文章目录
week 67 TMDM
摘要
本周阅读了题为Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting的论文。本文提出Transformer调制扩散模型(TMDM),结合条件扩散生成过程与Transformer,针对多变量时间序列(MTS)提供包含不确定性的精确分布预测。TMDM通过捕捉协变量依赖性和集成基于转换的预测方法提升性能,并引入两个新指标评估不确定性估计。实验表明,TMDM在6个数据集上的概率预测表现优异。
Abstract
This week’s weekly newspaper decodes the paper entitled Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting. This paper introduces the Transformer Modulated Diffusion Model (TMDM), which combines conditional diffusion generation processes with the Transformer architecture to provide accurate distribution predictions for multivariate time series (MTS) that include uncertainty. TMDM enhances performance by capturing covariate dependencies and integrating transformation-based prediction methods. Additionally, it introduces two new metrics to evaluate uncertainty estimation. Experiments show that TMDM exhibits excellent probabilistic prediction performance on six datasets.
1. 题目
标题:Transformer-Modulated Diffusion Models for Probabilistic Multivariate Time Series Forecasting
作者:Changze Lv 1 Yansen Wang 2 Dongqi Han 2 Xiaoqing Zheng 1 Xuanjing Huang 1 Dongsheng Li 2
发布:Proceedings of the 41 st International Conference on Machine Learning, Vienna, Austria. PMLR 235, 2024. Copyright 2024 by the author(s).
链接:https://openreview.net/forum?id=qae04YACHs
code:https://github.com/LiYuxin321/TMDM
概述:引入了一个Transformer-Modulated Diffusion Model(TMDM),将条件扩散生成过程与Transformer结合到一个统一的框架中,以实现对MTS的精确分布预测。TMDM利用Transformer从历史时间序列数据中提取关键信息。然后,将这些信息用作先验知识,捕捉扩散模型中正向和反向过程中的协变量依赖性。此外,我们将经过精心设计的基于Transformer的预测方法无缝集成到TMDM中,以提高其整体性能。
2. Abstract
Transformer在多变量时间序列(MTS)预测中得到了广泛的应用,并提供了令人印象深刻的性能。尽管如此,这些现有的基于Transformer的方法往往忽略了一个重要方面:将不确定性纳入预测序列,这在决策中具有重要价值。在本文中,我们引入了Transformer调制扩散模型(TMDM),将条件扩散生成过程与Transformer结合到一个统一的框架中,以实现对MTS的精确分布预测。TMDM利用Transformer的力量从历史时间序列数据中提取重要见解。然后将该信息用作先验知识,在扩散模型的正向和反向过程中捕获协变量依赖性。此外,我们将精心设计的基于转换的预测方法无缝集成到TMDM中,以提高其整体性能。此外,我们引入了两个新的指标来评估不确定性估计的性能。通过在6个数据集上使用4个评估指标的广泛实验,我们建立了TMDM在概率MTS预测中的有效性。
3. 文献解读
3.1 Introduction
时间序列预测在机器学习的商业和科学领域都发挥着关键作用,是支持一系列下游应用决策的重要工具。这些应用包括但不限于金融定价分析(Kim, 2003)、交通规划(Sapankevych & Sankar, 2009)和天气模式预测(Chatfield, 2000),以及其他各种领域(Rasul et al., 2022)。时间序列预测的主要目标是基于表示为 x 0 : N ∈ R d × N x_{0:N}\in\mathbb{R}^{d\times{N}} x0:N∈Rd×N的历史时间序列数据集,预测响应变量 y 0 : M ∈ R d × M y_{0:M}\in\mathbb{R}^{d\times M} y0:M∈Rd×M。这个预测过程的特征是函数 f ( x 0 : N ) ∈ R d × M f(\boldsymbol{x_{0:N}})\in\mathbb{R}^{d\times M} f(x0:N)∈Rd×M,其中f是一个确定性函数,它将历史时间序列 x 0 : N x_{0:N} x0:N转换为未来时间序列 y 0 : M y_{0:M} y0:M。
当前的时间序列扩散模型(Rasul et al., 2021a;Tashiro等人,2021;Alcaraz & Strodthoff, 2022;Shen & Kwok, 2023)主要专注于制作有效的条件嵌入以馈送到去噪网络中,这反过来又指导扩散模型中的反向过程。例如,TimeGrad (Rasul et al., 2021a)使用来自RNN的隐藏状态作为条件嵌入,而TimeDiff (Shen & Kwok, 2023)基于为时间序列数据明确设计的两个特征构建这种嵌入。与在反向过程中只使用条件嵌入的流行方法不同,TMDM在正向和反向过程中都使用条件信息作为先验知识。我们认为这种方法是利用现有基于Transformer的时间序列模型捕获的表征的更有效的方法(Liu et al., 2022;Wang et al., 2022)作为条件,考虑到他们对估计条件均值 E [ y 0 : M ∣ x 0 : N ] \mathbb{E}[\boldsymbol{y}_{0:M}\mid\boldsymbol{x}_{0:N}] E[y0:M∣x0:N]的熟练程度。通过这种强大的先验知识,TMDM旨在捕获未来时间序列 y 0 : M \boldsymbol{y}_{0:M} y0:M的不确定性,最终提供对整个分布的全面估计。
3.2 创新点
总结了以下贡献:
- 在概率多元时间序列预测领域,我们引入了基于Transformer的扩散生成框架TMDM。TMDM利用由设计良好的基于Transformer的时间序列模型捕获的表示作为先验。我们考虑了扩散模型中正向和反向过程的协变量依赖性,从而对未来时间序列进行了高度准确的分布估计。
- TMDM将扩散模型和基于Transformer的模型集成在一个内聚贝叶斯框架内,采用混合优化策略,作为一个即插即用框架,与现有设计良好的基于Transformer的预测模型无缝兼容;利用其强大的估计时间序列条件均值的能力,便于对完全分布的估计。
- 在实验评估中,我们探索了预测区间覆盖概率(PICP) (Yao et al., 2019)和分位数区间覆盖误差(QICE) (Han et al., 2022)作为指标在概率多元时间序列预测任务中的应用。这些指标为评估概率多变量时间序列预测模型的不确定性估计能力提供了有价值的见解。我们的研究证明了TMDM在六个真实数据集的四个分布指标上的出色表现,强调了其在概率MTS预测中的有效性。
4. 网络结构
在本节中,我们介绍了TMDM,这是一个结合了扩散生成过程的新框架(Ho et al., 2020;Sohl-Dickstein et al., 2015)和设计良好的Transformer结构(Liu et al., 2022;Wang et al., 2022)。这些Transformer模型擅长于准确估计条件均值
E
[
y
0
:
M
∣
x
0
:
N
]
\mathbb{E}[\boldsymbol{y}_{0:M}\mid x_{0:N}]
E[y0:M∣x0:N],而TMDM扩展了这一能力,以恢复未来时间序列y0:M的完整分布。如图1所示,TMDM由两个主要组成部分组成:Transformer驱动的条件分布学习模型(条件生成模型)和基于条件扩散的时间序列生成模型。这两个模型被集成到一个统一的贝叶斯框架中,利用混合优化方法。从概念的角度来看,TMDM可以被视为贝叶斯生成模型(Tran et al., 2019),其生成过程可以表示为:
p
(
y
0
:
M
0
)
=
∫
y
0
:
M
1
:
T
∫
z
p
(
y
0
:
M
T
∣
y
^
0
:
M
)
∏
t
=
1
T
p
(
y
0
:
M
t
−
1
∣
y
0
:
M
t
,
y
^
0
:
M
)
p
(
y
^
0
:
M
∣
z
)
p
(
z
)
d
z
d
y
0
:
M
1
:
T
(8)
p(\boldsymbol y^0_{0:M})=\int_{\boldsymbol y^{1:T}_{0:M}}\int_{\bold z }p(\boldsymbol y^T_{0:M}|\hat {\boldsymbol y}_{0:M})\prod^T_{t=1}p(\boldsymbol y^{t-1}_{0:M}|\boldsymbol y^t_{0:M},\hat {\boldsymbol y}_{0:M})p(\hat {\boldsymbol y}_{0:M}|\bold z)p(\bold z)d\bold z d \boldsymbol y^{1:T}_{0:M}\tag{8}
p(y0:M0)=∫y0:M1:T∫zp(y0:MT∣y^0:M)t=1∏Tp(y0:Mt−1∣y0:Mt,y^0:M)p(y^0:M∣z)p(z)dzdy0:M1:T(8)
在本文中,我们利用精心设计的Transformer,包括非平稳Transformer(Liu et al., 2022),自耦Transformer(Wu et al., 2021)和Informer(Zhou et al., 2021),来捕获嵌入在历史时间序列 x 0 : M x_{0:M} x0:M中的信息。我们利用这些信息对潜在变量z进行建模,进而生成条件表示 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M。这种表示作为后续正向和反向过程的条件。
4.1 学习Transformer的驱动条件
现有时间序列扩散模型(Rasul et al., 2021a;Tashiro等人,2021;Alcaraz & Strodthoff, 2022;Shen & Kwok, 2023)主要专注于设计有效的条件嵌入来指导反向过程。相比之下,我们的方法提倡利用已建立的基于Transformer的时间序列模型所捕获的表示。这种转变提供了几个明显的优势。首先,近年来在点估计时间序列预测任务方面取得了重大进展。对时间序列特性的广泛研究导致了为此目的量身定制专用Transformer的建议(Liu et al., 2022;Wu et al., 2021;Wang et al., 2022)。我们认为,采用这种Transformer衍生的条件比依靠自行设计的条件嵌入更有效。其次,这些专用Transformer表现出较强的估计条件均值 E [ y 0 : M ∣ x 0 : N ] \mathbb{E}[y_{0:M}|x_{0:N}] E[y0:M∣x0:N]的能力。采用该估计均值作为条件,扩散模型可以更有效地集中于不确定性的估计,简化了生成过程。相反,使用其他特殊设计的条件,如未来的混合(Shen & Kwok, 2023),可能会引入新的信息,但需要扩散模型同时估计平均值和不确定性,使生成更加复杂。最后,TMDM作为一个通用的即插即用框架,弥合了点估计和分布估计之间的差距。如果改进的Transformer结构用于点估计出现,我们可以无缝地将这些进步集成到分布估计领域。
给定Transformer结构 T ( ⋅ ) \mathscr{T}(\cdot) T(⋅)和历史时间序列 x 0 : N x_{0:N} x0:N,我们可以用 T ( x 0 : N ) \mathscr{T}(\boldsymbol{x}_{0:N}) T(x0:N)来表示。这个表示是近似z的真实后验分布的指导因素。这个过程定义如下:
q ( z ∣ T ( x 0 : N ) ) ∼ N ( μ ~ z ( T ( x 0 : N ) ) , σ ~ z ( T ( x 0 : N ) ) ) \begin{equation*} q\left(\boldsymbol{z} \mid \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right) \sim \mathcal{N}\left(\tilde{\boldsymbol{\mu}}_{z}\left(\mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right), \tilde{\boldsymbol{\sigma}}_{z}\left(\mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right)\right) \tag{9} \end{equation*} q(z∣T(x0:N))∼N(μ~z(T(x0:N)),σ~z(T(x0:N)))(9)
给定一个学习良好的z,我们可以生成如下的条件表示 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M
z ∼ N ( 0 , 1 ) and y ^ 0 : M ∼ N ( μ z ( z ) , σ z ) \begin{equation*} \boldsymbol{z} \sim \mathcal{N}(0,1) \quad \text { and } \quad \hat{\boldsymbol{y}}_{0: M} \sim \mathcal{N}\left(\boldsymbol{\mu}_{z}(\boldsymbol{z}), \boldsymbol{\sigma}_{z}\right) \tag{10} \end{equation*} z∼N(0,1) and y^0:M∼N(μz(z),σz)(10)
本文采用神经网络对三个非线性函数 μ ~ z , σ ~ z , a n d μ z \tilde{\mu}_z,\tilde{\sigma}_z,\mathrm{and~}\mu_z μ~z,σ~z,and μz,进行建模。我们将表示协方差矩阵的σz初始化为单位矩阵I。通过这种方式,我们定义了一个潜在变量z来总结设计良好的Transformer捕获的信息。然后使用这个潜在变量为TMDM中随后的正向和反向过程生成条件表示 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M。
4.2条件扩散的时间序列生成模型
Algorithm 1 Training
Algorithm 2 Inference
Initialize the parameters;
repeat
\quad
Draw
y
0
:
M
0
∼
q
(
y
0
:
M
0
∣
x
0
:
N
)
\boldsymbol{y}_{0: M}^{0} \sim q\left(\boldsymbol{y}_{0: M}^{0} \mid \boldsymbol{x}_{0: N}\right)
y0:M0∼q(y0:M0∣x0:N)
\quad
Draw
t
∼
Uniform
(
{
1
,
2
,
…
,
T
}
)
t \sim \operatorname{Uniform}(\{1,2, \ldots, T\})
t∼Uniform({1,2,…,T})
\quad
Draw
ϵ
∼
N
(
0
,
1
)
\boldsymbol{\epsilon} \sim \mathcal{N}(0,1)
ϵ∼N(0,1)
Compute the loss in Eq. 16
\quad
Take numerical optimization step 5:
\quad
on:
∇
L
ELbO
\nabla \mathcal{L}_{\text {ELbO }}
∇LELbO
until converged
y
0
:
M
T
∼
N
(
y
^
0
:
M
,
I
)
\boldsymbol{y}_{0: M}^{T} \sim \mathcal{N}\left(\hat{\boldsymbol{y}}_{0: M}, \boldsymbol{I}\right)
y0:MT∼N(y^0:M,I)
\quad
for
t
=
T
\mathrm{t}=T
t=T to 1 do
\quad
\quad
Calculate reparameterize:
Y
0
:
M
t
=
(
1
/
α
t
)
(
y
t
−
(
1
−
\boldsymbol{Y}_{0: M}^{t}=\left(1 / \alpha^{t}\right)\left(\boldsymbol{y}^{t}-(1-\right.
Y0:Mt=(1/αt)(yt−(1−
\quad
\quad
α
t
)
y
^
0
:
M
−
1
−
α
t
ε
θ
(
y
t
,
y
^
0
:
M
,
t
)
)
\left.\left.\sqrt{\alpha^{t}}\right) \hat{\boldsymbol{y}}_{0: M}-\sqrt{1-\alpha^{t}} \varepsilon_{\theta}\left(\boldsymbol{y}^{t}, \hat{\boldsymbol{y}}_{0: M}, t\right)\right)
αt)y^0:M−1−αtεθ(yt,y^0:M,t))
\quad
\quad
if
t
>
1
t>1
t>1 : draw
ϵ
∼
N
(
0
,
1
)
\boldsymbol{\epsilon} \sim \mathcal{N}(0,1)
ϵ∼N(0,1)
\quad
\quad
\quad
y
0
:
M
t
−
1
=
γ
0
Y
0
:
M
t
+
γ
1
y
0
:
M
t
+
γ
2
y
^
0
:
M
+
β
~
t
ε
\boldsymbol{y}_{0: M}^{t-1}=\gamma_{0} \boldsymbol{Y}_{0: M}^{t}+\gamma_{1} \boldsymbol{y}_{0: M}^{t}+\gamma_{2} \hat{\boldsymbol{y}}_{0: M}+\sqrt{\tilde{\boldsymbol{\beta}}^{t}} \boldsymbol{\varepsilon}
y0:Mt−1=γ0Y0:Mt+γ1y0:Mt+γ2y^0:M+β~tε
\quad
\quad
else:
y
0
:
M
t
−
1
=
Y
0
:
M
t
\quad \boldsymbol{y}_{0: M}^{t-1}=\boldsymbol{Y}_{0: M}^{t}
y0:Mt−1=Y0:Mt
\quad
end for
与假设扩散过程的端点 y 0 : M T y_{0:M}^T y0:MT,符合标准正态分布N(0,1)的传统扩散模型不同,我们将条件表示 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M合并到 p ( y 0 : M T ) p(\boldsymbol{y}_{0:M}^T) p(y0:MT)中,以更好地解释方程10中的条件信息。受Han等人(2022)的启发,我们将扩散过程的端点建模如下:
p ( y 0 : M T ∣ y ^ 0 : M ) = N ( y ^ 0 : M , I ) \begin{equation*} p\left(\boldsymbol{y}_{0: M}^{T} \mid \hat{\boldsymbol{y}}_{0: M}\right)=\mathcal{N}\left(\hat{\boldsymbol{y}}_{0: M}, \boldsymbol{I}\right) \tag{11} \end{equation*} p(y0:MT∣y^0:M)=N(y^0:M,I)(11)
其中,公式10中定义的 y ^ 0 : M \hat{y}_{0:M} y^0:M包含了Transformer捕获的信息。在式11中, y ^ 0 : M \hat{y}_{0:M} y^0:M可以看作是基于 x 0 : N x_{0:N} x0:N估计条件均值的先验知识。对于扩散调度 { β t } t = 1 : T ∈ ( 0 , 1 ) \{\beta^t\}_{t=1:T}\in(0,1) {βt}t=1:T∈(0,1),则前向过程在其他时间步长的条件分布可定义为:
q ( y 0 : M t ∣ y 0 : M t − 1 , y ^ 0 : M ) ∼ N ( y 0 : M t ∣ 1 − β t y 0 : M t − 1 + ( 1 − 1 − β t ) y ^ 0 : M , β t I ) \begin{equation*} q\left(\boldsymbol{y}_{0: M}^{t} \mid \boldsymbol{y}_{0: M}^{t-1}, \hat{\boldsymbol{y}}_{0: M}\right) \sim \mathcal{N}\left(\boldsymbol{y}_{0: M}^{t} \mid \sqrt{1-\beta^{t}} \boldsymbol{y}_{0: M}^{t-1}+\left(1-\sqrt{1-\beta^{t}}\right) \hat{\boldsymbol{y}}_{0: M}, \beta^{t} \boldsymbol{I}\right) \tag{12} \end{equation*} q(y0:Mt∣y0:Mt−1,y^0:M)∼N(y0:Mt∣1−βty0:Mt−1+(1−1−βt)y^0:M,βtI)(12)
在实际应用中,我们用任意时间步长t从 y 0 : M 0 y_{0:M}^0 y0:M0直接采样 y 0 : M t y_{0:M}^t y0:Mt:
q ( y 0 : M t ∣ y 0 : M 0 , y ^ 0 : M ) ∼ N ( y 0 : M t ∣ α t y 0 : M 0 + ( 1 − α t ) y ^ 0 : M , ( 1 − α t ) I ) \begin{equation*} q\left(\boldsymbol{y}_{0: M}^{t} \mid \boldsymbol{y}_{0: M}^{0}, \hat{\boldsymbol{y}}_{0: M}\right) \sim \mathcal{N}\left(\boldsymbol{y}_{0: M}^{t} \mid \sqrt{\alpha^{t}} \boldsymbol{y}_{0: M}^{0}+\left(1-\sqrt{\alpha^{t}}\right) \hat{\boldsymbol{y}}_{0: M},\left(1-\sqrt{\alpha^{t}}\right) \boldsymbol{I}\right) \tag{13} \end{equation*} q(y0:Mt∣y0:M0,y^0:M)∼N(y0:Mt∣αty0:M0+(1−αt)y^0:M,(1−αt)I)(13)
在这里,我们定义 α ˉ t : = 1 − β t a n d α t : = ∏ t = 1 T α ˉ t \bar{\alpha}^{t}:=1-\beta^{t}\mathrm{~and~}\alpha^{t}:=\prod_{t=1}^{T}\bar{\alpha}^{t} αˉt:=1−βt and αt:=∏t=1Tαˉt。在Eq. 12平均项中,扩散过程可以被概念化为真实数据 y 0 : M 0 y_{0:M}^{0} y0:M0与条件表示 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M之间的插值。它从真实数据 y 0 : M 0 y_{0:M}^{0} y0:M0开始,逐渐过渡到 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M。该方法有效地利用了Transformer T ( ⋅ ) \mathscr{T}(\cdot) T(⋅)的可靠条件均值估计 E [ y 0 : M ∣ x 0 : N ] \mathbb{E}[\boldsymbol{y}_{0:M}|{\boldsymbol{x}_{0:N}}] E[y0:M∣x0:N]。在相应的逆向过程中,以含有能够准确估计 E [ y 0 : M ∣ x 0 : N ] \mathbb{E}[\boldsymbol{y}_{0:M}|{\boldsymbol{x}_{0:N}}] E[y0:M∣x0:N]的信息的 y ^ 0 : M \hat{y}_{0:M} y^0:M发起,生成过程显著简化。如果提供的条件足够好,则模型可以专门关注不确定性估计。
类似于许多为时间序列设计的扩散模型(Rasul et al., 2021a;Shen &Kwok, 2023),将条件表示纳入反向过程是至关重要的 y ^ 0 : M \hat{\boldsymbol{y}}_{0:M} y^0:M。考虑Eq. 12中的正向过程,正向过程对应的可管理后验为:
q ( y 0 : M t − 1 ∣ y 0 : M 0 , y 0 : M t , y ^ 0 : M ) ∼ N ( y 0 : M t − 1 ∣ γ 0 y 0 : M 0 + γ 1 y 0 : M t + γ 2 y ^ 0 : M , β ~ t I ) γ 0 = β t α t − 1 1 − α t , γ 1 = ( 1 − α t − 1 ) α ˉ t 1 − α t , γ 2 = 1 + ( α t − 1 ) ( α ˉ t + α t − 1 ) 1 − α t , β ~ t = ( 1 − α t − 1 ) 1 − α t β t \begin{gather*} q\left(\boldsymbol{y}_{0: M}^{t-1} \mid \boldsymbol{y}_{0: M}^{0}, \boldsymbol{y}_{0: M}^{t}, \hat{\boldsymbol{y}}_{0: M}\right) \sim \mathcal{N}\left(\boldsymbol{y}_{0: M}^{t-1} \mid \gamma_{0} \boldsymbol{y}_{0: M}^{0}+\gamma_{1} \boldsymbol{y}_{0: M}^{t}+\gamma_{2} \hat{\boldsymbol{y}}_{0: M}, \tilde{\beta}^{t} \boldsymbol{I}\right) \\ \gamma_{0}=\frac{\beta^{t} \sqrt{\alpha^{t-1}}}{1-\alpha^{t}}, \gamma_{1}=\frac{\left(1-\alpha^{t-1}\right) \sqrt{\bar{\alpha}^{t}}}{1-\alpha^{t}}, \gamma_{2}=1+\frac{\left(\sqrt{\alpha^{t}}-1\right)\left(\sqrt{\bar{\alpha}^{t}}+\sqrt{\alpha^{t-1}}\right)}{1-\alpha^{t}}, \tilde{\beta}^{t}=\frac{\left(1-\alpha^{t-1}\right)}{1-\alpha^{t}} \beta^{t} \tag{14} \end{gather*} q(y0:Mt−1∣y0:M0,y0:Mt,y^0:M)∼N(y0:Mt−1∣γ0y0:M0+γ1y0:Mt+γ2y^0:M,β~tI)γ0=1−αtβtαt−1,γ1=1−αt(1−αt−1)αˉt,γ2=1+1−αt(αt−1)(αˉt+αt−1),β~t=1−αt(1−αt−1)βt(14)
4.3混合优化
在本文中,我们将条件生成模型和去噪模型整合为一个统一的优化目标。条件生成模型结合了Transformer T ( ⋅ ) \mathscr{T}(\cdot) T(⋅)结构和与潜在变量z相关的网络。在扩散模型组件中,训练了一个去噪模型。如式8所示,TMDM的优化目标是使对数边际似然的证据下界(ELBO)最大化,其公式为:
log p ( y 0 : M 0 ∣ x 0 : N ) ≥ log E q ( y 0 : M 1 : T , z ∣ y 0 : M 0 , y ^ 0 : M , T ( x 0 : N ) ) [ p ( y 0 : M 0 : T ∣ y ^ 0 : M ) p ( y ^ 0 : M ∣ z ) p ( z ) q ( y 0 : M 1 : T , z ∣ y 0 : M 0 , y ^ 0 : M , T ( x 0 : N ) ) ] = E q ( y 0 : M 1 : T ∣ y 0 : M 0 , y ^ 0 : M ) [ log p ( y ^ 0 : M 0 : T ∣ y ^ 0 : M ) q ( y 0 : M 11 ∣ y ^ 0 : M 0 , y ^ 0 : M ) ] + E q ( z ∣ T ( x 0 : N ) ) [ log p ( y ^ 0 : M ∣ z ) p ( z ) q ( z ∣ T ( x 0 : N ) ) ] \begin{align*} & \log p\left(\boldsymbol{y}_{0: M}^{0} \mid \boldsymbol{x}_{0: N}\right) \geq \log \mathbb{E}_{q\left(\boldsymbol{y}_{0: M}^{1: T}, \boldsymbol{z} \mid \boldsymbol{y}_{0: M}^{0}, \hat{\boldsymbol{y}}_{0: M}, \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right)}\left[\frac{p\left(\boldsymbol{y}_{0: M}^{0: T} \mid \hat{\boldsymbol{y}}_{0: M}\right) p\left(\hat{\boldsymbol{y}}_{0: M} \mid \boldsymbol{z}\right) p(\boldsymbol{z})}{q\left(\boldsymbol{y}_{0: M}^{1: T}, \boldsymbol{z} \mid \boldsymbol{y}_{0: M}^{0}, \hat{\boldsymbol{y}}_{0: M}, \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right)}\right] \\ & =\mathbb{E}_{q\left(\boldsymbol{y}_{0: M}^{1: T} \mid \boldsymbol{y}_{0: M}^{0}, \hat{\boldsymbol{y}}_{0: M}\right)}\left[\log \frac{p\left(\hat{y}_{0: M}^{0: T} \mid \hat{\boldsymbol{y}}_{0: M}\right)}{q\left(\boldsymbol{y}_{0: M}^{11} \mid \hat{y}_{0: M}^{0}, \hat{\boldsymbol{y}}_{0: M}\right)}\right]+\mathbb{E}_{q\left(\boldsymbol{z} \mid \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right)}\left[\log \frac{p\left(\hat{\boldsymbol{y}}_{0: M} \mid \boldsymbol{z}\right) p(\boldsymbol{z})}{q\left(\boldsymbol{z} \mid \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right)}\right] \tag{15} \end{align*} logp(y0:M0∣x0:N)≥logEq(y0:M1:T,z∣y0:M0,y^0:M,T(x0:N))[q(y0:M1:T,z∣y0:M0,y^0:M,T(x0:N))p(y0:M0:T∣y^0:M)p(y^0:M∣z)p(z)]=Eq(y0:M1:T∣y0:M0,y^0:M)[logq(y0:M11∣y^0:M0,y^0:M)p(y^0:M0:T∣y^0:M)]+Eq(z∣T(x0:N))[logq(z∣T(x0:N))p(y^0:M∣z)p(z)](15)
在Eq. 15中,第一项,记为 L d i f f u s i o n \mathcal{L}_{\mathrm{diffusion}} Ldiffusion,引导去噪模型预测不确定性,同时巧妙地调整条件生成模型,以提供更合适的条件表示。我们认为这是混合优化的一个优势。第二项 L c o n d \mathcal{L}_{\mathrm{cond}} Lcond的引入是为了保持条件生成模型对条件均值 E [ y 0 : M ∣ x 0 : N ] \mathbb{E}[\boldsymbol{y}_{0:M}|\boldsymbol{x}_{0:N}] E[y0:M∣x0:N]的准确估计能力。通过利用设计良好的转换器的功能,它还有助于生成改进的条件表示。其中, D K L ( q ∥ p ) \mathbf{D}_{KL}(q\|p) DKL(q∥p)表示从分布p到分布q的Kullback-Leibler (KL)散度。上述目标可表示为:
L E L B O = E q [ − log p ( y 0 : M 0 ∣ y 0 : M 1 , y ^ 0 : M ) ] + D K L ( q ( y 0 : M T ∣ y 0 : M 0 , y ^ 0 : M ) ∥ p ( y 0 : M T ∣ y ^ 0 : M ) ) + ∑ t = 2 T D K L ( q ( y 0 : M t − 1 ∣ y 0 : M 0 , y 0 : M t , y ^ 0 : M ) ∥ p ( y 0 : M t − 1 ∣ y 0 : M t , y ^ 0 : M ) ) + E q ( z ∣ T ( x 0 : N ) ) [ − log p ( y ^ 0 : M ∣ z ) ] + D K L ( q ( z ∣ T ( x 0 : N ) ) ∥ p ( z ) ) \begin{align*} \mathcal{L}_{\mathrm{ELBO}}= & \mathbb{E}_{q}\left[-\log p\left(\boldsymbol{y}_{0: M}^{0} \mid \boldsymbol{y}_{0: M}^{1}, \hat{\boldsymbol{y}}_{0: M}\right)\right]+\mathbf{D}_{K L}\left(q\left(\boldsymbol{y}_{0: M}^{T} \mid \boldsymbol{y}_{0: M}^{0}, \hat{\boldsymbol{y}}_{0: M}\right) \| p\left(\boldsymbol{y}_{0: M}^{T} \mid \hat{\boldsymbol{y}}_{0: M}\right)\right) \\ & +\sum_{t=2}^{T} \mathbf{D}_{K L}\left(q\left(\boldsymbol{y}_{0: M}^{t-1} \mid \boldsymbol{y}_{0: M}^{0}, \boldsymbol{y}_{0: M}^{t}, \hat{\boldsymbol{y}}_{0: M}\right) \| p\left(\boldsymbol{y}_{0: M}^{t-1} \mid \boldsymbol{y}_{0: M}^{t}, \hat{\boldsymbol{y}}_{0: M}\right)\right) \tag{16}\\ & +\mathbb{E}_{q\left(\boldsymbol{z} \mid \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right)}\left[-\log p\left(\hat{\boldsymbol{y}}_{0: M} \mid \boldsymbol{z}\right)\right]+\mathbf{D}_{K L}\left(q\left(\boldsymbol{z} \mid \mathscr{T}\left(\boldsymbol{x}_{0: N}\right)\right) \| p(\boldsymbol{z})\right) \end{align*} LELBO=Eq[−logp(y0:M0∣y0:M1,y^0:M)]+DKL(q(y0:MT∣y0:M0,y^0:M)∥p(y0:MT∣y^0:M))+t=2∑TDKL(q(y0:Mt−1∣y0:M0,y0:Mt,y^0:M)∥p(y0:Mt−1∣y0:Mt,y^0:M))+Eq(z∣T(x0:N))[−logp(y^0:M∣z)]+DKL(q(z∣T(x0:N))∥p(z))(16)
在式16中,前两行源于 L d i f f u s i o n \mathcal{L}_{\mathrm{diffusion}} Ldiffusion,后两行源于 L c o n d \mathcal{L}_{\mathrm{cond}} Lcond。算法1采用端到端随机梯度下降法对模型参数进行优化。算法2概述了推理过程。
5. 实验结果
数据集:选取了6个具有不同时空动态的真实数据集,包括电力、ILI、ETT、交易所、交通和天气。表1给出了这些数据集的基本统计信息。详情见附录A。
实现细节:在我们的实验中,我们将时间步长设置为T = 1000,并采用β1 = 10−4和βT = 0.02的线性噪声调度,与Ho et al.(2020)的设置一致。对于PICP,我们选择了第2.5和97.5百分位。因此,学习模型的理想PICP值应为95%。我们使用100个样本来近似估计分布,所有实验重复10次,记录均值和标准差。更多细节见附录B。
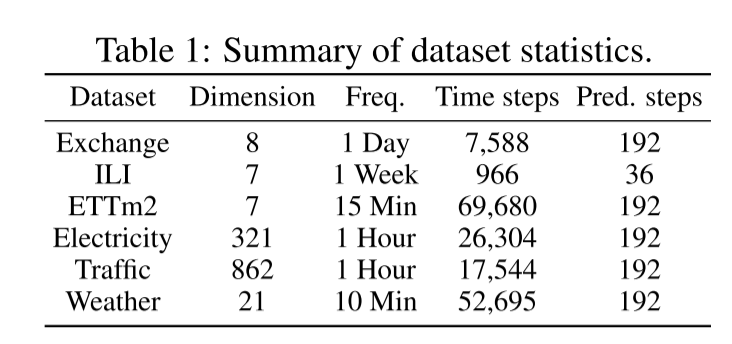
为了强调我们的分布估计能力,我们在图2中给出了预测的中位数,并将50%和90%的分布区间可视化。我们将TMDM与其他三种模型进行比较:TMDM-min: TMDM的简化版本,在条件生成模型中使用基本转换器。TimeDiff:在非自回归设置下运行的最新时间序列预测模型。然而,它主要是为点对点预测任务而设计的,这可能不会优先考虑概率预测。TimeGrad:一个著名的基于扩散的自回归模型。
总的来说,与其他三种模型相比,TMDM展示了更好的分布估计性能。虽然TMDM-min表现出比TMDM更差的均值和不确定性估计,但我们将其归因于在条件生成模型中使用了不同的Transformer。TMDM中使用的NSformer对均值估计功能更强大,有助于更好地估计整体分布。TimeDiff是为点对点预测任务而设计的,它生成宽度不同的分布间隔。因此,离真值较远的样本点是稀疏的。在具有挑战性的场景(列3、4和5)中,由于中间部分缺少点,50%的分布间隔突然扩大。这突出了点对点预测在捕获真实多变量时间序列数据方面的局限性,使其在现实应用中不太实用。TimeGrad依赖于RNN来捕获时序信息,在估计较长的时间序列时表现不佳。有关更详细的结果,请参阅附录E和F。