事务
在聊分布式事务前,有必要先回顾一下事务。事务可以简单的理解为:一个大的活动由不同的小活动组成,这些活动要么全部成功,要么全部失败。
说到事务,事务的四大特性ACID肯定逃不了:
- A(Atomic):原子性,表示构成事务的所有操作,要么全部执行完成,要么全部不执行。
- C(Consistency):一致性,表示事务执行前后,数据库的一致性约束没有被破坏。如:你账上有400,我账上有100,你给我打200块,此时你账上的钱应该是200,我账上的钱应该是300,不会存在我账上钱加了,你账上钱没扣的中间状态
- I(Isolation):隔离性,指在多个事务并发执行的时候不会互相干扰,即一个事务的内部的数据对于其他事务来说是隔离的,不可见的。
- D(Durability):持久性,指事务执行完成后,数据的变更将会被持久化到数据库中。
其实我觉得原子性和一致性有点像,可以简单的理解为:原子性要求操作要么全部执行要么全部不执行,而一致性要求操作要么全部执行成功,要么全部执行失败。
分布式事务是什么
分布式事务顾名思义,就是在分布式系统中实现事务。它其实是由多个本地事务组成的,对于分布式事务来说,传统的数据库事务将不再有效。
举个例子
对于本地事务来说,我们可以通过数据库自身提供的事务特性能控制:
begin transaction;
//1.本地数据库操作:张三减少金额
//2.本地数据库操作:李四增加金额
commit transation;
在这个场景中,由于这俩个操作使用的是同一个数据库连接,所以我们是可以直接通过数据库来控制事务的。但是在分布式环境下,会变成下面这样:
begin transaction;
//1.本地数据库操作:张三减少金额
//2.远程调用:李四增加金额
commit transation;
在这个场景下,可能由于网络原因,远程调用并没有返回,因此误以为远程调用失败,导致本地事务回滚,最后造成李四金额增加,而张三没有减少金额的错误场景。
分布式事务产生的场景
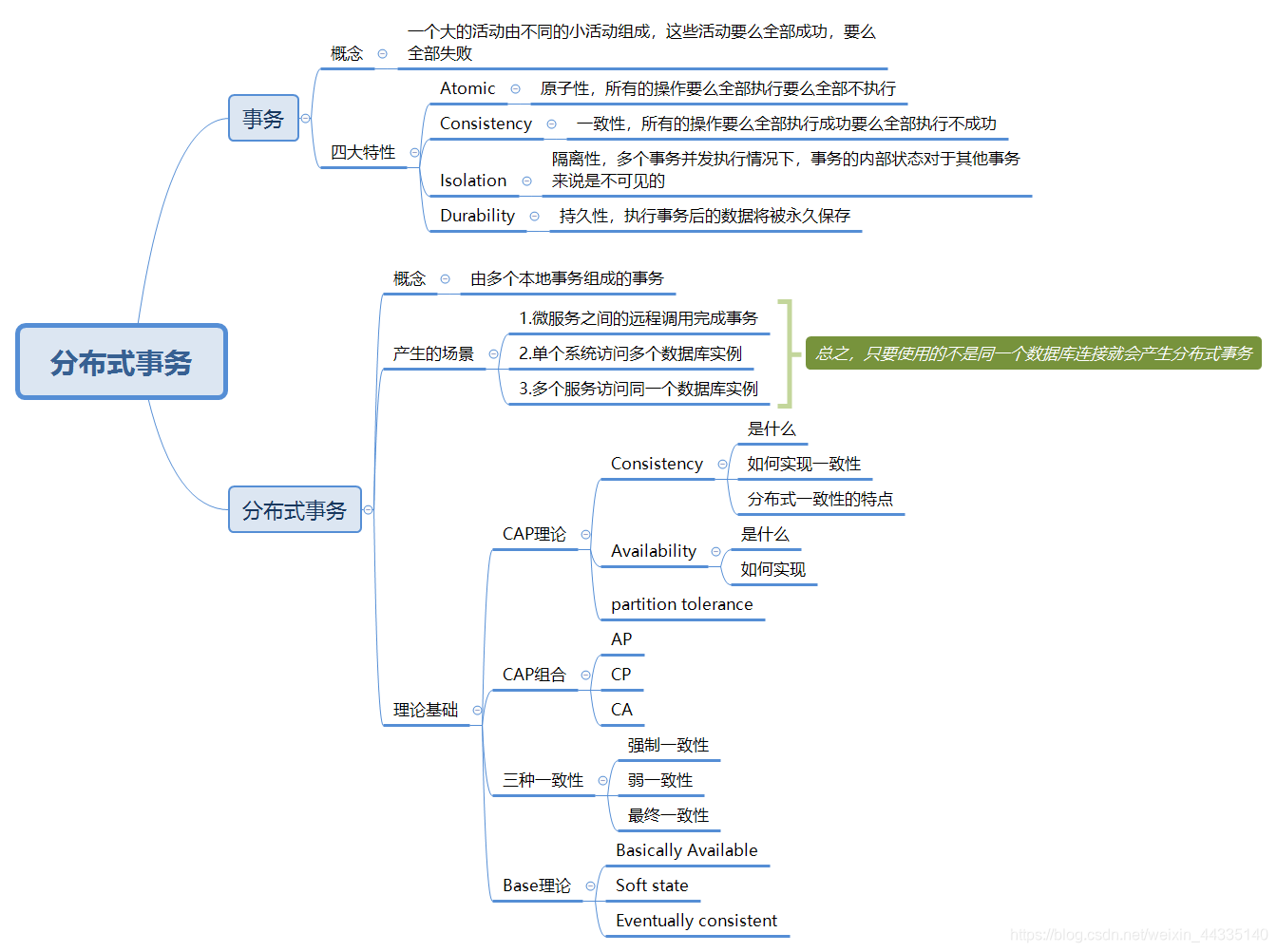
微服务之间的远程调用完成事务
这是最典型的场景。如订单微服务和库存微服务。下单后订单服务需要远程调用库存服务减库存。简而言之就是:跨JVM进程产生分布式事务。
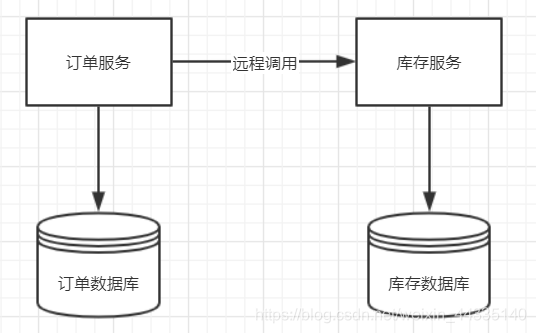
单个系统访问多个数据库实例
当单体系统需要访问多个数据库实例时,就会产生分布式事务,如下图所示:
简而言之:跨数据库实例产生分布式问题
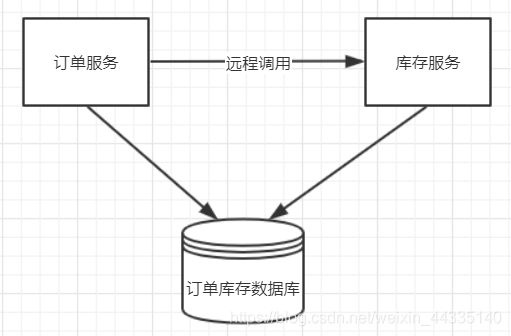
多个服务访问同一个数据库实例
订单服务和库存服务即使使用同一个数据库,由于存在跨JVM进程,也会产生分布式事务。
总结
仔细观察就会发生,上面三种情况,不管是跨JVM进程还是访问呢了多个数据库实例,本质上都是因为使用了不同的数据库连接。所以可以简单的理解为,一旦一组活动是由不同的数据库连接执行的,那么就会产生分布式事务问题。
分布式事务理论基础
在分布式事务中,提供服务的结点分布在不同的机器上,它们之间通过网络进行交互。而网络是极具不稳定的一个因素,我们不能由于一点网络问题就导致整个系统无法提供服务,因此网络因素承了分布式事务的考量标准之一。
我们接下来将学习CAP理论,通过CAP理论指导我们控制事务的目标,从而采取合适的分布式事务解决方案。
CAP理论
CAP是什么
CAP是Consistency、Availability和partition三个词语的缩写,分别表示一致性、可用性和分区容忍性。下面分别解释这三个名词。
Consistency
一致性指数据库写操作后的读操作可以读到最新的数据,当数据分布在多个节点上的时候,要求从结点上读到的数据都是最新数据。
如何实现一致性
- 写入主数据库后,需要将数据同步到从数据库中
- 在向从数据库同步期间需要将从数据库锁定,待数据同步后再释放锁,避免在数据同步期间,向从数据库中查到旧的数据
分布式一致性的特点
- 由于存在数据的同步,所以写操作的响应会有一定的延迟
- 为了保证一致性会对资源暂时锁定,待数据同步完成后释放锁定资源
- 如果请求数据同步失败的结点则会返回错误信息,一定不会返回旧数据
Availability
可用性要求任何事务操作都可以得到响应结果,你可以给我旧的数据,但是不能出现响应超时或相应错误。
如何实现可用性
- 写入主数据库后要将数据同步到从数据库中
- 为了保证数据库的可用性,不能锁定从数据库的资源(与一致性相反)。
- 查询从数据库时,即使还没同步新的数据,也要返回旧的数据,如果连旧的数据也没有,那么要按照约定返回一个默认的信息,但是不能返回错误或响应超时。
Partition tolerance(分区容忍)
一个分布式系统里面,节点组成的网络本来应该是连通的。然而可能因为一些故障,使得有些节点之间不连通了,整个网络就分成了几块区域。数据就散布在了这些不连通的区域中。这就叫分区。当你一个数据项只在一个节点中保存,那么分区出现后,和这个节点不连通的部分就访问不到这个数据了。这时分区就是无法容忍的。提高分区容忍性的办法就是一个数据项复制到多个节点上,那么出现分区之后,这一数据项就可能分布到各个区里。容忍性就提高了。然而,要把数据复制到多个节点,就会带来一致性的问题,就是多个节点上面的数据可能是不一致的。要保证一致,每次写操作就都要等待全部节点写成功,而这等待又会带来可用性的问题。总的来说就是,数据存在的节点越多,分区容忍性越高,但要复制更新的数据就越多,一致性就越难保证。为了保证一致性,更新所有节点数据所需要的时间就越长,可用性就会降低。
注意:分区容忍性是分布式系统最基本能力。
CAP组合
在一个标准的分布式系统中,分区容忍性是最基本的能力,在满足分区容忍性的前提下,C和A只能出现一个,因为他们从概念上就是互斥的。
所以在一个分布式系统中,只能满足AP或者CP。
AP
放弃一致性,追求分区容忍性和可用性。这是很多分布式系统设计时的选择。比如说,订单今日退款成功后,明日账户到账,这个时候只要用户可以接受在一定时间内到账即可。
通常我们都会使用最终一致性来实现AP。什么是最终一致性,举个例子。
用户:虽然我接受你晚点到账,但是你不能不到账是吧,最终一致性就是来保证最后一定到账的。
CP
放弃可用,追求一致性和分区容错性。在实时性要求较强的场景下,需要保证一致性,如跨行转账,一次转账请求需要等待双方银行系统都完成整个事务才算完成。
CA
放弃分区容忍性,即不进行分区,这种情况下其实就不是一个标准的分布式系统了。
当数据库没有从库的时,不需要进行远程的数据同步,也就不存在网络分区(不理解的话再看一下P的概率,这个情况只有一个节点)。那么CA的架构图应该是这样的:
单个数据库,通过事务隔离级别,天生就可以满足CA。
总结
在大多数应用层场景下,由于结点众多、部署分散,而且集群规模越来越大,所以结点故障、网络故障是常态,为了保证服务的可用性达到99.99…%,并达到良好的响应性能来提高用户体验,一般都选择AP,舍弃强一致性,保证最终一致性。
BASE理论
三类一致性
**强一致性:**这种一致性级别最符合用户的直觉,它要求系统写入的是什么,读出来的也要是什么,用户体验好,但是实现起来对系统的性能影响极大。
**弱一致性:**这种一致性级别,系统写入成功后,不保证立马可以读到写入的值,也不保证多久之后数据能够达到一致,但会尽量保证到某个时间(如秒级别后),数据能达到一致
**最终一致性:**是弱一致性的一种特例,系统保证在一定时间内达到一致,是业界在大型分布式系统数据一致性上用的比较多的一致性模型。
2、Base理论介绍
BASE是Basically Available(基本可用)、Soft state(软状态)和 Eventually consistent (最终一致性)三个短语的缩写。BASE理论是对AP的一个扩展,满足BASE理论的事务,我们称之为"柔性事务"。
基本可用: 这里的基本可用与CAP中的可用性不同。BASE的基本可用指的是允许损失部分可用性。
如数据库采用分片模式,100w个用户数据分在5个数据库实例上,如果破坏了一个实例,那么可用性还有80%,也就是还有80%的用户仍然可以登录,系统仍然可用。
电商大促是,为了应对访问量激增,部分用户可能会被引导到降级页面,服务层也可能只提供降级服务。这就是损失部分可用性的表现。
软状态: 由于不要求强一致性,所以BASE允许系统中存在中间状态(也叫软状态),这个状态不影响系统可用性,如订单的"支付中"、"数据同步中"等状态,待数据最终一致后改为"成功"状态
最终一致性: 最终一致性指经过一段时间后,所有结点数据都会达到一致。如订单的"支付中",最终会变成"支付成功"或"支付失败",使订单状态与实际交易结果达成一致,但需要一定时间的延迟、等待。
如有错误,欢迎指出!