文章目录
- 前言
- 一、class CVRPModel(nn.Module):__init__(self, **model_params)
- 二、class CVRPModel(nn.Module):pre_forward(self, reset_state)
- 三、class CVRPModel(nn.Module):forward(self, state)
- 四、def _get_encoding(encoded_nodes, node_index_to_pick)
- 五、class CVRP_Encoder(nn.Module)
- 六、class EncoderLayer(nn.Module)
- 七、CVRP_Decoder(nn.Module)
- 八、def reshape_by_heads(qkv, head_num)
- 九、def multi_head_attention(q, k, v, rank2_ninf_mask=None, rank3_ninf_mask=None)
- 十、class AddAndInstanceNormalization(nn.Module):__init__(self, **model_params)
- 十一、class AddAndInstanceNormalization(nn.Module):forward(self, input1, input2)
- 十二、class FeedForward(nn.Module):__init__(self, **model_params)
- 十三、class FeedForward(nn.Module):forward(self, input1)
- 附录
前言
学习代码:
class CVRPModel(nn.Module):
class CVRP_Encoder(nn.Module):
class EncoderLayer(nn.Module):
class CVRP_Decoder(nn.Module):
class AddAndInstanceNormalization(nn.Module):
class AddAndBatchNormalization(nn.Module):
class FeedForward(nn.Module):
/home/tang/RL_exa/NCO_code-main/single_objective/LCH-Regret/Regret-POMO/CVRP/POMO/CVRPModel.py
一、class CVRPModel(nn.Module):init(self, **model_params)
函数功能
init 是 CVRPModel 类的构造函数,负责初始化模型的各个组件。
主要任务包括:
- 接收和存储模型的参数(model_params)。
- 初始化编码器(encoder)和解码器(decoder)子模块。
- 初始化 encoded_nodes 变量,用于存储经过编码的节点数据。
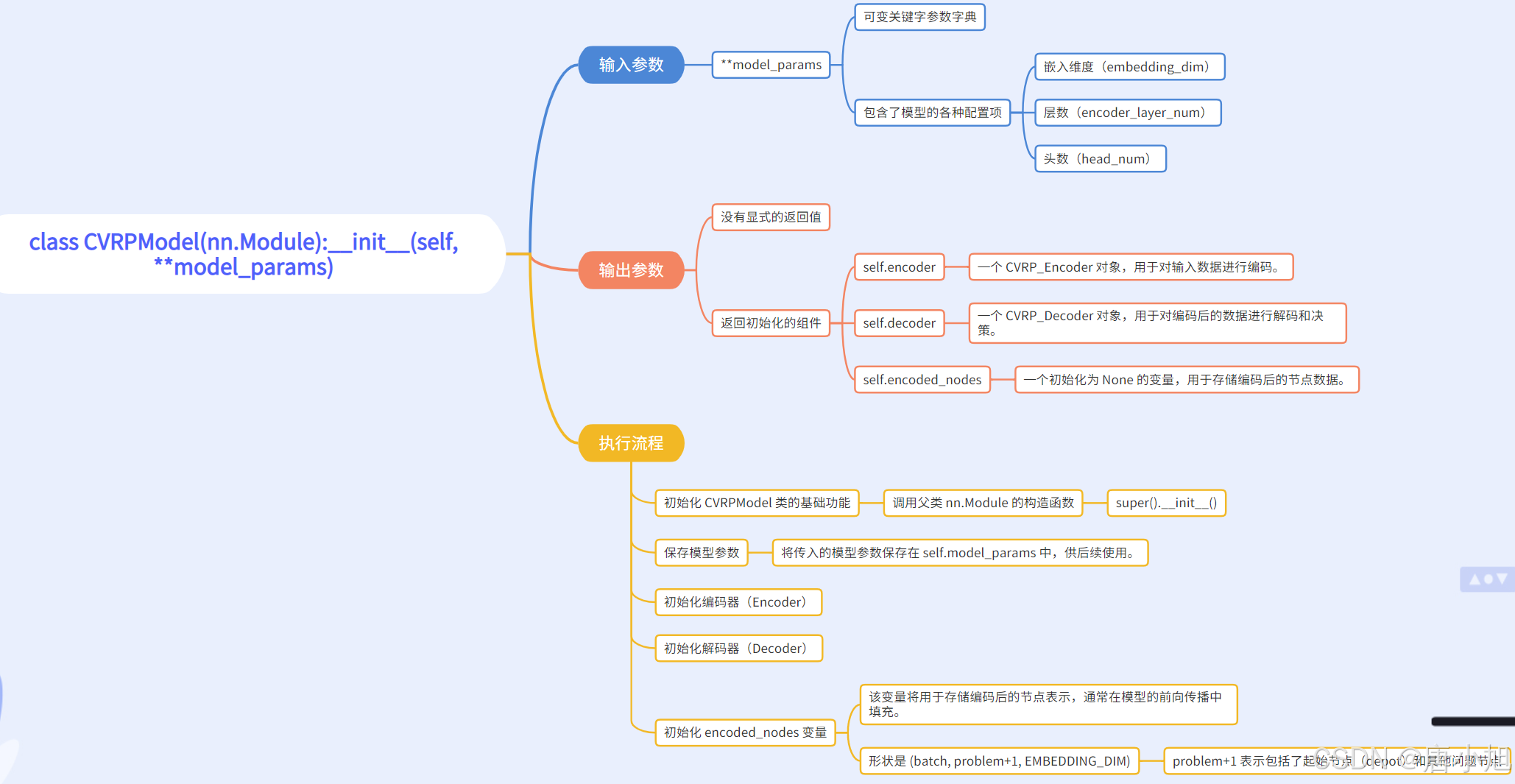
函数代码
def __init__(self, **model_params):
super().__init__()
self.model_params = model_params
self.encoder = CVRP_Encoder(**model_params)
self.decoder = CVRP_Decoder(**model_params)
self.encoded_nodes = None
# shape: (batch, problem+1, EMBEDDING_DIM)
二、class CVRPModel(nn.Module):pre_forward(self, reset_state)
函数功能
pre_forward 是 CVRPModel 类的一个前向传播前的准备函数。它的主要任务是根据给定的初始状态(reset_state)准备和编码数据,为模型的后续前向传播(forward)过程做准备。
具体来说,函数的作用是:
- 提取并处理初始状态的数据。
- 使用编码器对节点进行编码,得到编码后的节点表示。
- 为解码器设置额外的嵌入信息,并将编码后的节点与额外的嵌入信息拼接。
- 设置解码器中的 kv(key-value)信息,为解码过程做准备。
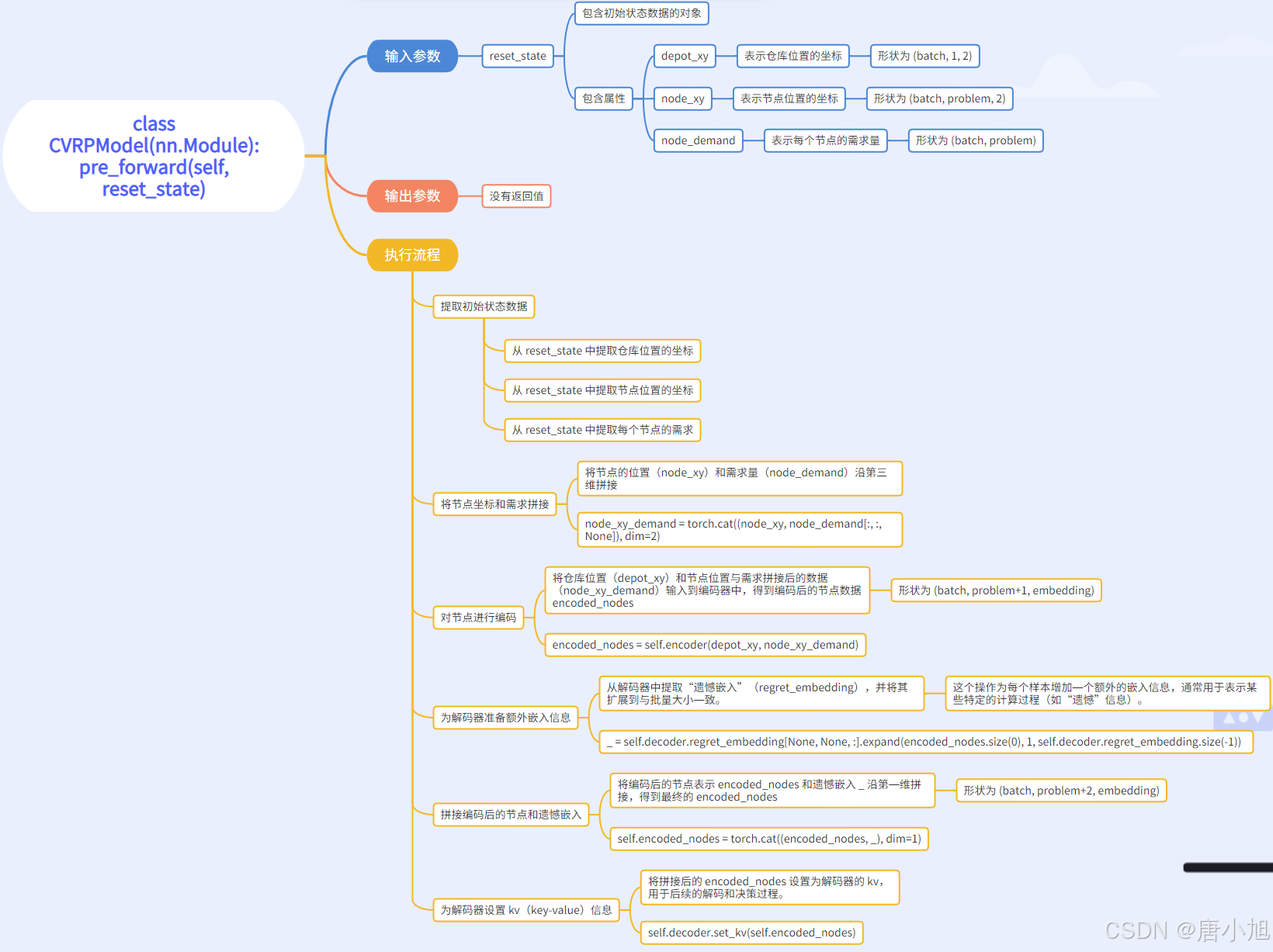
函数代码
def pre_forward(self, reset_state):
depot_xy = reset_state.depot_xy
# shape: (batch, 1, 2)
node_xy = reset_state.node_xy
# shape: (batch, problem, 2)
node_demand = reset_state.node_demand
# shape: (batch, problem)
node_xy_demand = torch.cat((node_xy, node_demand[:, :, None]), dim=2)
# shape: (batch, problem, 3)
encoded_nodes = self.encoder(depot_xy, node_xy_demand)
# shape: (batch, problem+1, embedding)
_ = self.decoder.regret_embedding[None, None, :].expand(encoded_nodes.size(0), 1,self.decoder.regret_embedding.size(-1))
# _ 的shape:(batch,1,embedding)
self.encoded_nodes = torch.cat((encoded_nodes, _), dim=1)
# self.encoded_nodes的shape:(batch,problem+2,embedding)
self.decoder.set_kv(self.encoded_nodes)
三、class CVRPModel(nn.Module):forward(self, state)
函数功能
forward 是 CVRPModel 类的核心前向传播函数,用于根据当前状态(state)生成模型的输出,包括选择的节点(selected)和相关的概率(prob)。
它的主要功能是基于当前的状态和历史选择来决定接下来应该选择哪个节点,并输出相应的概率。
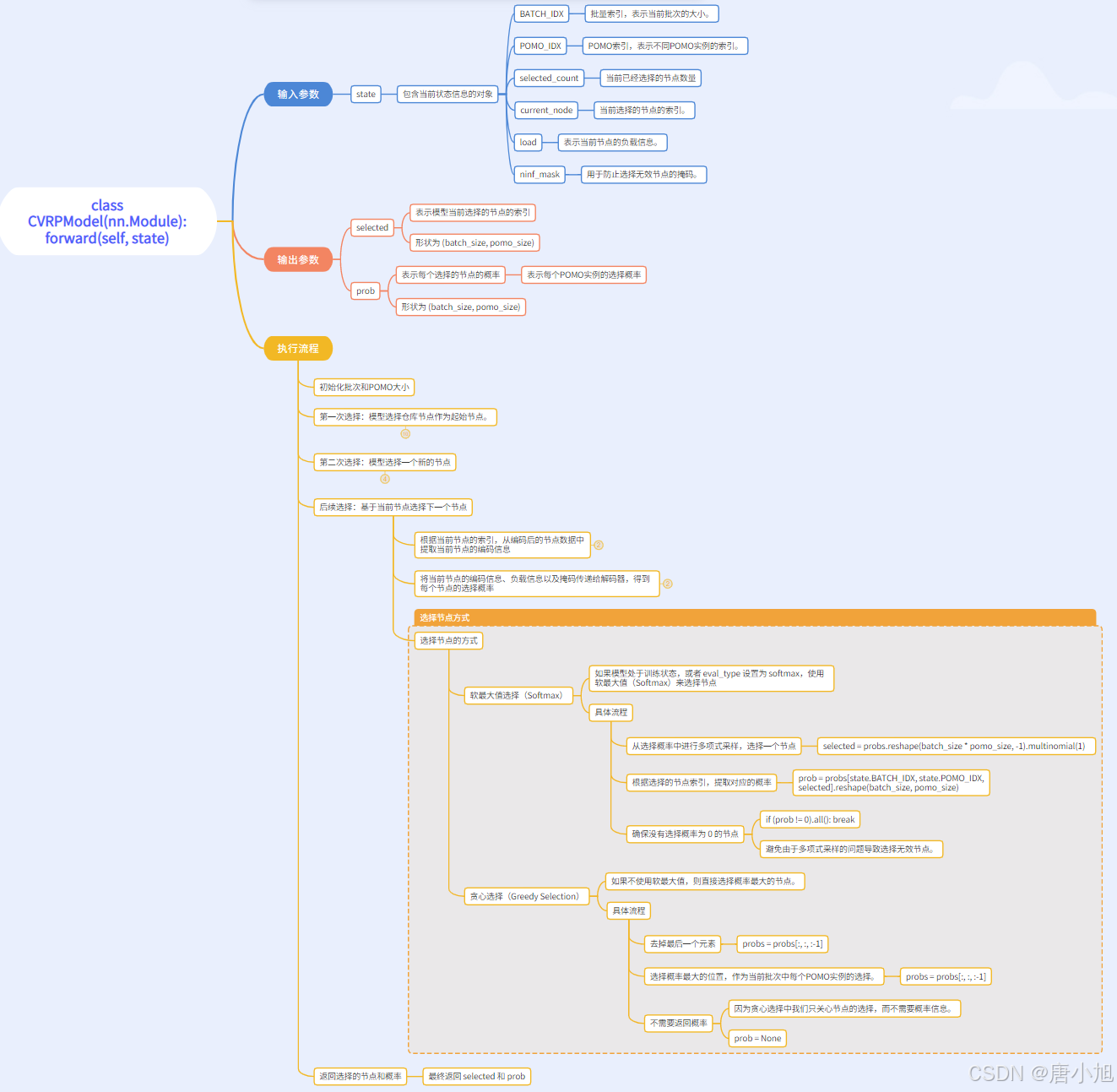
函数代码
def forward(self, state):
batch_size = state.BATCH_IDX.size(0)
pomo_size = state.BATCH_IDX.size(1)
if state.selected_count == 0: # First Move, depot
selected = torch.zeros(size=(batch_size, pomo_size), dtype=torch.long)
prob = torch.ones(size=(batch_size, pomo_size))
# # Use Averaged encoded nodes for decoder input_1
# encoded_nodes_mean = self.encoded_nodes.mean(dim=1, keepdim=True)
# # shape: (batch, 1, embedding)
# self.decoder.set_q1(encoded_nodes_mean)
# Use encoded_depot for decoder input_2
encoded_first_node = self.encoded_nodes[:, [0], :]
# shape: (batch, 1, embedding)
self.decoder.set_q2(encoded_first_node)
elif state.selected_count == 1: # Second Move, POMO
selected = torch.arange(start=1, end=pomo_size+1)[None, :].expand(batch_size, pomo_size)
prob = torch.ones(size=(batch_size, pomo_size))
else:
encoded_last_node = _get_encoding(self.encoded_nodes, state.current_node)
# shape: (batch, pomo, embedding)
probs = self.decoder(encoded_last_node, state.load, ninf_mask=state.ninf_mask)
# shape: (batch, pomo, problem+1)
if self.training or self.model_params['eval_type'] == 'softmax':
while True: # to fix pytorch.multinomial bug on selecting 0 probability elements
with torch.no_grad():
selected = probs.reshape(batch_size * pomo_size, -1).multinomial(1) \
.squeeze(dim=1).reshape(batch_size, pomo_size)
# shape: (batch, pomo)
prob = probs[state.BATCH_IDX, state.POMO_IDX, selected].reshape(batch_size, pomo_size)
# shape: (batch, pomo)
if (prob != 0).all():
break
else:
probs=probs[:,:,:-1]
selected = probs.argmax(dim=2)
# shape: (batch, pomo)
prob = None # value not needed. Can be anything.
return selected, prob
四、def _get_encoding(encoded_nodes, node_index_to_pick)
函数功能
_get_encoding 的作用是从 encoded_nodes 中按照 node_index_to_pick 选择相应的编码,并返回选中的编码信息。
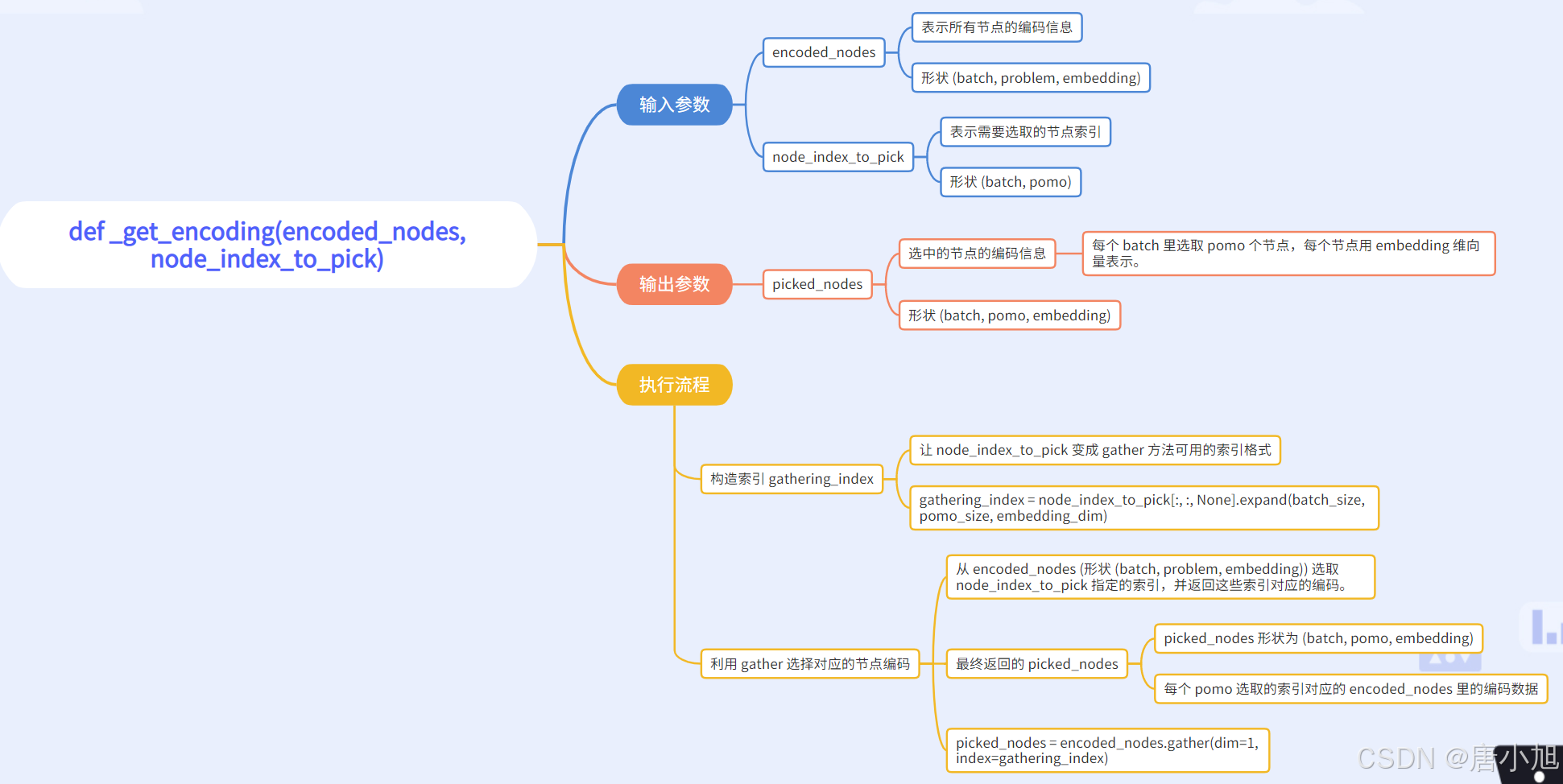
函数代码
def _get_encoding(encoded_nodes, node_index_to_pick):
# encoded_nodes.shape: (batch, problem, embedding)
# node_index_to_pick.shape: (batch, pomo)
batch_size = node_index_to_pick.size(0)
pomo_size = node_index_to_pick.size(1)
embedding_dim = encoded_nodes.size(2)
gathering_index = node_index_to_pick[:, :, None].expand(batch_size, pomo_size, embedding_dim)
# shape: (batch, pomo, embedding)
picked_nodes = encoded_nodes.gather(dim=1, index=gathering_index)
# shape: (batch, pomo, embedding)
return picked_nodes
五、class CVRP_Encoder(nn.Module)
笔记:20250226-代码笔记04-class CVRP_Encoder AND class EncoderLayer
六、class EncoderLayer(nn.Module)
笔记:20250226-代码笔记04-class CVRP_Encoder AND class EncoderLayer
七、CVRP_Decoder(nn.Module)
笔记:20250226-代码笔记05-class CVRP_Decoder
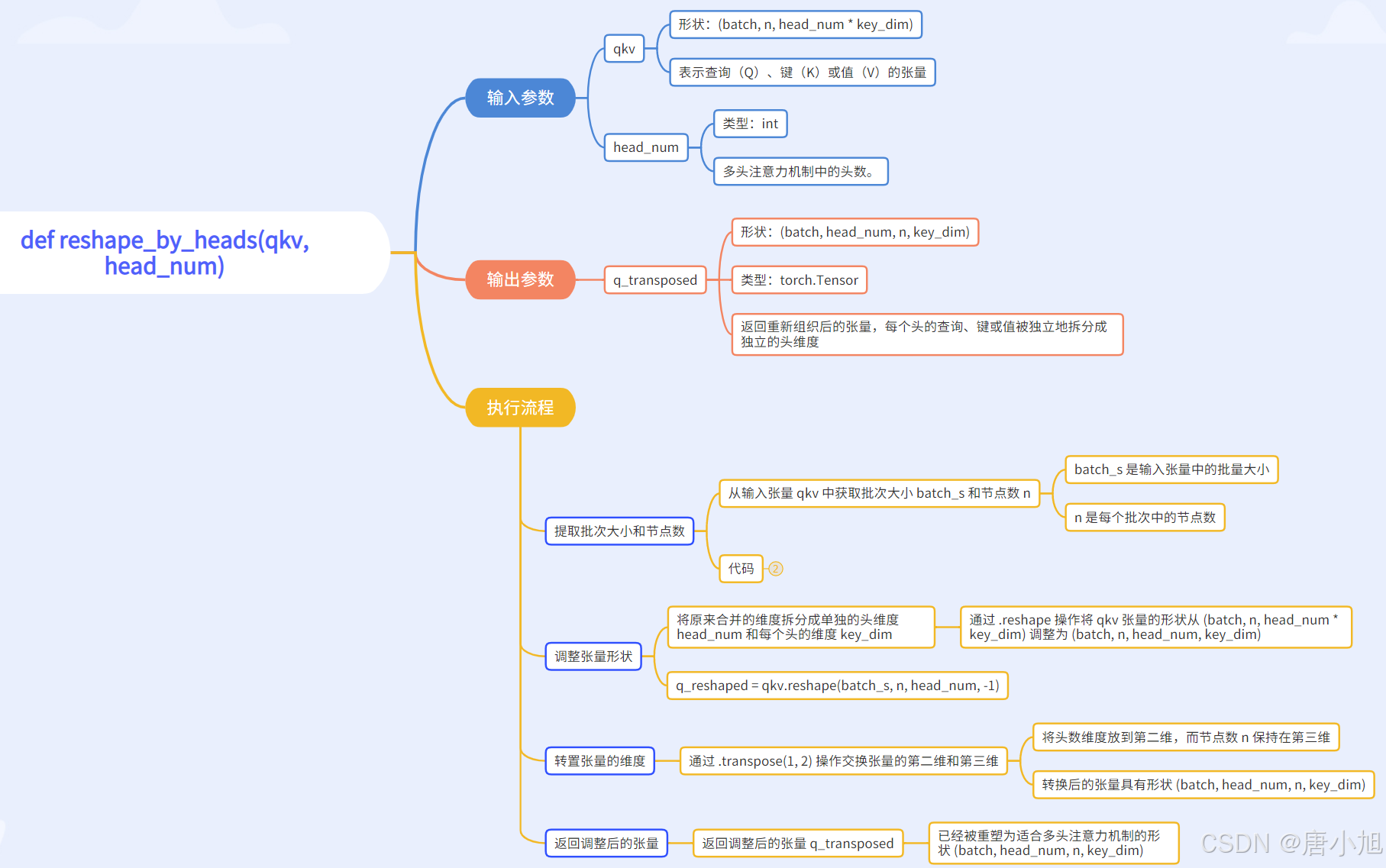
八、def reshape_by_heads(qkv, head_num)
函数功能
reshape_by_heads 函数的功能是将输入的张量(如查询 q, 键 k, 或值 v)从一个紧凑的多头结构 (batch, n, head_num * key_dim) 转换为适合多头注意力机制计算的结构 (batch, head_num, n, key_dim)。
此操作将多个注意力头的维度进行拆分,并将其调整为每个头独立计算的格式。
执行流程图链接
函数代码
def reshape_by_heads(qkv, head_num):
# q.shape: (batch, n, head_num*key_dim) : n can be either 1 or PROBLEM_SIZE
batch_s = qkv.size(0)
n = qkv.size(1)
q_reshaped = qkv.reshape(batch_s, n, head_num, -1)
# shape: (batch, n, head_num, key_dim)
q_transposed = q_reshaped.transpose(1, 2)
# shape: (batch, head_num, n, key_dim)
return q_transposed
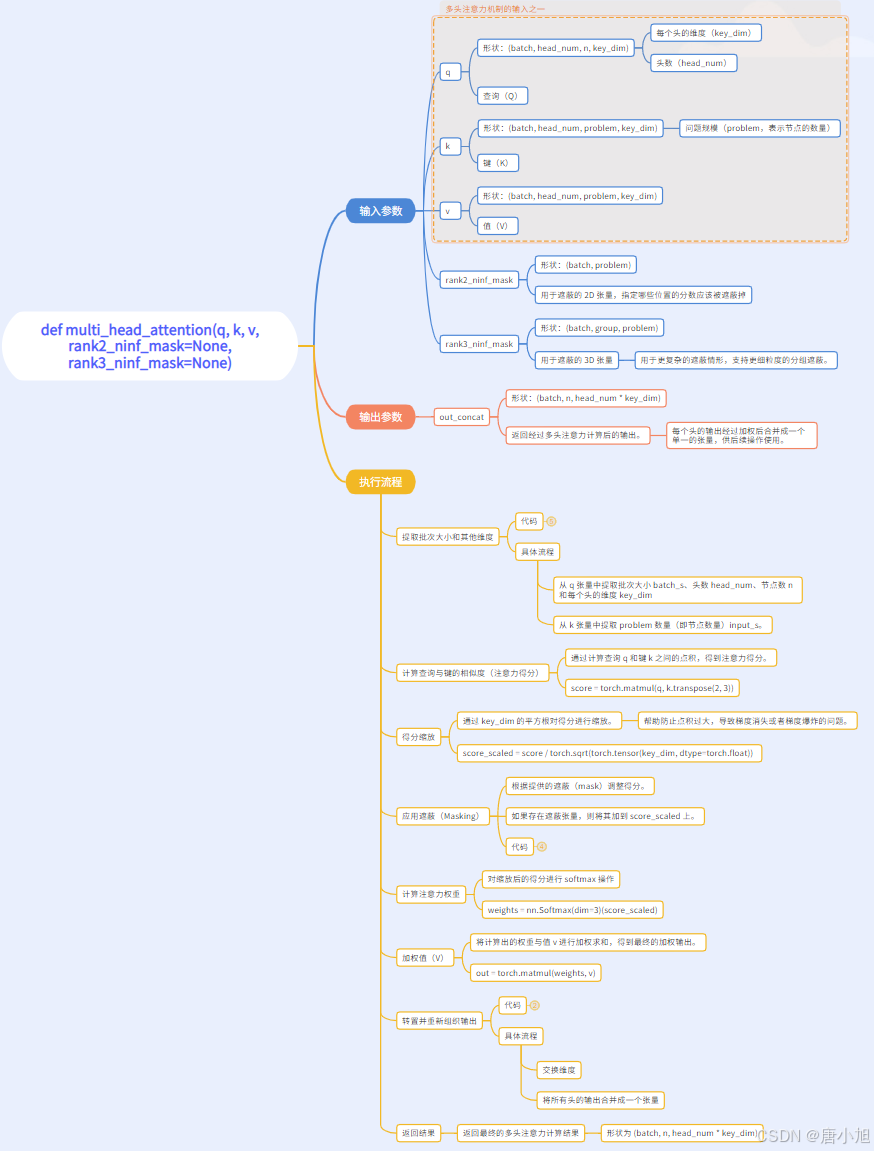
九、def multi_head_attention(q, k, v, rank2_ninf_mask=None, rank3_ninf_mask=None)
函数功能
multi_head_attention 函数的主要功能是实现 多头注意力机制。该函数接收查询(Q)、键(K)和值(V),并计算多头注意力输出。它通过计算查询与键之间的相似度,生成加权值的结果,并结合所有头的输出生成最终的注意力表示。
执行流程图链接
函数代码
def multi_head_attention(q, k, v, rank2_ninf_mask=None, rank3_ninf_mask=None):
# q shape: (batch, head_num, n, key_dim) : n can be either 1 or PROBLEM_SIZE
# k,v shape: (batch, head_num, problem, key_dim)
# rank2_ninf_mask.shape: (batch, problem)
# rank3_ninf_mask.shape: (batch, group, problem)
batch_s = q.size(0)
head_num = q.size(1)
n = q.size(2)
key_dim = q.size(3)
input_s = k.size(2)
score = torch.matmul(q, k.transpose(2, 3))
# shape: (batch, head_num, n, problem)
score_scaled = score / torch.sqrt(torch.tensor(key_dim, dtype=torch.float))
if rank2_ninf_mask is not None:
score_scaled = score_scaled + rank2_ninf_mask[:, None, None, :].expand(batch_s, head_num, n, input_s)
if rank3_ninf_mask is not None:
score_scaled = score_scaled + rank3_ninf_mask[:, None, :, :].expand(batch_s, head_num, n, input_s)
weights = nn.Softmax(dim=3)(score_scaled)
# shape: (batch, head_num, n, problem)
out = torch.matmul(weights, v)
# shape: (batch, head_num, n, key_dim)
out_transposed = out.transpose(1, 2)
# shape: (batch, n, head_num, key_dim)
out_concat = out_transposed.reshape(batch_s, n, head_num * key_dim)
# shape: (batch, n, head_num*key_dim)
return out_concat
十、class AddAndInstanceNormalization(nn.Module):init(self, **model_params)
函数功能
对输入数据进行基于嵌入维度的批量标准化操作,从而使得模型在训练过程中能够更好地收敛和提高稳定性。
Batch Normalization (BN) 是什么?
Batch Normalization (BN) 是一种在训练深度神经网络时常用的技术,它的目的是提高网络的训练速度、稳定性,并帮助避免梯度消失或爆炸问题。
Batch Normalization 操作的核心思想是对每一层的输入数据进行标准化,使得输入数据的均值接近 0,方差接近 1。这样可以避免激活函数输出过大或过小的问题,帮助优化过程更加稳定。
Batch Normalization 的具体操作
1. 计算均值和方差
对于一批输入样本(batch),在每个特征维度上计算均值和方差:
-
均值:
μ B = 1 m ∑ i = 1 m x i \mu_B = \frac{1}{m} \sum_{i=1}^{m} x_i μB=m1∑i=1mxi -
方差:
σ B 2 = 1 m ∑ i = 1 m ( x i − μ B ) 2 \sigma_B^2 = \frac{1}{m} \sum_{i=1}^{m} (x_i - \mu_B)^2 σB2=m1∑i=1m(xi−μB)2
其中, m m m 是一个批次中的样本数, x i x_i xi是每个样本的输入值。
2. 标准化
使用计算出的均值和方差将输入数据标准化,使得每个特征的均值为 0,方差为 1:
x ^ i = x i − μ B σ B 2 + ϵ \hat{x}_i = \frac{x_i - \mu_B}{\sqrt{\sigma_B^2 + \epsilon}} x^i=σB2+ϵxi−μB
这里 ϵ \epsilon ϵ是一个非常小的数值,用来防止除以零的情况。
3. 缩放和平移
由于标准化可能会影响到模型的表达能力,Batch Normalization 还会引入两个可学习的参数 γ \gamma γ(缩放参数)和 β \beta β(平移参数),它们允许模型重新调整标准化后的数据:
y i = γ x ^ i + β y_i = \gamma \hat{x}_i + \beta yi=γx^i+β
其中, γ \gamma γ 和 β \beta β是学习的参数,通常会通过反向传播进行优化。
Batch Normalization 的优势
- 加速训练:Batch Normalization 通过减少输入数据的偏移(internal covariate shift),使得每一层的输入分布更加稳定,从而加速了网络的训练过程。
- 提高稳定性:由于它通过标准化输入避免了梯度爆炸或梯度消失问题,使得训练更加稳定。
- 缓解过拟合:在一些情况下,Batch Normalization 也可以起到正则化的作用,减少了模型对训练数据的过拟合。
- 减少对初始化的依赖:Batch Normalization 可以在一定程度上缓解对权重初始化的敏感性。
函数代码
def __init__(self, **model_params):
super().__init__()
embedding_dim = model_params['embedding_dim']
self.norm = nn.InstanceNorm1d(embedding_dim, affine=True, track_running_stats=False)
十一、class AddAndInstanceNormalization(nn.Module):forward(self, input1, input2)
函数功能
forward 方法,它执行了加法和批量归一化操作。
forward 方法的主要功能是:
- 加法操作:将两个输入张量
input1和input2相加。 - 批量归一化:将加法结果进行批量归一化(Batch Normalization),标准化其特征维度。
- 形状恢复:批量归一化后,将张量的形状恢复到原来的维度。
执行流程:
函数代码
- 获取输入张量的维度:
batch_s = input1.size(0)
problem_s = input1.size(1)
embedding_dim = input1.size(2)
batch_s表示批次大小,problem_s表示问题的大小(特征的数量),embedding_dim表示嵌入的维度。- 这些维度来自输入张量
input1,并且假设input2具有相同的形状。
- 加法操作:
added = input1 + input2
- 对
input1和nput2进行逐元素加法。此时,added张量的形状与input1和input2相同,仍为(batch_s, problem_s, embedding_dim)。
- 批量归一化:
normalized = self.norm_by_EMB(added.reshape(batch_s * problem_s, embedding_dim))
- 将
added张量的形状重塑为(batch_s * problem_s, embedding_dim),将批次维度和问题维度合并,以便进行批量归一化操作。这样就对每个特征维度(embedding_dim)做了批量标准化。 self.norm_by_EMB是一个BatchNorm1d层,它会对每个特征维度执行标准化,使得每个特征的均值接近 0,方差接近 1。
- 恢复形状:
back_trans = normalized.reshape(batch_s, problem_s, embedding_dim)
- 批量归一化后,将
normalized张量的形状恢复回(batch_s, problem_s, embedding_dim),即恢复原本的输入形状。
- 返回结果:
return back_trans
- 返回经过批量归一化的张量
back_trans,它的形状与输入相同,并且每个特征维度已经经过标准化。
def forward(self, input1, input2):
# input.shape: (batch, problem, embedding)
added = input1 + input2
# shape: (batch, problem, embedding)
transposed = added.transpose(1, 2)
# shape: (batch, embedding, problem)
normalized = self.norm(transposed)
# shape: (batch, embedding, problem)
back_trans = normalized.transpose(1, 2)
# shape: (batch, problem, embedding)
return back_trans
十二、class FeedForward(nn.Module):init(self, **model_params)
函数功能
FeedForward 的类,它是一个典型的前馈神经网络(Feedforward Neural Network)模块,实现了一个简单的两层神经网络。
__init__方法是类的构造函数,用来初始化网络的层和超参数。embedding_dim和ff_hidden_dim是通过model_params传递的超参数,分别表示嵌入维度和前馈神经网络隐藏层的维度。embedding_dim是输入和输出的维度。ff_hidden_dim是隐藏层的维度,即在网络的中间层。
self.W1和self.W2是两个全连接层(nn.Linear):self.W1将输入的embedding_dim维度的向量转换为ff_hidden_dim维度的向量。self.W2将ff_hidden_dim维度的向量转换回embedding_dim维度的向量。
函数代码
def __init__(self, **model_params):
super().__init__()
embedding_dim = model_params['embedding_dim']
ff_hidden_dim = model_params['ff_hidden_dim']
self.W1 = nn.Linear(embedding_dim, ff_hidden_dim)
self.W2 = nn.Linear(ff_hidden_dim, embedding_dim)
十三、class FeedForward(nn.Module):forward(self, input1)
函数功能
forward方法定义了数据流通过网络的方式,也就是前向传播过程。- 输入
input1的形状为(batch, problem, embedding),即批次大小batch、问题数量problem和每个问题的嵌入维度embedding。 - 执行的步骤如下:
-
1.第一层线性变换(
self.W1):输入通过self.W1进行线性变换,将输入的嵌入维度转换为隐藏层的维度(ff_hidden_dim)。变换公式为:
其中x是输入,W1是权重矩阵,b1是偏置。 -
2.激活函数(ReLU):对
self.W1的输出应用 ReLU 激活函数,ReLU 将负值归零,保留正值。公式为:
-
3.第二层线性变换(
self.W2):通过self.W2进行线性变换,将隐藏层的输出转换回原始的嵌入维度(embedding_dim)。变换公式为:
-
- 最终输出是经过两层线性变换和 ReLU 激活函数处理的结果,形状仍然是 (batch, problem, embedding)。
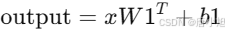
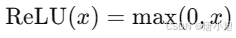
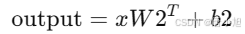
函数代码
def forward(self, input1):
# input.shape: (batch, problem, embedding)
return self.W2(F.relu(self.W1(input1)))
附录
代码(全)
import torch
import torch.nn as nn
import torch.nn.functional as F
class CVRPModel(nn.Module):
def __init__(self, **model_params):
super().__init__()
self.model_params = model_params
self.encoder = CVRP_Encoder(**model_params)
self.decoder = CVRP_Decoder(**model_params)
self.encoded_nodes = None
# shape: (batch, problem+1, EMBEDDING_DIM)
def pre_forward(self, reset_state):
depot_xy = reset_state.depot_xy
# shape: (batch, 1, 2)
node_xy = reset_state.node_xy
# shape: (batch, problem, 2)
node_demand = reset_state.node_demand
# shape: (batch, problem)
node_xy_demand = torch.cat((node_xy, node_demand[:, :, None]), dim=2)
# shape: (batch, problem, 3)
encoded_nodes = self.encoder(depot_xy, node_xy_demand)
# shape: (batch, problem+1, embedding)
_ = self.decoder.regret_embedding[None, None, :].expand(encoded_nodes.size(0), 1,self.decoder.regret_embedding.size(-1))
# _ 的shape:(batch,1,embedding)
self.encoded_nodes = torch.cat((encoded_nodes, _), dim=1)
# self.encoded_nodes的shape:(batch,problem+2,embedding)
self.decoder.set_kv(self.encoded_nodes)
def forward(self, state):
batch_size = state.BATCH_IDX.size(0)
pomo_size = state.BATCH_IDX.size(1)
if state.selected_count == 0: # First Move, depot
selected = torch.zeros(size=(batch_size, pomo_size), dtype=torch.long)
prob = torch.ones(size=(batch_size, pomo_size))
# # Use Averaged encoded nodes for decoder input_1
# encoded_nodes_mean = self.encoded_nodes.mean(dim=1, keepdim=True)
# # shape: (batch, 1, embedding)
# self.decoder.set_q1(encoded_nodes_mean)
# Use encoded_depot for decoder input_2
encoded_first_node = self.encoded_nodes[:, [0], :]
# shape: (batch, 1, embedding)
self.decoder.set_q2(encoded_first_node)
elif state.selected_count == 1: # Second Move, POMO
selected = torch.arange(start=1, end=pomo_size+1)[None, :].expand(batch_size, pomo_size)
prob = torch.ones(size=(batch_size, pomo_size))
else:
encoded_last_node = _get_encoding(self.encoded_nodes, state.current_node)
# shape: (batch, pomo, embedding)
probs = self.decoder(encoded_last_node, state.load, ninf_mask=state.ninf_mask)
# shape: (batch, pomo, problem+1)
if self.training or self.model_params['eval_type'] == 'softmax':
while True: # to fix pytorch.multinomial bug on selecting 0 probability elements
with torch.no_grad():
selected = probs.reshape(batch_size * pomo_size, -1).multinomial(1) \
.squeeze(dim=1).reshape(batch_size, pomo_size)
# shape: (batch, pomo)
prob = probs[state.BATCH_IDX, state.POMO_IDX, selected].reshape(batch_size, pomo_size)
# shape: (batch, pomo)
if (prob != 0).all():
break
else:
probs=probs[:,:,:-1]
selected = probs.argmax(dim=2)
# shape: (batch, pomo)
prob = None # value not needed. Can be anything.
return selected, prob
def _get_encoding(encoded_nodes, node_index_to_pick):
# encoded_nodes.shape: (batch, problem, embedding)
# node_index_to_pick.shape: (batch, pomo)
batch_size = node_index_to_pick.size(0)
pomo_size = node_index_to_pick.size(1)
embedding_dim = encoded_nodes.size(2)
gathering_index = node_index_to_pick[:, :, None].expand(batch_size, pomo_size, embedding_dim)
# shape: (batch, pomo, embedding)
picked_nodes = encoded_nodes.gather(dim=1, index=gathering_index)
# shape: (batch, pomo, embedding)
return picked_nodes
########################################
# ENCODER
########################################
class CVRP_Encoder(nn.Module):
def __init__(self, **model_params):
super().__init__()
self.model_params = model_params
embedding_dim = self.model_params['embedding_dim']
encoder_layer_num = self.model_params['encoder_layer_num']
self.embedding_depot = nn.Linear(2, embedding_dim)
self.embedding_node = nn.Linear(3, embedding_dim)
self.layers = nn.ModuleList([EncoderLayer(**model_params) for _ in range(encoder_layer_num)])
def forward(self, depot_xy, node_xy_demand):
# depot_xy.shape: (batch, 1, 2)
# node_xy_demand.shape: (batch, problem, 3)
embedded_depot = self.embedding_depot(depot_xy)
# shape: (batch, 1, embedding)
embedded_node = self.embedding_node(node_xy_demand)
# shape: (batch, problem, embedding)
out = torch.cat((embedded_depot, embedded_node), dim=1)
# shape: (batch, problem+1, embedding)
for layer in self.layers:
out = layer(out)
return out
# shape: (batch, problem+1, embedding)
class EncoderLayer(nn.Module):
def __init__(self, **model_params):
super().__init__()
self.model_params = model_params
embedding_dim = self.model_params['embedding_dim']
head_num = self.model_params['head_num']
qkv_dim = self.model_params['qkv_dim']
self.Wq = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.Wk = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.Wv = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.multi_head_combine = nn.Linear(head_num * qkv_dim, embedding_dim)
self.add_n_normalization_1 = AddAndInstanceNormalization(**model_params)
self.feed_forward = FeedForward(**model_params)
self.add_n_normalization_2 = AddAndInstanceNormalization(**model_params)
def forward(self, input1):
# input1.shape: (batch, problem+1, embedding)
head_num = self.model_params['head_num']
q = reshape_by_heads(self.Wq(input1), head_num=head_num)
k = reshape_by_heads(self.Wk(input1), head_num=head_num)
v = reshape_by_heads(self.Wv(input1), head_num=head_num)
# qkv shape: (batch, head_num, problem, qkv_dim)
out_concat = multi_head_attention(q, k, v)
# shape: (batch, problem, head_num*qkv_dim)
multi_head_out = self.multi_head_combine(out_concat)
# shape: (batch, problem, embedding)
out1 = self.add_n_normalization_1(input1, multi_head_out)
out2 = self.feed_forward(out1)
out3 = self.add_n_normalization_2(out1, out2)
return out3
# shape: (batch, problem, embedding)
########################################
# DECODER
########################################
class CVRP_Decoder(nn.Module):
def __init__(self, **model_params):
super().__init__()
self.model_params = model_params
embedding_dim = self.model_params['embedding_dim']
head_num = self.model_params['head_num']
qkv_dim = self.model_params['qkv_dim']
# self.Wq_1 = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.Wq_2 = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.Wq_last = nn.Linear(embedding_dim+1, head_num * qkv_dim, bias=False)
self.Wk = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.Wv = nn.Linear(embedding_dim, head_num * qkv_dim, bias=False)
self.regret_embedding = nn.Parameter(torch.Tensor(embedding_dim))
self.regret_embedding.data.uniform_(-1, 1)
self.multi_head_combine = nn.Linear(head_num * qkv_dim, embedding_dim)
self.k = None # saved key, for multi-head attention
self.v = None # saved value, for multi-head_attention
self.single_head_key = None # saved, for single-head attention
# self.q1 = None # saved q1, for multi-head attention
self.q2 = None # saved q2, for multi-head attention
def set_kv(self, encoded_nodes):
# encoded_nodes.shape: (batch, problem+1, embedding)
head_num = self.model_params['head_num']
self.k = reshape_by_heads(self.Wk(encoded_nodes), head_num=head_num)
self.v = reshape_by_heads(self.Wv(encoded_nodes), head_num=head_num)
# shape: (batch, head_num, problem+1, qkv_dim)
self.single_head_key = encoded_nodes.transpose(1, 2)
# shape: (batch, embedding, problem+1)
def set_q1(self, encoded_q1):
# encoded_q.shape: (batch, n, embedding) # n can be 1 or pomo
head_num = self.model_params['head_num']
self.q1 = reshape_by_heads(self.Wq_1(encoded_q1), head_num=head_num)
# shape: (batch, head_num, n, qkv_dim)
def set_q2(self, encoded_q2):
# encoded_q.shape: (batch, n, embedding) # n can be 1 or pomo
head_num = self.model_params['head_num']
self.q2 = reshape_by_heads(self.Wq_2(encoded_q2), head_num=head_num)
# shape: (batch, head_num, n, qkv_dim)
def forward(self, encoded_last_node, load, ninf_mask):
# encoded_last_node.shape: (batch, pomo, embedding)
# load.shape: (batch, pomo)
# ninf_mask.shape: (batch, pomo, problem)
head_num = self.model_params['head_num']
# Multi-Head Attention
#######################################################
input_cat = torch.cat((encoded_last_node, load[:, :, None]), dim=2)
# shape = (batch, group, EMBEDDING_DIM+1)
q_last = reshape_by_heads(self.Wq_last(input_cat), head_num=head_num)
# shape: (batch, head_num, pomo, qkv_dim)
# q = self.q1 + self.q2 + q_last
# # shape: (batch, head_num, pomo, qkv_dim)
# q = q_last
# shape: (batch, head_num, pomo, qkv_dim)
q = self.q2 + q_last
# # shape: (batch, head_num, pomo, qkv_dim)
out_concat = multi_head_attention(q, self.k, self.v, rank3_ninf_mask=ninf_mask)
# shape: (batch, pomo, head_num*qkv_dim)
mh_atten_out = self.multi_head_combine(out_concat)
# shape: (batch, pomo, embedding)
# Single-Head Attention, for probability calculation
#######################################################
score = torch.matmul(mh_atten_out, self.single_head_key)
# shape: (batch, pomo, problem)
sqrt_embedding_dim = self.model_params['sqrt_embedding_dim']
logit_clipping = self.model_params['logit_clipping']
score_scaled = score / sqrt_embedding_dim
# shape: (batch, pomo, problem)
score_clipped = logit_clipping * torch.tanh(score_scaled)
score_masked = score_clipped + ninf_mask
probs = F.softmax(score_masked, dim=2)
# shape: (batch, pomo, problem)
return probs
########################################
# NN SUB CLASS / FUNCTIONS
########################################
def reshape_by_heads(qkv, head_num):
# q.shape: (batch, n, head_num*key_dim) : n can be either 1 or PROBLEM_SIZE
batch_s = qkv.size(0)
n = qkv.size(1)
q_reshaped = qkv.reshape(batch_s, n, head_num, -1)
# shape: (batch, n, head_num, key_dim)
q_transposed = q_reshaped.transpose(1, 2)
# shape: (batch, head_num, n, key_dim)
return q_transposed
def multi_head_attention(q, k, v, rank2_ninf_mask=None, rank3_ninf_mask=None):
# q shape: (batch, head_num, n, key_dim) : n can be either 1 or PROBLEM_SIZE
# k,v shape: (batch, head_num, problem, key_dim)
# rank2_ninf_mask.shape: (batch, problem)
# rank3_ninf_mask.shape: (batch, group, problem)
batch_s = q.size(0)
head_num = q.size(1)
n = q.size(2)
key_dim = q.size(3)
input_s = k.size(2)
score = torch.matmul(q, k.transpose(2, 3))
# shape: (batch, head_num, n, problem)
score_scaled = score / torch.sqrt(torch.tensor(key_dim, dtype=torch.float))
if rank2_ninf_mask is not None:
score_scaled = score_scaled + rank2_ninf_mask[:, None, None, :].expand(batch_s, head_num, n, input_s)
if rank3_ninf_mask is not None:
score_scaled = score_scaled + rank3_ninf_mask[:, None, :, :].expand(batch_s, head_num, n, input_s)
weights = nn.Softmax(dim=3)(score_scaled)
# shape: (batch, head_num, n, problem)
out = torch.matmul(weights, v)
# shape: (batch, head_num, n, key_dim)
out_transposed = out.transpose(1, 2)
# shape: (batch, n, head_num, key_dim)
out_concat = out_transposed.reshape(batch_s, n, head_num * key_dim)
# shape: (batch, n, head_num*key_dim)
return out_concat
class AddAndInstanceNormalization(nn.Module):
def __init__(self, **model_params):
super().__init__()
embedding_dim = model_params['embedding_dim']
self.norm = nn.InstanceNorm1d(embedding_dim, affine=True, track_running_stats=False)
def forward(self, input1, input2):
# input.shape: (batch, problem, embedding)
added = input1 + input2
# shape: (batch, problem, embedding)
transposed = added.transpose(1, 2)
# shape: (batch, embedding, problem)
normalized = self.norm(transposed)
# shape: (batch, embedding, problem)
back_trans = normalized.transpose(1, 2)
# shape: (batch, problem, embedding)
return back_trans
class AddAndBatchNormalization(nn.Module):
def __init__(self, **model_params):
super().__init__()
embedding_dim = model_params['embedding_dim']
self.norm_by_EMB = nn.BatchNorm1d(embedding_dim, affine=True)
# 'Funny' Batch_Norm, as it will normalized by EMB dim
def forward(self, input1, input2):
# input.shape: (batch, problem, embedding)
batch_s = input1.size(0)
problem_s = input1.size(1)
embedding_dim = input1.size(2)
added = input1 + input2
normalized = self.norm_by_EMB(added.reshape(batch_s * problem_s, embedding_dim))
back_trans = normalized.reshape(batch_s, problem_s, embedding_dim)
return back_trans
class FeedForward(nn.Module):
def __init__(self, **model_params):
super().__init__()
embedding_dim = model_params['embedding_dim']
ff_hidden_dim = model_params['ff_hidden_dim']
self.W1 = nn.Linear(embedding_dim, ff_hidden_dim)
self.W2 = nn.Linear(ff_hidden_dim, embedding_dim)
def forward(self, input1):
# input.shape: (batch, problem, embedding)
return self.W2(F.relu(self.W1(input1)))