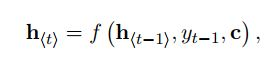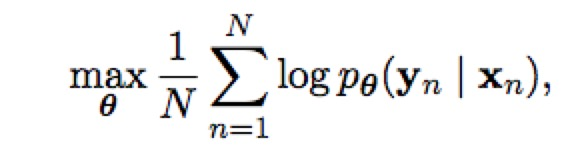Encoder-Decoder
准确来说,Encoder–Decoder是一种框架,许多算法中都有该种框架。Encoder–Decoder是一种思想,因此在解释这种框架的时候需要结合某种算法来详细说明它的实现方式。
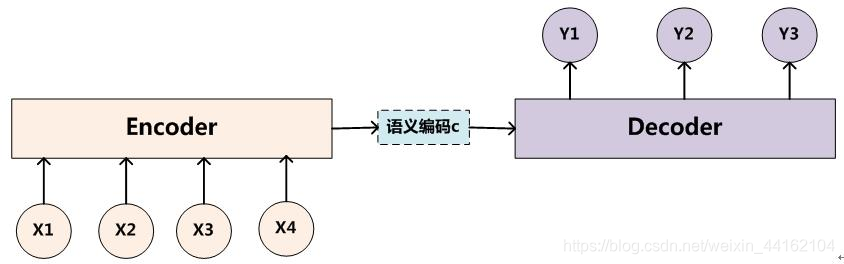
Encoder-Decoder框架有一个最显著的特征就是它是一个End-to-End学习的算法,在机器翻译中,比如将中文翻译成英语。编码是将输入序列转化成一个固定长度的向量;解码就是将之前生成的固定向量再转化成输出序列。
现在我们大体了解了一个工作的流程Encoder-Decoder后,我们来介绍一个深度学习当中,最经典的Encoder-Decoder实现方式,即用RNN来实现。
在RNN Encoder-Decoder的工作当中,我们用一个RNN去模拟大脑的读入动作,用一个特定长度的特征向量去模拟我们的记忆,然后再用另外一个RNN去模拟大脑思考得到答案的动作,将三者组织起来利用就成了一个可以实现Sequence2Sequence工作的“模拟大脑”了。
而我们剩下的工作也就是如何正确的利用RNN去实现,以及如何正确且合理的组织这三个部分了。
参考:http://blog.csdn.net/mebiuw/article/details/53341404
Seq2Seq
seq2seq 是一个Encoder–Decoder 结构的网络,它的输入是一个序列,输出也是一个序列。 Encoder 中将一个可变长度的信号序列变为固定长度的向量表达,Decoder 将这个固定长度的向量变成可变长度的目标的信号序列。
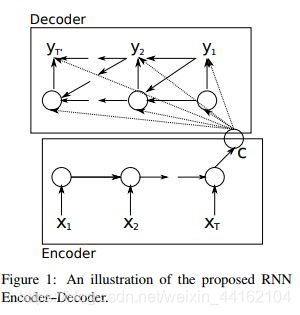
Seq2Seq模型是基于输入序列,预测未知输出序列的模型。它有两个部分组成,对输入序列的Encoder编码阶段和生成输出序列的Decoder解码阶段。定义输入序列[x1,x2,…,xm],由m个固定长度为d的向量构成;输出序列为[y1,y2,…,yn],由n个固定长度为d的向量构成;
上图中可以看出,Encoder使用RNN编码后形成语义向量C.再将C作为输出序列模型Decoder的输入。解码过程中每一个时间点t的输入是上一个时刻隐层状态ht-1和中间语义向量C和上一个时刻的预测输出yt-1.之后将每个时刻的yt相乘得到整个序列出现的概率。其中f是非线性的激活函数。
最后Seq2Seq两个部分(Encoder和Decoder)联合训练的目标函数是最大化条件似然函数。其中θ为模型的参数,N为训练集的样本个数。
参考:https://blog.csdn.net/u014732537/article/details/81206267