 LLM 的最佳方式是查看开源 LLM 排行榜。
为了加快推理速度,我们将加载模型的量化版本:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">导入</span>torch
<span style="color:#aa0d91">从</span>transformers<span style="color:#aa0d91">导入</span>AutoTokenizer、AutoModelForCausalLM、BitsAndBytesConfig
model_name = <span style="color:#c41a16">"HuggingFaceH4/zephyr-7b-beta"</span>
bnb_config = BitsAndBytesConfig(
load_in_4bit= <span style="color:#aa0d91">True</span>,bnb_4bit_use_double_quant= <span style="color:#aa0d91">True</span>,bnb_4bit_quant_type= <span style="color:#c41a16">"nf4"</span>,bnb_4bit_compute_dtype=torch.bfloat16
)
model = AutoModelForCausalLM.from_pretrained(model_name,quantization_config=bnb_config)
tokenizer = AutoTokenizer.from_pretrained(model_name)</span></span></span></span>2.4. 设置 LLM 链
最后,我们拥有了建立 LLM 链所需的所有部分。
首先,使用加载的模型及其标记器创建一个 text_generation 管道。
接下来,创建一个提示模板——这应该遵循模型的格式,所以如果你替换模型检查点,请确保使用适当的格式。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>langchain.llms<span style="color:#aa0d91">导入</span>HuggingFacePipeline
<span style="color:#aa0d91">从</span>langchain.prompts<span style="color:#aa0d91">导入</span>PromptTemplate
<span style="color:#aa0d91">从</span>transformers<span style="color:#aa0d91">导入</span>pipeline
<span style="color:#aa0d91">从</span>langchain_core.output_parsers<span style="color:#aa0d91">导入</span>StrOutputParser
text_generation_pipeline = pipeline(
model=model,
tokenizer=tokenizer,
task= <span style="color:#c41a16">"text-generation"</span> ,
temperature= <span style="color:#1c00cf">0.2</span> ,
do_sample= <span style="color:#aa0d91">True</span> ,
repetition_penalty= <span style="color:#1c00cf">1.1</span> ,
return_full_text= <span style="color:#aa0d91">True</span> ,
max_new_tokens= <span style="color:#1c00cf">400</span> ,
)
llm = HuggingFacePipeline(pipeline=text_generation_pipeline)
prompt_template = <span style="color:#c41a16">"""
<|system|>
根据您的知识回答问题。使用以下上下文来帮助:
{context}
</s>
<|user|>
{question}
</s>
<|assistant|>
"""</span>
prompt = PromptTemplate(
input_variables=[ <span style="color:#c41a16">"context"</span> , <span style="color:#c41a16">“问题”</span> ],
模板=prompt_template,
)
llm_chain = prompt | llm | StrOutputParser()</span></span></span></span>注意:您还可以使用tokenizer.apply_chat_template将消息列表(如 dicts: {'role': 'user', 'content': '(...)'})转换为具有适当聊天格式的字符串。
最后,我们需要将llm_chain与检索器结合起来,创建一个 RAG 链。我们将原始问题传递到最后的生成步骤,以及检索到的上下文文档:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">从</span>langchain_core.runnables<span style="color:#aa0d91">导入</span>RunnablePassthrough
检索器 = db.as_retriever()
rag_chain = { <span style="color:#c41a16">“context”</span> : 检索器,<span style="color:#c41a16">“question”</span> : RunnablePassthrough()} | llm_chain</span></span></span></span>2.5. 比较结果
让我们看看 RAG 在生成针对图书馆特定问题的答案方面有何不同。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">问题 = <span style="color:#c41a16">“如何组合多个适配器?”</span></span></span></span></span>首先,让我们看看仅使用模型本身,不添加上下文,我们能得到什么样的答案:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">llm_chain.invoke({ <span style="color:#c41a16">“上下文”</span>:<span style="color:#c41a16">“”</span>,<span style="color:#c41a16">“问题”</span>:问题})</span></span></span></span>输出:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424"><span style="color:#aa0d91">要</span>组合多个适配器,您需要<span style="color:#aa0d91">确保</span><span style="color:#aa0d91">它们</span><span style="color:#aa0d91">彼此</span> 兼容并且<span style="color:#5c2699">与要</span><span style="color:#aa0d91">连接</span>的设备兼容。<span style="color:#007400">您可以按照以下方法操作:</span><span style="color:#1c00cf">1.</span>确定所需的连接器类型:组合适配器之前,请确定输入和输出设备都需要哪些连接器<span style="color:#aa0d91">。</span>例如,<span style="color:#5c2699">如果</span><span style="color:#aa0d91">要将</span>USB <span style="color:#aa0d91">-</span> C<span style="color:#aa0d91">设备</span>连接到<span style="color:#aa0d91">HDMI</span><span style="color:#aa0d91">显示器</span>,则可能需要 USB-C<span style="color:#aa0d91">转</span>HDMI 适配器,<span style="color:#5c2699">然后</span><span style="color:#aa0d91">如果</span>您的显示器仅支持 DVI,则需要单独的 HDMI 转 DVI 适配器。2. 检查兼容性:确保您选择的适配器彼此兼容<span style="color:#aa0d91">并且</span>与<span style="color:#1c00cf">要</span>连接<span style="color:#aa0d91">的</span><span style="color:#5c2699">设备</span><span style="color:#aa0d91">兼容</span><span style="color:#aa0d91">。</span>这一点<span style="color:#5c2699">很</span>重要,因为某些适配器可能<span style="color:#5c2699">无法</span><span style="color:#aa0d91">一起</span>工作<span style="color:#5c2699">或</span>可能导致信号丢失<span style="color:#5c2699">或</span>干扰。<span style="color:#1c00cf">3.</span>连接适配器:确定兼容的适配器后,请<span style="color:#aa0d91">按</span>正确的<span style="color:#aa0d91">顺序连接它们。通常,最靠近</span><span style="color:#aa0d91">要</span>连接的设备的<span style="color:#aa0d91">适配器</span>首先连接,然后<span style="color:#aa0d91">是</span>任何其他所需的适配器。<span style="color:#1c00cf">4.</span>测试连接:连接所有适配器后,测试连接<span style="color:#aa0d91">以</span>确保一切<span style="color:#5c2699">正常</span>。<span style="color:#aa0d91">如果</span>遇到任何问题,<span style="color:#aa0d91">请尝试</span>重新排列适配器<span style="color:#aa0d91">的</span><span style="color:#aa0d91">顺序</span><span style="color:#5c2699">或</span>完全<span style="color:#aa0d91">使用不同的适配器。 </span><span style="color:#1c00cf">5.</span>固定连接:<span style="color:#aa0d91">为</span>防止意外断开连接,请使用电缆扎带<span style="color:#5c2699">或</span>夹子<span style="color:#aa0d91">将</span>适配器<span style="color:#5c2699">和</span>电缆<span style="color:#aa0d91">固定</span>到位。这也有助于<span style="color:#aa0d91">组织</span>您的设置<span style="color:#5c2699">并</span>使其更易于<span style="color:#aa0d91">管理</span>。请记住,组合多个适配器有时会导致<span style="color:#aa0d91">信号</span>丢失<span style="color:#5c2699">或</span>干扰,因此
<span style="color:#007400">在依赖连接执行关键任务之前,彻底测试连接至关重要。此外,请注意组合电缆的最大长度,以避免信号衰减。如您所见,模型将问题解释为有关物理计算机适配器的问题,而在 PEFT 的上下文中,“适配器”是指 LoRA 适配器。让我们看看添加来自 GitHub 问题的上下文是否有助于模型给出更相关的答案:</span></span></span></span></span><span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">rag_chain.invoke(问题)</span></span></span></span>输出:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">根据提供的上下文,以下是使用 PEFT( Transformers<span style="color:#aa0d91">的</span>Python 扩展)组合多个适配器的一些潜在方法:
<span style="color:#1c00cf">1.</span>分别加载每个适配器<span style="color:#aa0d91">并</span>连接它们的输出:
```python
<span style="color:#aa0d91">from</span> peft <span style="color:#aa0d91">import</span> Peft
<span style="color:#007400"># 加载基础模型和适配器 1</span>
base_model = AutoModelForSequenceClassification.from_pretrained( <span style="color:#c41a16">"your_base_model"</span> )
adapter1 = Peft( <span style="color:#c41a16">"adapter1"</span> ).requires_grad_( <span style="color:#aa0d91">False</span> )
adapter1(base_model).load_state_dict(torch.load( <span style="color:#c41a16">"path/to/adapter1.bin"</span> ))
<span style="color:#007400"># 加载适配器 2</span>
adapter2 = Peft( <span style="color:#c41a16">"adapter2"</span> ).requires_grad_( <span style="color:#aa0d91">False</span> )
adapter2(base_model).load_state_dict(torch.load( <span style="color:#c41a16">"path/to/adapter2.bin"</span> ))
<span style="color:#007400"># 连接两个适配器的输出</span>
<span style="color:#aa0d91">def </span> forward ( <span style="color:#5c2699">self, input_ids,tention_mask</span> ):
x = self.base_model(input_ids,tention_mask)[ <span style="color:#1c00cf">0</span> ]
x = torch.cat([x, adapter1(x), adapter2(x)], dim=- <span style="color:#1c00cf">1</span> )
<span style="color:#aa0d91">return</span> x
<span style="color:#007400"># 创建包含连接输出的新模型类</span>
<span style="color:#aa0d91">class </span> MyModel ( BaseModel ):
<span style="color:#aa0d91">def </span> __init__ ( <span style="color:#5c2699">self</span> ):
<span style="color:#5c2699">super</span> ().__init__()
self.forward = forward
<span style="color:#007400"># 实例化新模型类并用于推理</span>
my_model = MyModel()
```
<span style="color:#1c00cf">2.</span>冻结多个适配器<span style="color:#aa0d91">并</span>在推理过程中有选择地激活它们:
```python
<span style="color:#aa0d91">from</span> peft <span style="color:#aa0d91">import</span> Peft
<span style="color:#007400"># 加载基础模型和所有适配器</span></span></span></span></span>我们可以看到,添加的上下文确实有助于完全相同的模型,为特定于图书馆的问题提供更相关、更明智的答案。
值得注意的是,组合多个适配器进行推理的功能已添加到库中,您可以在文档中找到此信息,因此对于此 RAG 的下一次迭代,可能值得包含文档嵌入。
所以,现在我们了解了如何从头开始构建 LLM RAG 应用程序。
Google Colab(来源):https ://colab.research.google.com/github/huggingface/cookbook/blob/main/notebooks/en/rag_zephyr_langchain.ipynb
接下来,我们将利用我们的理解来构建另外 3 个 LLM 应用程序。
对于以下应用程序,我们将使用 Ollama 作为我们的 LLM 服务器。让我们从下面了解有关 LLM 服务器的更多信息开始。
3. LLM 服务器
此应用程序最关键的组件是 LLM 服务器。借助Ollama,我们拥有一个可在本地设置的强大 LLM 服务器。
什么是 Ollama?
可以从ollama.ai 网站安装 Ollama 。
Ollama 不是一个单一的语言模型,而是一个让我们可以在本地机器上运行多个开源 LLM 的框架。你可以把它想象成一个可以玩不同语言模型(如 Llama 2、Mistral 等)的平台,而不是一个特定的播放器本身。
另外,我们还可以使用 Langchain SDK,这是一个可以更方便地与 Ollama 合作的工具。
在命令行上使用 Ollama 非常简单。以下是我们可以尝试在计算机上运行 Ollama 的命令。
ollama pull— 此命令从 Ollama 模型中心提取模型。ollama rm— 此命令用于从本地计算机删除已下载的模型。ollama cp— 此命令用于复制模型。ollama list— 该命令用于查看已下载模型的列表。ollama run— 此命令用于运行模型,如果模型尚未下载,它将拉取模型并为其提供服务。ollama serve— 该命令用于启动服务器,为下载的模型提供服务。
我们可以将这些模型下载到本地机器,然后通过命令行提示符与这些模型进行交互。或者,当我们运行模型时,Ollama 还会运行一个托管在端口 11434(默认情况下)的推理服务器,我们可以通过 API 和其他库(如 Langchain)与该服务器进行交互。
截至本文发布时,Ollama 已有 74 个模型,其中还包括嵌入模型等类别。
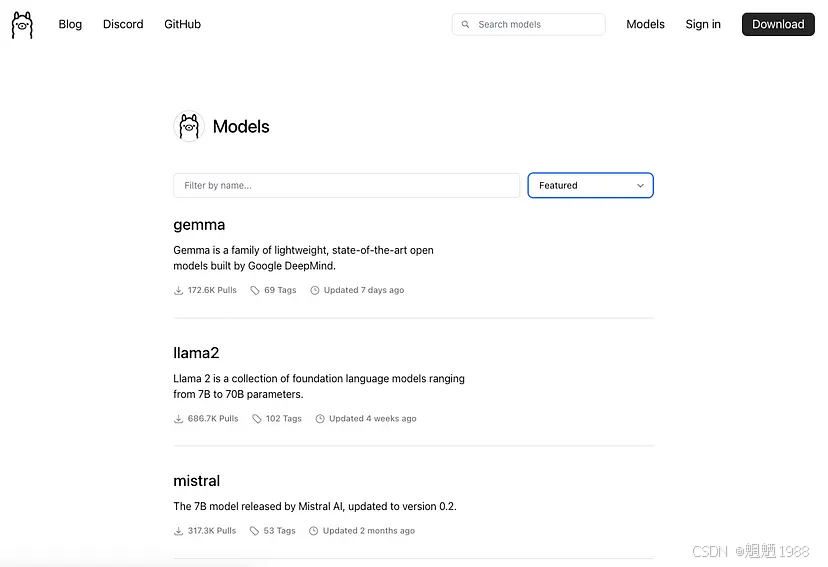
来源:Ollama
4.聊天机器人应用程序
我们接下来要构建的 3 个基本聊天机器人应用程序是:
- 使用 LangChain、ChromaDB 和 Streamlit 与多个 PDF 聊天
- 带有开放 WebUI 的聊天机器人
- 使用 Docker 部署聊天机器人。
在这 3 个应用程序结束时,我们将直观地了解如何构建和大规模部署工业应用程序。
5.应用一:与多个PDF聊天
我们将构建一个与ChatPDF类似但更简单的应用程序。用户可以在其中上传多个 PDF 文档并通过简单的 UI 提出问题。
有了 Langchain、Ollama 和 Streamlit,我们的技术堆栈变得非常简单。

- LLM 服务器:此应用程序最关键的组件是 LLM 服务器。得益于Ollama,我们拥有一个强大的 LLM 服务器,可以在本地甚至在笔记本电脑上进行设置。虽然llama.cpp是一个选项,但我发现用 Go 编写的 Ollama 更易于设置和运行。
- RAG:毫无疑问,LLM 领域的两个领先库是Langchain和LLamIndex。对于这个项目,我将使用 Langchain,因为我从我的专业经验中对它很熟悉。任何 RAG 框架的一个基本组件是向量存储。我们将在这里使用Chroma,因为它与 Langchain 集成得很好。
- 聊天 UI:用户界面也是一个重要组件。虽然有很多可用的技术,但为了省心,我更喜欢使用 Python 库Streamlit 。
好的,我们开始设置。
聊天机器人可以访问各种 PDF 中的信息。具体细节如下:
- 数据来源:多个 PDF
- 存储: ChromaDB 的矢量存储(高效存储和检索信息)
- 处理: LangChain API 为大型语言模型 (LLM) 准备数据
- LLM 集成:可能涉及检索增强生成 (RAG) 以增强响应
- 用户界面: Streamlit 创建了一个用户友好的聊天界面
GitHub Repo 结构:https ://github.com/vsingh9076/Building_LLM_Applications.git
文件夹结构
- 将存储库克隆到本地机器。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">git<span style="color:#5c2699">克隆</span>https://github.com/vsingh9076/Building_LLM_Applications.git
<span style="color:#5c2699">cd</span> 7_Ollama/local-pdf-chatbot</span></span></span></span>2.创建虚拟环境:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">python3 -m venv myenv
<span style="color:#5c2699">源</span>myenv/bin/activate</span></span></span></span>3.安装要求:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">pip 安装 -r 要求.txt</span></span></span></span>4. 安装Ollama并提取 config.yml 中指定的 LLM 模型 [ 我们已经在上一节中介绍了如何设置 Ollama ]
5. 使用 Ollama 运行 LLama2 模型
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama 拉 llama2
ollama 运行 llama2</span></span></span></span>6. 使用 Streamlit CLI 运行 app.py 文件。执行以下命令:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">streamlit 运行应用程序.py</span></span></span></span>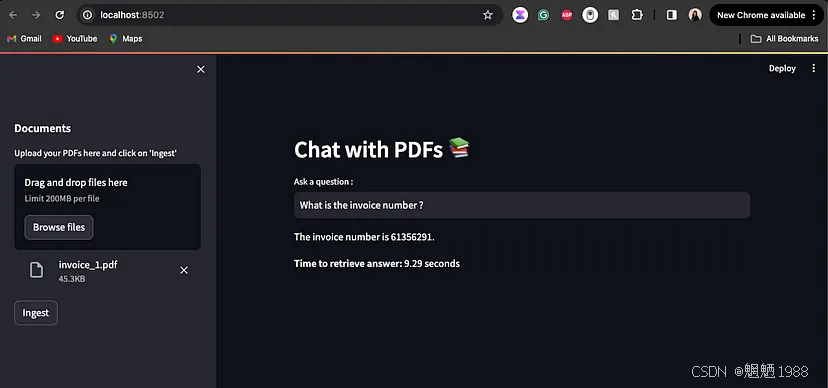
作者图片
6. 应用二:带有开放 WebUI 的聊天机器人
在这个应用程序中,我们将使用 Open WebUI 而不是 Streamlit / Chainlit / Gradio 作为 UI 来构建聊天机器人。
步骤如下:
- 安装 Ollama 并部署 LLM
我们可以直接在本地机器上安装 Ollama,也可以在本地部署 Ollama docker 容器。选择权在我们手中,它们都可以适用于 langchain Ollama 界面、Ollama 官方 python 界面和 open-webui 界面。
以下是在我们的本地系统中直接安装 Ollama 的说明:
设置和运行 Ollama 非常简单。首先,访问ollama.ai并下载适合我们的操作系统的应用程序。
接下来,打开终端并执行以下命令来获取最新模型。虽然还有许多其他LLM 模型可用,但我选择 Mistral-7B,因为它体积小巧且质量有竞争力。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama 拉 llama2</span></span></span></span><span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama 奔跑 llama2</span></span></span></span>所有其他型号的设置过程都相同。我们需要拉动并运行。
2.安装open-webui(ollama-webui)
Open WebUI 是一款可扩展、功能丰富且用户友好的自托管 WebUI,旨在完全离线运行。它支持各种 LLM 运行器,包括 Ollama 和 OpenAI 兼容 API。
官方 GitHub Repo: https: //github.com/open-webui/open-webui
运行以下 docker 命令在本地机器上部署 open-webui docker 容器。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v ollama-webui:/app/backend/data --name ollama-webui --restart always ghcr.io/ollama-webui/ollama-webui:main</span></span></span></span>作者图片
3.打开浏览器
打开浏览器,使用端口 3000 调用 localhost
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">http://本地主机:3000</span></span></span></span>作者图片
首先,我们需要进行首次注册。只需单击“注册”按钮即可创建我们的帐户。
作者图片
一旦注册,我们将被路由到 open-webui 的主页。
作者图片
根据我们在本地机器上部署的 LLM,这些选项将反映在下拉列表中以供选择。
{kind=link}
作者图片
一旦选择,就可以聊天。
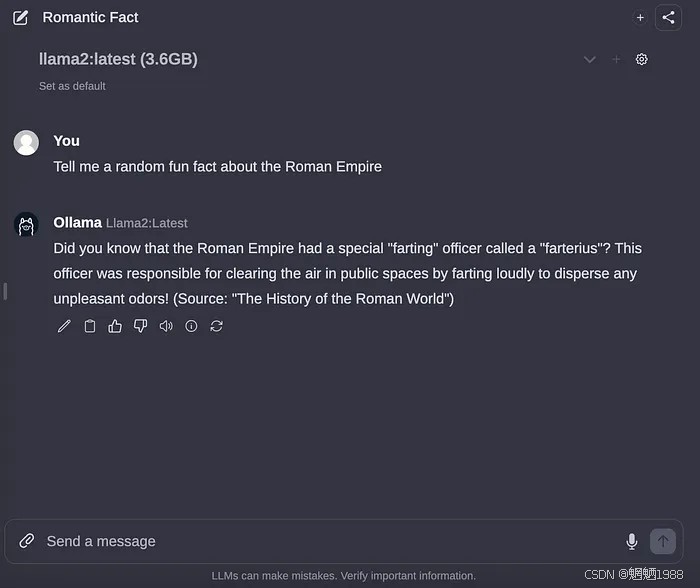
作者图片
这阻止我们创建 streamlit 或 gradio UI 界面来尝试各种开源 LLM、进行演示等。
我们现在可以与任何 PDF 文件进行聊天:
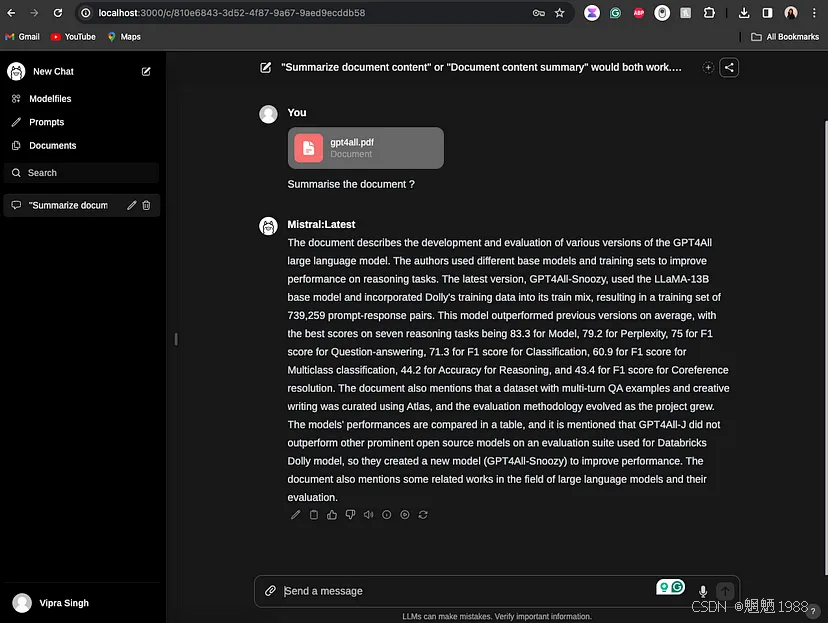
作者图片
附加一个演示 gif 文件,展示如何使用 open-webui 进行图像聊天。
来源:open-webui
{kind=link}
让我们看看如何将我们的自定义模型与 Ollama 结合使用。以下是具体步骤。
如何使用定制模型?
从 GGUF 导入
Ollama 支持在 Modelfile 中导入 GGUF 模型:
- 创建一个名为的文件
Modelfile,其中包含FROM我们要导入的模型的本地文件路径的指令。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">来自 ./vicuna-33b.Q4_0.gguf</span></span></span></span>2. 在 Ollama 中创建模型
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama<span style="color:#5c2699">创建</span>示例 -f 模型文件</span></span></span></span>3. 运行模型
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama 运行示例</span></span></span></span>从 PyTorch 或 Safetensors 导入
请参阅导入模型的指南以了解更多信息。
自定义提示
可以使用提示自定义 Ollama 库中的模型。例如,要自定义llama2模型:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama 拉 llama2</span></span></span></span>创建一个Modelfile:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">来自 llama2
<span style="color:#007400"># 将温度设置为 1 [越高越有创意,越低越连贯]</span>
参数温度 1
<span style="color:#007400"># 设置系统消息</span>
系统<span style="color:#c41a16">“” </span><span style="color:#c41a16">“
你是超级马里奥兄弟中的马里奥。仅以助手马里奥的身份回答。
” </span><span style="color:#c41a16">“”</span></span></span></span></span>接下来创建并运行模型:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">ollama create mario -f ./Modelfile
ollama run mario
>>> hi
你好!我<span style="color:#c41a16">是你的朋友马里奥。</span></span></span></span></span>有关更多示例,请参阅示例目录。有关使用 Modelfile 的更多信息,请参阅Modelfile文档。
7.应用三:使用Docker部署聊天机器人
让我们使用 Langshan 构建聊天机器人应用程序,为了从 Python 应用程序访问我们的模型,我们将构建一个简单的 Steamlit 聊天机器人应用程序。我们将在容器中部署此 Python 应用程序,并将在另一个容器中使用 Ollama。我们将使用 docker-compose 构建基础设施。
下图展示了容器如何交互的架构以及它们将访问哪些端口。
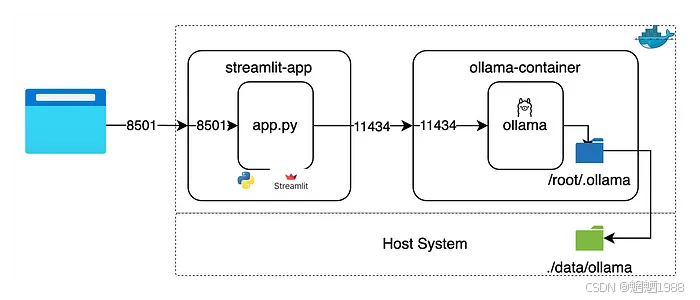
我们建造了两个集装箱,
- Ollama 容器使用主机卷来存储和加载模型(
/root/.ollama映射到本地./data/ollama)。Ollama 容器监听 11434(外部端口,内部映射到 11434) - Streamlit 聊天机器人应用程序将监听 8501(外部端口,内部映射到 8501)。
GitHub 存储库:
文件夹结构
将存储库克隆到本地机器。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">git<span style="color:#5c2699">克隆</span>https://github.com/vsingh9076/Building_LLM_Applications.git
<span style="color:#5c2699">cd</span> 7_Ollama/docker-pdf-chatbot</span></span></span></span>创建虚拟环境:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">python3 -m venv./ollama-langchain-venv
<span style="color:#5c2699">源</span>./ollama-langchain-venv/bin/activate</span></span></span></span>安装要求:
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">pip 安装 -r 要求.txt</span></span></span></span>Ollama 是一个框架,它允许我们将 Ollama 服务器作为 docker 映像运行。这对于构建使用 Ollama 模型的微服务应用程序非常有用。我们可以轻松地在 docker 生态系统中部署我们的应用程序,例如 OpenShift、Kubernetes 等。要在 docker 中运行 Ollama,我们必须使用 docker run 命令,如下所示。在此之前,我们应该在系统中安装 docker。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">docker run -d -v ollama:/root/.ollama -p 11434:11434 --name ollama ollama/ollama</span></span></span></span>以下是输出:
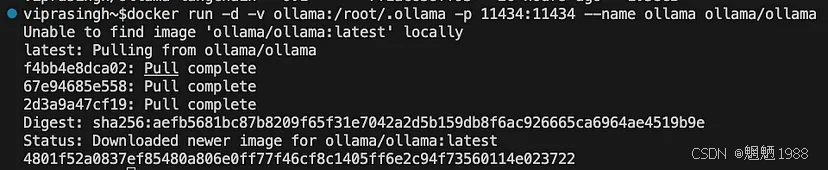
作者图片
然后我们应该能够使用与该容器进行交互docker exec,如下所示,并运行提示。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">docker <span style="color:#5c2699">exec</span> -it ollama ollama 运行 phi</span></span></span></span>
作者图片
在上面的命令中,我们在docker中运行phi。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">curl http: <span style="color:#007400">//localhost:11434/api/generate -d'{ </span>
<span style="color:#c41a16">“model”</span>:<span style="color:#c41a16">“phi:latest”</span>,
<span style="color:#c41a16">“prompt”</span>:<span style="color:#c41a16">“你是谁?”</span>,
<span style="color:#c41a16">“stream”</span>:<span style="color:#aa0d91">false</span>
}'</span></span></span></span>结果如下:
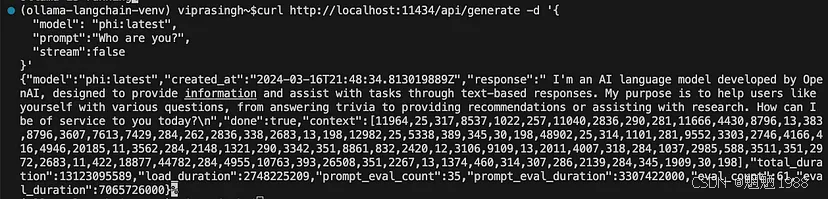
作者图片
请注意,docker 容器是临时的,无论我们拉取什么模型,当我们重新启动容器时,它们都会消失。我们将在下一篇博客中解决这个问题,我们将从头开始构建一个分布式 Streamlit 应用程序。我们将将容器的卷与主机进行映射。
Ollama 是一款功能强大的工具,它支持以新的方式在云上创建和运行 LLM 应用程序。它简化了开发过程并提供了灵活的部署选项。它还允许轻松管理和扩展应用程序。
现在,让我们开始使用 Streamlit 应用程序。
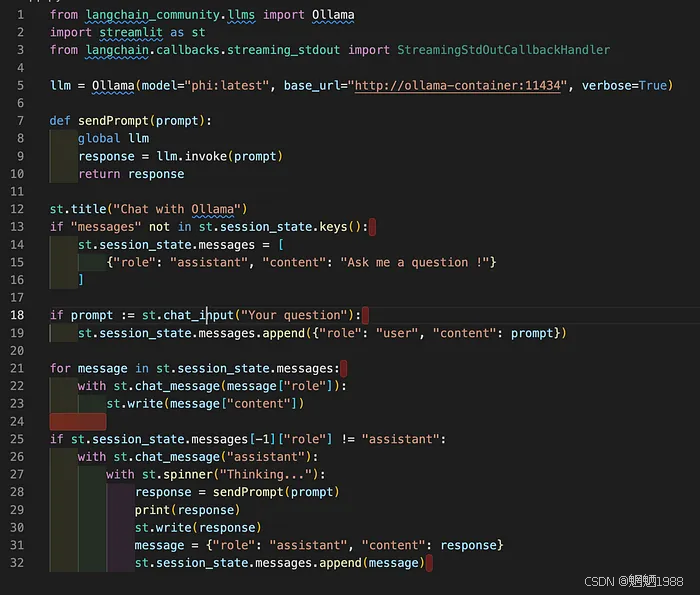
我们正在通过 Ollama Langchain 库(它是的一部分)使用Ollama和调用该模型langchain_community
让我们在 requirement.txt 中定义依赖项。

现在让我们定义一个 Dockerfile 来构建 Streamlit 应用程序的 docker 镜像。
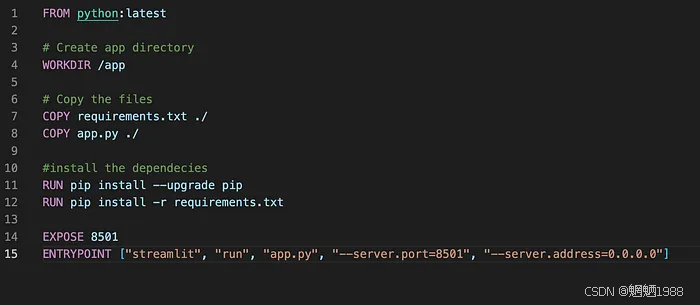
我们使用 Python docker 镜像作为基础镜像,并创建一个名为 的工作目录/app。然后我们将应用程序文件复制到那里,并运行pip installs来安装所有依赖项。然后我们公开端口 8501 并启动streamlit应用程序。
我们可以使用命令构建docker镜像docker build,如下所示。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">docker build .-t viprasingh/ollama-langchain:0.1</span></span></span></span>
作者图片
我们应该能够使用docker images命令检查 Docker 镜像是否已构建,如下所示。

作者图片
现在让我们构建一个 docker-compose 配置文件,定义 Streamlit 应用程序和 Ollama 容器的网络,以便它们可以相互交互。我们还将定义各种端口配置,如上图所示。对于 Ollama,我们还将映射卷,以便无论提取什么模型,都会保留下来。
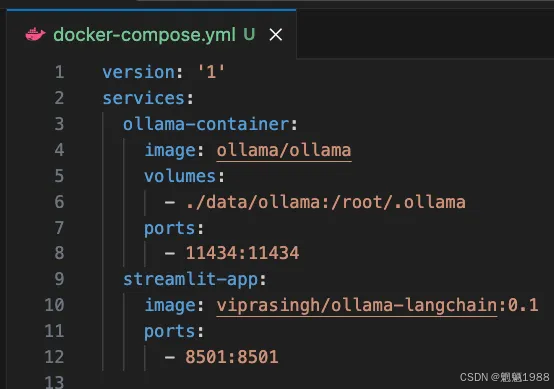
docker-compose.yml
我们可以通过运行 docker-compose up 命令来启动应用程序,一旦执行docker-compose up,我们就会看到两个容器都开始运行,如下面的屏幕截图所示。
作者图片
我们应该能够通过执行docker-compose ps以下命令看到正在运行的容器。
作者图片
我们现在通过调用http://localhost:11434来检查 Ollama 是否正在运行,如下面的屏幕截图所示。
现在让我们通过使用 docker exec 命令登录到 docker 容器来下载所需的模型,如下所示。
<span style="color:rgba(0, 0, 0, 0.8)"><span style="background-color:#ffffff"><span style="background-color:#f9f9f9"><span style="color:#242424">docker <span style="color:#5c2699">exec</span> -it docker-pdf-chatbot-ollama-container-1 ollama run phi</span></span></span></span>由于我们使用的是模型 phi,因此我们正在提取该模型并通过运行它来测试它。我们可以看到下面的屏幕截图,其中下载了 phi 模型并将开始运行(由于我们使用了-it标志,因此我们应该能够与示例提示进行交互和测试)

我们可以在本地文件夹中看到下载的模型文件和清单./data/ollama(该文件夹内部映射到/root/.ollama容器,Ollama 在此处查找下载的模型以提供服务)
作者图片
现在让我们通过在浏览器上打开http://localhost:8501来运行访问我们的 streamlit 应用程序。以下屏幕截图显示了界面
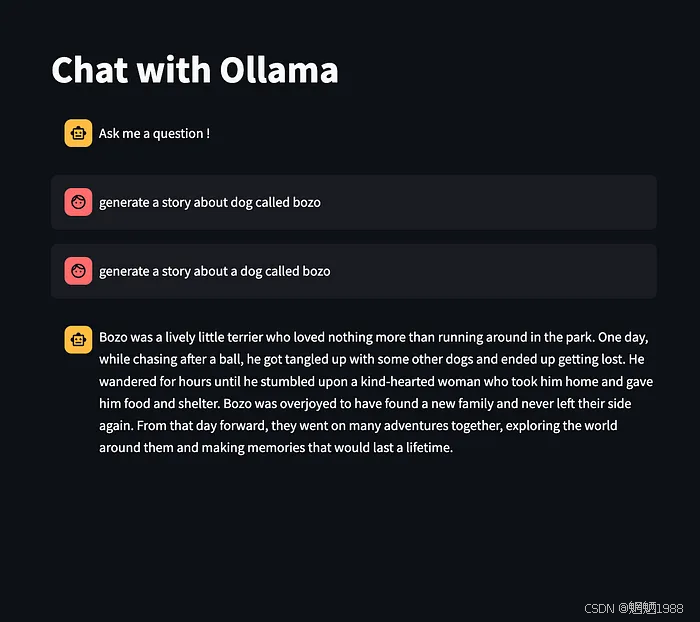
让我们尝试运行一个提示“生成一个关于一只叫 bozo 的狗的故事”。我们应该能够看到控制台日志反映了来自我们的 Streamlit 应用程序的 API 调用,如下所示

我们可以在下面的截图中看到我发送的提示所得到的响应
我们可以通过调用 docker-compose down 来关闭部署
以下屏幕截图显示了输出

就这样。在这篇博客上,我们让 Ollama 与 Langchain 合作,并使用 Docker-Compose 将它们部署到 Docker 上,这真是太有趣了
结论
该博客探讨了如何在本地构建大型语言模型 (LLM) 应用程序,重点关注检索增强生成 (RAG) 链。它涵盖了由 Ollama 提供支持的 LLM 服务器、LangChain 框架、用于嵌入的 Chroma 和用于 Web 应用程序的 Streamlit 等组件。它详细介绍了如何使用 Ollama、LangChain、ChromaDB 和 Streamlit 创建聊天机器人应用程序,以及 GitHub 存储库结构和 Docker 部署。总的来说,它提供了有效开发 LLM 应用程序的实用指南。